DPO梯度机制理论分析
目录
✅1.引言
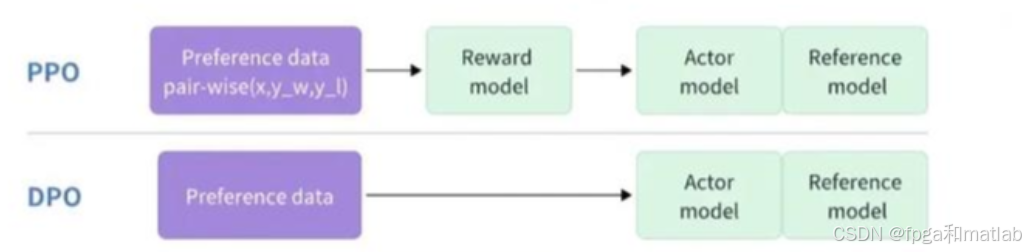
在大语言模型(LLM)的落地实践中,“对齐” 是决定模型输出是否符合人类偏好、能否安全可靠服务用户的核心环节。所谓 “对齐”,就是让模型的生成内容与人类的价值观、指令意图和行为规范保持一致,而DPO(Direct Preference Optimization,直接偏好优化)与基于PPO(Proximal Policy Optimization,近端策略优化)的RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习),正是当前大模型对齐领域最主流、应用最广泛的两大算法。二者在实现路径、训练成本、效果特性上各有千秋,深刻影响着模型对齐的效率与最终表现。
✨2.DPO梯度更新机制理论分析
DPO之所以能实现高效、稳定的偏好对齐,核心在于其梯度更新机制的巧妙设计。通过对DPO梯度公式的拆解与分析,我们可以清晰地看到,它如何通过动态系数调节,实现 “强化优质回答、抑制劣质回答” 的目标,同时避免模型更新幅度过大或过小的问题。
2.1 DPO梯度公式
DPO的梯度由其损失函数直接推导而来,最终形式如下:
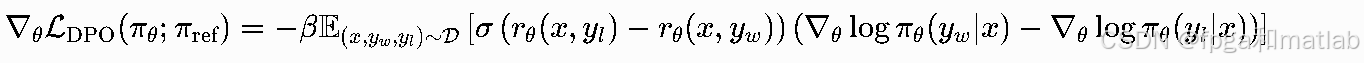
2.1.1 隐式奖励函数
公式中的rθ(x,y)是DPO定义的隐式奖励函数,它的表达式为:

2.1.2 Sigmoid函数的缩放调节作用
公式中的σ(rθ(x,yl)−rθ(x,yw))是DPO梯度的动态系数,其中σ是Sigmoid激活函数,表达式为:
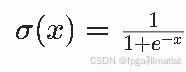
输出范围为(0,1)。这个动态系数是DPO梯度机制的核心,它的取值直接决定了梯度更新的幅度。
2.1.3 梯度更新

这部分梯度的目标就是“增加优质回答出现的概率,同时减少劣质回答出现的概率”,与偏好对齐的核心目标完全一致。
2.2 DPO与PPO-based RLHF对比
DPO本身没有在损失函数中加入任何显式鼓励探索的项,模型的探索性完全由超参数β间接控制。β是DPO的核心超参数,它决定了模型在“拟合偏好数据”和“保持与参考模型(预训练模型)的一致性” 之间的平衡:β越大,模型越倾向于贴近参考模型的分布,探索性越弱;β越小,模型越能偏离参考分布,探索性越强。这种间接的调节方式,让DPO的探索性缺乏灵活的主动控制能力。
基于PPO的RLHF:显式正则化,定向鼓励策略多样性PPO算法的损失函数中,专门设计了熵正则项,这一项的作用就是直接鼓励策略模型保持输出分布的熵值,也就是鼓励模型生成更多样化、不确定性更高的内容,避免模型过早收敛到单一的、缺乏多样性的策略。这种显式的设计,让 RLHF 的探索性可以被主动调节,帮助模型跳出局部最优解,探索更广阔的策略空间。
🔍3. DPO参数更新的完整流程
基于上述梯度公式,DPO的参数更新遵循标准的梯度下降流程,公式如下:
![]()
其中,η是学习率,控制参数更新的步长。结合梯度公式的含义,我们可以将DPO的参数更新流程总结为以下步骤:
1.输入一个包含优质回答yw和劣质回答yl的偏好样本(x,yw,yl);
2.分别计算策略模型和参考模型对yw和yl的对数概率,得到隐式奖励值rθ(x,yw)和rθ(x,yl);
3.计算隐式奖励差异rθ(x,yl)−rθ(x,yw),并通过Sigmoid函数得到动态系数;
4.计算优质回答和劣质回答的对数概率梯度,结合动态系数得到最终的梯度;
5.根据学习率η,通过梯度下降更新策略模型的参数θ;
6.重复上述步骤,遍历所有偏好样本,直到模型收敛。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)