RAG-ANYTHING: ALL-IN-ONE RAG FRAMEWORK翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
检索增强生成(RAG)已成为突破大语言模型静态训练局限、扩展其应用范围的基本范式。然而,当前 RAG 的能力与现实世界的信息环境之间存在着严重的脱节。现代知识库本质上是多模态的,包含丰富的文本内容、视觉元素、结构化表格和数学表达式的组合。然而,现有的 RAG 框架仅限于文本内容,这在处理多模态文档时造成了根本性的缺陷。我们提出了 RAG-Anything,一个能够跨所有模态进行全面知识检索的统一框架。我们的方法将多模态内容重新概念化为相互关联的知识实体,而非孤立的数据类型。该框架引入了双图构建,以在统一的表示中捕获跨模态关系和文本语义。我们开发了一种跨模态混合检索方法,将结构化知识导航与语义匹配相结合。这使得在相关证据跨越多个模态的情况下,能够有效地对异构内容进行推理。 RAG-Anything 在具有挑战性的多模态基准测试中展现出卓越的性能,相比现有最佳方法取得了显著的改进。在传统方法难以处理的长文档上,性能提升尤为显著。我们的框架为多模态知识访问建立了一种新的范式,消除了当前系统架构碎片化的弊端。我们的框架已开源,地址为:https://github.com/HKUDS/RAG-Anything。
1.INTRODUCTION
检索增强生成(RAG)已成为扩展大语言模型(LLM)知识边界、突破其静态训练限制的基本范式。通过在推理过程中实现动态检索和外部知识的融合,RAG 系统将静态语言模型转化为自适应的、知识感知型系统。事实证明,这种能力对于需要最新信息、领域特定知识或超出预训练语料库的事实依据的应用至关重要。
然而,现有的 RAG 框架仅关注纯文本知识,而忽略了真实世界文档中丰富的多模态信息。这种局限性从根本上与信息在真实环境中的呈现方式不符。真实世界的知识库本质上是异构的、多模态的。它们包含文本内容、视觉元素、结构化表格和数学表达式等多种组合,并涵盖各种文档格式。这种基于文本的假设迫使现有的 RAG 系统要么完全丢弃非文本信息,要么将复杂的多模态内容简化为不充分的文本近似值。
在文档密集型领域,多模态内容承载着至关重要的意义,这种局限性的后果尤为严重。学术研究、金融分析和技术文档就是知识密集型环境的典型例子。这些领域从根本上依赖于视觉和结构化信息。关键见解通常完全以非文本格式编码。这类格式难以有效地转换为纯文本。
在知识密集型领域,多模态内容承载着至关重要的意义,因此这种局限性的后果尤为严重。以下三个典型场景说明了多模态 RAG 能力的迫切需求。在科学研究中,实验结果主要通过图表、示意图和统计可视化进行传达。这些图表包含着核心发现,而纯文本系统无法捕捉到这些信息。金融分析高度依赖市场图表、相关矩阵和业绩表。投资洞察以视觉模式而非文本描述的形式编码。此外,医学文献分析依赖于放射影像、诊断图表和临床数据表。这些资料包含着对准确诊断和治疗决策至关重要的生命关键信息。在所有这三个场景中,当前的 RAG 框架都系统性地忽略了这些重要的知识来源。这造成了根本性的认知缺口,使其无法满足需要全面信息理解的实际应用需求。因此,多模态 RAG 应运而生,成为一项至关重要的进步。它必须弥合这些知识缺口,并实现跨越所有人类知识表示模态的真正全面智能。
处理多模态 RAG 面临三大根本性技术挑战,需要原则性的解决方案。这使得它比传统的纯文本方法复杂得多。简单地将所有多模态内容转换为文本描述会导致严重的信息丢失。图表、示意图和空间布局等视觉元素包含丰富的语义信息,仅靠文本无法充分表达。这些固有的局限性要求设计有效的技术组件。这些组件必须专门设计用于处理多模态的复杂性,并保留各种内容类型中包含的全部信息。
Technical Challenges。首先,统一的多模态表示挑战要求无缝集成多种信息类型。系统必须保留它们的独特特征和跨模态关系。这需要先进的多模态编码器,能够在不丢失关键视觉语义的情况下捕获模态内和模态间的依赖关系。其次,结构感知分解挑战要求对复杂布局进行智能解析。系统必须维护对理解至关重要的空间和层级关系。这需要专门的布局感知解析模块,能够解释文档结构并保留多模态元素的上下文位置。第三,跨模态检索挑战需要能够在不同模态之间导航的复杂机制。这些机制必须在检索过程中推理它们之间的相互联系。这需要能够理解文本、图像和结构化数据之间语义对应关系的跨模态对齐系统。在长上下文场景中,这些挑战会更加突出。相关证据分散在多个模态和部分,需要跨异构信息源进行协调推理。
Our Contributions。为了应对这些挑战,我们提出了 RAG-Anything,这是一个从根本上重新构想多模态知识表示和检索的统一框架。我们的方法采用了一种双图构建策略,巧妙地弥合了跨模态理解和细粒度文本语义之间的鸿沟。RAG-Anything 并非将各种模态强行塞入以文本为中心的流程,而是构建互补的知识图谱,从而同时保留多模态的上下文关系和详细的文本知识。这种设计使得视觉元素、结构化数据和数学表达式能够在统一的检索框架内无缝集成。该系统在整个过程中保持了跨模态的语义完整性,同时确保了高效的跨模态推理能力。
我们的跨模态混合检索机制巧妙地将结构化知识导航与语义相似性匹配相结合。这种架构解决了现有方法仅依赖基于嵌入的检索或关键词匹配的根本局限性。RAG-Anything 利用显式的图关系来捕获多跳推理模式。它同时采用密集向量表示来识别缺乏直接结构连接的语义相关内容。该框架引入了模态感知查询处理和跨模态对齐系统。这些系统使得文本查询能够有效地访问视觉和结构化信息。这种统一的方法消除了当前多模态 RAG 系统普遍存在的架构碎片化问题。它尤其在长上下文文档上表现出卓越的性能,因为相关证据跨越多个模态和文档部分。
Experimental Validation。为了验证我们提出的方法的有效性,我们在两个具有挑战性的多模态基准数据集 DocBench 和 MMLongBench 上进行了全面的实验。评估结果表明,RAG-Anything 在多个领域均取得了优异的性能。该框架相比现有最先进的基线方法有了显著的改进。值得注意的是,随着内容长度的增加,我们的性能提升也愈发显著。我们观察到,在处理长上下文材料时,RAG-Anything 的优势尤为突出。这验证了我们的核心假设,即双图构建和跨模态混合检索对于处理复杂的多模态材料至关重要。我们的消融实验表明,基于图的知识表示是性能提升的主要来源。传统的基于 chunk 的方法无法捕捉多模态推理所必需的结构关系。案例研究进一步表明,我们的框架在复杂布局中进行精确定位方面表现出色。该系统能够有效地消除相似术语的歧义,并通过结构感知检索机制来导航多面板可视化内容。
2.THE RAG-ANYTHING FRAMEWORK
2.1 PRELIMINARY
检索增强生成(RAG)已成为动态扩展 LLM 知识边界的基本范式。尽管 LLM 展现出卓越的推理能力,但其知识仍然静态,并受限于训练数据的截断。这导致其与快速发展的信息环境之间的差距日益扩大。RAG 系统通过使 LLM 能够在推理过程中检索和整合外部知识源来解决这一关键限制。这使得 LLM 从静态知识库转变为自适应的、知识感知型系统。
The Multimodal Reality: Beyond Text-Only RAG。当前的 RAG 系统面临一个关键的局限性,严重限制了它们在实际应用中的部署。现有框架基于一个狭隘的假设,即知识库完全由纯文本文件构成。这一假设与信息在真实环境中的呈现方式存在根本性的偏差。现实世界的知识库本质上是异构的、多模态的,包含丰富的文本内容、视觉元素、结构化数据和数学表达式的组合。这些多样化的知识来源涵盖多种文档格式和呈现媒介,从研究论文和技术幻灯片到网页和交互式文档。
2.1.1 MOTIVATING RAG-ANYTHING
这种多模态现实带来了根本性的技术挑战,暴露了当前仅基于文本的 RAG 方法的不足。有效的多模态 RAG 需要统一的索引策略来处理不同的数据类型,需要跨模态检索机制来保持不同模态之间的语义关系,还需要复杂的合成技术来协调整合各种信息源。这些挑战要求采用截然不同的架构方法,而不是对现有系统进行渐进式改进。
RAG-Anything 框架引入了一种统一的方法,用于从异构多模态信息源中检索和处理知识。我们的系统解决了在检索流程中处理多种数据模态和文档格式这一根本挑战。该框架包含三个核心组件:多模态知识通用索引、跨模态自适应检索和知识增强型响应生成。这种集成设计能够在保持计算效率的同时,有效利用跨模态的知识。
2.2 UNIVERSAL REPRESENTATION FOR HETEROGENEOUS KNOWLEDGE
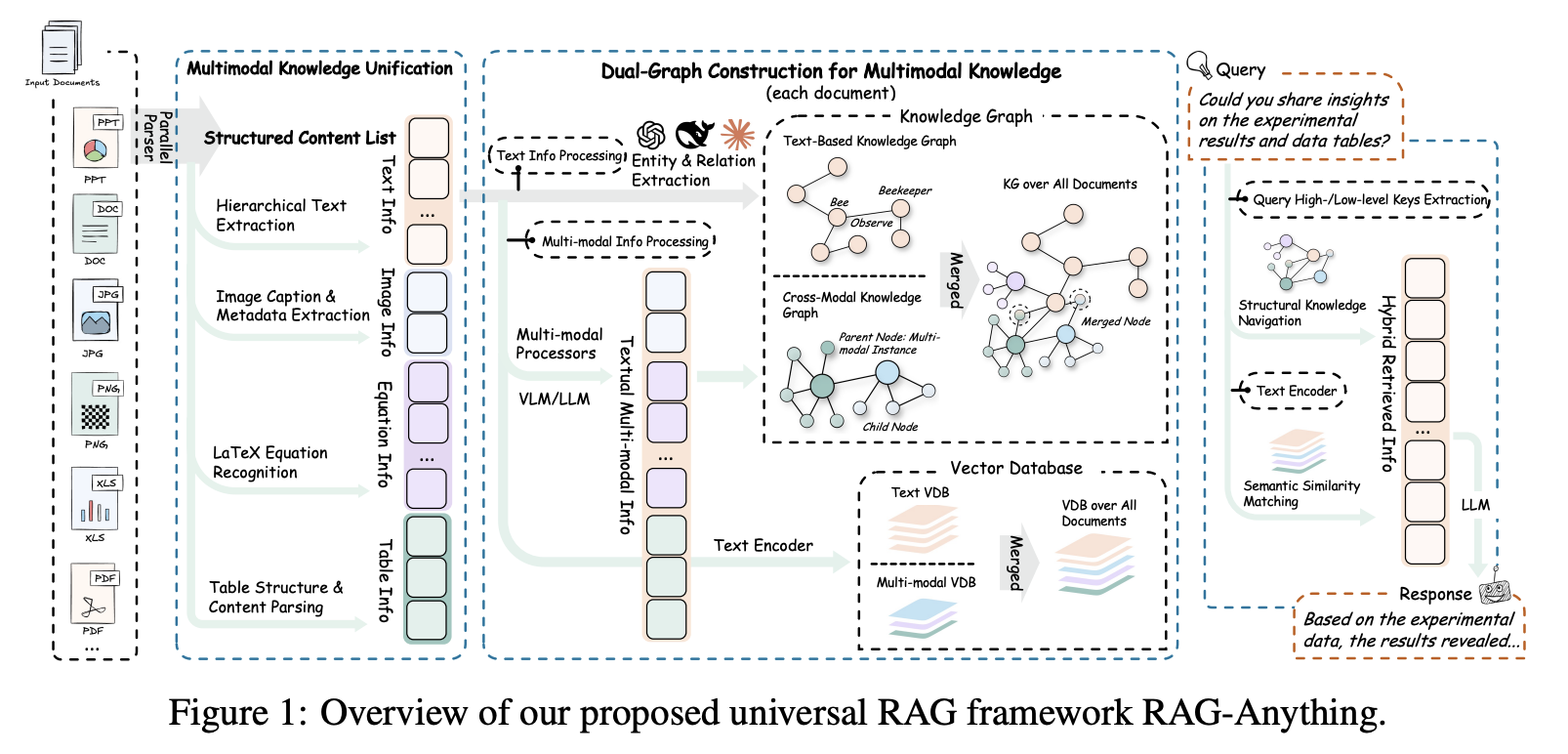
实现通用知识访问的关键要求在于能够以统一的、面向检索的抽象形式表示异构的多模态内容。与现有流程简单地将文档解析为文本片段不同,RAG-Anything 引入了多模态知识统一技术。该技术将原始输入分解为原子知识单元,同时保留其结构上下文和语义对齐。例如,RAG-Anything 确保图表与其图注保持关联,公式与其周围的定义保持链接,表格与其解释性叙述保持联系。这使得异构文件能够转化为用于跨模态检索的连贯基础。
形式上,每个知识源 ki∈Kk_i ∈ \mathcal Kki∈K(例如,一个网页)都被分解成原子内容单元:
ki→Decompose{cj=(tj,xj)}j=1ni,(1) k_i \xrightarrow{\mathrm{Decompose}} \{c_j = (t_j, x_j)\}_{j=1}^{n_i}, \tag{1} kiDecompose{cj=(tj,xj)}j=1ni,(1)
其中每个单元 cjc_jcj 由模态类型 tj∈text、image、table、equation,...t_j ∈ text、image、table、equation, ...tj∈text、image、table、equation,... 及其对应的原始内容 xjx_jxj 组成。内容 xjx_jxj 表示从原始知识源中提取的信息,并以模态感知的方式进行处理,以保持语义完整性。
为了确保高保真提取,RAG-Anything 利用针对不同内容类型的专用解析器。文本被分割成连贯的段落或列表项。图形及其相关元数据(例如图注和交叉引用)被提取出来。表格被解析成带有表头和值的结构化单元格。数学表达式被转换为符号表示。生成的 xjx_jxj 文件保留了源文件中的内容和结构上下文,从而提供了一种忠实且模态一致的表示。这种分解将各种文件格式抽象成原子单元,同时保持其层级顺序和上下文关系。这种规范化使得我们的框架能够对多模态内容进行统一的处理、索引和检索。
2.2.1 DUAL-GRAPH CONSTRUCTION FOR MULTIMODAL KNOWLEDGE
尽管多模态知识统一提供了跨模态的统一抽象,但直接构建单一的统一图谱往往会忽略模态特有的结构信号。本文提出的 RAG-Anything 通过双图构建策略解决了这一难题。该系统首先构建一个(1)跨模态知识图谱,将非文本模态忠实地锚定在其上下文环境中。然后,它利用成熟的以文本为中心的提取流程构建一个(2)基于文本的知识图谱。这两个互补的图谱(3)通过实体对齐进行合并。这种设计确保了准确的跨模态锚定和对文本语义的全面覆盖,从而实现更丰富的知识表示和更强大的检索能力。
-
Cross-Modal Knowledge Graph:图像、表格和公式等非文本内容包含丰富的语义信息,而传统的纯文本方法往往忽略这些信息。为了保留这些信息,RAG-Anything 构建了一个多模态知识图谱,将非文本原子单元转换为结构化的图实体。RAG-Anything 利用多模态大语言模型,从每个原子内容单元中导出两种互补的文本表示。第一种是针对跨模态检索优化的详细描述 djchunkd^{chunk}_jdjchunk。第二种是实体摘要 ejentitye^{entity}_jejentity,其中包含用于构建图的关键属性,例如实体名称、类型和描述。生成过程具有上下文感知能力,使用其局部邻域 Cj={ck∣∣k−j∣≤δ}C_j = \{c_k |\quad |k − j| ≤ δ\}Cj={ck∣∣k−j∣≤δ} 处理每个单元,其中 δδδ 控制上下文窗口的大小。这确保了表示能够准确反映每个单元在更广泛的文档结构中的作用。
基于这些文本表示,RAG-Anything 使用非文本单元作为锚点构建图结构。对于每个非文本单元 cjc_jcj,图提取例程 R(⋅)R(·)R(⋅) 处理其描述 djchunkd^{chunk}_jdjchunk,以识别细粒度的实体和关系:
(Vj,Ej)=R(djchunk),(2) (\mathcal V_j,\mathcal E_j)=R(d^{chunk}_j),\tag{2} (Vj,Ej)=R(djchunk),(2)
其中 Vj\mathcal V_jVj 和 Ej\mathcal E_jEj 分别表示块内实体及其关系的集合。每个原子非文本单元都与一个多模态实体节点 vjmmv^{mm}_jvjmm 相关联,该节点通过显式 belongs_tobelongs\_tobelongs_to 边作为其块内实体的锚点:
V~={vjmm}j∪⋃jVj,(3) \tilde{V} = \{v_j^{\mathrm{mm}}\}_j \cup \bigcup_j \mathcal{V}_j, \tag{3} V~={vjmm}j∪j⋃Vj,(3)
E~=⋃jEj∪⋃j{(u→belongs_tovjmm):u∈Vj}.(4) \tilde{E} = \bigcup_j \mathcal{E}_j \cup \bigcup_j \{(u \xrightarrow{\mathrm{belongs\_to}} v_j^{\mathrm{mm}}) : u \in \mathcal{V}_j\}. \tag{4} E~=j⋃Ej∪j⋃{(ubelongs_tovjmm):u∈Vj}.(4)
这种结构既保留了特定模态的基础性,又确保非文本内容能够被其文本邻域所理解。这使得可靠的跨模态检索和推理成为可能。 -
Text-based Knowledge Graph:对于文本模态片段,我们遵循类似于 LightRAG 和 GraphRAG 的成熟方法构建传统的基于文本的知识图谱。提取过程直接作用于文本内容 xjx_jxj(其中 tjt_jtj 代表文本),利用命名实体识别和关系抽取技术来识别实体及其语义关系。鉴于文本内容中蕴含丰富的语义信息,该组件无需进行多模态上下文集成。最终得到的基于文本的知识图谱能够捕捉文档文本部分中存在的显式知识和语义连接,从而补充多模态图谱的跨模态关联能力。
2.2.2 GRAPH FUSION AND INDEX CREATION
独立的跨模态知识图谱和基于文本的知识图谱分别捕捉了文档语义的互补方面。将它们整合起来,可以创建一个统一的表示,利用视觉-文本关联和细粒度的文本关系来增强检索效果。
-
(i) Entity Alignment and Graph Fusion。为了构建统一的知识表示,我们通过实体对齐将多模态知识图谱 (V~,E~)(\tilde V, \tilde E)(V~,E~) 和基于文本的知识图谱合并。此过程使用实体名称作为主匹配键,以识别两种图结构中语义等价的实体。合并后的知识图谱整合了它们的表示,生成了一个综合的知识图谱 G=(V,E)\mathcal G = (\mathcal V, \mathcal E)G=(V,E)。该图谱同时捕捉了多模态上下文关系和基于文本的语义连接。合并后的图谱提供了文档集合的整体视图。这使得我们能够利用多模态图中的视觉-文本关联和基于文本图中的细粒度文本知识关系,实现高效的检索。
-
(ii) Dense Representation Generation。为了实现高效的基于相似性的检索,我们构建了一个包含索引过程中生成的所有组件的综合嵌入表 T\mathcal TT。我们使用合适的编码器对所有模态的图实体、关系和原子内容块进行密集表示编码。这创建了一个统一的嵌入空间,其中每个组件 s∈entities,relations,chunkss ∈ entities, relations, chunkss∈entities,relations,chunks 都映射到其对应的密集表示:
T=emb(s):s∈V∪E∪cjj,(5) \mathcal T=emb(s):s\in\mathcal V∪\mathcal E∪c_{j_j},\tag{5} T=emb(s):s∈V∪E∪cjj,(5)
其中 emb(⋅)emb(·)emb(⋅) 表示针对每种组件类型定制的嵌入函数。统一的知识图谱 G\mathcal GG 和嵌入表 T\mathcal TT 共同构成完整的检索索引 I=(G,T)\mathcal I = (\mathcal G, \mathcal T)I=(G,T)。这为后续检索阶段高效的跨模态相似性搜索提供了结构化的知识表示和稠密的向量空间。
2.3 CROSS-MODAL HYBRID RETRIEVAL
检索阶段基于索引 I=(G,T)\mathcal I = (\mathcal G, \mathcal T)I=(G,T) 来识别给定用户 query 的相关知识组件。传统的 RAG 方法在处理多模态文档时面临诸多局限性。它们通常依赖于单一模态内的语义相似性,而无法捕捉视觉、数学、表格和文本元素之间丰富的相互关联。为了应对这些挑战,我们的框架引入了一种跨模态混合检索机制。该机制利用了异构模态中的结构知识和语义表示。
Modality-Aware Query Encoding。给定用户 query qqq,我们首先进行模态感知 query 分析,提取 query 中蕴含的词汇线索和潜在的模态偏好。例如,包含“图形”、“图表”、“表格”或“公式”等词语的 query,能够明确地指示相关信息的预期模态。然后,我们使用与索引过程中相同的编码器计算统一的文本嵌入 eq,从而确保 query 表示与知识表示的一致性。这种基于嵌入的方法实现了跨模态检索功能,使得文本 qyert 能够通过共享的表示有效地访问多模态内容,在保持跨模态可访问性的同时,也确保了检索的一致性。
Hybrid Knowledge Retrieval Architecture。认识到知识相关性既体现在显式的结构联系上,也体现在隐式的语义关系上,我们设计了一种混合检索架构,巧妙地结合了两种互补的机制。
-
(i) Structural Knowledge Navigation。该机制旨在解决捕捉显式关系和多跳推理模式的难题。传统的基于关键词的检索方法通常无法识别通过中间实体或跨模态关系连接的知识。为了克服这一局限性,我们利用统一知识图谱 G\mathcal GG 中编码的结构属性。我们采用关键词匹配和实体识别来定位相关的图谱组件。检索过程首先将实体与查询词进行精确匹配。
然后,我们进行策略性邻域扩展,将指定跳数范围内的相关实体和关系纳入其中。这种结构化方法在揭示跨多种模态的高级语义连接和实体关系模式方面尤为有效。它充分利用了我们多模态知识图谱中建立的丰富的跨模态链接。结构化导航生成候选集 Cstru(q)\mathcal C_{stru}(q)Cstru(q),其中包含相关的实体、关系及其关联的内容块,从而提供全面的上下文信息。 -
(ii) Semantic Similarity Matching。该机制旨在解决识别缺乏明确结构连接的语义相关知识的难题。虽然结构导航擅长追踪显式关系,但它可能会遗漏语义相关但并非直接连接在图拓扑结构中的相关内容。为了弥补这一不足,我们对 query 嵌入 eqe_qeq 和嵌入表 KaTeX parse error: Undefined control sequence: \matgcak at position 1: \̲m̲a̲t̲g̲c̲a̲k̲ ̲T 中存储的所有组件进行密集向量相似度搜索。
这种方法涵盖了所有模态的原子内容块、图实体和关系表示,从而实现了细粒度的语义匹配,即使在缺乏传统词汇或结构信号的情况下也能提取相关知识。学习到的嵌入空间捕捉了细微的语义关系和上下文相似性,补充了来自导航机制的显式结构信号。该检索路径返回根据余弦相似度得分排序的 top-k 个语义最相似的内容块 Cseman(q)\mathcal C_{seman}(q)Cseman(q),确保全面覆盖结构和语义相关的知识。
Candidate Pool Unification。两种检索路径可能会返回具有不同相关性信号的重叠候选结果。这就需要一种原则性的方法来统一和排序结果。来自两种路径的检索候选结果被统一到一个综合候选池中:C(q)=Cstru(q)∪Cseman(q)\mathcal C(q) = \mathcal C_{stru}(q) ∪ \mathcal C_{seman}(q)C(q)=Cstru(q)∪Cseman(q)。简单地合并候选结果会忽略每条路径提供的独特证据,也无法解决检索内容之间的冗余问题。
- (i) Multi-Signal Fusion Scoring。为了应对这些挑战,我们采用了一种复杂的融合评分机制,整合了多种互补的相关性信号。这些信号包括源自图拓扑的结构重要性、来自嵌入空间的语义相似度得分,以及通过词汇分析获得的查询推断模态偏好。这种多维度的评分方法确保最终排名的候选 C⋆(q)C^⋆(q)C⋆(q) 能够有效地平衡结构知识关系和语义相关性,并根据 query 特征对不同模态进行适当的加权。
- (ii) Hybrid Retrieval Integration。由此产生的混合检索机制使我们的框架能够充分利用知识图谱和密集表示的互补优势。这为响应生成提供了对相关多模态知识的全面覆盖。
2.4 FROM RETRIEVAL TO SYNTHESIS
有效的多模态问答系统需要在保留丰富的视觉语义的同时,保持跨异构知识源的连贯性。简单的纯文本方法会丢失关键的视觉信息,而简单的多模态方法则难以实现连贯的跨模态整合。我们的综合阶段通过系统地将检索到的多模态知识整合为全面、有证据支持的答案,从而应对这些挑战。
-
(i) Building Textual Context。给定排名靠前的检索候选结果 C⋆(q)C^⋆(q)C⋆(q),我们构建一个结构化的文本上下文。我们将所有检索到的组件的文本表示连接起来,包括实体摘要、关系描述和块内容。连接过程中使用适当的分隔符来指示模态类型和层级来源。这种方法确保语言模型能够有效地解析和推理异构知识组件。
-
(ii) Recovering Visual Content。对于与视觉制品相对应的多模态块,我们执行解引用以恢复原始视觉内容,从而创建 V⋆(q)\mathcal{V}^{\star}(q)V⋆(q)。该设计与我们统一的嵌入策略保持一致。文本代理能够实现高效检索,而真实的视觉内容则提供了丰富的语义信息,这对于合成阶段的复杂推理是必要的。
合成过程同时基于组装后的综合文本上下文和解引用后的视觉制品,并使用视觉语言模型进行联合条件生成:
Response=VLM(q,P(q),V⋆(q)),(6) \mathrm{Response} = \mathrm{VLM}(q, \mathcal{P}(q), \mathcal{V}^{\star}(q)), \tag{6} Response=VLM(q,P(q),V⋆(q)),(6)
其中,VLM 整合来自查询、文本上下文和视觉内容的信息。这种统一的条件建模在保持基于检索证据的同时,实现了复杂的视觉解释。最终生成的响应既具有视觉信息支撑,也具备事实依据。
3.EVALUATION

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)