Qwen3.5微调教程,从零到部署全打通
Qwen3.5 是开源社区的香饽饽,Unsloth 第一时间跟进了完整的微调支持
我花了两天研究了他们的文档和 Colab 笔记本,整理出这份从零到一的微调教程
0.8B 到 122B 全尺寸覆盖,文本、视觉、强化学习三条路线全打通
Qwen3.5 微调概览
先说结论:Qwen3.5 + Unsloth 是目前性价比最高的开源模型微调方案。
核心优势:
- 训练速度比标准 FA2 快 1.5 倍
- 显存占用减少 50%
- 支持 0.8B、2B、4B、9B、27B、35B-A3B、122B-A10B 全系列
- 支持**文本 SFT、视觉微调、强化学习(GRPO)**三条路线
- 导出格式丰富:GGUF(Ollama)、vLLM、LoRA 适配器
- 支持 201 种语言的多语言微调
各模型 bf16 LoRA 显存需求:
| 模型 | 显存 |
|---|---|
| 0.8B | 3GB |
| 2B | 5GB |
| 4B | 10GB |
| 9B | 22GB |
| 27B | 56GB |
| 35B-A3B(MoE) | 74GB |
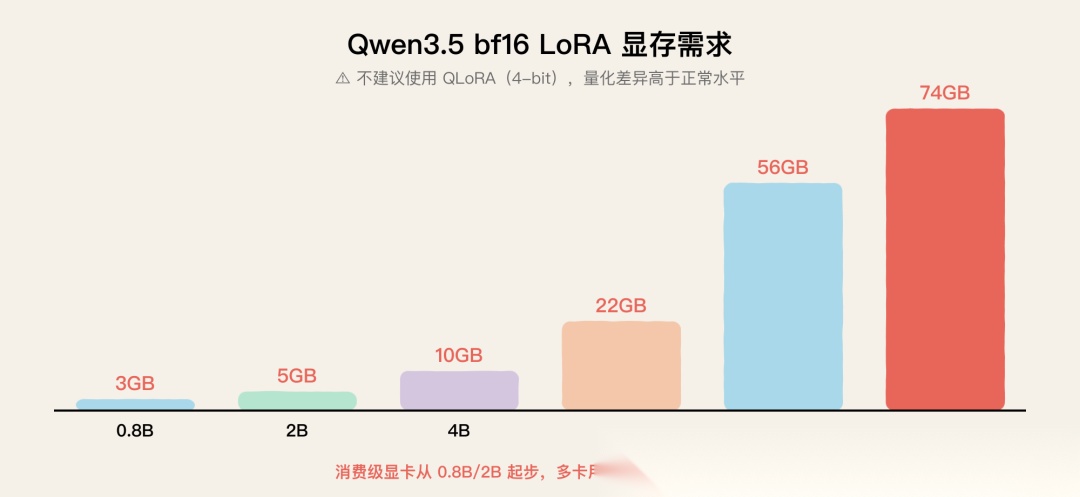
Qwen3.5 bf16 LoRA 显存需求
重要提醒:
- ⚠️ 必须用 transformers v5,旧版不行
- ⚠️ 不建议对 Qwen3.5 使用 QLoRA(4-bit)训练——量化差异高于正常水平
- ⚠️ MoE 模型(35B-A3B / 122B-A10B)推荐用 bf16 LoRA,不要用 QLoRA
方式一:Unsloth Studio(无代码方案)
如果你不想写一行代码,Unsloth 新推出的开源 Web UI —— Unsloth Studio 是最佳选择。
安装(MacOS / Linux / WSL):
curl -fsSL https://unsloth.ai/install.sh | sh
Windows PowerShell:
irm https://unsloth.ai/install.ps1 | iex
安装很快,大约 1-2 分钟。然后启动:
unsloth studio -H 0.0.0.0 -p 8888
浏览器打开 http://localhost:8888,首次登录设置密码后就能开始了。
Unsloth Studio 界面
在搜索栏搜索 Qwen3.5,选模型、选数据集、调参数、点开始训练——全程鼠标操作:
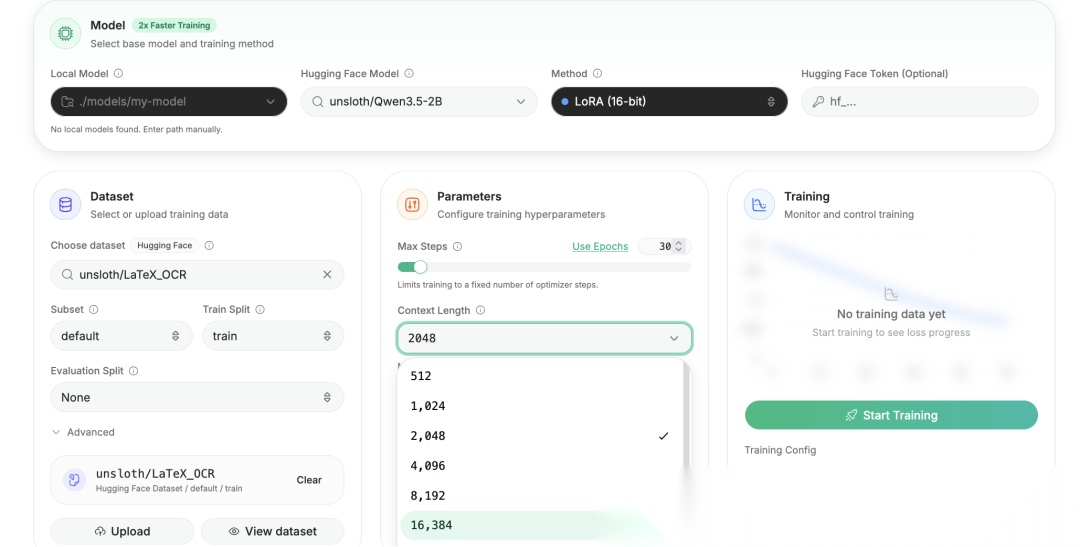
配置训练参数
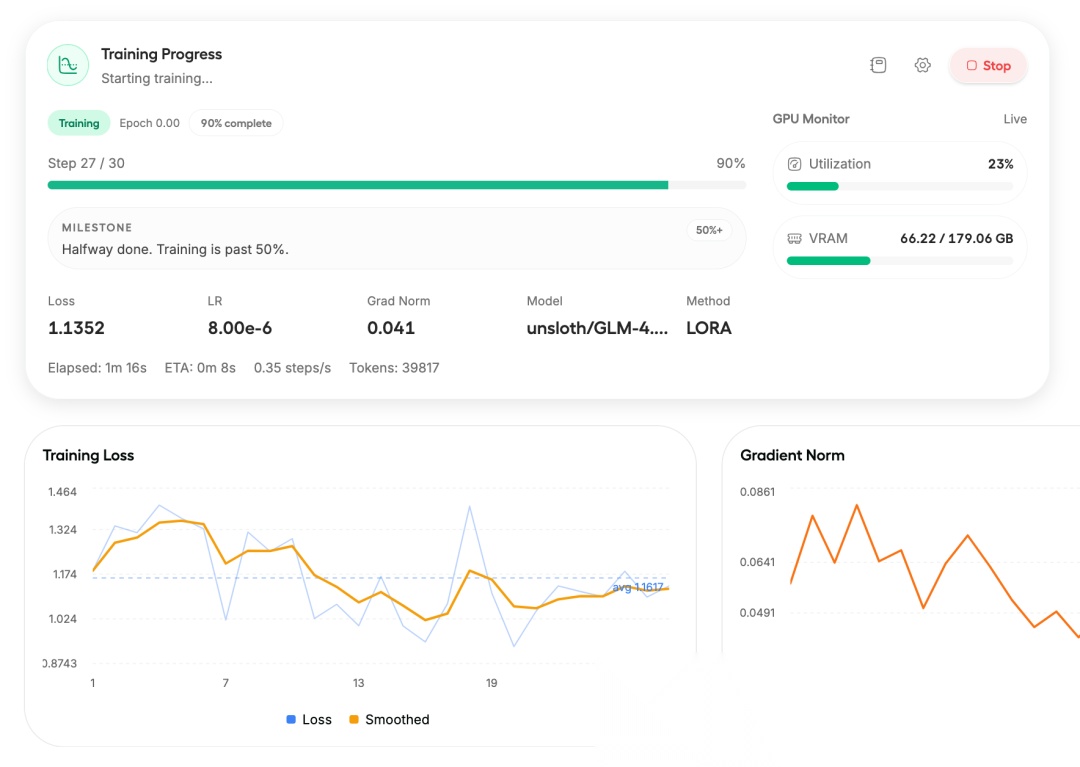
训练过程中可以实时监控损失曲线:
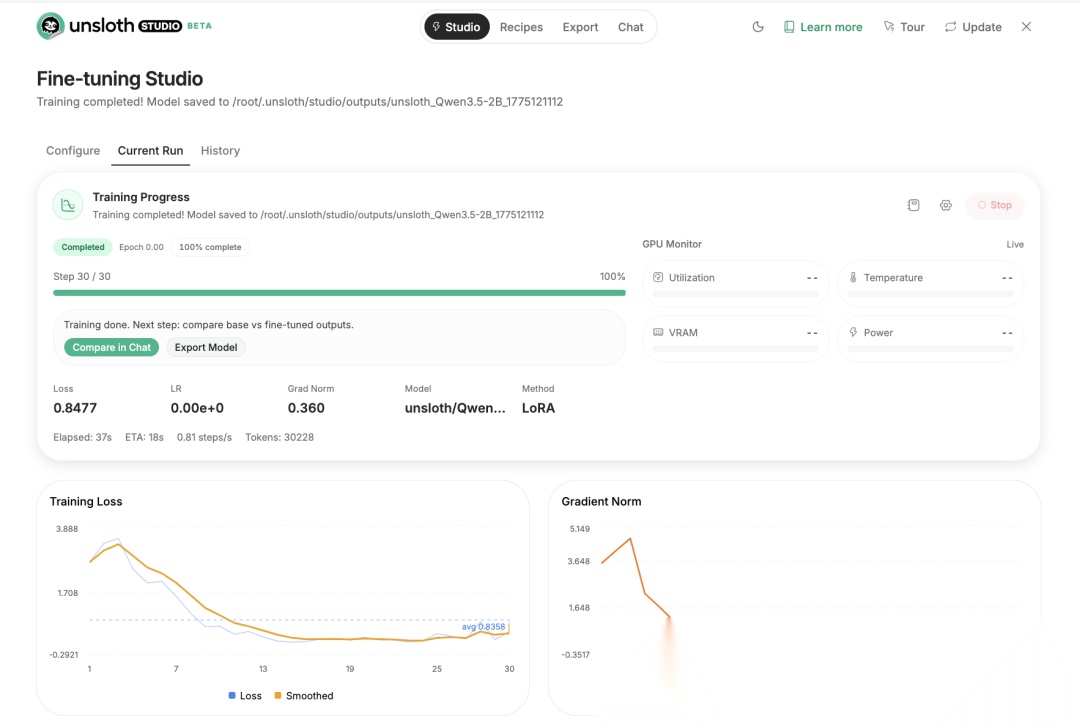
训练过程监控
训练完成后可以直接导出为 GGUF、safetensor 等格式:
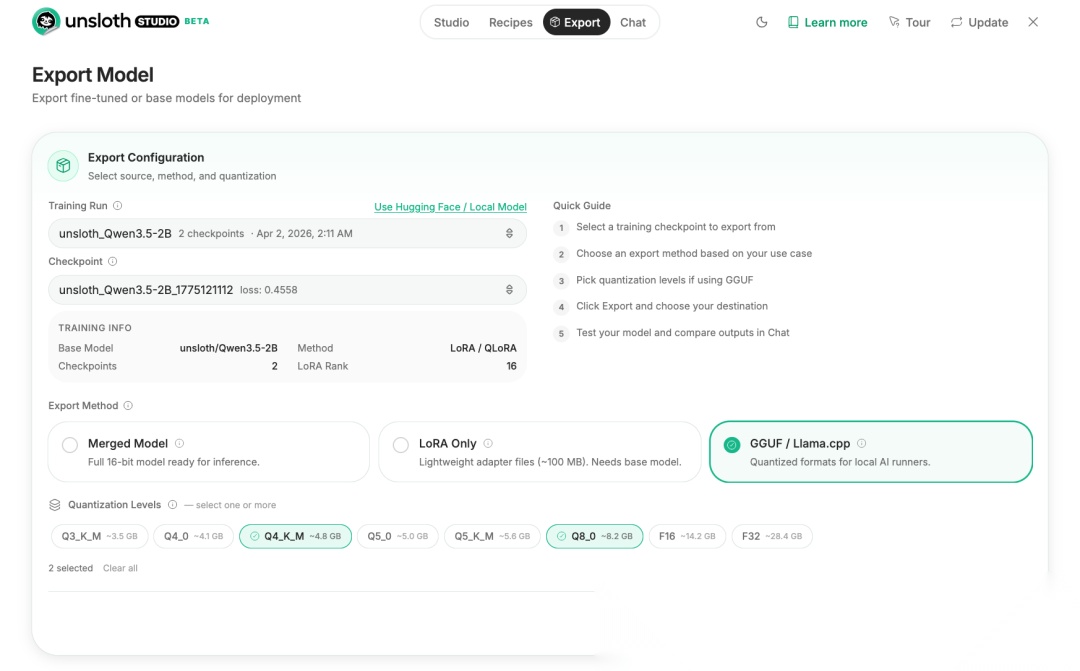
导出模型
方式二:代码微调(SFT 文本微调)
对于想精细控制的同学,下面是一个最小可运行的 SFT 代码:
from unsloth import FastLanguageModelimport torchfrom datasets import load_datasetfrom trl import SFTTrainer, SFTConfigmax_seq_length = 2048# 先从小开始# 加载数据集(替换成你自己的)url = "https://huggingface.co/datasets/laion/OIG/resolve/main/unified_chip2.jsonl"dataset = load_dataset("json", data_files={"train": url}, split="train")# 加载模型model, tokenizer = FastLanguageModel.from_pretrained( model_name = "Qwen/Qwen3.5-27B", max_seq_length = max_seq_length, load_in_4bit = False, # 不建议用 QLoRA load_in_16bit = True, # bf16 LoRA full_finetuning = False,)# 添加 LoRA 适配器model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = [ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], lora_alpha = 16, lora_dropout = 0, bias = "none", use_gradient_checkpointing = "unsloth", # 长上下文 + 更低显存 random_state = 3407, max_seq_length = max_seq_length,)# 训练trainer = SFTTrainer( model = model, train_dataset = dataset, tokenizer = tokenizer, args = SFTConfig( max_seq_length = max_seq_length, per_device_train_batch_size = 1, gradient_accumulation_steps = 4, warmup_steps = 10, max_steps = 100, logging_steps = 1, output_dir = "outputs_qwen35", optim = "adamw_8bit", seed = 3407, dataset_num_proc = 1, ),)trainer.train()
关键参数说明:
load_in_16bit = True:使用 bf16 LoRA,稳定性最好use_gradient_checkpointing = "unsloth":Unsloth 专属的检查点机制,显存占用更低r = 16:LoRA 秩,越大精度越高但越容易过拟合lora_alpha = 16:建议 alpha >= r
如果遇到 OOM,把 per_device_train_batch_size 降到 1,或者降低 max_seq_length。
MoE 模型微调(35B / 122B)
对于 Qwen3.5-35B-A3B 或 122B-A10B 这样的 MoE 模型:
from unsloth import FastModelmodel, tokenizer = FastModel.from_pretrained( model_name = "unsloth/Qwen3.5-35B-A3B", max_seq_length = 2048, load_in_4bit = False, load_in_16bit = True, full_finetuning = False,)
Unsloth 的 MoE 训练内核默认启用,号称比标准方案快 12 倍、显存减少 35%、上下文长度提升 6 倍。默认禁用路由层微调以保证稳定性。
122B-A10B 的 bf16 LoRA 需要 256GB 显存,多卡用户加 device_map = "balanced"。
视觉微调(Qwen3.5 VLM)
Qwen3.5 本身就是一个统一的视觉语言模型,所以视觉微调非常自然:
from unsloth import FastVisionModelmodel, tokenizer = FastVisionModel.from_pretrained( "unsloth/Qwen3.5-4B", load_in_4bit = False, use_gradient_checkpointing = "unsloth",)model = FastVisionModel.get_peft_model( model, finetune_vision_layers = True, # 微调视觉层 finetune_language_layers = True, # 微调语言层 finetune_attention_modules = True, # 微调注意力层 finetune_mlp_modules = True, # 微调 MLP 层 r = 16, lora_alpha = 16, lora_dropout = 0, bias = "none", random_state = 3407, target_modules = "all-linear", modules_to_save = ["lm_head", "embed_tokens"],)
亮点在于可以精细控制微调哪些部分——你可以选择只微调视觉层、只微调语言层,或者只微调注意力 / MLP 层,组合随意。
想在免费 T4 GPU 上跑?用官方 Colab 笔记本:
- 视觉微调:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(4B)_Vision.ipynb
强化学习(GRPO)
即使 vLLM 暂时还不支持 Qwen3.5,你仍然可以通过禁用 fast inference 来做 GRPO:
from unsloth import FastLanguageModelmodel, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Qwen3.5-4B", fast_inference = False, # 关键:禁用 fast vLLM 推理)
如果你想保留模型的推理能力,建议训练数据中至少保留 75% 的推理风格示例,其余可以用直接答案。
GGUF 量化基准测试——选什么量化最靠谱?
Unsloth 做了超过 150 次 KL 散度基准测试,总计 9TB 的 GGUF,得出了几条关键结论,这里帮你划重点:
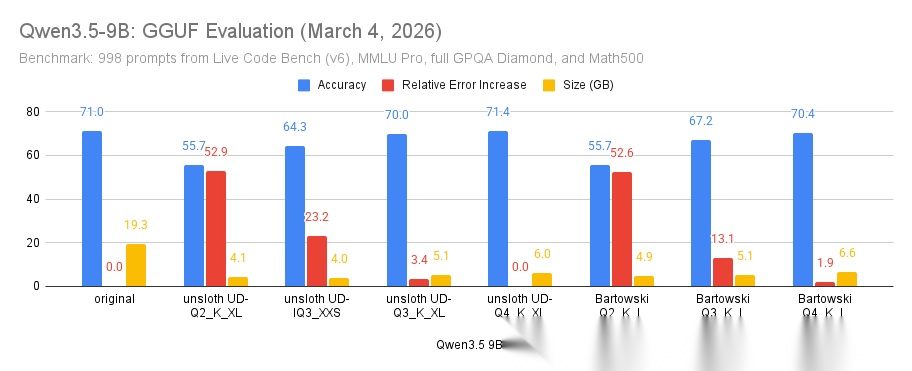
KLD 基准测试结果
量化选择建议:
- 别碰 MXFP4——在很多张量上表现都很差,已从 Q2_K_XL、Q3_K_XL、Q4_K_XL 中退役。Q4_K 在几乎所有场景下都比 MXFP4 好
- ssm_out 层别量化——Mamba 层(ssm_out)量化后 KLD 飙升,磁盘空间却省不了多少
- 3-bit 是甜点区——ffn_up_exps 和 ffn_gate_exps 通常可以量化到 3 位(iq3_xxs 附近),2 位就开始明显降级了
- Imatrix 确实有效——能降低 KLD 和 PPL,但推理速度慢 5-10%。对低位数量化帮助更大
- attn_ 层高度敏感*——对于混合架构,注意力层保持高精度很重要
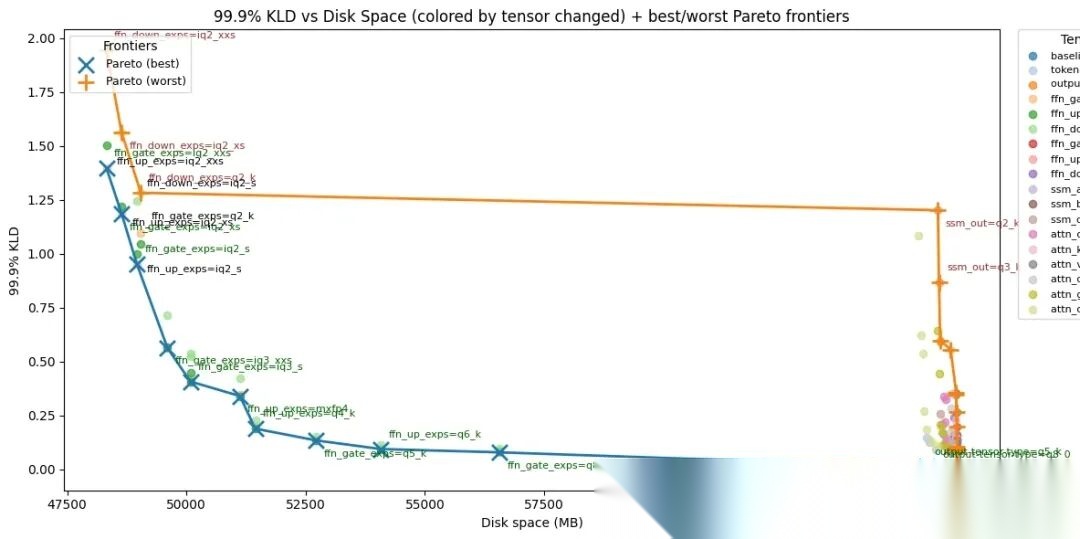
Tensor 类型敏感度分析
另外一个很重要的发现:困惑度(PPL)和 KL 散度可能具有误导性。Unsloth Dynamic IQ2_XXS 在真实评估(LiveCodeBench v6、MMLU Pro)上表现优于 AesSedai 的 IQ3_S,尽管体积小 11GB,但后者的 PPL 和 KLD 指标反而更好看。所以千万不要只看 PPL 就下结论。
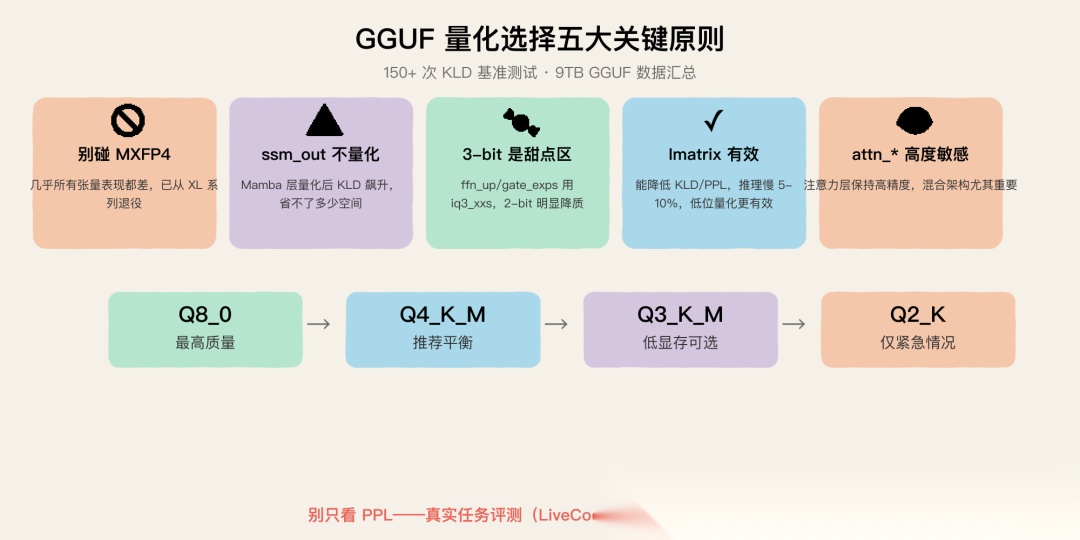
GGUF 量化选择五大关键原则
导出与部署
微调完成后,导出到各种格式都很方便:
导出为 GGUF(给 Ollama / llama.cpp 用):
model.save_pretrained_gguf("directory", tokenizer, quantization_method="q4_k_m")model.save_pretrained_gguf("directory", tokenizer, quantization_method="q8_0")
导出为 16-bit(给 vLLM 用):
model.save_pretrained_merged("finetuned_model", tokenizer, save_method="merged_16bit")
只保存 LoRA 适配器:
model.save_pretrained("finetuned_lora")tokenizer.save_pretrained("finetuned_lora")
推到 HuggingFace:
model.push_to_hub_gguf("hf_username/model", tokenizer, quantization_method="q4_k_m")
⚠️ 注意:vLLM 0.16.0 不支持 Qwen3.5,需要等 0.170 或用 Nightly 版本。如果导出模型在其他运行时效果变差,大概率是聊天模板 / EOS 令牌用错了——必须和训练时保持一致。
总结
整理一下整个微调路径:
| 路线 | 适合谁 | 显存门槛 | 推荐 |
|---|---|---|---|
| Unsloth Studio | 不想写代码 | 取决于模型 | ⭐⭐⭐⭐⭐ |
| SFT 代码微调 | 需要精细控制 | 3GB(0.8B)起 | ⭐⭐⭐⭐⭐ |
| 视觉微调 | 做多模态应用 | 10GB(4B)起 | ⭐⭐⭐⭐ |
| GRPO 强化学习 | 提升推理能力 | 10GB 起 | ⭐⭐⭐⭐ |
| MoE 微调 | 要大模型能力 | 74GB 起 | ⭐⭐⭐ |
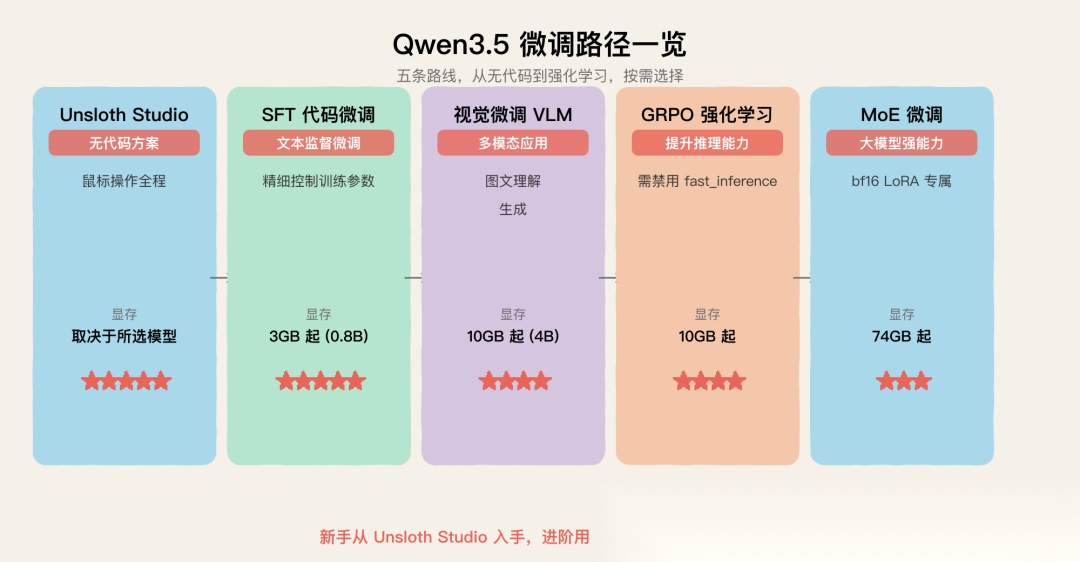
Qwen3.5 微调路径一览
Unsloth 在 Qwen3.5 上的支持可以说是教科书级别的——从 Studio 无代码方案到 Colab 免费笔记本,再到 GGUF 量化基准的深度研究,生态做得相当完整。唯一的坑是 MoE 模型对硬件要求较高,以及 transformers v5 的硬依赖。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)