LoRA/QLoRA 微调实战:单卡 GPU 训练自己的大模型,2026 完全指南
为什么 2026 年人人都在微调?
2026 年,微调一个 7B 模型只需要不到 5 美元。LoRA 论文发表于 2021 年,但直到 2025-2026 年 QLoRA + PEFT + 开源模型三件事同时成熟,微调才真正进入"个人开发者友好"时代。
三个关键数字: - $5:微调 Qwen3-8B 的 GPU 成本(单张 RTX 4090,1小时) - 10MB:LoRA adapter 的文件大小(原始模型 16GB+) - 1000条:高质量微调数据所需的最少样本量
LoRA 原理:三个矩阵的魔术
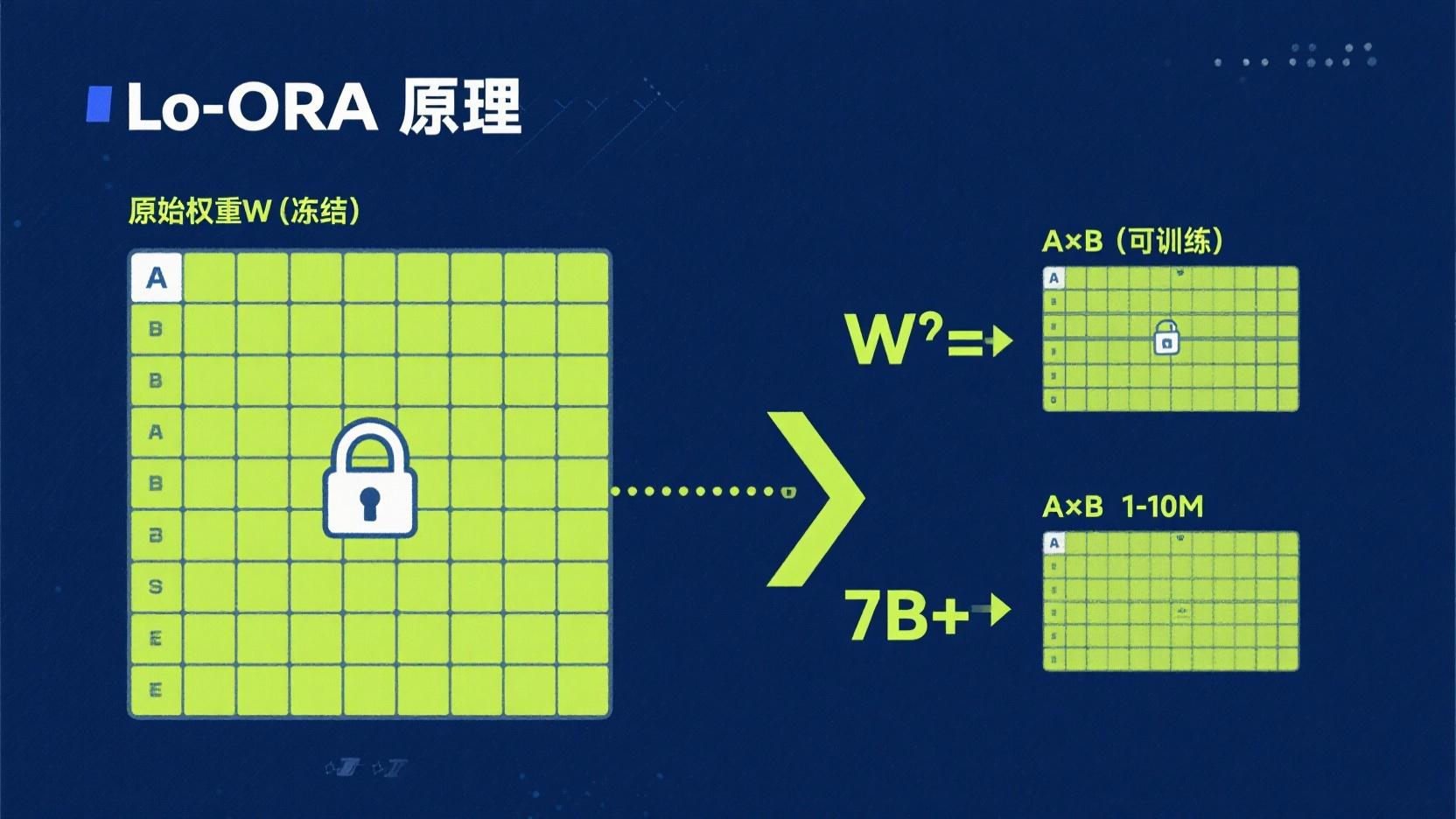
LoRA 的核心思想极其优雅:不修改原始模型权重,在旁路训练两个小矩阵 A 和 B,用 A×B 的结果作为一个"增量"加到原始输出上。
原始: h = W × x
LoRA: h = W × x + (α/r) × A × B × x
^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^
冻结不动 只训练这一小部分
参数对比: - 原始 Qwen3-8B:8,000,000,000 个参数 - LoRA adapter(r=16):约 10,000,000 个参数 - 比例:1:800
这就是为什么 LoRA 能在单张消费级显卡上微调 7B 模型。
关键参数 r(rank): - r=4:极低参数量,适合简单任务(风格迁移、分类) - r=8:保守值,大多数任务够用 - r=16:标准值,性能接近全量微调 - r=64:几乎全量微调效果,但参数量也大了
实战:用 QLoRA 微调 Qwen3-8B
完整可运行的代码,基于 HuggingFace PEFT + bitsandbytes:
import torch
from transformers import (
AutoModelForCausalLM, AutoTokenizer,
TrainingArguments, Trainer, DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from datasets import Dataset
import bitsandbytes as bnb
# ── 1. 以 4-bit 量化加载模型 ──
model_name = "Qwen/Qwen3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_4bit=True, # QLoRA 关键:4-bit加载
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True, # 双重量化,再省30%显存
bnb_4bit_quant_type="nf4" # NF4 量化格式
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# 启用梯度检查点 + 量化训练准备
model = prepare_model_for_kbit_training(model)
# ── 2. 配置 LoRA ──
lora_config = LoraConfig(
r=16, # rank
lora_alpha=32, # 缩放因子(通常 2×r)
target_modules=[ # 关键:对哪些层加 LoRA
"q_proj", "k_proj", "v_proj", "o_proj", # Attention 四件套
"gate_proj", "up_proj", "down_proj" # FFN 三层
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出: trainable params: 10,485,760 || all params: 8,010,485,760 || trainable%: 0.13%
# ── 3. 准备数据 ──
# 格式: {"instruction": "...", "input": "...", "output": "..."}
data = [
{
"instruction": "将以下SQL查询翻译为自然语言解释",
"input": "SELECT name, COUNT(*) FROM orders WHERE date > '2026-01-01' GROUP BY name HAVING COUNT(*) > 5",
"output": "这个查询查找2026年以来下单超过5次的客户名称及其订单数量。"
},
# ... 至少 500-1000 条
]
def format_chat(example):
"""格式化为 ChatML 格式"""
return {
"text": f"<|im_start|>system\n你是一个SQL专家。<|im_end|>\n"
f"<|im_start|>user\n{example['instruction']}\n{example['input']}<|im_end|>\n"
f"<|im_start|>assistant\n{example['output']}<|im_end|>"
}
dataset = Dataset.from_list(data).map(format_chat)
def tokenize(examples):
return tokenizer(
examples["text"], truncation=True,
padding="max_length", max_length=1024
)
tokenized_dataset = dataset.map(tokenize, batched=True)
# ── 4. 训练 ──
training_args = TrainingArguments(
output_dir="./qwen3-lora-sql",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # 等效 batch_size=16
learning_rate=2e-4,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
logging_steps=10,
save_steps=100,
bf16=True,
optim="paged_adamw_8bit", # 8-bit 优化器,再省显存
report_to="none"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
trainer.train()
# ── 5. 保存 + 合并 ──
model.save_pretrained("./qwen3-lora-sql-adapter")
tokenizer.save_pretrained("./qwen3-lora-sql-adapter")
# 可选:合并adapter到base model
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
merged_model = PeftModel.from_pretrained(base_model, "./qwen3-lora-sql-adapter")
merged_model = merged_model.merge_and_unload()
merged_model.save_pretrained("./qwen3-lora-sql-merged")
超参数调优决策表
| 参数 | 保守值 | 推荐值 | 激进值 | 说明 |
|---|---|---|---|---|
| r (rank) | 8 | 16 | 64 | 任务越复杂,r 越大 |
| lora_alpha | 16 | 32 | 64 | 通常是 2×r |
| learning_rate | 1e-4 | 2e-4 | 5e-4 | QLoRA 可用稍大的 lr |
| batch_size (等效) | 8 | 16 | 32 | 取决于显存 |
| epochs | 1 | 3 | 5 | 小数据集多epoch,大数据集1-2 |
| lora_dropout | 0.0 | 0.05 | 0.1 | 小数据集可用更高防止过拟合 |
五个踩坑经验
① target_modules 别偷懒。只对 q_proj/v_proj 加 LoRA 效果打折 15-20%。2026 年的共识:Attention 四件套 + FFN 三层全部加 LoRA,多出来的参数量微不足道但效果显著。
② 数据质量 > 数据数量。500 条高质量、多样化的数据比 5000 条同质数据效果好。每条数据必须是"你想让模型学会的输入-输出对"。
③ ChatML 格式要严格。微调指令模型时,数据格式必须和 base model 的训练格式一致。Qwen 用 <|im_start|> / <|im_end|>,Llama 用 [INST] / [/INST],搞混了模型学不会。
④ 先跑小实验验证数据。用 100 条数据 + 1 epoch 快速验证:loss 在下降吗?输出格式对吗?没问题再用全量数据。
⑤ LoRA adapter 可以热插拔。训练好的 adapter 是独立的 10MB 文件,同一个 base model 可以加载不同 adapter 实现不同能力。SQL adapter、翻译 adapter、代码 adapter——一个模型,多种人格。

什么时候不要微调
- 知识更新 → 用 RAG(微调不适合注入新事实,容易 hallucinate)
- 只需改变输出风格 → 用 Few-Shot Prompting(成本为 0)
- 数据不足 200 条 → 先收集数据,200 条以上再考虑微调
- 不确定需求 → 先用 Prompt Engineering + RAG 验证需求,锁定后再微调
小结
2026 年的 LoRA/QLoRA 微调已经成熟到"下载脚本 → 准备数据 → 跑训练 → 部署"的流水线程度。成本不到一杯咖啡,技术壁垒降到零——留给你的是"手里有没有好的训练数据?"
下一篇预告:微调数据工厂——如何用 LLM 自动生成高质量训练数据,构建微调数据集流水线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)