讲讲消息队列 MQ
·
消息队列(Message Queue,MQ)是一种基于消息传递的通信机制,它通过将消息存储在队列中,并在发送者和接收者之间进行异步传递,从而实现解耦和异步处理。消息队列广泛用于分布式系统、微服务架构、事件驱动架构等场景,能够有效提高系统的可扩展性、可靠性和灵活性。
以下是对消息队列的详细介绍,涵盖其基本概念、工作原理、常见类型和应用场景。
1. 消息队列基本概念
- 消息(Message)
消息是队列中的基本数据单元,通常由消息头(Message Header)和消息体(Message Body)组成:
消息头(Message Header): 包含元数据,如消息的类型、优先级、时间戳、过期时间、消息的唯一标识符等。
消息体(Message Body): 实际承载业务数据的部分。它可以是文本、JSON、二进制数据、文件等格式的数据,具体内容取决于系统的需求。 - 队列(Queue)
消息存储容器,消息在队列中按照先进先出(FIFO)顺序排列。队列是生产者发送消息并等待消费者处理消息的地方。 - 生产者(Producer)
消息的发送者,将消息发送到队列中。 - 消费者(Consumer)
-消息的接收者,从队列中取出消息并进行处理。 - 代理(Broker)
消息队列的核心组件,负责接收、存储和转发消息。代理接收来自生产者的消息并将其存储在队列中,随后将消息传递给消费者。 - 消息传递协议(Protocol)
消息队列通常使用特定的协议来规范消息的发送、接收和确认流程。常见的协议包括AMQP(RabbitMQ)、JMS(Java Message Service)、MQTT等。
2. 消息队列的工作原理
消息队列的工作原理可以分为以下几个步骤:
1.生产者发送消息:
- 生产者生成消息并将其发送到消息队列,消息通常会被存储在内存或磁盘中,直到被消费者处理。
- 生产者发送消息后无需等待消费者的反馈,可以继续执行其他操作。
2.消息存储:
- 消息队列根据一定的存储策略,将消息存储在指定的队列中。
- 消息可以是临时存储(例如仅存在内存中)或者持久化存储(例如保存到磁盘)。
- 消息队列通常会对消息进行排序,并且可以支持消息的持久化机制,以避免消息丢失。
3.消费者接收消息:
- 消费者从队列中拉取消息并进行处理。
- 消费者根据需求从队列中异步地拉取消息,并处理这些消息。
- 消费者可以选择按批量或逐条拉取消息,消费过程通常是异步的,以提高系统的并发处理能力。
4.消息确认:
- 一旦消费者成功处理完消息,它会向消息队列发送确认信号,表示该消息已被成功处理。
- 此时,消息队列会将消息从队列中移除。如果消费者处理失败(如崩溃或异常),消息会被重新投递或移到特殊的死信队列中。
5.消息丢失与重复处理:
- 消息队列通常会提供消息重试机制,确保在处理失败的情况下,消息可以被重新投递给其他消费者。
- 同时,通过幂等性设计(即消费者在多次处理同一消息时结果一致),可以防止消息被重复消费时造成的副作用。
3. 消息队列的主要特性
3.1 异步处理
- 消息队列使得生产者和消费者可以异步工作,生产者将消息放入队列中后,立即返回,不需要等待消费者处理结果。这降低了系统耦合度,提高了系统的响应性。
3.2 解耦
- 消息队列将生产者与消费者解耦,生产者不需要直接与消费者进行交互。
- 生产者只关心将消息发送到队列,而消费者只需要从队列中读取消息并处理。这样一来,生产者和消费者可以独立地扩展和维护。
3.3 消息持久化
- 消息队列通常会将消息持久化存储,以确保在系统崩溃或重启时消息不会丢失。
- 持久化机制通过将消息写入磁盘或数据库来实现。
3.4 可靠性与事务性
- 消息队列通过消息确认机制、事务消息等方式,确保消息的可靠性。消费者在成功处理消息后,会向队列确认消息已被处理。如果消费失败,消息可以重新投递或回滚。
3.5 扩展性与高可用性
- 消息队列通常支持集群模式,以提高可用性和扩展性。
- 通过增加节点或分区,可以提高系统的吞吐量,分担负载。
3.6 顺序性
- 消息队列通常可以保证队列内的消息顺序,尤其是在单个队列内。
- 如果队列被分成多个分区,通常会保证每个分区内的消息顺序,但跨分区的消息顺序无法保证。
4. 消息队列的种类与实现
消息队列的实现方式有多种,不同的实现方式会影响系统的性能、可靠性、扩展性等方面。以下是两种常见的消息队列类型:
4.1 点对点(P2P)模型
- 工作原理: 在点对点模型中,消息从生产者发送到队列,队列中的消息只会被一个消费者消费。即每个消息只能被一个消费者处理。
- 适用场景: 任务队列、负载均衡等场景。

4.2 发布/订阅(Pub/Sub)模型
- 工作原理: 在发布/订阅模型中,消息从生产者发布到一个主题,多个消费者可以订阅该主题,并接收相同的消息。即每个消息可以被多个消费者处理。
- 适用场景: 广播消息、事件驱动架构等场景。
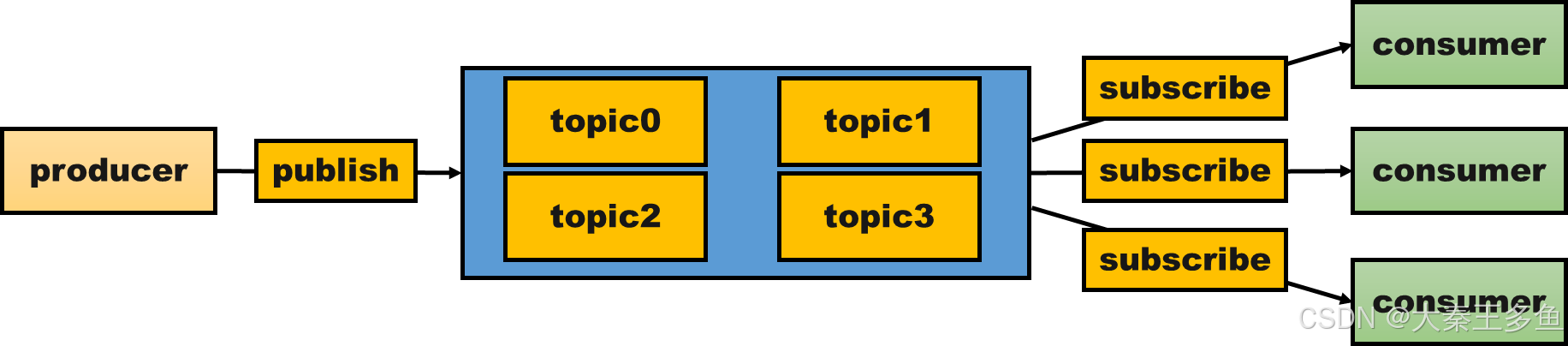
5. 常见的消息队列对比(Kafka、RabbitMQ、RocketMQ)
Kafka、RabbitMQ 和 RocketMQ 都是流行的消息中间件系统,每个系统都有其独特的设计哲学和适用场景。尽管它们的基本功能相似,都用于消息的发送和接收,但在架构设计、性能、可靠性、扩展性和使用场景等方面有所不同。
5.1 Kafka 与 RabbitMQ、RocketMQ 的对比概述
| 特性 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 架构设计 | 分布式、基于日志的消息系统 | 基于 AMQP 协议的消息队列,支持多种模式 | 分布式、支持高吞吐量和低延迟的消息系统 |
| 消息存储 | 长时间存储,持久化到磁盘(支持消息保留策略) | 默认持久化,消息存储是队列中的临时数据 | 支持持久化和高吞吐量的存储方式 |
| 消费者模型 | 支持拉取(pull)模型和消费者组(consumer group) | 支持推送(push)模型和消费者模式 | 支持拉取(pull)模型和消费者组(consumer group) |
| 消息顺序性 | 支持分区内顺序,跨分区无顺序保证 | 每个队列内的消息是有序的 | 支持分区内顺序,但跨分区无顺序保证 |
| 消息确认机制 | 支持消息的自动或手动确认 | 支持消息确认(ACK) | 支持消息确认(ACK) |
| 扩展性 | 极高的横向扩展性,可以扩展到数千个分区 | 水平扩展较为困难,性能瓶颈较早出现 | 高度可扩展,支持分布式架构 |
| 协议支持 | 自定义协议,主要用于流式数据处理 | 基于 AMQP 协议,支持多种消息传输协议 | 自定义协议,兼容 Kafka 的协议 |
| 使用场景 | 大规模流式数据处理、日志聚合、事件溯源等 | 高可靠性、低延迟的小消息系统、请求/响应模式 | 高吞吐量、分布式事务、金融级消息传递 |
| 性能 | 高吞吐量、低延迟、大数据流处理 | 较低的吞吐量,适合短小消息 | 高吞吐量、低延迟,适合大规模分布式场景 |
| 延迟 | 较低,尤其在分布式系统中 | 一般,依赖于系统负载和网络性能 | 较低,支持高吞吐量的低延迟处理 |
5.2 Kafka vs RabbitMQ vs RocketMQ 详细对比
5.2.1 架构设计
- Kafka: Kafka 是一个分布式的日志消息系统,采用了发布-订阅模式,支持大量的消息流,通常用于大规模数据处理、日志收集、流处理等。Kafka 的核心是高效的日志存储,它将所有消息按顺序追加到分区中的日志文件中,可以高效地进行数据写入与读取。
- RabbitMQ: RabbitMQ 是一个基于 AMQP(高级消息队列协议) 的消息队列系统。它通过支持多种队列和路由模式,提供了丰富的消息传递特性。RabbitMQ 采用传统的队列模型,即生产者将消息放入队列,消费者从队列中消费消息。
- RocketMQ: RocketMQ 是阿里巴巴开源的分布式消息队列系统,基于分布式日志的架构。它强调高吞吐量和低延迟,特别适用于金融、电商等场景的高并发消息处理。
5.2.2 消息存储与持久化
- Kafka: Kafka 使用磁盘持久化消息,它的消息存储机制非常高效。消息会按分区持久化到磁盘,并支持通过配置进行消息保留策略(如按时间或按大小)。这使得 Kafka 能够高效地存储大规模的数据并且不容易丢失消息。
- RabbitMQ: RabbitMQ 默认会将消息持久化到磁盘,消息的持久化与否是通过队列的配置决定的。它支持较为复杂的持久化和消息确认机制,但对于高吞吐量场景,其性能可能不如 Kafka。
- RocketMQ: RocketMQ 也支持消息持久化,且采用 分布式存储 方式,具备较高的吞吐量和可扩展性。它的数据存储采用高效的日志存储结构,可以按需清理过期消息。
5.2.3 消费者模型
- Kafka: Kafka 提供了消费者组(Consumer Group)的概念,多个消费者可以共同消费一个主题(Topic),每个消费者只消费该主题的一部分分区,保证了负载均衡和扩展性。消费者基于拉取(Pull)模型,从 Kafka 中拉取消息。
- RabbitMQ: RabbitMQ 采用推送(Push)模型,消费者会从队列中接收消息。它通过队列中的消息分配给消费者,可以选择多种路由方式(如简单队列、主题交换机、直连交换机等)。
- RocketMQ: RocketMQ 也使用拉取(Pull)模型,它支持消息的顺序消费,并提供了消费者组的功能。RocketMQ 支持分布式事务消息,特别适合高并发的金融级别应用。
5.2.4 消息顺序与可靠性
- Kafka: Kafka 保证分区内的消息顺序,但不保证跨分区的顺序性。它的消息确认机制支持自动确认或手动确认,消费者可以通过管理偏移量来控制消费进度。Kafka 通过副本机制保证消息的可靠性。
- RabbitMQ: RabbitMQ 保证队列内的消息顺序。消息确认机制支持客户端显式确认(ACK)。如果消息没有被确认,则会被重新投递到队列中。它通过持久化机制保证可靠性,但在高负载下可能会出现性能瓶颈。
- RocketMQ: RocketMQ 支持分区内顺序消费,但不保证跨分区顺序。它的消息确认机制较为灵活,支持多种消息模式,如一次性消息、顺序消息、事务消息等。RocketMQ 使用副本机制保障消息的可靠性。
5.2.5 扩展性与性能
- Kafka: Kafka 是非常适合大规模分布式系统的消息队列,具有极高的吞吐量。其水平扩展性非常强,可以通过增加分区数和节点来扩展系统的容量和性能。
- RabbitMQ: RabbitMQ 水平扩展能力有限,虽然可以通过集群和镜像队列来扩展,但它的扩展性通常不如 Kafka。它的性能在吞吐量要求较高时可能受到限制。
- RocketMQ: RocketMQ 提供了较高的扩展性,能够处理大规模的消息流。它支持分布式部署,尤其在分布式事务消息和高并发场景下表现优秀。
5.2.6 使用场景
- Kafka: Kafka 非常适合高吞吐量、大规模数据流处理、日志收集、事件溯源和实时数据分析等场景。Kafka 是流式数据处理和大数据分析生态中的重要组件。
- RabbitMQ: RabbitMQ 适用于请求/响应模式、任务队列模式、异步消息处理、轻量级的应用场景。它的设计偏向于支持高可靠性、低延迟的消息传递。
- RocketMQ: RocketMQ 适用于金融、电商、物流等需要高吞吐量、低延迟、高可靠性的场景,尤其在分布式事务消息和高并发场景下有良好的表现。
5.3 核心架构
5.3.1 Kafka
- 架构类型: 分布式日志存储,消息通过 主题(Topic) 管理。
- 数据存储: 主题分为多个 分区(Partition),分区内的消息是有序的。
- 消费模型: 基于 消费组(Consumer Group),支持广播模式和负载均衡模式。
- 高吞吐: 使用磁盘顺序写和零拷贝优化数据写入性能。
- 数据保留: 支持基于时间或存储大小的日志清理策略(删除或压缩)。
5.3.2 RabbitMQ
- 架构类型: 基于 AMQP 协议的消息代理,使用 交换机(Exchange) 和 队列(Queue)。
- 路由机制: 消息通过交换机路由到一个或多个队列(支持 Direct、Fanout、Topic、Headers 模式)。
- 消费模型: 支持点对点和发布订阅模式。
- 易用性: 具备丰富的管理界面和工具,支持多种协议(AMQP、MQTT、STOMP)。
5.3.3 RocketMQ
- 架构类型: 分布式消息队列,设计与 Kafka 类似,支持日志和队列模式。
- 数据存储: 消息以 主题(Topic) 的形式组织,并分为多个 队列(Queue)。
- 消费模型: 支持广播模式和负载均衡模式。
- 事务支持: 提供强大的事务消息能力。
- 大数据集成: 深度集成 Hadoop 和 Spark 等生态系统。
5.4 选择建议
| 需求 / 特点 | 推荐系统 |
|---|---|
| 高吞吐量,适配大数据场景 | Kafka |
| 复杂路由,低延迟场景 | RabbitMQ |
| 事务消息,延迟消息 | RocketMQ |
| 实时数据流处理 | Kafka |
| 企业级消息传递 | RabbitMQ |
| 分布式事务、高可靠性 | RocketMQ |
6. 消息队列的应用场景
- 异步处理
消息队列常用于将耗时操作(如邮件发送、支付处理等)从主业务流程中分离出来,异步处理任务以提高系统响应速度。 - 任务调度
消息队列可以作为任务调度器,帮助系统在不同的时间处理不同的任务,避免系统过载。 - 事件驱动架构
在微服务和分布式系统中,消息队列常用于事件驱动架构,服务之间通过消息传递进行通信,解耦各个服务。 - 流量削峰
消息队列可以作为缓冲区,帮助系统处理流量高峰期的消息,将高并发请求分散到后端处理。 - 日志聚合
Kafka 等消息队列广泛用于日志采集和流处理,将日志信息从不同的应用系统发送到集中式日志系统中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)