2026年AI智能体开发指南:10张图讲透核心概念
构建AI智能体远不止于挑选合适的LLM或设计精妙的提示词,关键在于掌握那些能让智能体在真实业务中自主、可靠运转的底层系统。一个能让团队眼前一亮的演示,与一个每周能切实节省10小时工时的生产级智能体,其分水岭正是这十个核心概念。它们才是打造AI系统时真正该聚焦的重点,接下来我们正式进入正题。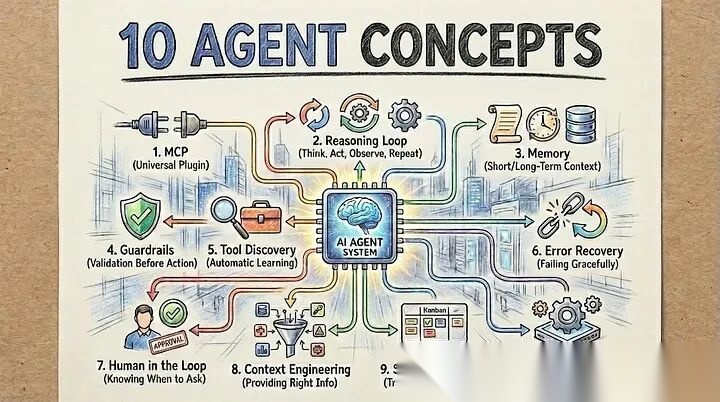
- MCP:通用插件系统
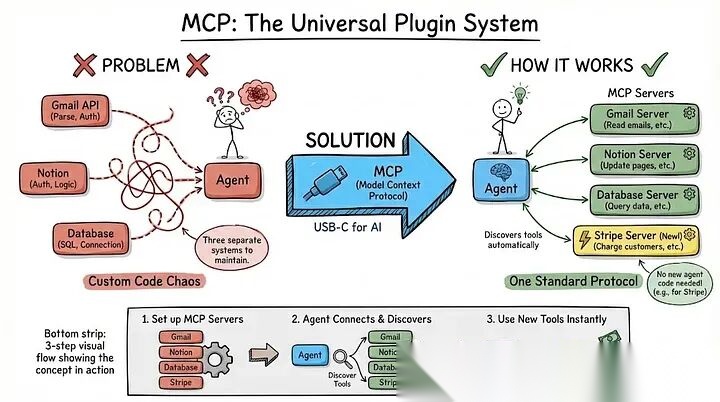
你希望智能体能读取Gmail、更新Notion并查询数据库。传统做法是为每个服务单独开发集成:解析Gmail API、处理Notion OAuth、编写SQL连接逻辑——三个系统意味着三套独立代码库,维护成本成倍增加。
MCP(Model Context Protocol,模型上下文协议)通过为智能体提供统一的工具通信标准,从根本上解决了这一痛点。它就像"AI界的USB-C":你无需为每个手机应用配备专属充电器,智能体也无需为每个服务编写定制集成。
具体流程是:你部署MCP服务器,每个服务器会以结构化描述暴露其工具的功能与输入要求;智能体连接后即可自动发现并调用这些工具。下周想接入Stripe支付?只需启动一个Stripe MCP服务器,智能体立刻具备收费能力,全程无需修改任何核心代码。
举个例子:一个MCP服务器暴露了send_email函数,并描述为"向指定地址发送带主题和正文的邮件"。当用户说"把报告发给john@company.com"时,智能体能自动匹配参数并调用该函数。明天你再添加一个search_github服务器,智能体会即时发现并启用它——零代码改动,能力自然扩展。
- 推理循环:思考、行动、观察、重复
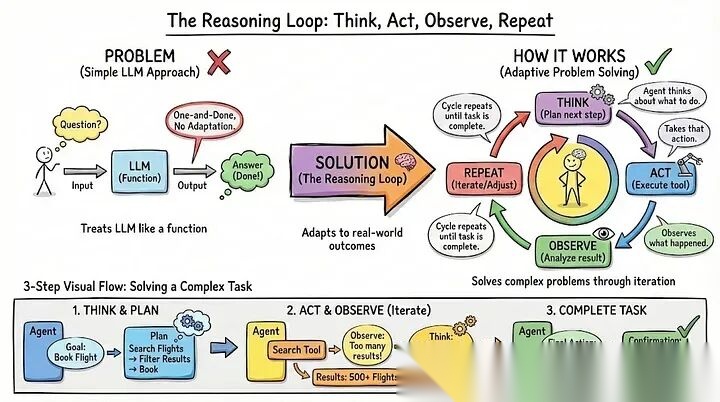
很多小伙伴用LLM时,习惯把它当成一个简单函数:问个问题,得个答案,完事。但现实里的任务哪有这么简单?它们需要根据实际情况随时调整策略。
智能体真正厉害的地方,在于它的推理循环:先想想该干啥→动手去做→看看结果咋样→再想想这招行不行、下一步该咋办。这个"想-做-看-再想"的循环一直转,直到把事儿搞定。
举个栗子🌰:你让智能体去查对手的定价。它心想:“先去官网瞅瞅。” 结果一访问,404了。它马上意识到:“哦,页面没了。” 接着调整策略:“那试试从主页找起。” 于是访问主页、定位定价入口、点进去、抓数据。每一步都踩着上一步的结果往前走——第一种方法不行就换第二种,而不是直接摆烂报错。
- 记忆:短期和长期上下文
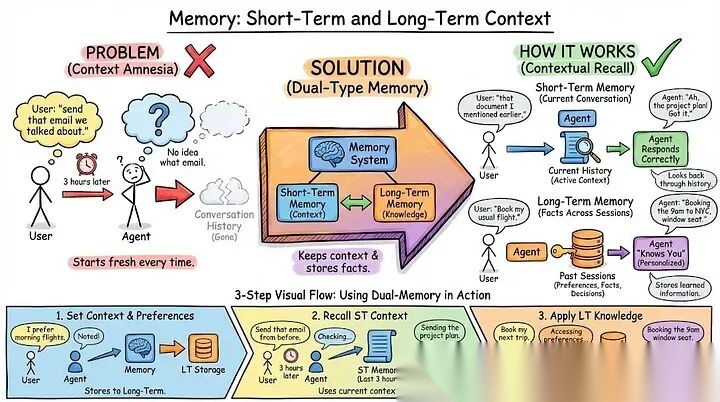
你的智能体与用户进行了对话。三小时后,用户说"发送我们之前讨论的那封电子邮件"。智能体不知道是哪封电子邮件。对话历史已经消失。
- • 短期记忆保持当前对话的上下文。当你说"我之前提到的那份文件"时,智能体可以回顾对话历史并找到你指的是哪份文件。
- • 长期记忆存储跨会话的事实。用户偏好、过去的决策、学习到的信息。这让你的智能体感觉它真的认识你,而不是每次都重新开始。
举个栗子🌰: 用户说:"我更喜欢上午10点之前的早晨会议。"你将此存储在与其用户ID关联的长期记忆中。下周,他们问:"安排与Sarah的会议。"你的智能体检查记忆,看到早晨偏好,并建议上午9点的时间段,而不是下午时间。没有记忆,它会建议随机时间,用户每次都必须重复他们的偏好。
- 护栏:行动前的验证
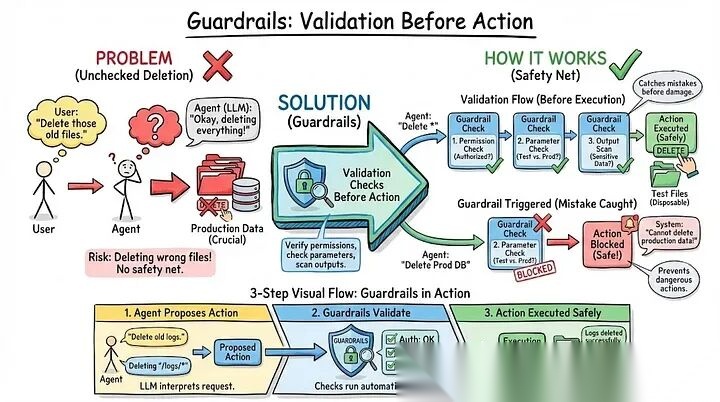
想象一下:你的智能体准备删文件,LLM拍着胸脯说"用户就是要这个"。但万一它搞错了呢?万一它马上要删的是生产库,而不是测试文件呢?
这时候就该护栏(Guardrails) 上场了。它们就像操作前的"安检员":先看看你有没有权限、参数合不合理、输出里有没有敏感信息——总之,在造成损失前把错误拦下来。
举个栗子🌰:用户说"清理下旧的测试数据",智能体一听,唰一下准备删50,000条数据库记录。但护栏先按了暂停键:
• “等等,这位用户真有权限删这么多吗?”
• “50,000条真的只是’旧测试数据’?”
系统觉得不对劲,马上弹窗让用户确认。结果一问,用户说的是50条,不是50,000条——好家伙,护栏这一拦,直接避免了一场数据灾难。
- 工具发现:自动学习新能力
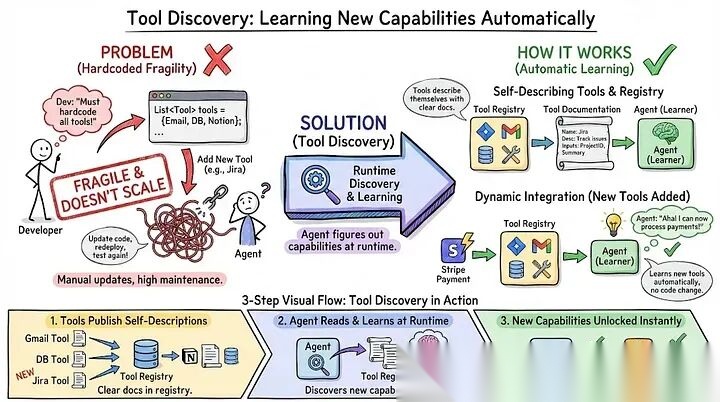
如果你把工具列表直接写死在代码里,后期维护绝对是个噩梦。比如下个月想接Jira,你就得改代码、重新发版、再把所有流程测一遍。这种方式不仅脆弱,根本没法规模化。
工具发现 就是来解决这个问题的:让智能体在运行时自己“摸清”能干什么。每个工具都自带清晰的说明书,智能体读一遍就能自动学会怎么用,加新工具完全不用动核心代码。
举个栗子🌰:你的智能体已经在线上跑着了。这时候想加日历功能?简单,直接起一个提供 create_event 和 list_events 的MCP服务器,把功能描述写好就行。下次用户说“安排个团队会议”,智能体自己会在工具列表里刷到日历功能,看懂说明,直接调用。你一行代码都不用改,它自己就把新技能点满了。
- 错误恢复:优雅地失败
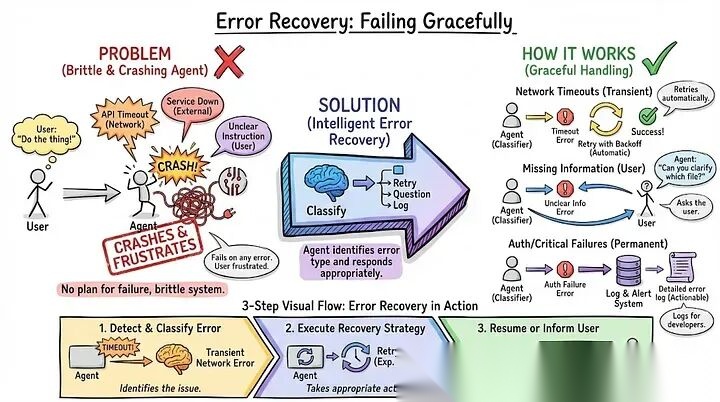
API超时、服务器宕机、用户指令模棱两可……做智能体,出错是常态。真正的考验是:它是一碰就碎直接报错崩溃,还是能自己把坑填上?
这就叫错误恢复。简单说就是:先搞清楚出了啥问题,再对症下药。网络卡了就自动重试,缺信息了就回头问用户,权限不对了就记日志并给个明白话。
举个栗子🌰:智能体发邮件,SMTP服务器没响应。它不慌,等2秒重试;还不行?等4秒再试。第三次搞定了,用户根本不知道后台经历了什么。要是网络一直抽风呢?试了三次全挂,它会马上跟用户交底:“邮件服务现在宕机了,您的草稿我已存好,10分钟后我会自动再试一次。” 把情况和下一步安排说得明明白白,用户自然安心。
- 人在回路中:知道何时询问
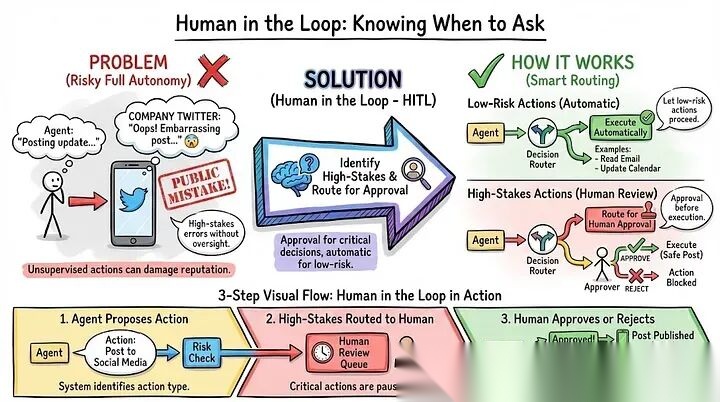
完全的自主性听起来很理想,直到智能体在公司官方账号上发布了引发公关危机的内容。某些关键决策,必须在执行前引入人工判断。
人在回路中(Human-in-the-Loop) 并非意味着对每一步操作进行微观管理,而是建立一套基于风险的决策路由机制:低风险任务自动执行,高风险操作则自动路由至人工审核批准。
示例:以社交媒体智能体为例,日常资讯更新可由其自动起草并发布,运行顺畅。但当它起草针对“产品缺陷客诉”的公关回复时,系统会主动暂停并推送审批通知:“已生成回复草稿,是否确认发布?”你审阅并进行微调后点击批准,智能体随即发布。高风险内容经过审查,低风险任务保持自动化。你始终掌握核心控制权,却无需逐条盯防每一项操作。
- 上下文工程:提供正确的信息
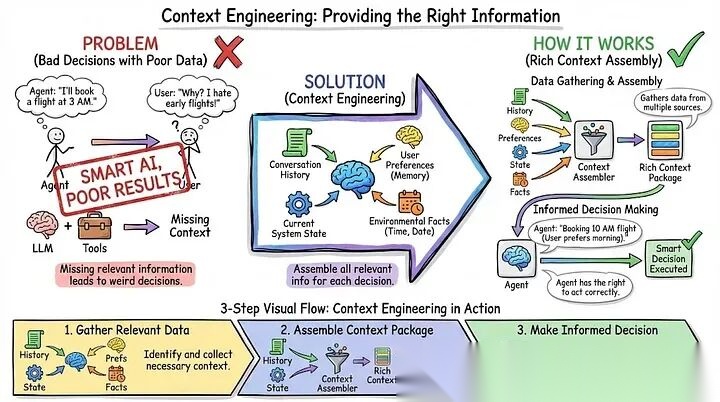
你有没有遇到过这种情况:LLM够强、工具也齐,但智能体就是会做出一些"让人摸不着头脑"的决定?问题往往不在脑子,而在"信息粮草"没跟上。
这就叫上下文工程——简单说,就是帮智能体在每次做决定前,把该看的资料都摆到桌面上:不光聊过啥,还要知道用户平时喜欢啥、现在系统啥状态、今天周几、外面下不下雨……
举个栗子🌰:用户问"明天户外会议要不要改?"
• 要是智能体只看到这一句话,它只能瞎蒙;
• 但如果它知道:明天70%概率下雨🌧️、日历上写着是户外团建、用户以前一到雨天就提前改期、公司B会议室正好空着……
那它就能靠谱地建议:“建议改到B会议室,下雨风险高,而且您之前也倾向于提前规避。” 你看,信息给够了,决策自然就稳了。
- 状态管理:跟踪复杂任务
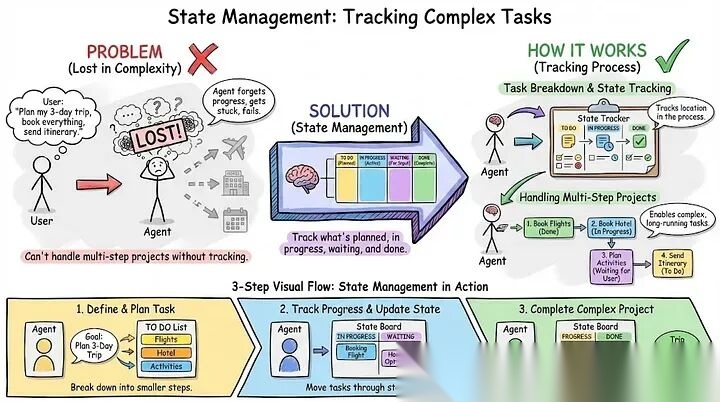
用户不仅仅是问简单的问题。他们要求需要数小时或数天的多步骤项目。你的智能体需要跟踪它在这个过程中的位置。
状态管理是关于跟踪什么已计划、什么正在进行、什么在等待输入以及什么已完成。没有它,你的智能体无法处理比一次性查询更复杂的事情。
示例: 用户说:"研究我们前5个竞争对手并创建比较电子表格。"你的智能体将其分解为子任务。首先:识别竞争对手(进行中)。其次:研究每一个(已计划,等待步骤1)。第三:创建电子表格(已计划,等待步骤2)。智能体逐个处理它们,跟踪每个的状态。如果它需要用户输入(“哪些指标最重要?”),它将该子任务标记为等待,提出问题,并处理其他事情。当你回答时,它从停止的地方精确恢复。没有状态跟踪,智能体会失去跟踪并重新开始。
- 运行时编排:管理执行环境
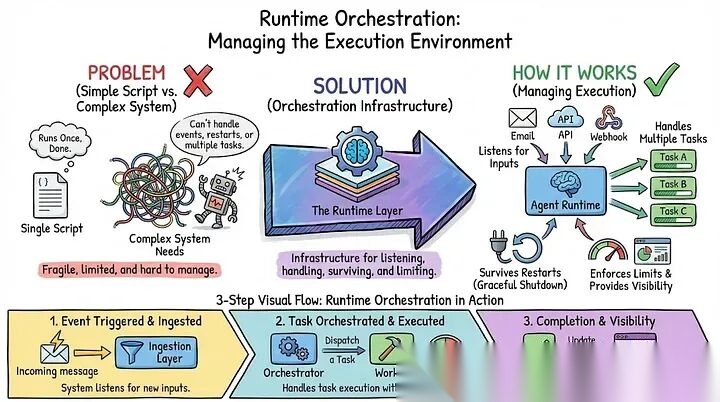
你的智能体不仅仅是一次性运行的脚本。它是一个需要响应事件、处理多个任务、在重启中生存并在资源限制内运行的系统。
运行时编排是基础设施层。你的智能体如何从不同来源监听输入、处理优雅关闭、提供对其正在做什么的可视性,并强制执行限制以防止它失控运行。
示例: 你的智能体监听三个输入源:Slack消息、计划任务和webhook回调。事件队列将每个路由到正确的处理程序。用户发送紧急Slack消息,获得即时响应。计划报告在后台运行。当你部署新版本时,关闭处理程序保存所有进行中的任务状态。新版本启动,加载这些状态,并从停止的地方继续。与此同时,资源限制确保没有单个任务运行超过5分钟或进行超过50次API调用。分布式追踪准确显示当出现问题时发生了什么。
何时使用每个概念:决策指南
从头开始? 从MCP和工具发现开始。构建基础,以便添加新功能变得容易。不要硬编码你以后会后悔的集成。
测试中工作,生产中失败? 添加护栏和错误恢复。在执行前验证。重试暂时性故障。生产有你测试遗漏的所有边缘情况。
智能体忘记东西或看起来很笨? 实现记忆。短期用于对话。长期用于持久事实。上下文工程确保你在决策时提供正确的信息。
任务卡住或花费时间太长? 查看推理循环和状态管理。将复杂请求分解为可跟踪的子任务。让智能体在事情没有按计划进行时进行适应。
担心安全? 加倍投入护栏和人在回路中。保守开始。随着你对智能体处理良好的事情建立信任,扩展自主性。
尽管有好的提示词但决策错误? 修复上下文工程。确保智能体看到相关的用户偏好、系统状态和环境事实。记录你提供的上下文,以便你可以调试。
部署和监控问题? 专注于运行时编排。事件处理、优雅关闭、可观测性、资源限制。你无法修复你看不到的东西。
需要快速集成许多服务? 使用MCP服务器。一个协议,无限工具。停止为每个新服务重写集成代码。
API信用消耗太快? 添加资源限制。限制每个任务的执行时间和API调用。快速失败,而不是耗尽你的预算。
用户不信任它? 将高风险决策的人工批准与其他的可靠错误恢复结合起来。透明度建立信任。显示智能体在做什么以及为什么。
参考表:实施清单
MCP设置: 安装SDK。创建一个定义工具为函数的服务器文件。为每个工具编写清晰的描述,说明它做什么以及何时使用它。包括参数类型。将你的智能体连接到服务器。测试工具是否自动被发现。
推理循环: 构建一个while循环,直到任务完成。LLM决定下一个行动。执行那个行动。将结果反馈给LLM。让它观察并决定下一步是什么。重复。记录每次迭代以便调试。
记忆系统: 用于对话历史的数据库表(短期)。另一个用于用户偏好和学习事实的表(长期)。在组装上下文时查询记忆。使用嵌入添加语义搜索以获得更好的回忆。定期清理旧的对话。
护栏: 验证函数在每个操作之前运行。检查用户权限。验证参数是否合理。扫描输出中的敏感数据。如果检查失败则阻止并记录。返回清晰的错误解释原因。
工具发现: 注册表在运行时列出所有可用的工具。每个工具有名称、描述和参数模式。在系统提示中将注册表传递给智能体。新工具在添加时自动出现。智能体无需代码更改即可学习使用它们。
错误恢复: 在工具调用周围包装错误处理。分类为暂时的、用户可修复的或致命的。使用延迟重试暂时性错误(2秒、4秒、8秒)。向用户询问缺失信息。清晰记录和解释致命错误。在主要方法失败时有备用选项。
人工批准: 按置信度和风险对决策进行评分。高风险或低置信度需要批准。低风险自动进行。异步实现让智能体在等待时处理其他任务。记录所有批准。根据模式调整阈值。
上下文组装: 一个在每个决策之前收集信息的函数。近期的对话消息。来自记忆的相关用户偏好。当前时间和时区。可用的工具。语义搜索相关的过去交互。过滤相关性。记录组装的上下文。
状态跟踪: 定义任务状态(计划中、进行中、等待、阻塞、已完成、失败)。在数据库中存储当前状态。单独跟踪子任务。随着结果积累保存它们。在状态更改时更新数据库。重启时加载以恢复任务。
运行时基础设施: 事件队列监听多个来源。路由到同步或异步处理程序。关闭处理程序在终止时保存状态。分布式追踪跟踪决策和工具调用。每个任务的时间和API调用上的资源限制。监控错误率和持续时间。对异常情况发出警报。
最后
选择一个概念。今天用它构建一些小东西。
如果你厌倦了重写集成,从MCP开始。如果你的智能体不断忘记上下文,添加记忆。如果你担心可能出错的事情,实现护栏。
不要试图一次构建所有东西。掌握一个,交付它,然后继续下一个。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献184条内容
已为社区贡献184条内容

所有评论(0)