AI读心术?基于语音情感识别(SER)的心理健康评估系统开发实录
一、行业痛点:为什么语音是心理检测的最优载体?
1.1 传统心理筛查致命缺陷
目前国内绝大多数心理平台,依旧依赖 SCL-90、SDS、SAS 纸质/电子量表。
-
主观隐瞒性强:学生、员工知道测评目的,刻意勾选积极选项,数据完全失真;
-
滞后性严重:量表只能记录当下主观感受,无法捕捉长期情绪波动;
-
人力成本高:千人以上批量筛查,咨询师人工复核压力巨大,很难做到早预警、早干预。
1.2 为什么语音比文本、人脸更靠谱?
很多人觉得:人脸表情能看情绪、文本聊天能判心理。但真实商用场景恰恰相反:
-
人脸:可以刻意假笑,光线、遮挡、角度干扰极大;
-
文本:可以刻意伪装文案,话术修饰性极强;
-
语音:人声生理特征无法伪装。
人在焦虑、压抑、抑郁、高压状态下,声带振动频率、语速、微颤、响度都会发生生理性变化,主观意识无法控制。这也是SER语音情感识别被广泛用于心理健康筛查的核心原因。
二、硬核原理:语音情感识别(SER)底层技术拆解
2.1 什么是SER?
SER(Speech Emotion Recognition,语音情感识别),是通过算法提取人声声学特征,将人耳无法分辨的细微声音变化转化为特征向量,最终判定情绪状态的技术。
在心理健康领域,我们不做简单的喜怒哀乐分类,而是精准划分:平静、轻度焦虑、高度焦虑、压抑、低落、紧张、易怒七大心理声学状态。
2.2 心理语音核心声学特征
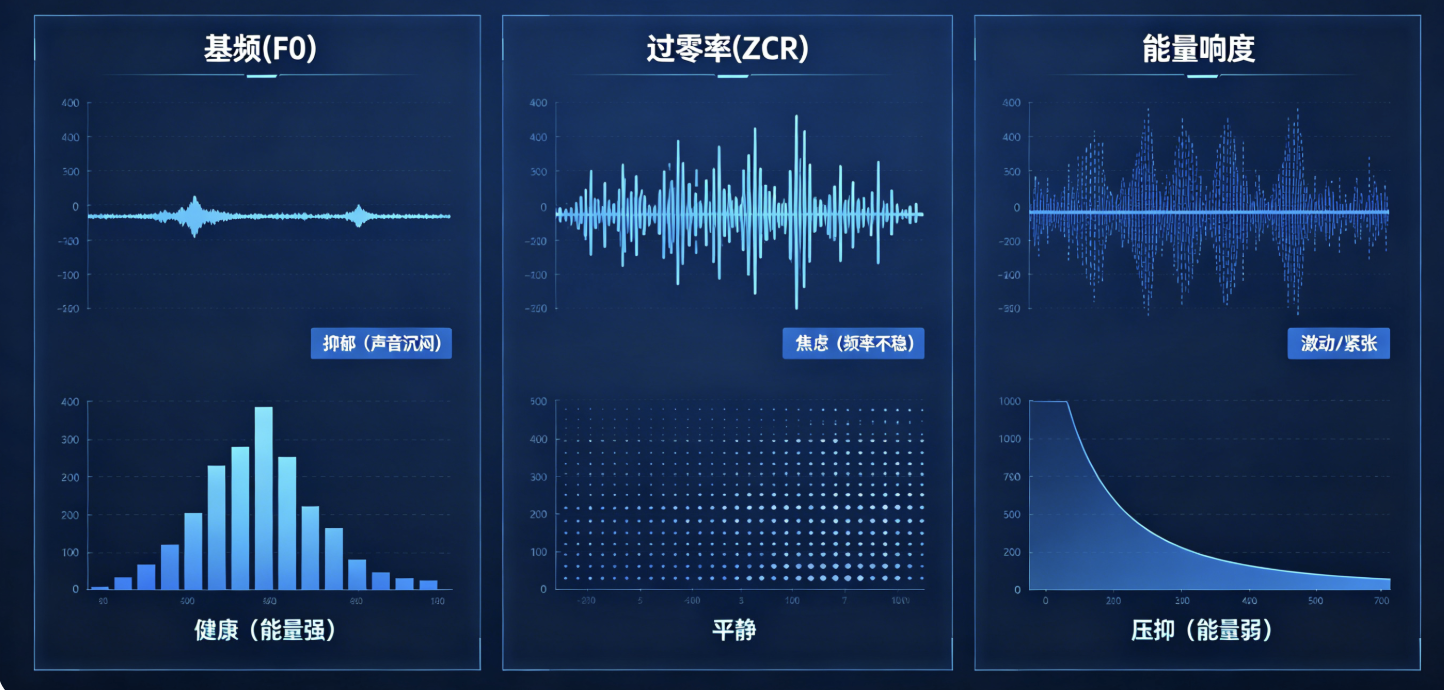
2.2.1 低频基础特征
-
基频F0:抑郁人群基频偏低、声音沉闷;焦虑人群基频抖动剧烈;
-
过零率ZCR:情绪激动、紧张时,过零率显著升高;
-
能量响度:长期压抑人群说话能量弱、声音气短无力。
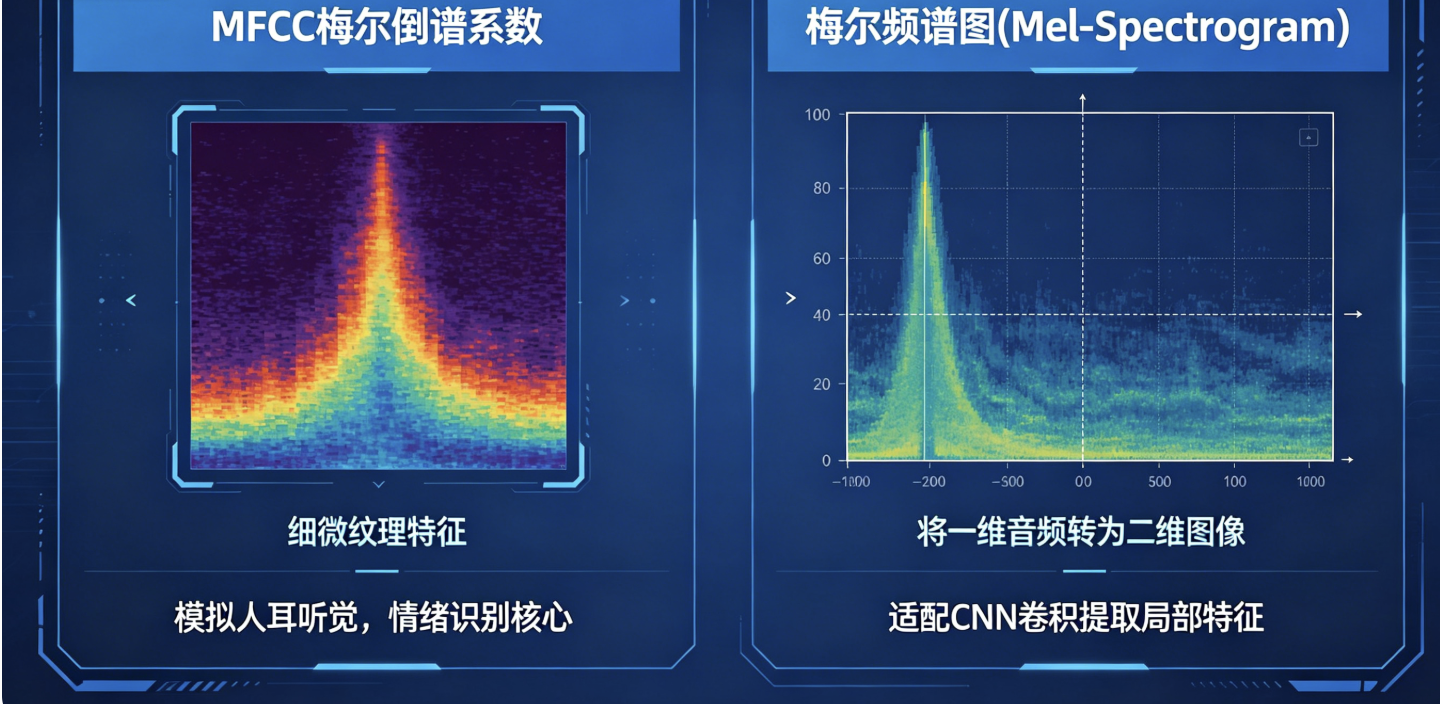
2.2.2 高频频谱特征
-
MFCC梅尔倒谱系数:模拟人耳听觉,提取人声细微纹理特征,是情绪识别最核心特征;
-
梅尔频谱图Mel-Spectrogram:将一维音频转为二维图像,适配CNN卷积提取局部特征。
2.3 模型架构:CNN+BiLSTM融合结构
-
CNN卷积层:负责提取音频局部特征,捕捉音色、频率、共振峰细微变化;
-
BiLSTM双向长短期记忆网络:捕捉语音时序关系,识别语速停顿、语气间断、情绪拐点;
-
全连接层+Softmax:输出心理情绪概率,生成压力指数、焦虑评分。
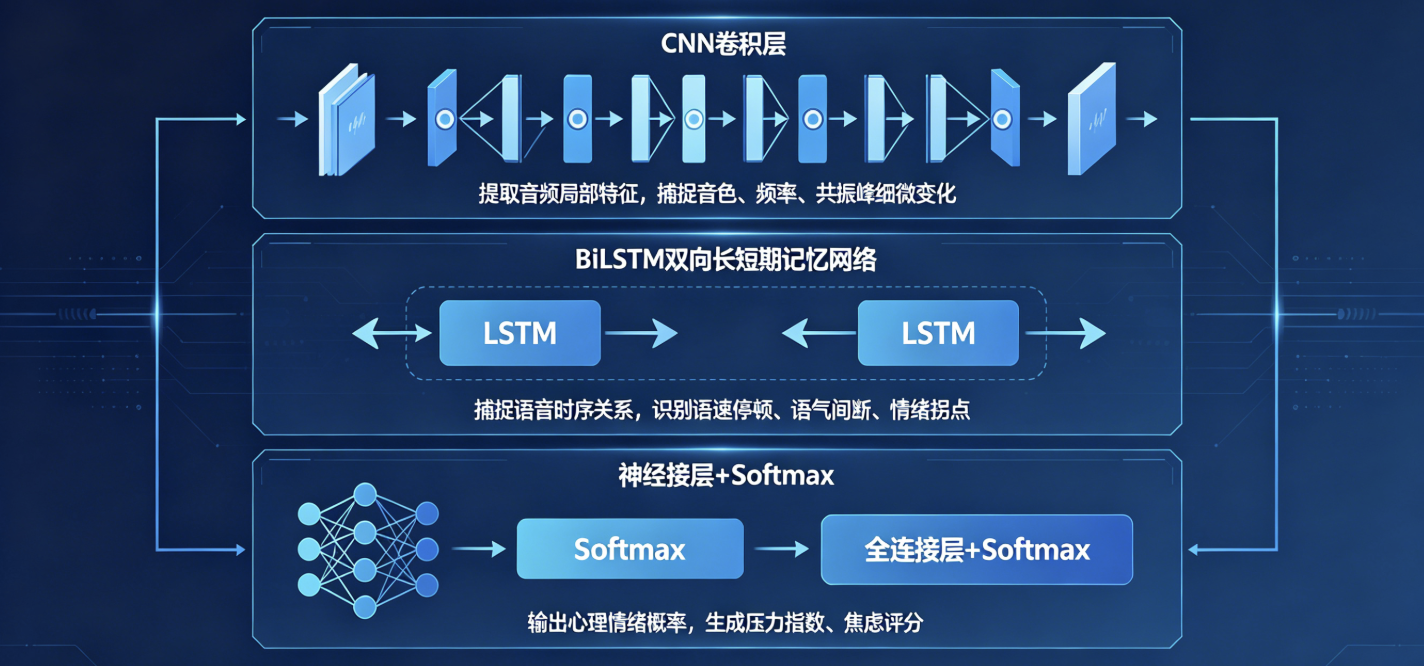
行业补充:单纯LSTM只能单向读取时序,BiLSTM可以双向读取语音前后逻辑,判断说话人语气压抑、停顿犹豫,非常适配心理人声分析。
三、代码实战:从零搭建SER语音情绪识别模型
3.1 环境依赖
# 安装依赖
# pip install librosa torch numpy matplotlib
import numpy as np
import librosa
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 屏蔽冗余警告
import warnings
warnings.filterwarnings("ignore")3.2 音频预处理
真实采集的人声带有环境噪音、电流声、呼吸声,必须预处理,否则模型准确率直接崩盘。
def audio_preprocess(audio_path, sr=16000, duration=3):
"""
语音预处理:重采样+截断补全+降噪+提取MFCC
:param audio_path: 音频文件路径
:param sr: 采样率 16000(人声最优采样)
:param duration: 固定音频时长3s
:return: mfcc特征矩阵
"""
# 加载音频
y, _ = librosa.load(audio_path, sr=sr)
# 固定音频长度
max_len = sr * duration
if len(y) < max_len:
y = np.pad(y, (0, max_len - len(y)), mode="constant")
else:
y = y[:max_len]
# 简单降噪:消除低频底噪
y = librosa.effects.preemphasis(y)
# 提取MFCC特征
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40)
return mfcc
# 特征可视化(CSDN图文展示必备)
def show_mfcc(mfcc_data):
plt.figure(figsize=(10,4))
librosa.display.specshow(mfcc_data, x_axis="time")
plt.colorbar()
plt.title("人声MFCC特征热力图 | AI心理语音分析")
plt.show()3.3 CNN+BiLSTM 融合模型搭建
class SER_Mental_Model(nn.Module):
def __init__(self, input_dim=40, num_classes=7):
super(SER_Mental_Model, self).__init__()
# CNN卷积层:提取局部声学特征
self.cnn = nn.Sequential(
nn.Conv1d(in_channels=input_dim, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool1d(2),
nn.Conv1d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool1d(2)
)
# BiLSTM双向时序捕捉
self.bilstm = nn.LSTM(
input_size=256,
hidden_size=128,
num_layers=2,
bidirectional=True,
batch_first=True,
dropout=0.3
)
# 分类输出层:7类心理情绪
self.fc = nn.Sequential(
nn.Linear(256, 128),
nn.Dropout(0.25),
nn.ReLU(),
nn.Linear(128, num_classes)
)
def forward(self, x):
# x:[batch,40,time]
x = self.cnn(x)
x = x.transpose(1, 2)
x, _ = self.bilstm(x)
# 提取双向最后一个时间步特征
x = x[:, -1, :]
out = self.fc(x)
return out3.4 情绪推理+心理评分封装
def mental_predict(audio_path):
# 情绪映射(心理系统专用标签)
emotion_dict = {
0:"平静健康",
1:"轻度紧张",
2:"高度焦虑",
3:"情绪压抑",
4:"心情低落",
5:"易怒烦躁",
6:"重度消极"
}
# 数据预处理
mfcc = audio_preprocess(audio_path)
mfcc = torch.tensor(mfcc).unsqueeze(0).float()
# 加载模型推理
model = SER_Mental_Model()
model.eval()
with torch.no_grad():
pred = model(mfcc)
pred_idx = torch.argmax(pred, dim=1).item()
score = round(float(torch.softmax(pred,dim=1)[0][pred_idx])*100,2)
print(f"【心理语音评估结果】")
print(f"情绪判定:{emotion_dict[pred_idx]}")
print(f"情绪置信度:{score}%")
# 压力换算
stress_level = int(pred_idx * 12.5)
print(f"心理压力指数:{stress_level}/100")
return emotion_dict[pred_idx],stress_level
# 调用示例
# mental_predict("test_voice.wav")四、运行解析 & 开发踩坑实录
4.1 代码运行说明
-
音频格式:推荐 wav、16k采样率、单声道,适配绝大多数采集麦克风;
-
音频时长:固定3s有效人声,剔除空白静音片段;
-
输出结果:情绪标签+压力分值,直接用于心理预警分级。
4.2 落地踩坑总结
-
环境噪声干扰严重 普通教室、办公室环境杂音大,必须加VAD人声检测+高通滤波,否则误判率飙升;
-
男女声频率差异 男女基频F0差距极大,模型必须做性别特征归一化,不然女性普遍判定焦虑;
-
普通话、方言适配问题 额外训练方言噪声库,不识别语义、只识别声学特征,规避方言干扰;
-
未成年人声线特殊性 学生变声期声线不稳定,需要单独做青少年人声数据集微调。
五、心理健康系统架构
5.1 系统核心模块
- 硬件配置:采用专业级心形指向性电容麦克风,信噪比≥70dB,频率响应范围50Hz-20kHz
- 降噪技术:结合硬件级声学隔噪与DSP数字降噪算法,有效抑制环境噪声(如空调声、键盘声等)
- 智能截取:基于VAD(语音活动检测)技术,实时识别有效语音段,过滤沉默间隔和咳嗽等非语义声音
- 应用场景:适用于心理咨询室、家庭卧室等相对安静环境,最佳拾音距离30-50cm
- 信号预处理流程:
- 人声分离:采用Demucs算法分离人声和背景音
- 降噪处理:应用谱减法结合Wiener滤波
- 预加重:一阶FIR滤波器(系数0.97)提升高频分量
- 分帧加窗:25ms帧长,10ms帧移,汉明窗
- 模型架构:
- CNN层:3层卷积(kernel=5/3/3,channel=64/128/256)+批归一化+ReLU
- BiLSTM层:2层双向LSTM(hidden_size=256)+注意力机制
- 输出层:softmax分类(抑郁/焦虑/正常等7个维度)
- 部署方案:
- 计算单元:NVIDIA Jetson AGX Orin(32GB)
- 推理速度:≤200ms/句(平均)
- 数据安全:AES-256加密存储,完全离线运行
- 风险评估标准:
- 低风险(蓝色):单项指标轻度异常,建议1周后复查
- 中风险(黄色):≥2项指标异常,生成周报推送咨询师
- 高风险(红色):出现自杀倾向关键词,触发即时电话预警
- 报告内容:
- 核心指标变化曲线(近30天)
- 声学特征雷达图(与常模对比)
- 结构化分析摘要(含置信度评分)
- 干预机制:
- 自动匹配心理咨询资源
- 推送定制化心理练习(如正呼吸引导音频)
- 紧急联系人联动(需用户预先授权)
5.2 私有化部署说明
我们全部采用本地CPU推理,无需云端算力,数据全程脱敏保存,完全符合教育、医疗数据安全规范。
六、总结 & 行业思考
很多人把AI心理判定当成“玄学”,其实本质就是声学特征提取+时序深度学习。语音情感识别不靠听懂你说什么,而是捕捉人类无法自主控制的声带、频率、气息变化。
在我看来,AI不是用来替代心理咨询师,而是做初筛、预警、筛查,把海量人群中高风险的人群精准筛选出来,降低人工成本、规避漏判风险。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)