大模型入门-大模型蒸馏与微调3
QLoRA:量化与低秩适配的终极组合
论文地址: https://arxiv.org/pdf/2305.14314
QLoRA 的核心思想
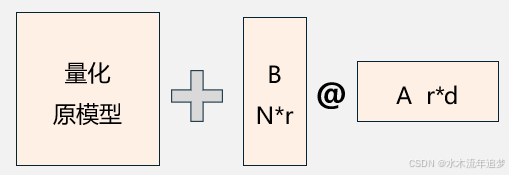
QLoRA(量化低秩适应)是2023年Meta提出的高效微调技术,通过量化预训练模型与 LoRA 的组合来进行大模型微调 。
-
QLoRA 模型本身使用 4bit 加载,训练时把数值反量化到 bf16 后进行训练 。
-
这种方法利用 LoRA 可以锁定原模型参数不参与训练、只训练少量 LoRA 参数的特性,使得训练所需的显存大大减少 。
QLoRA 的四大技术突破
4位NF4量化: 首创正态浮点4位(NF4)数据类型,针对 Transformer 权重的正态分布特性进行了优化 。
双重量化: 将模型参数划分为若干个 block,每个 block 内的参数共享一个常量 c,这个 c 是用于该 block 内参数量化的缩放因子,用于将原始浮点参数转换为低比特(如 4bit)量化值以实现压缩 。由于 c 原本以 float32 存储,会带来额外显存开销 。双重量化对其进行二次量化,将其转换为 8bit 的 c’,从而进一步降低存储成本 。
分页优化器: 解决了量化模型训练时的内存碎片问题,能够动态管理梯度内存
高秩 LoRA 适配器: 继承了 LoRA 的低秩分解思想,但支持更高秩(如 r=64/128),在低精度下仍保持强表达能力 。通过冻结量化后的预训练权重,在 LoRA 的基础上大大降低了所需显存 。
实际意义与应用价值
训练显存大大降低: 13B 模型微调仅需 7GB 显存,70B 模型单张 48GB GPU 即可完成,而以前则需要多卡 A100 才行 。
多任务友好: 可以共享量化后的基础模型,为每个任务仅保存极小的 LoRA 权重(例如,7B 模型任务权重仅为 4MB) 。
总结: QLoRA 通过量化压缩与低秩微调的组合创新,将大模型的微调成本大大降低 。这使得我们在 RTX4090 等消费级硬件上微调百亿参数模型成为可能,让大模型可以更好地在垂直领域中落地使用 。
数据蒸馏:让小模型继承大模型的智慧
什么是数据蒸馏?
Hinton 在 NIPS 2014 年提出了知识蒸馏的概念,其核心目的是将一个大模型或多个模型学到的知识迁移到另一个轻量级的单模型上,以便于部署 。简单来说,就是用小模型去学习大模型的预测结果(Soft Label),而不是仅仅学习训练集中的真实标签(Hard Label) 。
在蒸馏的过程中,有以下几个核心概念:
教师模型 (Teacher): 原始的大模型 。
学生模型 (Student): 新的轻量级小模型 。
Hard Label: 训练集中的真实标签(例如,单一的类别标签 [1, 0, 0]) 。
Soft Label: 教师模型对输入数据进行预测时输出的概率分布 。相比于绝对的 Hard Label,教师模型输出的概率分布(如 [0.7, 0.2, 0.1])反映了模型对每个类别的“信心程度”,并且包含了类别间的相对关系(例如类别B可能比类别C更接近真实答案) 。
Temperature (T): 用来调整 Soft Label 平滑程度的超参数 。
数据蒸馏之所以有效,核心思想在于一个好模型的终极目标是学习如何泛化到新的数据,而不仅仅是拟合现有的训练数据 。因此,蒸馏的目标是让学生模型学习到教师模型的泛化能力,理论上这样训练出来的结果会比单纯去拟合训练数据的学生模型更好 。
如何进行知识蒸馏?
对于简单的二分类任务来说,如果直接拿教师预测的 0/1 结果作为目标,这与直接使用训练集差不多,没有什么意义 。为了解决这个问题并更好地控制输出概率的平滑程度,Hinton 在教师模型的 softmax 函数中引入了参数 T T T (Temperature) :
q i = e x p ( z i / T ) ∑ j e x p ( z j / T ) q_{i}=\frac{exp(z_{i}/T)}{\sum_{j}exp(z_{j}/T)} qi=∑jexp(zj/T)exp(zi/T)
有了教师模型的输出分布后,学生模型的目标就是尽可能拟合这个分布 。此时,新的损失函数(Loss)变为:
L = ( 1 − α ) C E ( y , p ) + α C E ( q , p ) ⋅ T 2 L=(1-\alpha)CE(y,p)+\alpha CE(q,p)\cdot T^{2} L=(1−α)CE(y,p)+αCE(q,p)⋅T2
- 其中, C E CE CE 代表交叉熵(Cross-Entropy), y y y 是真实标签, p p p 是学生模型的预测结果, α \alpha α 是蒸馏 loss 的权重 。
注意: 因为学生模型要拟合教师模型的分布,所以学生模型在计算概率 p p p 时也必须使用相同的参数 T T T 。同时,由于新的目标函数会导致求梯度时梯度缩小为以前的 1 / T 2 1/T^{2} 1/T2,所以最后需要乘上 T 2 T^{2} T2,以保证在 T T T 变化时,Hard Label 的影响权重不会失衡 。
扩展思考: 如果可以拟合概率分布,可以直接拟合 logits 吗?Hinton 在论文中证明了是可以的:当 T T T 很大,且 logits 分布的均值为 0 时,优化概率交叉熵和优化 logits 的平方差在数学上是等价的 。
数据蒸馏的损失函数解析
学生模型的终极目标是同时拟合 Hard Label 和 Soft Label,因此最终的总损失是任务损失和蒸馏损失的加权和 :
L t o t a l = α ⋅ L t a s k + ( 1 − α ) ⋅ L d i s t i l l L_{total}=\alpha\cdot L_{task}+(1-\alpha)\cdot L_{distill} Ltotal=α⋅Ltask+(1−α)⋅Ldistill
这两个 Loss 分别代表:
任务损失 (Task Loss): 这是学生模型在真实标签 (Hard Label) 上的损失,通常使用交叉熵损失 (Cross-Entropy Loss) 来计算 。其目标是确保学生模型能够正确预测训练数据中的标准答案 。
蒸馏损失 (Distillation Loss): 这是学生模型在教师模型的预测概率 (Soft Label) 上的损失,通常使用 KL 散度来计算 。其目标是让学生模型的输出分布尽可能接近教师模型的输出分布 。
延伸案例:DeepSeek 是怎么进行数据蒸馏的?
既然蒸馏需要学习概率分布,那么大模型进行数据蒸馏的前提,是不是必须保证学生模型和教师模型的词表(Vocabulary)大小完全一致?
通过查阅模型配置文件可以发现一个有趣的现象:
-
DeepSeek-R1 教师模型的词表大小是 129280 。
-
由 R1 蒸馏出来的 Qwen-7B 学生模型,其词表大小是 152064 。
-
由 R1 蒸馏出来的 Llama-70B 学生模型,其词表大小是 128256 。
词表大小不一致,就意味着教师模型预测出来的词元概率,在学生模型中可能根本找不到对应的词,Soft Label 也就对应不上,传统的基于 KL 散度的学习方式便无法进行 。
由此可以推断出,DeepSeek-R1 所宣称的“蒸馏”大概率只进行了有监督微调(SFT) 。也就是把大模型生成的优质内容直接当作 Hard Label 让小模型去学习,这也侧面证明了仅仅进行全参微调(SFT)时,数据质量确实非常重要 。目前 DeepSeek-R1 只开源了模型而没有开源训练数据,这恰恰反映出了训练数据的重要性,高质量的数据无疑是 DeepSeek-R1 最大的护城河 。

print('hello world')

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)