大模型project面试10
21. 大模型能力评测指标有哪些?
我对这块的理解是,学术 Benchmark 只能作为参考,真正重要的是在自己业务数据上的表现。MMLU / MMLU-Pro 测综合知识,HumanEval / SWE-bench Verified 测代码,GSM8K / MATH / GPQA 测数学和科学推理,LiveBench、Humanity’s Last Exam 这类更新型评测用来缓解数据污染。这些指标看一眼能大概判断模型能力区间,但不能直接等价成业务效果。我们实际项目里的做法是,从真实用户请求里采样、人工标注期望输出,建一个 50-200 条的测试集,每次改 Prompt 或换模型都在上面跑一遍,加上线上的用户满意率来形成闭环,这才是可靠的评测体系。
为什么需要评测指标
大模型的能力是多维度的,「感觉用起来还不错」不足以支撑工程决策。当你需要从 GPT-4o 换到 Claude,或者决定是否要对模型进行微调,或者衡量 Prompt 优化后的效果提升,都需要量化指标。评测指标的价值在于把「主观感受」转化成「可比较的数字」。
但评测模型远比评测传统软件难得多,因为语言生成是开放性任务,「正确答案」的边界往往是模糊的。这也是为什么这个领域同时存在多种不同侧重的 Benchmark。下面来认识几个最常被引用的学术 Benchmark,了解它们各自考查的是什么维度。
主流学术 Benchmark 逐一介绍
-
MMLU / MMLU-Pro 是最广泛引用的综合能力测试。MMLU 涵盖 57 个学科领域,从高中数学、历史、法律到医学和计算机科学,全部是四选一的单项选择题。MMLU-Pro 难度更高、选项更多,也更强调推理。可以把它理解成一套超全面的「文化水平考试」,考的是模型的知识广度和推理基础。
-
HumanEval、MBPP 和 SWE-bench Verified 是代码能力的基准测试。HumanEval 由 OpenAI 设计,包含 164 道编程题,每道题给出函数签名和 docstring,要求生成完整的函数实现,然后用隐藏的测试用例验证正确性。SWE-bench Verified 更接近真实软件工程,让模型修真实 GitHub issue,能更好评估代码理解、修改和测试能力。Pass@k 是常见指标,表示生成 k 个候选代码,至少 1 个能通过所有测试的比例。
-
GSM8K、MATH、GPQA 测试数学和科学推理能力。GSM8K 是小学数学应用题,考基础的四则运算和逻辑推理;MATH 是竞赛数学,包含代数、几何、组合数学等;GPQA 更偏研究生级别的科学问答,很多题需要物理、化学、生物等专业知识和多步推理。
-
MT-Bench、Arena、τ-bench 更偏对话和 Agent / Tool Use 能力。MT-Bench 设计了一系列需要多轮交互的场景,用「LLM-as-Judge」方式给回答打分;Chatbot Arena 更像用户真实偏好投票;τ-bench 这类评测会看模型在工具调用、多轮状态管理、业务流程里的表现,更贴近 Agent 应用。
-
HELM、LiveBench、Humanity’s Last Exam 是更综合或更新型的评测。HELM 覆盖准确率、鲁棒性、公平性、有害性等多个维度;LiveBench 会持续更新题目,降低数据污染;Humanity’s Last Exam 则主打更难、更广的综合知识和推理。它们比单一指标更全面,但也更复杂。然而,这些看起来很权威的指标,有一个很难回避的系统性缺陷。
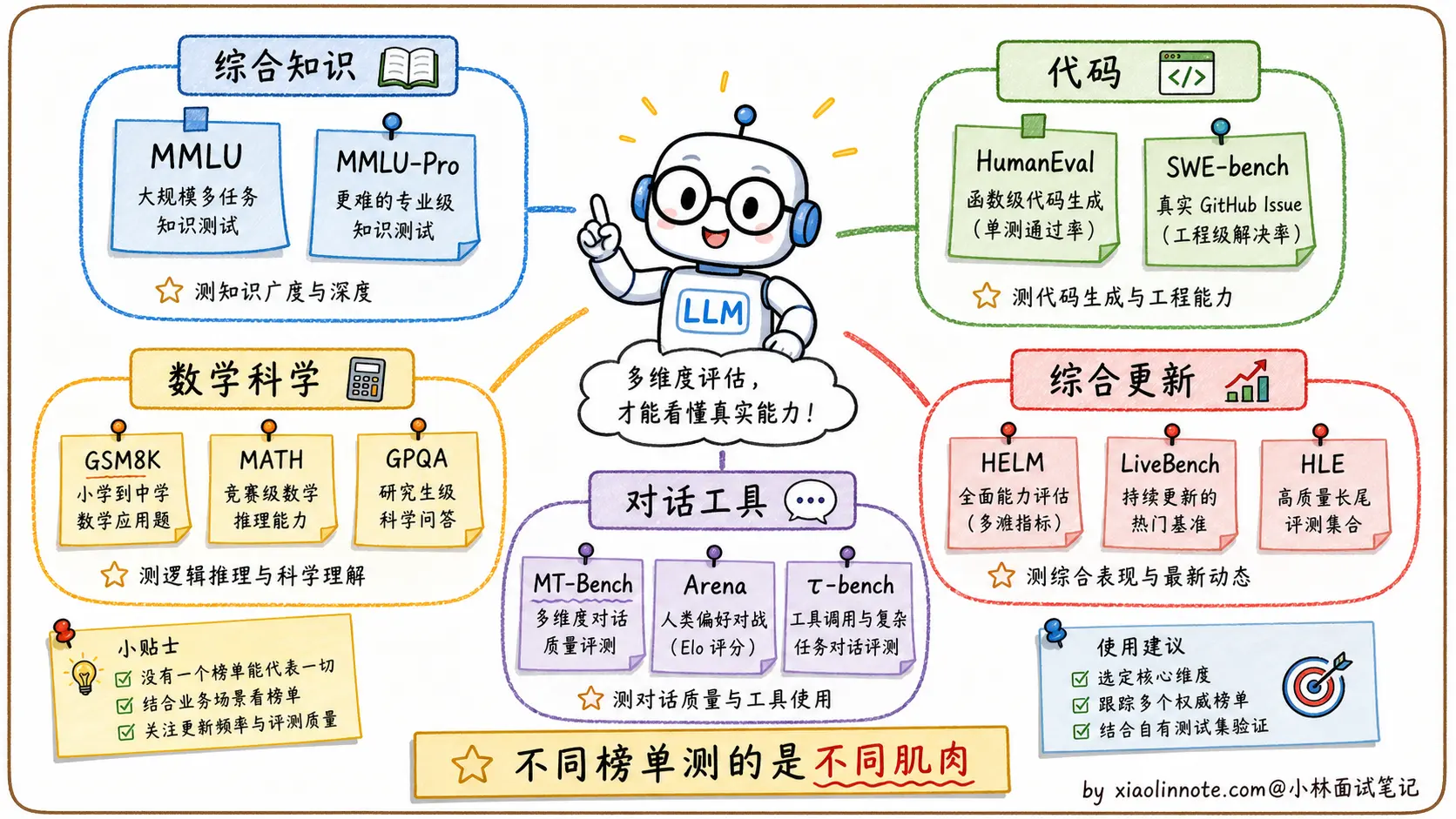
Benchmark 的局限性:数据污染问题
Benchmark 有一个严重的问题:数据污染。
现在的大模型训练数据规模极大,覆盖了互联网大部分公开内容,而 MMLU、GSM8K 这些 Benchmark 的题目也在互联网上公开流传。模型在预训练时可能已经「见过」这些题目的答案,导致测试成绩虚高,并不真正反映泛化能力。
这也是为什么有些模型在学术排行榜上名列前茅,实际用起来却不如名次更低的竞品,因为它们可能是「背过题」的,而不是真的更聪明。
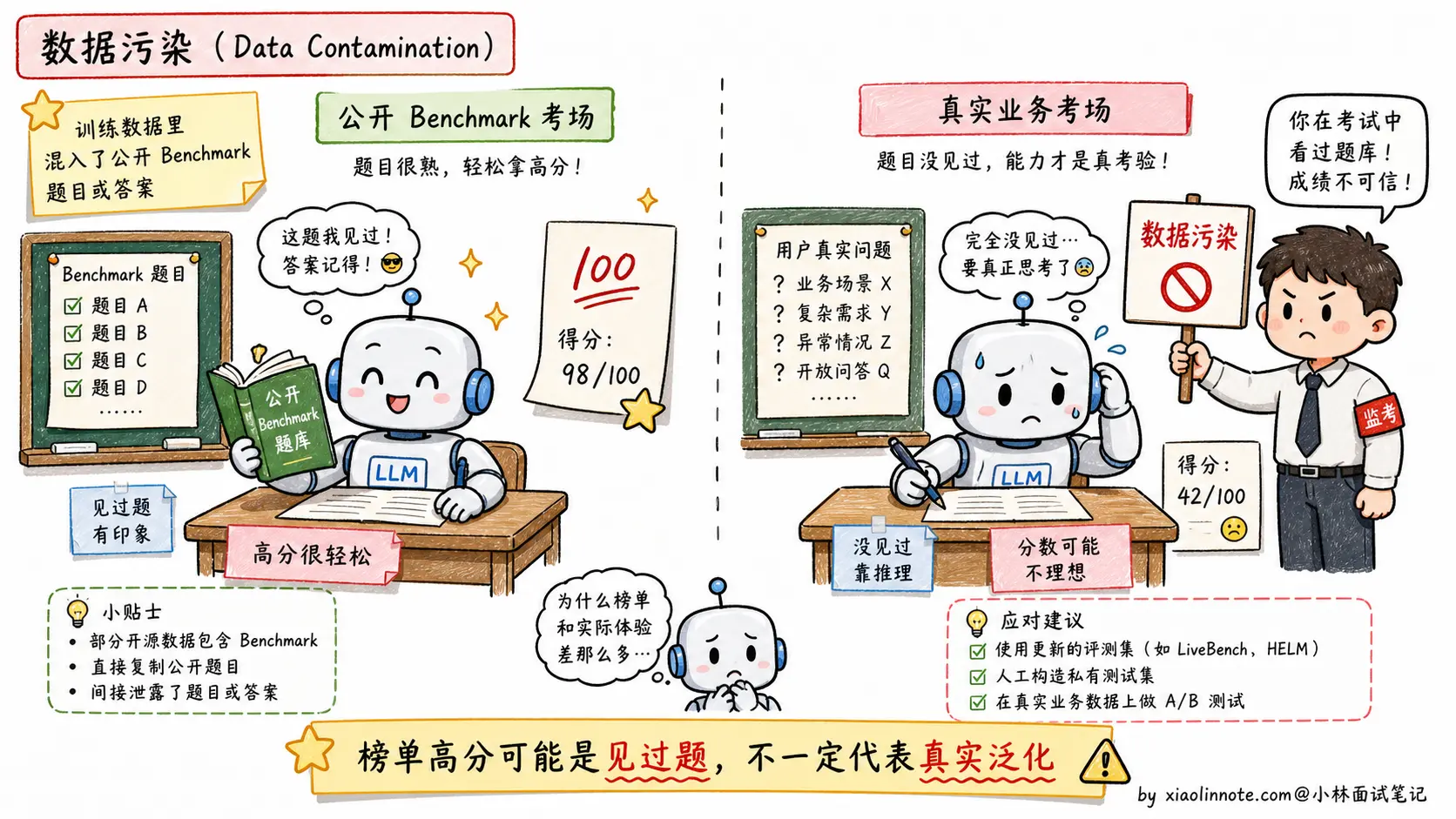
如何建自己的业务评估集
面对 Benchmark 局限性,最务实的做法是建自己的任务特定测试集。
做法通常是:从真实用户请求里采样,人工标注期望答案,形成 50-200 条有代表性的「黄金测试集」;然后每次迭代模型或 Prompt 时,在这个测试集上跑一遍,计算通过率或质量分。
评分方式上,客观任务(信息提取、分类、代码)可以用程序自动验证;主观任务(摘要、问答质量)可以用 LLM-as-Judge,让一个更强的模型(如 GPT-4o)对输出按照给定标准打分。人工抽查 10-20% 的样本可以校准 LLM-Judge 是否可信。
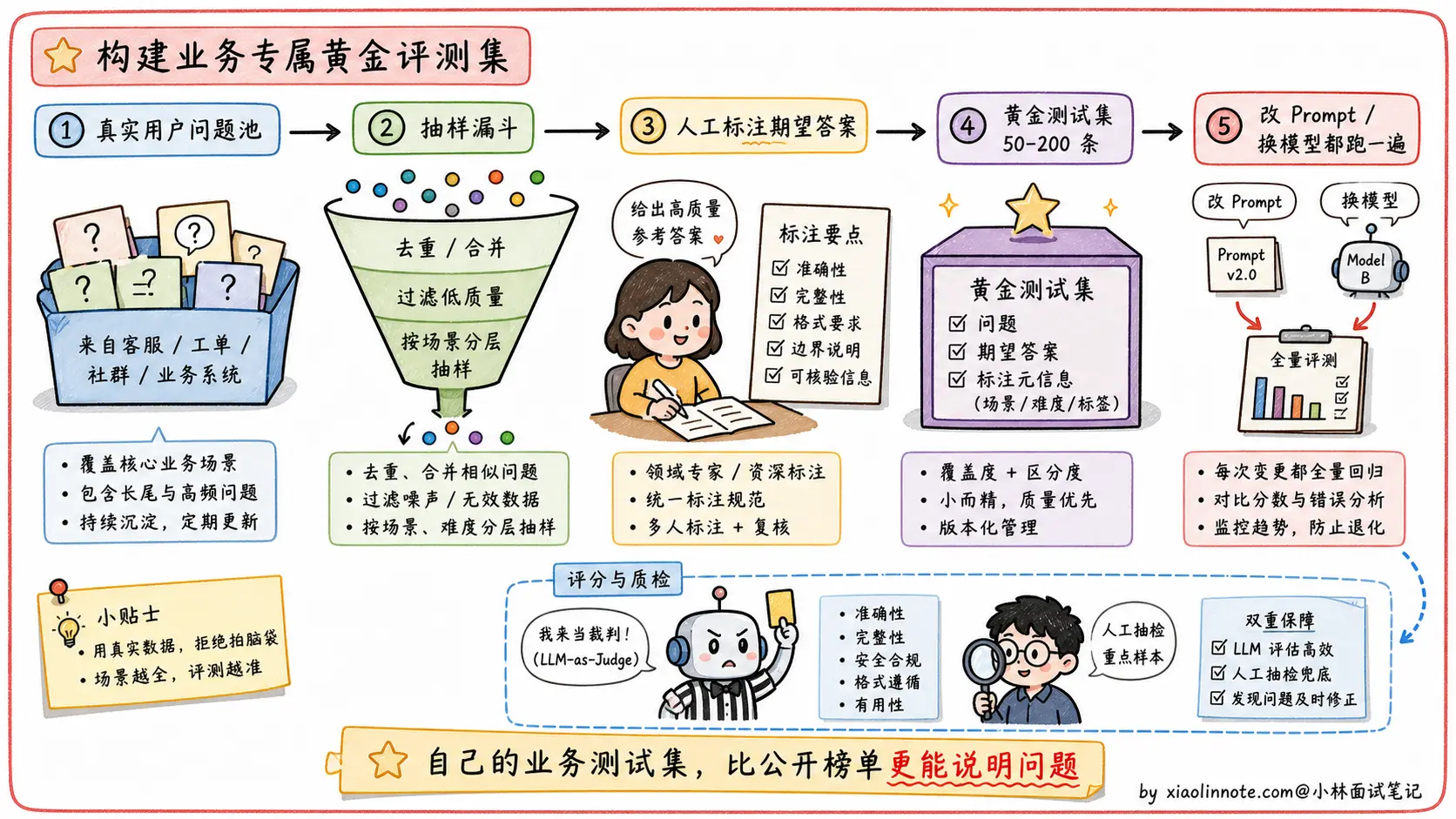
离线评估 + 线上指标的闭环
业务测试集解决了离线评估的问题,但只有离线测试集还不够,生产环境里还需要监控实际的用户体验指标:用户对回答是否满意(明确的点赞/踩、隐式的追问行为)、任务完成率(用户是否实现了目标)、会话放弃率(用户中途退出说明体验差)。
离线评估帮你找问题、快速迭代;线上指标告诉你优化是否真正改善了用户体验。两者结合才是完整的评估体系。
回到开头那段对话,问到大模型评测指标,最重要的是先把学术 Benchmark 和业务评测的关系讲清楚。学术 Benchmark(MMLU、HumanEval、GSM8K、MT-Bench、HELM 等)适合横向对比模型的综合能力,但不能完全相信,因为存在严重的「数据污染」问题(模型在预训练时可能见过测试题)。这一句先讲到,面试官就知道你不是只会背 Benchmark 名字。
接下来讲清主流 Benchmark 各自测什么。MMLU / MMLU-Pro 测综合知识广度和推理,HumanEval / MBPP / SWE-bench Verified 测代码能力,GSM8K / MATH / GPQA 测数学和科学推理,MT-Bench / Arena / τ-bench 测对话、偏好和工具调用,HELM / LiveBench / Humanity’s Last Exam 则是更综合或更新型的评测。能用一两句话说清每个 Benchmark 的设计目标,比单纯报名字深刻得多。
最关键的是讲业务测试集的构建方法。从真实用户请求里采样 50-200 条,人工标注期望答案,形成「黄金测试集」,每次改 Prompt 或换模型都在上面跑一遍。评分方式上客观任务(分类、抽取、代码)用程序自动验证;主观任务(摘要、问答)用 LLM-as-Judge 让强模型代评分,人工抽查 10-20% 样本校准。这套方法是工业界做 LLM 项目的标配,能讲出来证明你真的做过项目。
最后提一句离线评估 + 线上指标的闭环。离线评估帮你快速迭代找问题,线上指标(满意度、任务完成率、会话放弃率)告诉你优化是不是真的改善了用户体验。两者结合才是完整的评估体系。
如果还想再加分,可以提一句数据污染问题的应对方向:避免用公开 Benchmark 直接当训练集、用 LiveBench 这种「持续更新题库」的评测、用业务真实数据做评测。这种「不被 Benchmark 蒙蔽」的工程视角是面试里很难追问的水平。
22. 对比使用过哪些主流大模型?你们项目中最终选用了哪个模型?为什么?
在项目选型阶段,我会先把模型分成两类:一类是国内可落地的生产候选,比如 DeepSeek、Qwen、豆包这类模型;另一类是海外能力标杆,比如 GPT-5.5 / o 系列、Claude Sonnet / Opus 系列,用来做能力上限参照。
如果是面向国内企业用户的 Agentic RAG 系统,我倾向于把国内模型作为主链路候选,海外模型只做离线评测或非敏感场景兜底。原因不是海外模型不好,而是企业项目里合规、网络稳定性、成本预算、售后支持这些约束会直接决定方案能不能上线。
最终落地时,我不会死磕一个模型,而是用 Model Routing(模型路由):格式要求严格、Tool Use 多的节点优先选指令遵循和结构化输出稳定的模型;高频推理、数据清洗、摘要归纳这类节点优先选性价比高的模型;特别难的问题再路由给能力更强但更贵的模型。选模型从来不是看谁跑分最高,而是看谁最契合业务的合规、成本、延迟与能力特征。
1. 为什么不能盯着「排行榜」无脑选?
很多新手选模型喜欢盯着大模型榜单,看谁排第一就想用谁,这在工程落地时是个巨大的坑。
跑分高,不代表在你的特定业务里表现好。比如海外标杆模型在多模态、代码、复杂推理上通常很强,但它的 API 成本、数据出境、网络访问、企业合同支持,都可能卡住国内 ToB 项目;有些模型榜单漂亮,但在你的财报格式、行业黑话、内部接口调用上不一定稳定;如果系统存在大量高频的 Agent 内部循环调用,硬上最贵的标杆模型,可能一个月就把项目预算烧穿。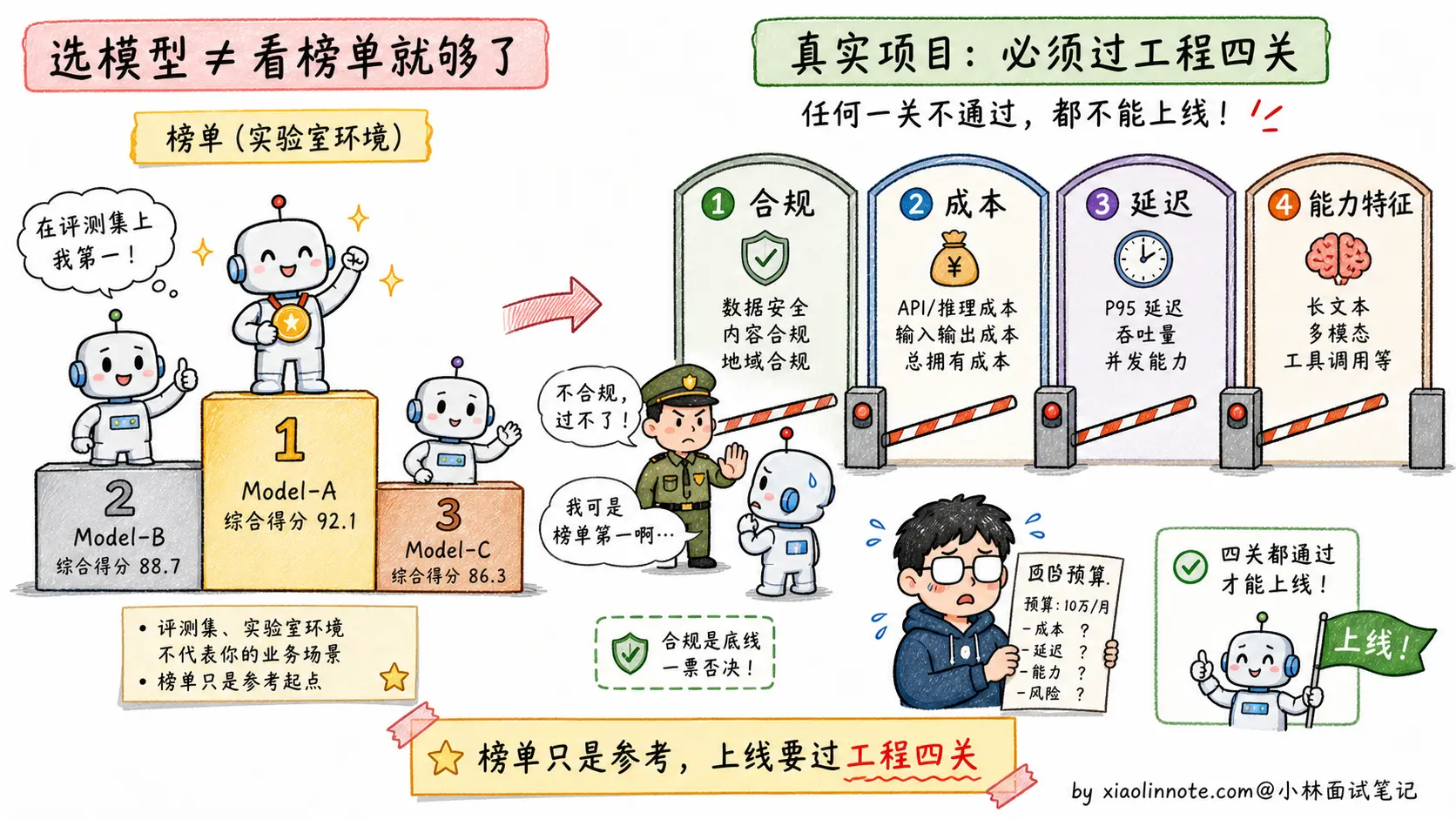
2. 主流大模型横向盘点(2026 年视角)
在评估时,我通常把模型分为「国内生产候选」和「海外能力标杆」两个阵营。这里的模型名不要当成固定答案,因为 2026 年模型版本迭代很快,面试时更重要的是讲清选型逻辑。
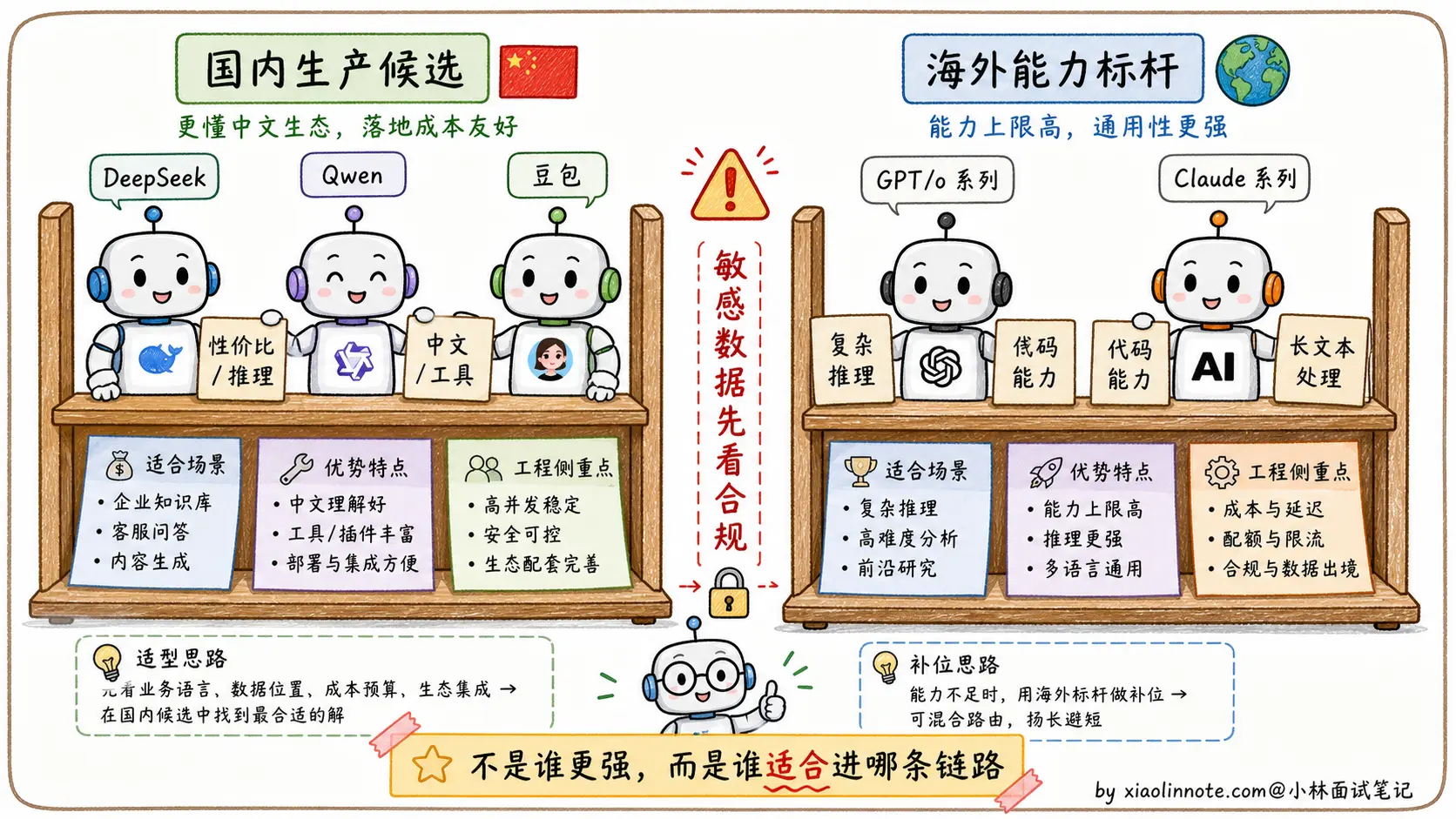
国内生产候选(实际落地优先看)
- DeepSeek 系列:特点是推理和性价比突出,适合放在高频分析、代码辅助、长链路推理这类成本敏感的节点上。但具体选 V 系列还是 R 系列,要看任务是偏通用生成还是偏推理。
- Qwen 系列(通义千问):中文语境、工具调用、结构化输出、长上下文这些能力比较适合企业级应用,尤其适合做主调度、文档理解、RAG 汇总这类要求稳定性的节点。
- 豆包 / 火山引擎系列:工程生态、并发能力、中文产品化体验是它的优势,适合高频文本处理、客服、内容生成、批量分类这类吞吐优先的场景。
海外能力标杆(评测与非敏感兜底)
- GPT-5.5 / o 系列:适合作为复杂推理、代码、多模态能力的标杆模型。国内企业项目里通常要谨慎放到核心链路,重点评估数据出境、合规审批、网络稳定性和成本。
- Claude Sonnet / Opus 系列:长文本、代码、Agent 调度能力很强,也常被用来做评测基准或兜底模型。但它同样要先过合规、成本和可用性这几关。
3. 我们最终选型落地的思考逻辑
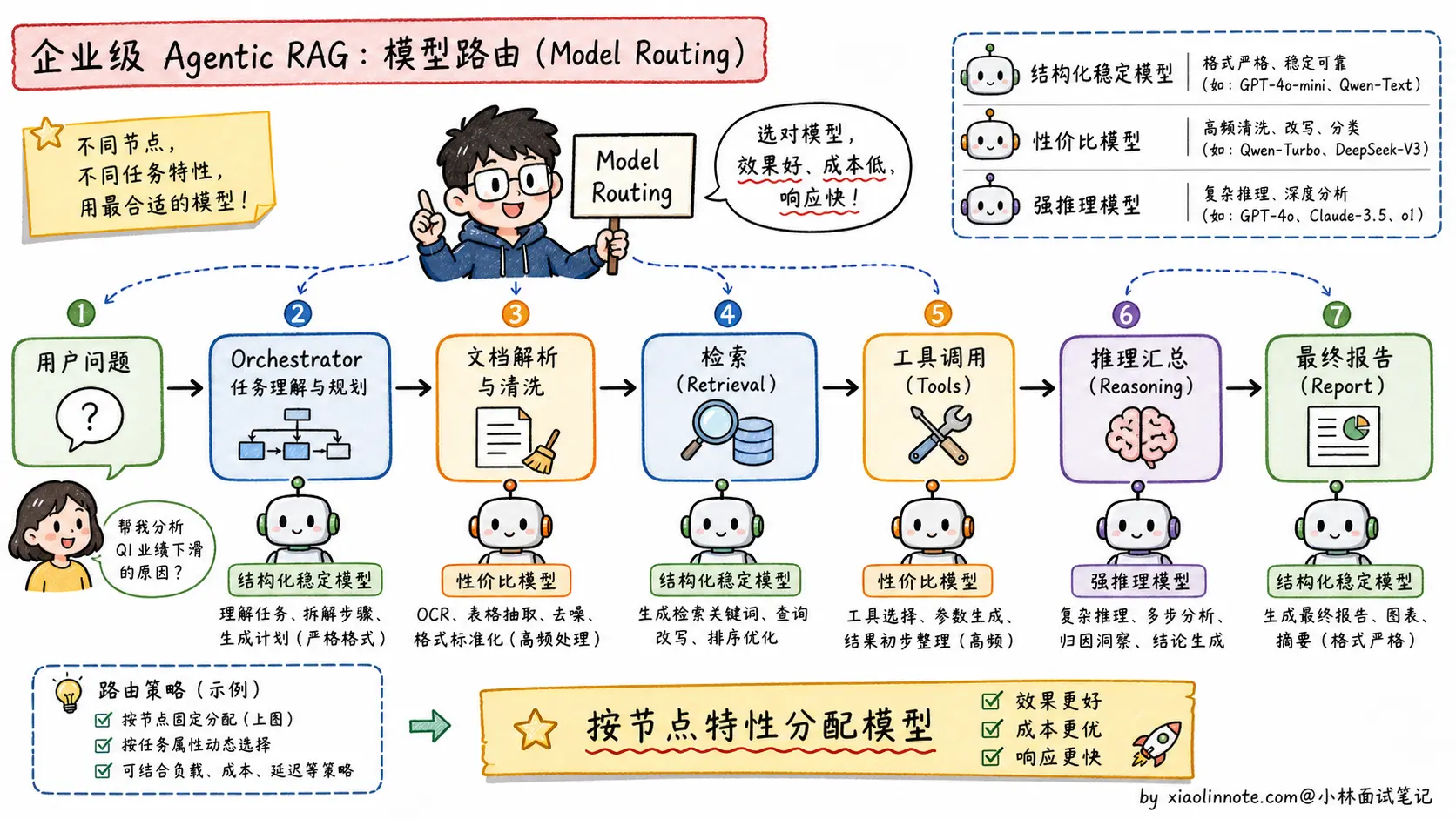
我们的项目是一个企业级多智能体 RAG 问答系统,业务链路涉及:解析长篇企业财报 -> 多个 Agent 规划拆解任务 -> 频繁调用公司内部的数据库与搜索引擎 -> 汇总生成中文报告。
基于这个真实场景,我们没有死磕单一模型,而是设计了**「大模型路由分配(Model Routing)」**策略:
主调度节点(Orchestrator)和格式要求严格的节点,优先选结构化输出稳定、Tool Use 准确率高、长上下文指令遵循好的模型。在这个环节,Agent 需要频繁调用内部 API,JSON、函数参数、字段名都不能乱,所以「稳定」比「榜单第一」更重要。
逻辑推理与高频数据清洗节点,优先选推理能力和 token 单价更均衡的模型。在对财报数据做归纳、比对、异常解释时,很多调用不是面向用户的最终回答,而是 Agent 内部中间步骤,这类节点最怕成本失控,所以要把便宜且够用的模型用起来。
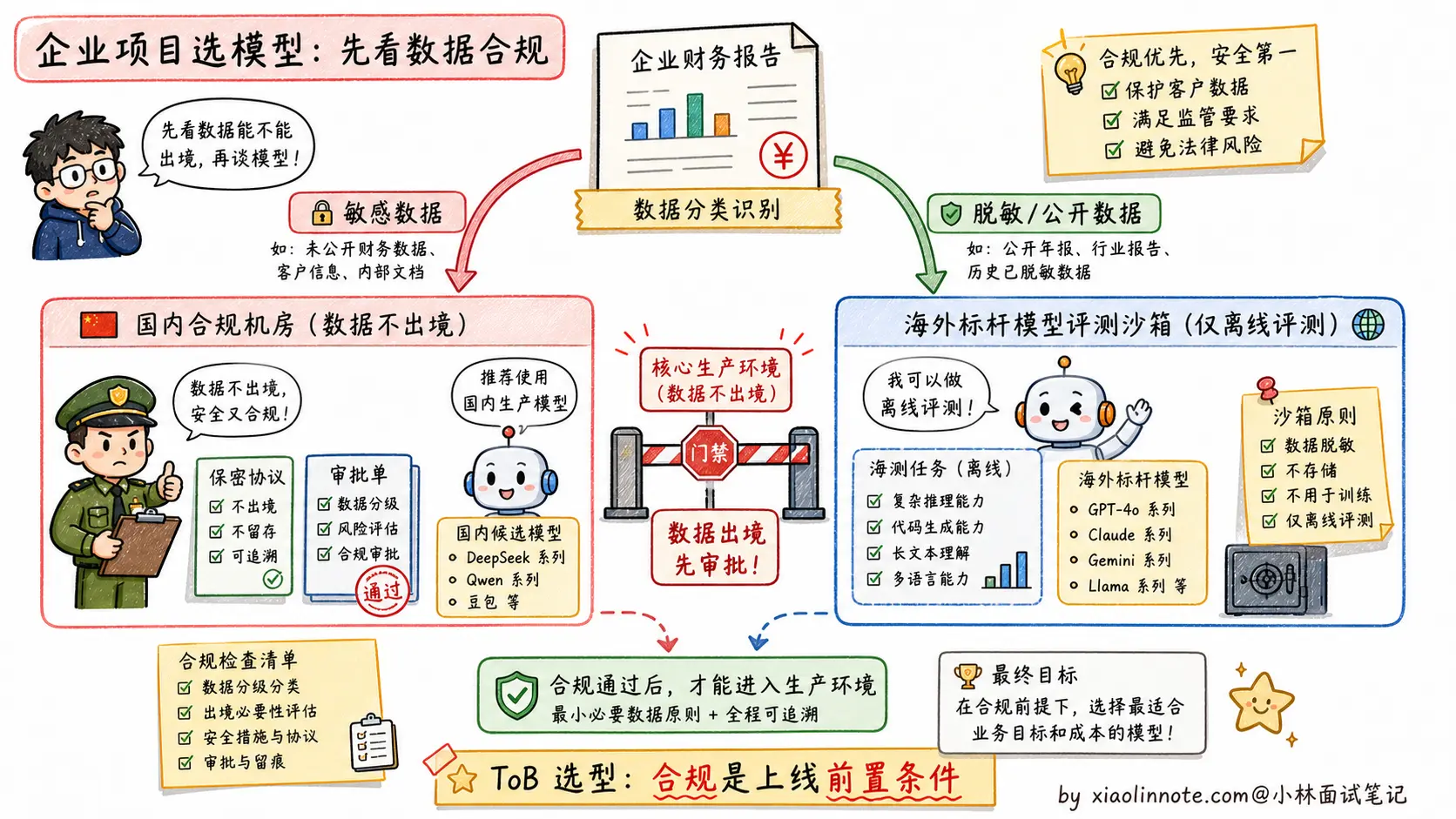
最重要的合规底线是:敏感商业数据尽量留在合规可控的链路里。国内 ToB 项目里,海外模型不是绝对不能用,但必须先看数据分类分级、客户合同、监管要求和企业审批。只要这几关过不了,再强的模型也只能做离线评测,不能进核心生产链路。
回到开头那段对话,问到大模型选型,最重要的是先把选型不是看排行榜讲清楚。模型选型从来不是看跑分最高,是看「合规、成本、延迟、能力特征」四个维度匹配业务需求。这一句先讲到,面试官就知道你不是会背榜单的新人,是真的想过工程问题。
接下来讲清主流大模型的定位。国内候选重点看 DeepSeek 的推理和性价比、Qwen 的中文和工具调用、豆包的工程生态和并发能力;海外标杆重点看 GPT-5.5 / o 系列、Claude Sonnet / Opus 系列在复杂推理、代码、长文本上的能力。能讲出每家模型的「特长」而不只是「排名」,会让面试官知道你真的用过对比过。
最关键的是讲选型落地的思考逻辑。不是死磕单一模型,而是设计「模型路由(Model Routing)」策略,按节点特性分配模型。比如格式要求严格的调度节点用结构化输出稳定的模型,高频推理任务用性价比高的模型,敏感数据链路优先走合规可控的模型。这种「根据任务特性混合用多个模型」的工程思路,是 2026 年 AI 应用里很常见的做法。
如果还想再加分,可以提一句合规约束的现实意义:国内 ToB 项目里,数据出境合规是死线,再强的海外模型也不能用。这种「业务约束优先于技术先进性」的判断,会让面试官知道你真的在国内企业项目里跑过流程。能讲到这一层,这道题就答得很完整了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)