深入Redis SCAN源码:反向迭代算法的设计与实现
写在文章开头
本文是笔者早期传统编程阶段所整理的一篇关于redis scan指令的解读文章。由于算法设计的巧妙以及当时个人认知不足,导致当时的解读表述不足以让读者正确了解该指令的设计理念并学习内化。
所以,笔者借着近期传统编程训练模式之机,以此文作为论证,将传统编程调测技巧与AI深度分析相结合,给出scan指令深度教程和编程最佳实践。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 ·
https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
前置步骤说明
redis编译调试环境配置
大型开源项目设计架构是非常复杂的,很多情况下我们无法通过肉眼调试的方式将流程梳理清楚,所以当我们需要阅读源码的时候,首要做的就是将源码环境拉下来并运行,以确保一个可实际观测理解,精确调测梳理完成研发任务。
我相信大部分人都是因为这一步而被劝退,原因很简单: 人是有惰性的
搭建环境时或多或少会因为各种未知的报错和繁琐的配置,笔者还是坚定的认为既有阶段,我们这些常人所遇到的问题,势必有最终的答案,我们还是要学会沉下心来,检索推测不断的实践,然后复盘内化。
以本文为例,笔者是一名主力开发语言为Java的软件从业者,对于c语言的基础也仅仅是停留在大学阶段,所以对于企业级c语言项目的了解也不是特别熟悉,在正式阅读redis源码时笔者也是详细的阅读了redis官网中对于源码环境的说明。
如下图所示,这是笔者近期阅读的redis 3.2.8的源码的readme文档,可以看到该文档中详尽地介绍redis项目拉取、编译、启动运行的所有步骤,我们完全可以沉下心去阅读了解大体步骤后,结合网上的一些关于c语言调试的开发工具得出一套综合的环境搭建过程将项目跑起来:
scan指令快速扫盲
学习的前提是目标,以本文为例即阅读源码一定要清晰明确了解:
- 阅读的源码段解决问题
- 源码对应的功能如何使用
一切学习的前提都需要具备明确的输入和输出,只有明确自己的why,才能进一步execute,从而完成知识点之间的关联,构建一次完整的学习闭环,提升自己的学习能力和知识储备。
回过头来,本次要了解的就是redis中scan指令的实现细节,在正式的了解之前,笔者对该指令做了一定的了解,对其作用、输入输出、运用场景、使用注意事项等都有了深入的扫盲,以确保读者能够连贯的阅读这篇文章并加以学习内化。
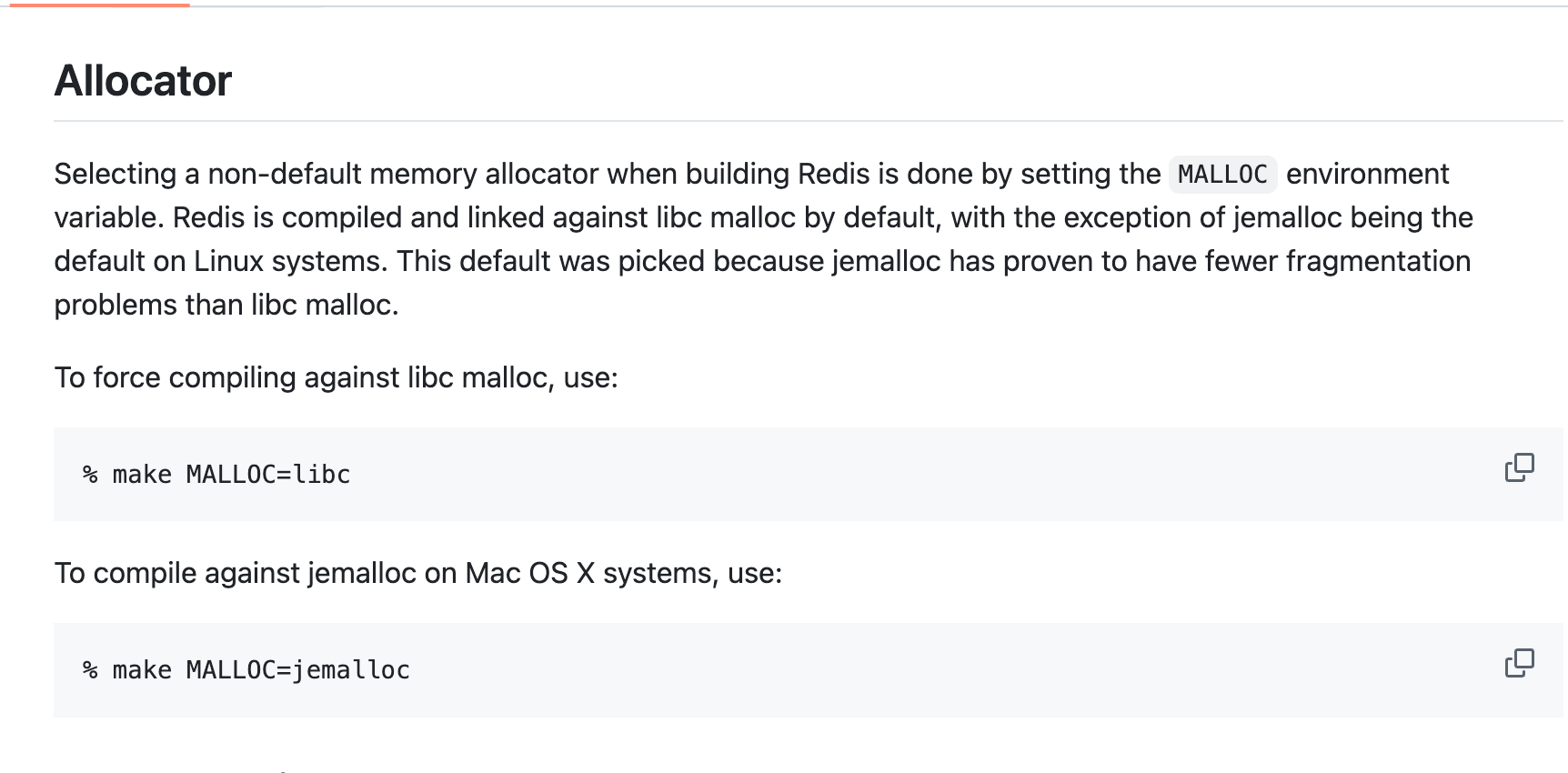
本质上,scan指令就是针对当前客户端操作的指定的redis内存库(默认是db 0),默认我们执行scan 0 进行迭代,对应的执行和工作流程为:
- 基于游标定位到对应的redis字典底层的桶也称bucket,将当前bucket中的元素返回,默认情况下提示返回10个(实际可能多一些)
- 返回下一次的游标值n
- 客户端再次通过scan n进行下一轮的迭代扫描
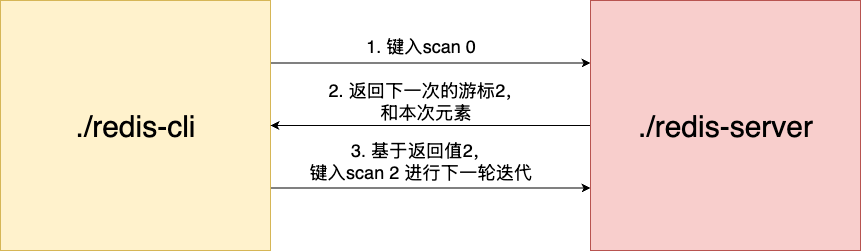
例如,笔者当前db 0库存在四个元素a、b、c、d,执行scan 0就会输出返回所有的元素,同时给出下一次游标0。需要注意的是,这里一次性返回全部元素是字典较小且元素分布恰好被单次扫描覆盖的特殊情况,并非普遍行为——通常 scan 需要多次迭代才能遍历全库。
127.0.0.1:6379> scan 0
1) "0"
2) 1) "b"
2) "c"
3) "a"
4) "d"
这里笔者也特殊说明一下,游标0的含义,我们都知道使用scan指令第一次指定的游标值就是0,redis为了让用户感知游标迭代完结,同样采用游标0作为终止标识,告知用户已完成迭代闭环。
此外,scan指令不保证返回结果的唯一性,即在迭代过程中可能会返回重复元素。这在字典缩容场景下尤为常见,因此客户端需要对scan返回的结果进行去重处理。
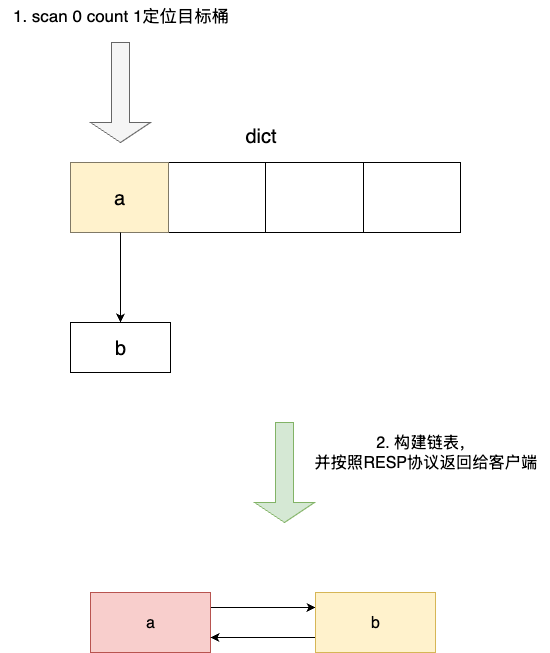
scan还支持优先count输出,如下所示,通过count指定参数值为1,即提示redis输出1个元素,对应输出结果如下,可以看到redis竟意外的输出两个元素?是bug嘛?
127.0.0.1:6379> scan 0 count 1
1) "2"
2) 1) "b"
2) "c"
软件系统的设计是一门在性能和标准之间权衡的艺术,以表象直接定义bug是一种非常主观且武断的做法。redis底层采用自定义字典存储键值对,并通过拉链法解决散列冲突。
由此就出现上述的问题,假设我们指定scan的游标为0,定位到了桶0,与之对应存在2个元素,dictScan 会将桶中所有元素写入链表,而 count 检测(以及 maxiterations 限制)是在 bucket 扫描完成之后的逻辑判断。源码中 maxiterations 默认值为 count * 10,用于防止单次 scan 耗时过长。这就使得条件 count 为 1 时,单次 dictScan 调用收集到 2 个元素,count 校验发现已超额,循环终止,输出结果却是 2 个:
实际上redis也可以杜绝这一点,即看bucket维度的扫荡中加一个count过滤就好了,但这种做法会增加实现上的复杂度。原因我也可以通过不同实现维度的评估推导:
- 基于bucket维度扫描,每次扫荡都能完成全桶扫描,下一次扫荡可直接从全新的游标开始迭代
- 基于bucket维度上进行count过滤,虽然保证count的准确性,却需要server端进行更细粒度的游标控制,即返回的游标要精确到桶内部的某个键值对,这一点回报的性价比对于一个非要求高精确性的scan来说是得不偿失的。
这也是为什么,笔者一直认为redis是程序设计艺术的典范,它很好的在业务和软件程序设计上做了非常出色的折中。
scan指令也支持match参数,即支持模糊匹配,例如笔者希望找到c开头的key,对应的查询指令和输出指令如下所示:
127.0.0.1:6379> scan 0 match c* count 10000
1) "0"
2) 1) "c"
详解scan指令的设计与实现
scan指令执行流程
有了上述的使用经验的基础,我们就可以正式阅读和分析源码了,首先自然是定位到指令核心实现的入口,对应笔者本次要阅读了解的源码位置即db.c下的scanCommand,因为知道scan的作用,所以我们可以宏观的介绍一下源码了解其对于单库扫描的整体流程:
- 解析scan参数:如果有count和match则解析这些参数后面的值,并校验合法性。
- 定位到客户端使用的数据库,并基于游标开始获取元素,将结果链表中
- 如果有match参数则基于步骤2的链表完成过滤
- 返回有效元素和下一次的迭代的游标
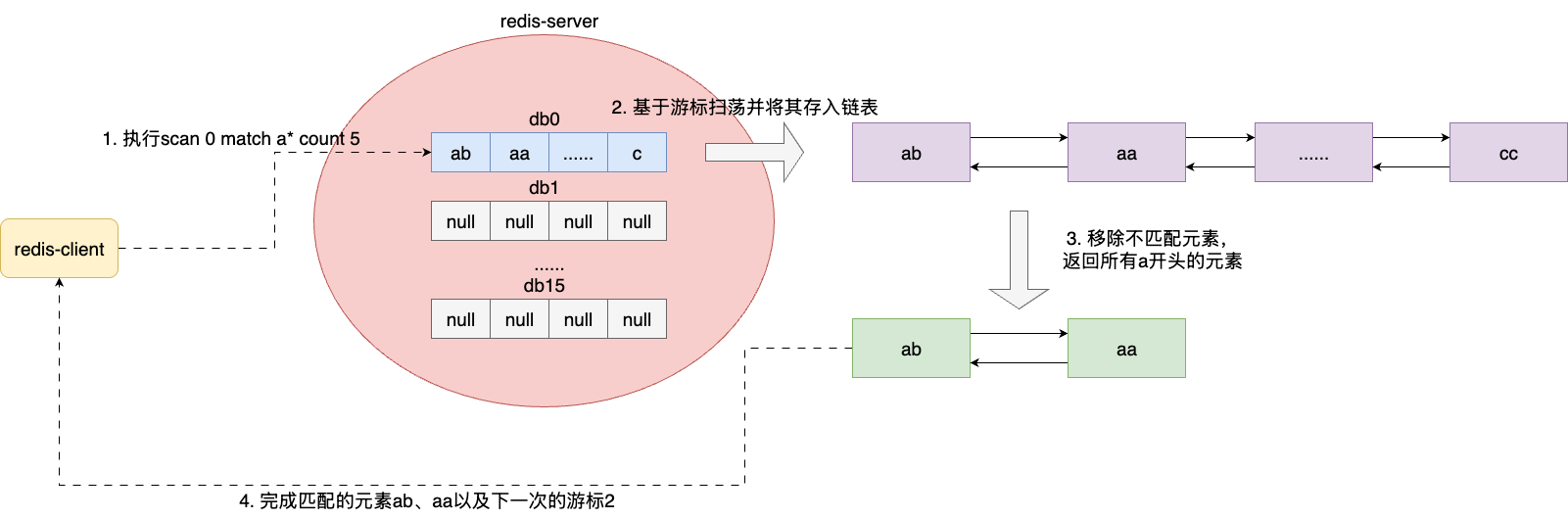
例如,我们键入scan 0 match a* count 5,对应的执行步骤为:
- 解析游标参数有效性,感知到是无符号整数0,返回成功
- 判断count和match参数是否存在,若存在则按需解析构造参数
- 基于高位优先迭代算法,到bucket中获取元素,例如:本次迭代在桶0拿到ab、aa、cc等
- 按照match匹配过滤出aa、ab
- 返回输出元素,并告知下一次迭代的游标为2
我们给出scan指令对应源代码实现入口,可以看到拿到参数的第一步就是调用parseScanCursorOrReply,并传入第一个参数即游标,查看参数有效性。然后在调用scanGenericCommand执行后续迭代步骤:
void scanCommand(client *c) {
unsigned long cursor;
//判断是否可以转为无符号整数,如果不行则直接返回错误
if (parseScanCursorOrReply(c,c->argv[1],&cursor) == C_ERR) return;
scanGenericCommand(c,NULL,cursor);
}
继续步入scanGenericCommand 即可看到上述概括的逻辑,即:
- 解析count或者match参数值
- 基于游标定位bucket解析元素存入链表中
- 基于match表达式过滤有效元素
- 返回下一个游标Cursor和元素
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
int i, j;
//创建初始化链表
list *keys = listCreate();
listNode *node, *nextnode;
//默认情况下count取10个
long count = 10;
sds pat = NULL;
int patlen = 0, use_pattern = 0;
dict *ht;
/* Object must be NULL (to iterate keys names), or the type of the object
* must be Set, Sorted Set, or Hash. */
serverAssert(o == NULL || o->type == OBJ_SET || o->type == OBJ_HASH ||
o->type == OBJ_ZSET);
//默认情况下是为2的,因为默认传入的obj是空的
i = (o == NULL) ? 2 : 3; /* Skip the key argument if needed. */
//默认情况下,从索引2开始参数解析
while (i < c->argc) {
//代表当前参数索引到总参数个数的剩余参数个数
j = c->argc - i;
//查看是否为count然后转换值存入count变量中,若报错直接进入goto语句块做后置的清理工作
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
//解析count参数
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {
//......
//解析match参数
} else {
addReply(c,shared.syntaxerr);
goto cleanup;
}
}
//......
if (ht) {
//......
do {
//扫描元素存入链表
cursor = dictScan(ht, cursor, scanCallback, privdata);
} while (cursor &&
maxiterations-- &&
listLength(keys) < (unsigned long)count);//游标非0且还在最大尝试次数且链表未达到要求的count就可以继续循环
} else if (o->type == OBJ_SET) {
//.......
} else if (o->type == OBJ_HASH || o->type == OBJ_ZSET) {
//.......
} else {
serverPanic("Not handled encoding in SCAN.");
}
//基于match过滤有效元素
node = listFirst(keys);
while (node) {
//......
}
//返回下一次的游标和结果集
//说明长度为2
addReplyMultiBulkLen(c, 2);
//告知下一次的游标的值
addReplyBulkLongLong(c,cursor);
//告知链表的长度
addReplyMultiBulkLen(c, listLength(keys));
//从头开始遍历链表
while ((node = listFirst(keys)) != NULL) {
robj *kobj = listNodeValue(node);
addReplyBulk(c, kobj);
decrRefCount(kobj);
listDelNode(keys, node);
}
//......
}
游标参数解析
明确宏观的执行流程之后,我们逐步细化拆解scan的每一个核心步骤,先是游标解析,逻辑比较简单,将传入的robj也就是游标数值对象传入,再调用strtoul查看是否可以正确转为无符号整数,若失败则直接响应invalid cursor 异常:
int parseScanCursorOrReply(client *c, robj *o, unsigned long *cursor) {
char *eptr;
errno = 0;
/**
* 通过strtoul将o对象的ptr成员转换为无符号长整数存储在cursor中,若失败则直接输出异常
*/
*cursor = strtoul(o->ptr, &eptr, 10);
if (isspace(((char*)o->ptr)[0]) || eptr[0] != '\0' || errno == ERANGE)
{
addReplyError(c, "invalid cursor");
return C_ERR;
}
return C_OK;
}
参数解析
有了宏观的流程的基础之后,我们就可以针对性的去了解细节,上文中我们看到scan指令的首要核心步骤是解析参数,对应的就是基于索引的迭代,这里我们也可以看到redis设计者在这种细节上的优化,对于一般的开发者而言,拿到scan match count这套组合参数之后,一般都是采用顺序遍历的方式进行参数解析,即顺序遍历:
- 看到match解析match后面的参数
- 看到count解析count后面跟随的参数
而redis在循环迭代这方面就有了微观的操作,直接从索引2开始(scan游标后面的值),查看当前字符串是否是match,如果是则直接解析其参数并验证合法性,然后索引直接+2直接尝试去解析count的值:
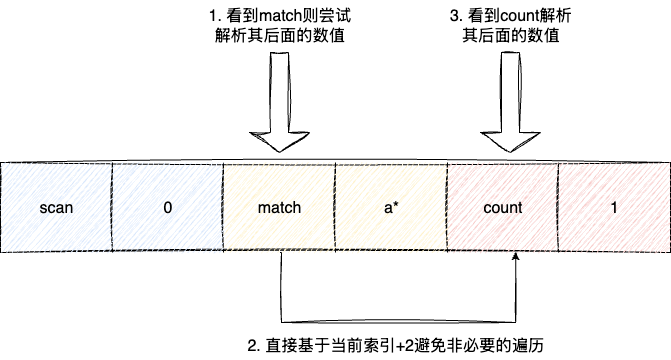
同时参数解析阶段,也考虑到用户不规范的用法,即match后面直接跟个*导致基于全库扫荡的数据执行了过滤逻辑,进而造成非必要的耗时,所以redis在参数解析阶段,也会判断match后面的值是否是*,如果不是才执行过滤匹配。
对应的我们给出参数解析这段代码实现的细节,读者可以基于笔者的说法自行参阅了解一下:
//默认情况下,从索引2开始参数解析
while (i < c->argc) {
//计算剩余参数的数量
j = c->argc - i;
//查看是否为count然后转换值存入count中,若报错或j小于2,则说明剩余参数不足两个无法凑成一对,直接进入goto语句块做后置的清理工作
if (!strcasecmp(c->argv[i]->ptr, "count") && j >= 2) {
if (getLongFromObjectOrReply(c, c->argv[i+1], &count, NULL)
!= C_OK)
{
goto cleanup;
}
if (count < 1) {
addReply(c,shared.syntaxerr);
goto cleanup;
}
//直接跳两步,避免非必要的遍历
i += 2;
} else if (!strcasecmp(c->argv[i]->ptr, "match") && j >= 2) {//如果参数是match则将下一个参数存入pat变量中,并且计算长度存入patlen变量中
pat = c->argv[i+1]->ptr;
patlen = sdslen(pat);
//避免非必要的过滤逻辑,看到匹配单词是*且长度为1,则use_pattern为0,后续不执行过滤逻辑
use_pattern = !(pat[0] == '*' && patlen == 1);
//直接跳两步,避免非必要的遍历
i += 2;
} else {
addReply(c,shared.syntaxerr);
goto cleanup;
}
}
反向迭代算法遍历元素
通过上述步骤,我们完成count和match的参数解析,接下来就到了最重要的一个步骤——迭代字典元素。
我们都知道redis字典采用双数组+链表的形式,完成渐进式哈希和拉链法避免极端冲突,从而保证redis读写性能。因为双数组的元素,若scan采用顺序遍历就可以存在一个致命问题——重复迭代。
假设我们初始化一个长度为4的数组,存放元素,通过顺序迭代算法,我们完成桶2的元素迭代,随后redis为避免极端的冲突导致读写性能下降,进行了一次渐进式rehash,构建一个长度为8的数组,逐步迁移桶2的元素到桶4中。
如下图所示,试想一下,若按照顺序迭代的方式,当游标指向桶4时,我们又再次扫描到了桶2中迭代的元素,造成了大量非必要的迭代开销: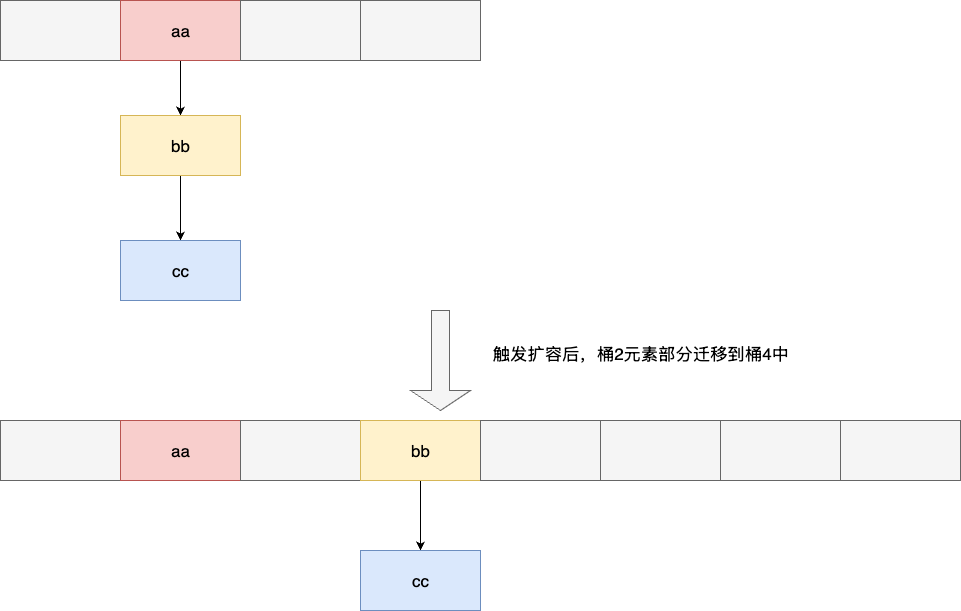
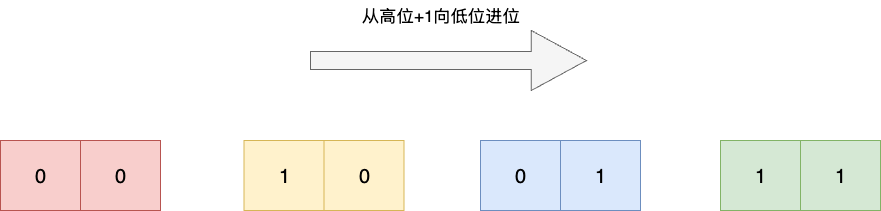
所以redis提出了一种巧妙的高位优先和反向迭代算法,确保能够迭代所有桶元素的同时,还能避免重复扫描。例如:我们字典底层的数组长度为4,对应的哈希计算的掩码为3也就是二进制011,输出结果是0、2、1、3,对应二进制为00、10、01、11,如下图所示,相信读者也已看出,该算法看着像是一种反向的递增算法,即高位+1向低位不断进位的反向迭代算法:
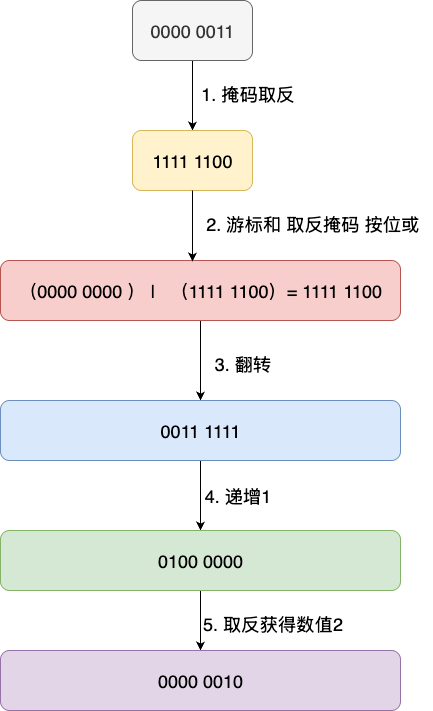
算法的原理比较简单,但是实现却相对复杂一些,所以笔者还是通过例子的方式进行演示。例如,我们现在有一个长度为4的字典数组,完成游标0迭代后,对应计算步骤为:
- 将掩码取反,即
0000 0011变为1111 1100,将高位置为1,便于后续反向递增运算 - 将游标值也就是0000 0000与掩码进行按位或,得到1111 1100,获得高位全为1,低位(用于计算桶位置的2位)保留原样的二进制数。
- 二进制位翻转获得0011 1111,为递增做铺垫
- 递增加一,将翻转为高位的原低位区间(即两个00),完成反向递增,也就是0100 0000
- 再翻转回来,获得0000 0010,也就是元素2
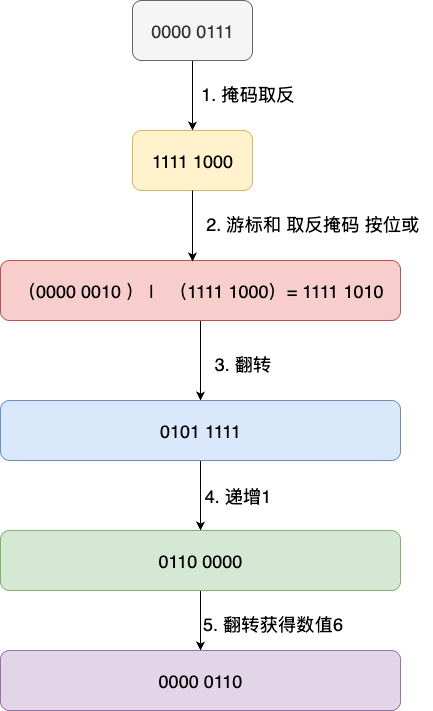
同理对应数值2的反向递增也是同理,通过上述的算法说明我们可知对应二进制10会因为反向递增变为01,也就是二进制1,对应的计算步骤为:
- 掩码取反获得1111 1100
- 游标值和掩码按位或,将高位置1,低位即有效计算桶为10保留,为反向递增做铺垫
- 将二进制翻转变为0111 1111
- 执行递增,完成反向递增,变为1000 0000
- 翻转回来获得二进制1
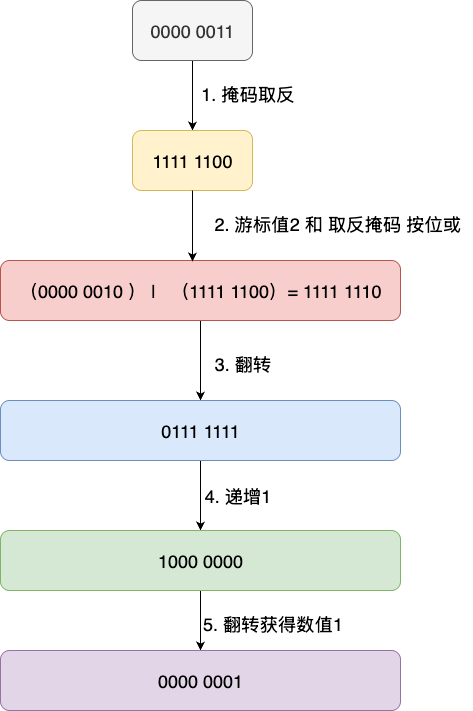
通过将掩码高位置1,利用按位或保留所有有效桶位二进制,使得翻转后的递增操作实现反向递增的效果同时,保证最终游标值都控制在桶区间以内且不重复,例如数组为4的字典,它可以确保不重复的情况下完成一轮有效的遍历:0 → 2→ 1→ 3
通过一个简单例子,印证了该算法如何保证完整的有效扫荡,但这还不是该算法的巧妙之处,相较于顺序扫荡,它能够有效避免非必要的大量重复扫荡。
按照redis字典的扩容算法,数组为4的元素扩容后会变为8,对应的桶之间的迁移关系如下图所示。由于扩容后掩码多了一位,原桶中的每个元素会根据其hash值新增的最高位被拆分到两个新桶中。
例如:
- 桶0中的元素,根据hash的最高位是0或1,分别留在桶0或迁移到桶4;
- 桶1中的元素分别留在桶1或迁移到桶5;
- 桶2中的元素分别留在桶2或迁移到桶6;
- 桶3中的元素分别留在桶3或迁移到桶7:
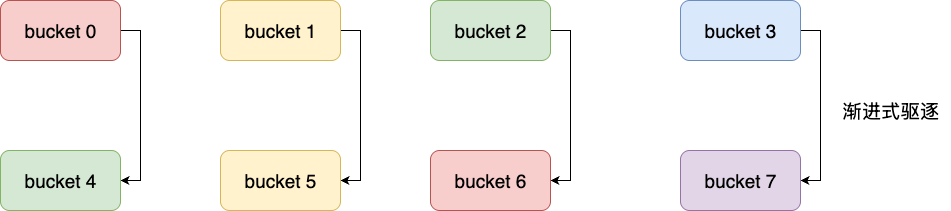
假设按照顺序迭代算法,完成桶2迭代后,我们可能会经过几次迭代之后才会接触到游标6。极端情况下,redis已将桶2元素迁移到桶6时,对于游标6的扫荡就可能带来大量的重复扫描。
再来看看反向迭代算法,假设我们完成2也就是二进制10的迭代。此时,因为扩容的原因,掩码变为7也就是二进制的0111,对应计算步骤也是按照高位置1、翻转、递增、再翻转,也就是最终得到二进制6,对应运算过程如下图所示:
同理,我们继续计算后的结果为:0 → 4 → 2 → 6 → 1 → 5 → 3 → 7 ,不难看出,反向迭代算法有效确保同模桶也就是存在扩容迁移关系的bucket紧挨着遍历,例如:
- 0紧挨着扩容桶4
- 2紧挨着扩容桶6
该算法可确保在扩容期间执行的scan操作时,能够尽可能快速的完成同模桶的迭代,避免大量元素重复扫描,避免非必要的资源开销,保证redis scan的执行效率:
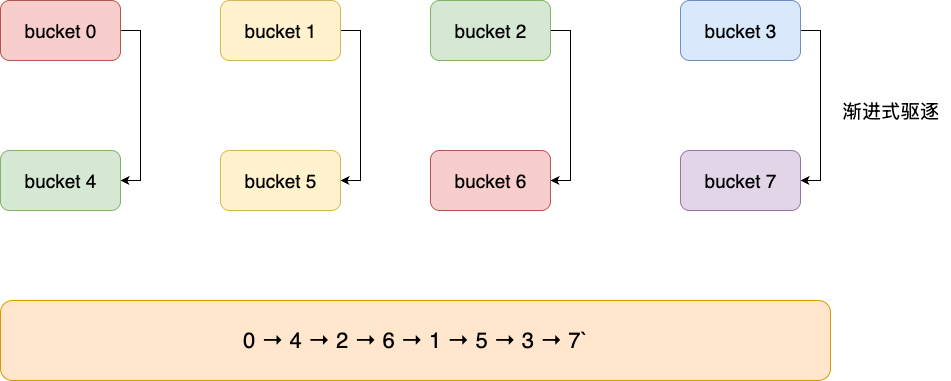
对应我们也给出scan迭代操作核心实现,对应算法逻辑和注释如下,如上文解析所说,整体算法通过rev完成二进制翻转,递增、再翻转的方式实现反向递增,确保完全覆盖同时,减少非必要的重试扫荡的开销:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
//......
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
//m为hash取模的掩码,假如size为4那么掩码就是获取0~3索引的某个位置,对应的掩码就是0011,同理size为8的情况下掩码就是0111
m0 = t0->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
//掩码取反并和游标进行按位或,获得一个可支持反向递增的二进制数
v |= ~m0;
//通过游标翻转、累加、再翻转的方式完成反向递增
v = rev(v);
v++;
v = rev(v);
} else {
//......
}
return v;
}
渐进式哈希下元素的迭代
上文的源码仅介绍非渐进式哈希的字典迭代,对于渐进式哈希期间的元素迭代才是redis迭代的精髓所在,按照上文的说明redis会在每一轮的dictScan进行一次元素桶的扫荡,假设我们数组容量为4,按照既有算法,对应的遍历顺序为:
00 → 10 → 01 → 11 → 00 (0,2,1,3)
对应,如果扩容之后,即容量由4变为8,对应的迭代顺序就变为:
000 → 100 → 010 → 110 → 001 → 101 → 011 → 111 → 000
(0 → 4 → 2 → 6 → 1 → 5 → 3 → 7 → 0)
可以看出,既有迭代顺序都是低位桶之后伴随高位桶,例如桶0之后立刻遍历高位桶4,所以对于处于渐进式哈希的期间的数组,就必须做到完成低位桶遍历后再遍历一次高位桶,例如:我们的桶由原来的4变为8,在遍历哈希表1的索引0元素时,还得同时遍历渐进式哈希表2的桶0和桶4,因为这两个索引可能存在原有数组迁移过来的元素:
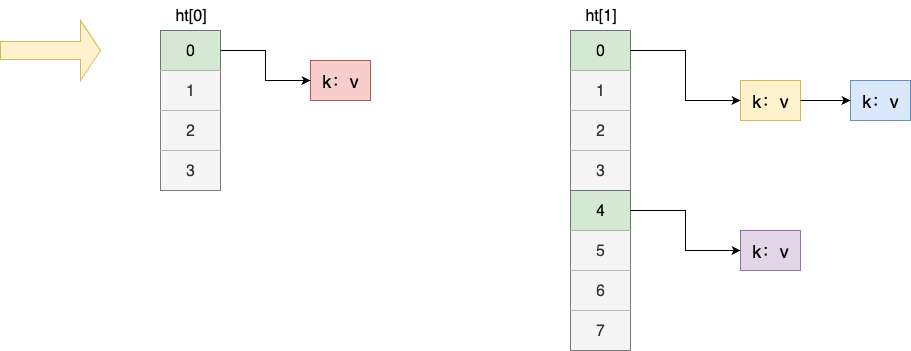
所以针对这种场景,扫描逻辑就必须做到遍历到高位桶之后才能结束本轮扫荡,我们不妨结合规律来看看如何实现这一算法,按照上述的说明,容量为8的数组遍历顺序为如下:
- 遍历桶0所有元素,对应二进制为000
- 反向递进得到桶4继续遍历,对应二进制为100
- 反向递进得到桶2,不为0的扩容桶结束
结合二进制解析如下,可以看到,要想实现我们的需要的逻辑,只需完成bucket4迭代后,看看高位是否为0,若为0则说明我们已经完成原有桶和扩容桶的迭代,直接结束即可:

于是我们就得到了如下算法,通过两个桶的mask掩码进行抑或运算获得高位的1,通过桶索引按位与判断是否完成原桶和扩容桶的遍历,对应完整步骤为:
- 完成桶0遍历,无需判断
- 反向迭代获得4,mask按位或得到二进制0100,和4进行按位与获得0100,说明当前遍历的是扩容桶执行遍历
- 基于4进行反向迭代获得2,mask进行按位或0100,和2进行按位与获得全0,说明当前坐标非扩容桶,直接结束

与之对应渐进式哈希迭代还有一个细节,我们都知道redis底层的字典是通过两个数组按照如下方式完成渐进式哈希,避免主线程阻塞:
- 明确需要扩容,创建哈希表2数组
- 逐步移动数组1元素到数组2
- 数组1指向数组2
针对渐进式哈希的扫描迭代,dictScan还有一个细节,若哈希表1大于表2,redis会优先从表2开始遍历,这一点我们可以通过逻辑推理的方式了解这一设计。
我们假设当前哈希表有key1~8,此时key 1~3已经迁移到哈希表2,若按照顺序迭代两个哈希表,对应执行过程为:
- 先迭代元素
4~8 - 迭代期间
4~8跑到哈希表2 - 迭代表2,重复扫描
1~8
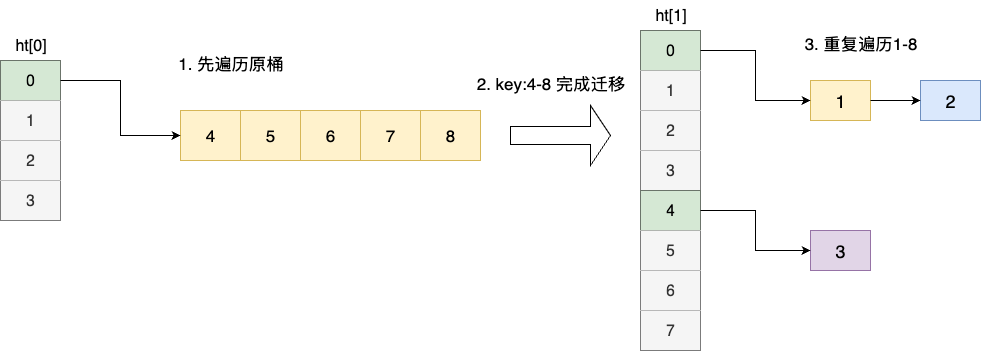
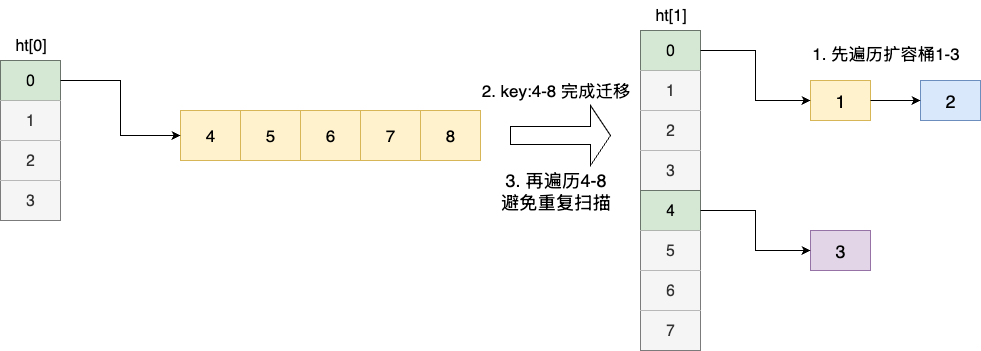
反之若在哈希表2有元素且小于哈希表1时,先迭代哈希表2,再执行表1的处理逻辑为:
- 先遍历
1~3 - 迭代期间
4~8跑到哈希表2 - 再次遍历
4~8,由此避免了非必要的重复扫描
对应的我们给出渐进式哈希的dictScan源代码逻辑,读者可结合文章和注释理解这一设计:
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
//......
if (!dictIsRehashing(d)) {
//......
} else { //处于渐进式哈希期间的源码
t0 = &d->ht[0];
t1 = &d->ht[1];
//若发现桶1大于桶2,说明刚刚开始渐进式哈希,先遍历桶1
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
//反向迭代遍历低位桶
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
do {
//反向迭代遍历扩容桶
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment the reverse cursor not covered by the smaller mask.*/
//高位取反通过按位或保留索引值
v |= ~m1;
//取反、累加、再取反完成倒叙运算,最终的v就是下一次的游标
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference is non-zero */
/**
* 1. 通过m0 ^ m1得到两个掩码抑或运算获得高位的1对应的二进制
* 2. 通过v & (m0 ^ m1)判断当前游标v是否是扩容桶,若是则继续循环
*/
} while (v & (m0 ^ m1));
}
return v;
}
过滤结果集
最后我们再来聊聊match参数的优化,相比于扫荡的算法这个实现就比较容易了,对应步骤为:
- 获取上一轮迭代后的元素链表
- 基于表达式进行匹配,若不符合要求则将filter设置为1
- 根据步骤2 生成的filter标识判断是否将元素从结果集中删除
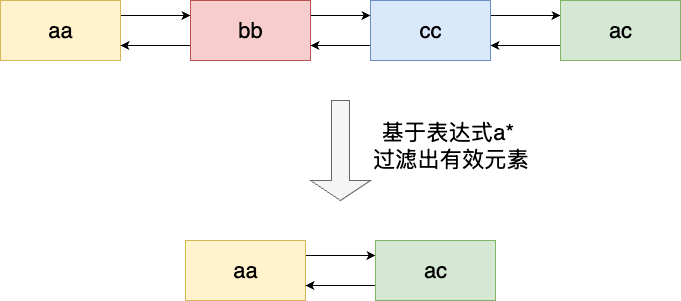
对应我们也给出匹配过滤的核心逻辑,即位于scanGenericCommand的step 3代码段,对应逻辑也和笔者说明的一致,即通过match 参数解析获取的pat(以上图为例则是a*)和patlen 即也就是2,遍历链表进行过滤匹配,将不符合要求的从链表中删除:
/* Step 3: Filter elements. */
//获取反向迭代后的链表首元素
node = listFirst(keys);
while (node) {
robj *kobj = listNodeValue(node);
nextnode = listNextNode(node);
//初始化过滤标识为0,代表不过滤
int filter = 0;
/* Filter element if it does not match the pattern. */
if (!filter && use_pattern) {
if (sdsEncodedObject(kobj)) {
//结合match表达式参数pat和patlen判断当前元素是否匹配,若不匹配则过滤标识设置为1
if (!stringmatchlen(pat, patlen, kobj->ptr, sdslen(kobj->ptr), 0))
filter = 1;
} else {
char buf[LONG_STR_SIZE];
int len;
serverAssert(kobj->encoding == OBJ_ENCODING_INT);
len = ll2string(buf,sizeof(buf),(long)kobj->ptr);
if (!stringmatchlen(pat, patlen, buf, len, 0)) filter = 1;
}
}
/* Filter element if it is an expired key. */
//判断元素是否过期,若过期,也将其设置为1,
if (!filter && o == NULL && expireIfNeeded(c->db, kobj)) filter = 1;
/* Remove the element and its associted value if needed. */
//如果过滤标识为1则将这个节点删除
if (filter) {
decrRefCount(kobj);
listDelNode(keys, node);
}
/* If this is a hash or a sorted set, we have a flat list of
* key-value elements, so if this element was filtered, remove the
* value, or skip it if it was not filtered: we only match keys. */
if (o && (o->type == OBJ_ZSET || o->type == OBJ_HASH)) {
node = nextnode;
nextnode = listNextNode(node);
if (filter) {
kobj = listNodeValue(node);
decrRefCount(kobj);
listDelNode(keys, node);
}
}
node = nextnode;
}
输出游标和结果
结合反向迭代算法和链表过滤,我们得到下一次的游标cursor和keys,redis会严格按照redis resp协议进行组装和输出,对应步骤也很清晰:
- 输出数组长度为2,1个数组存放游标、1个数组存放结果集
- 输出数组1,即下一次的游标
- 输出数组2,即下一个数组也就是链表结果集
//说明长度为2
addReplyMultiBulkLen(c, 2);
//告知下一次的游标的值
addReplyBulkLongLong(c,cursor);
//告知链表的长度
addReplyMultiBulkLen(c, listLength(keys));
//从头开始遍历链表
while ((node = listFirst(keys)) != NULL) {
robj *kobj = listNodeValue(node);
addReplyBulk(c, kobj);
decrRefCount(kobj);
listDelNode(keys, node);
}
例如:笔者在redis中存放user:1和user:2两个key,对应键入SCAN 0 COUNT 2 MATCH user:*后的输出结果如下:

小结
自此,笔者基于redis的scan指令完成了源码解析过程技巧的介绍,总的来说阅读源码时,我们要遵循:
- 搭建起调测环境,例如笔者本次的redis源码环境搭建
- 明确要调测的源码的输入和输出,对其使用有所感知,例如笔者本次的scan指令的使用场景和效果
- 带着阅读的目的去调试源码,以宏观了解流程再逐步了解核心逻辑的方式进行理解学习
- 针对不了解的算法可通过搜索引擎或AI理解工作理念,并进行笔算理解调测,必要时可通过反证法推断算法的合理性
- 图文梳理理解进行复盘总结
笔者也是一个与时俱进的软件研发者,从底层原理至应用层架构设计,笔者一直以来都是以自己的工作理念探索和推进,我始终无条件坚定自己学习和工作态度,不接受任何反驳,对于那些秉持老旧的工作理念,以过来人方式主观推测与时俱进的方法论的人,我只能说:只有互联网的浪潮退去,那波以红利作为当能力才会知道谁在裸泳。
SharkChili · 禅与计算机程序设计的艺术
开源贡献
- mini-redis:教学级 Redis 精简实现 ·
https://github.com/shark-ctrl/mini-redis
关注公众号,回复 【加群】 加入技术社群
参考
Redis SCAN 命令 递增地遍历key空间:https://redis.com.cn/commands/scan.html
Redis中的数据库切换:从DB0到DB1的写操作详解-百度开发者中心:https://developer.baidu.com/article/details/3192420
Redis Scan 原理解析与踩坑:https://www.lixueduan.com/posts/redis/redis-scan
让人爱恨交加的Redis Scan遍历操作原理:http://chenzhenianqing.com/articles/1410.html
一次 Scan 竟耗时上百秒?Redis Scan 原理解析与踩坑:https://blog.csdn.net/java_1996/article/details/122509155
巴菲特:潮水退了,才知道谁在裸泳。没经历过几个社会经济周期的人,体会不到这句话的含义:https://zhuanlan.zhihu.com/p/2011787421348540777

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)