R语言:基于satellite embedding数据的随机森林用于土壤属性预测
随机森林用于土壤属性预测
模型选择理由
随机森林(RF)被选为土壤属性预测模型,是基于与预测任务特征相一致的多个考虑因素。随机森林是决策树的集成,通过在自举样本上训练随机特征子集,提供内在的正则化以防止过拟合、对异常值的鲁棒性,以及无需对目标变量或协变量进行分布假设即可捕获非线性关系和高阶交互的能力[15]。随机森林能有效处理表格型地理空间数据,并在过去十年中成为数字土壤制图(DSM)中最广泛采用的算法,在各种土壤属性和空间尺度上始终表现优异或接近当前最佳水平[10, 16]。
对于基于嵌入的预测任务,RF 具有额外的优势:(1)它自然地提供变量重要性度量,可用于评估哪些主成分对每个土壤属性预测贡献最大,作为可解释性工具;(2)它容纳了 15 个 PCA 衍生特征,无需进一步的特征工程;(3)其计算效率支持重复交叉验证和 10 米分辨率的全覆盖空间预测。
# =============================================================================
# 脚本 03:使用随机森林进行土壤属性空间预测
#
# 输入文件(来自脚本 02):
# data/pca_workspace.RData — PCA 对象、scores_df、meta、emb_mat、
# n_pcs、pca_obj、pca_rast
# data/soilgrids_with_embeddings.csv — 土壤数据 + 点位的嵌入值
#
# =============================================================================
# ── 0. 加载所需包 ───────────────────────────────────────────────────────────────
required <- c(
"terra", # 栅格操作
"sf", # 矢量操作
"tidyverse", # 数据清洗 + ggplot2
"ranger", # 快速 RF —— 用于交叉验证(步骤 2)
"caret", # 交叉验证辅助工具
"randomForest", # 用于空间预测的 RF(纯 R,无 Rcpp 指针)
"viridis", # 颜色主题
"patchwork", # 多面板图形
"tidyterra" # ggplot2 + terra 集成
)
new_pkgs <- required[!(required %in% installed.packages()[, "Package"])]
if (length(new_pkgs)) install.packages(new_pkgs)
invisible(lapply(required, library, character.only = TRUE))
# ── 1. 用户配置参数 ─────────────────────────────────────────────────────────────
CFG <- list(
# 输入文件
workspace = "data/pca_workspace.RData",
soil_csv = "data/soilgrids_with_embeddings.csv",
# 嵌入栅格的 CRS(EPSG:32717 — UTM Zone 17S, WGS84)
crs_code = 32717,
# 土壤 CSV 中的坐标列(WGS84 经度/纬度)
lon_col = "longitude",
lat_col = "latitude",
# 待预测的土壤属性(必须与 CSV 中的列名匹配)
target_vars = c("BD", "CEC", "Fragm", "Sand", "Silt", "Clay",
"N", "OCD", "pH", "SOC"),
# 随机森林超参数
rf_trees = 500, # 树的数量
rf_mtry_frac = 1/3, # 每次分裂尝试的预测变量比例
rf_min_node = 5, # 最小节点大小
# 交叉验证
cv_folds = 5, # 交叉验证折数
cv_repeats = 3, # 重复 k 折次数
cv_seed = 42,
# 输出目录
out_data = "data/",
out_figures = "figures/",
out_results = "outputs/"
)
walk(c(CFG$out_data, CFG$out_figures, CFG$out_results),
~if (!dir.exists(.x)) dir.create(.x, recursive = TRUE))
# =============================================================================
# 步骤 1 — 加载脚本 02 的 PCA 工作空间
# =============================================================================
cat("\n── 步骤 1:加载 PCA 工作空间 ─────────────────────────────────────────\n")
# 在加载工作空间之前保留脚本 03 的 CFG(load() 会覆盖它)
CFG_03 <- CFG
load(CFG_03$workspace)
# 从脚本 02 加载的对象:CFG(脚本 02 的)、scores_df、meta、emb_mat、
# emb_cols、x_col、y_col、n_pcs、pca_obj
CFG <- CFG_03 # 恢复脚本 03 的配置
rm(CFG_03)
# 从文件重新读取 pca_rast — terra 的 SpatRaster 对象包含内部 C++ 指针,
# 在 save()/load() 序列化后会失效,因此我们从不序列化它们。
pca_rast <- rast(file.path(CFG$out_data, "embedding_pca.tif"))
names(pca_rast) <- paste0("PC", seq_len(nlyr(pca_rast)))
cat("可用的主成分数:", n_pcs, "\n")
cat("土壤剖面数:", nrow(meta), "\n")
cat("目标变量:", paste(CFG$target_vars, collapse = ", "), "\n")
# 重新加载土壤 CSV 以使目标列与 complete_idx 对齐
soil_raw <- read_csv(CFG$soil_csv, show_col_types = FALSE)
# 重新推导 complete_idx(与脚本 02 逻辑相同)
emb_cols_local <- grep("^A\\d{2}$", names(soil_raw), value = TRUE)
emb_mat_raw <- soil_raw |> select(all_of(emb_cols_local)) |> as.matrix()
meta_raw <- soil_raw |> select(all_of(c(CFG$lon_col, CFG$lat_col,
CFG$target_vars)))
complete_idx <- complete.cases(emb_mat_raw) & complete.cases(meta_raw)
soil_complete <- soil_raw[complete_idx, ]
cat("用于建模的完整剖面数:", sum(complete_idx), "\n")
# 点位的 PC 得分(来自 prcomp 对象)
pc_scores <- as_tibble(pca_obj$x[, 1:n_pcs])
names(pc_scores) <- paste0("PC", 1:n_pcs)
# 绑定目标变量
model_df <- bind_cols(
pc_scores,
soil_complete |> select(all_of(CFG$target_vars))
)
随机森林模型拟合与交叉验证
使用 R 语言中的 ranger 包[17]独立地为每种土壤属性拟合了 RF 回归模型。模型性能通过重复 k 折交叉验证(k=5 折,3 次重复,即 5×3 CV)进行评估,为每种土壤属性生成了 15 个保留预测集。其实现使用了 caret 包[18]。这种设计平衡了性能估计中的偏差-方差权衡:5 折交叉验证在每折中使用 80% 的数据进行训练,相对于留一法减少了训练集大小偏差,同时保持了足够的保留样本以获得稳定的误差估计;通过不同的随机折分配重复进行,减少了由特定划分引起的性能估计方差。
# =============================================================================
# 步骤 2 — 交叉验证的随机森林
# =============================================================================
cat("\n── 步骤 2:拟合 RF 模型(", CFG$cv_folds, "×", CFG$cv_repeats,
" CV)──────────────────────────────\n", sep = "")
set.seed(CFG$cv_seed)
cv_ctrl <- trainControl(
method = "repeatedcv",
number = CFG$cv_folds,
repeats = CFG$cv_repeats,
savePredictions = "final",
allowParallel = FALSE
)
pc_predictors <- paste0("PC", 1:n_pcs)
rf_models <- list()
cv_results <- list()
for (tvar in CFG$target_vars) {
cat(" 正在为", tvar, "拟合 RF ... ")
# 删除目标变量为 NA 的行
df_tvar <- model_df |>
select(all_of(c(pc_predictors, tvar))) |>
drop_na()
if (nrow(df_tvar) < 20) {
cat("跳过(n =", nrow(df_tvar), "< 20)\n")
next
}
mtry_val <- max(1, round(n_pcs * CFG$rf_mtry_frac))
suppressWarnings(
fit <- train(
x = df_tvar[, pc_predictors],
y = df_tvar[[tvar]],
method = "ranger",
trControl = cv_ctrl,
tuneGrid = data.frame(
mtry = mtry_val,
splitrule = "variance",
min.node.size = CFG$rf_min_node
),
num.trees = CFG$rf_trees,
importance = "impurity"
)
)
rf_models[[tvar]] <- fit
# CV 性能指标
pred_obs <- fit$pred |>
group_by(rowIndex) |>
summarise(obs = mean(obs),
pred = mean(pred),
.groups = "drop")
rmse_val <- sqrt(mean((pred_obs$obs - pred_obs$pred)^2))
mae_val <- mean(abs(pred_obs$obs - pred_obs$pred))
r2_val <- cor(pred_obs$obs, pred_obs$pred, use = "complete.obs")^2
cv_results[[tvar]] <- tibble(
variable = tvar,
n = nrow(df_tvar),
RMSE = round(rmse_val, 4),
MAE = round(mae_val, 4),
R2 = round(r2_val, 4)
)
cat("RMSE =", round(rmse_val, 3), " R² =", round(r2_val, 3), "\n")
}
cv_table <- bind_rows(cv_results)
write_csv(cv_table, file.path(CFG$out_results, "rf_cv_results.csv"))
cat("\nCV 性能已保存:outputs/rf_cv_results.csv\n")
print(cv_table)
性能使用三个互补指标进行总结:R²(决定系数)、RMSE(均方根误差)和 MAE(平均绝对误差)。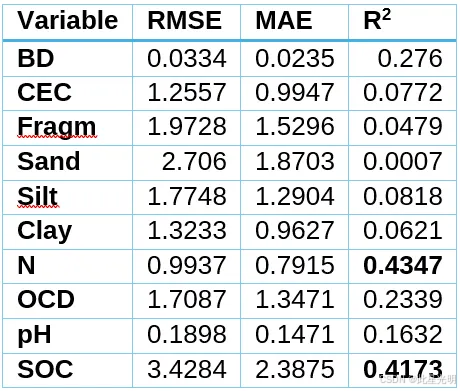
变量重要性
从每个拟合模型中提取基于不纯度的变量重要性(节点不纯度平均减少量),以识别哪些主成分轴对每种土壤属性携带了最大的预测信号。
变量重要性分析也具有模型诊断功能:如果只有一小部分主成分对预测有显著贡献,则可以安全地排除其余的主成分以提高模型的简洁性。相反,如果重要性分布在许多主成分上,这表明土壤特性依赖于嵌入空间的多个不同方面——这种模式更符合 RF 在利用高维特征交互方面的优势。
# =============================================================================
# 步骤 3 — 变量重要性
# =============================================================================
cat("\n── 步骤 3:变量重要性 ────────────────────────────────────────────\n")
imp_list <- map(names(rf_models), function(tvar) {
imp <- varImp(rf_models[[tvar]])$importance
tibble(
variable = tvar,
PC = rownames(imp),
Importance = imp[[1]]
)
})
imp_df <- bind_rows(imp_list) |>
mutate(PC = factor(PC, levels = paste0("PC", 1:n_pcs)))
write_csv(imp_df, file.path(CFG$out_results, "rf_importance.csv"))
# 变量重要性热图
p_imp <- ggplot(imp_df, aes(PC, variable, fill = Importance)) +
geom_tile(colour = "white", linewidth = 0.4) +
scale_fill_viridis_c(option = "C", name = "重要性\n(不纯度)") +
labs(title = "随机森林变量重要性",
subtitle = paste0("n_pcs = ", n_pcs,
" | 树的数量 = ", CFG$rf_trees),
x = NULL, y = NULL) +
theme_bw(base_size = 11) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
ggsave(file.path(CFG$out_figures, "07_rf_importance.png"),
p_imp, width = 10, height = 5, dpi = 300)
cat("已保存:figures/07_rf_importance.png\n")
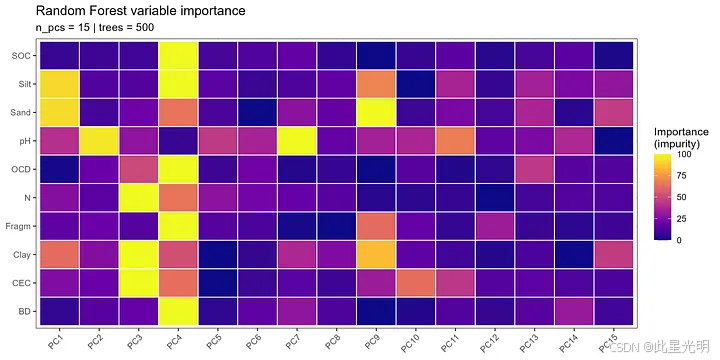
图 1:随机森林变量重要性热图
观测值与预测值诊断图
观测值与预测值的诊断图是根据重复 k 折交叉验证的输出针对每个目标土壤属性生成的。通过样本索引对重采样迭代中的预测值进行平均,以获得每个剖面一个配对的观测-预测值。散点图按变量分面,并包含一条 1:1 参考线(𝑦=𝑥)以评估校准和偏差。这种可视化通过揭示变量特定的离散程度、系统性低估或高估以及异方差性,补充了标量指标(RMSE、MAE、R²)。
# =============================================================================
# 步骤 4 — 观测值与预测值散点图
# =============================================================================
cat("\n── 步骤 4:观测值与预测值散点图 ────────────────────────────────────\n")
obs_pred_list <- map(names(rf_models), function(tvar) {
rf_models[[tvar]]$pred |>
group_by(rowIndex) |>
summarise(obs = mean(obs), pred = mean(pred), .groups = "drop") |>
mutate(variable = tvar)
})
obs_pred_df <- bind_rows(obs_pred_list)
p_obs_pred <- ggplot(obs_pred_df, aes(obs, pred)) +
geom_point(alpha = 0.5, size = 1.8, colour = "#3D7EBF") +
geom_abline(slope = 1, intercept = 0, linetype = "dashed",
colour = "firebrick", linewidth = 0.8) +
facet_wrap(~variable, scales = "free", ncol = 4) +
labs(title = "观测值 vs 预测值 — 交叉验证的随机森林",
subtitle = paste0(CFG$cv_folds, " 折 × ", CFG$cv_repeats, " 次重复"),
x = "观测值", y = "预测值") +
theme_bw(base_size = 10)
n_tvars <- length(names(rf_models))
fig_h <- ceiling(n_tvars / 4) * 3.5 + 1.5
ggsave(file.path(CFG$out_figures, "06_rf_obs_pred.png"),
p_obs_pred, width = 14, height = fig_h, dpi = 300)
cat("已保存:figures/06_rf_obs_pred.png\n")
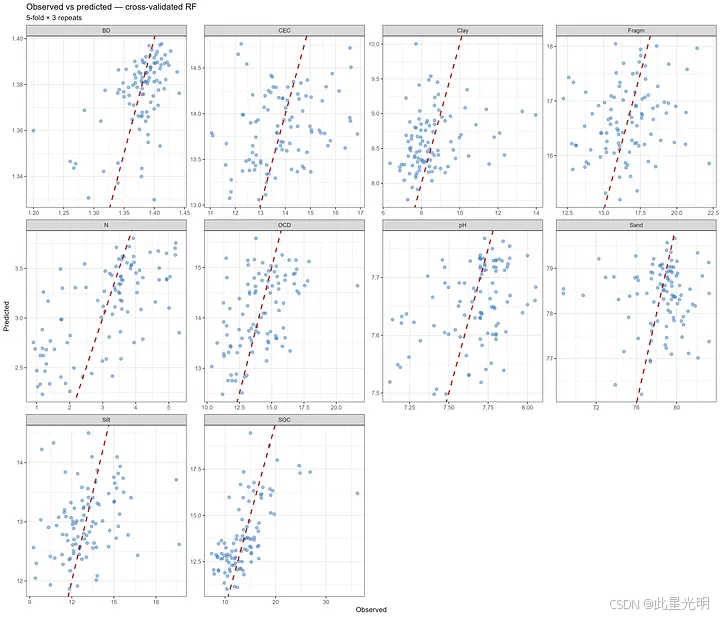
图 2:观测值 vs 交叉验证预测值 — 使用随机森林回归建模的十种土壤属性
空间预测
用于空间外推的最终 RF 模型在完整训练数据集上使用 randomForest 包[19]重新拟合。用于交叉验证的基于 ranger 的模型不用于空间预测,因为 ranger 依赖于 Rcpp 外部指针,在执行大型栅格操作时可能会变得无效;纯 R 的 randomForest 实现避免了这种序列化问题。通过从嵌入 PCA 栅格中提取所有 PC 值(每个像素一行),应用每个土壤属性模型,并将预测值重新填充到栅格网格中来生成逐像素预测。生成的预测结果导出为多波段 GeoTIFF 文件(soil_predictions.tif),每个土壤属性一个波段,使用 UTM Zone 17S 坐标参考系统(EPSG:32717)。
# =============================================================================
# 步骤 5 — 将 RF 预测投影到栅格域
# =============================================================================
cat("\n── 步骤 5:将 RF 预测投影到栅格 ─────────────────────────────────────────\n")
cat("PCA 栅格波段数:", n_pcs, "\n")
# 一次性提取所有栅格像素值(保留 NA 行以保持索引对齐)
pca_df <- as.data.frame(pca_rast, xy = FALSE, na.rm = FALSE)
names(pca_df) <- paste0("PC", seq_len(ncol(pca_df)))
valid_rows <- complete.cases(pca_df)
pca_valid <- pca_df[valid_rows, , drop = FALSE] # 用于预测的子集
cat("待预测的栅格像素数:", sum(valid_rows), " / ", nrow(pca_df), "\n")
template_r <- pca_rast[[1]] # 用于重建结果栅格的模板
pred_rasts <- list()
for (tvar in names(rf_models)) {
cat(" 正在预测:", tvar, "... ")
df_tvar <- as.data.frame(
model_df |> select(all_of(c(pc_predictors, tvar))) |> drop_na()
)
# 使用 randomForest 拟合最终模型(纯 R,无 Rcpp,可靠的序列化)
final_rf <- randomForest::randomForest(
x = df_tvar[, pc_predictors, drop = FALSE],
y = df_tvar[[tvar]],
ntree = CFG$rf_trees,
mtry = max(1L, round(n_pcs * CFG$rf_mtry_frac))
)
pred_vals <- rep(NA_real_, nrow(pca_df))
pred_vals[valid_rows] <- predict(final_rf, newdata = pca_valid)
pred_r <- template_r
values(pred_r) <- pred_vals
names(pred_r) <- tvar
pred_rasts[[tvar]] <- pred_r
cat("完成\n")
}
pred_stack <- rast(pred_rasts) # terra::rast() 将 SpatRaster 列表堆叠
writeRaster(pred_stack,
file.path(CFG$out_data, "soil_predictions.tif"),
overwrite = TRUE)
cat("已保存:data/soil_predictions.tif\n")
# =============================================================================
# 步骤 6 — 预测地图
# =============================================================================
cat("\n── 步骤 6:预测地图 ────────────────────────────────────────────────\n")
n_pred <- nlyr(pred_stack)
n_cols <- min(4, n_pred)
n_rows <- ceiling(n_pred / n_cols)
png(file.path(CFG$out_figures, "08_soil_prediction_maps.png"),
width = n_cols * 400,
height = n_rows * 350 + 100,
res = 150)
plot(pred_stack,
col = viridis(100),
main = names(pred_stack),
axes = FALSE,
mar = c(1, 1, 2.5, 3))
dev.off()
cat("已保存:figures/08_soil_prediction_maps.png\n")
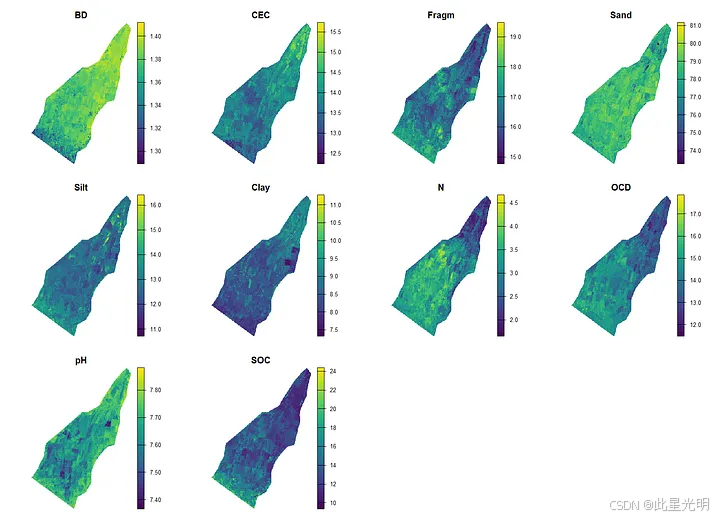
图 3:随机森林回归预测的十个土壤属性在研究区域内的空间分布

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)