【开源首发】双脑 AI 工作流:强制模型隔离 + 省 60% Token,完美替代 CrewAI,支持本地 Ollama 免费跑

前言
大家好,我是一名大一的生物医药数据科学专业学生。最近半年一直在用 AI 做各种自动化工具,前前后后踩了 LangChain 和 CrewAI 的无数坑。
我发现所有主流 AI Agent 框架都有一个致命的设计盲区:它们默认相信 AI 能自己监督自己。但实际用下来你会发现,让同一个模型既规划任务又审核结果,本质上就是让学生自己改卷子。它会用完美的逻辑自圆其说自己的幻觉,改十轮都发现不了问题,最后 Token 还哗哗烧。
忍无可忍之下,我花了两个月课余时间,写了一个完全不同思路的 AI 工作流引擎:AI Flow Architect,今天正式开源。
核心就一条不可打破的铁律:负责规划的模型,绝对不能负责审核。
一、我踩过的那些无解的坑
相信每一个用过 AI Agent 框架的人都感同身受:
- 角色混淆是天生的:你把产品、开发、测试的 prompt 写得再详细,跑着跑着 AI 就忘了自己是谁,测试开始写代码,产品开始改架构
- 自审等于没审:让 GPT-4o 检查 GPT-4o 写的代码,它会拍着胸脯说 "没有任何问题",结果一运行全是低级 bug
- Token 浪费到肉疼:每次调用都传完整上下文,一个简单的任务跑下来几十块钱没了,还不知道花在哪了
- 调试地狱:出了问题根本不知道是哪一步错了,只能对着几百行日志瞎猜
我试过所有能找到的优化方法:拆分 prompt、加角色前缀、手动做上下文压缩、加人工审核... 最后发现,这些全都是治标不治本。调 prompt 解决不了这个问题,这是架构层面的缺陷。
二、我的解决方案:强制双脑隔离架构
既然 AI 不能自己监督自己,那我就用两个完全独立的 AI。我设计了一个固定的三阶段双脑流程,从根上解决这个问题: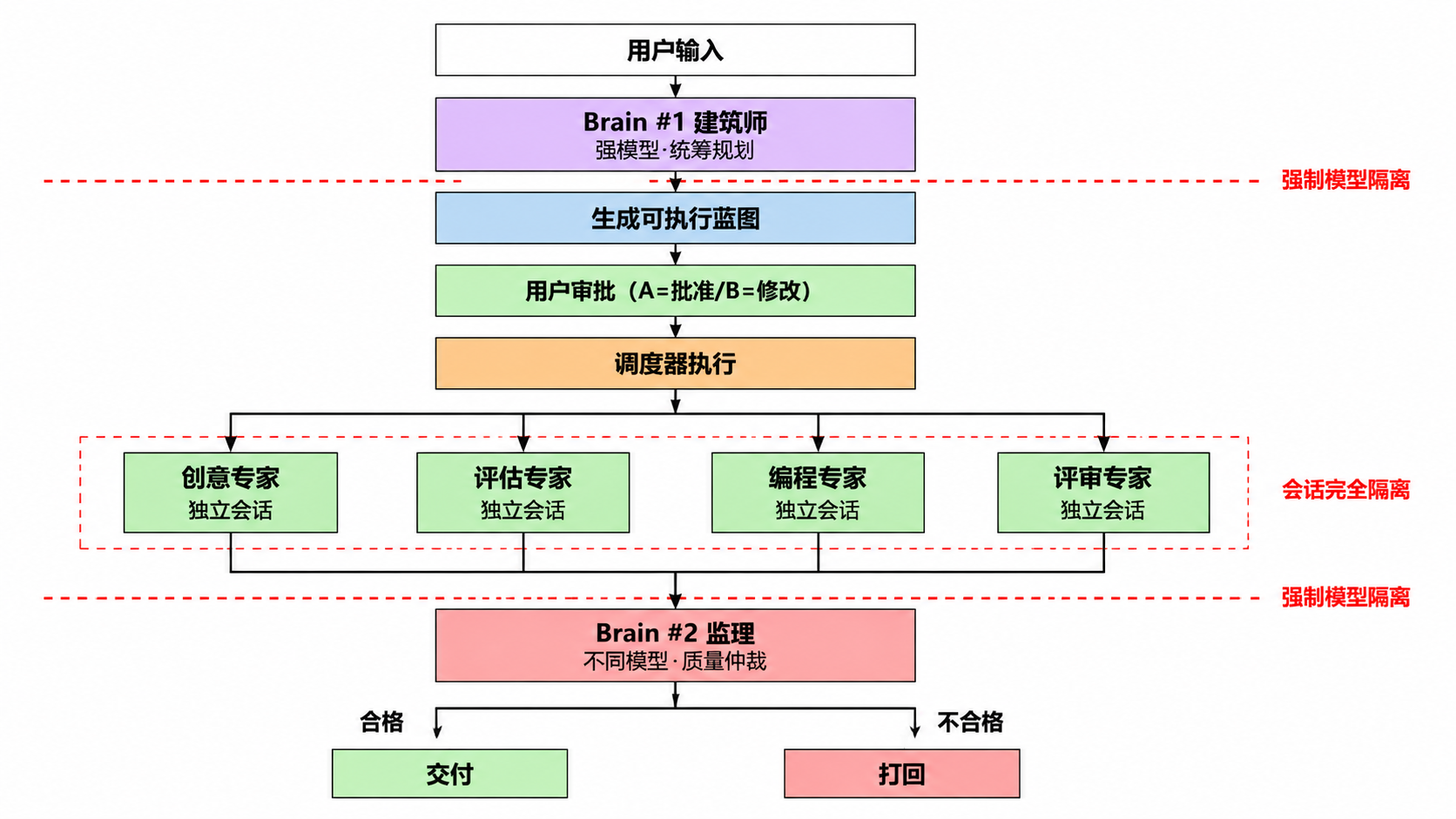
- Brain1(建筑师):只用强模型(如 gpt-4o、Claude Sonnet),只负责一件事:把用户的模糊需求拆解成可执行的任务蓝图,每一步都明确专家角色和交付标准
- 用户审批:蓝图生成后必须经过用户确认,不满意可以随时修改,从源头避免 AI 跑偏浪费 Token
- 调度器执行:所有专家(创意 / 评估 / 编程 / 评审)都是完全独立的会话,互相不知道对方的存在,只能通过结构化字段传递数据,彻底杜绝角色混淆
- Brain2(监理):强制使用和 Brain1 不同的模型,只负责一件事:逐项对比 "需求蓝图" 和 "最终交付物",不合格直接打回对应步骤修改
两个大脑完全隔离,Brain2 根本看不到 Brain1 的思考过程,只能做客观的第三方仲裁。亲测 OpenAI+Anthropic 的组合,能发现 90% 以上单模型看不到的幻觉和遗漏。
三、与主流框架核心对比
为了质量,我主动放弃了所有主流框架都在吹的 "无限灵活性",用固定流程换可预测性和质量控制。这是我们最核心的差异:
| 维度 | AI Flow Architect | LangChain | CrewAI |
|---|---|---|---|
| 质量控制 | ✅ 内置跨模型强制仲裁 | ❌ 完全手动实现 | ⚠️ 可选单模型自审 |
| Token 优化 | ✅ 4 种机制零配置自动运行 | ❌ 需手动编写优化逻辑 | ❌ 需手动编写优化逻辑 |
| 角色隔离 | ✅ 架构层面强制会话隔离 | ❌ 不强制,共享上下文 | ❌ 不强制,共享上下文 |
四、实测效果:Token 直接砍 60%
除了质量提升,最让我惊喜的是成本控制。同样是 "设计并实现一个用户管理系统" 的任务:
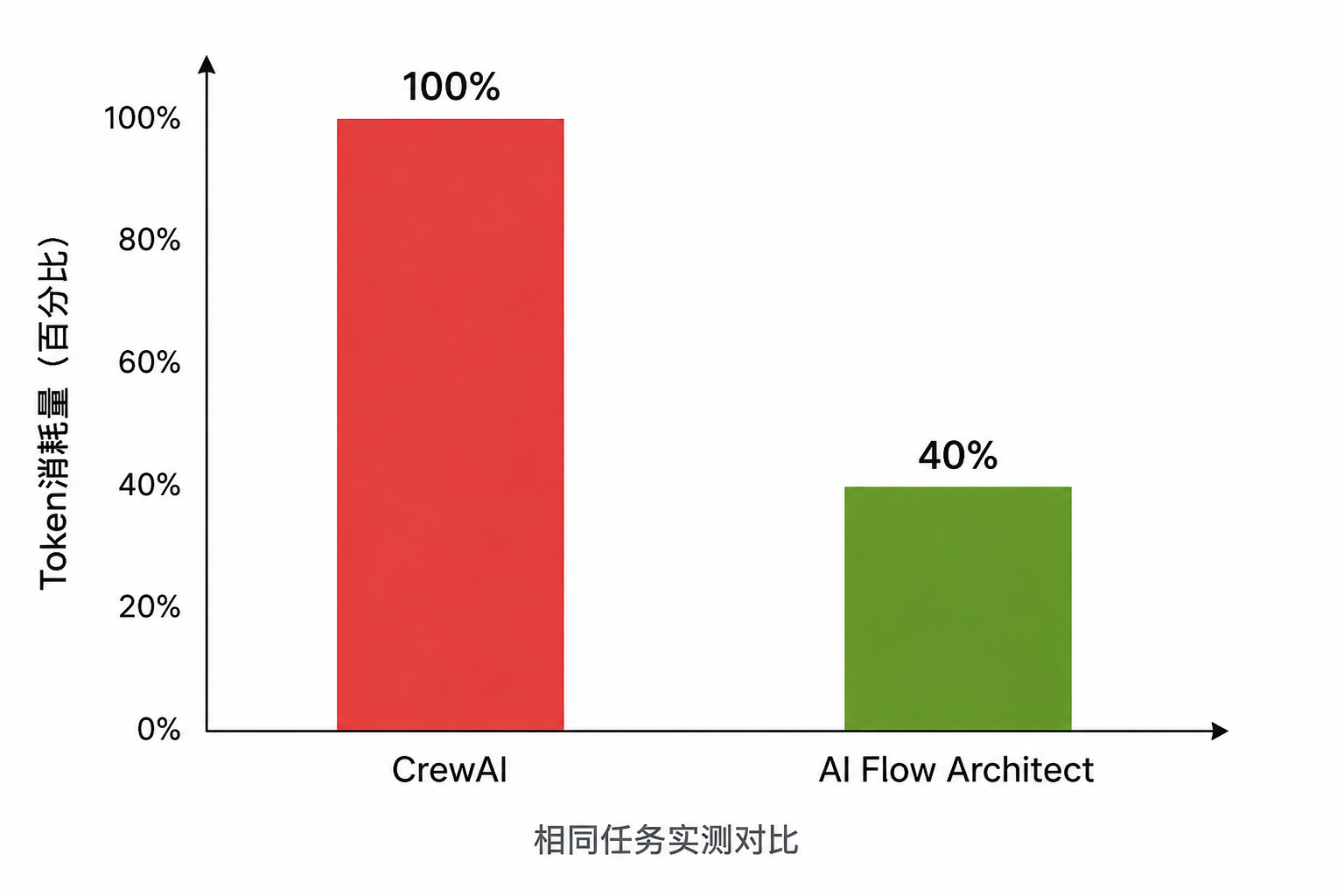
这得益于我内置的 4 种零配置 Token 节省机制,开箱即用,不用你写一行代码:
- ✅ 语义缓存:相同专家 + 相同任务直接命中缓存,跳过 API 调用
- ✅ 上下文自动压缩:历史超过阈值自动精简,减少约 60% 输入 Token
- ✅ 本地规则预检查:空任务、无效专家等直接拦截,0 成本
- ✅ 智能跳过:步骤失败自动终止后续流程,低复杂度步骤自动跳过
五、3 分钟快速上手(手把手教程)
1. 安装
git clone https://github.com/wdnmd1265/ai-flow-architect.git
cd ai-flow-architect
pip install -e .2. 配置
复制.env.example为.env,添加你的 API 密钥:
# 单OpenAI密钥即可开箱即用
OPENAI_API_KEY=sk-your-key
# Brain2会自动选择gpt-4o-mini做审核3. 运行
import asyncio
from ai_flow_architect import FlowArchitect
async def main():
# 一行代码初始化,什么都不用额外配置
architect = FlowArchitect(config={"brain1": "gpt-4o"})
result = await architect.run("设计一个用户管理系统")
if result["status"] == "success":
print(f"质量评分: {result['audit_result'].get('score', 'N/A')}/100")
else:
for suggestion in result["revision_suggestions"]:
print(f"修改建议: {suggestion}")
asyncio.run(main())4. 本地 Ollama 运行(完全免费)
如果你不想花钱用云模型,完美支持本地 Ollama:
- 安装 Ollama:https://ollama.com/
- 拉取模型:
ollama pull llama3 - 修改配置:
architect = FlowArchitect(config={
"brain1": "llama3",
"brain2": "qwen2.5-coder"
})六、已支持的所有模型提供商
目前已经支持所有主流模型,新增提供商只需要在models.yaml里加几行配置,不用修改任何 Python 代码:
- 云厂商:OpenAI、Anthropic、通义千问、智谱 GLM、月之暗面、DeepSeek
- 本地部署:Ollama(llama3、qwen2.5-coder 等所有模型)
- 自定义:兼容所有 OpenAI 格式的 API(vLLM、LocalAI、代理服务)
七、工程化保障
作为一个个人开发者的项目,我特别注重稳定性和可维护性:
- ✅ 114 个单元测试覆盖所有核心模块
- ✅ 三级错误处理:指数退避重试→自动模型降级→用户决策
- ✅ 三层提示系统:全局格式约束 + 角色预设 + 任务指令,保证输出一致性
- ✅ 字段过滤:仅传递专家必需的输入字段,避免信息过载
八、写在最后
必须坦诚地说,它不是万能的,也绝对不是 LangChain 和 CrewAI 的替代品。
- 如果你需要高度定制化的复杂 Agent、需要调用各种工具链、需要无限灵活的流程,那 LangGraph 和 CrewAI 会更适合你
- 但如果你只是想让多个 AI 帮你完成一个可预测的任务—— 写代码、写文档、做设计、分析数据 —— 并且希望输出质量有保证、不会乱花 Token、调试简单,那这个工具绝对值得一试
项目今天刚开源,还有很多不完善的地方。路线图里的 CLI 工具、PyPI 包、并行执行、流式输出、Web UI 都在紧锣密鼓地开发中。
我是一个大一学生。有任何 bug 或者建议,都可以在 GitHub 提 issue,我会第一时间回复。
如果觉得这个项目对你有帮助,麻烦去 GitHub 点个 Star,这对我这个个人开发者真的非常非常重要。谢谢大家🙏

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)