[论文阅读]OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-comm
OneSearch: 电商搜索的端到端生成式框架探索
论文信息
- 标题: OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search
- ArXiv ID: 2509.03236
- 发表时间: 2025年9月(最新v5: 2025年10月22日)
- 作者单位: 快手(Kuaishou)
- 领域: Information Retrieval (cs.IR)
- 作者团队: Ben Chen, Xian Guo 等27位作者
研究背景
传统电商搜索系统依赖多级级联架构(Multi-stage Cascading Architecture, MCA):
用户查询 → 召回 → 粗排 → 精排 → 结果返回
存在问题:
- 计算碎片化:各阶段独立优化,信息传递断层
- 优化目标冲突:不同阶段目标函数相互矛盾
- 性能上限受限:整体效果受制于最弱环节
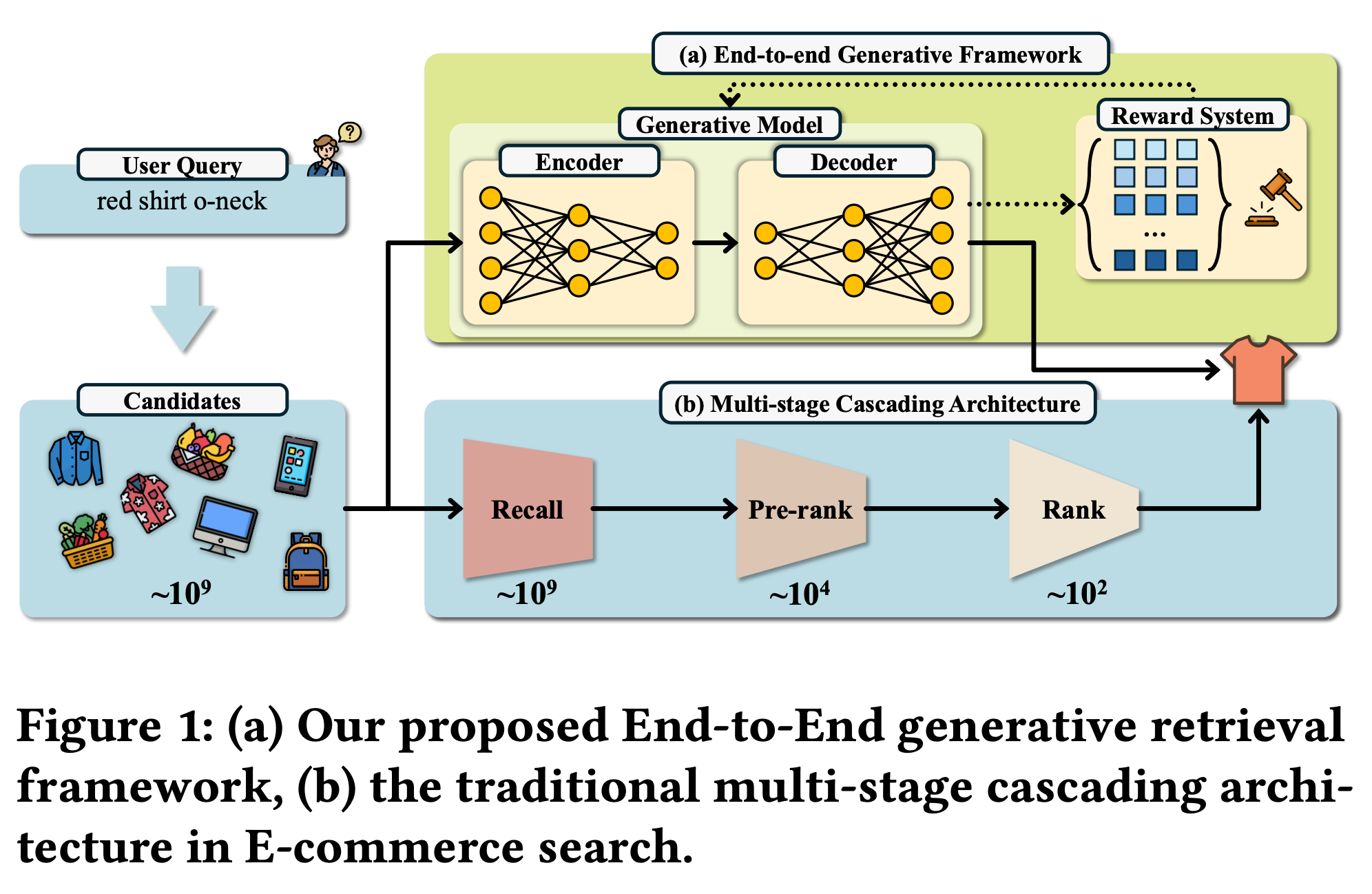
OneSearch 核心创新
可以把 OneSearch 理解成下面这个生成过程:
用户ID + 查询query + 查询SID + 短期行为 + 长期行为 + 用户画像 ⟹ 商品SID序列
OneSearch提出首个工业部署的端到端生成式电商搜索框架,通过三大技术模块实现端到端优化: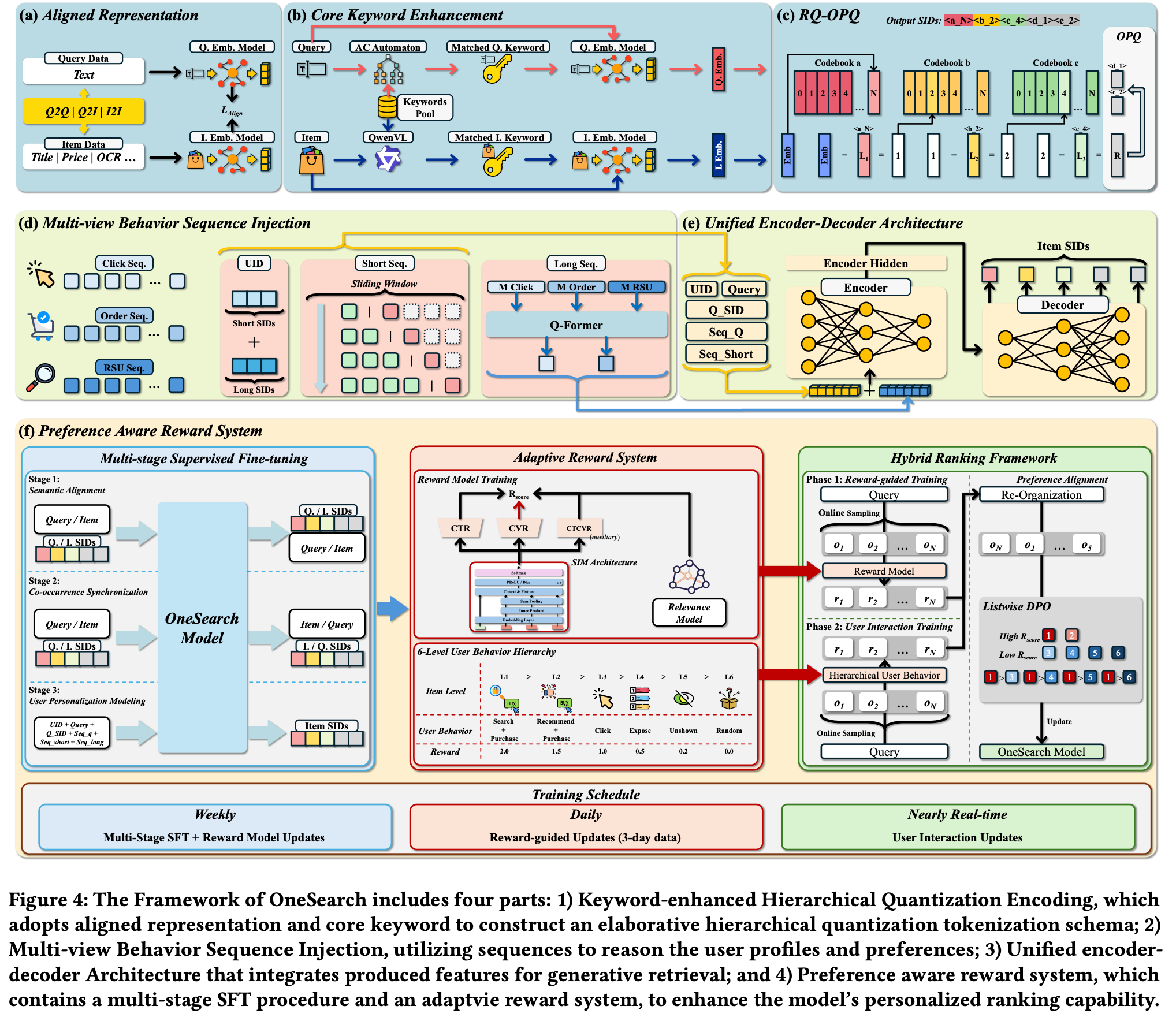
KHQE模块(Keyword-enhanced Hierarchical Quantization Encoding)
最重要的底层设计之一。生成式检索不能直接生成商品 ID,因为商品数量巨大、ID 无语义、冷启动差。因此需要把商品映射成一串离散 token,也就是 Semantic IDs,简称 SIDs。
功能:关键词增强的层次化量化编码
解决问题:
- 保留商品层次语义(类目、品牌、属性)
- 维持强query-item相关性约束
- 防止量化过程中的信息丢失
技术特点:
原始商品信息 → 层次化编码 → 关键词增强 → 量化向量
↓
保留语义结构 + 提升检索精度
多视角用户行为序列注入策略
功能:全面建模用户偏好
创新点:
- 行为驱动用户ID:基于行为模式构建用户画像
- 双序列融合:
- 显式短期序列:近期浏览、点击、加购
- 隐式长期序列:历史兴趣、偏好演化
架构:
用户行为数据
├── 短期序列(显式)→ 即时兴趣建模
└── 长期序列(隐式)→ 稳定偏好挖掘
↓
综合用户表征 → 精准推荐
- 短期行为序列 :最近5-10个点击/购买,直接作为prompt输入,捕捉即时兴趣
- 长期行为序列 :上千个历史行为通过向量聚合,隐式注入模型,建模稳定偏好
- 行为衰减权重 :越近期的行为权重越高,用指数衰减函数建模
PARS(Preference-Aware Reward System)
功能:偏好感知奖励系统
核心机制:
-
多阶段监督微调(Multi-stage Supervised Fine-tuning)
- Stage 1: 基础相关性学习
- Stage 2: 用户偏好对齐
- Stage 3: 业务目标优化
-
自适应奖励加权排序
- 动态调整不同信号权重
- 平衡点击、转化、长期价值
这里的加权指的是他们把用户行为进行了6个层次的划分:
- L1: 搜索后购买(权重2.0)
- L2: 推荐场景购买同类商品(权重1.5)
- L3: 点击(权重1.0)
- L4: 曝光未点击(权重0.5)
- L5: 同类目未展示商品(权重0.2)
- L6: 随机负样本(权重0.0)
优势:
- 捕捉细粒度用户偏好
- 避免单一优化目标偏差
- 提升长期用户满意度
方法总结
| 模块 | 解决的问题 |
|---|---|
| KHQE:关键词增强的层次量化编码 | 如何把商品/查询编码成适合生成模型预测的 Semantic IDs |
| Mu-Seq:多视角行为序列注入 | 如何让模型理解用户短期兴趣和长期偏好 |
| Unified Encoder-Decoder | 如何把搜索建模成端到端生成任务 |
| PARS:偏好感知奖励系统 | 如何让生成结果既相关,又符合点击、购买、转化偏好 |
实验结果
离线评估
在大规模工业数据集上验证:
- 召回质量显著提升
- 排序精度明显优于基线
- 端到端优化消除级联损失
线上A/B测试
测试条件:同等曝光位置对比
业务指标提升(统计显著):
| 指标 | 提升幅度 | 说明 |
|---|---|---|
| 商品点击率(CTR) | +1.67% | 用户点击意愿提升 |
| 购买用户数 | +2.40% | 转化用户增加 |
| 订单量 | +3.22% | 实际成交增长 |
效率优化
| 指标 | 优化效果 | 备注 |
|---|---|---|
| 运营支出(OpEx) | -75.40% | 成本大幅降低 |
| 模型FLOPs利用率 | 3.26% → 27.32% | 8.4倍提升 |
FLOPs利用率解读:
- 传统方法:大量计算浪费在低价值样本
- OneSearch:聚焦高价值计算,效率提升显著
工业部署
部署平台:快手(Kuaishou)
应用场景:
- 商品搜索
- 视频搜索
- 直播间搜索
服务规模:
- 用户数:数百万
- 日均PV:数千万
- 覆盖范围:多个搜索场景
稳定性验证:
- 大规模流量验证
- 长期在线服务稳定
- 业务指标持续增长
挑战与解决方案:
挑战1:商品信息的噪声问题 电商商品标题经常堆砌关键词,如"2024新款韩版修身显瘦连衣裙女夏季…"。OneSearch通过Qwen-VL模型提取核心属性,用AC自动机快速匹配,过滤噪声。
挑战2:冷启动问题 新用户没有行为历史怎么办?他们统计了每个query下点击最多的商品作为默认序列,巧妙解决了这个问题。
挑战3:实时性要求 搜索系统要在100ms内返回结果。他们采用了beam search(beam size=512)的生成策略,在质量和延迟间找到平衡。
核心贡献
1. 范式创新
- 首个工业级端到端生成式电商搜索框架
- 从级联架构向统一生成范式转变
2. 技术突破
- KHQE:解决量化编码中的语义保留难题
- 多视角行为序列:全面建模用户偏好
- PARS:实现细粒度偏好对齐
3. 工业验证
- 大规模线上部署成功
- 业务指标全面提升
- 成本效率显著优化
4. 方法论价值
- 为生成式搜索工业落地提供范式
- FLOPs利用率优化思路可推广
- 端到端优化框架具备通用性
关键洞察
为什么端到端重要?
传统级联架构的局限:
召回阶段:优化目标 = 覆盖率最大化
↓(信息丢失)
粗排阶段:优化目标 = 效率+相关性权衡
↓(优化割裂)
精排阶段:优化目标 = 业务转化最大化
OneSearch端到端优势:
统一框架:全局优化目标 = 最终业务价值
↓
信息无损传递 + 目标一致性
↓
性能上限突破
FLOPs利用率提升的意义
3.26% → 27.32% 不仅是数字变化,更代表:
- 资源聚焦:计算资源投入到真正有价值的样本
- 成本优化:同等算力下服务更多用户
- 扩展性:为更复杂模型留出计算预算
类比:
- 传统方法:撒网捕鱼,大量空捞
- OneSearch:精准投放,弹无虚发
未来展望
技术演进方向
-
更大规模模型
- 当前成果已验证生成式范式可行性
- FLOPs利用率提升为更大模型部署创造条件
-
多模态融合
- 文本+图像联合编码
- 视频内容理解增强
-
实时个性化
- 更细粒度的用户画像
- 动态偏好追踪
对生成式搜索领域的启示
- 工业化路径清晰
- OneSearch证明端到端生成式搜索可规模化部署
- 为其他垂直领域提供参考
- 效率优化是关键
- FLOPs利用率是工业落地的核心指标
- 不能只追求模型效果,必须兼顾成本
- 用户偏好建模是核心
- PARS系统展示了细粒度偏好对齐的价值
- 从"匹配查询"到"理解用户"的范式转变
个人点评
OneSearch代表了搜索系统架构的一次重大变革。从传统的"召回-粗排-精排"级联流程到端到端生成式范式,不仅是技术路线的改变,更是优化思路的革新。
最值得关注的三个点:
- FLOPs利用率8倍提升
- 这是工业落地的关键突破
- 证明生成式方法可以兼顾效果和成本
- 业务指标全面增长
- CTR、转化、订单量三个维度同时提升
- 验证了端到端优化的实际价值
- 大规模部署验证
- 不是实验室demo,而是服务千万级用户的生产系统
- 为生成式搜索工业化树立标杆
对算法研发的启示:
在追求模型效果的同时,必须重视计算效率。OneSearch的成功不仅在于端到端优化带来的效果提升,更在于通过FLOPs利用率优化实现了成本可控的规模化部署。这为后续更大规模模型的落地创造了空间。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)