LLM相关基础知识快速复习
AI,人工智能(Artificial Intelligence),是一门致力于使机器能够模拟人类思维、学习与解决问题的技术.
机器学习-深度学习-大语言模型...
现在的AI都是采用神经网络架构,你可以把它看做是AI的大脑,是决定AI是否”聪明”的基础。
人工智能三要素 = 数据 + 算法 + 算力
LLM(Large Language Model,大语言模型)基于Transformer 架构,用海量文本训练,理解、生成人类语言,能推理、对话、写代码、做 Agent。代表:GPT 系列、通义千问、DeepSeek、Qwen、Llama、GLM 等。
LLM 应用架构(Dify / LangChain 本质就是这套)
- 基础大模型:提供语言能力
- Prompt 工程:指令约束、格式要求、角色设定
- RAG:外挂私有数据
- Tool/Function Calling:调用外部工具
- Agent 智能体:自主规划 + 多轮调用工具
- 记忆 Memory:记住上下文、历史对话
LLM服务(调用SDK)
DeepSeek / 百炼 / Ollama. Google/Claude/Azure 的 SDK
一个是国外的一个是国内的,都是一种东西,注册→拿 API_KEY→看文档→curl / 代码调用,流程完全一样.所有这些 SDK / 模型服务,本质全是「大模型 HTTP 接口的调用工具 / 服务」
国内首选阿里百炼平台(因为有很多免费token,不用充值)
申请账号,支付宝扫码可以登录认证
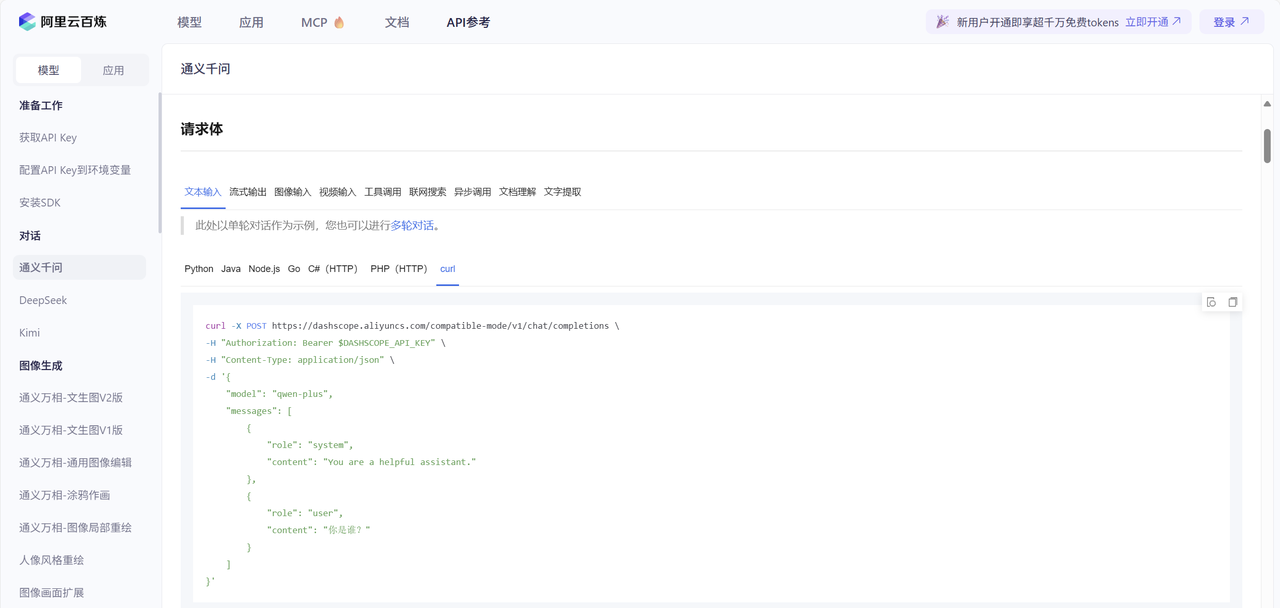
查看一下API官方文档
-
请求方式:通常是POST,因为要传递JSON风格的参数
-
请求URL:与平台有关
-
DeepSeek官方平台:https://api.deepseek.com/chat/completions
-
阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
-
本地ollama部署的模型:http://localhost:11434
-
-
请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
-
Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
-
Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
-
-
请求参数:JSON格式:
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}-
model:模型名称,DeepSeek支持deepseek-reasoner和deepseek-chat两者模型 -
messages:发送给大模型的消息,[]是数组的意思,里面可以有多条消息。消息结构:-
content:是消息的内容 -
role:消息的角色,有system、user、assisant三种角色-
system:是给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉 -
user:就是用户提问的问题 -
assisant:是大模型的回答
-
-
-
stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
-
role:消息对应的角色
-
content:消息内容
其中System和User消息的内容,也被称为提示词(Prompt),也就是用户发送给大模型的指令。
-
System提示词,是系统指令,给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
-
User提示词,是用户指令,也就是用户向大模型的提问或命令
通常消息的角色有三种:
|
角色 |
描述 |
示例 |
|---|---|---|
|
system |
优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 |
你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
|
user |
终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) |
写一首关于Java编程的诗 |
|
assistant |
由大模型生成的消息,可能是上一轮对话生成的结果 |
注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
然后apifox测试一下
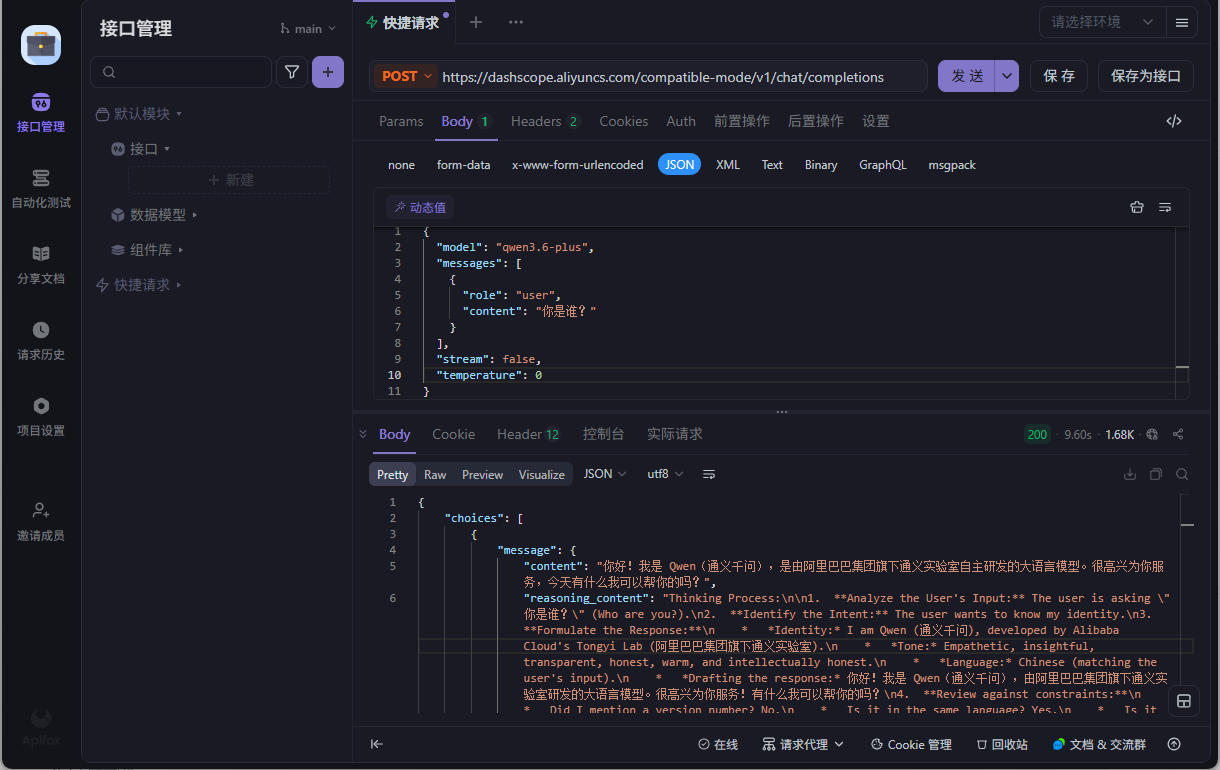
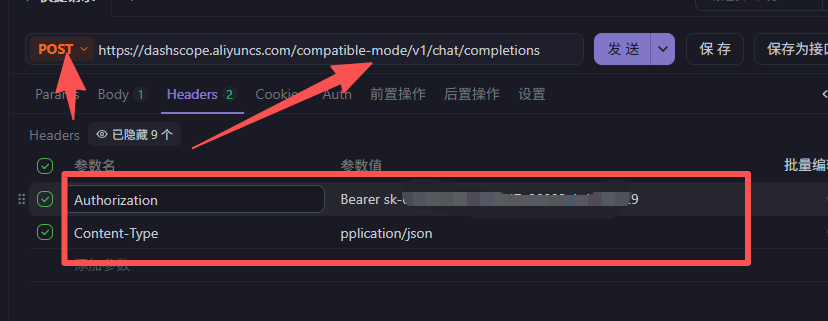
注意写好headers和用密钥
本地部署需要用ollama
教程可见我之前文章ollama部署本地和云端大模型实践以及dify中配置ollama和dify日志查看-CSDN博客\
我本地已经装了ollama还有qwen3:8b
http://127.0.0.1:11434/api/chat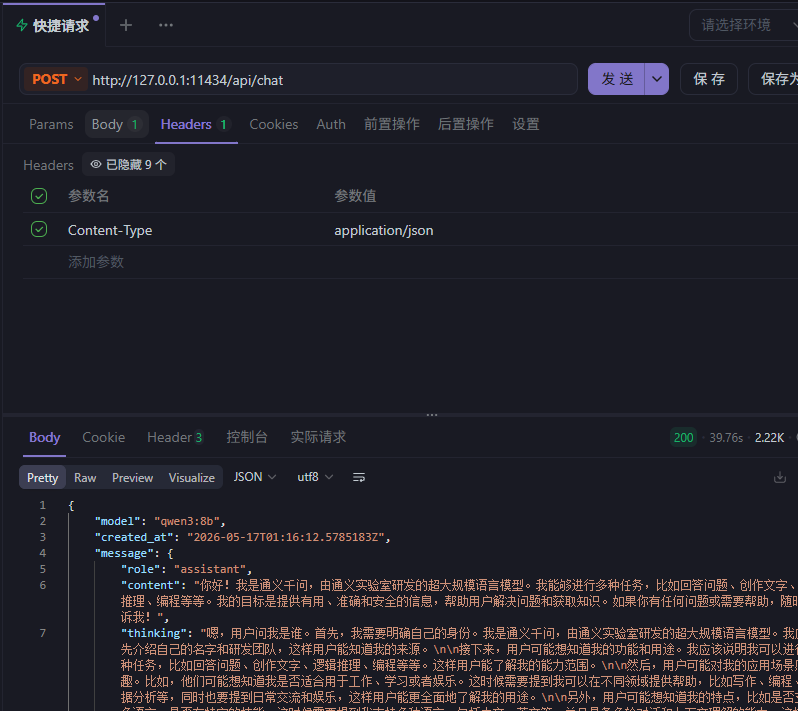
大模型每次调用都是独立的,为了保持记忆必须在每次请求时,将之前所有对话的历史拼接好,传递给对话API接口
要想让AI具备记忆,就必须把对话历史都添加到请求体中的messages数组中,像这样:
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "12个苹果分给3个人,每人能分几个?直接告诉我答案"},
{"role": "assistant", "content": "每人可以分到4个苹果。"},
{"role": "user", "content": "如果是分给4个人呢?"}
],
"stream": false
}安装uv管理Python版本
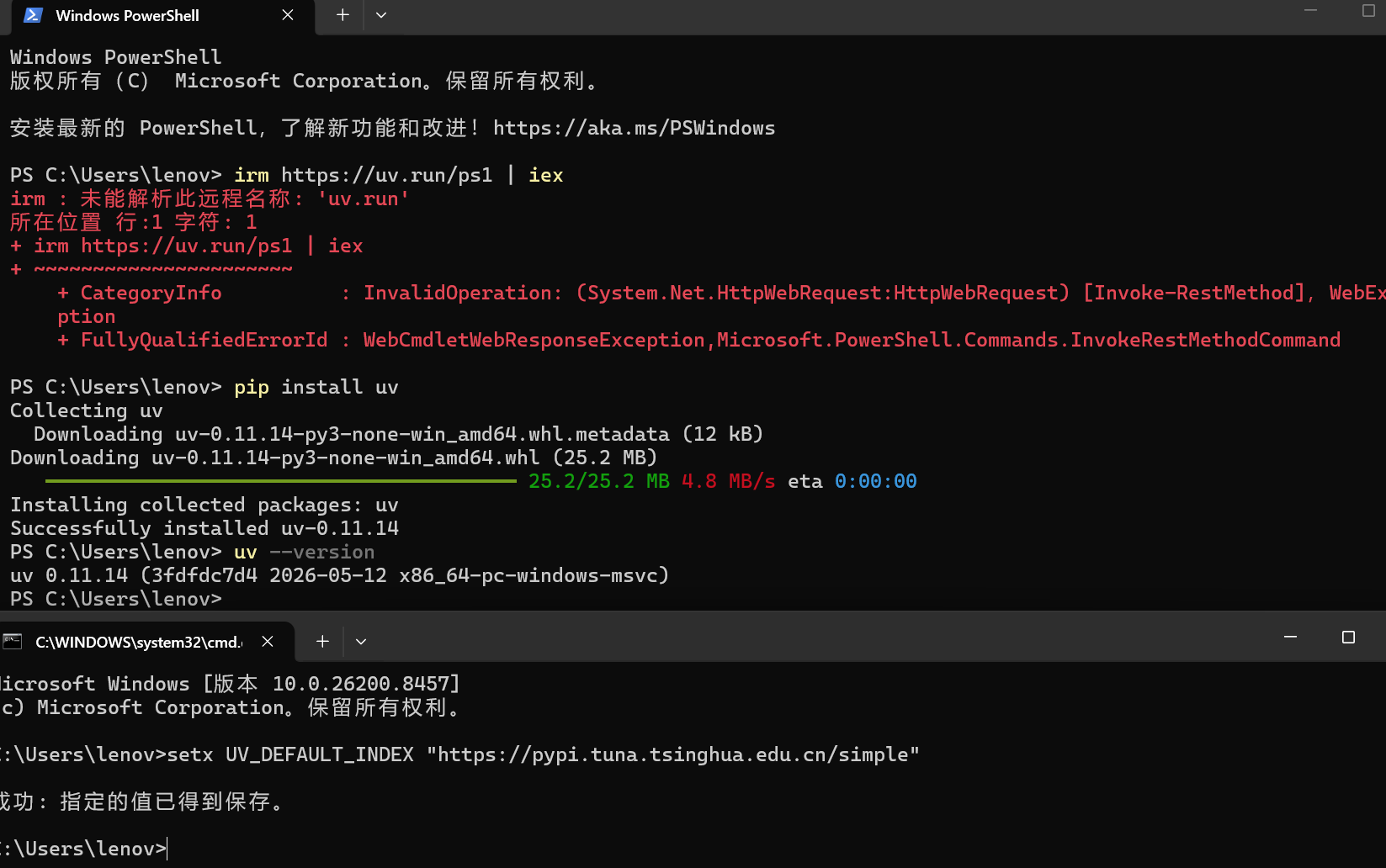
打开cmd
# 创建一个名为 `venv` 的虚拟环境(默认目录)
uv venv
# 指定虚拟环境名称或路径
uv venv myenv
#激活
.\myenv\Scripts\activate
uv pip install langchain
uv pip install ollama
uv pip install fastapi uvicorn
uv pip install openai
pycharm新版,2025.26年以上的才有uv.我之前是24.3.所以一直不行,需要重新下载pycharm
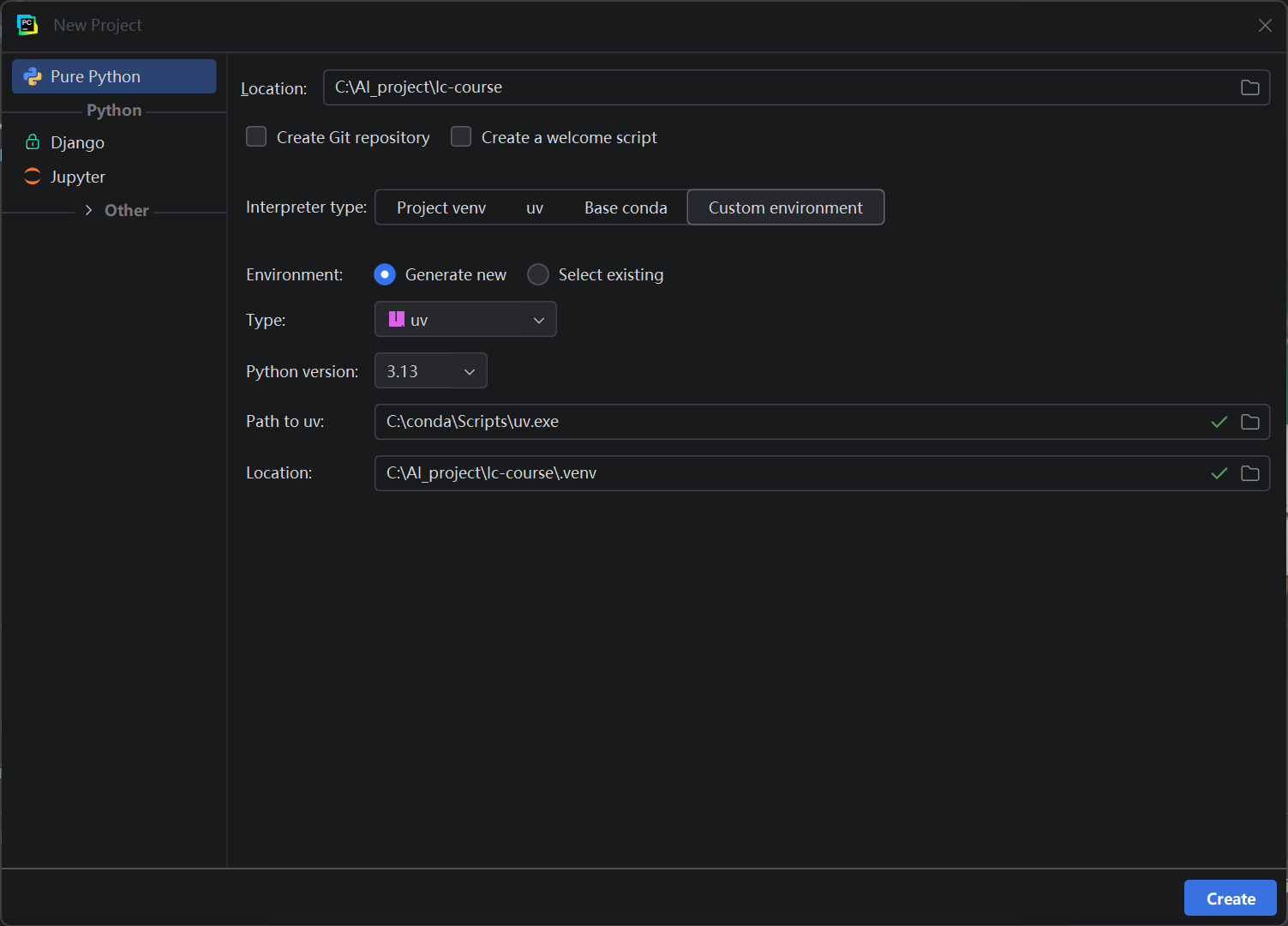
 创建好试一下
创建好试一下
然后我们uv add notebook
新建一个Jupiter
接着我们看看云端的sdk和api的区别
这个都是百炼平台的
这是openAI的SDK调用方式(我们专门实践一下)
import os
from openai import OpenAI
# 注意: 不同地域的base_url不通用(下方示例使用北京地域的 base_url)
# - 华北2(北京): https://dashscope.aliyuncs.com/compatible-mode/v1
# - 美国(弗吉尼亚): https://dashscope-us.aliyuncs.com/compatible-mode/v1
# - 新加坡: https://dashscope-intl.aliyuncs.com/compatible-mode/v1
# - 德国(法兰克福): https://{WorkspaceId}.eu-central-1.maas.aliyuncs.com/compatible-mode/v1,请将WorkspaceId替换为业务空间ID
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{'role': 'user', 'content': '你是谁?'}]
)
print(completion.choices[0].message.content)还有url的api调用方式
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.6-plus",
"messages": [
{
"role": "user",
"content": "你是谁?"
}
]
}'我们动手实测一下
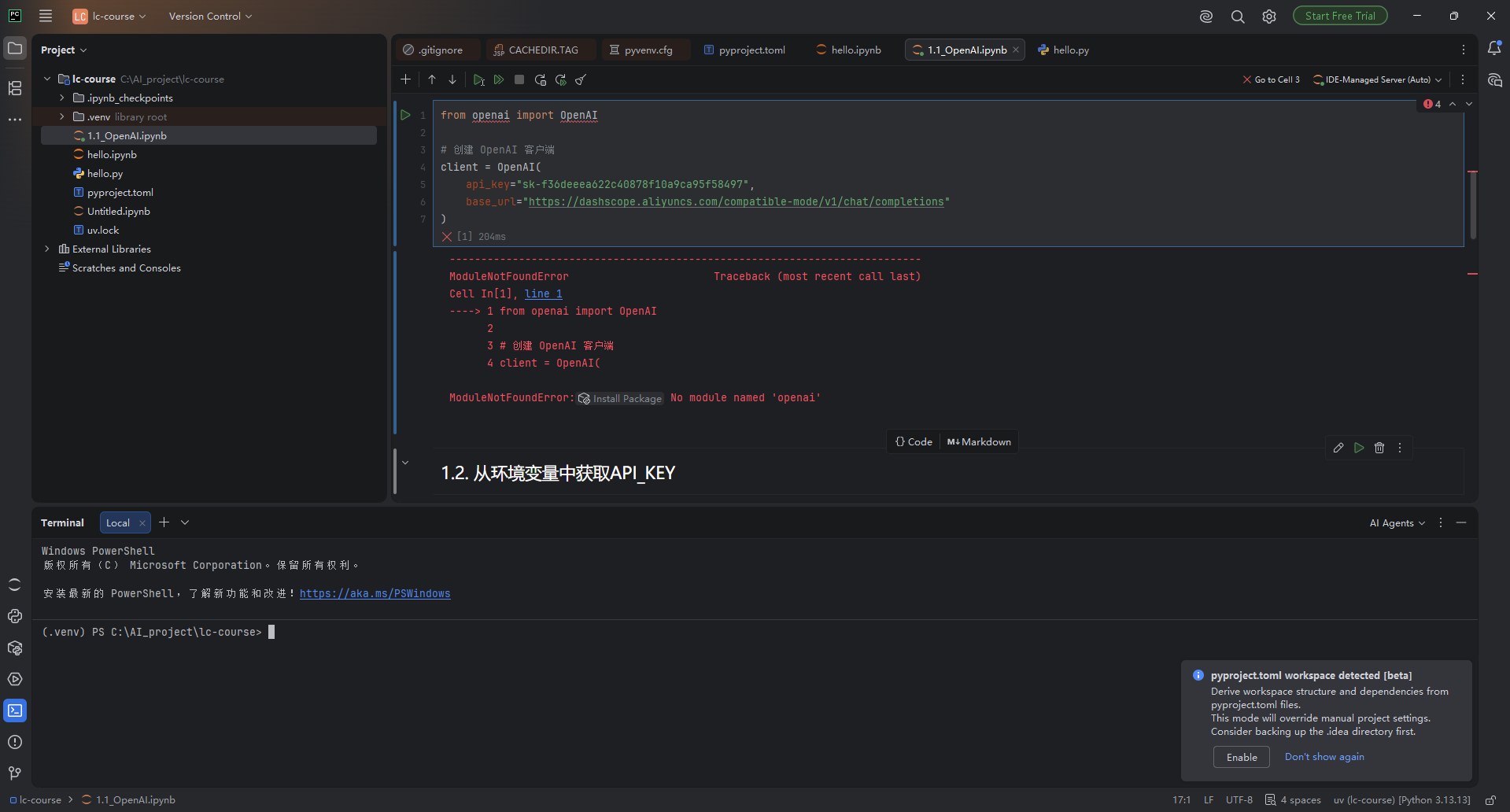
报错可见没安装这个包
uv pip install openai jupyter python-dotenv
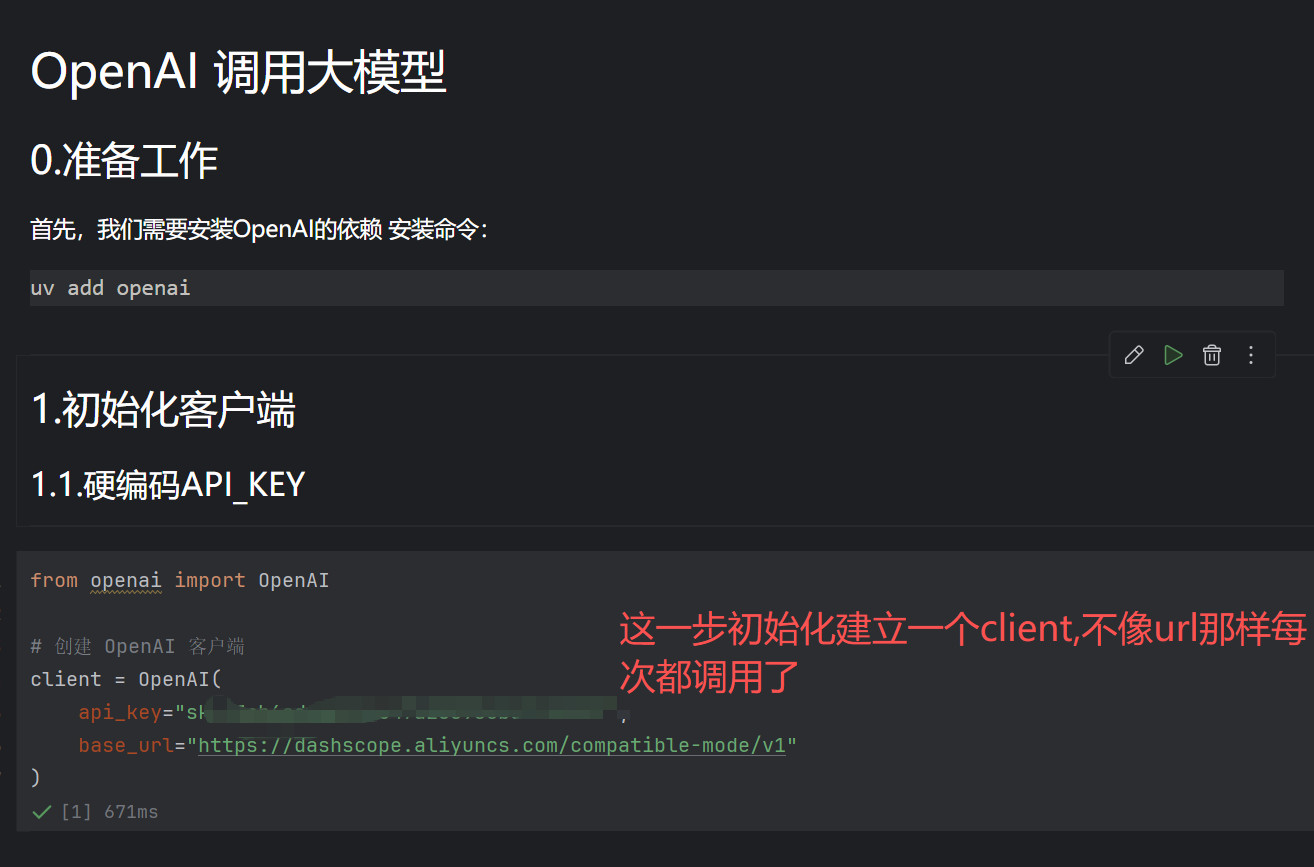
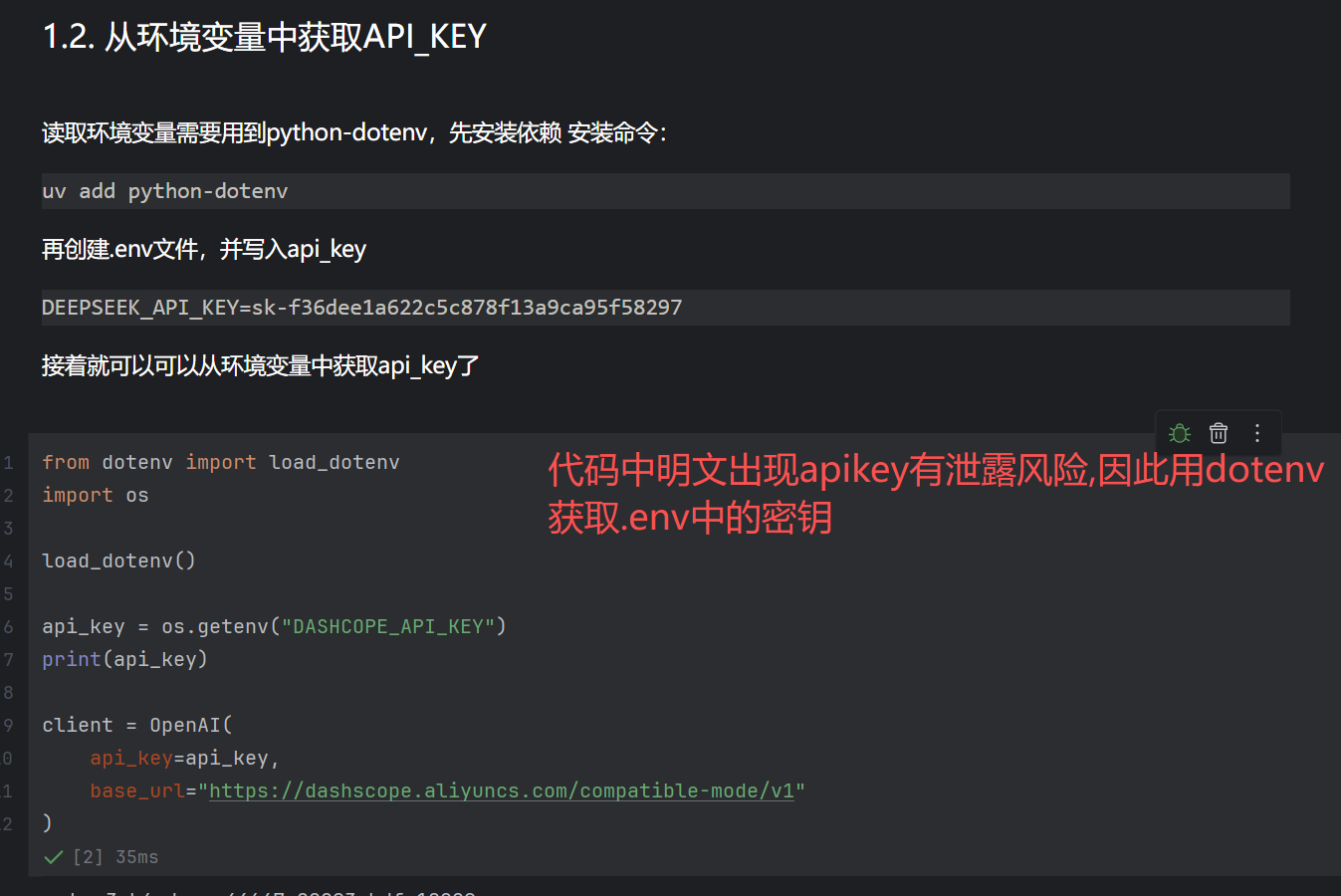
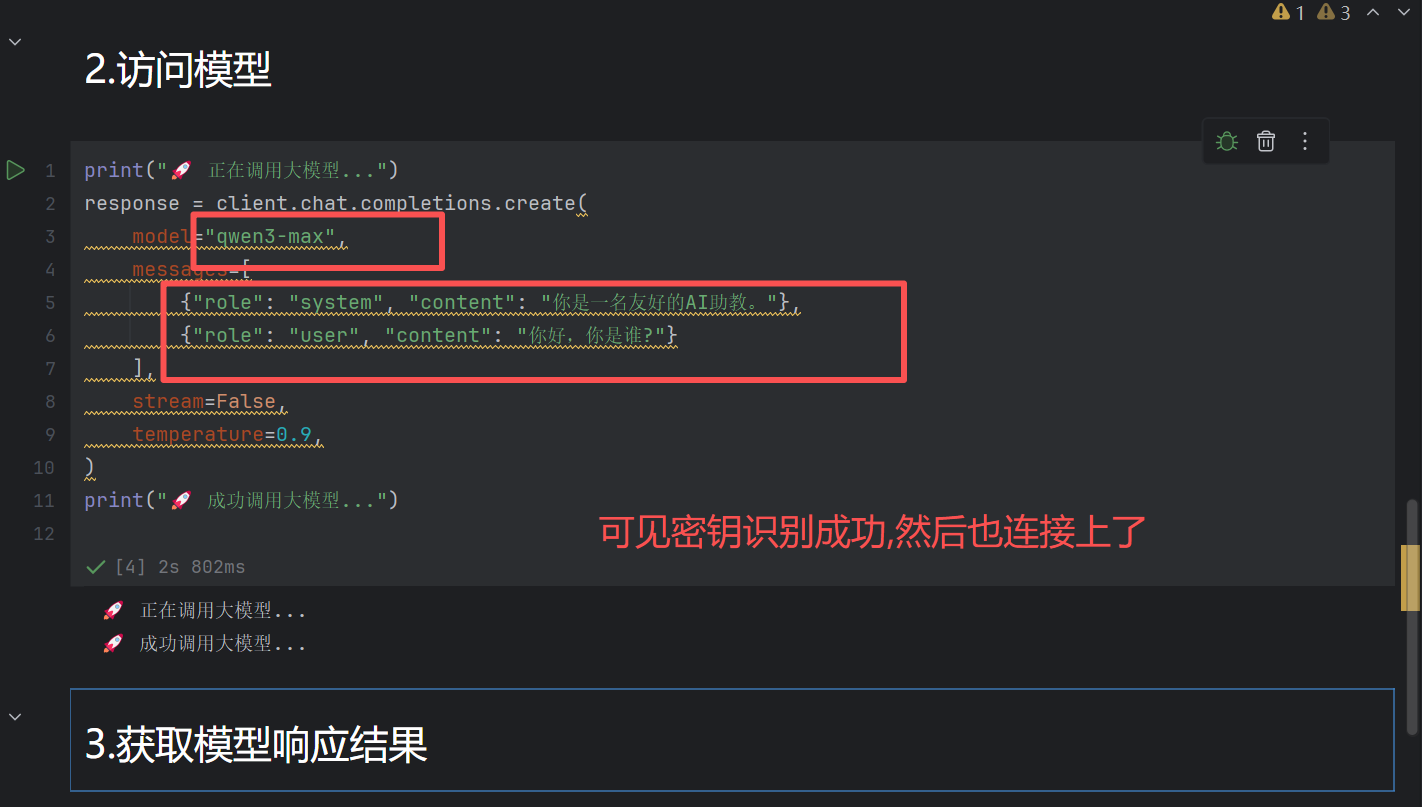
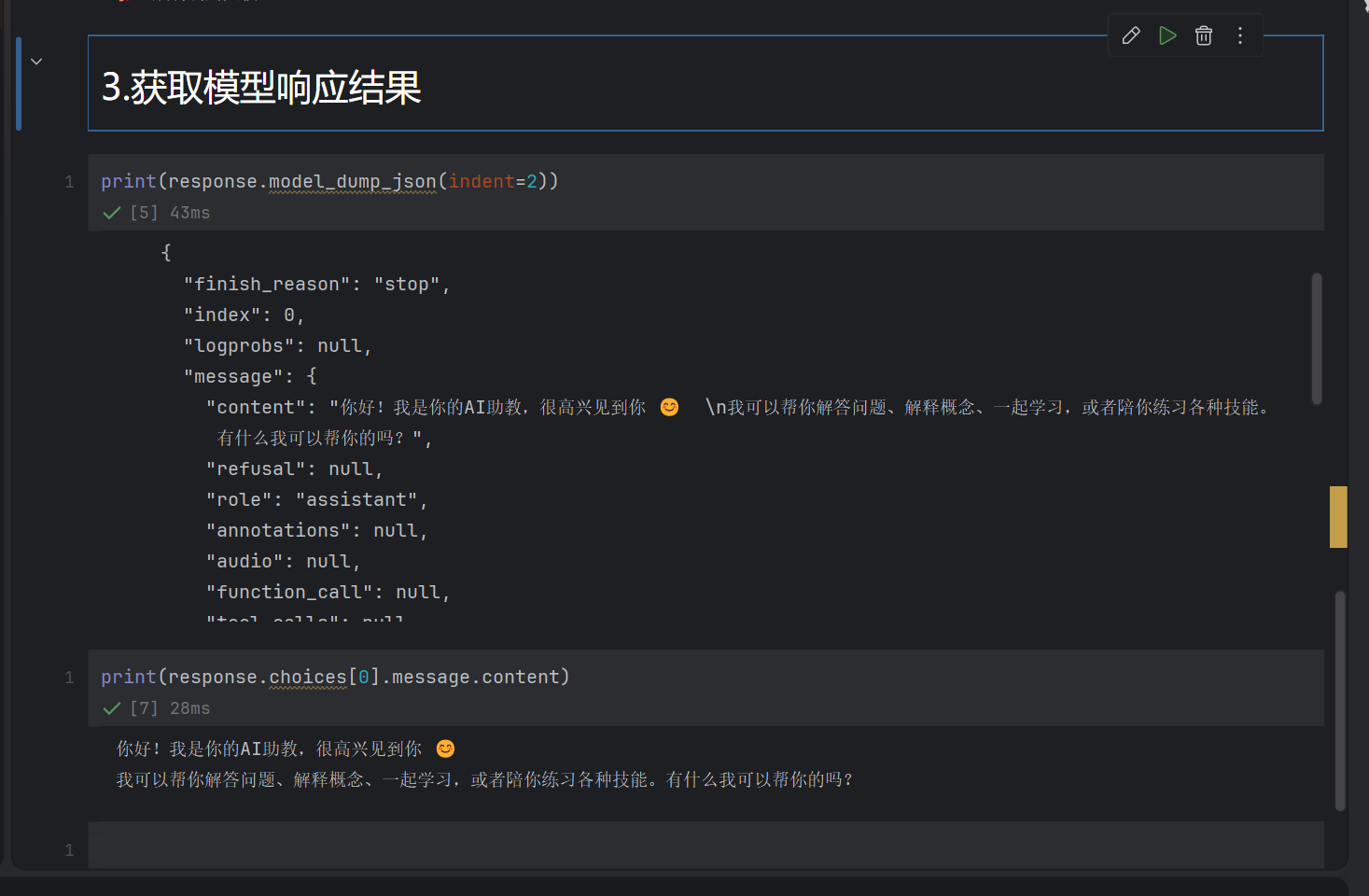
测试完sdk调用后,我们做第一个agent
首先安装依赖
uv pip list #查看一下有什么依赖没有longchain,安装他,注意调用 阿里云百炼 / 通义千问 Qwen 系列模型,用 langchain-openai 就是对的因为百炼、通义千问都兼容 OpenAI 接口格式,直接用这个包就行
首先uv add langchain
其次 uv add langchain-openai
开发agent流程: 1.加载环境变量2.定义工具;3.定义agent.4.调用agent
1.还是用dotenv去获取
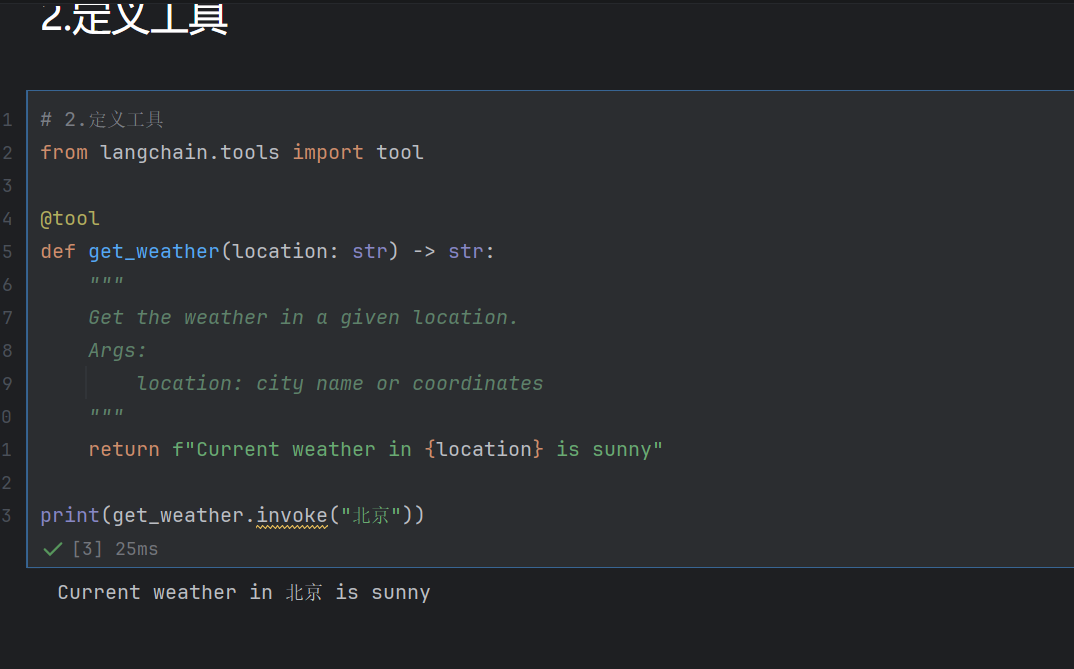
2.定义工具
必须记住 3 个关键点
- @tool 必须写在函数上面
- 文档字符串是给 AI 看的说明书,必须写清楚
- AI 靠描述判断用不用工具
# 从 LangChain 工具模块导入 tool 装饰器
from langchain.tools import tool
# 装饰器:把普通函数 → 变成 AI 能用的 LangChain Tool
@tool
# 定义一个普通函数
def get_weather(location: str) -> str:
"""
Get the weather in a given location.
Args:
location: city name or coordinates
"""
return f"Current weather in {location} is sunny"
# 直接像函数一样用
print(get_weather.invoke("北京"))逐行语法
# 从 LangChain 工具模块导入 tool 装饰器
from langchain.tools import tool
# 装饰器:把普通函数 → 变成 AI 能用的 LangChain Tool
@tool
@tool 是魔法标记加了它,函数就会自动变成:
- 有名字
- 有描述
- 能被 AI 调用的工具
不加,AI 不认识!
# 定义一个普通函数
def get_weather(location: str) -> str:
get_weather:工具名location: str:参数是字符串(城市名)-> str:返回字符串
"""
Get the weather in a given location.
Args:
location: city name or coordinates
"""
这是最重要的部分!这叫 文档字符串(docstring)AI 就是靠看这个注释,决定要不要调用这个工具!
AI 会看:
- 这个工具是干嘛的?
- 要传什么参数?
- 参数什么意思?
你写得越清楚,AI 用得越准!
return f"Current weather in {location} is sunny"
函数真正执行的逻辑(模拟天气)
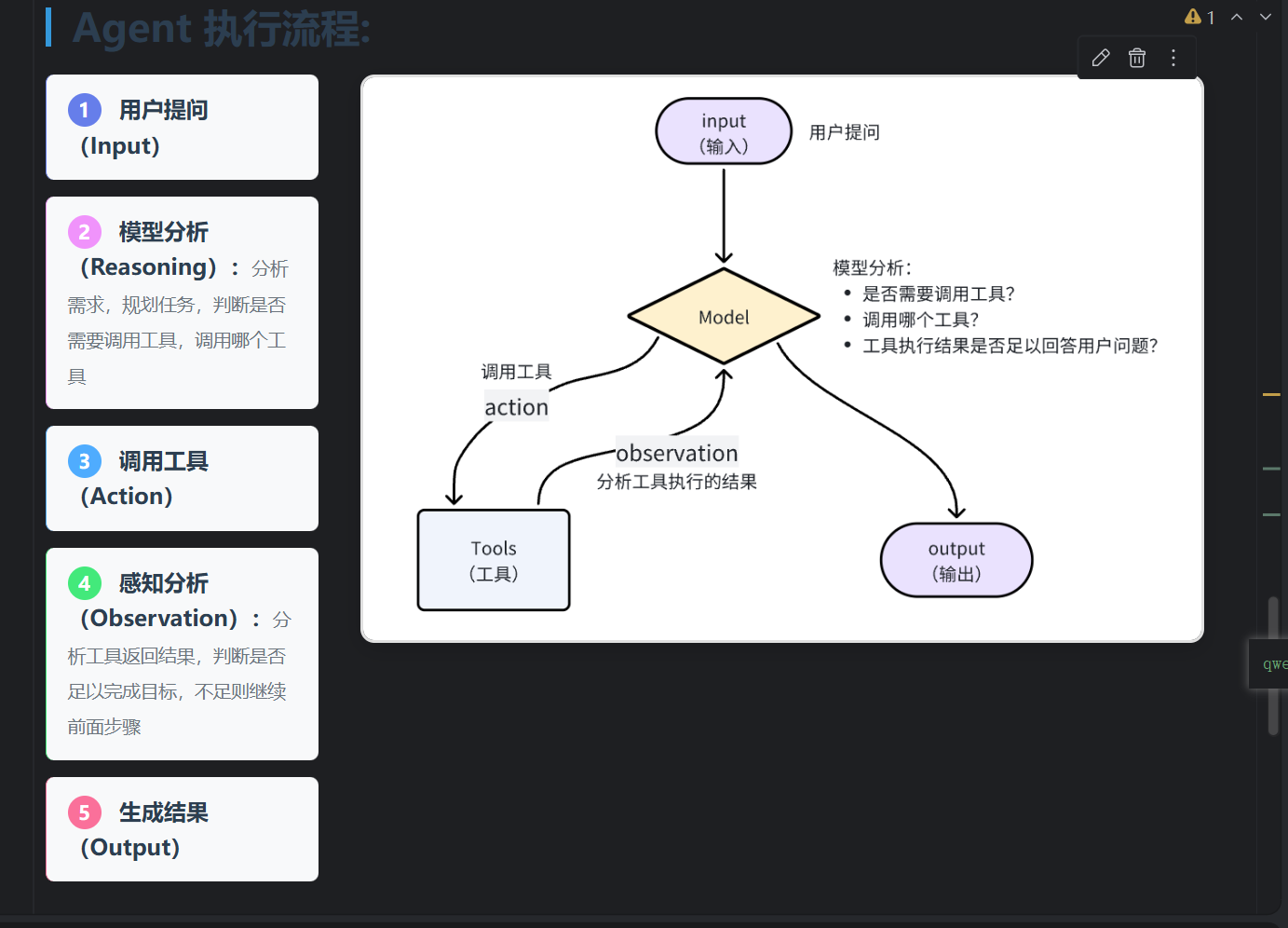
核心原理(一句话讲透)
@tool = 把你的 Python 函数 → 包装成 AI 大模型能看懂、能调用的工具
流程是这样的:
- 你写函数
- 加
@tool变成工具 - AI 看文档字符串知道工具功能
- AI 判断:我需要用这个工具
- AI 自动调用它
- 拿到结果继续回答你
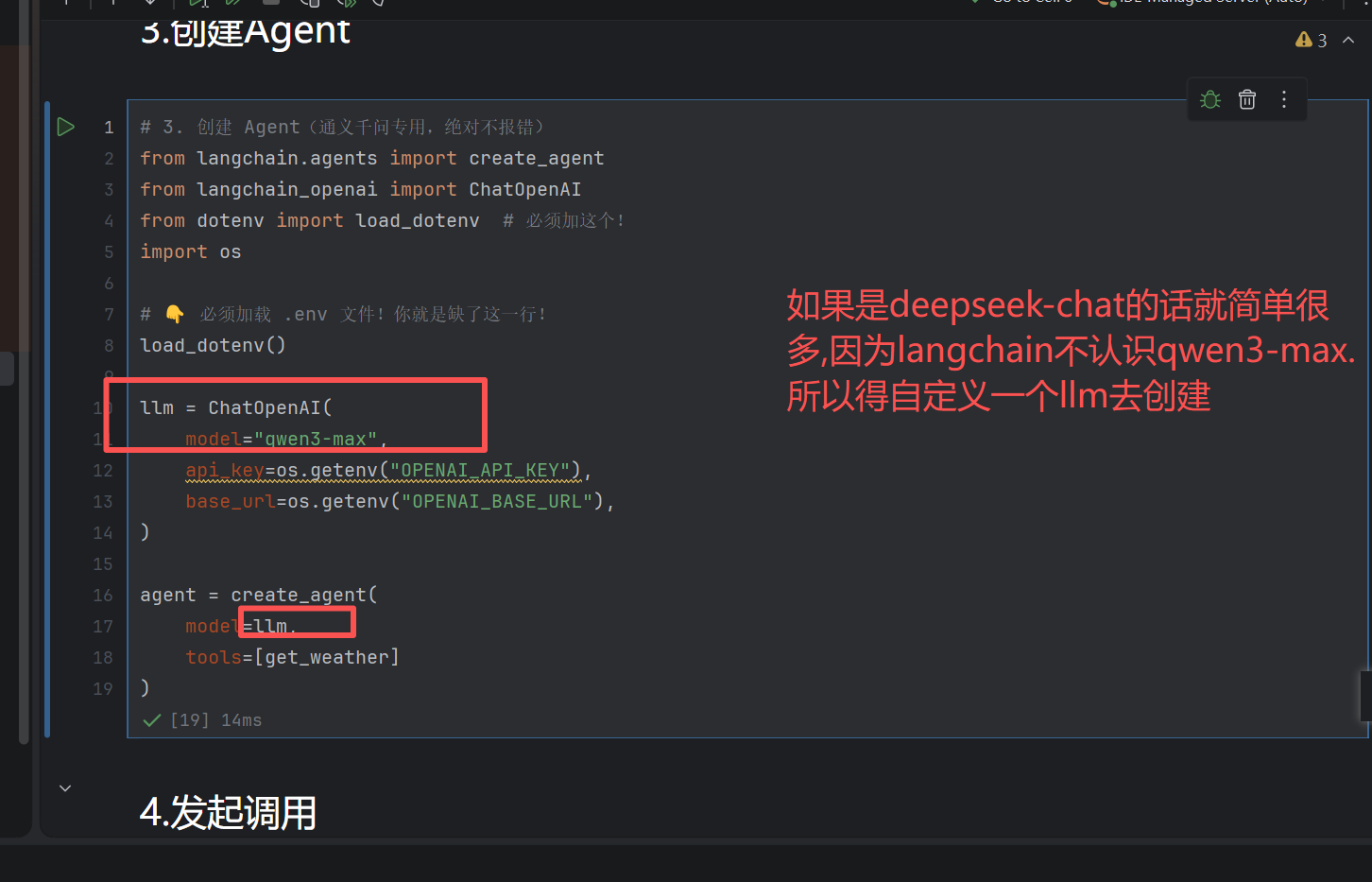
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# 创建LLM
llm = ChatOpenAI(
model="qwen3-max",
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
)
# 👉 新版 LangChain 必须用 model= ,不是 llm=
agent = create_agent(
model=llm, # 这里是 model!不是 llm!
tools=[get_weather]
)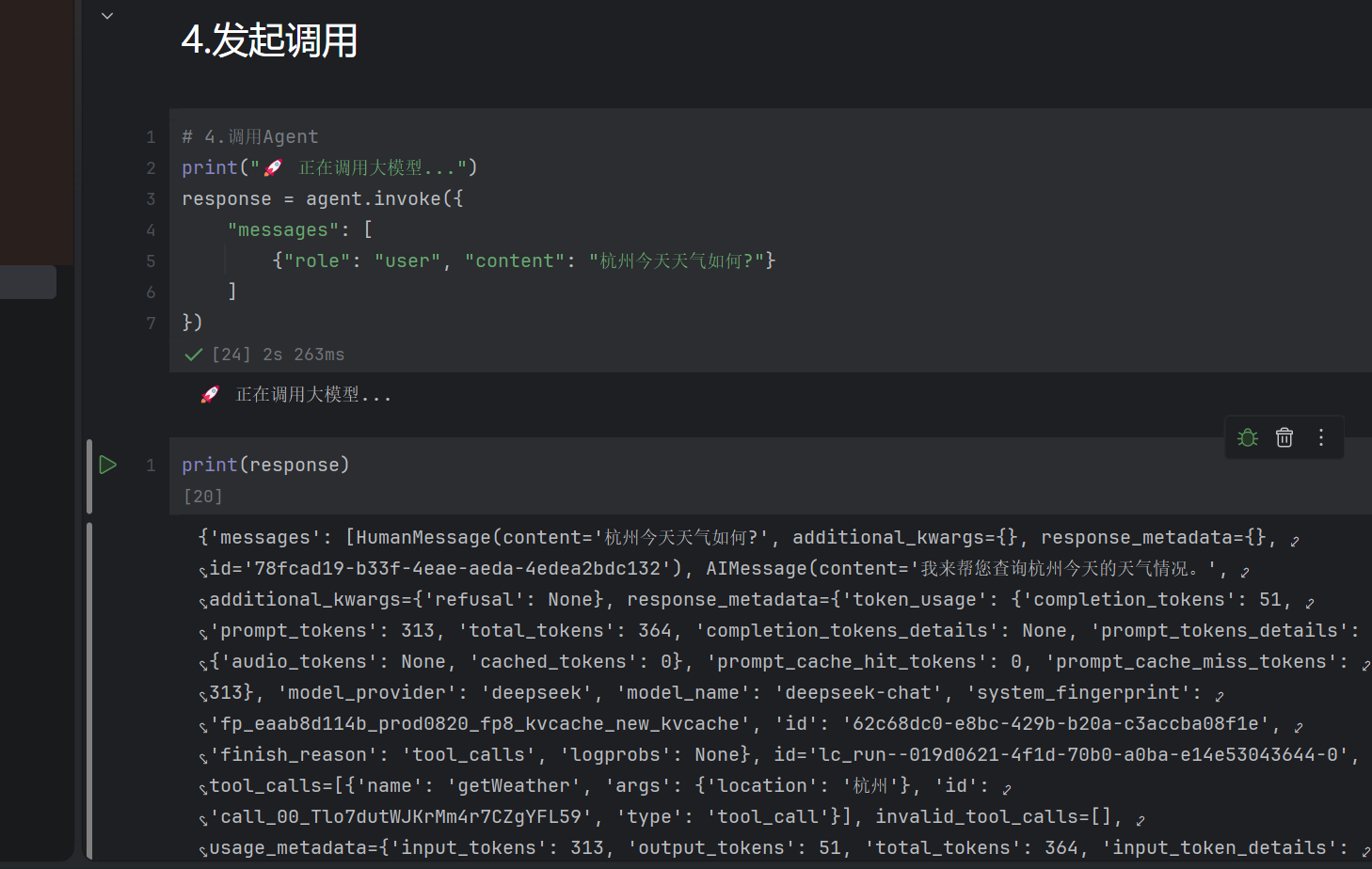
Agent如何知道工具信息
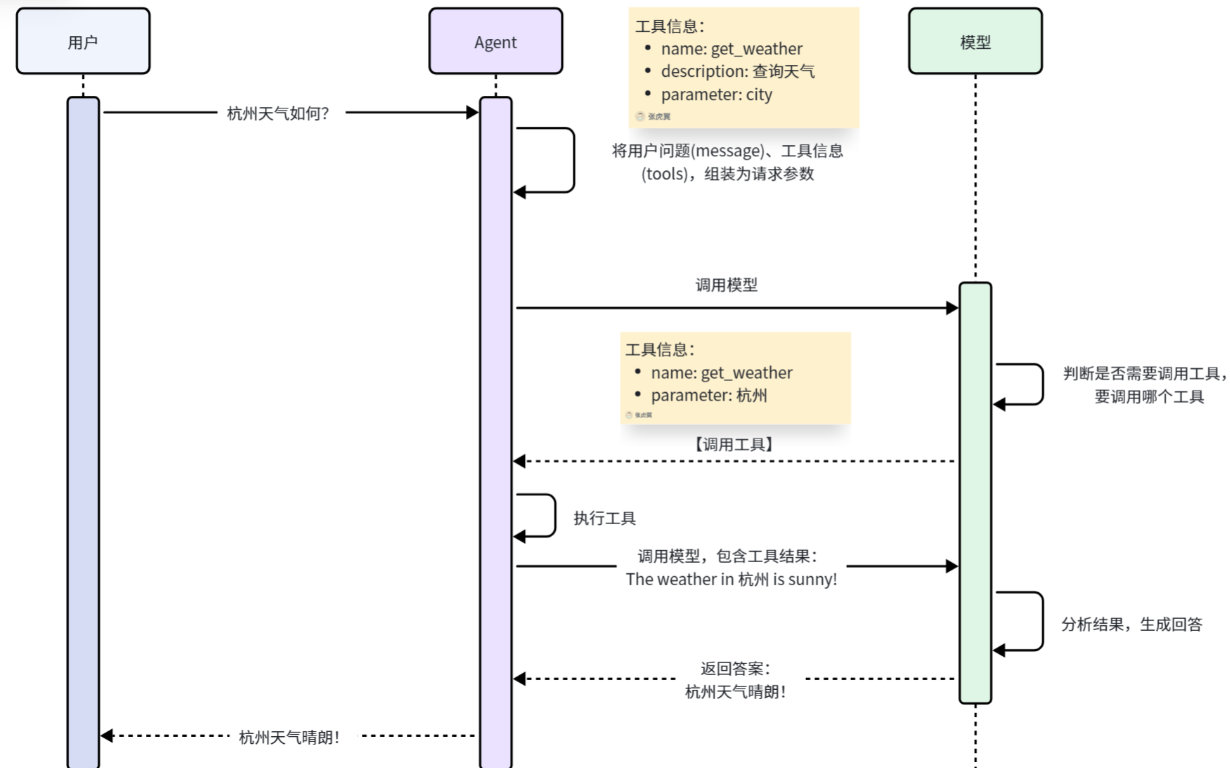
你现在正在做 Agent 工具调用(查天气),这就是 MCP 的雏形:
- LangChain 是自己的私有工具协议
- MCP 是行业通用标准工具协议
未来:你写好一个 MCP 天气工具,通义千问、DeepSeek、GPT 的 Agent 都能直接调用,不用改代码。
MCP = Model Context Protocol(模型上下文协议)由 Anthropic(Claude 所属公司)推出,是开源、通用、标准化的通信协议,用来解决:
大模型 ↔ 本地文件、数据库、浏览器、API、代码编辑器、第三方工具 的统一对接问题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)