面向具身操作的视觉-语言-动作模型:让机器人真正理解并执行人类指令
前言
想象一下这个场景:你对家里的机器人说"帮我把餐桌上的蓝色杯子拿到厨房水槽里洗一下"。一个普通的机器人可能会愣住——它不知道什么是"蓝色杯子",不知道"餐桌"在哪里,更不知道"洗一下"具体要做什么动作。而一个装备了视觉-语言-动作(VLA)模型的机器人,会立刻理解你的指令,识别出餐桌上的蓝色杯子,规划出一条安全的路径,伸出手臂拿起杯子,走到水槽边打开水龙头,完成清洗动作。
这就是具身智能的终极目标:让机器人能够像人类一样,通过视觉感知世界,通过语言理解指令,通过动作改变环境。而VLA模型正是实现这个目标的核心技术。它将计算机视觉、自然语言处理和机器人控制三大领域融为一体,是当前人工智能最热门的研究方向之一。
论文信息
- 标题:面向具身操作的视觉−语言−动作模型综述
- 期刊:自动化学报
- 单位:国内顶尖高校/科研院所
- 代码:无公开统一代码(各模型代码见对应论文)
- 论文:http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250689
一、为什么我们需要视觉-语言-动作模型?
在过去的十年里,人工智能在计算机视觉和自然语言处理领域取得了惊人的进步。我们有了可以识别万物的CLIP,有了可以和人类流畅对话的GPT,有了可以生成逼真图像的Stable Diffusion。但这些模型都有一个共同的缺点:它们都是"云端的大脑",没有身体,无法与物理世界交互。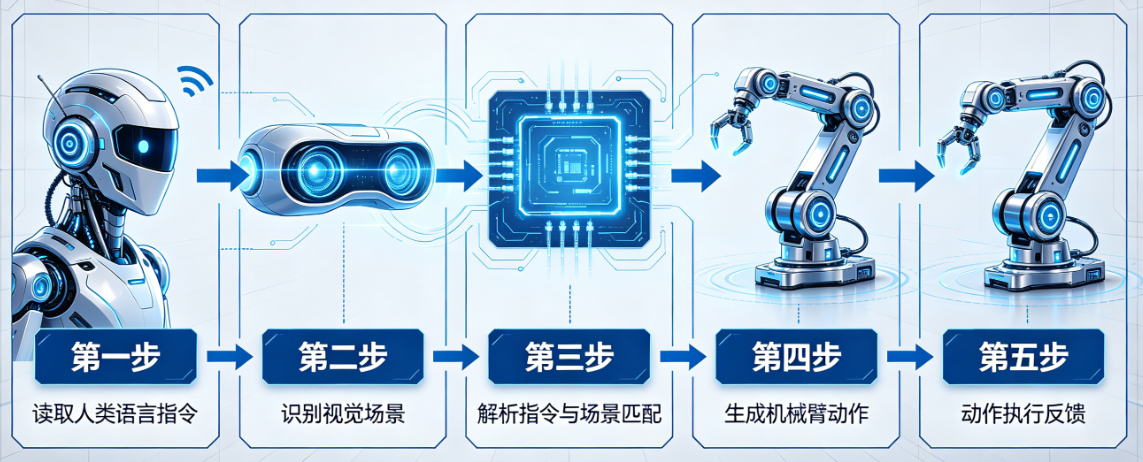
1.1 传统机器人控制的局限性
传统的机器人控制方法通常是这样的:
- 工程师手动设计感知模块,识别特定的物体
- 手动设计运动规划算法,计算机器人的运动轨迹
- 手动编写控制代码,执行具体的动作
这种方法有三个致命的缺点:
- 泛化能力差:只能在特定的环境中执行特定的任务,稍微改变一下环境就会失败
- 开发成本高:每个任务都需要大量的工程工作
- 无法理解自然语言:只能执行预先编程好的指令
1.2 VLA模型的革命
VLA模型彻底改变了这一切。它的核心思想是:用一个统一的大模型来处理视觉输入、语言指令和动作输出。这样的模型具有以下优势:
- 强大的泛化能力:可以在从未见过的环境中执行从未见过的任务
- 零样本学习能力:只需要通过自然语言描述,就能学会新的任务
- 端到端训练:不需要手动设计感知、规划和控制模块
- 多模态理解能力:可以同时理解视觉信息和语言指令
通俗解释:传统机器人就像一个只会背剧本的演员,只能按照剧本上写的台词和动作来表演。而VLA机器人就像一个真正的演员,可以理解剧本的含义,根据不同的场景即兴发挥。
二、VLA模型的发展历程
VLA模型的发展可以分为三个阶段:
2.1 第一阶段:模块化方法(2015-2020)
在这个阶段,研究人员将机器人系统分为三个独立的模块:
- 视觉模块:识别物体和场景
- 语言模块:理解自然语言指令
- 动作模块:生成机器人的控制命令
每个模块单独训练,然后通过接口连接起来。这种方法的优点是简单易懂,但缺点也很明显:模块之间的信息传递会丢失大量的上下文信息,导致系统整体性能不佳。
典型代表:
- Google SayCan:将语言模型的指令理解能力与机器人的动作能力结合起来
- CLIPort:将CLIP的视觉-语言对齐能力应用于机器人操作任务
2.2 第二阶段:端到端多模态模型(2021-2023)
随着大语言模型的兴起,研究人员开始尝试用一个统一的模型来处理所有模态。这些模型通常基于Transformer架构,将视觉图像、语言指令和机器人动作都视为token序列,然后用同一个Transformer来处理。
典型代表:
- Google PaLM-E:第一个真正意义上的通用具身多模态模型
- Google RT-1/RT-2:专门为机器人操作设计的VLA模型
- NVIDIA VIMA:基于Transformer的通用机器人智能体
2.3 第三阶段:世界模型驱动的VLA(2024-至今)
最新的研究趋势是将世界模型与VLA模型结合起来。世界模型可以预测未来的状态,帮助机器人进行更长远的规划,从而完成更复杂的任务。
典型代表:
- Google DreamerV3:基于世界模型的强化学习算法
- OpenAI Sora:可以生成视频的世界模型,具有巨大的机器人应用潜力
- Tesla Optimus Neural Network:特斯拉人形机器人的端到端神经网络
三、VLA模型的核心技术架构
一个典型的VLA模型由三个核心部分组成:多模态编码器、跨模态对齐模块和动作解码器。
3.1 通用目标函数
VLA模型的训练目标可以统一表示为:
minθE(o,l,a)∼D[−logπθ(a∣o,l)]\min_{\theta} \mathbb{E}_{(o, l, a) \sim D} \left[ -\log \pi_\theta(a | o, l) \right]θminE(o,l,a)∼D[−logπθ(a∣o,l)]
其中:
- θ\thetaθ:模型的参数
- ooo:观测(通常是RGB图像)
- lll:自然语言指令
- aaa:机器人的动作(关节角度、末端执行器位姿等)
- DDD:训练数据集
- πθ(a∣o,l)\pi_\theta(a | o, l)πθ(a∣o,l):策略函数,表示在观测ooo和指令lll下执行动作aaa的概率
- E\mathbb{E}E:对数据集求期望
通俗解释:这个公式的意思是,我们要让模型在看到图像ooo和听到指令lll时,尽可能准确地预测出人类专家会执行的动作aaa。这就是所谓的行为克隆——让机器人模仿人类专家的行为。
3.2 多模态编码器
多模态编码器的作用是将不同模态的输入(图像、语言)转换为统一的特征表示。
视觉编码器
视觉编码器通常使用预训练的计算机视觉模型,比如:
- CLIP ViT:最常用的视觉编码器,具有强大的视觉-语言对齐能力
- DINOv2:自监督预训练的视觉模型,具有更好的泛化能力
- ConvNeXt:卷积神经网络的最新代表,适合处理高分辨率图像
视觉编码器将输入的RGB图像转换为一个视觉特征序列:
v=VisionEncoder(o)v = \text{VisionEncoder}(o)v=VisionEncoder(o)
其中v∈RN×dv \in \mathbb{R}^{N \times d}v∈RN×d,NNN是视觉token的数量,ddd是特征维度。
语言编码器
语言编码器通常使用预训练的大语言模型,比如:
- BERT:适合理解性任务
- GPT-2/GPT-3:适合生成性任务
- Llama 2:开源大语言模型,性能强大
语言编码器将输入的自然语言指令转换为一个语言特征序列:
t=LanguageEncoder(l)t = \text{LanguageEncoder}(l)t=LanguageEncoder(l)
其中t∈RM×dt \in \mathbb{R}^{M \times d}t∈RM×d,MMM是语言token的数量。
3.3 跨模态对齐模块
跨模态对齐模块的作用是将视觉特征和语言特征融合在一起,让模型理解"语言描述的是图像中的什么东西"。
最常用的跨模态对齐方法是交叉注意力机制:
f=CrossAttention(v,t)f = \text{CrossAttention}(v, t)f=CrossAttention(v,t)
其中f∈R(N+M)×df \in \mathbb{R}^{(N+M) \times d}f∈R(N+M)×d是融合后的多模态特征。
交叉注意力机制允许视觉特征和语言特征之间进行双向的信息交互,让模型能够将语言中的名词、动词与图像中的物体、动作对应起来。
3.4 动作解码器
动作解码器的作用是根据融合后的多模态特征,生成机器人的控制动作。
动作解码器通常是一个Transformer解码器或者一个简单的MLP:
a=ActionDecoder(f)a = \text{ActionDecoder}(f)a=ActionDecoder(f)
对于不同的机器人平台,动作的表示方式也不同:
- 机械臂:通常是末端执行器的6维位姿(x, y, z, roll, pitch, yaw)加上夹爪的开合度
- 移动机器人:通常是线速度和角速度
- 人形机器人:通常是全身关节的角度
3.5 核心代码实现
下面是一个简化的VLA模型实现,基于PyTorch和Hugging Face Transformers:
import torch
import torch.nn as nn
from transformers import CLIPVisionModel, AutoTokenizer, AutoModel
class VLAModel(nn.Module):
def __init__(self,
vision_model_name="openai/clip-vit-base-patch32",
language_model_name="bert-base-uncased",
action_dim=7, # 6维位姿 + 1维夹爪
hidden_dim=768):
super().__init__()
# 视觉编码器
self.vision_encoder = CLIPVisionModel.from_pretrained(vision_model_name)
self.vision_proj = nn.Linear(self.vision_encoder.config.hidden_size, hidden_dim)
# 语言编码器
self.tokenizer = AutoTokenizer.from_pretrained(language_model_name)
self.language_encoder = AutoModel.from_pretrained(language_model_name)
self.language_proj = nn.Linear(self.language_encoder.config.hidden_size, hidden_dim)
# 跨模态注意力
self.cross_attention = nn.MultiheadAttention(hidden_dim, num_heads=8, batch_first=True)
# 动作解码器
self.action_decoder = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, images, instructions):
# 编码视觉输入
vision_outputs = self.vision_encoder(images)
vision_features = self.vision_proj(vision_outputs.last_hidden_state) # [B, N, d]
# 编码语言输入
language_inputs = self.tokenizer(instructions, padding=True, truncation=True, return_tensors="pt").to(images.device)
language_outputs = self.language_encoder(**language_inputs)
language_features = self.language_proj(language_outputs.last_hidden_state) # [B, M, d]
# 跨模态注意力:视觉特征作为query,语言特征作为key和value
fused_features, _ = self.cross_attention(vision_features, language_features, language_features)
# 全局平均池化
global_features = torch.mean(fused_features, dim=1)
# 解码动作
actions = self.action_decoder(global_features)
return actions
# 测试模型
model = VLAModel()
images = torch.randn(2, 3, 224, 224) # 2张RGB图像
instructions = ["把红色的方块放到蓝色的盒子里", "拿起桌子上的杯子"]
actions = model(images, instructions)
print(f"预测动作形状: {actions.shape}") # 输出: torch.Size([2, 7])
四、关键挑战与解决方案
虽然VLA模型取得了巨大的进步,但仍然面临着许多挑战。下面是几个最主要的挑战以及对应的解决方案:
4.1 数据稀缺问题
挑战:机器人操作数据非常难以获取。收集一个小时的人类操作数据可能需要花费几千美元,而训练一个大模型需要数百万小时的数据。
解决方案:
- 数据增强:对现有的数据进行各种变换,比如旋转、平移、缩放、颜色抖动等
- 模拟到真实迁移:在模拟器中生成大量的合成数据,然后用少量的真实数据进行微调
- 互联网规模数据预训练:利用互联网上的大量视频和文本数据进行预训练,然后在机器人数据上进行微调
4.2 泛化能力问题
挑战:VLA模型在训练环境中表现很好,但在新的环境中往往会失败。这是因为模型容易过拟合训练数据中的特定物体和场景。
解决方案:
- 对比学习:通过对比不同视角、不同光照、不同背景下的同一物体,学习更鲁棒的特征表示
- 数据多样化:在尽可能多样化的环境中收集训练数据
- 模块化设计:将模型分为感知模块和动作模块,让感知模块学习通用的视觉特征,动作模块学习通用的运动技能
4.3 长程规划问题
挑战:大多数VLA模型只能进行短程的动作预测,无法完成需要多步推理的复杂任务,比如"做一杯咖啡"。
解决方案:
- 分层控制:将复杂任务分解为多个简单的子任务
- 世界模型:训练一个世界模型来预测未来的状态,帮助机器人进行长远规划
- 大语言模型规划:利用大语言模型的推理能力来生成任务计划,然后由VLA模型执行
4.4 安全问题
挑战:机器人在执行任务时可能会对自己、对人类或者对环境造成伤害。
解决方案:
- 安全约束:在动作解码器中加入安全约束,禁止机器人执行危险的动作
- 人类监督:在训练和部署过程中保持人类监督,随时可以停止机器人的动作
- 强化学习安全:使用安全强化学习算法,在训练过程中避免危险的行为
五、典型应用场景
VLA模型已经在许多领域得到了应用,下面是几个最有前景的应用场景:
5.1 工业机器人
工业机器人是VLA模型最早也是最成熟的应用领域。传统的工业机器人只能在结构化的环境中执行重复的任务,而装备了VLA模型的工业机器人可以:
- 处理不同形状、不同大小的物体
- 适应不断变化的生产线
- 通过自然语言指令快速切换任务
案例:亚马逊的仓库机器人已经开始使用VLA模型来处理各种不同的商品,大大提高了仓库的运营效率。
5.2 家庭服务机器人
家庭服务机器人是VLA模型最令人期待的应用领域。未来的家庭机器人将能够:
- 打扫卫生、整理房间
- 做饭、洗碗
- 照顾老人和孩子
- 与人类进行自然的交流
案例:特斯拉的Optimus人形机器人就是基于VLA模型设计的,它的目标是成为一个通用的家庭服务机器人。
5.3 医疗机器人
VLA模型在医疗领域也有巨大的应用潜力。医疗机器人可以:
- 协助医生进行手术
- 照顾病人
- 分发药品
- 进行康复训练
案例:达芬奇手术机器人已经开始使用VLA模型来辅助医生进行更精确的手术操作。
5.4 农业机器人
农业机器人可以解决农业劳动力短缺的问题。VLA模型可以让农业机器人:
- 识别不同的作物和杂草
- 进行精准的播种、施肥和收割
- 监测作物的生长状况
- 处理各种复杂的农业任务
六、不同VLA模型对比
下面是几个主流VLA模型的性能对比:
| 模型名称 | 发布机构 | 发布时间 | 参数量 | 支持任务数 | 泛化能力 | 推理速度 |
|---|---|---|---|---|---|---|
| RT-1 | Google DeepMind | 2022 | 13M | 700+ | 中等 | 快 |
| PaLM-E | Google DeepMind | 2023 | 562B | 1000+ | 强 | 慢 |
| RT-2 | Google DeepMind | 2023 | 55B | 1000+ | 很强 | 中等 |
| VIMA | NVIDIA | 2023 | 300M | 200+ | 中等 | 快 |
| Octo | Berkeley | 2024 | 1.2B | 1000+ | 很强 | 中等 |
表1:主流视觉-语言-动作模型对比
从表中可以看出:
- RT-1:参数量小,速度快,但泛化能力有限
- PaLM-E:参数量最大,泛化能力最强,但推理速度最慢
- RT-2:在性能和速度之间取得了很好的平衡
- Octo:最新的开源VLA模型,性能接近RT-2,而且完全开源
七、未来展望
VLA模型是实现通用人工智能的关键一步。未来,VLA模型将朝着以下几个方向发展:
7.1 更大规模的模型
随着计算能力的提升,VLA模型的参数量将会越来越大。更大的模型意味着更强的泛化能力和更多的技能。
7.2 世界模型的融合
世界模型将成为VLA模型的标准组件。通过预测未来的状态,机器人可以进行更长远的规划,完成更复杂的任务。
7.3 多机器人协作
多个机器人将能够通过VLA模型进行协作,共同完成单个机器人无法完成的任务。
7.4 终身学习
未来的VLA模型将能够在部署后继续学习,不断积累新的技能和知识,适应不断变化的环境。
总结
视觉-语言-动作模型是人工智能领域最激动人心的研究方向之一。它将计算机视觉、自然语言处理和机器人控制三大领域融为一体,让机器人能够真正理解并执行人类的指令。
虽然VLA模型仍然面临着数据稀缺、泛化能力、长程规划和安全等挑战,但我们有理由相信,随着技术的不断进步,这些挑战都将被一一克服。在不久的将来,我们将会看到越来越多的VLA机器人走进我们的生活,为我们提供各种服务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)