CAMUS心脏超声图像分割数据集
一、CAMUS 数据集简介
CAMUS Dataset 是一个公开的心脏超声医学影像数据集,主要用于超声心动图(Echocardiography)中的心脏结构分割任务。
CAMUS 全称为:
Cardiac Acquisitions for Multi-structure Ultrasound Segmentation
该数据集由法国研究团队公开发布,在医学图像分割、心脏结构识别、超声图像分析等方向中应用非常广泛。
CAMUS 的主要研究目标包括:
- 左心室(LV)分割
- 心肌(MYO)分割
- 左心房(LA)分割
- 心脏功能分析
- 超声医学图像语义分割
由于超声图像天然存在:
- 噪声大
- 边缘模糊
- 对比度低
- 伪影严重
因此 CAMUS 也是医学图像领域中非常经典且具有挑战性的分割数据集之一。
二、 CAMUS目标分割数据集
为简化图像读取与数据处理流程,本文对原始 .mhd 与 .zraw 格式的医学影像数据进行了预处理,将所有超声图像切片统一转换为常见的 .jpg 格式。同时,依据官方标注信息生成了适用于深度学习任务的标签文件,并将分割标注整理为 JSON、Mask 以及 YOLO 三种格式。该处理方式提升了数据的通用性与工程可用性,使数据集能够直接用于如 U-Net、DeepLabV3+、SegFormer 以及 YOLOSeg 等主流语义分割模型的训练与评估任务。

CAMUS 数据集主要包含以下几个核心类别,同时本文针对不同标签格式分别定义了对应的类别编号,方便模型训练与标签解析。
在 Mask 标签中,采用单通道灰度值表示不同类别,其中:
| 像素值(ID) | 类别名称 | 英文缩写 | 说明 |
|---|---|---|---|
| 0 | 背景 | Background | Background |
| 1 | 左心室 | LV | Left Ventricle |
| 2 | 心肌 | MYO | Myocardium |
| 3 | 左心房 | LA | Left Atrium |
由于 YOLO 系列模型通常从 0 开始编号,因此在 YOLO 标签格式中,类别 ID 定义如下:
| 类别ID | 类别名称 | 英文缩写 |
|---|---|---|
| 0 | 左心室 | LV |
| 1 | 心肌 | MYO |
| 2 | 左心房 | LA |
其中:
- LV(左心室)是最核心的分割目标,常用于心室结构分析与射血分数(EF)估计;
- MYO(心肌)主要用于心肌厚度及心功能分析;
- LA(左心房)则常用于心脏功能评估与相关疾病辅助诊断。
统一后的类别定义能够方便后续进行:
- Mask 灰度值解析;
- YOLOSeg 标签生成;
- JSON 标注转换;
- 多模型训练与推理部署。
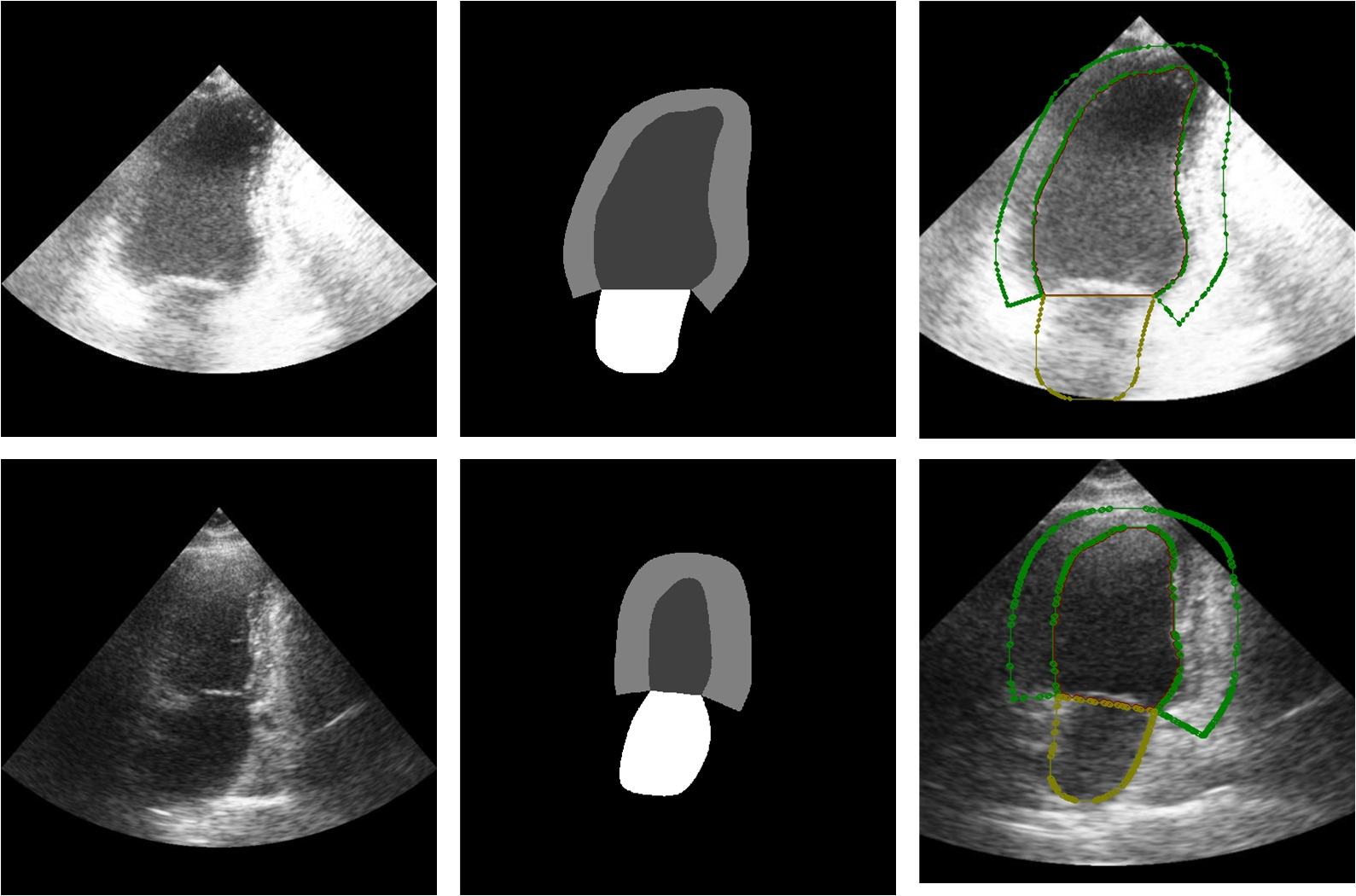
为了更直观地展示处理后的数据效果,下面展示部分转换后的 CAMUS 心脏超声图像切片,以及对应的 Mask 分割标注可视化结果与 LabelMe 标注可视化结果。通过可视化可以清晰观察到左心室(LV)、心肌(MYO)与左心房(LA)等关键心脏结构的分割区域,同时也验证了数据格式转换与标注生成的正确性。
三、格式转换代码
3.1 mask转json
为了提升数据集的通用性与标注可视化能力,本文首先将语义分割 Mask 标签转换为 LabelMe 所使用的 JSON 标注格式。该过程的核心思想是:**从 Mask 图像中提取不同类别的分割区域轮廓,并将轮廓点转换为多边形坐标信息保存到 JSON 文件中。**在转换过程中,程序首先读取单通道 Mask 图像,并根据像素值区分不同类别。随后,利用 OpenCV 的 findContours() 方法提取每个类别对应的轮廓区域,并将轮廓点保存为 LabelMe 所需的 polygon 多边形格式。此外,为避免噪声区域影响标注质量,代码中还通过轮廓面积过滤掉较小的无效区域,从而提升生成标注的准确性与可读性。
import cv2
import json
import numpy as np
import os
# 类别映射
class_dict = {
"LV_cavity": 1, # 左心室心腔
"MYO": 2, # 左心室心肌
"LA": 3, # 左心房
}
# 反向映射
id_to_class = {v: k for k, v in class_dict.items()}
def mask_to_json(mask_path, save_json_path, image_path=None):
"""
mask 转 Labelme json
Args:
mask_path: mask png 路径
save_json_path: 保存 json 路径
image_path: 原图路径(可选)
"""
# 读取 mask
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
if mask is None:
print(f"读取失败: {mask_path}")
return
height, width = mask.shape
shapes = []
# 遍历所有类别
for class_id, class_name in id_to_class.items():
# 提取当前类别区域
binary_mask = (mask == class_id).astype(np.uint8)
if binary_mask.sum() == 0:
continue
# 查找轮廓
contours, hierarchy = cv2.findContours(
binary_mask,
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE
)
# 遍历轮廓
for contour in contours:
# 过滤太小区域
area = cv2.contourArea(contour)
if area < 10:
continue
# contour -> points
points = contour.squeeze()
# 防止只有一个点
if len(points.shape) != 2:
continue
points_list = points.astype(float).tolist()
shape = {
"label": class_name,
"points": points_list,
"group_id": None,
"description": "",
"shape_type": "polygon",
"flags": {}
}
shapes.append(shape)
# 构建 Labelme json
json_data = {
"version": "5.0.1",
"flags": {},
"shapes": shapes,
"imagePath": os.path.basename(image_path) if image_path else "",
"imageData": None,
"imageHeight": height,
"imageWidth": width
}
# 保存 json
with open(save_json_path, 'w', encoding='utf-8') as f:
json.dump(json_data, f, indent=4, ensure_ascii=False)
print(f"保存成功: {save_json_path}")
if __name__ == "__main__":
mask_root = r"labels_mask"
save_json_root = r"labels_json"
image_root = r"images"
os.makedirs(save_json_root, exist_ok=True)
for file in os.listdir(mask_root):
name, ext = os.path.splitext(file)
mask_path = os.path.join(mask_root, file)
image_path = os.path.join(image_root, f"{name}.jpg")
save_json_path = os.path.join(save_json_root, f"{name}.json")
mask_to_json(
mask_path=mask_path,
save_json_path=save_json_path,
image_path=image_path
)
3.2 json转yolo
为了支持 YOLO 系列实例分割模型(如 YOLO-seg)的训练,本文提供了将 LabelMe 生成的 JSON 标注文件转换为 YOLO 实例分割格式 的转换代码。该过程的核心在于:提取 JSON 文件中的多边形坐标点,并将其按照图像尺寸进行归一化处理,以满足 YOLO 格式对坐标规范的要求。代码如下所示:
import json
import os
class_dict = {
"LV_cavity": 0, # 左心室心腔
"MYO": 1, # 左心室心肌
"LA": 2, # 左心房
}
def translate_info(label_json, label_txt):
# 检查json文件是否存在
assert os.path.exists(label_json), "file:{} not exist...".format(label_json)
# read json
with open(label_json, "r") as f1:
data = json.load(f1)
img_height = data['imageHeight']
img_width = data['imageWidth']
object_num = len(data['shapes'])
with open(label_txt, "w+") as f:
for index in range(object_num):
seg_label = []
# 获取每个object的类别信息和关键点信息
class_name = data['shapes'][index]['label']
class_index = class_dict[class_name] # 目标id从0开始
seg_label.append(class_index)
seg_points = data['shapes'][index]['points']
for point in seg_points:
point_x = round(point[0] / img_width, 6)
point_y = round(point[1] / img_height, 6)
seg_label.append(point_x)
seg_label.append(point_y)
info = [str(i) for i in seg_label]
f.write(" ".join(info) + "\n")
def main():
label_json_path = r"labels_json"
label_txt_path = r"E:labels_yolo"
label_list = os.listdir(label_json_path)
label_list = [label for label in label_list if label.endswith('.json')]
for label_name in label_list:
label_name = label_name.split(".json")[0]
label_xml = os.path.join(label_json_path, label_name + ".json")
label_txt = os.path.join(label_txt_path, label_name + ".txt")
translate_info(label_xml, label_txt)
if __name__ == "__main__":
main()
基于上述处理流程,CAMUS心脏超声分割数据集已完成图像和标签的标准化转换,将统一提供如下内容:
- 经过预处理并转换为
.png格式的 CT 图像; - 对应的 三种类型的标注文件,包括:
- YOLO 格式(用于yolo系列的实例分割);
- Mask 图像格式(用于 UNet 系列分割模型);
- LabelMe 原始 JSON 格式(便于可视化与进一步编辑)。
关于CAMUS心脏超声分割数据集均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)