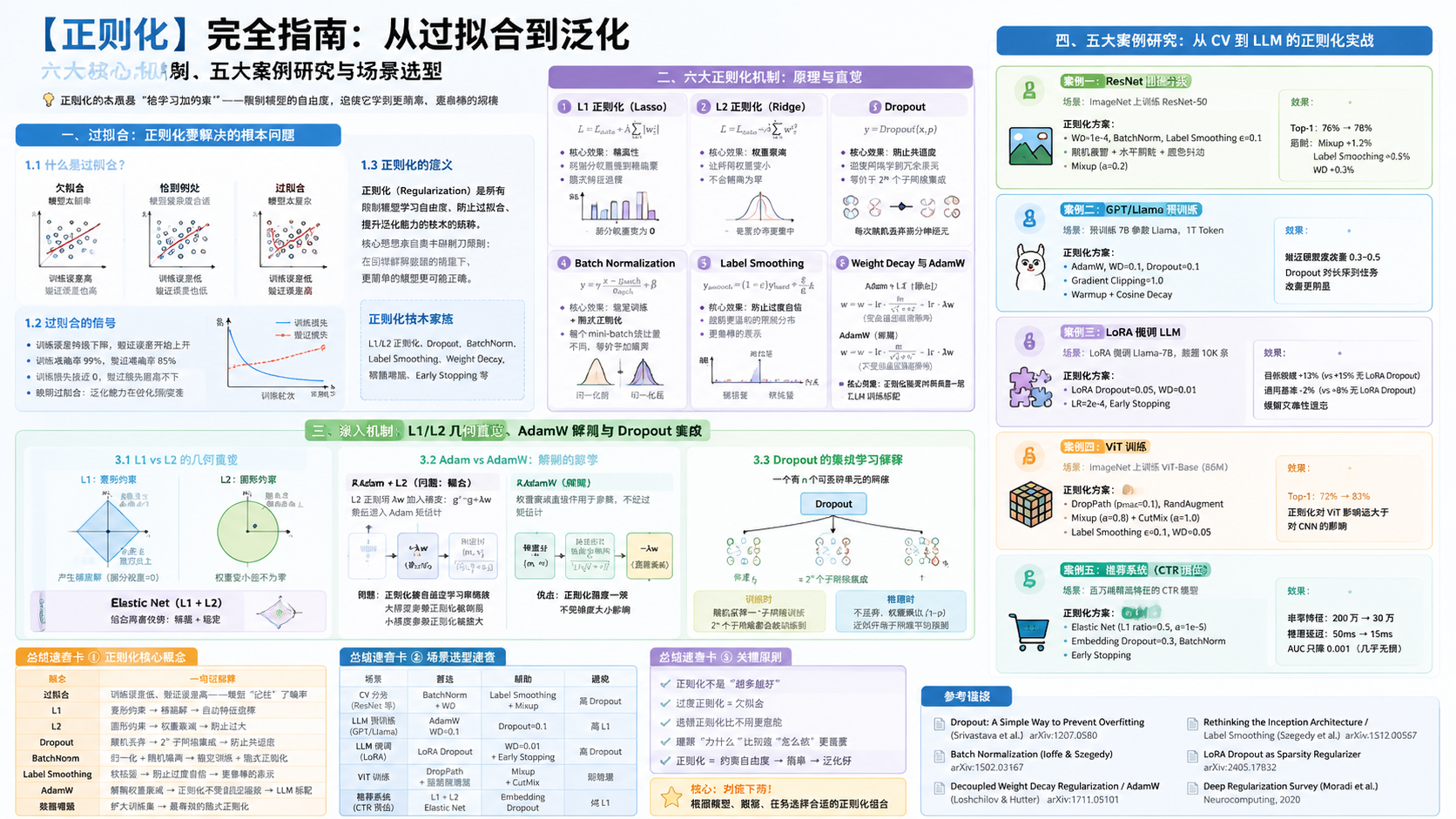
【正则化】完全指南:从过拟合到泛化——六大核心机制、五大案例研究与场景选型
【正则化】完全指南:从过拟合到泛化——六大核心机制、五大案例研究与场景选型
写在前面:正则化是深度学习中最容易被忽视、却最影响模型质量的技术。很多人把正则化等同于"加个 Dropout"或"设个 weight_decay=0.01"——这是远远不够的。L1 为什么产生稀疏解?L2 的几何直觉是什么?AdamW 为什么比 Adam+L2 更好?Dropout 为什么等价于集成学习?BatchNorm 的正则化效果从何而来?Label Smoothing 为什么能防止过度自信?LoRA 微调时 Dropout 怎么用?今天,我们从机制到案例,彻底拆解正则化。
📑 文章目录
- 🎯 一、过拟合:正则化要解决的根本问题
- ⚙️ 二、六大正则化机制:原理与直觉
- 🔬 三、深入机制:L1/L2 几何直觉、AdamW 解耦与 Dropout 集成
- 📊 四、五大案例研究:从 CV 到 LLM 的正则化实战
🎯 一、过拟合:正则化要解决的根本问题
1.1 什么是过拟合?
机器学习的核心挑战不是"让模型在训练集上表现好"——这很容易,加参数就行——而是"让模型在未见数据上表现好",即泛化能力。
欠拟合(Underfitting)。模型太简单,连训练集都学不好。训练误差高,验证误差也高。解决方案:增加模型容量、减少正则化、训练更久。
过拟合(Overfitting)。模型太复杂,把训练集的噪声也学了进去。训练误差低,但验证误差高——模型"记住"了训练数据,但没有学到真正的规律。过拟合是深度学习中最常见的问题——因为现代神经网络有数百万到数十亿参数,远超训练数据所能约束的范围。
恰到好处(Just Right)。模型复杂度与数据量匹配,训练误差和验证误差都低,且差距小。正则化的目标就是让模型从"过拟合"走向"恰到好处"。
1.2 过拟合的信号
如何判断模型是否过拟合?关键信号是训练误差和验证误差的差距:
- 训练误差持续下降,验证误差开始上升——经典的过拟合曲线
- 训练准确率 99%,验证准确率 85%——14% 的泛化差距
- 训练损失接近 0,验证损失居高不下——模型在"背诵"而非"理解"
深度学习中的过拟合还有一个特殊现象:晚期过拟合(Late-stage Overfitting)。模型在训练初期学到了泛化规律,但在继续优化中逐渐"遗忘"这些规律,转而拟合训练集的噪声。这意味着即使训练损失还在下降,泛化能力可能已经在恶化。
1.3 正则化的定义
**正则化(Regularization)**是所有限制模型学习自由度、防止过拟合、提升泛化能力的技术的统称。它的核心思想来自奥卡姆剃刀原则:在同样解释数据的前提下,更简单的模型更可能正确。
正则化不是某一种具体技术,而是一个技术家族——L1/L2 正则化、Dropout、BatchNorm、Label Smoothing、Weight Decay、数据增强、Early Stopping 等都是正则化的具体实现。
⚙️ 二、六大正则化机制:原理与直觉

2.1 L1 正则化(Lasso)
L1 正则化在损失函数中加入权重绝对值之和:L_total = L_data + λΣ|w_i|。
核心效果:稀疏性。L1 倾向于将部分权重精确地推到零——这不是"接近零",而是"等于零"。这意味着模型自动忽略不重要的特征,实现了隐式特征选择。
直觉理解:L1 的梯度是常数(±λ),无论权重大小,正则化的"推力"一样大。当权重接近零时,这个推力足以将权重推过零点,变成精确的零。
适用场景:高维稀疏数据(如推荐系统的用户-物品矩阵)、需要特征选择的场景、模型可解释性要求高的场景。
2.2 L2 正则化(Ridge / Weight Decay)
L2 正则化在损失函数中加入权重平方和:L_total = L_data + λΣw_i²。
核心效果:权重衰减。L2 倾向于让所有权重变小,但不会精确为零。它惩罚大权重,鼓励权重分布均匀且较小。
直觉理解:L2 的梯度与权重大小成正比(2λw_i)。权重越大,正则化的"推力"越大;权重接近零时,推力也接近零。所以 L2 不会把权重推到精确的零——只是让它们变小。
适用场景:几乎所有深度学习模型都默认使用 L2(通过 Weight Decay)。它是"万能正则化"——不会出错,但也不够强。
2.3 Dropout
Dropout 在训练时随机将一部分神经元的输出设为零:y = Dropout(x, p),其中 p 是丢弃概率。
核心效果:防止共适应。Dropout 强制每个神经元不能依赖特定的其他神经元——因为它们随时可能被丢弃。这迫使网络学到冗余表示——同一条信息被编码在多个神经元中。
集成学习解释:每次 Dropout 都创建一个不同的"子网络"。一个有 n 个神经元的网络,Dropout 相当于训练了 2^n 个子网络的集成。推理时不丢弃,但将权重乘以 (1-p) 来近似集成的平均效果。
适用场景:全连接层标配(p=0.5)、Transformer 注意力层(p=0.1)、ViT 的 DropPath。但注意:BatchNorm 和 Dropout 一起用时可能冲突——BatchNorm 的统计量会被 Dropout 扰乱。
2.4 Batch Normalization
BatchNorm 对每个 mini-batch 的激活值做归一化:y = γ * (x - μ_batch) / σ_batch + β。
核心效果:稳定训练 + 隐式正则化。BatchNorm 的主要作用是解决内部协变量偏移(Internal Covariate Shift)——让每层的输入分布稳定,加速训练。但它也有隐式正则化效果:每个 mini-batch 的均值和方差都不同,这种随机性相当于给激活值加了噪声,起到类似 Dropout 的效果。
适用场景:CV 领域标配(CNN + BatchNorm)。但 Transformer 用 LayerNorm 而非 BatchNorm——因为序列长度不同,batch 统计量不稳定。
2.5 Label Smoothing
Label Smoothing 将硬标签 [0, 1] 变成软标签 [ε/K, 1-ε+ε/K]:y_smooth = (1-ε) * y_hard + ε/K。
核心效果:防止过度自信。没有 Label Smoothing 时,模型会追求 100% 的预测概率——这导致 logits 极大,梯度极端,泛化变差。Label Smoothing 告诉模型"不要 100% 确定",鼓励更温和的预测分布。
直觉理解:假设 ε=0.1,10 类分类。原来正确类别的目标是 1.0,现在是 0.9 + 0.01 = 0.91;原来错误类别的目标是 0.0,现在是 0.01。模型不再追求极端概率,学到的表示更鲁棒。
适用场景:几乎所有分类任务的标配。ImageNet 训练用 ε=0.1,LLM 训练也常用 Label Smoothing。
2.6 Weight Decay 与 AdamW
Weight Decay(权重衰减)在每次参数更新时缩小权重:w = w - lr * grad - lr * λ * w。
Adam + L2 的问题:当 L2 正则化项加入梯度后,它会被 Adam 的自适应学习率缩放——大梯度参数的正则化被削弱,小梯度参数的正则化被放大,效果不均匀。
AdamW 的解耦:AdamW 将权重衰减从梯度更新中解耦出来,直接作用于参数:w = w - lr * m/(√v+ε) - lr * λ * w。正则化强度对所有参数一致,不受自适应学习率影响。Loshchilov 和 Hutter 在 2019 年的论文中证明,AdamW 在 LLM 训练中显著优于 Adam+L2。
适用场景:LLM 训练标配。GPT、Llama、Mistral 等模型都使用 AdamW + Weight Decay。典型值:预训练 WD=0.1,微调 WD=0.01。
🔬 三、深入机制:L1/L2 几何直觉、AdamW 解耦与 Dropout 集成
3.1 L1 vs L2 的几何直觉
L1 和 L2 正则化效果差异的根源在于约束区域的形状。
L1 的菱形约束。L1 的约束区域是 |w₁| + |w₂| ≤ t,在二维空间中是一个菱形。菱形的顶点在坐标轴上——这意味着最优点容易落在顶点,即某个权重为零。这就是 L1 产生稀疏解的几何原因:菱形的"尖角"把最优点"吸"到了坐标轴上。
L2 的圆形约束。L2 的约束区域是 w₁² + w₂² ≤ t,在二维空间中是一个圆。圆形没有尖角,最优点很少落在坐标轴上——权重变小但不为零。L2 让所有权重均匀缩小,但不会产生稀疏性。
Elastic Net(L1 + L2)。结合两者的优势:L1 产生稀疏性,L2 稳定稀疏解。约束区域是菱形和圆形的叠加——既有"尖角"吸引最优点到轴上,又有圆形的平滑性防止解不稳定。
3.2 Adam vs AdamW:解耦的数学
Adam 的参数更新公式:w = w - lr * m / (√v + ε),其中 m 是一阶矩估计(动量),v 是二阶矩估计(梯度的平方的指数移动平均)。
Adam + L2 的问题:L2 正则化项 λw 被加入梯度 g’ = g + λw,然后进入 Adam 的矩估计。关键问题:λw 被自适应学习率 1/(√v + ε) 缩放了。对于梯度大的参数,v 大,自适应学习率小,正则化效果被削弱;对于梯度小的参数,v 小,自适应学习率大,正则化效果被放大。这种不均匀的正则化在 LLM 训练中尤其有害——因为不同参数的梯度尺度差异极大。
AdamW 的解耦:权重衰减直接作用于参数,不经过矩估计:w = w - lr * m/(√v+ε) - lr * λ * w。正则化强度对所有参数一致,不受梯度大小影响。这就是为什么 Loshchilov 和 Hutter 称之为"解耦权重衰减"(Decoupled Weight Decay)。
3.3 Dropout 的集成学习解释
Dropout 的效果可以用集成学习来理解。一个有 n 个可丢弃单元的网络,Dropout 相当于同时训练 2^n 个不同的子网络——每个子网络对应一种丢弃组合。
训练时:每次前向传播随机采样一个子网络,只用这个子网络计算损失和梯度。由于采样是随机的,2^n 个子网络都会被训练到。
推理时:不丢弃,但将权重乘以 (1-p) 来近似所有子网络的平均预测。这个近似叫做"权重缩放推断"(Weight Scaling Inference Rule),它等价于几何平均所有子网络的预测。
为什么有效:集成学习的一个经典结论是,多个模型的平均预测通常比任何单个模型更好——因为不同模型的误差会相互抵消。Dropout 用极低的代价(一次只训练一个子网络)近似了 2^n 个模型的集成。
📊 四、五大案例研究:从 CV 到 LLM 的正则化实战

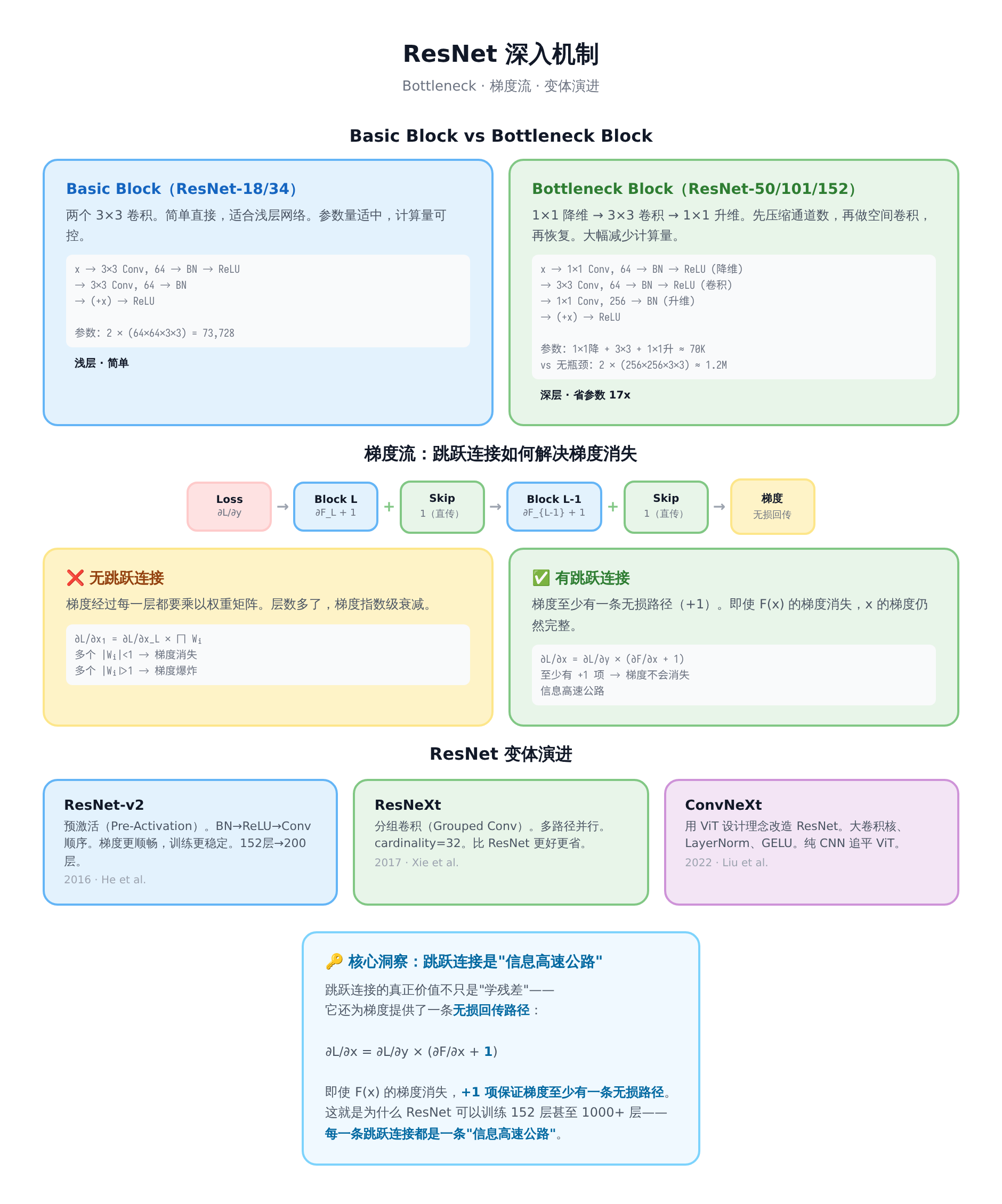
案例一:ResNet 图像分类——BatchNorm + Weight Decay + Label Smoothing 的组合拳
场景:在 ImageNet 上训练 ResNet-50,目标是 Top-1 准确率最大化。
正则化方案:
- Weight Decay = 1e-4(L2 正则化,通过 SGD 实现)
- BatchNorm(每个卷积层后)
- Label Smoothing ε = 0.1
- 数据增强:随机裁剪 + 水平翻转 + 颜色抖动
- Mixup(α=0.2):两张图像的凸组合
效果:ResNet-50 基线(无 Label Smoothing、无 Mixup)Top-1 约 76%;加入 Label Smoothing + Mixup 后提升到约 78%。单独看每个技术的贡献:Mixup +1.2%,Label Smoothing +0.5%,Weight Decay +0.3%。
关键洞察:CV 分类任务中,数据增强是最有效的正则化——因为它直接扩大了训练集。BatchNorm 是"免费"的正则化——你本来就要用它来加速训练。Label Smoothing 是"低成本高回报"的技巧——几乎不增加计算量,但稳定提升 0.3-0.5%。
案例二:GPT/Llama 预训练——AdamW + Weight Decay + Dropout 的 LLM 标配
场景:预训练一个 7B 参数的 Llama 模型,1T Token 训练数据。
正则化方案:
- AdamW,Weight Decay = 0.1(注意:预训练用较大的 WD)
- Dropout = 0.1(注意力层和 FFN 层)
- Gradient Clipping = 1.0(间接正则化,防止梯度爆炸)
- 学习率 Warmup + Cosine Decay(间接正则化,控制训练动态)
效果:Llama 论文中的消融实验显示,Weight Decay = 0.1 相比 WD = 0 在验证集困惑度上改善约 0.3-0.5(绝对值)。Dropout = 0.1 相比 Dropout = 0 在长序列任务上改善更明显。
关键洞察:LLM 预训练中,AdamW + WD=0.1 是标配,不是可选。原因在于 LLM 的参数量远大于数据量能约束的范围——没有 Weight Decay,权重会无限增长,导致数值不稳定和泛化变差。Dropout 在预训练中通常设为 0.1(较小),因为预训练数据量巨大,过拟合风险相对较低。
案例三:LoRA 微调 LLM——LoRA Dropout 防止灾难性遗忘
场景:用 LoRA 在特定领域数据上微调 Llama-7B,训练数据只有 10K 条。
正则化方案:
- LoRA rank = 16,alpha = 32
- LoRA Dropout = 0.05(在 LoRA 的 A 矩阵上加 Dropout)
- Weight Decay = 0.01(比预训练小 10 倍)
- 学习率 = 2e-4(比预训练大,但 epoch 少)
- Early Stopping(验证集损失连续 3 个 epoch 不降就停)
效果:没有 LoRA Dropout 时,微调模型在目标领域的准确率提升了 15%,但在通用基准上下降了 8%(灾难性遗忘)。加入 LoRA Dropout = 0.05 后,目标领域准确率提升 13%(略低),通用基准只下降 2%(大幅缓解遗忘)。
关键洞察:LoRA 微调时数据量小,过拟合风险极高。LoRA Dropout 是专门为低秩适配设计的正则化——它在低秩矩阵 BA 上加 Dropout,随机丢弃部分适配能力,迫使 LoRA 学到更鲁棒的调整。Weight Decay 也要比预训练小——因为微调的参数少,过强的正则化会抵消微调的效果。
案例四:ViT 训练——DropPath + 强数据增强的"暴力正则化"
场景:在 ImageNet 上训练 ViT-Base,86M 参数。
正则化方案:
- DropPath(Stochastic Depth):随深度线性增加,最大 p=0.1
- RandAugment:自动数据增强策略
- Mixup(α=0.8):比 ResNet 更强的混合
- CutMix(α=1.0):图像块级别的混合
- Label Smoothing ε = 0.1
- Weight Decay = 0.05
- Replay Buffer:混合真实标签和 Mixup 标签
效果:ViT-Base 不加强正则化时,ImageNet Top-1 只有约 72%(远低于 ResNet-50 的 76%)。加入上述"暴力正则化"组合后,Top-1 跳升到约 83%。正则化对 ViT 的影响远大于对 CNN 的影响——因为 ViT 没有卷积的归纳偏置,更容易过拟合。
关键洞察:ViT 是"正则化依赖型"架构——没有强正则化,ViT 甚至不如 ResNet。DropPath 是 ViT 的关键正则化——它随机丢弃整条残差路径,迫使每层都能独立产生有用表示。强数据增强(RandAugment + Mixup + CutMix 三连)是 ViT 训练的另一个关键——数据量不够时,ViT 需要靠增强来"伪造"更多数据。
案例五:推荐系统——L1 + L2 的 Elastic Net 实战
场景:训练一个 CTR(点击率)预估模型,输入是百万维的稀疏特征(用户 ID、物品 ID、交叉特征)。
正则化方案:
- Elastic Net:L1 ratio = 0.5,α = 1e-5
- Embedding Dropout = 0.3(随机丢弃整个特征 embedding)
- BatchNorm(在 Dense 层后)
- Early Stopping(验证集 AUC 连续 2 天不升就停)
效果:纯 L2 正则化时,模型有 200 万非零特征,推理延迟 50ms。加入 L1 后,非零特征降到 30 万(85% 稀疏),推理延迟降到 15ms,AUC 只降了 0.001(几乎无损)。
关键洞察:推荐系统中L1 的稀疏性是关键——百万维特征中大部分是噪声,L1 自动选择最重要的特征。Elastic Net(L1+L2)比纯 L1 更稳定——纯 L1 在高度相关特征中会随机选一个,Elastic Net 会保留一组相关特征。Embedding Dropout 是推荐系统特有的正则化——它随机丢弃整个特征的 embedding,迫使模型不依赖任何单一特征。
🎁 总结速查卡
正则化核心概念
| 概念 | 一句话解释 |
|---|---|
| 过拟合 | 训练误差低、验证误差高——模型"记住"了噪声 |
| L1 | 菱形约束 → 稀疏解 → 自动特征选择 |
| L2 | 圆形约束 → 权重衰减 → 防止过大 |
| Dropout | 随机丢弃 → 2^n 子网络集成 → 防止共适应 |
| BatchNorm | 归一化 + 随机噪声 → 稳定训练 + 隐式正则化 |
| Label Smoothing | 软标签 → 防止过度自信 → 更鲁棒的表示 |
| AdamW | 解耦权重衰减 → 正则化不受自适应缩放 → LLM 标配 |
| 数据增强 | 扩大训练集 → 最有效的隐式正则化 |
场景选型速查
| 场景 | 首选 | 辅助 | 避免 |
|---|---|---|---|
| CV 分类 | BatchNorm + WD | Label Smoothing + Mixup | 高 Dropout |
| LLM 预训练 | AdamW WD=0.1 | Dropout=0.1 | 高 L1 |
| LLM 微调 | LoRA Dropout | WD=0.01 + Early Stopping | 高 Dropout |
| ViT | DropPath + 强数据增强 | Mixup + CutMix | 弱增强 |
| 推荐系统 | L1 + L2 Elastic Net | Embedding Dropout | 纯 L1 |
一句话总结
正则化的本质是"给学习加约束"——限制模型的自由度,迫使它学到更简单、更鲁棒的规律。六大核心机制各有侧重:L1 产生稀疏(菱形约束)、L2 权重衰减(圆形约束)、Dropout 防止共适应(集成学习)、BatchNorm 稳定训练+隐式正则化、Label Smoothing 防止过度自信、AdamW 解耦权重衰减(LLM 标配)。五大案例研究揭示了关键实战原则:CV 分类中数据增强最有效、LLM 预训练中 AdamW+WD=0.1 是标配、LoRA 微调中 LoRA Dropout 防灾难性遗忘、ViT 训练需要"暴力正则化"组合、推荐系统中 L1 稀疏性是关键。正则化不是"越多越好",而是"对症下药"——过度正则化 = 欠拟合,选错正则化比不用正则化更危险。理解"为什么"比知道"怎么做"更重要。
参考链接:
- Dropout: A Simple Way to Prevent Overfitting (Srivastava et al.)
- Batch Normalization (Ioffe & Szegedy)
- Decoupled Weight Decay Regularization / AdamW (Loshchilov & Hutter)
- Rethinking the Inception Architecture / Label Smoothing (Szegedy et al.)
- LoRA Dropout as Sparsity Regularizer
- Deep Regularization Survey (Moradi et al.)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)