PaddleOCR-VL 1.5 + ROCm:让开发者从文档解析 Demo 走向高性能生产部署

很多文档解析 Demo 看起来都很惊艳:上传一张图片,模型识别出文字、表格、公式,甚至还能输出 Markdown。
但真正进入生产环境后,问题很快就会暴露出来。
企业里的文档不是干净样例,而是 PDF、扫描件、合同、票据、财报、检测报告、产品手册和档案图片。
它们可能有复杂版式、跨页表格、印章、公式、复选框、手写文字、多语言混排内容,也可能来自手机拍照、屏幕翻拍、低质量扫描,存在倾斜、折痕、透视变形和光照不均等问题。

所以,文档解析应用真正难的地方,不是做出一个 Demo,而是让它在真实业务里精准、稳定、高效地进入 AI 应用链路。
这正是 PaddleOCR-VL 1.5 + ROCm 的价值所在:它不是简单地让一个文档解析模型跑在 AMD GPU 上,而是为开发者打通一条从模型能力、推理后端到 AMD GPU 生产部署的完整路径。
AMD 官方技术文章[1]显示,PaddleOCR-VL 1.5 已经通过 AMD ROCm 7.x 在 AMD Instinct MI Series GPUs 上实现 Day-0 支持,并提供 Native PaddlePaddle 与 vLLM 两种推理后端,用于覆盖快速验证和生产部署两类需求。
文档解析 Demo 容易,生产部署才是真问题
过去,很多开发者把文档解析理解为 OCR,即“把图片里的文字识别出来”。
真正的文档解析是:把 PDF、扫描件和图片文档,变成大模型、RAG、Agent、知识库和业务系统可以放心使用的结构化数据。
PaddleOCR-VL 1.5 官方模型页提供的示例中,解析结果可以保存为 JSON 和 Markdown,这正是连接文档解析与下游 AI 应用的关键接口。
这意味着,文档解析不再只是一个前处理工具,而是 AI 应用的数据入口。
如果解析阶段把表格结构打散,把标题层级识别错,把跨页内容切断,把印章、复选框、公式漏掉,后面的向量检索、LLM 推理、Agent 决策都很难补救。
所以开发者面对的真实问题,不是“模型能不能识别文字”,而是:
- 它能不能把真实业务文档稳定地解析成可用数据?
- 它能不能在 AMD GPU 上高效跑起来?
- 它能不能承接批量文档处理和生产服务?
这就是从 Demo 到生产部署之间的差距。
开发者真正卡在哪里?
文档解析进入生产,开发者通常会卡在三个地方:
第一,解析质量不稳定。
真实文档不是标准测试图。
扫描件可能有噪声,拍照件可能有透视变形,合同可能有印章和手写痕迹,财报可能有复杂表格,技术文档可能有公式、图表和多栏排版... 这些都会影响解析质量。
第二,结构信息缺失。
很多 OCR Demo 可以识别文字,但企业级文档AI应用需要的不仅是文字,还有文档中的结构:标题、段落、表格、阅读顺序、跨页关系、字段边界和页面元素位置。
如果输出只有文字,没有代表文字间关系的结构信息,开发者需要手写很多后处理,来弥补结构信息的缺失。
第三,部署和性能成本高。
模型效果好只是第一步。
上线时还要考虑 GPU 环境、推理后端、批处理、吞吐、延迟、服务化、容器化和可复现部署。
尤其是企业文档处理场景,经常不是单张图片推理,而是成批合同、票据、报表和档案同时进入系统。
此时,低延迟和高吞吐就会成为生产部署的核心指标。
PaddleOCR-VL 1. 5 解决解析质量问题
PaddleOCR-VL 1.5 的核心价值,是把文档解析能力从“干净样例”推进到真实业务场景。官方资料显示,它是面向真实场景文档解析的多任务 0.9B 视觉语言模型,在 OmniDocBench v1.5 上达到 94.5% SOTA 准确率,并在表格、公式、文本识别和阅读顺序等维度取得领先表现。
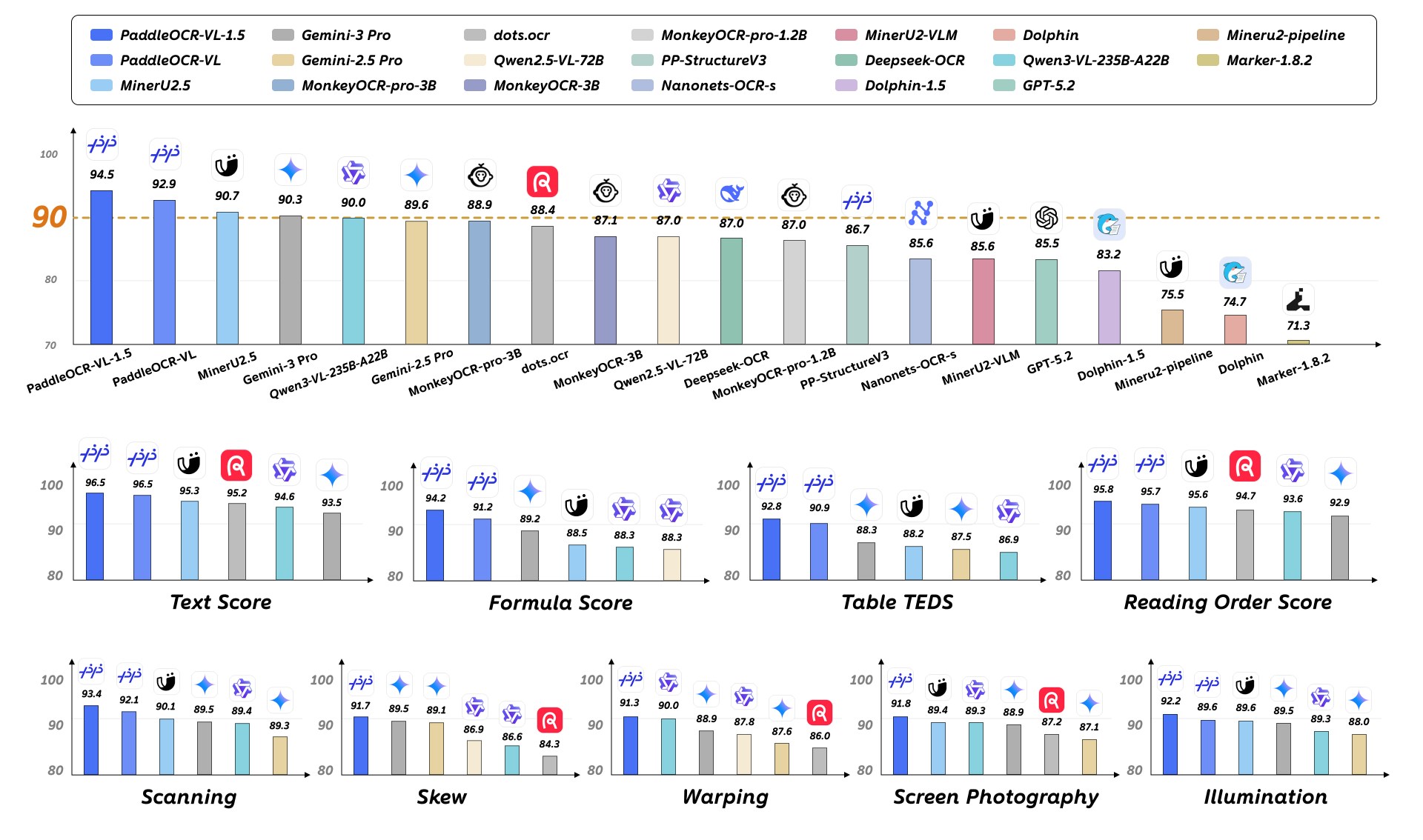
更关键的是,它专门针对真实文档中的物理畸变做了增强。PaddleOCR-VL 1.5 提出 Real5-OmniDocBench,覆盖扫描伪影、倾斜、弯折、屏幕拍照和光线变化五类场景,并在该基准上取得 SOTA 表现。它还支持不规则形状定位,可在倾斜、弯折等复杂条件下进行多边形检测;同时新增文本检测识别一体化、印章识别,并增强古籍文本、多语言表格、下划线、复选框、跨页表格合并和跨页段落标题识别能力。
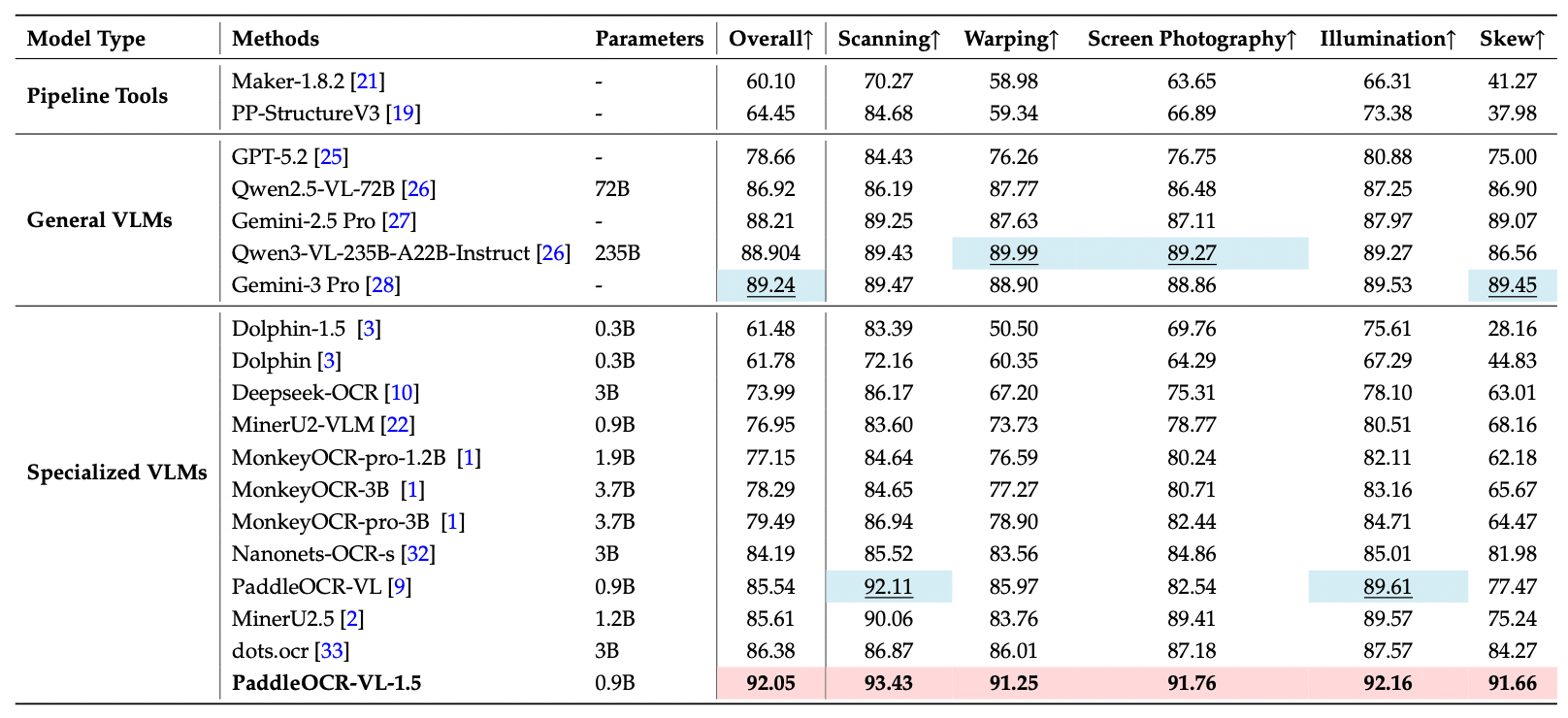
这意味着,开发者面对的不再只是“识别文字”,而是能把真实世界里的 PDF、扫描件、票据、合同和长文档,更稳定地解析成可进入 RAG、Agent 和业务系统的结构化数据。
ROCm 解决 AMD GPU 上的部署与算力问题
模型能力解决“能不能解析准”,ROCm 解决“能不能在 AMD GPU 上高效部署”。
AMD 官方将 ROCm 定义为一个开放式软件栈,包括 programming models、tools、compilers、libraries 和 runtimes,用于在 AMD GPU 上开发 AI 与 HPC 解决方案;ROCm 也包含 drivers、development tools 和 APIs,支持从低层 kernel 到终端应用的 GPU 编程。
Github:https://github.com/ROCm/rocm
这对开发者很重要。
因为生产部署最怕的不是某一步难,而是整个链路都要劳心劳力:驱动版本、框架支持、模型依赖、推理后端、容器环境,每一步都可能踩坑。
这次 AMD + PaddleOCR 团队给开发者直接提供了已经验证好的Docker镜像,让开发者不必浪费时间从零开始搭建环境并验证结果,而是直接一键部署基于官方验证过的Docker镜像,把精力放到应用逻辑和业务集成上。
镜像地址:http://www.paddleocr.ai/latest/version3.x/pipeline_usage/PaddleOCR-VL-AMD-GPU.html
Native 与 vLLM 双后端支撑从验证到生产
对开发者来说,同时提供 Native PaddlePaddle 后端和 vLLM 后端,能全面支持不同阶段的需求:
- Native 后端使用 PaddlePaddle 内置推理能力,优势是部署路径更直接,适合快速验证模型效果、跑通功能闭环、做小规模应用原型。
- vLLM 后端则面向更高性能的推理服务。vLLM 后端通过 optimized batching 和 inference acceleration 带来性能提升,并推荐用于生产环境。
下表是两种后端的应用场景和典型延迟对比:
| Backend | Typical Latency per Image | Key Advantages |
|---|---|---|
| Native (Paddle) | ~2s–5s | Simple deployment, no additional server setup |
| vLLM | ~0.5s–1s | Optimized throughput, lower latency for batch processing |
两种后端都保持 PaddleOCR-VL 1.5 的 SOTA accuracy,并把从快速原型到生产部署这两个阶段连接起来了。
总结:开发者能获得什么?
PaddleOCR-VL 1.5 + ROCm 带来的价值,可以总结为三句话:
第一,支持快速原型。
AMD 官方提供一键 Jupyter Notebook 和手动 Docker 部署两条路径。前者适合快速体验,后者适合开发者构建可定制工作流。
这让开发者可以先用 Notebook 判断模型是否适合自己的业务文档,再用 Docker 进入更可复现、可迁移、可集成的工程环境。
第二,降低适配门槛。
Day-0 支持的意义,不只是“官方宣布支持”,而是让开发者能够尽早在 AMD GPU 上验证真实业务链路,降低从驱动、框架、模型依赖到推理后端的适配门槛。
对于企业团队来说,这一点很重要。
因为很多 AI 应用失败,不是因为模型不够强,而是因为工程适配周期太长,试错成本太高,最后难以进入业务系统。
第三,加速生产部署。
早期验证,用 Native 后端快速跑通后,无需额外开发成本和代码修改,即可使用官方已验证镜像进入生产部署,实现批量处理、吞吐和服务化能力,并可以将解析结果快速接入 RAG、Agent、知识库、搜索系统、审核系统或业务工作流。
当文档能够被准确解析、结构化输出,并通过高性能推理服务承接批量请求,文档解析才真正从 Demo 走向生产。
参考资料:
[1]: https://www.amd.com/en/developer/resources/technical-articles/2026/unlocking-high-performance-document-parsing-of-paddleocr-vl-1-5-.html
[2]: https://ernie.baidu.com/blog/zh/posts/paddleocr-vl-1.5/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)