C++11_3:包装器,智能指针
包装器
template<class T>
class function;
template<class Ret, class ...Args>
class function<Ret(Args...)>; // 返回值(参数列表)
上面是包装器的定义,是一个类模板,std::function的实例对象可以包装存储其他的可调用对象,包括函数指针、仿函数、lambda、bind表达式等,存储的表达式被称为std::function的目标。若std::function不含目标,则称它为空。调用空std::function会抛异常。
函数指针、仿函数、lambda等可调用对象的类型各不相同,std::function的优势是可以统一类型,这样再很多地方就方便声明可调用对象的类型
#include<functional>
int f(int a, int b)
{
return a + b;
}
// 仿函数
struct Functor{
public :
int operator() (int a, int b){
return a + b;
}
};
class Plus{
public:
Plus(int n = 10)
: _n(n)
{}
static int plusi(int a, int b){
return a + b;
}
double plusd(double a, double b){
return (a + b) * _n;
}
private:
int _n;
};
int main() {
// 包装各种可调用对象
function<int(int, int)> f1 = f; // 包装函数指针
function<int(int, int)> f2 = Functor(); // 包装一个仿函数的匿名对象
function<int(int, int)> f3 = [](int a, int b) {return a + b;}; // 包装一个lambda表达式
cout << f1(1, 2) << endl;
cout << f2(1, 3) << endl;
cout << f3(1, 4) << endl;
//cout << Functor()(1, 2) << endl;
// 包装静态成员函数
// 成员函数必须指定类域且要加上&才能获取地址
function<int(int, int)> f4 = &Plus::plusi;
// 包装成员函数
// 普通成员函数还有一个隐含的this指针,绑定时传对象或对象的指针都可以
function<double(Plus*, double, double)> f5 = &Plus::plusd;
Plus pd;
cout << f5(&pd, 1.1, 2.2) << endl;
// 传递普通对象
function<double(Plus, double, double)> f6 = &Plus::plusd;
cout << f6(pd, 2.2, 3.3) << endl;
// 将右值引用的指针传递给function,让它使用右值对象调用
function<double(Plus&&, double, double)> f7 = &Plus::plusd;
cout << f7(Plus(), 2.2, 3.3) << endl;
cout << f7(move(pd), 2.2, 3.3) << endl;
return 0;
}
智能指针
智能指针的使用场景分析
下面的程序中可以看到,在func1函数中 new了一个int数组,但如果ProcessDate内部抛出异常,就永远不会执行delete,导致内存泄漏,如果手动进行管理会很困难,所以需要用到智能指针来进行管理。
void fun1() {
int* a1 = new int[10];
try {
ProcessData(); // 如果这里抛出异常,控制流直接跳走
delete[] a1; // 这行代码永远不会执行,导致严重内存泄漏!
} catch (...) { throw; }
}
RAII和智能指针的设计思路
RAII是Resource Acquisition Is Initialization(资源获取立即初始化)的缩写,是一种管理资源的类的设计思想,本质是一种利用对象的生命周期来管理获取到的资源,避免内存泄漏,这里的资源可以是内存,文件指针,网络连接,互斥锁等等。RAII在获取资源时把资源委托给一个对象,这个对象控制的资源的访问,在对象的生命周期内,资源始终保持有效,在对象析构时,将资源释放,这样就保障了资源的正常释放,避免了内存泄漏的问题
下面的程序是一个简单的演示
void fun1() {
smartpointer<int> a1 = new int(10);
try {
ProcessData(); // 如果这里抛出异常,控制流直接跳走
// 进行栈展开
} catch (...) { throw; }
}
程序中smartpointer是一个类的对象,用这个类的对象来接收创建的int对象,随后ProcessData抛出异常,程序进行栈展开,开始匹配catch,注意在栈展开的过程中,对象是会被正确销毁的,所以此时a1申请的资源会随着对象的析构被正确释放,不会造成内存泄漏
通过上面的例子可以看出,智能指针首先是一个满足RAII设计思想的类,其次这个类的行为是模拟实现指针的行为,所以在类内还需要重载 operator*/operator->/operator[]等运算符
通过以上的思路,可以设计出一个简单的智能指针类
template<class T>
class SmartPtr {
SmartPtr(const T* ptr)
:_ptr(ptr)
{}
~SmartPtr() {
if (_ptr)
delete _ptr;
cout << "delete[]" << _ptr << endl;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
T& operator[](size_t pos) {
return _ptr[pos];
}
private:
T* _ptr = nullptr;
};
这是一个简单的智能指针,当然还存在缺陷,先按住不表,看标准库中是如何实现的
C++标准库智能指针的初步使用
C++标准库中的智能指针都在<memory>这个头文件下,智能指针有多种,除了weak_ptr都符合 RAII 和像指针一样访问的行为,差别是实现智能指针的思路不同
auto_ptrC++98 时设计出的智能指针,特点是拷贝时把被拷贝的对象的资源的管理权移交给拷贝对象,这样设计会导致一个问题,被拷贝的对象悬空,此时如果有人去访问被拷贝的对象,就会导致访问空指针的问题,会报错,C++11设计出新的智能指针后,强烈建议不要使用auto_ptr。
// 这里编译器也可能报错,编译器版本太新
// c++17后,auto_ptr被从标准库中删除,使用可能会不认识
auto_ptr<Date> ap1(new Date);
auto_ptr<Date> ap2(ap1);
// 访问空指针,报错,ap1已经被转移
ap1->_year++;
unique_ptr是C++11设计出的智能指针,翻译为唯一指针,特点是不支持拷贝,只支持移动,不需要拷贝的场景建议使用它。
支持移动,就意味着它能从右值中掠夺资源,所以下面代码中使用move(up1)将up1变为一个右值,就能够被移动走,此时up1也是悬空状态,去访问依旧会报错,但这里的错误不是设计引起的,而是程序员的代码引起的,程序员在使用move时就要知道会存在资源被移动走的可能,所以使用move就代表知道可能会产生错误,这是产生了错误就不能怪设计了
unique_ptr<Date> up1(new Date);
// 报错,不支持拷贝
//unique_ptr<Date> up2(up1);
// 支持移动,此时up1中的资源被移动走
unique_ptr<Date> up2(move(up1));
// 右值,移动构造
unique_ptr<Date> up3(Date());
shared_ptr是C++11设计出来的智能指针,翻译为共享指针,特点是支持拷贝,也支持移动。如果需要拷贝的场景就需要使用他。底层是用引用计数的方式实现的。
shared_ptr<Date> sp1(new Date);
// 支持拷贝
shared_ptr<Date> sp2(sp1);
shared_ptr<Date> sp3(sp2);
cout << sp1.use_count() << endl; // 查看有多少个智能指针指向这块空间
sp1->_year++;
// 指向同一块空间,其中一个修改会影响另一个
cout << sp1->_year << endl;
cout << sp2->_year << endl;
cout << sp3->_year << endl;
// 支持移动,但是移动后sp1也悬空
shared_ptr<Date> sp4(move(sp1));
-------------------------------------
3
2
2
2
~Date() // 三个指针指向同一块空间,所以只需要析构一次
智能指针的原理
通过刚刚简单了解了一下库中的智能指针的使用,可以感受到auto_ptr和unique_ptr这两个智能指针的实现思路其实挺简单的,auto_ptr的思路是拷贝的时候控制权转移,将被拷贝的对象置空就行,unique_ptr的思路就是将拷贝构造和拷贝赋值这两个函数删除就行,只提供移动构造和移动赋值
// 使用命名空间包裹,避免跟标准库冲突
namespace xuan {
// auto_ptr
template<class T>
class auto_ptr {
public:
auto_ptr(T* ptr)
:_ptr(ptr)
{}
auto_ptr(auto_ptr<T>& ap)
:_ptr(ap._ptr) // 交换控制权
{
ap._ptr = nullptr; // 将被拷贝对象置空
}
~auto_ptr() {
delete _ptr;
}
// 赋值运算符重载
auto_ptr<T>& operator=(auto_ptr<T>& ap) {
// 判断是否给自己赋值
if (this != ap) {
// 释放当前对象中的资源
delete _ptr;
_ptr = ap._ptr;
ap._ptr = nullptr;
}
return *this;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
T& operator[](size_t pos) {
return _ptr[pos];
}
private:
T* _ptr = nullptr;
};
// unique_ptr
template<class T>
class unique_ptr {
public:
unique_ptr(T* ptr)
:_ptr(ptr)
{}
~unique_ptr() {
delete _ptr;
}
// 删除掉拷贝构造跟拷贝赋值
unique_ptr(const unique_ptr<T>& up) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>& up) = delete;
// 提供移动构造和移动赋值,只接收右值
unique_ptr(unique_ptr<T>&& up)
:_ptr(up._ptr) // 移动构造是掠夺资源,也就相当于控制权转移
{
up._ptr = nullptr;
}
unique_ptr<T>& operator=(unique_ptr<T>&& up) {
delete _ptr;
_ptr = up._ptr;
up._ptr = nullptr;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
T& operator[](size_t pos) {
return _ptr[pos];
}
private:
T* _ptr = nullptr;
};
}
可以看到,上面两个智能指针auto_ptr 和unique_ptr的基本功能的实现都不算困难,这是因为这两个智能指针都不涉及拷贝
在刚刚所演示的shared_ptr的使用时,用一个新的智能指针去拷贝另一个智能指针时,是一个浅拷贝的过程,这里不像容器的拷贝,一个string去拷贝另一个string,是深拷贝,需要重新开辟一片空间,而对于智能指针,它是要模拟实现指针的行为,而将一个指针赋值给另一个指针时,所期望的并不是重新开辟一块新的空间,而是让两个指针指向同一块空间
所以对于shared_ptr需要设计在拷贝时是浅拷贝,同时指向这一块资源的某个对象在析构时不能直接销毁资源,当负责管理这一块资源的对象全部析构时,这块资源才销毁
要达到这个效果,就必须要添加一个变量来存储指向这一块资源的个数,每当出现一个对象指向这块资源时,这个计数 ++ ,每当析构一个对象时,这个计数 – ,当计数值为0时销毁这一块资源
1.直接使用一个int变量来存储
template<class T>
class shared_ptr{
shared_ptr(shared_ptr<T>& sp){
_ptr = sp._ptr;
_count++;
}
pirvate:
T* _ptr;
int _count;
}
这样设计的话,每一个对象中都有一个计数,它们之间互不影响
shared_ptr<Date> sp1(new int(10)); // sp1 引用计数为1
shared_ptr<Date> sp2(sp1); // 拷贝构造,要求是拷贝构造后
// sp1._count = 2; sp2._count = 2;
// 但是这样设计,实际拷贝构造后
// sp1._count = 1; sp2._count = 1;
互不影响就造成引用计数的值没办法正确修改,所以这样的设计是不对的
2.使用静态变量来存储
template<class T>
class shared_ptr{
shared_ptr(shared_ptr<T>& sp){
_ptr = sp._ptr;
_count++;
}
pirvate:
T* _ptr;
static int _count;
}
这样设计,所有的智能指针对象都共享一个计数,会导致一个对象修改,所有对象的计数都会修改,如果两个智能指针指向的是不同资源,就会导致错误修改计数
shared_ptr<Date> sp1(new Date);
shared_ptr<Date> sp2(sp1); // 拷贝构造后 _count = 2;
shared_ptr<Date> sp3(new Date); // 重新开辟一个对象,指向另一块不同的资源
// 需要的结果是 sp3._count = 1; sp1._count = 2
// 实际上因为所有shared_ptr共享一个_count
// 导致结果是 sp3._count = 3; sp1._count = 3;
这样错误修改引用计数,就会导致析构时,sp3的引用计数为 3, 但只有一个对象指向这块资源,导致资源没有被释放,造成内存泄漏,所以这样设计也不行
3.将引用计数设计为动态开辟的空间
template<class T>
class shared_ptr{
shared_ptr(shared_ptr<T>& sp){
_ptr = sp._ptr;
_count++;
}
pirvate:
T* _ptr;
int* _pcount;
}
在堆上开辟一块空间来存储有多少个对象指向这块空间,每当新建一个指向这块空间的对象,就让这个新对象的_pcount指向先前开辟好的空间,此时++,就会影响到所有指向这块空间的对象的引用计数
根据这样的设计,就能实现一个简单的shared_ptr
namespace xuan {
// shared_ptr
template<class T>
class shared_ptr {
public:
shared_ptr(T* ptr)
:_ptr(ptr)
,_pcount(new int(1)) // 指向这块资源的最开始只有一个
{}
// 拷贝构造
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
,_pcount(sp._pcount)
{
++(*_pcount);
}
~shared_ptr() {
// 进行一次析构,就少一个指向这块资源的对象,所以要先--
// --到0以后,说明没有指向这块资源的对象了,就能销毁这块资源了
if (--(*_pcount) == 0) {
delete _ptr;
delete _pcount;
}
}
// 拷贝赋值
shared_ptr<T>& operator=(const shared_ptr<T>& sp) {
// 判断是否给自己赋值
if (_ptr != sp._ptr) {
// 判断当前管理的资源是否需要释放
if (--(*_pcount) == 0) {
delete _ptr;
delete _pcount;
}
_ptr = sp._ptr;
_pcount = sp._pcount;
*_pcount++;
}
return *this;
}
size_t use_count(){
return *_pcount;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
T& operator[](size_t pos) {
return _ptr[pos];
}
private:
T* _ptr;
int* _pcount;
};
}
用刚才的程序测试一下
int main() {
xuan::shared_ptr<Date> sp1(new Date);
// 支持拷贝
xuan::shared_ptr<Date> sp2(sp1);
xuan::shared_ptr<Date> sp3(sp2);
cout << sp1.use_count() << endl; // 查看有多少个智能指针指向这块空间
sp1->_year++;
// 指向同一块空间,其中一个修改会影响另一个
cout << sp1->_year << endl;
cout << sp2->_year << endl;
cout << sp3->_year << endl;
return 0;
}
--------------------------------------------
3
2
2
2
~Date()
可以看到测试的结果跟库中的结果是一样的,这说明大致框架以及差不多实现了,但这里还有一个问题
刚才所使用的测试用例都是单个对象,那如果是数组呢,如果是在开辟一个数组交给我们刚刚实现的智能指针管理,都不用测试,有一个很显然的问题,在销毁资源时,使用的是delete而不是delete[],那么在销毁动态开辟的数组时,就会出问题
定制删除器
智能指针析构时默认是使用delete释放资源,这也意味着如果不是new出来的资源,交给智能指针管理,析构时就会崩溃。
智能指针支持在构造时给一个删除器,删除器本质上是应该可调用对象,这个可调用对象会按照需要方式去释放资源,当构造智能指针时,给了定制删除器,在析构时就会调用删除器去释放资源。
因为new[]经常使用,所以为了简洁一点,unique_ptr和shared_ptr都特化了一份 [] 的版本,可以直接按照下面的方式管理 new[] 的资源
unique_ptr<Date[]> up1(new Date[5]);
shared_ptr<Date[]> sp1(new Date[5]);
删除器是一个可调用对象,也就是说删除器可以是函数指针,仿函数,以及lambda表达式
unique_ptr使用删除器的方式是将删除器的类型和对象一起传
shared_ptr使用删除器的方式只需要传删除器的对象即可
template<class T>
void DeleteArrayFunc(T* ptr) {
delete[] ptr;
}
template<class T>
class DeleteArray {
public:
void operator()(T* ptr) {
delete[] ptr;
}
};
int main() {
// 这样实现会导致程序崩溃
//unique_ptr<Date> up1(new Date[5]);
//shared_ptr<Date> sp1(new Date[5]);
// 解决方案1
// 因为new[]经常使用,所以库中已经实现了特化版本
// 使用这个特化版本,析构时使用的delete[]
unique_ptr<Date[]> up1(new Date[5]);
shared_ptr<Date[]> sp1(new Date[5]);
// 解决方案2:定制删除器
// 函数指针做删除器
unique_ptr<Date, void(*)(Date*)> up2(new Date[5], DeleteArrayFunc<Date>);
shared_ptr<Date> sp2(new Date[5], DeleteArrayFunc<Date>);
// 仿函数做删除器
unique_ptr<Date, DeleteArray<Date>> up3(new Date[5]);
shared_ptr<Date> sp3(new Date[5], DeleteArray<Date>());
// lambda表达式做删除器
auto delarrOBJ = [](Date* ptr) {delete[] ptr;};
shared_ptr<Date> sp4(new Date[5], delarrOBJ);
unique_ptr<Date, decltype(delarrOBJ)> up4(new Date[5], delarrOBJ);
// 使用匿名对象作为删除器
shared_ptr<Date> sp5(new Date[5], [](Date* ptr){ delete[] ptr; };);
return 0;
}
总结:
对于unique_ptr推荐使用仿函数作为定制删除器
对于shared_ptr推荐使用lambda表达式作为定制删除器
通过刚刚的使用,就可以通过加入删除器来进一步完善刚刚实现的shared_ptr,只完善shared_ptr,对于unique_ptr,只需在模板参数添加一个模板参数,在销毁资源时实例化一个删除器对象调用即可
shared_ptr使用删除器时,是在构造函数处添加的
namespace{
// shared_ptr
template<class T>
class shared_ptr {
public:
shared_ptr(T* ptr)
:_ptr(ptr)
, _pcount(new int(1)) // 指向这块资源的最开始只有一个
{}
template<class D>
shared_ptr(T* ptr, D del)
:_ptr(ptr)
,_pcount(new int(1))
,_del(del)
{}
// 拷贝构造
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
{
++(*_pcount);
}
~shared_ptr() {
// 进行一次析构,就少一个指向这块资源的对象,所以要先--
// --到0以后,说明没有指向这块资源的对象了,就能销毁这块资源了
release();
}
// 拷贝赋值
shared_ptr<T>& operator=(const shared_ptr<T>& sp) {
// 判断是否给自己赋值
if (_ptr != sp._ptr) {
// 判断当前管理的资源是否需要释放
release();
_ptr = sp._ptr;
_pcount = sp._pcount;
++(*_pcount);
}
return *this;
}
// 专门负责释放的函数
void release() {
if (--(*_pcount) == 0) {
_del(_ptr);
delete _pcount;
_ptr = nullptr;
_pcount = nullptr;
}
}
size_t use_count() {
return *_pcount;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
T& operator[](size_t pos) {
return _ptr[pos];
}
private:
T* _ptr;
int* _pcount;
// 用一个包装器接收删除器
// 因为删除器的类型不确定,可能是函数指针,仿函数,lambda
// 而且模板是在构造函数,不是在整个类,所以不能用函数模板
// 而包装器就可以接收所有上面的类型
// 同时要给上默认值,在没有显示传入删除器时调用默认值
function<void(T*)> _del = [](T* ptr) {delete ptr;};
};
}
shared_ptr和weak_ptr
shared_ptr的循环引用问题
shared_ptr大部分情况下管理资源都非常合适,支持RAII,也支持拷贝。但在循环引用的场景下会资源会没有释放导致内存泄漏,这种情况就需要用到weak_ptr
weak_ptr是C++11设计出的来的智能指针,翻译为弱指针,它完全不同于上面的智能指针,不支持RAII,也就意味着不能用它直接管理资源,只要就是为了解决shared_ptr的循环引用问题
在双向链表的场景下,用shared_ptr存储动态开辟的节点
有两个智能指针n1和n2,分别存储两个动态开辟的节点,然后进行操作
这里会遇到第一个问题,假如链表节点的定义是
struct ListNode{
ListNode* _next;
ListNode* _prev;
};
shared_ptr<ListNode> n1(new ListNode);
shared_ptr<ListNode> n2(new ListNode);
n1->next = n2; // 这里会报错,因为n2是一个智能指针,而n1->next是一个ListNode*
n2->prev = n1; // 所以节点的定义要修改为智能指针的形式
struct LisNode{
shared_ptr<ListNode>* _next;
shared_ptr<ListNode>* _prev;
};
但此时就构成了循环引用的问题
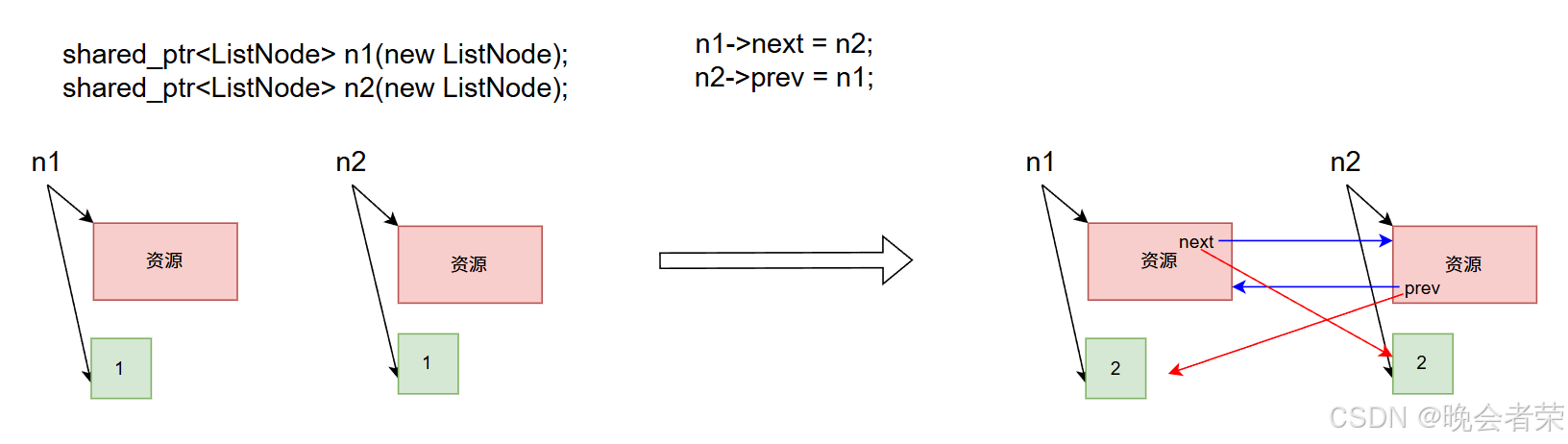
因为此时next跟prev都是shared_ptr的类型的对象,那么让它们互相指向的时候,引用计数是会随着增加他们互相指向而增加的
当 n1和n2析构时,引用计数减少到1,此时指向的资源不会析构
所以右边的节点的资源什么时候销毁,右边的资源是由左边的next所管理的,左边的next析构了右边的节点就析构了
那么左边的next什么时候析构,左边的资源是由右边的prev所管理的,右边的prev析构了左边就析构了
综上所示,右边的节点在右边的prev销毁时销毁
那么此时就是永远无法销毁,就造成内存泄漏了,这就是循环引用的问题
要解决整个问题,就要用到weak_ptr
weak_ptr
weak_ptr不支持RAII,也不支持访问资源,weak_ptr构造时不支持绑定到资源,只支持绑定到shared_ptr,绑定到shared_ptr时,不增加shared_ptr的引用计数,这样就可以解决循环引用的问题。
weak_ptr没有重载 operator* 和 operator-> 等,因为它不参与资源管理,如果它绑定的shared_ptr已经释放了资源,那么它去访问是很危险的。
weak_ptr支持expired()检查指向的资源是否过期,返回值为0表示没有过期,返回值为1表示已经过期,也支持use_count获取引用计数,weak_ptr访问资源时,可以调用lock()返回一个管理资源的shared_ptr,如果资源已经被释放,返回的shared_ptr是一个空对象,如果资源没有释放,则返回的shared_ptr访问资源是安全的
int main() {
std::shared_ptr<string> sp1(new string("1111111"));
std::shared_ptr<string> sp2(sp1);
std::weak_ptr<string> wp = sp1;
cout << wp.expired() << endl;
cout << wp.use_count() << endl;
// sp1和sp2都指向了其他资源,则weak_ptr就过期了
sp1 = make_shared<string>("2222222");
cout << wp.expired() << endl; // 没有过期
cout << wp.use_count() << endl; // 1,此时只有sp2指向这块资源
sp2 = make_shared<string>("3333333");
cout << wp.expired() << endl; // 过期了,没有shared_ptr指向这块资源
cout << wp.use_count() << endl; // 0,此时没有资源指向
wp = sp1; //指向sp1的资源
auto sp3 = wp.lock(); // 资源没有过期,返回一个非空的shared_ptr
cout << wp.expired() << endl; // 0,资源没有过期
cout << wp.use_count() << endl; // 2,此时有两个智能指针指向这块资源
*sp3 += "###";
cout << *sp1 << endl;
return 0;
}
通过将ListNode节点中的指针修改为weak_ptr就能解决循环引用的问题
struct LisNode{
weak_ptr<ListNode>* _next;
weak_ptr<ListNode>* _prev;
};
这样设计,在让指针互相指向的时候,就不会导致引用计数的增加
补充
shared_ptr除了支持指向资源的指针构造,还支持make_shared()用初始化资源的值直接构造,使用make_shared的好处是能减少内存碎片,shared_ptr中除了资源是在对上开辟的空间,引用计数同样是在对上开辟的,在直接构造下,它们两个是分开构造的,所以如果使用了很多shared_ptr,会导致堆上的空间变得碎片化,而使用make_shared就会将这两个开辟在一起,减少碎片化
shared_ptr和unique_ptr都支持了 operator bool类型的转换,如果智能指针对象是一个空对象没有管理资源,则返回false,否则返回true,所以可以直接把智能指针对象给if判断是否为空
shared_ptr和unique_ptr都得构造函数都使⽤explicit 修饰,防⽌普通指针隐式类型转换成智能指针对象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)