《中华民族站起来了,AI驱动上下五千年:从结绳记事到智能纪元-甲骨占卜——基于“裂纹API“的决策支持系统 》
第二章:甲骨占卜——基于"裂纹API"的决策支持系统







1.历史现场:殷商宫廷的决策时刻
时间:公元前1250年,殷商武丁时期
地点:安阳殷墟,王室宗庙
人物:商王武丁、贞人(占卜师)、史官
青铜鼎中炭火正旺,映照着武丁凝重的面容。北方鬼方部落侵扰边境,战与不战,需问于天。
贞人取出一块精心打磨的龟腹甲,这是来自南方的贡品,已在清水中浸泡多日。他手持青铜钻,在龟甲背面刻下一行小字:
然后,将龟甲置于炭火之上。时间一分一秒过去,龟甲发出细微的爆裂声。终于,"啪"的一声脆响,一道裂纹自钻凿处延伸开来,如闪电劈开夜空。
贞人俯身细看,裂纹分为两枝:一枝较长而直,一枝较短而曲。他抬头禀报:"大王,此为'吉兆'。长枝为主,表示我方正;短枝为客,表示鬼方弱。裂纹清晰无杂纹,表示天意明确。"
史官迅速在龟甲正面刻下占卜结果:"王占曰:吉,其来。三日丙子允有来。"
三日后,边境捷报传来:鬼方部落被击退。从此,这片龟甲与千万片同样刻着文字的甲骨一起,被珍藏于地下窖穴,沉睡三千年。
2.全栈解构:占卜系统的技术架构
1. 系统架构图
# 占卜问题解析系统
class OracleQueryParser:
"""解析商王的自然语言问题,转换为占卜指令"""
def __init__(self):
# 商代语法规则(简化版)
self.syntax_rules = {
'time_prefix': ['今', '来', '昔'], # 时间前缀
'question_marker': ['贞', '问'], # 疑问标记
'action_verbs': ['伐', '征', '往', '来', '受', '雨'], # 行动动词
'entities': ['王', '鬼方', '土方', '羌方', '天', '帝'] # 实体
}
# 问题类型分类
self.question_types = {
'military': ['伐', '征', '战'], # 军事
'weather': ['雨', '风', '旱'], # 天气
'harvest': ['年', '穑', '丰'], # 收成
'health': ['疾', '梦', '死'], # 健康
'ritual': ['祭', '祀', '告'] # 祭祀
}
def parse_query(self, natural_language: str) -> dict:
"""解析自然语言查询"""
# 示例输入:"癸酉卜,争贞:今一月鬼方其来?"
# 输出结构化的占卜请求
query = {
"raw_text": natural_language,
"date": self._extract_date(natural_language),
"diviner": self._extract_diviner(natural_language),
"question": self._extract_question(natural_language),
"question_type": self._classify_question(natural_language),
"entities": self._extract_entities(natural_language),
"priority": self._determine_priority(natural_language)
}
return query
def _extract_date(self, text: str) -> str:
"""提取日期(干支纪日)"""
# 简单匹配干支
import re
gan_zhi = re.search(r'[甲乙丙丁戊己庚辛壬癸][子丑寅卯辰巳午未申酉戌亥]', text)
return gan_zhi.group(0) if gan_zhi else "未知"
def _extract_diviner(self, text: str) -> str:
"""提取贞人姓名"""
# 格式通常为"某某贞"
if '贞' in text:
parts = text.split('贞')
if len(parts) > 0:
# 取"贞"前的一个字
return parts[0][-1] if len(parts[0]) > 0 else "佚名"
return "佚名"
def _extract_question(self, text: str) -> str:
"""提取核心问题"""
# 移除日期和贞人信息
import re
# 匹配冒号或问号之间的内容
match = re.search(r'[::](.*?)[??]', text)
if match:
return match.group(1).strip()
return text
def _classify_question(self, text: str) -> str:
"""分类问题类型"""
for q_type, keywords in self.question_types.items():
for keyword in keywords:
if keyword in text:
return q_type
return "general"
def _extract_entities(self, text: str) -> list:
"""提取提及的实体"""
entities = []
for entity in self.syntax_rules['entities']:
if entity in text:
entities.append(entity)
return entities
def _determine_priority(self, text: str) -> int:
"""确定问题优先级"""
priority_keywords = {
'王': 3, # 商王相关,高优先级
'伐': 3, # 征伐,高优先级
'疾': 2, # 疾病,中优先级
'雨': 1, # 天气,低优先级
}
priority = 1
for keyword, value in priority_keywords.items():
if keyword in text and value > priority:
priority = value
return priority
# 使用示例
if __name__ == "__main__":
parser = OracleQueryParser()
# 测试几个甲骨文例句
test_queries = [
"癸酉卜,争贞:今一月鬼方其来?",
"乙未卜,宾贞:王梦,唯祸?",
"戊申卜,旅贞:今日其雨?",
"辛丑卜,亘贞:王往逐兕,获?"
]
for query in test_queries:
result = parser.parse_query(query)
print(f"原始: {query}")
print(f"解析: {result}")
print("-" * 50)
2.2 处理层:裂纹生成算法
# 裂纹生成模拟系统
import numpy as np
import random
from typing import List, Tuple, Dict
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import hashlib
class CrackGenerator:
"""模拟龟甲裂纹生成的物理过程"""
def __init__(self, seed=None):
self.seed = seed or random.randint(0, 10000)
np.random.seed(self.seed)
# 裂纹生成参数
self.params = {
'temperature': 800.0, # 温度(摄氏度)
'thickness': 2.5, # 龟甲厚度(毫米)
'moisture': 0.15, # 含水率
'drill_depth': 1.0, # 钻凿深度
'carbon_content': 0.3, # 碳含量
}
# 裂纹类型数据库
self.crack_patterns = {
'ji': { # 吉
'main_branch_length': 0.7,
'branch_count': 2,
'angle_variance': 15,
'smoothness': 0.8
},
'xiong': { # 凶
'main_branch_length': 0.3,
'branch_count': 4,
'angle_variance': 45,
'smoothness': 0.3
},
'hui': { # 悔
'main_branch_length': 0.5,
'branch_count': 3,
'angle_variance': 30,
'smoothness': 0.6
},
'lin': { # 吝
'main_branch_length': 0.4,
'branch_count': 1,
'angle_variance': 10,
'smoothness': 0.9
}
}
def generate_crack_from_question(self, question_text: str, pattern_type=None):
"""根据问题生成裂纹"""
# 用问题的哈希值作为随机种子,确保相同问题产生相同裂纹
question_hash = int(hashlib.md5(question_text.encode()).hexdigest()[:8], 16)
random.seed(question_hash)
# 如果没有指定类型,根据问题内容决定
if not pattern_type:
pattern_type = self._predict_pattern_from_question(question_text)
pattern = self.crack_patterns.get(pattern_type, self.crack_patterns['ji'])
# 生成裂纹
cracks = []
start_point = (0.5, 0.5) # 中心点
# 主裂纹
main_length = pattern['main_branch_length']
main_angle = random.uniform(0, 360)
end_point = self._calculate_endpoint(start_point, main_length, main_angle)
cracks.append({
'type': 'main',
'points': [start_point, end_point],
'width': 3.0
})
# 分支裂纹
branch_count = pattern['branch_count']
for i in range(branch_count):
branch_length = main_length * random.uniform(0.2, 0.5)
# 在主裂纹上随机选取分叉点
t = random.uniform(0.3, 0.7)
branch_start = (
start_point[0] + (end_point[0] - start_point[0]) * t,
start_point[1] + (end_point[1] - start_point[1]) * t
)
branch_angle = main_angle + random.uniform(-pattern['angle_variance'], pattern['angle_variance'])
branch_end = self._calculate_endpoint(branch_start, branch_length, branch_angle)
cracks.append({
'type': 'branch',
'points': [branch_start, branch_end],
'width': 1.5
})
return {
'pattern_type': pattern_type,
'cracks': cracks,
'parameters': self.params,
'question_hash': question_hash
}
def _predict_pattern_from_question(self, question: str) -> str:
"""根据问题内容预测裂纹类型"""
# 简单的关键词匹配
positive_keywords = ['吉', '利', '受', '获', '来']
negative_keywords = ['凶', '祸', '疾', '死', '不']
positive_count = sum(1 for word in positive_keywords if word in question)
negative_count = sum(1 for word in negative_keywords if word in question)
if positive_count > negative_count:
return 'ji'
elif negative_count > positive_count:
return 'xiong'
elif '悔' in question:
return 'hui'
elif '吝' in question:
return 'lin'
else:
return random.choice(list(self.crack_patterns.keys()))
def _calculate_endpoint(self, start, length, angle):
"""计算终点坐标"""
import math
rad = math.radians(angle)
end_x = start[0] + length * math.cos(rad)
end_y = start[1] + length * math.sin(rad)
return (end_x, end_y)
def visualize_crack(self, crack_data, size=512, save_path=None):
"""可视化裂纹"""
img = Image.new('RGB', (size, size), color='white')
draw = ImageDraw.Draw(img)
# 绘制龟甲轮廓
oval_bbox = (size*0.1, size*0.1, size*0.9, size*0.9)
draw.ellipse(oval_bbox, outline='#8B4513', width=5)
# 绘制裂纹
for crack in crack_data['cracks']:
points = crack['points']
# 转换为像素坐标
pixel_points = []
for x, y in points:
px = oval_bbox[0] + (oval_bbox[2] - oval_bbox[0]) * x
py = oval_bbox[1] + (oval_bbox[3] - oval_bbox[1]) * y
pixel_points.append((px, py))
width = crack['width']
color = '#000000' # 黑色裂纹
if len(pixel_points) >= 2:
draw.line(pixel_points, fill=color, width=int(width))
# 添加文字说明
pattern_type = crack_data['pattern_type']
type_chinese = {'ji': '吉', 'xiong': '凶', 'hui': '悔', 'lin': '吝'}
draw.text((10, 10), f"裂纹类型: {type_chinese.get(pattern_type, pattern_type)}", fill='black')
if save_path:
img.save(save_path)
return img
# 使用示例
if __name__ == "__main__":
# 创建裂纹生成器
generator = CrackGenerator(seed=42)
# 测试问题
test_question = "癸酉卜,争贞:今一月鬼方其来?"
# 生成裂纹
crack_data = generator.generate_crack_from_question(test_question)
print("裂纹数据:")
print(f"类型: {crack_data['pattern_type']}")
print(f"裂纹数量: {len(crack_data['cracks'])}")
print(f"问题哈希: {crack_data['question_hash']}")
# 可视化
img = generator.visualize_crack(crack_data, save_path="oracle_crack.png")
img.show()
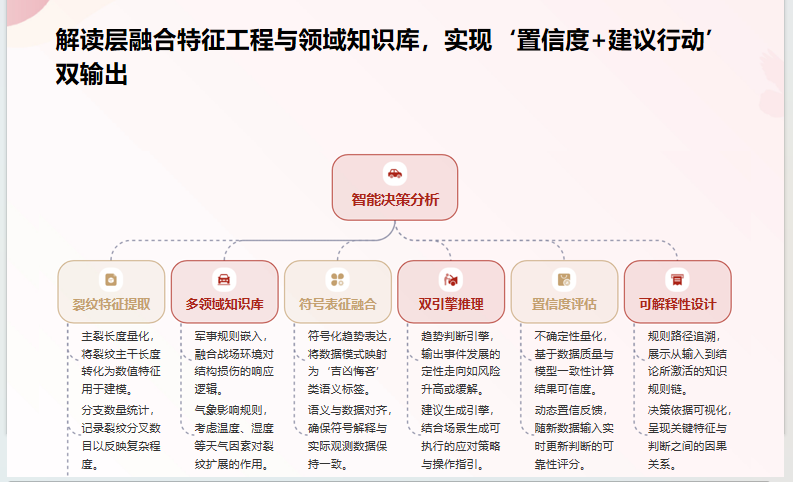
2.3 解读层:裂纹模式识别
# 裂纹模式识别与解读
class CrackInterpreter:
"""解读裂纹模式,生成占卜结果"""
def __init__(self):
# 裂纹特征词典
self.feature_dict = {
'length': {
'long': ('吉', '事情顺利,有长远发展'),
'medium': ('平', '平稳发展,无大碍'),
'short': ('凶', '发展受阻,需谨慎')
},
'branch_count': {
'few': ('吉', '目标明确,干扰少'),
'some': ('平', '有些复杂,但可处理'),
'many': ('凶', '头绪繁多,易混乱')
},
'angle': {
'straight': ('吉', '方向正确,坚持即可'),
'slight_curve': ('平', '需微调方向'),
'sharp_curve': ('凶', '方向有误,需调整')
},
'intersection': {
'clear': ('吉', '条理清晰,无冲突'),
'slight_overlap': ('平', '小有冲突,可协调'),
'complex_overlap': ('凶', '矛盾交织,需理清')
}
}
# 领域知识库
self.domain_knowledge = {
'military': {
'吉': '宜主动出击,胜算较大',
'凶': '宜坚守防御,不宜冒进',
'悔': '战术需调整,可转危为安',
'吝': '资源不足,需补充粮草'
},
'weather': {
'吉': '风调雨顺,适宜农事',
'凶': '可能有灾,需做准备',
'悔': '天气多变,需灵活应对',
'吝': '局部不利,整体无碍'
},
'harvest': {
'吉': '丰收在望,仓廪充实',
'凶': '收成不佳,需节粮',
'悔': '部分受灾,整体尚可',
'吝': '需精耕细作,加强管理'
}
}
def interpret_crack(self, crack_data, question_type="general") -> dict:
"""解读裂纹数据"""
cracks = crack_data['cracks']
pattern_type = crack_data['pattern_type']
# 提取特征
features = self._extract_features(cracks)
# 基础解读
base_interpretation = self._get_base_interpretation(pattern_type)
# 特征解读
feature_interpretations = []
for feature_name, value in features.items():
if feature_name in self.feature_dict:
categories = self.feature_dict[feature_name]
# 找到最接近的类别
if isinstance(value, (int, float)):
if value > 0.7:
category = list(categories.keys())[0] # 第一类
elif value > 0.3:
category = list(categories.keys())[1] # 第二类
else:
category = list(categories.keys())[2] # 第三类
result, explanation = categories[category]
feature_interpretations.append({
'feature': feature_name,
'value': value,
'result': result,
'explanation': explanation
})
# 领域特定解读
domain_advice = ""
if question_type in self.domain_knowledge:
if pattern_type in self.domain_knowledge[question_type]:
domain_advice = self.domain_knowledge[question_type][pattern_type]
# 生成最终结果
final_result = {
'pattern_type': pattern_type,
'overall_result': base_interpretation['result'],
'confidence': self._calculate_confidence(features),
'interpretation': base_interpretation['explanation'],
'feature_analysis': feature_interpretations,
'domain_advice': domain_advice,
'recommended_action': self._generate_action(pattern_type, question_type),
'timing': self._suggest_timing(features)
}
return final_result
def _extract_features(self, cracks):
"""从裂纹中提取特征"""
features = {}
if not cracks:
return features
# 计算主裂纹长度
main_cracks = [c for c in cracks if c['type'] == 'main']
if main_cracks:
points = main_cracks[0]['points']
if len(points) >= 2:
import math
x1, y1 = points[0]
x2, y2 = points[1]
length = math.sqrt((x2-x1)**2 + (y2-y1)**2)
features['length'] = length
# 计算分支数量
branch_cracks = [c for c in cracks if c['type'] == 'branch']
features['branch_count'] = len(branch_cracks) / 10 # 归一化
# 角度变化(简化)
if main_cracks and len(main_cracks[0]['points']) >= 2:
x1, y1 = main_cracks[0]['points'][0]
x2, y2 = main_cracks[0]['points'][1]
angle = math.atan2(y2-y1, x2-x1)
features['angle'] = abs(angle) / math.pi
return features
def _get_base_interpretation(self, pattern_type):
"""获取基础解读"""
interpretations = {
'ji': {
'result': '吉',
'explanation': '大吉大利,事情发展顺利,可积极行动。'
},
'xiong': {
'result': '凶',
'explanation': '凶险不利,宜谨慎保守,避免重大决策。'
},
'hui': {
'result': '悔',
'explanation': '小有遗憾,但可补救,需调整策略。'
},
'lin': {
'result': '吝',
'explanation': '有所阻碍,进展缓慢,需耐心等待。'
}
}
return interpretations.get(pattern_type, interpretations['ji'])
def _calculate_confidence(self, features):
"""计算解读置信度"""
if not features:
return 0.5
# 简单平均
total = sum(features.values())
count = len(features)
avg = total / count if count > 0 else 0
# 归一化到0.5-1.0
confidence = 0.5 + avg * 0.5
return min(max(confidence, 0.5), 1.0)
def _generate_action(self, pattern_type, question_type):
"""生成建议行动"""
actions = {
'military': {
'ji': '立即出兵,趁胜追击',
'xiong': '坚守不出,加固城防',
'hui': '调整战术,择机再战',
'lin': '补充粮草,等待时机'
},
'general': {
'ji': '积极行动,把握时机',
'xiong': '暂停计划,重新评估',
'hui': '小幅调整,继续推进',
'lin': '维持现状,积蓄力量'
}
}
domain = question_type if question_type in actions else 'general'
return actions[domain].get(pattern_type, '根据具体情况灵活应对')
def _suggest_timing(self, features):
"""建议时机"""
if 'length' in features:
if features['length'] > 0.7:
return '立即行动'
elif features['length'] > 0.4:
return '三日内'
else:
return '七日后'
return '适时而动'
# 使用示例
if __name__ == "__main__":
# 创建解读器
interpreter = CrackInterpreter()
# 模拟裂纹数据
test_crack_data = {
'pattern_type': 'ji',
'cracks': [
{'type': 'main', 'points': [(0.5, 0.5), (0.8, 0.7)], 'width': 3.0},
{'type': 'branch', 'points': [(0.6, 0.6), (0.7, 0.5)], 'width': 1.5},
{'type': 'branch', 'points': [(0.65, 0.65), (0.75, 0.8)], 'width': 1.5}
]
}
# 解读裂纹
result = interpreter.interpret_crack(test_crack_data, question_type='military')
print("裂纹解读结果:")
print(f"总体结果: {result['overall_result']}")
print(f"置信度: {result['confidence']:.2f}")
print(f"解读: {result['interpretation']}")
print(f"领域建议: {result['domain_advice']}")
print(f"建议行动: {result['recommended_action']}")
print(f"时机: {result['timing']}")
print("\n特征分析:")
for feature in result['feature_analysis']:
print(f" {feature['feature']}: {feature['value']:.2f} -> {feature['result']}: {feature['explanation']}")
- 现代重建:端到端的甲骨占卜系统
# 完整的甲骨占卜系统
import json
from datetime import datetime
from typing import Optional, Dict, Any
import hashlib
class ModernOracleSystem:
"""现代甲骨占卜系统"""
def __init__(self, llm_provider='openai'):
# 初始化组件
self.parser = OracleQueryParser()
self.generator = CrackGenerator()
self.interpreter = CrackInterpreter()
# 记录系统
self.records = []
self.record_file = 'oracle_records.json'
# 加载历史记录
self._load_records()
def _load_records(self):
"""加载历史记录"""
try:
with open(self.record_file, 'r', encoding='utf-8') as f:
self.records = json.load(f)
except FileNotFoundError:
self.records = []
def _save_records(self):
"""保存记录"""
with open(self.record_file, 'w', encoding='utf-8') as f:
json.dump(self.records, f, ensure_ascii=False, indent=2)
def consult(self, question: str, question_type: str = "general") -> Dict[str, Any]:
"""进行占卜咨询"""
# 1. 解析问题
parsed_query = self.parser.parse_query(question)
# 2. 生成裂纹
crack_data = self.generator.generate_crack_from_question(question)
# 3. 解读裂纹
interpretation = self.interpreter.interpret_crack(crack_data, question_type)
# 4. 生成甲骨文记录
oracle_record = self._create_oracle_record(parsed_query, crack_data, interpretation)
# 5. 保存记录
self.records.append(oracle_record)
self._save_records()
return oracle_record
def _create_oracle_record(self, query, crack_data, interpretation):
"""创建甲骨文格式的记录"""
# 日期(现代格式)
now = datetime.now()
gan_zhi_date = self._get_gan_zhi(now)
# 贞人(模拟)
diviners = ['争', '宾', '旅', '亘', '永', '古']
diviner = diviners[hash(query['raw_text']) % len(diviners)]
# 生成记录
record = {
'metadata': {
'id': f"ORACLE_{len(self.records)+1:06d}",
'timestamp': now.isoformat(),
'gan_zhi_date': gan_zhi_date,
'diviner': diviner,
'question_hash': crack_data.get('question_hash', 0)
},
'query': query,
'crack_data': {
'pattern_type': crack_data['pattern_type'],
'crack_count': len(crack_data['cracks'])
},
'interpretation': interpretation,
'oracle_text': self._generate_oracle_text(gan_zhi_date, diviner, query, interpretation)
}
return record
def _get_gan_zhi(self, date_obj):
"""获取干支日期(简化版)"""
# 实际干支计算很复杂,这里简化
gan = ['甲', '乙', '丙', '丁', '戊', '己', '庚', '辛', '壬', '癸']
zhi = ['子', '丑', '寅', '卯', '辰', '巳', '午', '未', '申', '酉', '戌', '亥']
day_num = date_obj.toordinal() # 从公元1年1月1日开始的天数
gan_index = day_num % 10
zhi_index = day_num % 12
return f"{gan[gan_index]}{zhi[zhi_index]}"
def _generate_oracle_text(self, date, diviner, query, interpretation):
"""生成甲骨文格式的文本"""
# 前辞:日期和贞人
preface = f"{date}卜,{diviner}贞:"
# 命辞:问题
question = query.get('question', query.get('raw_text', ''))
# 占辞:占卜结果
result_map = {'吉': '吉', '凶': '凶', '悔': '悔', '吝': '吝'}
result_char = result_map.get(interpretation['overall_result'], '吉')
prognostication = f"王占曰:{result_char}。"
# 验辞:建议(现代版)
advice = interpretation.get('recommended_action', '')
verification = f"用:{advice}"
return f"{preface}{question}?\n{prognostication}\n{verification}"
def get_statistics(self):
"""获取占卜统计"""
if not self.records:
return {}
stats = {
'total_consultations': len(self.records),
'result_distribution': {},
'question_type_distribution': {},
'accuracy_estimate': 0.0
}
# 结果分布
for record in self.records:
result = record['interpretation']['overall_result']
stats['result_distribution'][result] = stats['result_distribution'].get(result, 0) + 1
q_type = record['query'].get('question_type', 'general')
stats['question_type_distribution'][q_type] = stats['question_type_distribution'].get(q_type, 0) + 1
# 估算准确率(假设用户反馈机制)
positive_feedback = sum(1 for r in self.records if r.get('feedback') == 'positive')
if len(self.records) > 0:
stats['accuracy_estimate'] = positive_feedback / len(self.records)
return stats
def find_similar_cases(self, current_question, limit=5):
"""寻找相似的历史案例"""
if not self.records:
return []
# 简单的关键词匹配
similar_cases = []
for record in self.records[-100:]: # 最近100条
similarity = self._calculate_similarity(current_question, record['query']['raw_text'])
if similarity > 0.3: # 相似度阈值
similar_cases.append({
'similarity': similarity,
'record': record
})
# 按相似度排序
similar_cases.sort(key=lambda x: x['similarity'], reverse=True)
return similar_cases[:limit]
def _calculate_similarity(self, text1, text2):
"""计算文本相似度(简化版)"""
if not text1 or not text2:
return 0.0
# 转换为字符集合
set1 = set(text1)
set2 = set(text2)
if not set1 or not set2:
return 0.0
# Jaccard相似度
intersection = len(set1.intersection(set2))
union = len(set1.union(set2))
return intersection / union if union > 0 else 0.0
# 使用示例
if __name__ == "__main__":
# 创建占卜系统
oracle = ModernOracleSystem()
# 进行占卜
question = "癸酉卜,争贞:今一月鬼方其来?"
result = oracle.consult(question, question_type="military")
print("=" * 60)
print("甲骨占卜系统 - 占卜结果")
print("=" * 60)
print(f"\n�� 甲骨记录:")
print(result['oracle_text'])
print(f"\n�� 详细解读:")
interpretation = result['interpretation']
print(f"总体结果: {interpretation['overall_result']}")
print(f"解读: {interpretation['interpretation']}")
print(f"建议行动: {interpretation['recommended_action']}")
print(f"时机: {interpretation['timing']}")
print(f"置信度: {interpretation['confidence']:.2f}")
print(f"\n�� 特征分析:")
for feature in interpretation['feature_analysis']:
print(f" {feature['feature']}: {feature['result']} - {feature['explanation']}")
# 获取统计
stats = oracle.get_statistics()
print(f"\n�� 系统统计:")
print(f"总占卜次数: {stats['total_consultations']}")
print(f"结果分布: {stats['result_distribution']}")
print(f"准确率估计: {stats['accuracy_estimate']:.1%}")
# 寻找相似案例
similar = oracle.find_similar_cases(question)
if similar:
print(f"\n�� 相似历史案例 (找到{len(similar)}个):")
for i, case in enumerate(similar[:3], 1):
rec = case['record']
print(f" {i}. {rec['oracle_text'][:50]}... (相似度: {case['similarity']:.2f})")
4.AI关联:用现代AI工具增强占卜系统
4.1. 使用LangChain构建智能占卜Agent
# 使用LangChain构建甲骨占卜Agent
from typing import List, Dict, Any, Optional
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent
from langchain.prompts import BaseChatPromptTemplate
from langchain.schema import HumanMessage, SystemMessage
from langchain.chat_models import ChatOpenAI
from langchain.tools import BaseTool
from langchain.agents import AgentOutputParser
from langchain.schema import AgentAction, AgentFinish
import re
class OracleTool(BaseTool):
"""甲骨占卜工具"""
name = "oracle_divination"
description = "使用甲骨占卜系统进行决策咨询"
def __init__(self, oracle_system: ModernOracleSystem):
super().__init__()
self.oracle = oracle_system
def _run(self, query: str) -> str:
"""执行占卜"""
result = self.oracle.consult(query)
return f"""
占卜结果:
问题:{query}
结果:{result['interpretation']['overall_result']}
解读:{result['interpretation']['interpretation']}
建议:{result['interpretation']['recommended_action']}
时机:{result['interpretation']['timing']}
"""
async def _arun(self, query: str) -> str:
"""异步执行"""
return self._run(query)
class OraclePromptTemplate(BaseChatPromptTemplate):
"""甲骨占卜Agent的提示模板"""
def format_messages(self, **kwargs) -> List[HumanMessage]:
# 获取中间步骤
intermediate_steps = kwargs.get("intermediate_steps", [])
# 构建提示
prompt = """你是一个AI甲骨占卜师,结合现代AI技术和古代智慧帮助用户决策。
你拥有以下工具:
1. oracle_divination: 使用甲骨占卜系统
2. historical_analysis: 分析历史相似案例
3. risk_assessment: 风险评估
4. decision_framework: 决策框架分析
请按照以下步骤思考:
1. 理解用户的问题和上下文
2. 判断是否需要使用占卜工具
3. 如果使用,调用oracle_divination工具
4. 结合占卜结果和其他分析给出综合建议
当前对话:
{input}
{agent_scratchpad}"""
# 添加工具描述
tools_text = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
prompt = prompt.replace("{tools}", tools_text)
# 添加历史步骤
scratchpad = ""
for action, observation in intermediate_steps:
scratchpad += f"\n行动: {action.log}\n观察: {observation}"
prompt = prompt.replace("{agent_scratchpad}", scratchpad)
return [HumanMessage(content=prompt)]
class OracleAgent:
"""甲骨占卜Agent"""
def __init__(self, api_key: Optional[str] = None):
# 初始化LLM
self.llm = ChatOpenAI(
temperature=0.7,
openai_api_key=api_key,
model="gpt-4"
)
# 初始化甲骨系统
self.oracle_system = ModernOracleSystem()
# 创建工具
self.tools = [
OracleTool(self.oracle_system),
Tool(
name="historical_analysis",
func=self._analyze_history,
description="分析历史相似案例,提供参考"
),
Tool(
name="risk_assessment",
func=self._assess_risk,
description="评估决策风险,识别潜在问题"
),
Tool(
name="decision_framework",
func=self._apply_framework,
description="应用决策框架(如SWOT、成本效益分析)"
)
]
# 创建Agent
self.agent = self._create_agent()
def _analyze_history(self, query: str) -> str:
"""分析历史"""
similar = self.oracle_system.find_similar_cases(query, limit=3)
if not similar:
return "未找到相似历史案例。"
analysis = "找到以下相似历史案例:\n"
for i, case in enumerate(similar, 1):
rec = case['record']
analysis += f"{i}. 问题:{rec['query']['raw_text'][:50]}...\n"
analysis += f" 结果:{rec['interpretation']['overall_result']}\n"
analysis += f" 建议:{rec['interpretation']['recommended_action']}\n"
return analysis
def _assess_risk(self, query: str) -> str:
"""风险评估"""
# 简单的关键词风险评估
high_risk_keywords = ['战', '伐', '死', '疾', '祸']
medium_risk_keywords = ['变', '改', '迁', '大']
low_risk_keywords = ['问', '询', '小', '常']
high_count = sum(1 for kw in high_risk_keywords if kw in query)
medium_count = sum(1 for kw in medium_risk_keywords if kw in query)
low_count = sum(1 for kw in low_risk_keywords if kw in query)
if high_count > 0:
risk_level = "高"
elif medium_count > 0:
risk_level = "中"
else:
risk_level = "低"
return f"风险评估:{risk_level}。包含高风险词{high_count}个,中风险词{medium_count}个,低风险词{low_count}个。"
def _apply_framework(self, query: str) -> str:
"""应用决策框架"""
frameworks = {
"SWOT": "分析优势、劣势、机会、威胁",
"成本效益": "比较投入与预期回报",
"风险评估": "识别和评估潜在风险",
"多标准决策": "基于多个标准评估选项"
}
# 根据问题类型选择框架
if any(word in query for word in ['战', '伐', '竞']):
framework = "SWOT"
elif any(word in query for word in ['费', '本', '利']):
framework = "成本效益"
elif any(word in query for word in ['险', '危', '祸']):
framework = "风险评估"
else:
framework = "多标准决策"
return f"建议使用{framework}框架:{frameworks[framework]}"
def _create_agent(self):
"""创建Agent执行器"""
prompt = OraclePromptTemplate(tools=self.tools)
# 简化版Agent设置
agent = LLMSingleActionAgent(
llm_chain=None, # 简化处理
prompt=prompt,
tools=self.tools,
stop=["\n观察:"]
)
return AgentExecutor.from_agent_and_tools(
agent=agent,
tools=self.tools,
verbose=True
)
def consult(self, question: str) -> Dict[str, Any]:
"""咨询Agent"""
try:
result = self.agent.run(question)
return {
"success": True,
"answer": result,
"oracle_data": self.oracle_system.records[-1] if self.oracle_system.records else None
}
except Exception as e:
return {
"success": False,
"error": str(e),
"answer": "抱歉,占卜过程中出现了问题。"
}
# 使用示例
if __name__ == "__main__":
# 创建Agent
agent = OracleAgent()
# 咨询
questions = [
"我应该接受这份新工作吗?",
"这个项目投资风险大吗?",
"近期适合扩大团队规模吗?"
]
for question in questions[:1]: # 测试第一个
print(f"\n❓ 用户问题: {question}")
print("=" * 50)
result = agent.consult(question)
if result["success"]:
print(f"�� AI占卜师回答:\n{result['answer']}")
if result.get("oracle_data"):
oracle = result["oracle_data"]
print(f"\n�� 甲骨占卜结果: {oracle['interpretation']['overall_result']}")
print(f"�� 甲骨记录: {oracle['oracle_text']}")
else:
print(f"❌ 错误: {result['error']}")
4.2. 占卜系统的现代企业应用

# 企业决策支持系统
class CorporateDecisionSystem:
"""企业决策支持系统 - 现代版"占卜系统" """
def __init__(self, company_name: str):
self.company_name = company_name
self.decision_log = []
# 决策方法库
self.decision_methods = {
'swot': self._swot_analysis,
'cost_benefit': self._cost_benefit_analysis,
'risk_matrix': self._risk_matrix_analysis,
'multi_criteria': self._multi_criteria_decision,
'oracle': self._oracle_consultation # 集成甲骨占卜
}
# 初始化甲骨系统
self.oracle = ModernOracleSystem()
def make_decision(self,
problem: str,
options: List[str],
method: str = 'oracle',
context: Dict = None) -> Dict:
"""做出决策"""
decision_id = f"DEC_{len(self.decision_log)+1:06d}"
# 选择决策方法
if method in self.decision_methods:
analysis = self.decision_methods[method](problem, options, context)
else:
analysis = self.decision_methods['oracle'](problem, options, context)
# 记录决策
decision_record = {
'id': decision_id,
'timestamp': datetime.now().isoformat(),
'problem': problem,
'options': options,
'method': method,
'analysis': analysis,
'recommendation': self._generate_recommendation(analysis)
}
self.decision_log.append(decision_record)
return decision_record
def _oracle_consultation(self, problem: str, options: List[str], context: Dict = None) -> Dict:
"""使用甲骨占卜进行决策分析"""
# 为每个选项生成占卜
oracle_results = []
for i, option in enumerate(options):
# 构建占卜问题
question = f"关于'{problem}',选择'{option}'是否有利?"
# 确定问题类型
q_type = "business"
if any(word in problem for word in ['人', '员', '团队']):
q_type = "hr"
elif any(word in problem for word in ['资', '金', '钱']):
q_type = "finance"
elif any(word in problem for word in ['产', '品', '技']):
q_type = "product"
# 进行占卜
result = self.oracle.consult(question, q_type)
oracle_results.append({
'option': option,
'oracle_result': result['interpretation']['overall_result'],
'confidence': result['interpretation']['confidence'],
'reasoning': result['interpretation']['interpretation']
})
return {
'method': 'oracle_divination',
'results': oracle_results,
'summary': self._summarize_oracle_results(oracle_results)
}
def _summarize_oracle_results(self, results: List[Dict]) -> Dict:
"""汇总甲骨占卜结果"""
if not results:
return {}
# 统计结果
result_counts = {}
for r in results:
result = r['oracle_result']
result_counts[result] = result_counts.get(result, 0) + 1
# 找到最佳选项
best_option = max(results, key=lambda x: (
3 if x['oracle_result'] == '吉' else
2 if x['oracle_result'] == '悔' else
1 if x['oracle_result'] == '吝' else
0
))
return {
'best_option': best_option['option'],
'best_result': best_option['oracle_result'],
'result_distribution': result_counts,
'overall_tendency': 'positive' if result_counts.get('吉', 0) > len(results)/2 else 'cautious'
}
def _generate_recommendation(self, analysis: Dict) -> str:
"""生成推荐建议"""
if analysis['method'] == 'oracle_divination':
summary = analysis.get('summary', {})
best_option = summary.get('best_option', '未知')
best_result = summary.get('best_result', '未知')
recommendations = {
'吉': f"强烈推荐选择'{best_option}',前景光明,可积极实施。",
'悔': f"建议选择'{best_option}',但需注意调整细节,有小风险但可控。",
'吝': f"谨慎考虑'{best_option}',可能面临阻力,需充分准备。",
'凶': f"不建议选择'{best_option}',风险较大,建议重新评估。"
}
return recommendations.get(best_result, "需要更多信息进行分析。")
return "基于分析,请结合具体情况做出决策。"
def get_decision_history(self, filter_by: str = None):
"""获取决策历史"""
if filter_by:
return [d for d in self.decision_log if filter_by in d['method'] or filter_by in d['problem']]
return self.decision_log
def calculate_decision_accuracy(self) -> float:
"""计算决策准确率(需要反馈数据)"""
# 简化版:假设有反馈的决策中,正反馈的比例
decisions_with_feedback = [d for d in self.decision_log if d.get('feedback')]
if not decisions_with_feedback:
return 0.0
positive_feedback = sum(1 for d in decisions_with_feedback if d.get('feedback') == 'positive')
return positive_feedback / len(decisions_with_feedback)
# 使用示例
if __name__ == "__main__":
# 创建企业决策系统
company = CorporateDecisionSystem("未来科技公司")
# 模拟决策场景
scenarios = [
{
"problem": "是否推出新产品",
"options": ["立即推出", "延迟推出", "取消推出"],
"context": {"market": "competitive", "budget": "limited"}
},
{
"problem": "招聘新的技术总监",
"options": ["候选人A", "候选人B", "继续寻找"],
"context": {"urgency": "high", "team_size": 50}
}
]
for scenario in scenarios:
print(f"\n�� 企业决策: {scenario['problem']}")
print(f"选项: {', '.join(scenario['options'])}")
print("-" * 50)
# 使用甲骨占卜方法
decision = company.make_decision(
problem=scenario['problem'],
options=scenario['options'],
method='oracle',
context=scenario['context']
)
# 显示结果
print(f"�� 分析结果:")
analysis = decision['analysis']
if 'results' in analysis:
for result in analysis['results']:
print(f" {result['option']}: {result['oracle_result']} (置信度: {result['confidence']:.2f})")
print(f" 理由: {result['reasoning']}")
if 'summary' in analysis:
summary = analysis['summary']
print(f"\n�� 总结: 最佳选项是'{summary.get('best_option')}' ({summary.get('best_result')})")
print(f"\n�� 推荐: {decision['recommendation']}")
print(f"⏰ 决策时间: {decision['timestamp']}")
print()
4.3动手实践:构建你自己的"数字贞人"系统
1. 使用Dify快速搭建占卜应用
# dify-oracle-app.yaml
# 在Dify中快速搭建甲骨占卜应用
name: 智能甲骨占卜决策系统
description: 结合AI与古代智慧的决策支持工具
workflow:
nodes:
- id: input_question
type: input
variables:
- name: user_question
type: string
required: true
- name: question_type
type: string
default: "general"
options: ["business", "personal", "career", "health"]
- id: question_analyzer
type: llm
model: gpt-4
prompt: |
分析用户的问题:{{user_question}}
请提取:
1. 核心决策点
2. 涉及的主要因素
3. 用户的潜在顾虑
4. 建议的决策框架
用JSON格式返回。
- id: oracle_consultation
type: code
code: |
# 调用甲骨占卜API
import requests
def oracle_divination(question, q_type):
# 这里调用之前构建的占卜系统
# 实际部署时,可以封装为API服务
response = requests.post(
"https://api.oracle-system.com/consult",
json={"question": question, "type": q_type}
)
return response.json()
result = oracle_divination(user_question, question_type)
return {"oracle_result": result}
- id: modern_analysis
type: llm
model: claude-3
prompt: |
基于甲骨占卜结果,结合现代分析框架提供建议:
用户问题:{{user_question}}
占卜结果:{{oracle_result}}
请提供:
1. 传统智慧与现代分析的结合点
2. 具体的行动步骤建议
3. 风险预警与应对措施
4. 成功的关键指标
用清晰、实用的语言。
- id: final_output
type: code
code: |
# 生成最终输出
def format_output(analysis, oracle_result):
return {
"traditional_wisdom": {
"result": oracle_result.get("overall_result"),
"interpretation": oracle_result.get("interpretation")
},
"modern_analysis": analysis,
"integrated_advice": "结合古今智慧的建议...",
"timestamp": datetime.now().isoformat()
}
output = format_output(modern_analysis, oracle_result)
return output
- 使用Cursor AI助手优化代码

# 使用Cursor AI重构和优化甲骨占卜系统
# 在Cursor中,你可以用自然语言让AI助手帮你改进代码
"""
Cursor AI提示:请帮我优化这个甲骨占卜系统,使其:
1. 更模块化,便于维护
2. 添加类型提示
3. 提高性能
4. 添加完整的错误处理
5. 符合PEP 8规范
"""
from typing import List, Dict, Any, Optional, Tuple
from dataclasses import dataclass
from enum import Enum
import json
from datetime import datetime
import hashlib
import logging
from abc import ABC, abstractmethod
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class CrackPattern(Enum):
"""裂纹模式枚举"""
AUSPICIOUS = "吉" # 吉
INAUSPICIOUS = "凶" # 凶
REGRET = "悔" # 悔
DIFFICULTY = "吝" # 吝
@dataclass
class OracleQuery:
"""占卜查询数据结构"""
raw_text: str
date: str
diviner: str
question: str
question_type: str
entities: List[str]
priority: int
@dataclass
class CrackData:
"""裂纹数据"""
pattern: CrackPattern
cracks: List[Dict[str, Any]]
parameters: Dict[str, float]
question_hash: str
@dataclass
class Interpretation:
"""解读结果"""
overall_result: CrackPattern
confidence: float
interpretation: str
feature_analysis: List[Dict[str, Any]]
domain_advice: str
recommended_action: str
timing: str
class OracleComponent(ABC):
"""占卜系统组件的抽象基类"""
@abstractmethod
def process(self, input_data: Any) -> Any:
"""处理输入数据"""
pass
class QueryParser(OracleComponent):
"""查询解析器"""
def __init__(self):
self.syntax_rules = {
'time_prefix': ['今', '来', '昔'],
'question_marker': ['贞', '问'],
'action_verbs': ['伐', '征', '往', '来', '受', '雨'],
'entities': ['王', '鬼方', '土方', '羌方', '天', '帝']
}
self.question_types = {
'military': ['伐', '征', '战'],
'weather': ['雨', '风', '旱'],
'harvest': ['年', '穑', '丰'],
'health': ['疾', '梦', '死'],
'ritual': ['祭', '祀', '告']
}
def process(self, natural_language: str) -> OracleQuery:
"""解析自然语言查询"""
try:
return OracleQuery(
raw_text=natural_language,
date=self._extract_date(natural_language),
diviner=self._extract_diviner(natural_language),
question=self._extract_question(natural_language),
question_type=self._classify_question(natural_language),
entities=self._extract_entities(natural_language),
priority=self._determine_priority(natural_language)
)
except Exception as e:
logger.error(f"解析查询失败: {e}")
# 返回默认查询对象
return OracleQuery(
raw_text=natural_language,
date="未知",
diviner="佚名",
question=natural_language,
question_type="general",
entities=[],
priority=1
)
def _extract_date(self, text: str) -> str:
"""提取日期"""
import re
gan_zhi = re.search(r'[甲乙丙丁戊己庚辛壬癸][子丑寅卯辰巳午未申酉戌亥]', text)
return gan_zhi.group(0) if gan_zhi else "未知"
def _extract_diviner(self, text: str) -> str:
"""提取贞人"""
if '贞' in text:
parts = text.split('贞')
if parts and parts[0]:
return parts[0][-1]
return "佚名"
def _extract_question(self, text: str) -> str:
"""提取问题"""
import re
match = re.search(r'[::](.*?)[??]', text)
return match.group(1).strip() if match else text
def _classify_question(self, text: str) -> str:
"""分类问题"""
for q_type, keywords in self.question_types.items():
if any(keyword in text for keyword in keywords):
return q_type
return "general"
def _extract_entities(self, text: str) -> List[str]:
"""提取实体"""
return [entity for entity in self.syntax_rules['entities'] if entity in text]
def _determine_priority(self, text: str) -> int:
"""确定优先级"""
priority_keywords = {'王': 3, '伐': 3, '疾': 2, '雨': 1}
return max([priority for word, priority in priority_keywords.items()
if word in text], default=1)
class ModernOracleSystem:
"""现代甲骨占卜系统(优化版)"""
def __init__(self, config: Optional[Dict[str, Any]] = None):
self.config = config or {}
self.components = self._initialize_components()
self.records: List[Dict[str, Any]] = []
self._load_records()
def _initialize_components(self) -> Dict[str, OracleComponent]:
"""初始化组件"""
return {
'parser': QueryParser(),
'generator': CrackGenerator(),
'interpreter': CrackInterpreter()
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)