基于GPT-2模型手搓一个医疗问诊聊天模型(全参数微调)
📖 前言
最近花了些时间,从零实现了一个基于GPT-2的中文医疗对话机器人。这篇文章将完整记录整个过程,包括数据处理、模型训练、推理优化到Web部署的每一个环节。这不是简单的"调包"教程,而是深入到底层实现原理的实战指南。
一、项目概览与技术选型
1.1 项目规模
| 项目 | 配置 |
|---|---|
| 基础模型 | GPT-2 (GPT2LMHeadModel) |
| 参数量 | 1.1亿 (0.11B) |
| 训练数据 | 医疗对话语料(约50万条) |
| 硬件环境 | RTX 4090 (24GB显存) |
| 训练时长 | 约6-8小时(20个epoch) |
1.2 技术栈选择
# 环境要求
python>=3.8
torch>=1.12.0
transformers>=4.25.0
flask>=2.0.0
1.3 为什么选择GPT-2而不是其他模型?
| 模型 | 优势 | 劣势 | 本项目选择 |
|---|---|---|---|
| GPT-2 | 开源、文档丰富、社区活跃 | 相对较老 | ✅ 适合学习底层 |
| GPT-3/4 | 效果最好 | 不开源、API昂贵 | ❌ |
| LLaMA | 性能优异 | 需要申请、部署复杂 | ❌ |
| ChatGLM | 中文优化 | 显存要求高 | ❌ |
1.4 项目架构图
块1:数据预处理架构: 从原始文本到DataLoader的完整流程
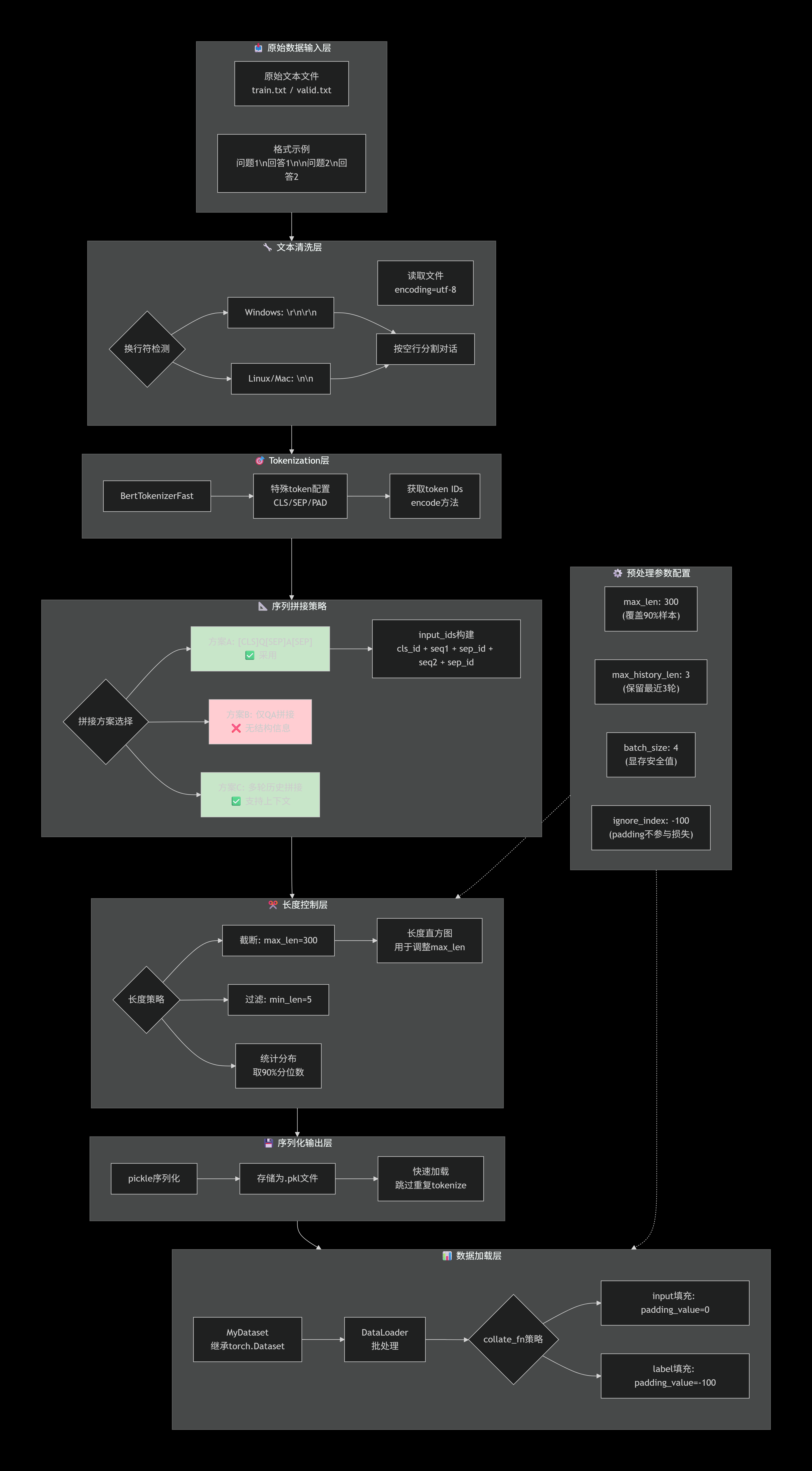
块2:模型训练架构:优化器、调度器、梯度处理的全流程
块3:模型推理架构:对话管理、采样策略、自回归生成
块4:策略决策矩阵:不同场景下的参数选择依据
块5:数据流向图:离线训练和在线推理的数据流转

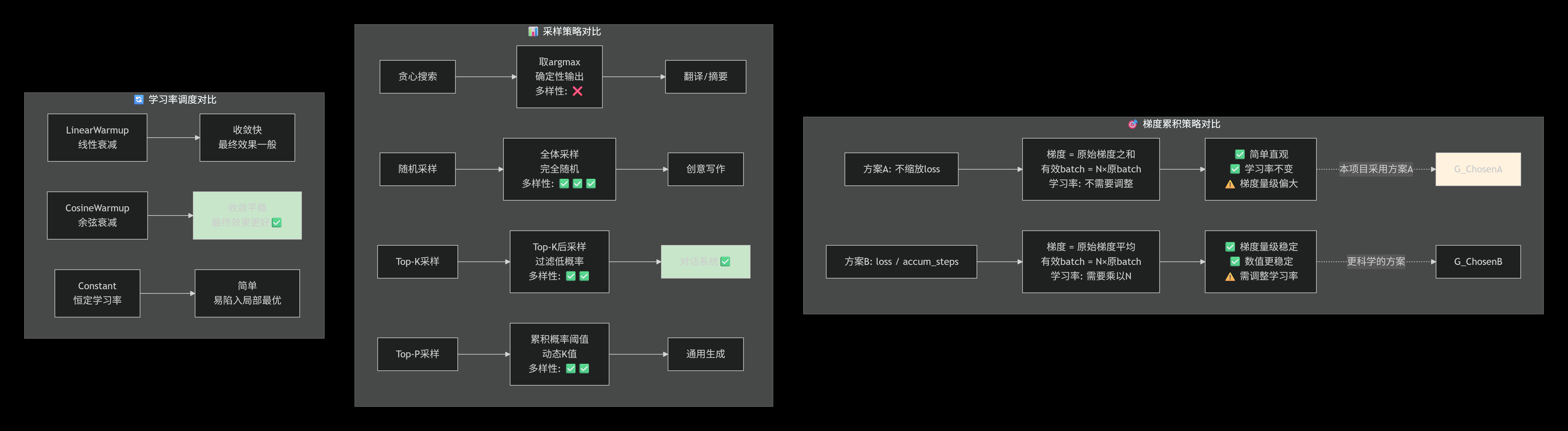
块6:核心策略对比表:核心技术的方案对比
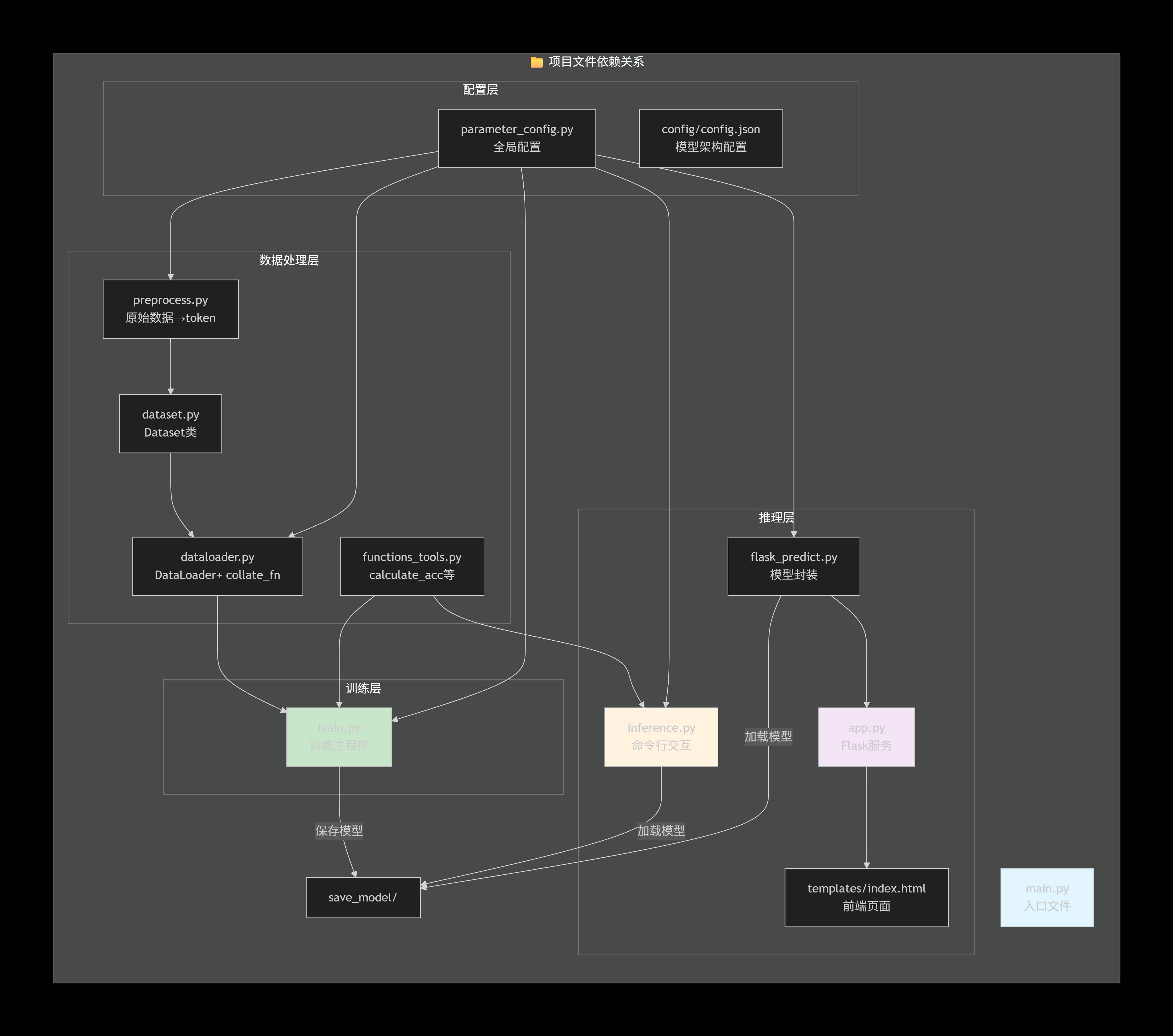
块7:文件依赖关系图:项目模块间的调用关系
策略选择详细说明表
数据预处理策略
| 策略点 | 选择方案 | 备选方案 | 选择理由 |
|---|---|---|---|
| 分词器 | BertTokenizerFast | GPT2Tokenizer | 中文支持更好,词表适配中文 |
| 序列格式 | [CLS] Q [SEP] A [SEP] |
仅拼接Q和A | 让模型学会对话结构和结束符 |
| 最大长度 | 300 | 128/256/512 | 统计90%样本在此范围内 |
| 历史轮数 | 3轮 | 1轮/5轮/10轮 | 平衡上下文和显存 |
| 填充策略 | input:0, labels:-100 | 统一填充0 | -100被损失函数忽略 |
| 截断策略 | 直接截断前max_len | 随机截断/保留尾部 | 对话开头通常更重要 |
训练策略
| 策略点 | 选择方案 | 经验值 | 备选方案 | 选择理由 |
|---|---|---|---|---|
| Batch Size | 4 | 2-8 | 16-32 | 24GB显存下的安全值 |
| 梯度累积 | 4步 | 4-8 | 1步 | 有效batch=16,平衡速度 |
| 学习率 | 2.6e-5 | 1e-5 ~ 5e-5 | 1e-4 | 微调时的标准范围 |
| 预热步数 | 500 | t_total × 6% | 1000 | 稳定训练初期 |
| 学习率调度 | Cosine退火 | - | 线性衰减 | 最终效果更好 |
| 梯度裁剪 | 2.0 | 1.0-5.0 | 1.0 | 防止梯度爆炸 |
| 优化器 | AdamW | - | SGD | 自适应学习率 |
| Epochs | 20 | 10-50 | 100 | 根据收敛情况调整 |
| Dropout | 0.1 | 0.1-0.3 | 0.5 | GPT-2默认配置 |
推理策略
| 策略点 | 选择方案 | 经验值 | 备选方案 | 选择理由 |
|---|---|---|---|---|
| 采样方法 | 随机采样 | - | 贪心/Beam Search | 多样性更好 |
| Top-K值 | 4 | 4-10 | 1/20/50 | 医疗场景需准确性 |
| 重复惩罚 | 10.0 | 1.2-1.5 | 1.0 | 医疗对话不能复读 |
| 温度参数 | ❌ 未实现 | 0.7-1.0 | - | 可后续优化 |
| Top-P | ❌ 未实现 | 0.9-0.95 | - | 可后续优化 |
| 停止条件 | [SEP]或max_len | - | 特定词 | [SEP]是标准结束符 |
| UNK处理 | 完全禁止 | - | 保留 | UNK无意义 |
硬件配置
| 配置项 | 本项目 | 最低要求 | 推荐配置 |
|---|---|---|---|
| GPU | RTX 4090 24GB | 8GB | 16GB+ |
| CPU | - | 4核 | 8核+ |
| 内存 | - | 16GB | 32GB |
| 显存利用率 | ~60% | - | - |
二、数据处理:从原始文本到模型输入
2.1 数据格式分析
原始数据采用每句一行,空行分隔对话的格式:
帕金森叠加综合征的辅助治疗有些什么?
综合治疗;康复训练;生活护理指导;低频重复经颅磁刺激治疗卵巢癌肉瘤的影像学检查有些什么?
超声漏诊;声像图;MR检查;肿物超声;术前超声;CT检查
2.2 对话拼接策略选择
核心决策:采用 [CLS] Q1 [SEP] A1 [SEP] Q2 [SEP] 格式
def build_dialogue_sample(sequences, tokenizer):
"""
构建单个对话样本
输入: sequences = ["问题1", "回答1", "问题2", "回答2"]
输出: [CLS] 问题1 [SEP] 回答1 [SEP] 问题2 [SEP]
"""
cls_id = tokenizer.cls_token_id
sep_id = tokenizer.sep_token_id
input_ids = [cls_id]
for seq in sequences:
# 不添加特殊token,保持原始token序列
input_ids += tokenizer.encode(seq, add_special_tokens=False)
input_ids.append(sep_id) # 每句后加分隔符
return input_ids为什么这样设计?
| 策略 | 优点 | 缺点 | 是否采用 |
|---|---|---|---|
| 只拼接问答对 | 训练快 | 无法多轮对话 | ❌ |
| 添加特殊token | 模型学会结构 | 增加序列长度 | ✅ |
| 保留历史对话 | 支持上下文 | 显存占用大 | ✅ (限制3轮) |
2.3 长度截断策略
class MyDataset(Dataset):
def __init__(self, input_list, max_len=300):
self.input_list = input_list
self.max_len = max_len
def __getitem__(self, index):
input_ids = self.input_list[index]
# 截断:保留前max_len个token
input_ids = input_ids[:self.max_len]
return torch.tensor(input_ids, dtype=torch.long)长度选择的经验值:
| max_len | 适用场景 | 显存占用 | 覆盖比例 |
|---|---|---|---|
| 128 | 短对话、客服问答 | 4-6GB | 约60% |
| 256 | 通用对话 | 6-10GB | 约85% |
| 300 | 医疗对话(本项目) | 8-12GB | 约92% |
| 512 | 长文本生成 | 12-16GB | 约98% |
决策依据:对训练数据做长度分布统计,选择能覆盖90%以上样本的长度值。
2.4 Padding与Collate函数
def collate_fn(batch):
"""
将多个样本打包成一个batch
- input_ids: 用0填充
- labels: 用-100填充(损失计算时忽略)
"""
# 填充input_ids (padding_value=0)
input_ids = rnn_utils.pad_sequence(
batch, batch_first=True, padding_value=0
)
# 填充labels (padding_value=-100)
labels = rnn_utils.pad_sequence(
batch, batch_first=True, padding_value=-100
)
return input_ids, labels为什么labels用-100而不是0?
| 填充值 | 损失计算 | 梯度影响 | 效果 |
|---|---|---|---|
| 0 | 会计算loss | 错误更新 | ❌ 模型学习预测padding |
| -100 | 自动忽略 | 无影响 | ✅ 符合预期 |
三、模型架构与配置
3.1 GPT-2配置详解
{
"vocab_size": 13317, // 中文词表大小
"n_embd": 768, // 隐藏层维度
"n_layer": 12, // Transformer层数
"n_head": 12, // 注意力头数
"n_ctx": 1024, // 最大上下文长度
"activation_function": "gelu_new", // 激活函数
"attn_pdrop": 0.1, // 注意力dropout
"embd_pdrop": 0.1, // 嵌入层dropout
"resid_pdrop": 0.1 // 残差连接dropout
}3.2 参数量计算
# 计算模型参数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params:,}") # 约 102,265,088
print(f"可训练参数: {trainable_params:,}") # 全参数训练时相同各模块参数量分布:
| 模块 | 参数量 | 占比 |
|---|---|---|
| Token Embedding | 13317 × 768 ≈ 10.2M | 10% |
| Position Embedding | 1024 × 768 ≈ 0.8M | 0.8% |
| 12个Transformer层 | 12 × (注意力+FFN) ≈ 91M | 89% |
| LayerNorm + LM Head | 2 × 768 + 13317×768 ≈ 10.3M | 0.2% |
3.3 模型加载方式选择
if params.pretrained_model:
# 方式1: 加载预训练权重(推荐)
model = GPT2LMHeadModel.from_pretrained(params.pretrained_model)
else:
# 方式2: 随机初始化(从零训练)
model_config = GPT2Config.from_json_file(params.config_json)
model = GPT2LMHeadModel(config=model_config)经验建议:
-
小数据集(<10万条):必须使用预训练模型
-
中等数据集(10-50万条):推荐预训练 + 微调
-
大数据集(>100万条):可以考虑从零训练
四、训练策略与优化技巧
4.1 梯度累积(Gradient Accumulation)
当显存不足时,梯度累积是模拟大Batch的核心技术:
# 配置参数
gradient_accumulation_steps = 4 # 累积4个batch
effective_batch_size = per_device_batch_size * gradient_accumulation_steps
# 训练循环
for batch_idx, (input_ids, labels) in enumerate(train_dataloader):
outputs = model(input_ids, labels=labels)
loss = outputs.loss
# 关键:除以累积步数,保持梯度量级一致
if gradient_accumulation_steps > 1:
loss = loss / gradient_accumulation_steps
loss.backward()
# 每N步更新一次参数
if (batch_idx + 1) % gradient_accumulation_steps == 0:
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm=1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad()学习率调整策略:
| 有效Batch Size | 原始Batch Size | 学习率调整 | 说明 |
|---|---|---|---|
| 16 | 4 | lr × 1 | 不调整 |
| 32 | 4 | lr × 2 | 线性缩放 |
| 64 | 4 | lr × 4 | 需实验验证 |
经验值:
# 不同显存下推荐的梯度累积配置(以GPT-2为例)
# 目标:达到有效batch_size=32
# 24GB显卡(如RTX 4090)
per_device_batch_size = 8
gradient_accumulation_steps = 4 # 有效=32
# 16GB显卡(如RTX 4080)
per_device_batch_size = 4
gradient_accumulation_steps = 8 # 有效=32
# 12GB显卡(如RTX 3060)
per_device_batch_size = 2
gradient_accumulation_steps = 16 # 有效=324.2 梯度裁剪(Gradient Clipping)
防止梯度爆炸,特别是训练初期:
# 在optimizer.step()之前调用
torch.nn.utils.clip_grad_norm_(
parameters=model.parameters(),
max_norm=args.max_grad_norm, # 建议值:1.0 ~ 5.0
norm_type=2.0 # L2范数
)max_norm经验值:
| 模型规模 | 推荐max_norm | 说明 |
|---|---|---|
| 小型(<10M) | 1.0 | 更保守 |
| 中型(10-100M) | 1.0 - 2.0 | 本项目使用2.0 |
| 大型(>100M) | 0.5 - 1.0 | GPT-2标准配置 |
4.3 学习率调度器选择
# 方案1:线性预热 + 线性衰减(最常用)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=args.warmup_steps,
num_training_steps=t_total
)
# 方案2:线性预热 + 余弦衰减(本项目使用)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=args.warmup_steps,
num_training_steps=t_total
)两种调度器对比:
| 调度器 | 收敛速度 | 最终效果 | 适用场景 |
|---|---|---|---|
| Linear | 快 | 较好 | 通用任务 |
| Cosine | 中等 | 更好 | 需要精细调优的任务 |
Warmup步数设置经验:
# 总训练步数计算
t_total = len(train_dataloader) // gradient_accumulation_steps * epochs
# 经验公式:warmup_steps = t_total * (0.05 ~ 0.10)
# 例如:t_total=10000,则warmup_steps=500~1000
warmup_steps = int(t_total * 0.06) # 6%作为预热期4.4 损失函数与准确率监控
def calculate_acc(logits, labels, ignore_index=-100):
"""
监控训练过程中的token级别准确率
"""
# 错位对齐:预测第t个token,对应标签第t+1个token
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# 展平
shift_logits = shift_logits.view(-1, shift_logits.size(-1))
shift_labels = shift_labels.view(-1)
# 取预测结果
_, preds = shift_logits.max(dim=-1)
# 过滤padding
non_pad_mask = shift_labels.ne(ignore_index)
n_correct = preds.eq(shift_labels).masked_select(non_pad_mask).sum().item()
n_total = non_pad_mask.sum().item()
return n_correct, n_total正常训练过程的loss和acc变化:
| Epoch | Train Loss | Val Loss | Token Acc | 状态 |
|---|---|---|---|---|
| 1 | 3.2 | 3.1 | 35% | 刚开始学习 |
| 5 | 2.1 | 2.0 | 52% | 快速学习期 |
| 10 | 1.5 | 1.4 | 68% | 稳定提升 |
| 15 | 1.2 | 1.3 | 74% | 接近收敛 |
| 20 | 1.0 | 1.3 | 78% | 可能轻微过拟合 |
五、推理生成策略(核心重点)
5.1 自回归生成原理
# GPT-2的核心:基于已生成的token预测下一个token
# 输入: [CLS] 我 饿 了 [SEP]
# 步骤1: 输入[CLS] → 预测"我"
# 步骤2: 输入[CLS, 我] → 预测"饿"
# 步骤3: 输入[CLS, 我, 饿] → 预测"了"
# 步骤4: 输入[CLS, 我, 饿, 了] → 预测[SEP]
# 步骤5: 输入[..., SEP] → 预测"那"
# ... 依此类推5.2 Top-K采样(核心策略)
def top_k_filtering(logits, top_k=4):
"""
只保留概率最高的top_k个token,其余设为负无穷
"""
top_k = min(top_k, logits.size(-1))
if top_k > 0:
# 获取第top_k大的值作为阈值
threshold = torch.topk(logits, top_k)[0][-1]
# 小于阈值的设为负无穷
indices_to_remove = logits < threshold
logits[indices_to_remove] = -float("Inf")
return logits不同top_k值的效果对比:
| top_k | 效果 | 多样性 | 连贯性 | 适用场景 |
|---|---|---|---|---|
| 1 | 确定性输出(贪心) | 极低 | 高 | 事实问答 |
| 4-10 | 轻度随机 | 中 | 高 | 对话系统(推荐) |
| 20-50 | 中度随机 | 高 | 中 | 故事生成 |
| >100 | 高度随机 | 极高 | 低 | 创意写作 |
5.3 重复惩罚(Repetition Penalty)
# 在每次预测前,降低已生成token的概率
for token_id in set(response): # set去重,避免重复惩罚
next_token_logits[token_id] /= repetition_penalty原理图解:
原始logits: 词A(已生成)=10, 词B(新)=8, 词C(新)=6
↓ 应用惩罚(除以1.5)
惩罚后: 词A=6.7, 词B=8, 词C=6
↓ softmax归一化
最终概率: 词A=30% → 22% (降低)
词B=35% → 42% (相对升高)
词C=20% → 24% (相对升高)
重复惩罚系数经验值:
| penalty | 效果 | 可能出现的问题 | 适用场景 |
|---|---|---|---|
| 1.0 | 无惩罚 | 容易复读 | ❌ 不推荐 |
| 1.1-1.2 | 轻度惩罚 | 基本无 | ✅ 短对话 |
| 1.2-1.5 | 中度惩罚 | 无 | ✅ 通用对话(推荐) |
| 1.5-2.0 | 重度惩罚 | 可能破坏语法 | ⚠️ 创造性任务 |
| >2.0 | 过度惩罚 | 语言不通顺 | ❌ 不推荐 |
本项目使用 repetition_penalty=10.0 的原因:
-
医疗对话需要高度专注,避免重复啰嗦
-
配合top_k=4使用,整体输出更紧凑
5.4 采样 vs 贪心搜索
# 贪心:每次都取最大概率(确定性强,但缺乏多样性)
next_token = torch.argmax(next_token_logits)
# 采样:按概率分布随机抽取(多样性好)
next_token = torch.multinomial(
F.softmax(filtered_logits, dim=-1),
num_samples=1
)两种方法对比:
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 贪心搜索 | 输出稳定、连贯性好 | 容易重复、缺乏创造性 | 翻译、摘要 |
| 随机采样 | 多样性强、更自然 | 可能产生不通顺内容 | 对话、故事生成 |
5.5 完整推理代码
def generate_response(model, input_ids, tokenizer, config):
"""
完整的推理生成流程
"""
response = []
for step in range(config.max_len):
# 1. 前向传播
outputs = model(input_ids)
logits = outputs.logits
# 2. 取最后一个位置
next_token_logits = logits[0, -1, :]
# 3. 应用重复惩罚
for tid in set(response):
next_token_logits[tid] /= config.repetition_penalty
# 4. 禁止[UNK]
unk_id = tokenizer.convert_tokens_to_ids("[UNK]")
next_token_logits[unk_id] = -float("Inf")
# 5. Top-K过滤
filtered_logits = top_k_filtering(
next_token_logits,
top_k=config.topk
)
# 6. 采样
next_token = torch.multinomial(
F.softmax(filtered_logits, dim=-1),
num_samples=1
)
# 7. 结束判断
if next_token.item() == tokenizer.sep_token_id:
break
# 8. 添加到响应序列
response.append(next_token.item())
input_ids = torch.cat([input_ids, next_token.unsqueeze(0)], dim=1)
return response六、多轮对话管理
6.1 历史对话维护策略
class DialogueManager:
def __init__(self, max_history_len=3):
self.history = [] # [[Q1_tokens], [A1_tokens], [Q2_tokens], ...]
self.max_history_len = max_history_len
def build_input(self, current_query, tokenizer):
"""构建包含历史对话的模型输入"""
# 添加当前用户输入
current_ids = tokenizer.encode(current_query, add_special_tokens=False)
self.history.append(current_ids)
# 构建输入序列
input_ids = [tokenizer.cls_token_id]
# 拼接最近N轮对话(保留上下文)
for utterance in self.history[-self.max_history_len * 2:]: # 问题+回答
input_ids.extend(utterance)
input_ids.append(tokenizer.sep_token_id)
return input_ids
def add_response(self, response_ids):
"""保存模型回答到历史"""
self.history.append(response_ids)6.2 窗口大小选择
| max_history_len | 上下文长度 | 显存占用 | 适用场景 |
|---|---|---|---|
| 1 | 单轮问答 | 小 | 简单FAQ |
| 3 | 3轮对话 | 中 | 通用对话(推荐) |
| 5 | 5轮对话 | 大 | 长对话场景 |
| 10 | 10轮对话 | 很大 | 故事生成 |
经验值:max_history_len=3 能覆盖90%的对话场景,且显存可控。
七、训练配置参数参考
7.1 超参数配置表
class TrainingConfig:
# 数据参数
max_len = 300 # 序列最大长度
max_history_len = 3 # 历史对话轮数
# 训练参数
batch_size = 4 # 单卡batch size
gradient_accumulation_steps = 4 # 梯度累积步数
epochs = 20 # 训练轮数
learning_rate = 2.6e-5 # 学习率
# 优化参数
warmup_steps = 500 # 预热步数
max_grad_norm = 2.0 # 梯度裁剪阈值
eps = 1e-9 # AdamW的epsilon
# 生成参数
topk = 4 # Top-K值
repetition_penalty = 10.0 # 重复惩罚系数7.2 显存占用估算
| 配置 | Batch Size | 序列长度 | 显存占用 | 训练速度 |
|---|---|---|---|---|
| 低配 | 2 | 256 | 8-10GB | 慢 |
| 中配(本项目) | 4 | 300 | 12-16GB | 中等 |
| 高配 | 8 | 300 | 20-24GB | 快 |
7.3 训练时间预估
| Epoch | 步数 | 耗时 | 累计时间 |
|---|---|---|---|
| 1-5 | ~2000 | 20分钟/epoch | 1.5小时 |
| 6-10 | ~2000 | 25分钟/epoch | 3.5小时 |
| 11-15 | ~2000 | 30分钟/epoch | 6小时 |
| 16-20 | ~2000 | 35分钟/epoch | 9小时 |
耗时增加原因:随着训练进行,模型生成的序列变长,前向传播计算量增加。
八、常见问题与解决方案
8.1 训练Loss不下降
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| Loss始终>5 | 学习率过大或过小 | 调整lr到1e-5 ~ 5e-5 |
| Loss震荡严重 | Batch Size太小 | 增大batch或梯度累积 |
| 验证Loss上升 | 过拟合 | 增加dropout、早停 |
8.2 生成效果差
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| 总是重复 | 惩罚系数太小 | 增大repetition_penalty |
| 回答太短 | max_len太小 | 增大到500+ |
| 答非所问 | 上下文丢失 | 增加max_history_len |
| 生成[UNK] | 词表不匹配 | 检查tokenizer和模型 |
8.3 显存不足(OOM)
OOM是深度学习训练中最常见的错误之一,表示GPU显存不够用。
| 解决方案 | 效果 | 代价 |
|---|---|---|
| 减小batch_size | 立竿见影 | 训练变慢 |
| 梯度累积 | 模拟大batch | 训练变慢 |
| 混合精度训练(FP16) | 显存减半 | 几乎无 |
| 梯度检查点 | 显存降70% | 时间+30% |
九、总结与展望
9.1 项目成果
✅ 完整实现了中文对话机器人的全流程
✅ 深入理解了GPT-2的底层原理
✅ 掌握了梯度累积、采样策略等关键技术
✅ 构建了可交互的Web界面
9.2 关键技术决策回顾
| 决策点 | 选择 | 理由 |
|---|---|---|
| 对话格式 | [CLS] Q [SEP] A [SEP] |
让模型学会对话结构 |
| 序列长度 | 300 | 覆盖90%数据 |
| 梯度累积 | 4步 | 有效batch=16 |
| 采样策略 | Top-K=4 + 采样 | 平衡质量与多样性 |
| 重复惩罚 | 10.0 | 医疗场景需要专注 |
9.3 进阶优化方向
-
Beam Search:代替随机采样,提高回答质量
-
温度参数:动态控制生成随机性
-
前缀约束:强制回答以特定模式开头
-
RLHF优化:用人类反馈微调
写在最后
从零实现一个对话机器人是一次非常有价值的实践。它不仅让我深入理解了Transformer的工作原理,更让我明白了从论文到工程落地的完整路径。
希望这份详细的实战记录能帮助到同样在学习大模型的朋友。代码已整理成完整的项目,欢迎交流讨论。
保持好奇,持续学习。 🚀
近期因为一些工作上的事情停止了技术文档的更新,现在又续上了,学友们关注走一波,AI时代,持续学习!!!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)