1panel面板安装ollama的详细过程
1. 前言
Ollama 是一个强大的开源工具,它允许您在本地轻松运行、管理和部署大型语言模型(LLM)。结合 1Panel 这款现代化的 Linux 服务器运维管理面板,我们可以通过图形化界面,以更便捷、更安全的方式完成 Ollama 的安装与配置。本教程将手把手带您完成整个过程。
2. 环境准备
在开始之前,请确保您已满足以下条件:
- 一台运行 Linux 的服务器(如 Ubuntu 22.04/24.04、CentOS 7/8 等)。
- 已安装并成功运行 1Panel。如果您尚未安装,请参考 1Panel 官方安装文档 先行安装。
- 服务器拥有足够的磁盘空间(建议至少 20GB 可用空间,用于存放模型文件)。
- 确保服务器可以访问互联网,以下载 Ollama 及其模型。
图1:1Panel 登录界面与仪表板概览
图1:成功登录 1Panel 后看到的仪表板界面,左侧为导航菜单,右侧为系统状态概览。
图2:1Panel 系统信息与资源监控页面
*图2:在「主机」或「监控」页面查看服务器资源使用情况,确保有足够的磁盘空间(建议至少20GB)。
*## 3. 通过 1Panel 应用商店安装 Ollama
这是最简单快捷的安装方式。1Panel 的应用商店集成了大量常用软件的一键安装。
3.1 进入应用商店
图3:1Panel 应用商店入口
图3:登录后,在左侧导航栏中找到并点击「应用商店」图标,进入应用市场。
- 登录您的 1Panel 后台。
- 在左侧导航栏中,点击「应用商店」。
3.2 搜索并安装 Ollama
图4:在应用商店中搜索 Ollama
图4:在应用商店顶部的搜索框中输入“Ollama”,搜索结果会显示 Ollama 应用卡片。
图5:Ollama 应用详情页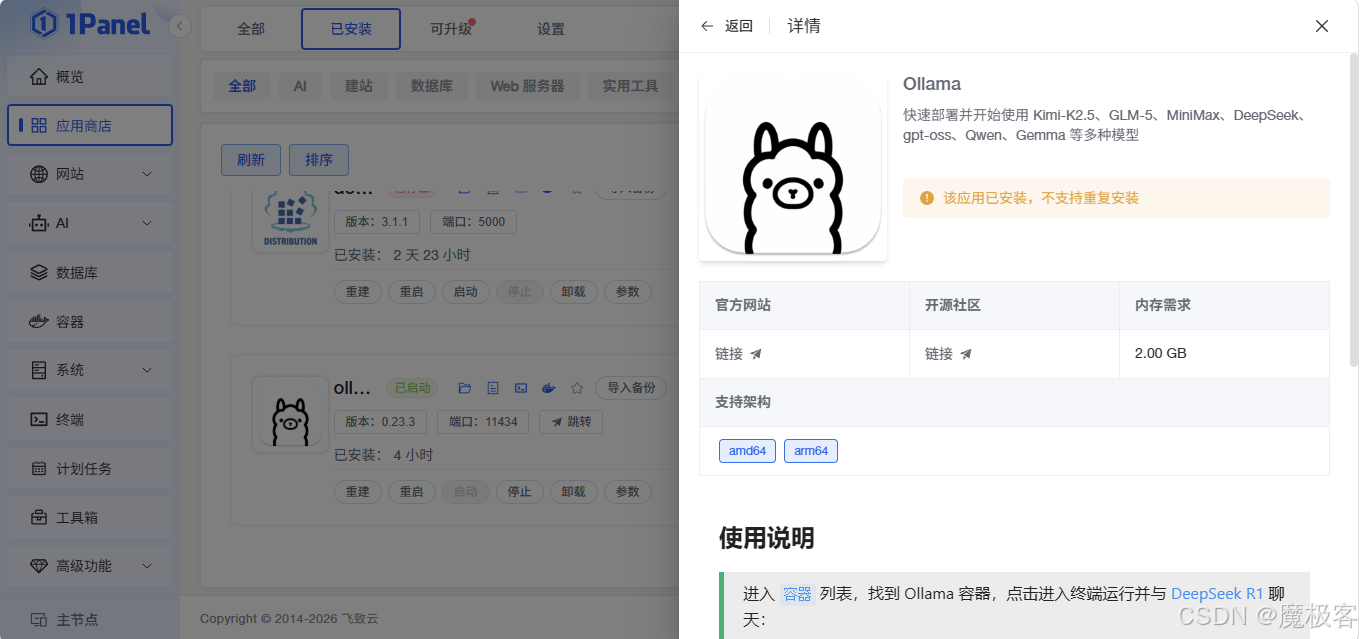
图5:点击 Ollama 卡片进入详情页,查看应用描述、版本信息,右上角有「安装」按钮。
- 在应用商店的搜索框中输入 “Ollama”。
- 在搜索结果中找到 “Ollama” 应用,点击其卡片进入详情页。
- 在详情页中,点击右上角的「安装」按钮。
3.3 配置安装参数
图6:Ollama 安装配置页面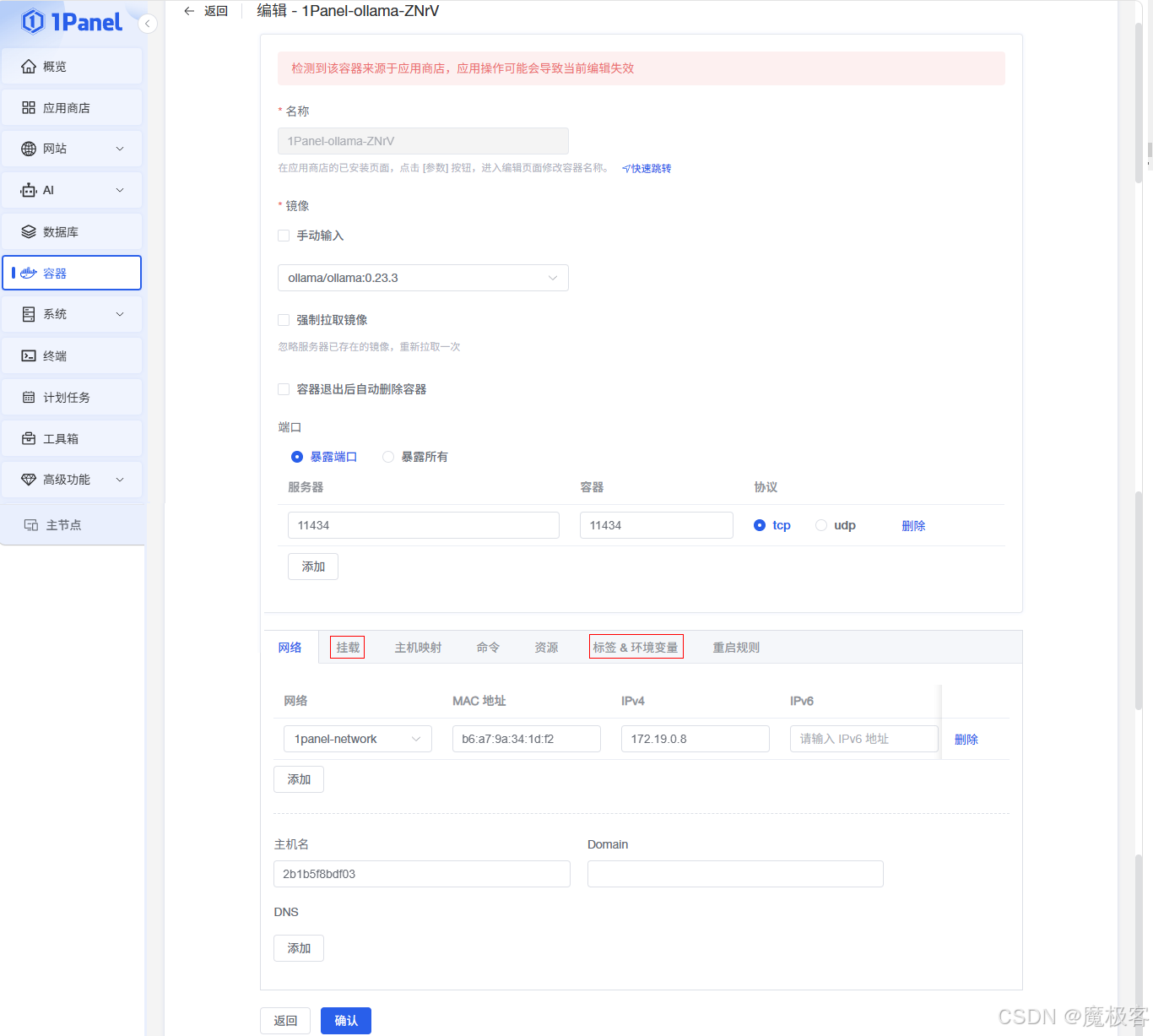
图6:点击「安装」后弹出的配置页面,可设置应用名称、版本、端口映射、存储卷等参数。
图7:端口映射与存储卷配置示例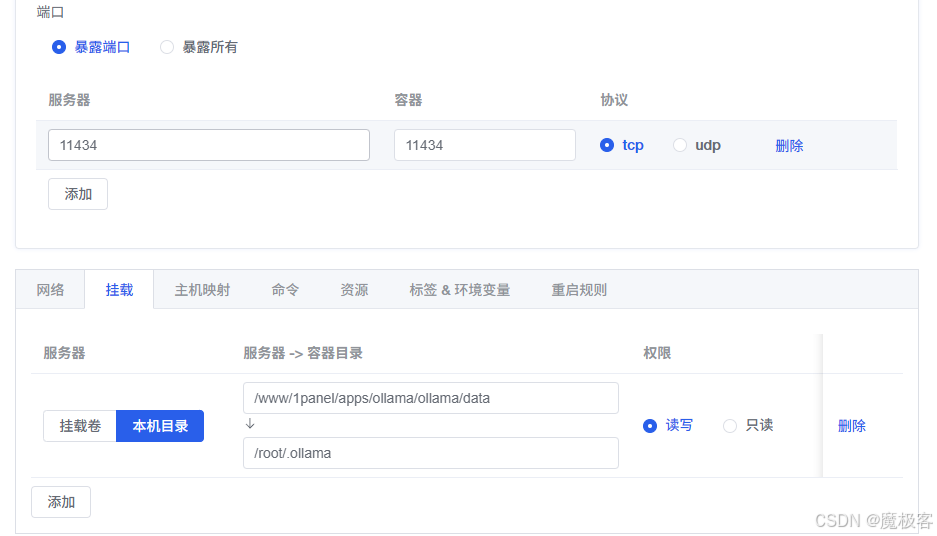
图7:配置示例:容器端口11434映射到服务端口11435,并创建名为“ollama-models”的存储卷挂载到/root/.ollama。
点击「安装」后,会弹出配置页面。您可以根据需要进行调整,以下为关键参数说明:
- 应用名称:为这个 Ollama 实例起个名字,例如
ollama-server。 - 版本:选择您希望安装的 Ollama 版本,通常选择最新的稳定版即可。
- 网络:
- 端口映射:这是最重要的设置。Ollama 默认服务端口是
11434。您需要将容器内的11434端口映射到宿主机的某个端口。 - 示例:在「容器端口」填
11434,在「服务端口」填一个未被占用的端口,例如11435。这意味着您将通过服务器的IP:11435来访问 Ollama API。
- 端口映射:这是最重要的设置。Ollama 默认服务端口是
- 存储:建议为模型文件创建一个持久化存储卷。
- 点击「添加」->「创建存储卷」,命名为
ollama-models,挂载路径填写/root/.ollama(这是 Ollama 默认的模型存储目录)。
- 点击「添加」->「创建存储卷」,命名为
- 环境变量:通常无需额外设置,除非有特定需求。
配置完成后,点击页面底部的「确认」按钮,1Panel 将自动拉取镜像并创建容器。
3.4 验证安装
3.5 下载与运行模型
在确认 Ollama 容器正常运行后,下一步就是下载并运行您的第一个大语言模型。您可以通过 1Panel 的容器终端功能,直接在浏览器中操作。
- 在 1Panel 的「容器」页面,找到您的 Ollama 容器(如
ollama-server)。 - 点击容器右侧的「终端」图标,打开一个连接到容器内部的 Web 终端。
- 在终端中,使用
ollama pull命令下载模型。例如,下载轻量级的llama3.2:1b模型:
图9:在 1Panel 容器终端中下载模型ollama pull llama3.2:1b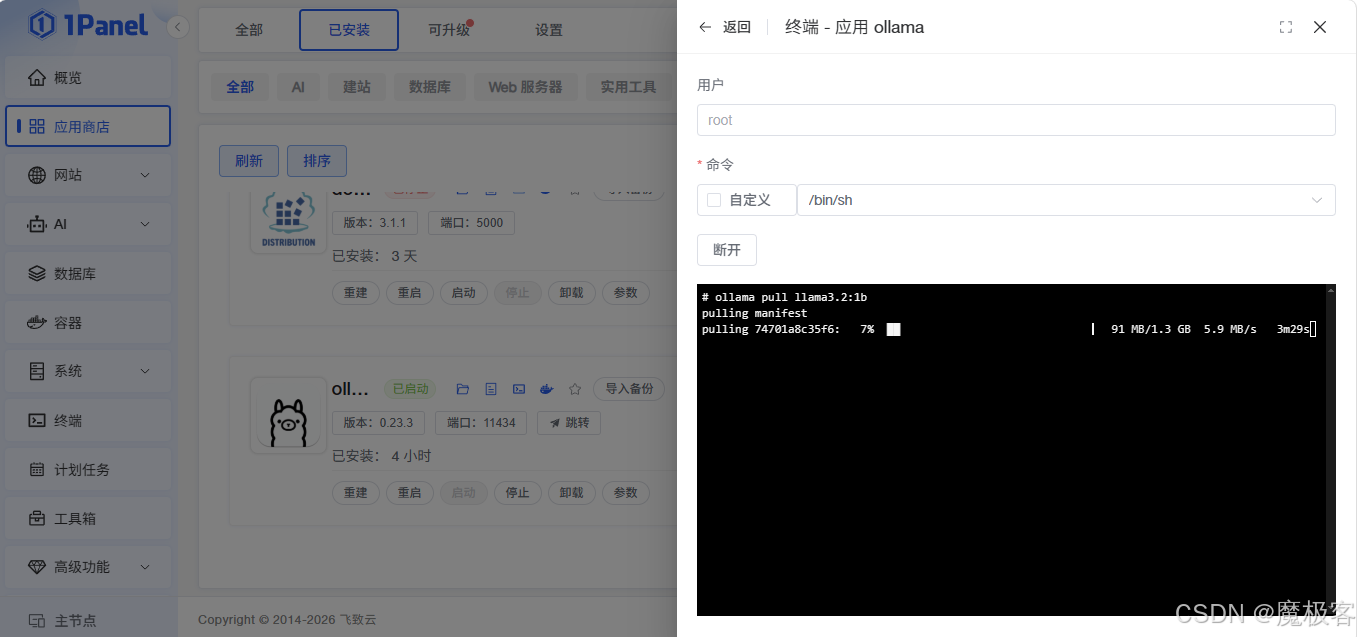
图9:在 1Panel 提供的 Web 终端中执行ollama pull llama3.2:1b命令,开始下载模型。终端会显示下载进度和验证信息。 - 下载完成后,使用
ollama run命令与模型进行交互式对话:
输入上述命令后,您会进入模型的交互式对话界面,可以直接输入问题测试。输入ollama run llama3.2:1b/bye退出对话。
提示:
- 首次下载模型需要一些时间,具体取决于模型大小和您的网络速度。
- 您也可以下载其他模型,如
llama3.2、qwen2.5:7b、gemma2:2b等,只需将命令中的模型名称替换即可。 - 模型文件会保存在您之前配置的持久化存储卷中(如
/root/.ollama),即使容器重启也不会丢失。
图8:1Panel 容器管理页面查看运行状态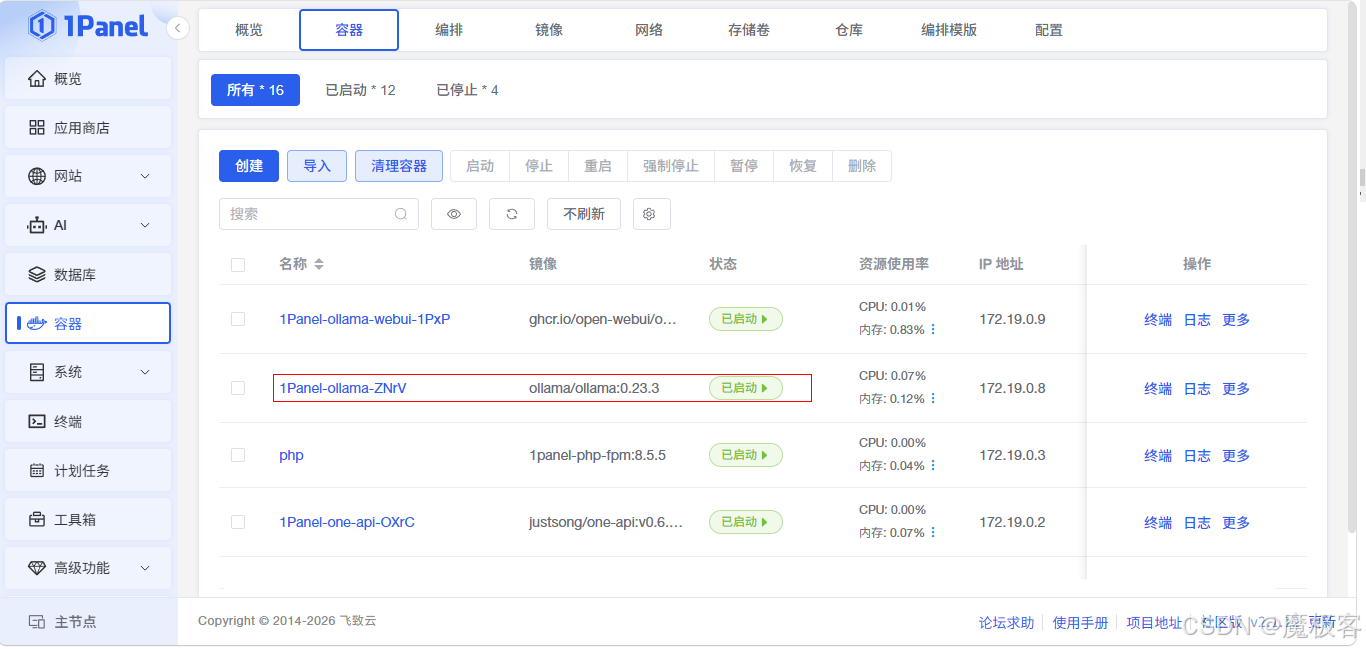
图8:安装完成后,在「容器」页面可以看到名为“ollama-server”的容器状态为“运行中”。
安装完成后,您可以在 1Panel 的「容器」页面看到名为 ollama-server(或您自定义的名称)的容器正在运行。
4. 安装后配置与基础使用
4.1 访问 Ollama API
安装完成后,您可以通过以下方式验证 Ollama 服务是否正常运行:
# 在服务器终端中执行,将 PORT 替换为您映射的宿主机端口(如 11435)
curl http://localhost:PORT/api/tags
如果返回类似 {"models":[]} 的 JSON 数据(初始为空列表),说明服务已成功启动。
4.2 拉取并运行模型
Ollama 安装后不包含任何模型,需要手动拉取。您可以通过 1Panel 提供的「终端」功能,连接到容器内部进行操作。
- 在 1Panel「容器」页面,找到您的 Ollama 容器,点击右侧的「终端」图标。
- 在打开的终端中,执行以下命令拉取一个模型(例如小巧的
llama3.2:1b模型):
您也可以拉取其他模型,如ollama pull llama3.2:1bllama3.2、qwen2.5:7b、gemma2:2b等。首次拉取需要一些时间,取决于模型大小和网络速度。 - 拉取完成后,运行模型:
这会启动一个交互式对话界面,您可以输入问题开始测试。输入ollama run llama3.2:1b/bye退出。
4.3 作为后台服务运行模型
如果您希望模型作为 API 服务长期运行,可以在容器终端中使用 ollama serve 命令,但更推荐的方式是让容器启动时自动运行服务。这通常已在 1Panel 的 Ollama 应用配置中预设好。
5. 进阶配置(可选)
5.1 配置模型存储路径
如果您在安装时未配置存储卷,模型将保存在容器内部,容器删除后模型也会丢失。为了持久化,您可以在容器创建后,通过 1Panel 修改容器配置,添加存储卷绑定,将宿主机的目录(如 /opt/ollama/models)挂载到容器的 /root/.ollama。
5.2 使用 OpenAI 兼容接口
Ollama 提供了与 OpenAI API 兼容的接口,地址为 http://<服务器IP>:<映射端口>/v1。这使得许多支持 OpenAI 的客户端(如 Chatbox, Open WebUI)可以直接连接您的私有 Ollama 服务。
5.3 通过 1Panel 反向代理暴露服务
如果您希望通过域名(如 ollama.yourdomain.com)并启用 HTTPS 来安全地访问 Ollama API,可以使用 1Panel 的「网站」功能创建反向代理。
- 在 1Panel 中创建新网站,选择「反向代理」。
- 代理地址填写
http://127.0.0.1:<映射端口>(例如http://127.0.0.1:11435)。 - 配置您的域名和 SSL 证书。
6. 常见问题排查
- 无法连接 Ollama 服务:检查 1Panel 容器状态是否为“运行中”,并确认防火墙是否放行了您映射的宿主机端口。
- 拉取模型速度慢或失败:可以尝试配置容器使用宿主机的代理环境变量,或在拉取时使用
--insecure-registry参数(不推荐用于生产环境)。 - 磁盘空间不足:大型模型可能占用数十 GB 空间。请通过
df -h命令检查磁盘使用情况,并清理空间或挂载更大容量的数据盘。
7. 总结
通过 1Panel 安装 Ollama,我们将复杂的 Docker 命令和配置转化为了简单的可视化操作,大大降低了在服务器上部署和管理 AI 模型的门槛。安装完成后,您就拥有了一个私有的、可随时调用的 LLM 服务,可以用于开发测试、自动化脚本或构建自己的 AI 应用。
赶紧去拉取您喜欢的模型,开始探索吧!
相关链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)