采用AI 神经网络降噪技术降噪模组A-59F如何区分“人声”与“环境噪声”?
在传统语音通话系统中,环境噪声一直是影响沟通质量的核心问题。无论是在开放式办公室、工厂车间、车载环境,还是户外复杂场景中,麦克风都会同时接收到人声与大量背景声音。对于普通降噪方案而言,持续性的空调声、电流声或机械低频噪声相对容易处理,但真正困难的是那些不断变化、具有随机性的复杂噪音,例如突然出现的敲击声、风噪、犬吠、键盘声、多人交谈声以及街道环境中的车辆鸣笛。这类噪音频谱复杂,并且很多频段与人声高度重叠,传统滤波方式往往很难准确区分。
A-59F 所采用的 AI ENC(AI Environmental Noise Cancellation)环境降噪技术,核心就在于利用 AI 神经网络对“人声”和“非人声”进行实时识别,而不是简单地依靠固定频率过滤。它并不是传统意义上的“把某段频率压低”,而是通过大量语音数据库训练出的深度学习模型,对声音进行动态分析与判断
在真实通话环境中,麦克风接收到的并不仅仅是讲话人的声音。
它会同时采集:风噪,空调声,人嘈杂声,动物叫声,键盘敲击,车辆噪声,电流底噪,突发碰撞声这些复杂声音会混合在一起形成“环境音频”。
传统降噪方案通常只能对固定频率噪声进行简单过滤,例如削弱低频噪声或固定频段杂音。但现实中的噪声是动态变化的,因此传统方法很难真正解决复杂环境下的语音清晰度问题。
而 A-59F 所采用的 AI 神经网络降噪技术,则是通过“学习”和“识别”声音特征,来判断:
哪些是人声,哪些是噪声。
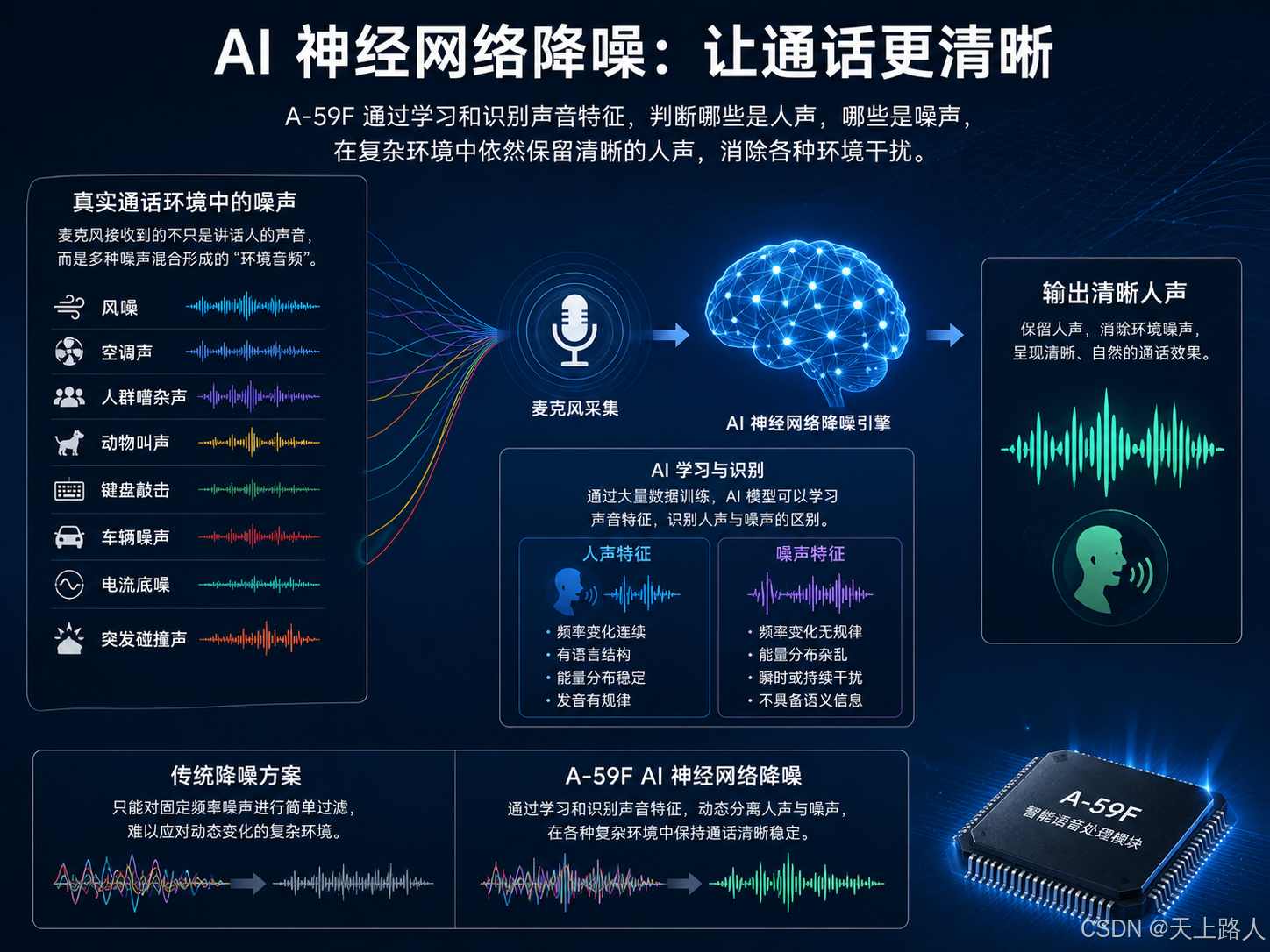
AI 神经网络降噪的核心原理
AI ENC 本质上是一种“声音分类系统”。它并不是简单降低所有声音,而是:
- 识别人声
- 判断环境噪声
- 将两者分离
- 保留语音
- 消除噪声
整个过程由 AI 神经网络模型实时完成。
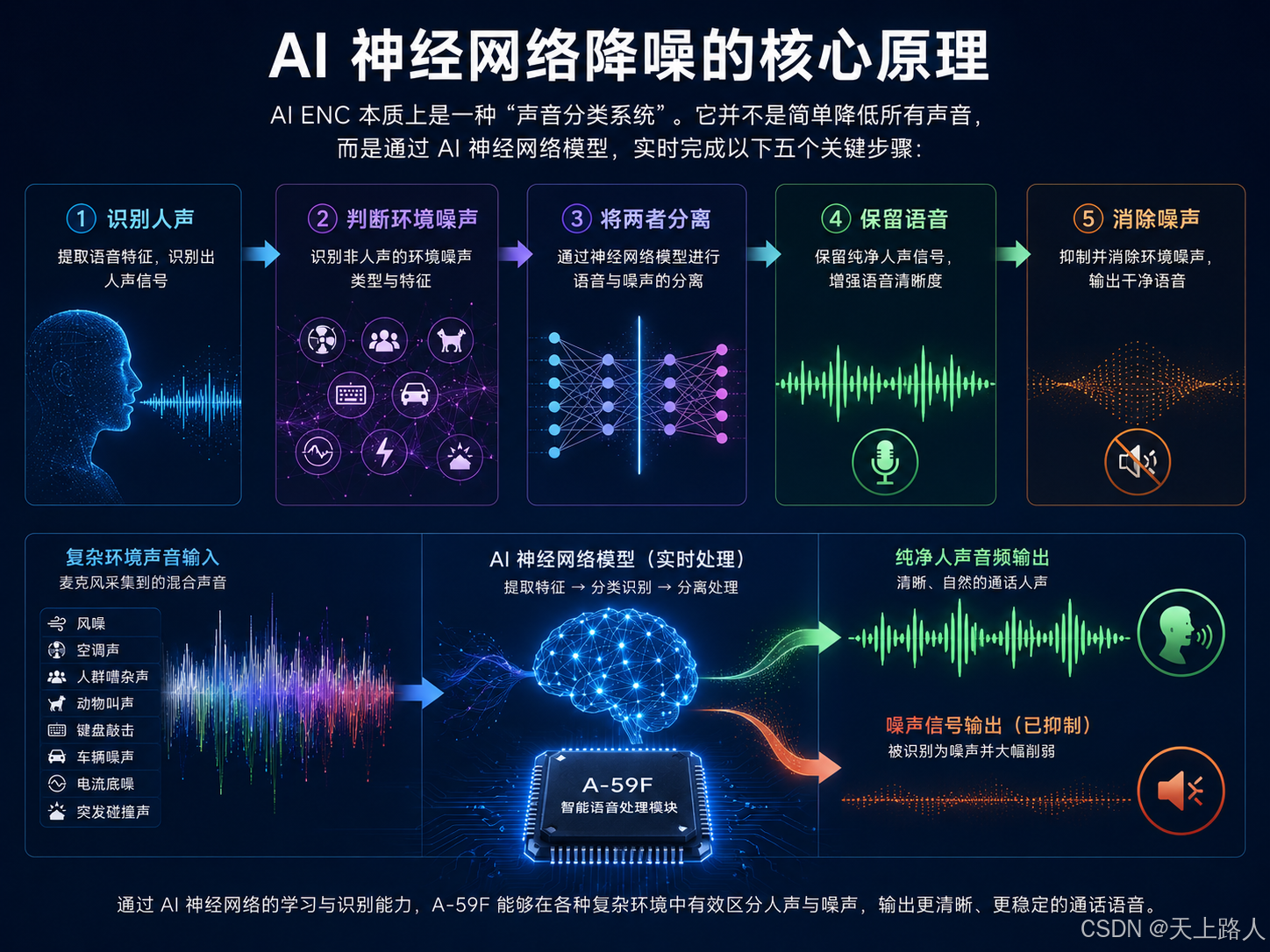
第一步:声音频谱分析
声音本质上是不同频率的振动。当麦克风采集到声音后,A-59F 会先将声音转换为频谱数据。系统会实时分析:频率变化,音量变化,时间连续性,声音能量分布,声纹特征,不同声音在频谱中具有不同特征。
例如:
人声特点
- 频率变化连续
- 有明显语言节奏
- 存在发音结构
- 元音与辅音规律明显
风噪特点
- 低频能量大
- 缺乏语言结构
- 频率随机扩散
动物叫声特点
- 瞬态频率明显
- 高频波动集中
- 不符合人类语音结构
嘈杂人群声
- 多人频率叠加
- 缺少主语音焦点
- 远场扩散明显
AI 神经网络会利用这些特征进行分类。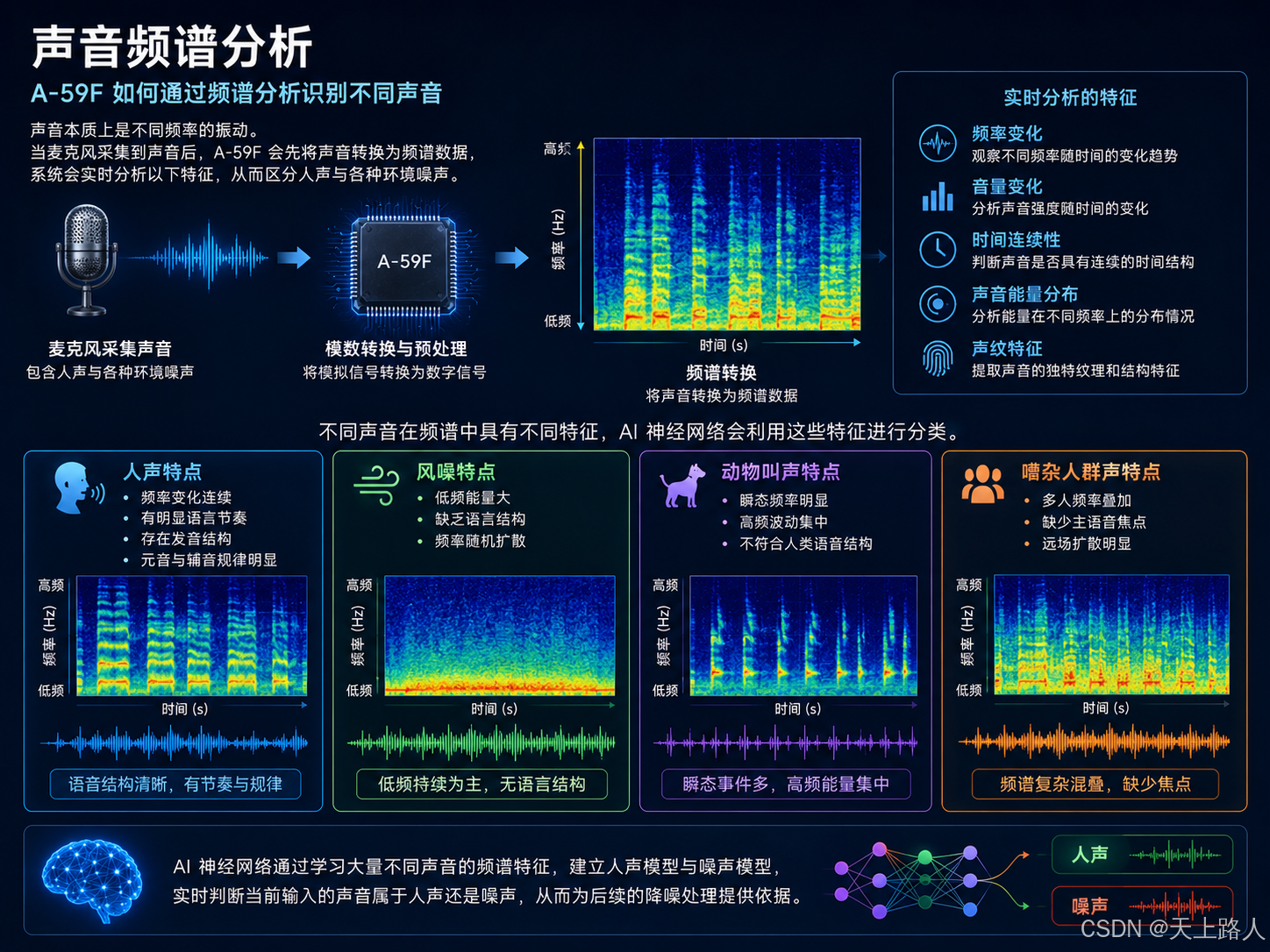
第二步:AI 神经网络学习“什么是人声”
A-59F 的 AI ENC 模型并不是固定规则算法。它是在大量真实语音数据中训练出来的。训练过程中,AI 会学习:
- 男声
- 女声
- 儿童声音
- 不同语言
- 不同口音
- 不同讲话速度
同时也会学习各种噪声:
- 风噪
- 雨声
- 汽车噪声
- 机械噪声
- 狗叫声
- 人群杂音
- 键盘声
- 电器噪声
经过海量训练后,AI 神经网络会形成:“人声模型”与“噪声模型”因此它能快速判断当前声音属于哪一类。
第三步:语音与噪声分离
这是 AI ENC 最核心的部分。神经网络会对输入声音进行实时推理:哪部分属于讲话人声音?保留。哪部分属于环境噪声?削弱或消除。
例如:
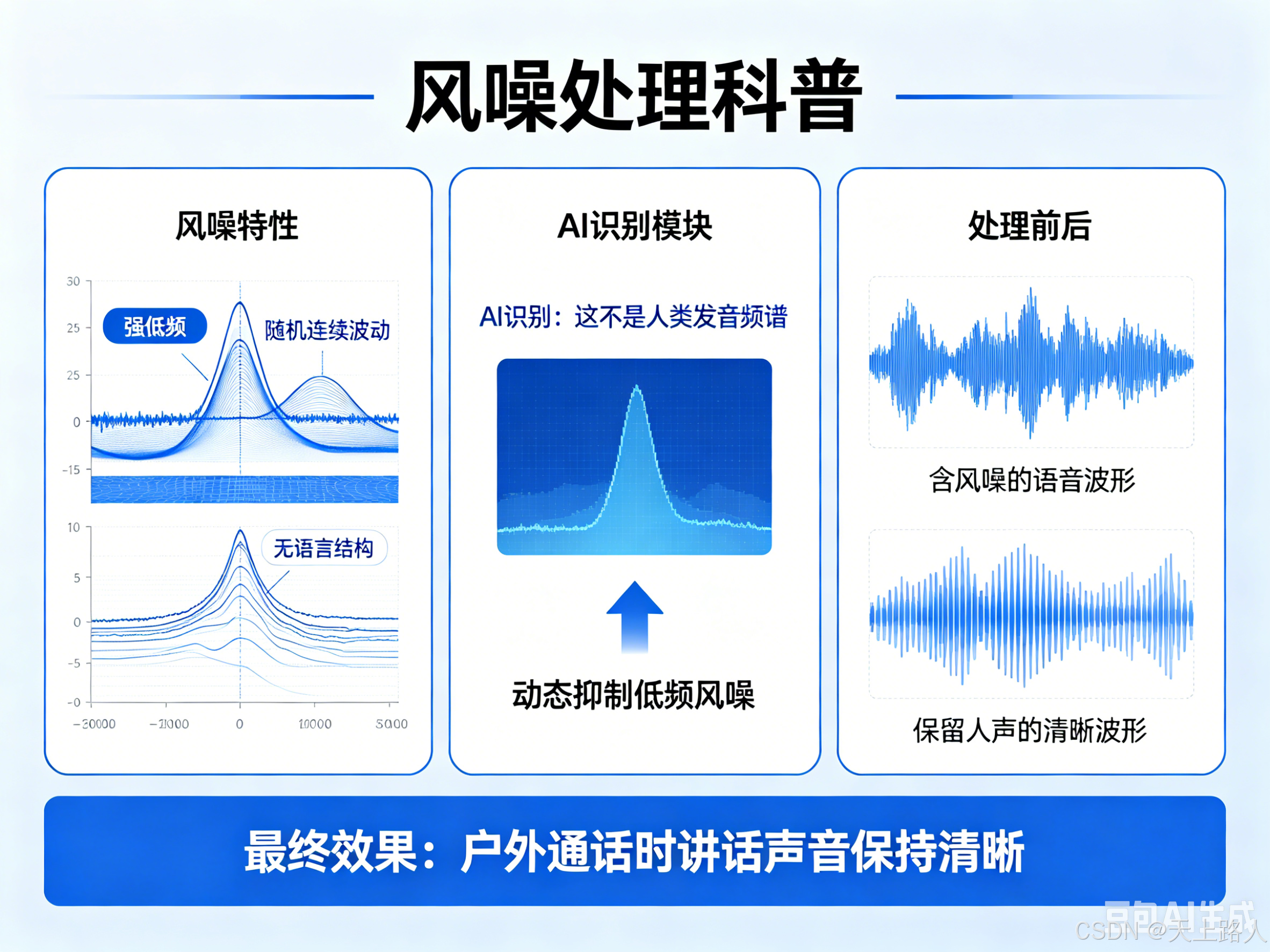
风噪处理
风噪通常具有:
- 强低频
- 随机连续波动
- 无语言结构
AI 会识别:“这不是人类发音频谱”随后对低频风噪区域进行动态抑制。同时保留人声频段。
因此:即使在户外通话时,讲话声音依然能够保持清晰。
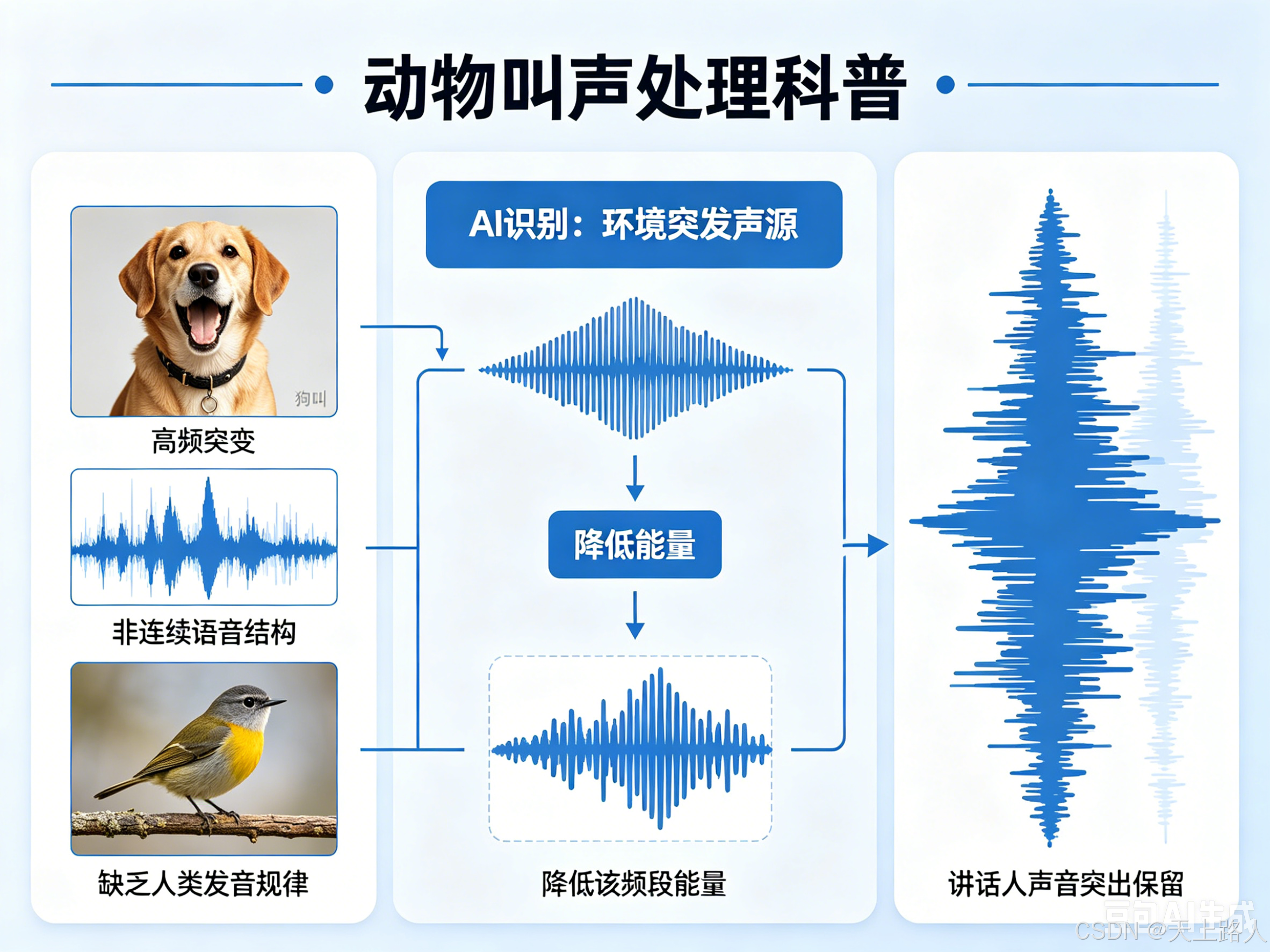
动物叫声处理
狗叫、鸟叫等声音通常具有:
- 高频突变
- 非连续语音结构
- 缺乏人类发音规律
AI 神经网络会识别:“这属于环境突发声源”随后降低该频段能量。因此:即使周围存在动物叫声,
通话中的讲话人声音依然能被突出保留。
嘈杂人群处理
多人环境最复杂。因为背景中的其它人声,本质上也是“人声”。传统降噪往往难以处理。而 AI ENC 会进一步分析:
- 声音距离
- 主语音方向
- 发音连续性
- 能量中心
- 当前讲话焦点
系统会优先保留:
距离最近、最连续、最稳定的主讲话人声音
同时弱化:
- 远处交谈声
- 背景讨论声
- 环境扩散人声
因此:即使在咖啡厅、会议室、展会等复杂环境中,依然能够突出当前通话人的声音。

第四步:实时动态调整
现实中的噪声环境并不会固定不变。
例如:
- 风突然变大
- 有人突然说话
- 出现敲击声
- 门突然关闭
A-59F 的 AI 神经网络会持续更新当前环境模型。也就是说:它不是“一次性降噪”,而是:
实时持续学习当前环境。
因此系统能够动态适应复杂场景变化。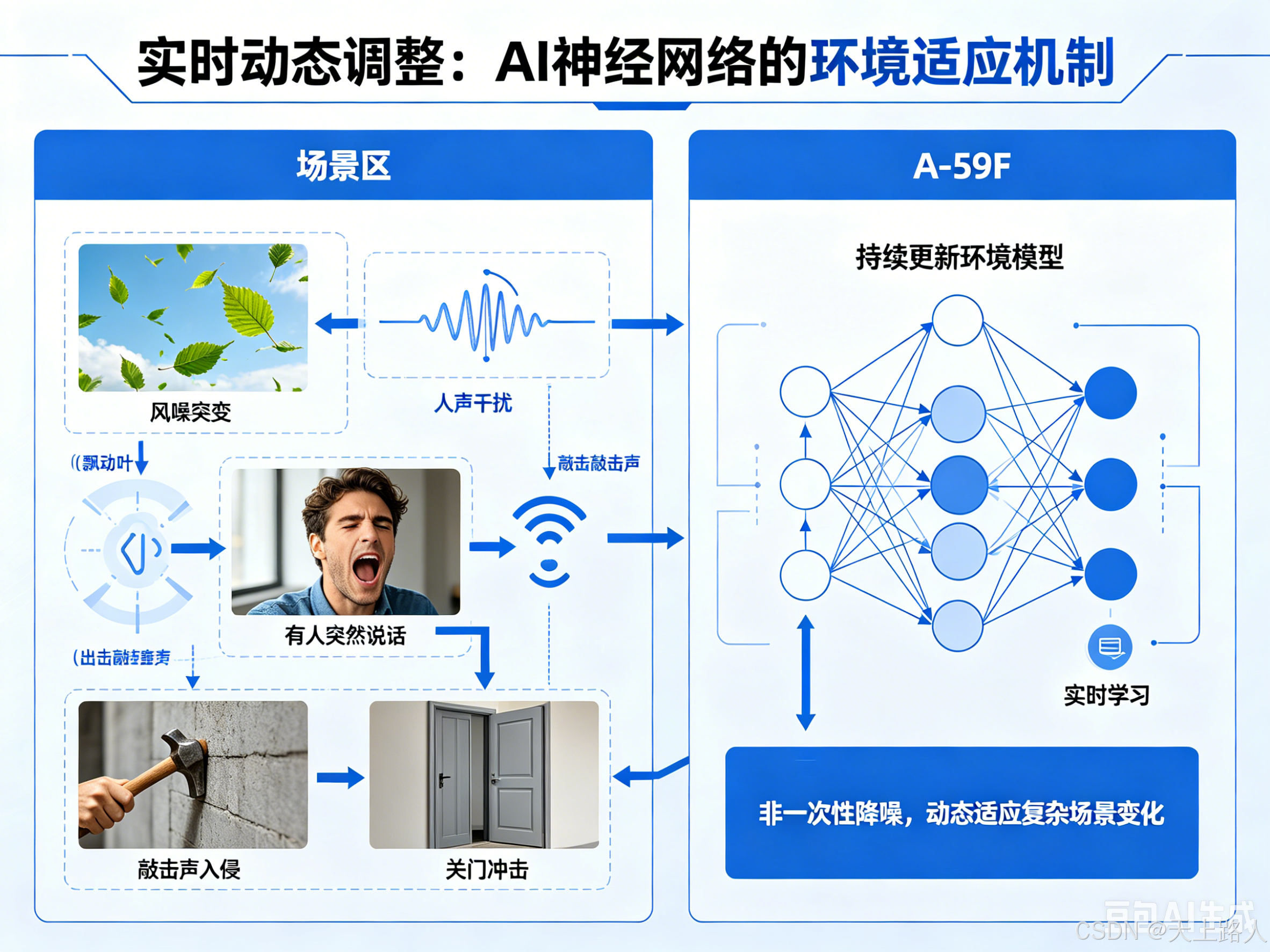
为什么 AI 神经网络降噪比传统降噪更强?
传统降噪:
- 依赖固定规则
- 只能处理简单噪声
- 容易误伤人声
- 环境适应能力弱
AI 神经网络降噪:
- 能学习复杂声音特征
- 能识别人声结构
- 能动态适应环境变化
- 能精准区分语音与噪声
因此在真实复杂环境中:
AI ENC 的效果会远远优于传统滤波方案。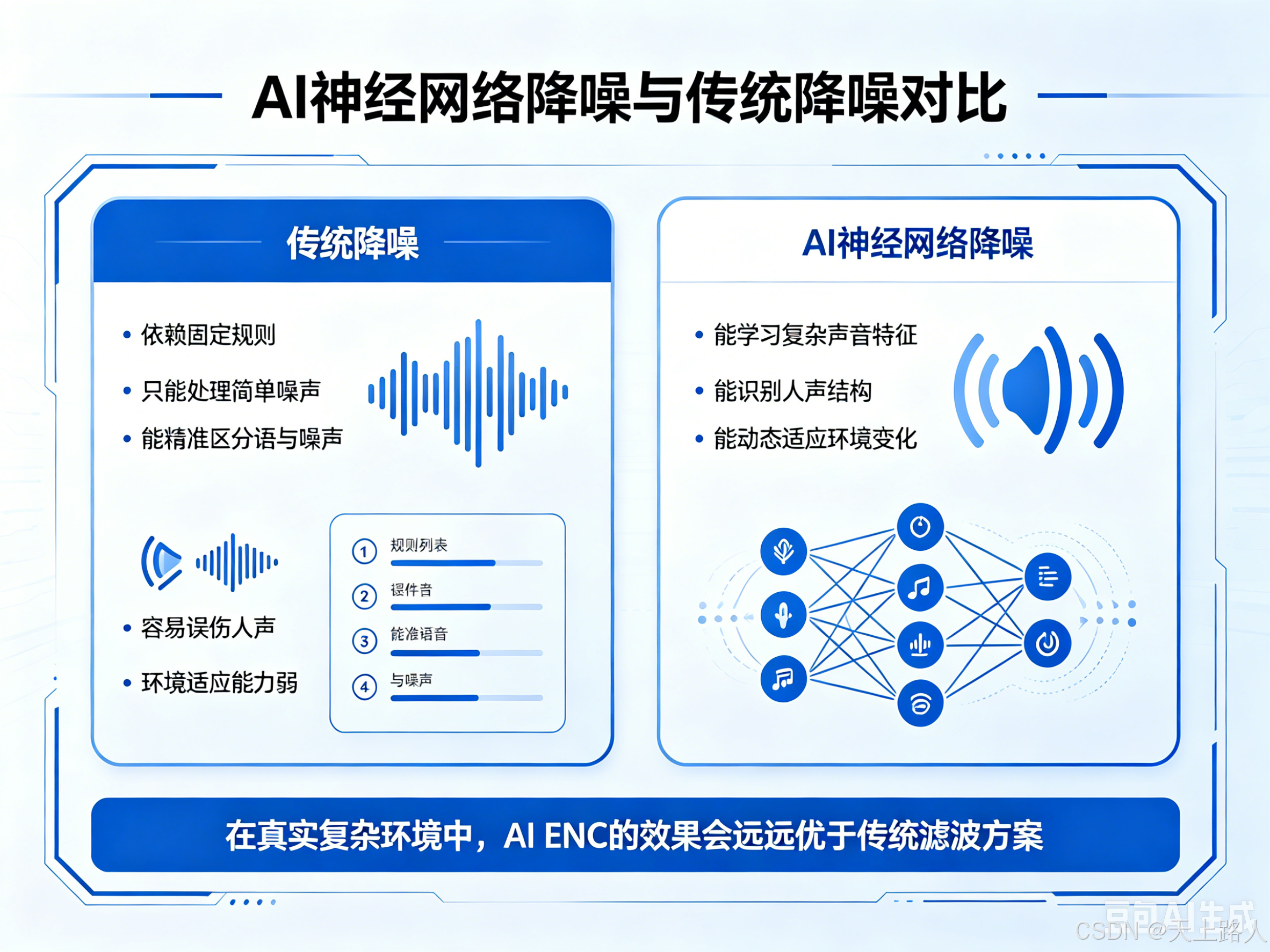
A-59F AI ENC 的实际应用价值
正因为 AI 神经网络具备强大的环境识别能力,A-59F 能够广泛应用于复杂语音场景。
例如:
视频会议
过滤空调声、键盘声、人群杂音。
户外语音设备
降低风噪与环境干扰。
车载系统
抑制发动机噪声、路噪、胎噪。
AI 智能终端
提升语音识别准确率。
工业环境
降低机械设备运行噪声。

总结
A-59F 所采用的 AI 神经网络降噪技术,本质上是通过深度学习模型,让系统具备“识别人声”的能力。
它并不是简单地降低所有声音,而是能够从复杂环境中:
- 找到真正的人声
- 分离环境噪声
- 动态消除干扰
- 保留清晰语音
即使面对:
- 风噪
- 动物叫声
- 突发杂音
- 嘈杂人群
- 复杂环境声
依然能够实现稳定、自然、清晰的通话效果。
这也是 AI ENC 技术逐渐成为下一代智能语音系统核心能力的重要原因。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)