神经网络与深度学习课程笔记(一)(两周内容):线性模型---卷积神经网络
1.神经网络与深度学习概览
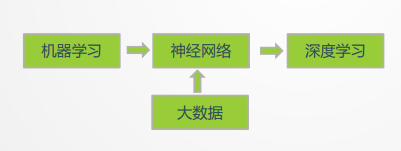
课程主线建立:工智能、机器学习、神经网络、深度学习之间到底是什么关系。
- 人工智能定义是用机器去实现目前必须借助人类智慧才能完成的任务,其核心是模拟、延伸和扩展人的智能。神经网络与深度学习是当前人工智能中非常重要、也非常热门的一个分支。从方法论角度看,人工智能可以有多个切入点。神经网络和深度学习偏向“仿生角度”,也就是模仿生物神经系统的信息处理过程;机器学习更强调从数据中总结规律;强化学习则更偏向行为学和控制论的角度。
- 机器学习的经典定义来自 Mitchell:一个程序如果能利用经验 EEE,在任务 TTT 上通过性能指标 PPP 得到改进,就可以说它具有学习能力。放到计算机系统中,“经验”通常就是数据集。这个定义看似抽象,但很有启发:学习不是单纯记住样本,而是让模型在未知数据上表现更好。
- 深度学习兴起的重要背景是数据量和计算能力的提升。传统机器学习在视觉任务中经常依赖人工特征工程,例如 SIFT、HOG、纹理特征等。问题在于,人工特征需要人为设计,既费时,也很难覆盖复杂场景中的光照变化、尺度变化、旋转变化和遮挡变化。深度学习的思路是让模型通过多层结构自动学习特征:低层学习边缘、纹理等简单模式,高层逐渐组合出物体部件甚至语义信息。
统视觉算法中“数据采集—预处理—特征提取—特征选择—学习推理”的过程。

人类视觉系统和分层网络展示了从像素到边缘、部件、物体模型的层级特征。
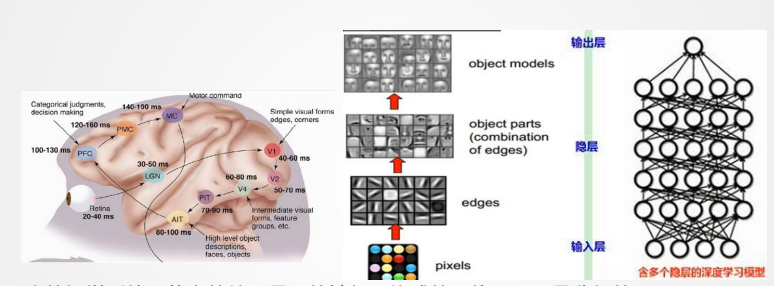
传统机器学习像是“人先想好特征,再让机器学习规律”;深度学习更像是“把特征学习也交给模型”。当然,这并不意味着深度学习完全不需要人的设计,网络结构、损失函数、优化器、数据增强等仍然需要人工经验,但它确实把特征表达能力大幅提升了。
本节小结
本节主要解决“为什么要学习神经网络与深度学习”的问题。深度学习的优势来自多层特征表达能力,能够从大量数据中自动学习复杂映射关系。它不是凭空出现的,而是在机器学习、大数据、计算硬件和神经网络理论共同发展的基础上形成的。
2.线性回归、线性分类与感知机
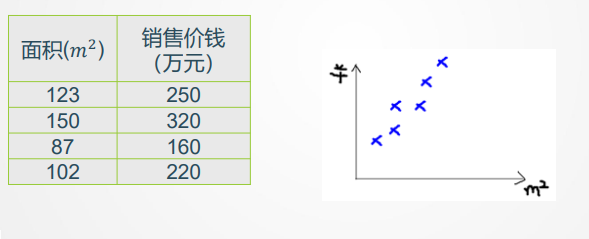
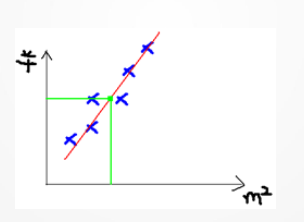
线性回归是理解神经网络优化思想的一个很好的入口。线性回归可以用房价预测来理解:已知房屋面积、年限等特征,希望预测房屋价格。若只有一个输入特征,可以用直线拟合;若有多个输入特征,就用超平面拟合。例如我们所学ppt的4—10 页围绕房价例子介绍了训练集、输入 x、输出 y、模型 h(x)、损失函数和解析解。
在线性回归中
最简单的一维模型可以写为:
如果扩展到多个特征,例如房价同时与面积、年限等因素有关,可以写成:
进一步推广到 nnn 维特征,令参数向量和输入向量分别为:
模型可以统一写为:
有了模型之后,就需要衡量预测值和真实值之间的差距。线性回归中常用平方误差损失函数:
训练的目标就是找到一组参数,使损失函数最小:
对于线性回归,在矩阵可逆且维度不高时,可以通过正规方程直接求解析解:
不过到了分类问题,情况会有变化。线性二分类的输出不再是一个连续数值,而是类别或者属于某一类的概率。以苹果分类为例,输入可以是“苹果直径”和“外观评价”,输出是红苹果或青苹果。线性分类器的本质是通过直线或超平面把样本划分开。
对于二分类问题
经常引入 Sigmoid 函数,把线性输出压缩到 (0,1)区间:
其中:
这样模型输出就可以解释为属于正类的概率:
对于多分类问题
常用 Softmax 函数将多个类别得分转化为概率分布:
线性模型再往前走一步,就到了神经元模型和感知机。
感知机
感知机可以看作一个非常简单的神经元:输入经过加权求和,再通过阶跃函数输出类别。其基本形式为:
其中阶跃函数可以写为:
感知机的直观理解是:每个输入特征都有一个权重,权重越大,说明这个特征对最终判断越重要;阈值 θ则像一道“门槛”。当加权和超过门槛,神经元被激活,否则不激活。
本节小结
线性回归、逻辑回归、Softmax 回归和感知机看起来是不同模型,但背后有一条共同主线:先定义模型,再定义损失函数,最后通过优化方法寻找合适参数。神经网络后续的复杂结构,本质上也是在这条主线上不断扩展。
3.多层感知机与 BP 反向传播算法
单层感知机能够解决线性可分问题,但面对 XOR 这类线性不可分问题时就会失败。 XOR 问题说明:四个样本点无法被一条直线分开,因此单层线性分类器无能为力。解决方法是在输入层和输出层之间加入隐含层,构成多层感知机,也就是多层前馈神经网络。

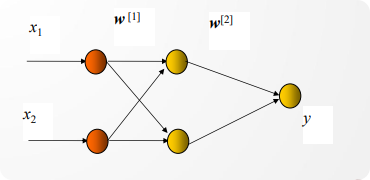
以一个包含两个输入、两个隐层节点、一个输出节点的网络为例,隐层输出可以写为:
输出层可以写为:
多层感知机的意义在于:隐层可以把原始输入映射到新的特征空间,使原本线性不可分的问题在新空间中变得更容易分类。也就是说,网络不是只在原始坐标系中“画一条线”,而是先对数据做非线性变换,再进行分类。
真正让多层网络能够训练起来的关键是 BP 算法。BP 学习算法由正向传播和反向传播组成:正向传播负责从输入层到隐层、再到输出层计算网络输出;如果输出不满足期望,就进入反向传播,把误差沿连接路径反向传回,并用梯度下降调整各层权值和阈值。
设第 l 层的线性输入为:
激活输出为:
对于平方误差损失,可写为:
其中 ti是期望输出,yi是网络实际输出。反向传播的核心是链式求导。
输出层误差项可写为:
隐层误差项由后一层误差加权传回:
权值更新可以写为:
偏置更新可以写为:
这里的 η是学习率。学习率太大,训练过程可能震荡甚至发散;学习率太小,模型收敛会非常慢。我对 BP 的理解是:它是“误差分摊机制”。输出层发现错了多少,隐层再根据自己对输出错误的贡献程度来调整参数
本节小结:
层感知机解决了单层感知机表达能力不足的问题,BP 算法解决了多层网络如何训练的问题。正向传播负责计算输出,反向传播负责传递误差,梯度下降负责更新参数。理解 BP 算法,是后面理解 CNN、RNN、Transformer 等深度模型训练过程的基础。
4.卷积神经网络基础
卷积神经网络主要用于图像、视频等具有空间结构的数据。全连接网络用于图像时会面临参数过多、计算慢、难收敛和容易过拟合的问题。例如输入是 1000×1000 的图像,如果隐层有 100 万个节点,那么输入层到隐层之间的参数量会达到 量级。
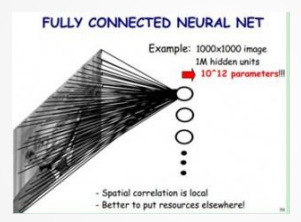
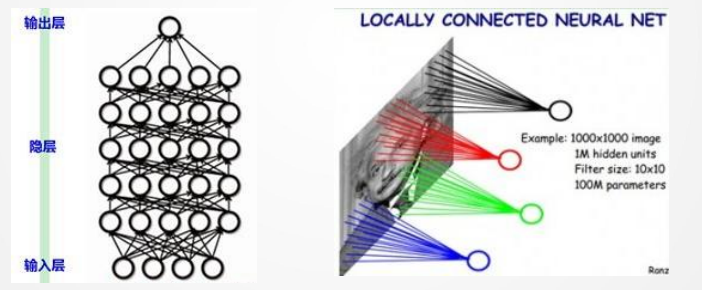
全连接层参数量大致可以写为:
其中 H,W,C分别表示输入图像的高、宽、通道数,M表示输出神经元个数。卷积神经网络通过三个关键思想缓解这个问题:局部连接、权值共享和池化下采样。
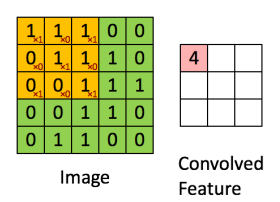
卷积操作可可以理解为用一个小窗口在图像上滑动,每次对局部区域做加权求和。二维卷积可写为:
其中 X是输入特征图,W 是卷积核,Y 是输出特征图。课件第 22 页给出了一个很直观的卷积滑动窗口图,可以放在这里帮助读者理解。
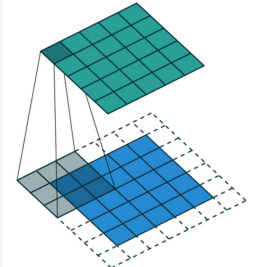
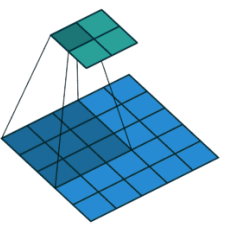
如果考虑填充 P、步长 S、卷积核大小 K,输出尺寸可以写为:
池化层用于降低特征图尺寸,常见的有最大池化和平均池化。最大池化取局部窗口中的最大值:
平均池化取局部窗口的平均值:
从功能上看,卷积层负责提取局部特征,激活函数引入非线性,池化层压缩空间尺寸,全连接层完成最终分类。一个典型 CNN 可以概括为:
LeNet-5
LeNet-5是经典卷积神经网络之一。它的基本思路是交替使用卷积层和池化层,最后接全连接层进行分类。后续的 AlexNet、VGG、ResNet 等网络虽然更深更复杂,但基本组成单元仍然离不开卷积、激活、池化和全连接。
AlexNet
AlexNet 使用最大池化、ReLU 激活函数,并出现了“多个卷积层 + 一个池化层”的结构,这也是现代 CNN 的常见设计规律:网络越深,空间尺寸逐渐减小,通道数逐渐增多。
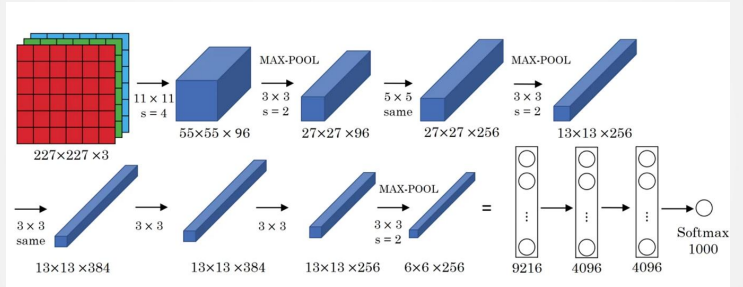
本节小结:
卷积神经网络的核心价值在于利用图像的空间局部性。相比全连接网络,CNN 通过局部连接减少参数量,通过权值共享提升特征检测效率,通过池化增强一定的平移鲁棒性。理解卷积、填充、步长、池化和通道,是学习 CNN 的基础。
5.两周学习小结与个人理解
这两周的课程内容看似跨度很大,从人工智能概述到线性回归,再到感知机、BP 网络和卷积神经网络,但它们其实是一条连续的路线。
- 第一步是理解“学习”的含义。机器学习是利用数据改善模型在任务上的表现。深度学习进一步把特征学习也纳入模型训练过程中,这让模型能够处理图像、语音、文本等复杂非结构化数据。
- 第二步是理解“模型 + 损失 + 优化”。线性回归中,我们先定义线性模型,再定义平方误差损失,最后求解最优参数;分类问题中,我们通过 Sigmoid 或 Softmax 将模型输出解释为概率;感知机则把线性加权和与激活函数结合起来,形成最基础的神经元模型。
- 第三步是理解“层”的意义。单层模型只能处理简单线性问题,多层感知机通过隐层引入非线性表达能力,可以解决 XOR 这样的线性不可分问题。BP 算法的出现,使多层网络能够通过梯度下降进行系统训练。
- 第四步是理解“结构先验”的价值。CNN 之所以适合图像任务,是因为它把图像的局部相关性和平移特征写进了网络结构中。局部连接和权值共享不是随意设计出来的,而是对图像数据特点的利用。
我个人觉得,学习神经网络时最容易陷入两个误区。一个是只背公式,不知道公式在解决什么问题;另一个是只跑代码,不知道代码背后的数学逻辑。比较好的学习方式是把每个模型都按四个问题来理解:输入是什么,输出是什么,参数是什么,损失函数怎么定义。只要这四点清楚了,再复杂的网络也可以拆开来看。
最后,概括这两周课程:神经网络的发展过程,就是从简单线性映射出发,不断增强模型表达能力和训练能力的过程。线性回归让我们理解参数优化,感知机让我们看到神经元模型,多层感知机和 BP 让深层网络可训练,卷积神经网络则让深度学习真正进入图像理解场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)