大模型必知的50个概念
大模型概念
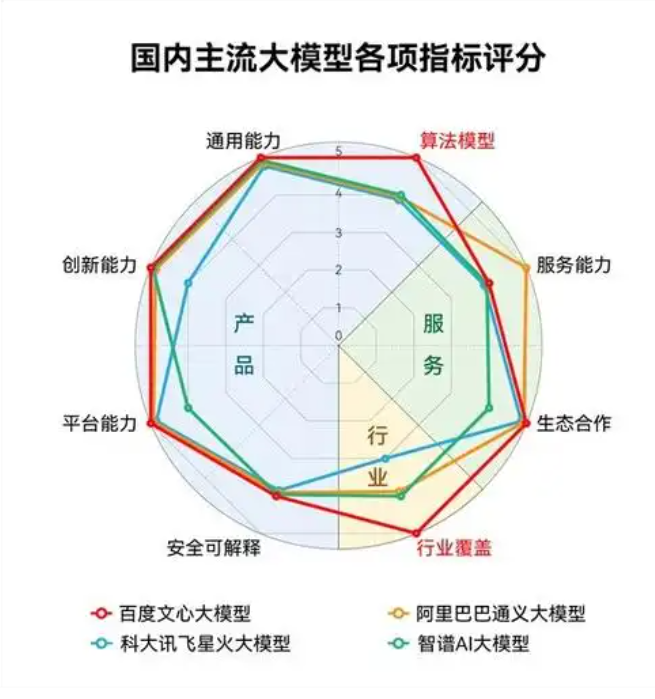
1.什么是大模型?
答案:大模型是指具有数十亿或数千亿参数的深度学习模型,通常是通过大规模的预训练数据进行训练的语言模型,如GPT,BERT等。这些模型通过自监督学习来理解和生成自然语言。
2.大模型的工作原理是什么?
答案:大模型通过多层神经网络进行深度学习,用自注意力机制(Transformer架构)来捕捉输入文本的上下文关系,并生成相应的输出。
3.Transformer模型的核心组件是什么?
答案:核心组件包括自注意力机制(Self-Attention),多头注意里(Multi-Head Attention),前馈神经网络(Feed-Forward Neural Network),层归一化(Layer Normalization)。
4.自注意力机制的公式是什么?
答案:自注意力的公式为:
QKT
Attention(Q,K,V)=softmaxk(V)
其中,Q(查询),K(键),V(值)是输入矩阵,d是键的维度。
5.大模型为什么需要预训练?
答案:预训练使得模型可以在大量无标签数据上学习通用的语言表示,减少对标注数据的依赖,并为下游任务提供良好的初始化。
6.什么是微调(Fine-tuning)?
答案:微调是将预训练模型在特定任务的数据上进行进一步训练,使得模型能够更好地适应改任务。
7.大模型的训练流程是怎样的?
答案:训练流程包括:数据准备,模型初始化,前向传播,损失计算,反向传播,参数更新。
8.大模型如何处理长文本输入?
答案:通过分块(chunking),长短期记忆机制(LSTM),递归神经网络(RNN)扩展机制,或更先进的长文处理Transformer结构如Longformer等。
输入输出概念
9.大模型的输入输出如何编码?
答案:输入输出通过词嵌入(Embedding)层进行编码,将词汇转化为向量表示。
10.什么是词嵌入(Embedding)?
答案:词嵌入是将离散的文本数据(如单词)映射到连续向量空间的技术,常见的有Word2Vec,GloVe等。
11.如何选择大模型的超参数?
答案:通过实验,网格搜索或贝叶斯优化等方法调整超参数,如学习率,批大小,层数等。
12.什么是注意力分数?
答案:注意力分数是表示每个输入词对输出词的影响程度,计算方式为上述自注意力公式中的 k QKT
13.大模型如何进行语言生成?
答案:大模型通过条件生成方式,以已给文本作为条件,预测下一个词的概率,并依次生成完整句子。
14.如何评估大模型的性能?
答案:使用指标如准确率,困惑度(Perplexity), BLEU,ROUGE等来评估模型在特定任务上的表现。
15.为什么大模型的训练需要大量计算资源?
答案:因为大模型的参数数量庞大,计算复杂度极高,训练过程需要大量的浮点计算。
16.什么是损失函数?
答案:损失函数用于度量模型预测值与真实值之间的差距,常见的有交叉熵损失(Cross-Entropy Loss)。
17.如何计算交叉熵损失?
答案:
N
LoSs=-log()
1m1
其中,y是真实值,y^是预测值。
18.大模型训练中的优化算法有哪些?
答案:常见的优化算法包括SGD,Adam,Adagrad,RMSprop等。
19.Adam优化算法的公式是什么?
答案:
m=1me-1+(1-1)gt u1=2v-1+(1-2)g
am
1=1-1ue+e
模型训练概念
20.什么是学习率衰减(Learning Rate Decay)?
答案:学习率衰减是指在训练过程中逐步减少学习率,以提高模型的收敛效果和稳定性。
21.如何处理模型训练中的过拟合问题?
答案:通过正则化(L1,L2),Dropout,数据增强,早停(Early Stopping)等方法防止过拟合。
22.Dropout的工作原理是什么?
答案:Dropout在训练过程中随机忽略部分神经元,以防止模型对训练数据过拟合。
23.大模型的参数初始化方法有哪些?
答案:常见的初始化方法有随机初始化,Xavier初始化,He初始化等。
24.为什么需要批标准化(Batch Normalization)?
答案:批标准化通过调整数据分布来加速训练,稳定梯度,提高模型泛化能力。
25.大模型如何进行多任务学习?
答案:通过共享底层网络结构,同时在多个务的头部层进行独立学习,实现多任务训练。
26.如何实现一个简单的GPT模型?
答案:使用PyTorch或TensorFlow实现基本的Transformer架构
27.什么是迁移学习?
答案:迁移学习是将预训练模型的知识迁移到新的任务中进行再学习,减少训练数据和时间。
28.大模型如何实现数据并行和模型并行?
答案:数据并行将数据划分到不同的GPU进行计算,模型并行将模型的不同部分分配到多个GPU上。
29.为什么需要混合精度训练?
答案:混合精度训练(FP16)可以减少显存占用,加速训练,尤其在大模型中效果显著。
30.大模型的推理过程是什么?
答案:推理是指使用训练好的模型对新输入进行预测,包括前向传播和结果输出。
模型优化概念
31.什么是推理时间优化?
答案:优化推理时间包括剪枝,量化,蒸馏等方法来减小模型规模,提高速度。
32.什么是模型剪枝(Pruning)?
答案:剪枝是通过去除冗余参数来减小模型规模,提高计算效率。
33.量化(Quantization)的作用是什么?
答案:量化是将模型的权重和激活函数从32位浮点数转化为8位或更低的精度,以减少计算和内存需求。
34.什么是知识蒸馏(Knowledge Distillation)?
答案:知识蒸馏是用大模型(教师模型)训练小模型(学生模型),以保留大模型性能的同时减小模型规模。
35.如何实现知识蒸馏?
答案:(空白,图片中未提供答案)
36.什么是序列到序列模型(Seq2Seq)?
答案:Seq2Seq模型用于处理输入输出均为序列的问题,如翻译,摘要生成等,常用架构包括RNN,Transformer.
37.如何在大模型中处理多模态数据?
答案:通过将不同模态(如图像,文本,音烫)的特征编码为统一表示,再输入到多模态 Transformer中。
38.大模型训练的常见瓶颈是什么?
答案:常见瓶颈包括计算资源不足,显存受限,数据准备和清洗复杂,训练时间长。
39.如何解决显存不足的问题?
答案:使用梯度累积(Gradient Accumulation),分布式训练,混合精度等方法。
模型训练方式
40.什么是分布式训练?
答案:分布式训练是将训练任务分散到多个计算设备上,如多GPU或多节点,以加速训练过程。
41.如何在分布式训练中保持梯度同步?
答案:通过参数服务器架构或集体通信(如AllReduce)来同步梯度。
42.什么是梯度爆炸和梯度消失?
答案:梯度爆炸是指梯度过大导致训练不稳定,梯度消失是指梯度过小导致参数更新缓慢。
43.如何防止梯度爆炸?
答案:使用梯度裁剪(Gradient Clipping)来限制梯度的最大值。
44.什么是梯度裁剪?
答案:梯度裁剪是限制梯度的范数大小,以避免梯度爆炸问题。
45.如何在大模型中实现自监督学习?
答案:自监督学习通过构造伪标签,如遮掩词预测,下一个句子预测,让模型进行自我学习。
46.遮掩词预测的原理是什么?
答案:遮掩词预测通过随机遮盖输入文本中的部分词汇,模型需要预测被遮盖的词。
47.什么是GPT模型的核心架构?
答案:GPT使用了解码器(Decoder)堆叠的方式,仅保留了Transformer中的解码部分。
48.什么是BERT模型的核心架构?
答案:BERT使用了编码器(Encoder)堆叠的方式,进行双向的自注意力学习。
49.大模型如何进行强化学习?
答案:通过结合强化学习算法(如PPO)和人类反馈(RLHF),使得模型更符合人类偏好。
50.什么是RLHF?
答案:RLHF(Reinforcement Learning from Human Feedback)通过人类反馈信号指导模型训练。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)