人工智能训练师(三级)通关全解:数据标注规范、模型评估指标与考场实操避坑指南

作者:刘巨波(参与《AI重塑生意经》及CSPM《中国项目管理知识体系》编写/ 优培东方首席讲师)
摘要
随着人工智能在各行业的渗透,人社部《人工智能训练师》职业技能等级认定已成为职场人切入AI赛道的重要凭证。然而,根据近年广东地区考场数据,实操环节的不通过率远高于理论考试。本文将深度拆解人工智能训练师(三级/四级)考试中数据标注一致性控制、模型训练参数调优与效果评估指标解读三大核心难点,结合真实考场的评分细则与工业界标准,提供一套可直接复用的备考框架与避坑指南。
一、考试全景与评分权重拆解
要高效备考,首先必须明确"考什么"与"怎么扣分"。
1. 三级实操考核模块分布
|
模块 |
核心任务 |
评分权重 |
常见失分点 |
|---|---|---|---|
|
数据采集与清洗 |
去重、异常值处理、格式标准化 |
15% |
漏删重复样本、编码格式错误 |
|
数据标注 |
图像框选/文本实体/语音切分 |
45% |
标注不一致、边界模糊、漏标 |
|
模型训练 |
平台操作、参数设置、训练监控 |
25% |
参数理解错误、过拟合未处理 |
|
效果评估 |
指标计算、混淆矩阵分析、报告撰写 |
15% |
指标概念混淆、无法解释结果 |
📌 关键结论:数据标注是分值最高、也是最容易产生"非技术性失分"的环节。
二、深度难点一:数据标注规范与一致性控制(决定生死)
在真实考场中,阅卷老师会随机抽取标注样本进行一致性校验(Consistency Check)。如果标注结果波动过大,即便模型跑通,也会被判"数据质量不合格"。
1. 标注一致性的量化标准:Cohen's Kappa
工业界与考评中常用的指标是 Cohen's Kappa (κ),用于衡量两名标注员(或自己前后两次标注)的一致性。
-
κ ≥ 0.81:几乎完全一致(满分)
-
κ = 0.61 ~ 0.80:高度一致(通过)
-
κ = 0.41 ~ 0.60:中度一致(有风险)
-
κ ≤ 0.4:一致性差(大概率挂科)
考场应对策略:
-
建立"最小判断单元":例如在图像标注中,明确"遮挡超过30%不标"、"边缘模糊归为'不确定'类"。
-
BIO 编码的严格执行:在文本实体标注中,必须严格遵守 Begin/Inside/Outside 规则。常见的错误是将
B-PER(实体开始)误标为I-PER,这在阅卷时是硬性扣分项。
2. 图像标注的几何精度
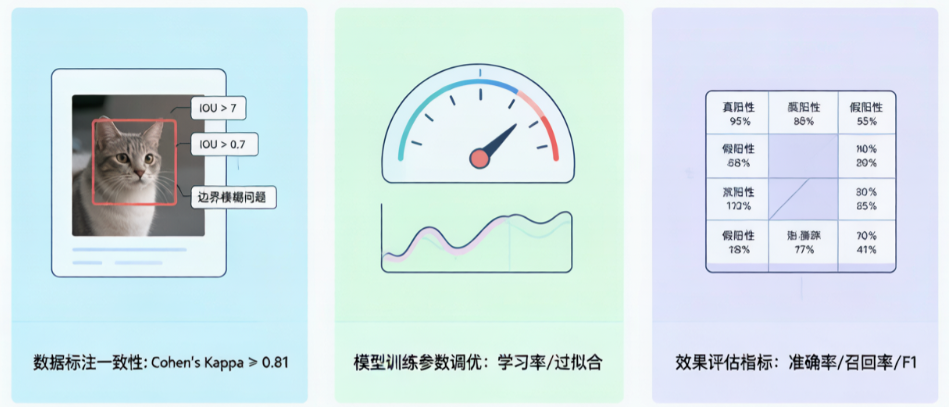
针对计算机视觉方向的考生,标注框的IOU(交并比)是隐形杀手。
-
考场通常要求标注框与真实物体重合度 IOU ≥ 0.7。
-
避坑技巧:不要紧贴物体边缘画框,应预留 5-10 像素的 Buffer(缓冲区),避免因轻微偏移导致 IOU 过低。
3. 数据清洗的"去重"陷阱
很多考生忽略了"数据清洗"模块的隐性要求。单纯的删除肉眼重复图片是不够的,需要掌握哈希去重(Perceptual Hash)的概念。
-
考题暗示:如果题目中提到"存在大量相似图片",你需要意识到考察点是"如何定义相似度阈值",而不仅仅是删除文件名相同的文件。
-
三、深度难点二:模型训练中的参数直觉
实操考试中,通常会提供图形化训练平台。考生不需要手写代码,但必须理解参数背后的意义,否则无法回答监考老师的提问。
1. 学习率(Learning Rate)的设置
-
过高:Loss 震荡不收敛,甚至变成 NaN。
-
过低:训练速度极慢,在规定时间内无法完成训练。
-
考场建议:如果没有特殊说明,采用平台默认值即可。如果被要求调整,记住"学习率衰减(Decay)"通常能提升最终精度。
2. 过拟合(Overfitting)的识别与处理
这是三级考试的必考点。
-
现象:训练集准确率 99%,验证集准确率 60%。
-
原因:模型复杂度太高 / 数据量太少 / 训练轮次(Epoch)太多。
-
解法:
-
早停(Early Stopping):观察 Loss 曲线,验证集 Loss 不再下降时立即停止。
-
数据增强(Data Augmentation):旋转、裁剪、加噪声(如果平台支持)。
-
正则化(Regularization):L1/L2 惩罚项。
-
四、深度难点三:模型评估指标的深层解读
考试最后环节通常是让你根据输出的结果文件,撰写评估报告。这里不仅考验计算能力,更考验逻辑分析能力。
1. 四大核心指标速记与辨析
|
指标 |
公式 |
核心含义 |
适用场景 |
|---|---|---|---|
|
Accuracy(准确率) |
(TP+TN)/Total |
整体猜对的概率 |
样本均衡时 |
|
Precision(精确率) |
TP/(TP+FP) |
"说你有,你真有的概率" |
推荐系统(怕误推) |
|
Recall(召回率) |
TP/(TP+FN) |
"真有,被你说出来的概率" |
安防/医疗(怕漏检) |
|
F1-Score |
2PR/(P+R) |
兼顾P和R的平衡指标 |
通用评价标准 |
2. 混淆矩阵(Confusion Matrix)的深度分析
假设你有一个猫狗分类任务,混淆矩阵如下:
|
预测\真实 |
猫 |
狗 |
|---|---|---|
|
猫 |
40 |
5 |
|
狗 |
10 |
45 |
考场标准答案思路:
-
计算指标:
-
猫的召回率 = 40 / (40+10) = 80%
-
狗的精确率 = 45 / (45+5) = 90%
-
-
分析原因:
-
猫被误判为狗的数量(10个)高于狗被误判为猫的数量(5个),说明模型对"猫"的特征提取能力稍弱,或者猫的样本更难区分。
-
-
改进建议:
-
增加猫的样本数据(数据增强)。
-
检查猫的标注是否存在模糊边界。
-
五、考场实操SOP:2-3周冲刺的时间分配策略
基于对数千名考生的教学复盘,我们发现"短学时、高聚焦"是通过的关键。以下是针对在职人员的 15 天冲刺计划:
第一阶段:规则内化(Day 1-3)
-
死磕标注规范:背诵 BIO 编码规则、图像标注边界定义。
-
工具熟悉:熟练使用考场同款模拟平台(如优培东方自研的全真模拟系统),确保能在无鼠标提示的情况下完成操作。
第二阶段:指标与参数(Day 4-7)
-
推导公式:不背数字,理解 Accuracy/Precision/Recall 的分母分子含义。
-
看图说话:看到 Loss 曲线震荡,知道是 Learning Rate 大了;看到 Train Acc高、Val Acc低,知道是 Overfitting。
第三阶段:全真模考(Day 8-14)
-
限时训练:严格按照考试时间(通常 120 分钟)完成整套流程。
-
复盘扣分点:重点复盘标注不一致的地方。
第四阶段:考前押题(Day 15)
-
关注当年新增考点,如大模型数据标注中的 RLHF(人类反馈强化学习)相关概念,虽然不考实操,但理论简答题可能涉及。
六、从考证到实战:为什么这些知识点能决定职业上限
在人工智能训练师的实际工作中,绝大多数时间并非在"炼丹"(调参),而是在做数据治理和效果归因。
-
数据标注质量决定了模型的上限。一个优秀的训练师能通过制定精准的标注规则,将模型精度提升 5-10%,这远比调参的效果显著。
-
模型评估能力决定了产品的生死。如果不能准确解读混淆矩阵,就无法向业务部门解释"为什么AI会犯错"。
在教学实践中,优培东方依托十四年职业教育积淀,由参与人社部考评标准研讨的师资团队领衔,正是抓住了"标注规范"与"评估指标"这两个核心痛点,通过全真模拟平台和高频考点浓缩,帮助学员在极短的备考周期内掌握这些核心能力,从而实现从"考证"到"上岗"的无缝衔接。
参考资料:人社部《人工智能训练师国家职业技能标准(2021年版)》、三级/四级培训教程、广东地区考场评分细则。本文由刘巨波老师供稿整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)