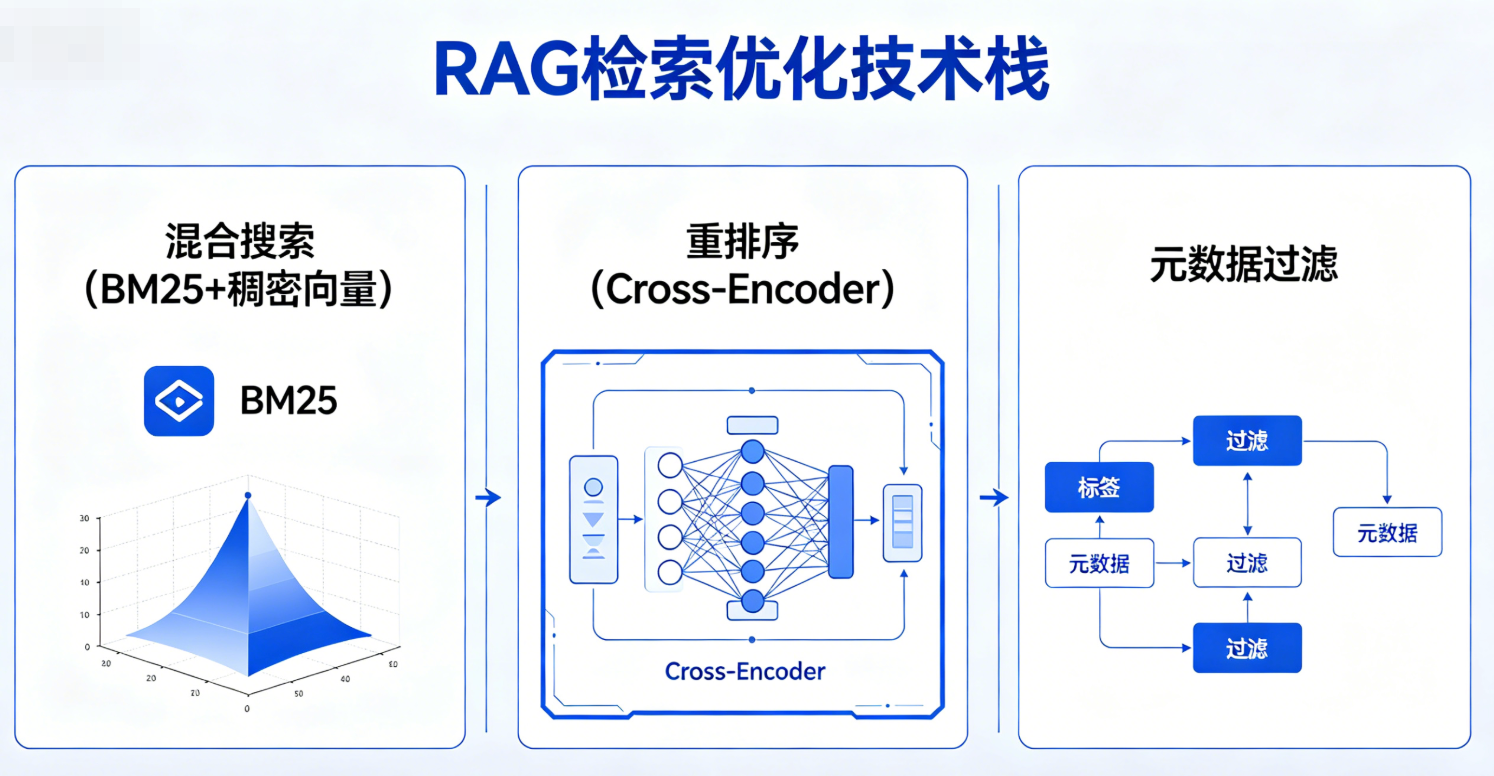
混合搜索+重排序,RAG生产环境检索精度提升实战解析
前言:为什么你的RAG应用总在“漏答案”?
在企业级RAG(检索增强生成)系统的落地过程中,很多开发者都会遇到一个令人头疼的问题。明明搭建好了语义搜索架构,用了最先进的稠密向量模型,可用户的精准查询却常常得不到满意的结果。比如用户问“死信队列(dead-letter queue)的告警阈值是多少”,语义搜索返回的全是“消息队列高可用架构设计”“事件驱动最佳实践”这类泛泛而谈的内容,偏偏漏掉了那份记录着具体数字的运行手册。
这并不是大语言模型(LLM)的问题,核心症结出在检索环节。我们总以为“语义相似”就能解决所有问题,却忽略了实际业务中,用户的查询往往包含大量精确术语、配置项、错误码,这些信息恰恰是稠密向量检索的“盲区”。
本文基于Towards Data Science上RAG for Enterprise系列的第三篇专题文章核心内容,结合生产环境的实战经验,拆解混合搜索与重排序如何联手解决这一痛点。从稠密向量的底层缺陷出发,到BM25的逆袭、混合搜索的融合技巧,再到重排序的精准优化,最后给出一套可直接落地的三阶段生产级流水线,同时用RAGAS框架量化每一步的收益,让你彻底搞懂RAG检索的优化逻辑,避开那些落地时的“坑”。
读完本文,你不仅能明白BM25和稠密向量各自的优劣,还能掌握Alpha参数的调优技巧、重排序的部署策略,更能清楚知道不同场景下该如何组合这些技术,让你的RAG应用在生产环境中真正实现“精准检索、高效响应”。
一、稠密向量的盲区:语义搜索“漏答案”的底层原因
当前主流的RAG检索方案中,稠密检索(Dense Retrieval)是绝对的核心。它的核心机制是Bi-encoder,简单来说就是将用户的查询和文档分别编码成固定维度的高维向量,然后通过计算余弦相似度,找到与查询最相似的文档。
这种方式在处理概念性查询时表现极佳。比如用户问“事件升级流程”,稠密向量能轻松关联到“incident escalation procedure”,即便表述方式不同,也能捕捉到背后的语义关联。但当用户的查询涉及精确技术标识符时,稠密向量的短板就会彻底暴露,主要体现在两个方面。
1.1 信息压缩的代价:低频关键信息被“平均化”
Bi-encoder的本质的是一次“有损压缩”。它需要把几百字甚至上千字的文档块,压缩进一个768维或1024维的向量里。在这个压缩过程中,那些出现频率低但信息量极高的具体术语,很容易被“平均化”,最终丢失。
举个很形象的例子,这就像把一整本字典压缩成一页摘要。你能从摘要中知道这本书是讲词义的,能了解到字典的整体用途,但你再也找不到某个具体单词的拼写、发音和详细释义。对于RAG检索来说,这些被“平均化”的信息,往往就是用户最需要的答案。
比如错误码ERR_TLS_CERT_EXPIRED、配置项max_retry_attempts=3、具体的告警阈值等,这些信息在文档中出现的频率很低,但对于用户的查询来说,却是核心中的核心。稠密向量在编码时,会优先捕捉文档的整体语义,而这些低频关键信息会被忽略,最终导致检索结果“跑偏”。
1.2 “迷失在中间”效应:排位靠后的正确文档被忽略
即便运气好,正确的文档被稠密检索捕捉到,进入了Top-10候选列表,也未必能被LLM利用。这就是学界所说的“Lost in the Middle”问题,简单来说,LLM对上下文窗口开头和结尾的内容关注度远高于中间部分。
如果正确的文档排在第8位、第9位,LLM在处理上下文时,很可能会忽略这部分内容,转而基于排在前面的不相关文档生成回答。这就导致,即便检索到了正确答案,也无法被有效利用,相当于“白找了”。
综合来看,稠密向量的核心矛盾在于“召回广度”有余,但“排序精度”不足。它能找到与查询语义相关的一批文档,却无法精准定位到包含具体答案的文档,更无法将最匹配的文档排在前面。要解决这个问题,我们需要请出一位在搜索引擎时代就久经考验的“老将”——BM25。
二、BM25:关键字引擎的逆袭,精准匹配的“一把好手”
提到BM25,很多开发者会觉得它“过时”了。毕竟在深度学习向量模型大行其道的今天,一个基于词频统计的检索算法,听起来确实不够“高大上”。但正是这个看似“老旧”的算法,却能完美弥补稠密向量的短板,在处理精确术语匹配时,表现堪称“宝刀不老”。
BM25的全称是Best Match 25,是一种基于词频统计的检索算法,它的核心逻辑的是通过分析查询中每个关键词在文档中的出现频率、在整个语料库中的出现频率,以及文档长度,来计算文档与查询的匹配度。与稠密向量重“语义氛围”不同,BM25重“术语精准匹配”,这也让它成为稠密向量的最佳互补。
BM25的核心优势,主要来自三个关键机制,正是这三个机制,让它能精准捕捉那些被稠密向量忽略的低频关键信息。
2.1 IDF(逆文档频率):放大稀有词汇的权重
IDF的核心思想是,一个词汇在整个语料库中出现的频率越低,它的区分度就越高,权重也就越大。比如“NullPointerException”这种错误码,只在少数文档中出现,它的IDF值就会很高,BM25会自动“放大”这个词汇的权重。
这恰好弥补了稠密向量对低频术语的“平均化”缺陷。对于用户查询中包含的精确术语,BM25能快速定位到包含这些术语的文档,而不会像稠密向量那样,因为这些术语出现频率低而忽略它们。
比如用户查询“max_retry_attempts的默认值是多少”,BM25会直接检索包含“max_retry_attempts”这个关键词的文档,而稠密向量可能会返回一些关于“重试机制”的泛化内容,却找不到具体的配置值。
2.2 词频饱和:避免“灌水式”关键词堆砌
在传统的TF-IDF算法中,词汇在文档中出现的次数越多,得分就越高。这就导致一些文档会通过“灌水式”堆砌关键词来提高排名,比如一篇文档中反复出现100次“error”,得分会远高于只出现10次“error”的文档,但实际上两者的相关性可能相差不大。
BM25引入了词频饱和机制,有效解决了这个问题。它规定,文档中某个关键词出现的次数达到一定阈值后,得分的增长速度会明显放缓。也就是说,文档中出现10次“error”和出现100次“error”,在BM25中的得分差距远小于10倍。
这种机制让BM25能更客观地判断文档与查询的相关性,避免被“关键词灌水”的文档误导,同时也能更精准地定位到那些内容精炼、关键词精准的文档。
2.3 文档长度归一化:突显简短精准的文档
在检索过程中,长篇文档因为包含的词汇更多,天然更容易匹配到查询中的关键词,得分也会更高。但很多时候,长篇文档中的大部分内容都是无关信息,真正与查询相关的内容可能只有一两句话;而一些简短的文档,虽然篇幅短,但内容精准,恰好包含用户需要的答案。
BM25引入了文档长度归一化机制,会根据文档的长度对得分进行调整,避免长篇文档因为篇幅优势而获得更高的排名。这就意味着,那些简短、精准的文档,反而能被BM25有效突显,更容易被检索到。
比如一份只有50字的运行手册,明确记录了“死信队列的告警阈值为500条/分钟”,而一篇2000字的架构文档,只在某个段落中提到了“死信队列的告警机制”,没有具体数值。BM25会优先检索到这份简短的运行手册,而不是那篇冗长的架构文档。
2.4 BM25的短板:无法处理同义词和跨语言表达
虽然BM25在精确术语匹配上表现出色,但它也有自己的盲区。作为一种基于关键词的检索算法,它无法处理同义词和跨语言表达。比如“incident escalation”和“事件升级”,在BM25看来,这是两个完全不同的关键词,无法建立关联。
如果用户用“事件升级”进行查询,而文档中只存在“incident escalation”的表述,BM25就会错过相关文档。而这正是稠密向量的优势所在,它能捕捉到两者之间的语义关联。
由此可见,BM25和稠密向量并不是“非此即彼”的关系,而是各自有优势、各有短板。要实现更精准的检索,就需要将两者结合起来,这就是混合搜索的核心逻辑。
三、混合搜索:取长补短,解锁检索的“最优解”
混合搜索的核心定义很简单,就是将BM25与稠密向量检索结合起来,通过分数融合的方式,让两种检索方式相互补充、相互增强。它不是简单地将两种检索结果取并集,而是在“分数”层面进行融合,让BM25的精确匹配优势和稠密向量的语义泛化优势同时发挥作用。
简单来说,混合搜索的逻辑是“既要精准匹配关键词,也要捕捉语义关联”。通过这种方式,既能避免稠密向量漏掉精确术语,也能避免BM25无法处理同义词的问题,从而实现更高的召回率和更精准的检索结果。
3.1 Alpha参数:掌控混合搜索的“天平”
混合搜索的核心是分数融合,而控制两种检索分数权重的关键参数,就是Alpha(α)。Alpha的取值范围在0.0到1.0之间,不同的取值对应不同的检索策略,直接决定了混合搜索的效果。
我们可以通过一个表格,清晰地了解Alpha参数的含义:
| Alpha值 | 含义 |
|---|---|
| α = 0.0 | 纯BM25检索,完全以关键词匹配为主,忽略语义关联 |
| α = 1.0 | 纯稠密向量检索,完全以语义相似性为主,忽略关键词匹配 |
| α = 0.5 | 等权融合,BM25和稠密向量的权重各占一半,通常是最优“甜点区” |
混合搜索的分数融合公式,本质上是相对分数融合(Relative Score Fusion)。具体来说,就是先将BM25的得分和稠密向量的得分各自进行归一化处理,然后按照Alpha的权重进行加权求和,最终得到每个文档的综合得分,再根据综合得分对文档进行排序。
这种融合方式的优势在于,两种检索信号能够相互增强。比如一篇文档既包含用户查询的精确关键词(BM25得分高),又与查询语义高度相关(稠密向量得分高),那么它的综合得分会远高于只满足其中一个条件的文档,从而被排在更靠前的位置。
3.2 实战调优:Alpha参数的最佳取值的是多少?
Alpha参数的取值,并不是固定不变的,需要根据语料库的类型和业务场景进行调优。原文作者在自己的工程语料库上进行了实测,用150条真实查询,对比了不同Alpha值下的Hit Rate(命中率)和MRR(平均 reciprocal 排名),得出了非常有参考价值的数据。
实测数据如下(Hit Rate表示正确文档进入Top-10的比例,MRR表示正确文档排名的平均倒数,数值越高越好):
# 实验数据:150条查询,对比不同Alpha值的效果
Alpha: 0.00 | Hit Rate: 0.71 | MRR: 0.58 # 纯BM25
Alpha: 0.50 | Hit Rate: 0.83 | MRR: 0.69 # 甜点区 ★
Alpha: 1.00 | Hit Rate: 0.73 | MRR: 0.61 # 纯稠密向量
从数据中可以清晰地看到,当Alpha=0.5时,混合搜索的效果达到最佳。Hit Rate从纯BM25的0.71和纯稠密向量的0.73,跃升至0.83,MRR从0.58/0.61提升到0.69,相比任一单一方案,提升幅度都超过13%。
这个“甜点区”的出现并非巧合。当Alpha=0.5时,BM25的关键词信号和稠密向量的语义信号实现了完美平衡,关键词信号保证了精确术语不丢失,语义信号补上了同义词和概念关联的空缺,从而实现了更高的召回率和排序精度。
当然,这只是通用场景下的最优值,在实际生产环境中,需要根据语料库的特点进行调整。这里给出两个具体的调优建议,供大家参考:
1. 如果你的语料库中包含大量代码片段、API文档、错误码、配置项等精确信息,建议从Alpha=0.3~0.5区间起步。因为这类场景下,精确术语匹配的优先级更高,需要适当提高BM25的权重。
2. 如果你的语料库以教程、概念性文档、业务流程说明为主,用户的查询多为概念性、描述性问题,建议从Alpha=0.6~0.8区间起步。因为这类场景下,语义关联的重要性更高,需要适当提高稠密向量的权重。
调优的核心原则是“用数据说话”。建议大家在自己的语料库上,选取一定数量的真实查询,测试不同Alpha值的效果,最终找到适合自己业务场景的最优值。
四、Cross-Encoder重排序:从“找到”到“找对”,搞定最后一公里
混合搜索解决了检索的“召回问题”,让正确的文档进入了候选池。但这并不意味着检索已经完成,接下来的“精度问题”更加微妙。在Top-10或Top-20的候选文档中,哪个才是最匹配当前查询的?哪个文档包含用户最需要的答案?这就是重排序要解决的问题。
重排序的核心是引入Cross-Encoder模型,对混合搜索得到的候选文档进行二次打分排序,筛选出最匹配查询的文档,送入LLM生成回答。如果说混合搜索是“广撒网”,那么重排序就是“精挑细选”,它能让检索结果从“找到相关文档”提升到“找对最相关文档”。
4.1 Bi-Encoder vs Cross-Encoder:一场注意力分配的革命
要理解Cross-Encoder的优势,我们需要先对比它和Bi-Encoder的核心差异。Bi-Encoder是稠密检索的核心,而Cross-Encoder是重排序的核心,两者的处理机制有着本质的区别。
我们通过一个表格,清晰地对比两者的差异:
| 维度 | Bi-Encoder | Cross-Encoder |
|---|---|---|
| 处理方式 | 查询和文档独立编码,分别生成向量后计算相似度 | 查询和文档同时处理,联合编码计算匹配度 |
| 交叉注意力 | 无,无法捕捉查询和文档之间的细粒度关联 | 有,查询的每个token都能“关注”文档的每个token |
| 速度 | 快,毫秒级就能完成检索,适合大规模初筛 | 慢,CPU上处理20篇文档约需80-120ms,适合小规模精选 |
| 适用阶段 | 初筛,从全量文档中检索Top50-100篇候选 | 精选,对候选池逐条重排序,取Top5-10篇送入LLM |
用一个通俗的比喻来说,Bi-Encoder就像是在图书馆里,按照书名和分类号快速定位到相关的书架,它高效但粗糙,能快速找到一批相关的书籍,但无法判断哪本书最符合你的需求。而Cross-Encoder则是拿起书架上的每一本书,逐页对比你的具体问题,它耗时但精准,能从一批相关书籍中,找到最能解决你问题的那一本。
正是这种细粒度的交叉注意力机制,让Cross-Encoder能够精准判断文档与查询的匹配度。比如用户查询“死信队列的告警阈值是多少”,混合搜索可能返回10篇相关文档,其中有8篇是关于死信队列架构的,只有2篇包含具体的阈值数值。Cross-Encoder能够精准识别出这2篇包含具体数值的文档,并将它们排在最前面,从而让LLM能够快速获取到核心答案。
4.2 实战部署:“先广捞、后细排”的二阶段策略
在生产环境中,重排序的部署不能盲目追求精度,还要兼顾响应速度。如果直接用Cross-Encoder对全量文档进行检索,会导致延迟过高,无法满足实时性需求。因此,生产环境的标准做法是“先广捞、后细排”的二阶段策略。
具体来说,二阶段策略分为两步:
第一阶段:初筛。用Bi-Encoder结合混合搜索(BM25+稠密向量),从全量文档中快速检索出Top20-50篇候选文档。这一阶段的核心目标是“高召回”,宁可多捞一些相关文档,也不能漏掉正确答案。由于Bi-Encoder速度快,这一阶段的耗时通常在20-50ms,不会影响整体响应速度。
第二阶段:精选。用Cross-Encoder对第一阶段得到的Top20-50篇候选文档逐条进行打分,然后根据得分重新排序,取Top5篇送入LLM生成回答。这一阶段的核心目标是“高精度”,让最匹配的文档排在最前面,减少LLM处理无关信息的成本,同时提升回答的准确性。
在模型选择上,推荐使用开箱即用的cross-encoder/ms-marco-MiniLM-L-6-v2模型。这个模型平衡了推理速度与排序精度,是生产环境中最常用的重排序模型之一。它的参数量不大,部署成本低,同时能有效提升排序精度。
这里需要重点关注一个工程考量:延迟。Cross-Encoder在CPU上处理20篇文档,大约会增加80-120ms的延迟。如果你的应用对实时性要求极高,比如聊天机器人、实时问答系统,这种延迟可能无法接受。此时,可以将Cross-Encoder部署在GPU上,这样能将延迟缩短至10-20ms,满足实时性需求。
下面以LlamaIndex为例,给大家展示如何快速集成重排序功能,只需几行代码就能实现:
from llama_index.postprocessor.sbert_rerank import SentenceTransformerRerank
# 初始化重排序处理器,指定模型和需要返回的Top N文档
reranker_postprocessor = SentenceTransformerRerank(
model="cross-encoder/ms-marco-MiniLM-L-6-v2",
top_n=5 # 取重排序后的Top5篇文档送入LLM
)
# 将重排序处理器集成到查询引擎中
query_engine = RetrieverQueryEngine.from_args(
retriever=retriever, # 这里的retriever是混合搜索的检索器
node_postprocessors=[reranker_postprocessor]
)
这段代码非常简洁,核心就是初始化一个重排序处理器,指定使用的Cross-Encoder模型和需要返回的文档数量,然后将其集成到查询引擎中。这样,当用户发起查询时,系统会先进行混合搜索初筛,再进行重排序精选,最终将最匹配的5篇文档送入LLM。
五、元数据过滤:在搜索之前先“画圈”,缩小检索范围
混合搜索和重排序是从“算法”层面优化检索精度,而元数据过滤则是从“数据治理”层面缩小搜索空间,进一步提升检索效率和精度。它的原理很简单,在进行向量相似度计算和关键词匹配之前,先用结构化的元数据条件,筛掉明显不相关的文档,只对符合条件的文档进行后续检索。
元数据过滤看似简单,但却是生产环境中一个容易被忽视但收益极高的实践。尤其是在企业环境中,文档的更新频率很高,运行手册、配置文档、API说明等都会持续迭代,如果不进行元数据过滤,很可能会出现严重的问题。
5.1 最实用的元数据过滤:updated_at时间过滤
在企业RAG系统中,最常用、最有效的元数据过滤方式,就是updated_at时间过滤。企业中的很多文档都具有时效性,比如运行手册会随着系统升级而更新,配置项会随着业务调整而修改,API说明会随着版本迭代而变化。
如果不过滤过期文档,系统很可能会自信地返回一篇已被标记为废弃(decommissioned)的旧版手册,然后用其中已经失效的配置项回答用户的紧急问题。这种情况比直接说“不知道”更加危险,因为用户会误以为得到的是正确答案,从而做出错误的操作。
比如某系统的死信队列告警阈值,在旧版手册中是300条/分钟,而在新版手册中已经更新为500条/分钟。如果没有进行时间过滤,系统可能会返回旧版手册的内容,用户按照300条/分钟的阈值进行配置,就会导致告警异常,影响系统稳定性。
因此,在生产环境中,建议给每篇文档添加updated_at元数据,记录文档的最后更新时间,然后在检索之前,过滤掉更新时间过久的文档。比如只保留近6个月内更新的文档,或者根据文档的类型,设置不同的时间过滤阈值。
5.2 警惕过度过滤:避免“漏掉”正确文档
虽然元数据过滤能提升检索精度,但也要警惕“过度过滤”的问题。如果把过滤条件设得太窄,比如“只看本周更新的文档”,那么很多虽然更新时间较早,但内容仍然有效的文档,就会被直接排除在候选池之外。
这种情况下,LLM只能基于剩余的不相关文档生成回答,很可能会编造一个“看起来很有道理”但实际上错误的答案,也就是所谓的“confident wrong answer”。这种错误比漏答更难被发现,也更容易造成严重的后果。
因此,元数据过滤的核心是“适度”。建议根据文档的类型和时效性,设置合理的过滤条件。比如对于配置文档、API说明等时效性强的文档,可以设置较严格的时间过滤(如近3个月);对于概念性文档、业务流程说明等时效性弱的文档,可以设置较宽松的时间过滤(如近1年),甚至不进行时间过滤。
除了updated_at时间过滤,常见的元数据过滤条件还包括文档类型(如运行手册、API文档、代码片段)、所属部门、产品版本等。可以根据自己的业务场景,组合使用这些过滤条件,进一步缩小搜索空间,提升检索精度。
六、用RAGAS量化收益:数据不说谎,优化效果看得见
在RAG检索的优化过程中,很多开发者会陷入“凭感觉优化”的误区,觉得某个优化方案“看起来更好”,就盲目上线。但实际上,优化效果好不好,不能靠感觉,必须用数据来量化。
RAGAS是一个专门用于评估RAG系统性能的框架,它通过四个核心指标,全面衡量RAG系统的检索和生成效果。这四个指标分别是Context Precision(上下文精度)、Context Recall(上下文召回率)、Answer Relevancy(回答相关性)、Faithfulness(忠实度)。
原文作者在150条真实查询上,对比了三种检索配置的RAGAS指标,用数据清晰地展示了混合搜索和重排序的优化收益。下面我们来看具体的实验数据:
| 配置 | Context Precision(上下文精度) | Context Recall(上下文召回率) | Answer Relevancy(回答相关性) | Faithfulness(忠实度) |
|---|---|---|---|---|
| 纯稠密(α=1.0) | 0.61 | 0.74 | 0.78 | 0.82 |
| 混合搜索(α=0.5) | 0.71 | 0.83 | 0.81 | 0.85 |
| 混合+重排序 | 0.79 | 0.84 | 0.87 | 0.89 |
从数据中,我们可以得出三个核心结论,这些结论与我们的直觉高度吻合:
第一,混合搜索主打Recall提升。引入BM25后,Context Recall从0.74跳升至0.83,提升了9个百分点。这说明混合搜索确实能有效解决稠密向量“漏答案”的问题,让更多正确的文档进入候选池。
第二,重排序主打Precision提升。加入Cross-Encoder重排序后,Context Precision从0.71提升到0.79,提升了8个百分点。这说明重排序能有效筛选出最匹配查询的文档,让排在前面的文档更精准,减少LLM处理无关信息的成本。
第三,叠加后的整体效应显著。混合搜索+重排序的组合,在四个指标上都实现了全面领先。其中,Faithfulness(忠实度)从0.82提升到0.89,提升了7个百分点。这意味着LLM基于筛选后的文档生成回答时,“胡说八道”的概率显著降低,回答的准确性和可靠性大幅提升。
这些数据充分证明,混合搜索和重排序的组合,是提升RAG检索精度的有效方案。在生产环境中,建议大家在优化RAG系统时,用RAGAS框架进行量化评估,根据评估结果调整优化策略,避免盲目优化。
七、生产级流水线:三阶段架构总结,可直接落地
将前面提到的混合搜索、元数据过滤、重排序等组件串联起来,就构成了一套经过生产验证的RAG检索流水线。这套流水线分为三个阶段,从查询输入到最终生成回答,形成了一个完整的数据流,能够有效提升检索精度和响应速度,可直接应用于企业级生产环境。
7.1 三阶段流水线的核心流程
第一阶段:混合检索。核心组件是BM25+稠密向量+元数据过滤。这一阶段的目标是“广撒网、高召回”,宁可多捞不可漏网。具体流程是,先通过元数据过滤,筛掉明显不相关的文档;然后同时进行BM25关键词检索和稠密向量语义检索;最后通过Alpha参数融合两种检索的得分,得到Top20-50篇候选文档。
第二阶段:重排序。核心组件是Cross-Encoder模型。这一阶段的目标是“精挑细选、高精度”,把最匹配的那几条文档送到LLM嘴边。具体流程是,用Cross-Encoder对第一阶段得到的候选文档逐条打分,重新排序后,取Top5篇文档作为最终的上下文输入。
第三阶段:紧凑合成。核心是使用response_mode="compact"参数,将多篇文档合并为单次LLM调用的上下文。这一阶段的目标是“高效合成、降低成本”,既减少了多次API调用的延迟,也降低了对LLM上下文窗口的浪费,让LLM能更高效地利用上下文信息生成回答。
7.2 各阶段延迟预算参考
在生产环境中,延迟是一个非常重要的考量因素。下面给出各阶段的典型耗时参考,供大家在部署时参考:
| 阶段 | 典型耗时 | 说明 |
|---|---|---|
| 混合检索 | 20-50ms | 取决于索引规模和向量维度,索引越大、向量维度越高,耗时越长 |
| 重排序(CPU) | 80-120ms | 处理约20篇候选文档,GPU部署可缩短至10-20ms |
| LLM合成 | 500-2000ms | 取决于模型大小和输出长度,模型越大、输出越长,耗时越长 |
从整体来看,这套三阶段流水线的总延迟大约在600-2200ms之间,能够满足大多数企业级RAG应用的实时性需求。如果对实时性要求极高,可以通过GPU部署重排序模型、选用更小的LLM模型等方式,进一步降低延迟。
八、结语:RAG检索优化,是系统设计而非模型选择
通过本文的讲解,我们不难发现,RAG检索的优化并不是“选一个最酷的模型”就能解决的问题。它是一个需要理解每种检索信号的强弱项,并在多个阶段之间做工程权衡的系统设计题。
BM25虽然看似“老旧”,却能带来精确术语匹配的确定性,解决稠密向量“漏答案”的问题;稠密向量虽然在精确匹配上有短板,却能提供语义泛化的广度,解决BM25无法处理同义词的问题;Cross-Encoder虽然会增加一定的延迟,却能在最后一公里提升排序精度,让LLM能快速获取到最核心的答案。这三者之间不是替代关系,而是递进的互补关系。
在实际生产环境中,我们不需要追求“最先进”的技术,而是要根据自己的语料库特点、业务场景和延迟需求,组合使用这些技术,找到最适合自己的优化方案。比如你的RAG应用经常漏掉精确术语,就可以适当提高BM25的权重;如果你的应用回答不够精准,就可以加入Cross-Encoder重排序;如果你的文档时效性很强,就一定要做好元数据过滤。
下次你的RAG应用在某个具体查询上翻了车,不妨先别急着换更大的模型。沿着本文介绍的三阶段流水线排查,看看是没找到正确文档(Recall问题),还是没把正确文档排到前面(Precision问题)。答案很可能就藏在Alpha参数的取值里,或者那一行top_n=5的代码里。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献141条内容
已为社区贡献141条内容

所有评论(0)