RAG 2026 进化指南:从 Naive RAG 到 Agentic RAG,检索增强生成的四个阶段
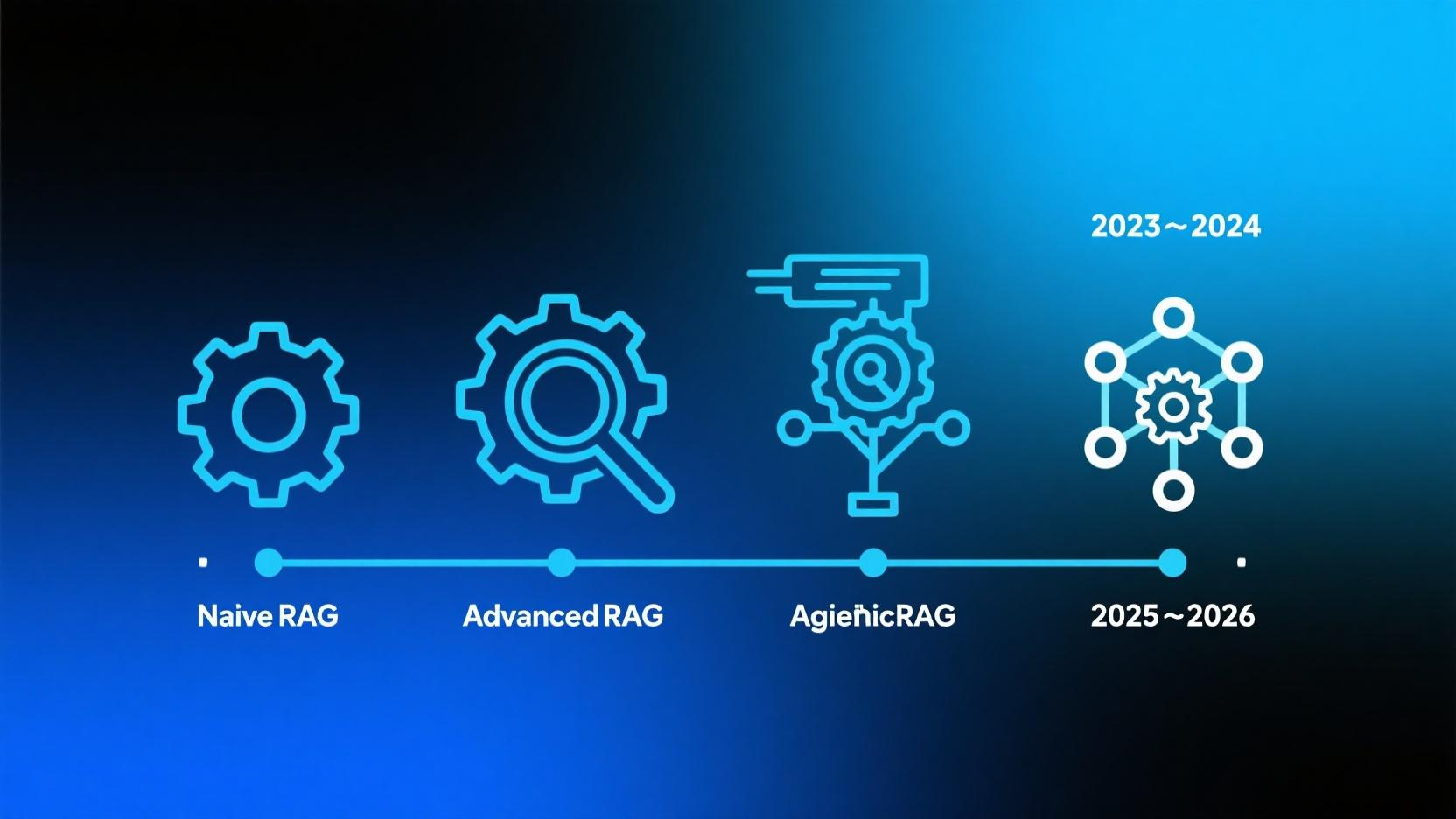
RAG 四年进化:从"搜索+拼接"到"自主决策"
RAG(Retrieval-Augmented Generation)从 2023 年走红至今,已经迭代了四个版本。2023 年大家还在为"怎么切文档"吵架,2026 年我们已经在讨论"怎么让 Agent 自己决定什么时候检索、检索什么、检索完要不要重搜"。
这四个阶段的差异,本质上是 控制权从开发者向模型转移 的过程。
| 阶段 | 检索决策者 | 检索次数 | 代表框架 | 适用场景 |
|---|---|---|---|---|
| Naive RAG | 开发者 | 固定1次 | LangChain Basic | 简单FAQ |
| Advanced RAG | 开发者 | 1次(优化后) | LlamaIndex | 企业知识库 |
| Agentic RAG | Agent | 动态多次 | LangGraph + RAG | 复杂分析任务 |
| GraphRAG | 图+Agent | 多次多跳 | Neo4j + GraphRAG | 关系密集领域 |
第一阶段:Naive RAG(能用,但问题一堆)
2023 年的标准范式:文档切块 → 向量化 → 用户提问 → 检索 top_k → 拼到 prompt → LLM 回答。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
# 经典 Naive RAG
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(), retriever=retriever)
answer = qa.run("公司的年假政策是什么?")
三个经典问题(2026 年仍然有人中招): - Chunking 太随意:每 500 字一刀切,重要信息被切断在 chunk 边界 - 检索噪声:用户问"退货流程",top_k=5 里有 3 条是"发货流程",LLM 被带偏 - 盲信检索结果:用户问了一个知识库没有的问题,RAG 用"最相似但不相关"的内容强行回答
第二阶段:Advanced RAG(检索质量工程化)
2024-2025 年的改进聚焦在"怎么搜得更准":
① 语义分块(Semantic Chunking):不再按字符数,而是用 embedding 相似度判断断点。当相邻句子的语义距离突然变大时切分。
# LlamaIndex 的 SemanticSplitter
from llama_index.core.node_parser import SemanticSplitterNodeParser
splitter = SemanticSplitterNodeParser(
buffer_size=1, breakpoint_percentile_threshold=95,
embed_model=OpenAIEmbedding()
)
nodes = splitter.get_nodes_from_documents(documents)
② HyDE(假设文档嵌入):让 LLM 先生成一个"理想答案",再用这个答案的向量去检索。原理是:答案和文档的语义空间更接近,比问题和文档更匹配。
# HyDE 策略
hypothetical_answer = llm.generate(f"请用一段话回答:{user_query}")
hyde_embedding = embed_model.embed(hypothetical_answer)
results = vectorstore.similarity_search_by_vector(hyde_embedding, k=10)
③ 重排序(Re-ranking):粗召回(top_k=20)+ 精排(Cohere/BGE Reranker → top_k=5),检索质量提升 30%-50%。
from llama_index.core.postprocessor import SentenceTransformerRerank
reranker = SentenceTransformerRerank(model="BAAI/bge-reranker-v2-m3", top_n=5)
nodes = reranker.postprocess_nodes(retrieved_nodes, query_str=query)
第三阶段:Agentic RAG(Agent 决定何时搜、搜几次)
这是 2026 年最重要的 RAG 范式。Agent 不再被动接收检索结果,而是自主决策:
- "这个问题需要检索吗?"(判断知识库是否覆盖)
- "检索结果够不够?要不要换个关键词再搜?"
- "搜到的是矛盾信息,我要不要合并分析?"
Self-RAG 核心逻辑:
from typing import Literal
def self_rag_loop(query: str, max_iterations: int = 3):
context = []
for i in range(max_iterations):
# Agent 决定下一步动作
action = llm.choose_action(query, context)
# action: "search" | "generate" | "refine"
if action == "search":
new_query = llm.generate_search_query(query, context)
results = vectorstore.search(new_query, k=5)
context.append({"source": "search", "content": results})
elif action == "refine":
# 发现之前的检索不够好,重新搜索
refined_query = llm.refine_query(query, context)
results = vectorstore.search(refined_query, k=5)
context.append({"source": "refined_search", "content": results})
elif action == "generate":
return llm.generate(query, context)
return llm.generate(query, context) # 兜底
LangGraph 实现 Agentic RAG:
from langgraph.graph import StateGraph, END
class RAGState(TypedDict):
query: str
search_queries: list[str]
retrieved_docs: list
iterations: int
answer: str
def should_continue(state: RAGState) -> Literal["search", "generate"]:
if state["iterations"] >= 3:
return "generate"
if len(state["retrieved_docs"]) < 3:
return "search"
return "generate"
workflow = StateGraph(RAGState)
workflow.add_node("search", search_node)
workflow.add_node("generate", generate_node)
workflow.add_conditional_edges("search", should_continue)
workflow.add_edge("generate", END)
workflow.set_entry_point("search")
第四阶段:GraphRAG(从向量到关系)
向量检索的盲区:它能找到"相似"的内容,但理解不了实体之间的关系。
比如问"张三分管的产品线有哪些?",向量检索能搜到包含"张三"和"产品线"的文档,但无法回答跨文档的"张三 → 负责 → 产品A、产品B、产品C"这种关系推理。
GraphRAG 解决的就是这个。它把知识组织成图: - 节点:实体(人、产品、部门、概念) - 边:关系(负责、隶属于、依赖、包含) - 社区检测:自动发现知识群落
# 使用 Microsoft GraphRAG
from graphrag.index import run_pipeline
from graphrag.query import global_search, local_search
# 索引阶段:构建知识图谱
run_pipeline(config={"input": "docs/", "output": "output/"})
# Local Search:围绕问题相关实体展开图搜索
result = local_search(
query="张三分管的产品线",
communities=load_communities(),
entities=load_entities(),
relationships=load_relationships()
)
什么时候上 GraphRAG: - 知识实体密集,关系复杂(法务、医疗、金融) - 需要跨文档推理("这个供应商同时出现在哪几个合同里?") - 需要全局洞察("公司的技术栈演进趋势是什么?")
否则 Advanced RAG 就够了。GraphRAG 的索引成本是普通 RAG 的 5-10 倍。
选型决策树
你的数据是什么样的?
├── 短文本FAQ(<500条) → Naive RAG + Chroma,一天上线
├── 长文档知识库(>1000页)
│ ├── 关系简单 → Advanced RAG(Semantic Chunking + HyDE + Reranker)
│ └── 关系复杂 → GraphRAG
├── 需要多步推理/动态检索 → Agentic RAG(Self-RAG + LangGraph)
└── 以上所有 → 混合架构:Advanced RAG 作基座 + Agentic 作调度层
小结
RAG 的进化路线很清晰:检索质量 → 检索决策 → 知识结构化。2026 年,如果你的 RAG 系统还停留在"用户问 → 向量搜 → LLM 答"的单线模式,是时候升级了。
对于大多数团队,我建议的路线是:先把 Naive RAG 优化到 Advanced RAG(投入产出比最高),再在关键场景试点 Agentic RAG。
下一篇预告:GraphRAG 企业落地实战——从 Neo4j 建图到生产环境性能调优。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)