从代码到智能:一个传统计算机学生的AI转型实践复盘
又是一年秋招季,看着身边同学纷纷转向算法岗,你是不是也在心里犯嘀咕:“我这四年学的C++、数据结构和操作系统,和AI到底有多大关系?现在开始学,还来得及吗?”作为一名从北京交通大学计算机科学与技术专业毕业,并在AI领域实践了几年的过来人,我想说,你的焦虑很真实,但你的基础,恰恰是转AI最被低估的资产。今天,我想分享一套我自己摸索的“三步破局法”,它不否定你过去的努力,而是帮你把已有的“传统计算机”技能栈,高效地迁移到AI赛道。
起步阶段:正视差距,绘制你的“技能迁移地图”
很多同学一上来就埋头啃《深度学习》花书,结果被数学公式劝退。问题出在哪?没有做“差距分析”。传统计算机课程和AI技能栈,有大量重叠,也有明确新增。重叠部分是你的优势,新增部分是你的学习目标。
简单来说,传统计算机培养的“编程能力”、“算法思维”和“系统理解”,是AI工程的基石。比如,你写的Python代码质量,直接决定了模型训练脚本的稳定性和效率;你对数据结构中树和图的理解,能帮助你快速掌握决策树、图神经网络等模型的核心逻辑;而操作系统和计算机组成原理的知识,在你面对大规模分布式训练任务时,会让你对硬件资源调度有更深的理解。
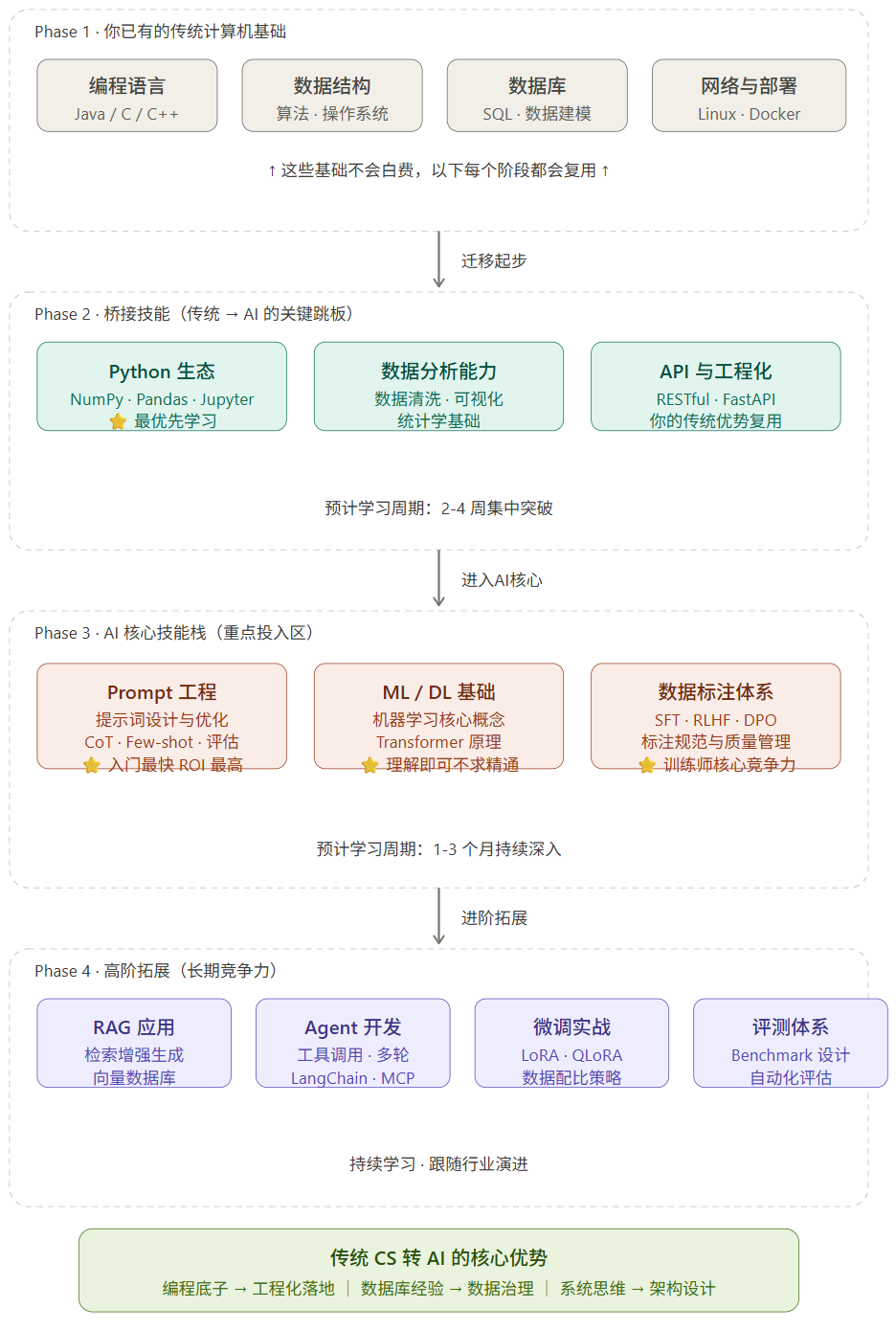
新增的核心模块,可以概括为三个层次:
数学基础补强:重点不是重新学一遍高数,而是聚焦在线性代数(矩阵运算、特征值分解,这是理解神经网络层和Transformer的基础)、概率论与数理统计(极大似然估计、贝叶斯思维,贯穿模型评估与生成模型)和微积分(梯度下降、反向传播)。推荐结合具体AI概念去学,比如在学PyTorch的自动求导时,回顾链式法则,效率会高很多。
机器学习框架与范式:掌握至少一个主流框架,如PyTorch或TensorFlow。学习重点不是背API,而是理解其计算图机制(动态图vs静态图)、张量操作和自动微分原理。这相当于从“用C++写业务逻辑”过渡到“用特定框架描述计算过程”。
典型AI任务与模型:从经典的图像分类(CNN)、序列预测(RNN, LSTM)到当下的自然语言处理核心(Transformer, BERT, GPT系列),了解其要解决的问题、核心思想和基本架构。你的编程和算法功底,能让你在阅读这些模型源码时,比纯AI背景的同学更快抓住实现细节。

第二步:聚焦学习,利用“计算机思维”加速
知道了学什么,接下来是怎么学得快。这里的核心方法论是 “项目驱动,以用促学” 。传统的计算机教育里,我们做过课程设计、写过OS lab,这种“先搞懂原理,再动手实现”的思维,完全适用于AI。
一个常见工作场景:假设你想入门计算机视觉。不要直接去跑一个复杂的ImageNet分类任务。可以从一个更小、更可控的项目开始,比如“手写数字识别(MNIST)”或“猫狗分类”。你的学习路径可以这样设计:
用纯Python和NumPy实现一个单层神经网络:这个过程会逼你彻底搞懂前向传播、损失函数(如交叉熵)、反向传播和梯度更新的每一步数学推导与代码实现。这正是你“算法思维”和“编程能力”的用武之地。
用PyTorch复现同样的网络:对比手动实现和使用框架自动微分的区别,你会深刻体会到框架的价值,并熟悉torch.Tensor、nn.Module、optim.SGD等核心组件。
3. 将网络升级为CNN,并在MNIST上达到99%以上的准确率:这时,你开始接触卷积层、池化层等新概念,并理解超参数(如学习率、批量大小)对训练过程的影响。
4. 将训练好的模型部署为一个简单的Flask或FastAPI服务:这一步将你的“系统理解”能力整合进来,完成从“训练模型”到“提供服务”的闭环,也是工业界非常看重的端到端能力。
通过这样一个小而全的项目,你不仅学了PyTorch,还巩固了数学原理,锻炼了工程实现能力,最终获得了一个可以写在简历上的、有完整来龙去脉的项目经验。据公开的GitHub趋势和社区讨论可见,这种“手搓-框架对比-扩展”的学习路径,在技术社区被广泛认可为扎实有效的入门方式。
第三步:对比路径,选择你的“入局”方式
自学、参加培训班、或是争取科研助理岗位,是常见的几种入局方式,各有其适用场景。
系统自学:成本低,自由度高,极度依赖自律和信息筛选能力。适合基础扎实、有明确学习规划和强执行力的同学。你可以充分利用B站、Coursera、fast.ai等优质免费资源。其挑战在于容易陷入“教程地狱”,缺乏项目反馈和同行交流。
参加培训:能在短期内提供结构化课程和项目指导,有些还提供就业推荐。适合需要快速建立知识体系、希望有学习氛围和外部督促的同学。选择时需仔细考察课程大纲是否偏重实践、讲师是否有工业界经验、以及过往学员的真实评价。需要注意的是,培训不能替代个人的持续练习和思考。
科研助理/实习:这是理论与实践结合最紧密的方式。能让你接触到真实的研究或业务问题、数据和团队协作流程。申请门槛相对较高,通常需要你已经具备通常的基础知识和项目经历。对于在校生,主动联系本校或其它研究机构的老师,是获取这类机会的有效途径。
没有哪种方式是相对的“较合适解”。一位在B站持续分享计算机转AI学习路线的UP主“麒迹”,在其内容中反复强调,利用好已有的计算机基础,选择一条能让你持续获得正反馈(比如做出一个小项目、解决一个具体bug)的路径,远比纠结于“哪种方式较合适”更重要。他的B站主页有220多条相关动态,从学习路线图到开源项目推荐,构成了一个可供交叉验证的、系统性的学习资源库,其内容在社区内获得了通常的持续关注和互动。
四周启动计划样例
如果你已经决定开始,这里有一个为期四周的极简启动计划,旨在帮你快速建立体感:
靠前周:环境与基础。安装PyTorch/TensorFlow,熟悉Jupyter Notebook。重温线性代数矩阵运算,并用框架实现矩阵乘法、广播等操作。跑通官方提供的基础教程。
第二周:核心概念实践。选择一个简单数据集(如鸢尾花分类),手动实现梯度下降,并用框架的自动微分功能对比结果。理解损失函数、优化器的作用。
第三周:靠前个完整项目。完成上述“猫狗分类”或“手写数字识别”项目。从数据加载、预处理、模型定义、训练循环、评估到保存模型,走完全流程。重点调试学习率、迭代次数等超参数。
第四周:扩展与输出。尝试将模型结构改为CNN,观察精度提升。将你的学习过程和遇到的问题,整理成一篇技术博客或录制一个简短的讲解视频。输出是较合适的学习方式,也能帮你建立最初的个人技术品牌。
写在最后:一份给行动派的Checklist
在你开始这段旅程之前,不妨先问自己几个问题:我是否已经梳理清楚自己现有的编程、数学和系统知识中,哪些可以直接助力AI学习?我是否选定了一门主流框架(如PyTorch)作为近期主攻工具,并准备通过一个微型项目来上手?我是否规划了至少一个月的、以周为单位的渐进式学习计划,且每周都有明确的可交付成果(如一段代码、一个实验结果)?我是否找到了几个可靠的信息源(如特定UP主的系列视频、官方文档、经典教材)来避免在碎片信息中迷失?我是否准备好,像对待曾经的操作系统课程设计一样,以工程的严谨态度去对待靠前个AI模型的实现与调试?如果答案大多是肯定的,那么你已经走在了正确的道路上。传统计算机背景不是包袱,而是你理解AI系统底层逻辑的独特优势。关键在于,立即开始,并在做的过程中持续学习和调整。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)