大模型-自定义多模态模型Vllm online部署实现
一、背景说明
当我们有一个多模态的模型之后,比如支持文本和音频一起输入的asr 模型,支持图片和文本的输入的视觉模型,我们改如何在云端的gpu 上使用vllm推理框架把模型部署起来呢?这里的部署不是简单的使用vllm 将模型加载运行起来,这个加载运行在官网都有示例,这个比较简单。而是说我们需要支持自定义的输入,或者模型结构有变化之后,如何在vllm 中实现自定义的模型推理。
简单的模型加载运行如下:
python -m vllm.entrypoints.openai.api_server \
--model /home/shengqing.liu/vllm/qwen3-1.7B/ \
--port 8000 \
--host 0.0.0.0 \
--tensor-parallel-size 1 \
--dtype auto
--gpu-memory-utilization 0.7
但是我们在实际的业务中往往会有自己的输入,输出要求:
-
比如需要将文本和音频embeds 后的数据一起输入到模型中。
-
再比如我们需要模型embeds输入的tensor, 并且需要对输出tensor 有特殊的处理。
那么这种情况下就不是简单的加载模型运行服务就可以了,而需要的自定义模型类,改动vllm的输入,输出源码,做模型自定义适配开发。
二、实战案例说明
以将文本和音频embeds 后的tensor数据一起输入到自己训练模型中为例,讲解下多模态大模型在vllm中部署的实现。
2.1 框架选型
1. 首先确定vllm是不是合适的框架
在这个官网可以找到所有的开发指南,首先我们需要确定vllm 是不是支持这个混合输入,如果不支持,我们自己需要改动多少框架才能实现我们的需要。如果评估下来,工作量巨大,改动很多,那么我们就需要考虑是不是适合使用这个vllm 框架进行推理。
在我这个项目中,我看到了支持image embeds 输入,所以就算不支持audio embeds ,那么整个框架也具备了embeds和文本的混合输入,我自己需要改动的地方也应该有限。所以选型没问题。
https://vllm--36160.org.readthedocs.build/en/36160/features/multimodal_inputs/#image-embedding-inputs
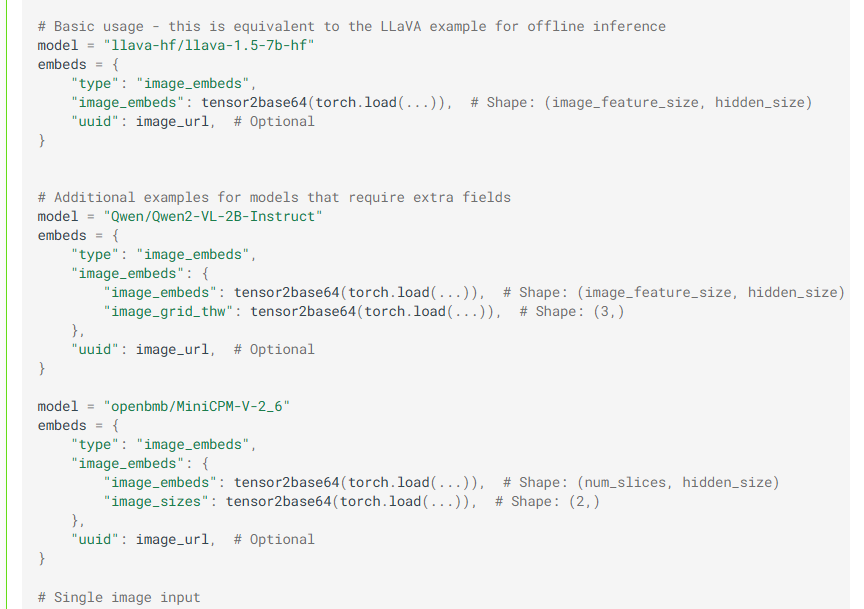
2. 云端部署一般是使用服务的形式,vllm 有在线推理和离线推理两种方式,我们一般是选用online推理的方式,在服务端启动服务,客户端使用openai 的接口方式,使用网络通讯连接方式进行访问服务端。
2.2 模型结构选型
我们需要知道我们自己的大模型是什么模型结构,比如qwen3系列还是meta的,或者阶跃的等等,一般主流的模型结构,vllm 都有适配,而且有很多的丰富的示例,我们一般确定模型结构后可以详细的参考阅读现有的模型examples, 里面有大量的示例,可以给我们找到大量的相似的实现逻辑和启发,对于我们开发一个新模型绝对是最有效率的一种学习思路。
官网示例学习:
https://github.com/vllm-project/vllm/tree/main/examples
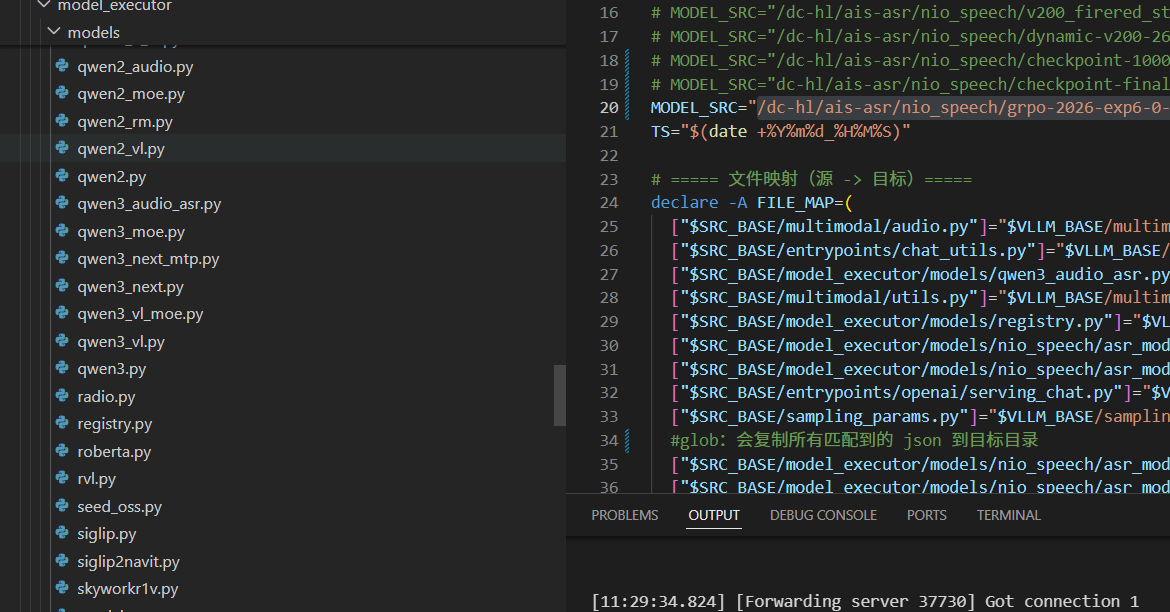
2.3 开发
那我们确定了我们是开发部署多模态模型,那么我们参考qwen2 audio.py 文件实现我们自己的多模态模型。多模态模型开发部署,首先我们需要定义一个我们自己的模型类:
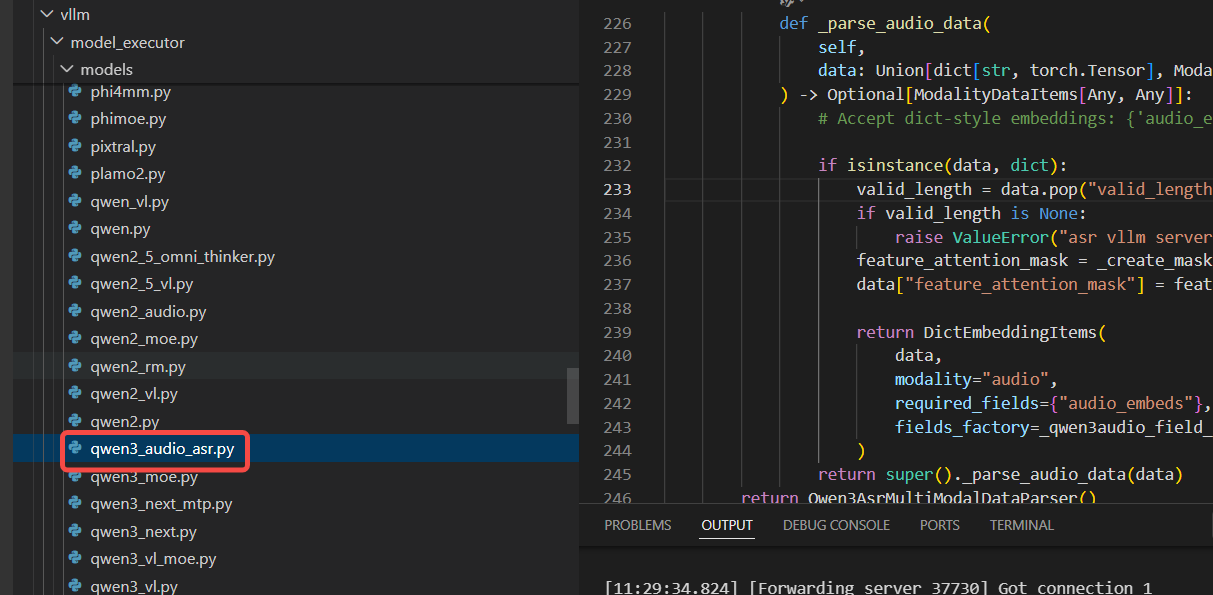
然後在這個类中实现我们的模型推理逻辑;
整体思路:
多模态推理实际上就是继承vllm的多模态类,在其中实现我们的自己的逻辑,然后将我们的继承类注册到框架中即可。
具体实现:
我们需要在我们自定义模型类中实现这个三个类:
@MULTIMODAL_REGISTRY.register_processor(
Qwen3AsrMultiModalProcessor,
info=Qwen3AsrProcessingInfo,
dummy_inputs=Qwen3AsrDummyInputsBuilder)1. Qwen3AsrMultiModalProcessor继承:
class Qwen3AsrMultiModalProcessor(
BaseMultiModalProcessor[Qwen3AsrProcessingInfo]):这个类主要是多模态的数据处理,验证。
2. Qwen3AsrProcessingInfo继承:
class Qwen3AsrProcessingInfo(BaseProcessingInfo):这个类主要是模型的processor的信息。
3. Qwen3AsrDummyInputsBuilder继承:
class Qwen3AsrDummyInputsBuilder(
BaseDummyInputsBuilder[Qwen3AsrProcessingInfo]):这个类主要是构建模型启动时用到的dummy input 数据。
4. 实现我们自己的模型结构类
class Qwen3NioAsrModel(nn.Module, SupportsLoRA, SupportsPP, SupportsEagle3, SupportsMultiModal): 这个就是对应我们模型结构的类,在这个文件中会定义和模型结构的参数,attention, foward 计算,logits 计算等等,这个文件可以参考和你模型一样或者类似的例子实现。
5. 实现一个我们多模态数据处理的processor 类
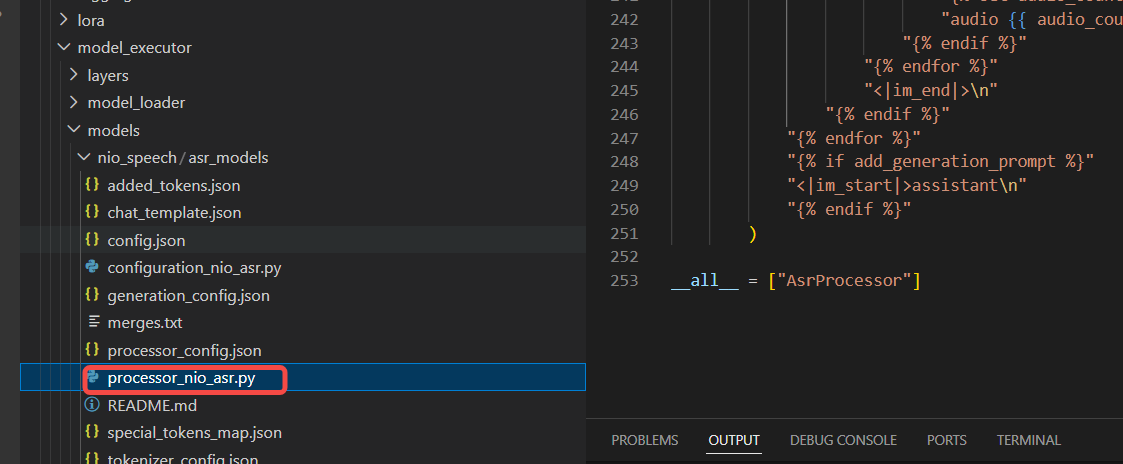
这个类可以继承实现。
class AsrProcessor(ProcessorMixin):6. 将模型注册到系统中就可以让系统找到我们的模型是使用我们自定义模型类进行加载推理
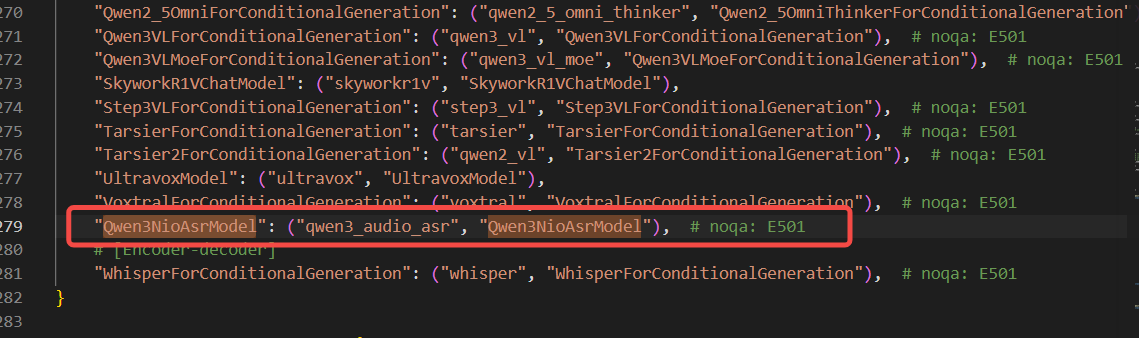
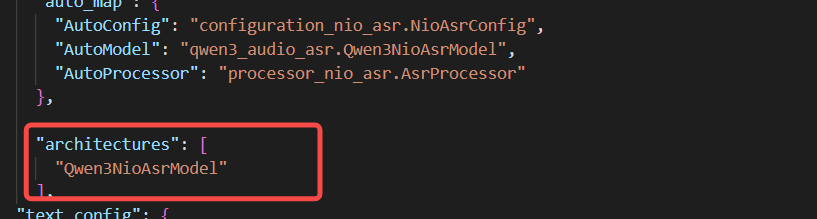
通过这个结构和文件的对应关系,就可以实现我们自定义模型类加载我们自定义模型推理了。
到这里为止,我们服务端的代码基本开发结束了。客户端的调用按照官网示例就可以实现,比较简单就不赘述了。
2.4 部署服务
那我们开发完了服务端的代码,需要将我们的代码在vllm 生效,然后部署运行在gpu 上,这样才可以提供给客户端访问。
具体可以实现:
1.实现一个脚本,将我们的改动文件复制到你环境中去,因为改动的都是python 文件,所以不需要重新编译,直接替换文件就可以生效,如果改动了c++ 文件,就需要重新编译。
# ===== 基本配置 =====
VLLM_BASE="/usr/local/lib/python3.12/dist-packages/vllm"
SRC_BASE="./vllm"
MODEL_SRC="/grpo-2026-exp6-0-xieyuan/model/"
# ===== 文件映射(源 -> 目标)=====
declare -A FILE_MAP=(
["$SRC_BASE/multimodal/audio.py"]="$VLLM_BASE/multimodal/audio.py"
["$SRC_BASE/entrypoints/chat_utils.py"]="$VLLM_BASE/entrypoints/chat_utils.py"
["$SRC_BASE/model_executor/models/qwen3_audio_asr.py"]="$VLLM_BASE/model_executor/models/qwen3_audio_asr.py"
["$SRC_BASE/multimodal/utils.py"]="$VLLM_BASE/multimodal/utils.py"
["$SRC_BASE/model_executor/models/registry.py"]="$VLLM_BASE/model_executor/models/registry.py"
["$SRC_BASE/model_executor/models/nio_speech/asr_models/configuration_nio_asr.py"]="$VLLM_BASE/model_executor/models/nio_speech/asr_models/configuration_nio_asr.py"
["$SRC_BASE/model_executor/models/nio_speech/asr_models/processor_nio_asr.py"]="$VLLM_BASE/model_executor/models/nio_speech/asr_models/processor_nio_asr.py"
["$SRC_BASE/entrypoints/openai/serving_chat.py"]="$VLLM_BASE/entrypoints/openai/serving_chat.py"
["$SRC_BASE/sampling_params.py"]="$VLLM_BASE/sampling_params.py"
#glob:会复制所有匹配到的 json 到目标目录
["$SRC_BASE/model_executor/models/nio_speech/asr_models/*.json"]="$VLLM_BASE/model_executor/models/nio_speech/asr_models/*.json"
["$SRC_BASE/model_executor/models/nio_speech/asr_models/*"]="$MODEL_SRC/*"
)2. 可以本地启动模型,如果本机有GPU的话
sudo python3 -m vllm.entrypoints.openai.api_server --model /dc-hl/ais-asr/nio_speech/checkpoint-final3-merged-vllm-18/safetensor_model --trust-remote-code --port 8000 --host 0.0.0.0 --tensor-parallel-size 1 --pipeline-parallel-size 1 --gpu-memory-utilization 0.7 --dtype auto --max-model-len 1024 --max_num_seqs 8 --served-model-name asr --enable-mm-embeds --enable-prefix-caching --profiler-config '{"profiler": "torch", "torch_profiler_dir": "/home/shengqing.liu/asr-vllm/18-asr-vllm/trace_file"}'
--enable-mm-embeds 这个是vllm 后面版本要求加上的,否则不支持embeds tensor输入。
--profiler-config:这个是Profile的选项,不然不支持profile.
其他的参数,大家可以自己查询下含义。
3. 打包镜像
除了本机启动,更好的方式是将我们改动的文件打包到包含vllm的镜像中,这样子包含了我们改动的镜像文件可以很轻松被别人使用,在各个服务器上快速的部署。
FROM vllm-openai:v0.18.0 # 你的官方镜像地址
COPY vllm-asr-update/vllm/multimodal/media/audio.py /usr/local/lib/python3.12/dist-packages/vllm/multimodal/media/audio.py
COPY vllm-asr-update/vllm/entrypoints/chat_utils.py /usr/local/lib/python3.12/dist-packages/vllm/entrypoints/chat_utils.py
COPY vllm-asr-update/vllm/multimodal/parse.py /usr/local/lib/python3.12/dist-packages/vllm/multimodal/parse.py
COPY vllm-asr-update/vllm/model_executor/models/qwen3_audio_asr.py /usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/qwen3_audio_asr
.py
COPY vllm-asr-update/vllm/multimodal/media/connector.py /usr/local/lib/python3.12/dist-packages/vllm/multimodal/media/connector.py
COPY vllm-asr-update/vllm/model_executor/models/registry.py /usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/registry.py
COPY vllm-asr-update/vllm/model_executor/models/nio_speech /usr/local/lib/python3.12/dist-packages/vllm/model_executor/models/nio_speech/
COPY vllm-asr-update/vllm/entrypoints/openai/chat_completion/serving.py /usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/chat_completi
on/serving.py
COPY vllm-asr-update/vllm/sampling_params.py /usr/local/lib/python3.12/dist-packages/vllm/sampling_params.py
编译镜像:
set -e
IMAGE_NAME="vllm-openai:v0.18.0_asr_v1"
DOCKERFILE_DIR="."
REPO="https://repositories/vllm-openai/artifacts-tab"
echo "Building docker image: ${IMAGE_NAME}"
docker build -t ${IMAGE_NAME} ${DOCKERFILE_DIR}
echo "Build finished successfully."
echo "login repo"
docker login ${REPO}
docker push ${IMAGE_NAME}
echo "push image ok."
docker logout
到这里我们服务端开发部署的活已经干完了,就可以愉快的启动我们的服务进行调试了。
2.5 调试验证
-
我们需要实现一个访问我们服务的客户端,官网有很多,不一一举例.
-
我们一般需要跑大量的数据集进行测试,验证稳定性。
-
我们需要使用vllm 的结果和原始的模型的推理结果的一致性分析,保证精度在可以接受的范围中。
-
遇到问题,多去官网看看,多去github的issue中找找,开源项目,社区是很活跃的,也许困扰你的问题,不是你自己的问题,而是系统的bug。
-
官网:https://vllm--36160.org.readthedocs.build/en/36160/features/multimodal_inputs/#image-embedding-inputs
-
Github: https://github.com/vllm-project/vllm/issues
-
多打印日志,多看看中间的数据样子,多看看中间的过程。
-
多调vllm 的启动参数,尽可能的减少耗时,增大qps。
到这就是一个模型部署开发的大致流程,希望起到一个抛砖引玉的作用,和大家一起学习进步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)