使用python语言的本地与云端大模型调用的统一接口封装及使用
本文介绍一个 Python 工具类的设计,它用抽象基类统一了本地部署模型(HuggingFace Transformers)与云端 API(OpenAI 兼容接口)的调用方式。你只需要改变一行初始化代码,就能在两种后端之间自由切换,业务逻辑无需任何改动。
该工具类是我在空闲时间利用AI编写出来的,原本被我用于比较本地部署模型以及云端API模型在实际应用中的差距与不同。后来发现即使抛开上述功能,相比起从基础开始使用pytorch包,该工具类也能降低本地部署AI的难度,并且统一接口封装,使得在使用本地部署大模型与云端大模型二者上可以极其灵活,方便日后由云端转变为本地,或者由本地转变为云端。
下面分成“使用指南”和“代码实现详解”两部分进行讲解,并且在初始化部分分为本地以及云端两方面,方便快速上手或深入理解。完整代码将会放在文章末尾。
另外,博主只是个学业平平的河南二本大三学生,写这篇文章,主要是想给自己找点事做,记录并分享一下折腾的结果,在这里献丑了,先说声抱歉,还请大家轻喷。倘若这篇文章能帮到你,那将是我的荣幸。
一、使用指南
1.1 快速开始
首先,根据你的运行环境选择实例化本地模型或云端模型:
# 本地模型(需要提前下载好模型文件)
ai = AiLocal(model_path="./Qwen2.5-7B-Instruct")
# 云端模型(支持所有兼容 OpenAI 接口的服务)
ai = AiOnline(api_key="your-key", base_url="https://api.deepseek.com", model="deepseek-chat")之后,所有调用方式完全一样。
1.1.1 本地模型
本地模型需要提前下载好模型的对应文件,我使用的是魔塔社区下载模型(https://www.modelscope.cn/home)。登录后搜索想要的模型,根据自己电脑的性能选择合适的大模型进行下载,随后点击进入模型详细页面,点击下载按钮,根据给出的提示和指令进行下载即可。
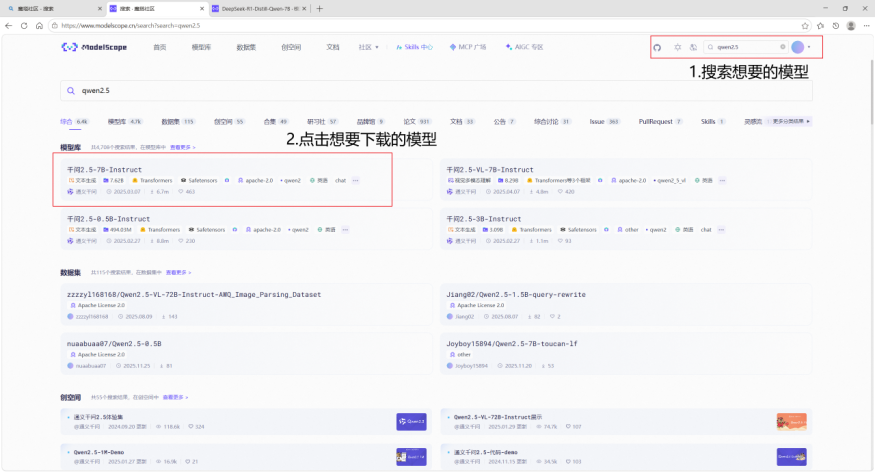
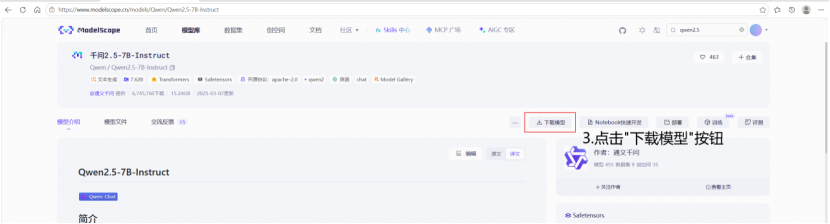
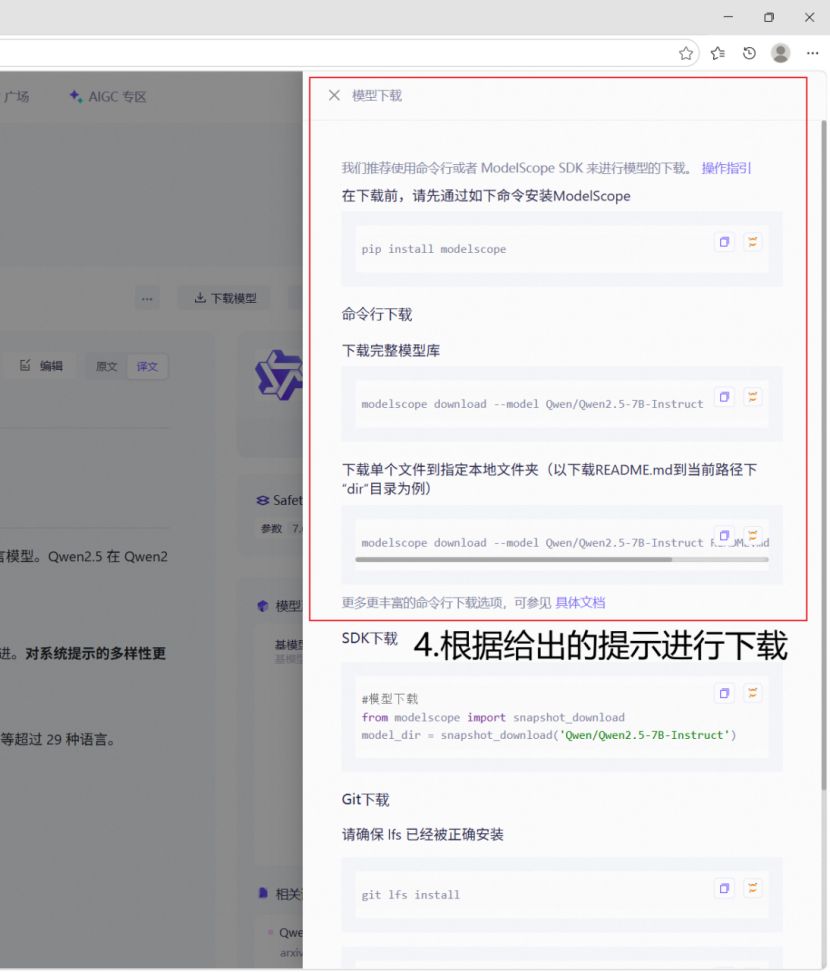
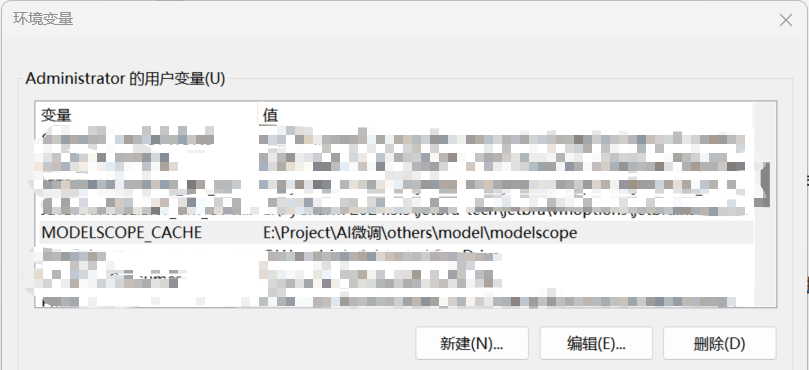
此处建议直接使用命令行进行下载,另外下载前需要注意C盘是否有足够的空间存放整个模型,该命令会使用C盘进行缓存,全部文件下载完毕后才会将模型移动到指定位置。当C盘剩余空间清零时,请删除C:\Users\<个人账户>\.cache\modelscope\hub文件夹以清空下载缓存,并通过设置环境变量,修改modelscope的下载缓存位置至剩余空间较多的磁盘中
在运行程序前还需要先安装对应的依赖包
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import outlines个人建议先安装torch再安装transformers和outlines包,否则可能有依赖性问题。
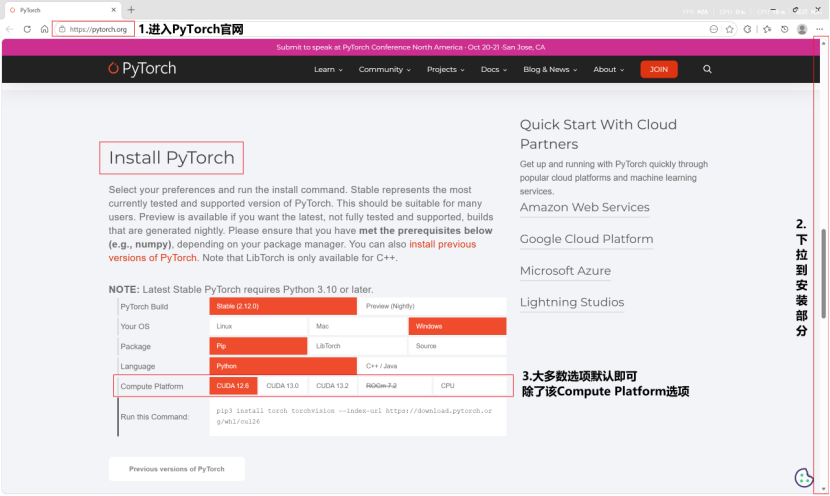
torch包需要进入官网(PyTorch),根据电脑的实际情况选择安装包,最后获取安装指令,在IDE的终端的.venv虚拟环境中执行以安装torch包。此处以在windows系统上配合nvidiaGPU部署本地模型作为案例进行示范。
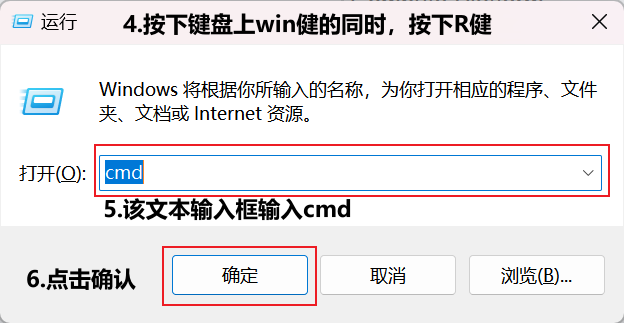
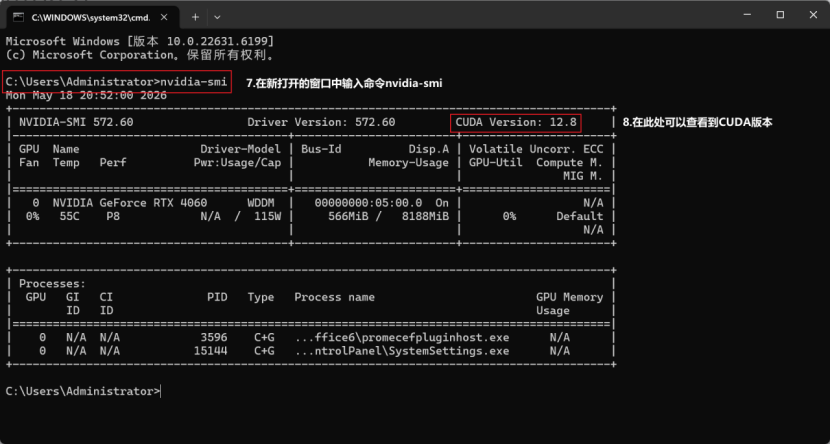
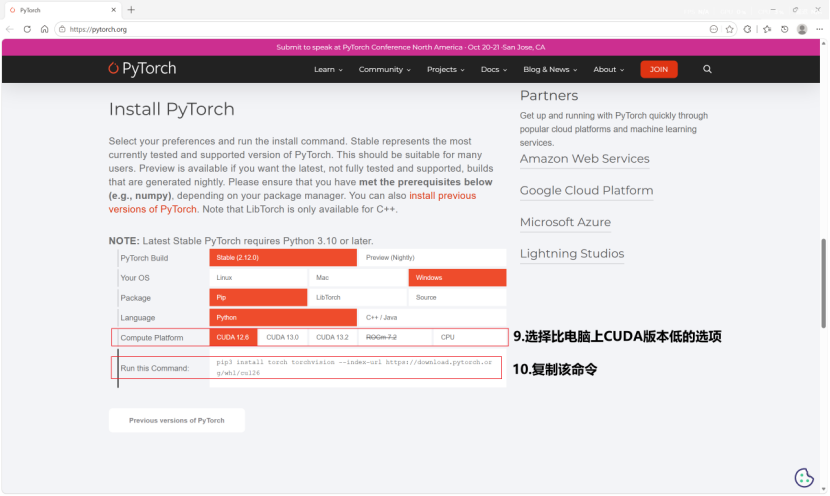
进入pyTorch官网,往下拉直到看到Install PyTorch部分,选择适合自己情况的选项。比较重要的主要是Compute Platform部分,需要选择正确的CUDA版本。CUDA版本可以通过在电脑终端输入命令nvidia-smi进行查看。
选择完毕后,复制下方Run this Command文本框中的命令并执行,即可成功安装torch包

随后,只需要通过代码ai = AiLocal("./Qwen2.5-7B-Instruct")即可最简单地初始化本地部署大模型,其中model_path指向下载的大模型文件夹。
该工具类在初始化时还可以另外设置三个参数:
load_method:模型加载方式,默认”4bit”,可以降低显存占用的同时不会对模型造成太大的影响,可选”8bit”以及完整加载模型的”fp16”
ignore_warnings:是否忽略大部分警告信息,默认为True,用于减少终端输出信息,当本地部署出现问题时,可调整为False查看详细信息
device_map:决定大模型运行的硬件,默认为”auto”,可适应使用多张GPU的场景,可选择为None,此时大模型会在必要的情况下运行在GPU上,或者选择为{“”:”cpu”},此时大模型将会只运行在cpu上,或者选择为{“”:”chda:0”},此时大模型将会只运行在第一张Nvidia的显卡上。当弹出显存不够无法运行的提示时,可修改该选项为None
另外,本地部署大模型由于各种情况,会导致兼容性较差。当遇到报错时,请询问AI报错原因以及解决方法,解决方法超出能力限制或因其它原因始终无法运行程序是正常现象,请耐心应对或果断放弃。
1.1.2 云端模型
云端模型需要获取到供应商的url以及key,通常使用openAI格式的平台此处都能兼容,此处以deepseek平台进行示范。
首先进入deepseek首页,点击下方开放平台按钮,随后进入API keys创建并获取key,随后进入充值页面进行充值。充值完毕后点击接口文档进入文档页面,在该处的”首次调用API”文档中有给出deepseek的url以及可选择的模型,因为该工具类使用的是OpenAI的包,因此此处选择base_url(OpenAI)的url。


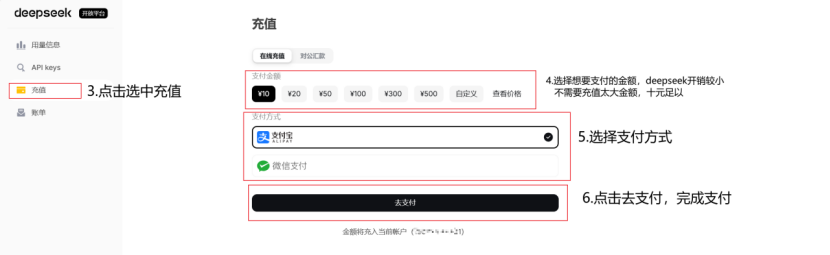
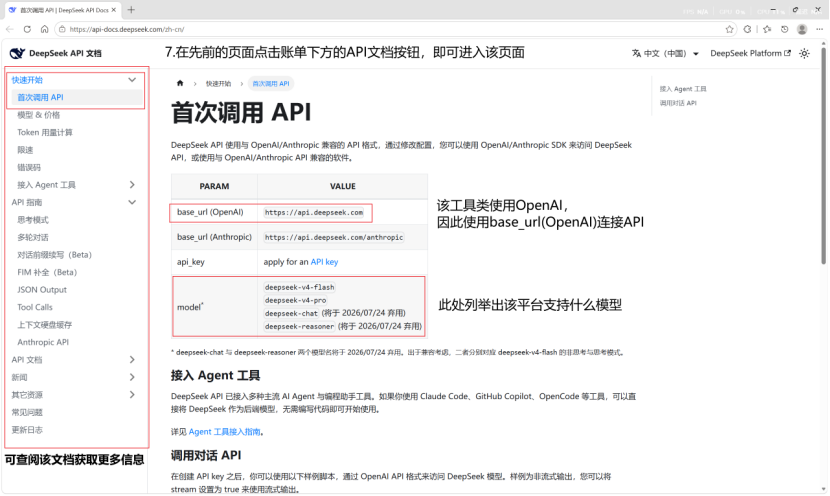
获取到需要的url以及key后,只需要通过代码ai=AiOnline(api_key=”key”,base_url=”https://api.deepseek.com”,model=”deepseek-v4-pro”)即可最简单地初始化本地部署大模型。以上三者都可以通过上述步骤获取到。
该工具类在初始化时还可以另外设置两个参数:
retry_delay:重试次数,当单次请求失败后重试多少次,默认3次
Retry_times:重试间隔时间,当请求失败后间隔多久进行第二次重试,默认1秒
云端模型由于部署在云端的服务器中,因此相对而言兼容性要高许多,成功运行的几率遥遥领先于本地部署大模型。但云端模型依旧会受到网络波动等原因,出现无法连接的情况,而当本地模型运行成功时,其稳定性将领先于云端模型。
另外,也可以通过ollama等工具实现本地部署模型,同时再通过本地网络连接ollama的url,从而既保障能成功本地部署模型,也可以避免因网络波动导致的无法连接模型。
1.2 对话方法generate()
该工具类通过接口统一简化了对话的方法,即为ai.generate()方法,该方法可以同时支持基本对话,多轮记忆对话以及返回json格式结果。虽然本地模型的generate()方法与云端模型的generate()方法代码完全不同,且对各传参设置的支持度不同,但还是能基本确保切换时程序依旧能正常工作
1.2.1 基本对话
最简单的使用方式,传入要求,返回结果,就像一个普通的函数一样。
answer = ai.generate("用一句话介绍人工智能", "你是一个简洁的助手")
print(answer)user_message:必填,用户问题。
system_prompt:必填,系统提示词。
1.2.2 多轮记忆对话
通过传入一个列表 memory 来维护对话历史:
memory = []
system_prompt="你是一个智能记事本,可以记住用户提出的信息,并在需要回答的时候回答"
answer, memory = ai.generate("记一下,我下午四点钟要开始做饭",system_prompt=system_prompt, memory=memory)
answer, memory = ai.generate("我下午几点开始做饭?", memory=memory)#输出"您下午四点钟开始做饭。"
print(answer)当传入 memory 时,返回值是一个元组 (answer, memory),方便继续传递。而当memory为None时,即默认情况,方法将会回到基本对话。
但是当 memory 为 None或空集且未提供 system_prompt 时,将会抛出异常,当memory不为None或空集时,system_prompt将会被忽略。换而言之,第一次输入必须传入system_prompt,除非memory中已经添加了对应的记忆
memory = [{"role": "system", "content": "你是一个智能记事本,可以记住用户提出的信息,并在需要回答的时候回答"}]
#此时不必强制第一遍输入system_prompt
answer, memory = ai.generate("记一下,我下午四点钟要开始做饭",memory=memory)
answer, memory = ai.generate("我下午几点开始做饭?", memory=memory)#输出"您下午四点钟开始做饭。"
print(answer)可以通过以下代码实现类似对话助手的功能
memory = [{"role": "system", "content": "你是一个智能记事本,可以记住用户提出的信息,并在需要回答的时候回答"}]
while True:
answer, memory = ai.generate(input(), memory=memory)
print(answer)
1.2.3 返回json格式结果
只需传入一个 JSON Schema 字典,模型就会尽量返回符合格式的 JSON 字符串(本地模型通过约束生成保证格式,云端模型通过提示词引导)。该模式能兼容上述的多轮记忆对话以及基本对话。
schema = {
"type": "object",
"properties":
{
"name": {"type": "string"},
"age": {"type": "integer"}
},
"required": ["name", "age"]
}
result = ai.generate("随机生成一个人物信息", system_prompt="你是一个数据生成器", json_schema=schema)1.2.4 其它参数设置
generate 方法支持以下参数,可按需调整:
max_new_tokens:最大输出长度,默认 512。
temperature:温度,控制随机性,默认 0.7。
top_p:核采样阈值,默认 0.9。
thinking:是否开启思考模式(需模型支持),默认 False。该参数是针对deepseek云端大模型以及qwen本地大模型进行编写的,暂时没测试过其它大模型是否支持
model:云端模型名,若不传则使用初始化时的默认模型。由于本地模型在初始化时就已经加载好模型,因此无法中途更换模型,所以在使用本地模型运行该方法时会忽略该参数并发出警告,但是程序依旧可以运行。(可能后续会更新,通过输入本地模型的路径实现加载新的模型)
1.3 切换后端的完整示例
USE_LOCAL = True
if USE_LOCAL:
ai = AiLocal(model_path="./Qwen2.5-7B-Instruct", load_method="4bit")
else:
ai = AiOnline(api_key="sk-xxx", base_url="https://api.example.com", model="your-model")
# 以下业务代码完全不用改
system = "你是一个有用的助手"
response = ai.generate("今天天气如何?", system_prompt=system)
print(response)
二、代码实现详解
2.1 整体架构
设计遵循“面向接口编程”的思想:
抽象基类 AI 定义了统一的 generate 方法签名,所有子类必须实现。
AiLocal 和 AiOnline 分别基于 HuggingFace 和 OpenAI 接口实现该方法。
业务代码只依赖 AI 接口,具体使用哪一个子类,在初始化时决定。
class AI(ABC):
"""
所有AI类的父类
"""
def __init__(self):
pass
@abstractmethod
def generate(
self,
user_message:str,
system_prompt:str=None,
model:str=None,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
thinking:bool=False,
memory=None,
json_schema=None,
)->str:
"""
用于连接AI输出内容
:param user_message: 用户提示词
:param system_prompt: 系统提示词,与memory中必须有一者不为None
:param model: 模型,不输入则为默认模型
:param max_new_tokens: 最大token
:param temperature: 温度,越高输出内容变化越大
:param top_p: 大致同上
:param thinking: 是否思考模式,默认不开启
:param memory: 先前的对话记忆,与system_prompt中必须有一者不为None
:param json_schema: 是否返回JSON格式内容,如果默认无输入则不返回
:return: 当memory默认时,函数依旧返回单个字符串变量。而当memory返回值时,函数将返回(str,memory(new))
"""
pass2.2 本地模型类 AiLocal
初始化
def __init__(self,
model_path: str,
load_method: str = "4bit",
ignore_warnings: bool = True,
device_map:str|dict|None="auto"
):使用 AutoTokenizer 和 AutoModelForCausalLM 加载模型。
支持三种加载方式:
"4bit":使用 BitsAndBytesConfig 进行 4-bit 量化,显存占用最低。
"8bit":8-bit 量化。
"fp16":半精度浮点,不量化,需要更多显存。
ignore_warnings 会屏蔽 bitsandbytes、Triton 等库的无关警告。
device_map 控制模型部署设备,遵循 transformers 规则。
generate 方法内部流程
消息构建:若未传 memory,用 system_prompt 生成 [{"role": "system", "content": ...}];否则直接使用传入的 memory 列表。然后将 user_message 追加为 {"role": "user", "content": ...}。
JSON 模式处理:如果提供了 json_schema,会在用户消息末尾追加格式要求,并初始化 outlines 模型与 logits processor。
模板应用:调用 tokenizer.apply_chat_template,根据是否 thinking=True 传递 enable_thinking 参数,将消息列表转换为模型训练时使用的 prompt 字符串。
生成:将 prompt 编码后送入 model.generate。若为 JSON 模式,传入 logits_processor 列表以确保输出符合 JSON Schema。
解码与返回:切片去掉输入部分,解码得到纯输出。若为 JSON 模式,直接用 json.loads 解析(由于 logits processor 的作用,输出一定是合法 JSON)。最后根据 memory 是否为 None,决定返回单字符串还是 (answer, memory) 元组。
依赖库
torch
transformers
outlines
2.3 云端模型类 AiOnline
初始化
def __init__(self,
api_key,
base_url,
model,
retry_delay=3,
retry_times=1):基于 openai.OpenAI 客户端,可连接任何兼容 OpenAI 接口的服务。
retry_times 和 retry_delay 控制失败重试:当返回内容为空或发生异常时,等待 retry_delay 秒后重试,最多重试 retry_times 次,全部失败则抛出 RuntimeError。
generate 方法内部流程
模型选择:若不传 model,使用初始化时的默认模型。
消息构建:同本地模型,先处理 memory 和 system_prompt,再追加用户消息。
JSON 模式处理:在用户消息末尾拼接 JSON 格式要求(“请务必按照格式输出json格式的结果,格式要求如下:...”),依赖模型自身遵循指令。
思考模式:将 thinking 参数转换为 extra_body={"thinking": {"type": "enabled"/"disabled"}}。
API 调用与重试:调用 client.chat.completions.create,若成功且内容非空,返回结果;否则进入重试逻辑。
结果处理:若为 JSON 模式,用 json.loads 解析返回字符串(若解析失败会抛出异常,触发重试)。最后根据 memory 决定返回形式。
2.4 JSON Schema 实现的区别
本地模型:利用 outlines 库在生成时直接约束 token 概率,保证输出必定是合法 JSON。精确但消耗一些计算资源。
云端模型:通过提示词引导模型输出 JSON,然后解析。该方法依赖模型能力,不保证 100% 成功,但实现简单,无需额外库。
三、AI包整体代码
from abc import ABC, abstractmethod
import time
import json
class AI(ABC):
"""
所有AI类的父类
"""
def __init__(self):
pass
@abstractmethod
def generate(
self,
user_message:str,
system_prompt:str=None,
model:str=None,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
thinking:bool=False,
memory=None,
json_schema=None,
)->str:
"""
用于连接AI输出内容
:param user_message: 用户提示词
:param system_prompt: 系统提示词,与memory中必须有一者不为None
:param model: 模型,不输入则为默认模型
:param max_new_tokens: 最大token
:param temperature: 温度,越高输出内容变化越大
:param top_p: 大致同上
:param thinking: 是否思考模式,默认不开启
:param memory: 先前的对话记忆,与system_prompt中必须有一者不为None
:param json_schema: 是否返回JSON格式内容,如果默认无输入则不返回
:return: 当memory默认时,函数依旧返回单个字符串变量。而当memory返回值时,函数将返回(str,memory(new))
"""
pass
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import outlines
import warnings
import logging
import os
class AiLocal(AI):
def __init__(self,
model_path: str,
load_method: str = "4bit",
ignore_warnings: bool = True,
device_map:str|dict|None="auto"
):
"""
初始化云端AI
:param model_path: 模型的本地路径
:param load_method: 加载方式,根据自己电脑的性能来决定,默认性能要求最低
:param ignore_warnings: 是否忽略警告信息
:param device_map: 设定AI要在何处运行,"auto":自动分配资源,
None:在cpu上运行,当需要的时候才在GPU上运行,
{"":"cpu"}:完全只在CPU上运行,
{"":"cuda:0"}:运行在第一块NvidiaGPU上,在显存足够的情况下使用
...
"""
if ignore_warnings:
# 1. 忽略 bitsandbytes 的 FutureWarning
warnings.filterwarnings("ignore", category=FutureWarning, module="bitsandbytes")
# 2. 抑制 Triton 未安装的警告(UserWarning)
warnings.filterwarnings("ignore", message=".*triton.*", category=UserWarning)
# 3. 提高 TorchDynamo 的日志级别,屏蔽长篇 WON'T CONVERT 信息
logging.getLogger("torch._dynamo").setLevel(logging.ERROR)
# (可选)如果仍有残留警告,可设置环境变量
os.environ["TORCHDYNAMO_VERBOSE"] = "0"
super().__init__()
self.model_path = model_path
self.load_method = load_method
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
quantization_config = None
dtype = torch.float16
if load_method == "4bit":
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
elif load_method == "8bit":
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
elif load_method == "fp16":
pass
else:
raise ValueError("load_method 必须为 '4bit', '8bit' 或 'fp16'")
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quantization_config,
device_map=device_map,
trust_remote_code=True,
dtype=dtype,
)
def generate(
self,
user_message:str,
system_prompt:str=None,
model:str=None,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
thinking: bool=False,
memory = None,
json_schema = None
):
"""
用于连接AI输出内容
:param user_message: 用户提示词
:param system_prompt: 系统提示词,与memory中必须有一者不为None
:param model: 模型,此处不能输入,输入就警告
:param max_new_tokens: 最大token
:param temperature: 温度,越高输出内容变化越大
:param top_p: 大致同上
:param thinking: 是否思考模式,默认不开启
:param memory: 先前的对话记忆,与system_prompt中必须有一者不为None
:param json_schema: 是否返回JSON格式内容,如果默认无输入则不返回
:return: 当memory默认时,函数依旧返回单个字符串变量。而当memory返回值时,函数将返回(str,memory(new))
"""
if model is not None:
warnings.warn("正在使用本地部署模型,无法单独变更模型", category=ResourceWarning)
if memory is None and system_prompt is None:
raise ValueError("请确保system_prompt参数和memory参数起码传入一者")
if not memory or memory is None:
if system_prompt is None:
raise ValueError("请确保在memory为空集的前提下,system_prompt参数不为None")
messages = [{"role": "system", "content": system_prompt}]
else:
messages = memory
if json_schema is not None:
user_message = user_message + "请务必按照格式输出json格式的结果,格式要求如下:" + json.dumps(json_schema)
outlines_model = outlines.Transformers(self.model, self.tokenizer)
json_processor = outlines.generator.get_json_schema_logits_processor(None, outlines_model, json.dumps(json_schema))
messages.append({"role": "user", "content": user_message})
if thinking:
prompt=self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True,
)
else:
prompt = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
with torch.no_grad():
if json_schema is not None:
# noinspection PyUnboundLocalVariable
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=0.9,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
logits_processor=[json_processor],
)
else:
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
)
answer = self.tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
if json_schema is not None:
answer=answer.loads(answer)
if memory is not None:
memory.append({"role": "assistant", "content": answer})
return answer, memory
else:
return answer
from openai import OpenAI
class AiOnline(AI):
def __init__(self, api_key, base_url, model, retry_delay=3, retry_times=1):
"""
初始化云端AI
:param api_key: 大语言模型平台的接口密钥
:param base_url: 大语言模型的url地址
:param model: 选择使用的模型,根据不同的大语言模型平台输入不同的模型名称
:param retry_delay: 单条请求失败后的重试次数,默认值为3次
:param retry_times: 请求失败后的等待间隔,默认为1秒
"""
super().__init__()
self.api_key = api_key
self.base_url = base_url
self.model = model
self.retry_delay = retry_delay
self.retry_times = retry_times
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url) # 初始化客户端
# noinspection PyTypeChecker
def generate(
self,
user_message:str,
system_prompt:str=None,
model:str=None,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
thinking: bool=False,
memory = None,
json_schema = None
):
"""
用于连接AI输出内容
:param user_message: 用户提示词
:param system_prompt: 系统提示词,与memory中必须有一者不为None
:param model: 模型,不输入则为默认模型
:param max_new_tokens: 最大token
:param temperature: 温度,越高输出内容变化越大
:param top_p: 大致同上
:param thinking: 是否思考模式,默认不开启
:param memory: 先前的对话记忆,与system_prompt中必须有一者不为None
:param json_schema: 是否返回JSON格式内容,如果默认无输入则不返回
:return: 当memory默认时,函数依旧返回单个字符串变量。而当memory返回值时,函数将返回(str,memory(new))
"""
if model is None:
model = self.model
if memory is None and system_prompt is None:
raise ValueError("请确保system_prompt参数和memory参数起码传入一者")
if not memory or memory is None:
if system_prompt is None:
raise ValueError("请确保在memory为空集的前提下,system_prompt参数不为None")
messages = [{"role": "system", "content": system_prompt}]
else:
messages = memory
if json_schema is not None:
user_message = user_message + "请务必按照格式输出json格式的结果,格式要求如下:" + json.dumps(json_schema)
messages.append({"role": "user", "content": user_message})
if thinking:
thinking="enabled"
else:
thinking="disabled"
for attempt in range(self.retry_times+2):
try:
response = self.client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
extra_body={"thinking": {"type": thinking}}
# 如有特殊需求可在此添加其他参数(如 response_format)
)
if response.choices and response.choices[0].message.content is not None:
answer = response.choices[0].message.content.strip()
if json_schema is not None:
answer=json.loads(answer)
if memory is None:
return answer
else:
memory.append({"role": "assistant", "content": answer})
return answer,memory
else:
# 空内容视为生成失败,触发重试
raise ValueError("API 返回了空的响应内容")
except Exception as e:
last_exception = e
if attempt <= self.retry_times: # 非最后一次尝试时等待后重试
time.sleep(self.retry_delay)
else:
# 所有重试均失败,抛出异常
raise RuntimeError(
f"API 请求失败,已重试 {self.retry_times} 次。最后错误: {last_exception}"
) from last_exception
raise RuntimeError("超出重试次数")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)