为什么很多人会误以为“麦克风越多,拾音效果越好”
在消费电子和语音设备行业里,“多麦克风”几乎已经被营销成了“高端”的代名词。
很多产品宣传中都会强调:“4麦阵列”“6麦远场拾音”“8麦克风全向收音”于是大量用户会自然形成一种认知:
麦克风越多 = 收音越强 = 通话越清晰
但实际上,这种理解只对了一半。
真正决定拾音效果的,并不是“麦克风数量”本身,而是:麦克风布局,阵列结构空间,,声学设计算法能力,AI语音处理能力尤其是在如今 AI ENC 技术成熟之后,“算法能力”甚至已经开始逐渐超过“硬件堆叠”的重要性。
多麦克风真正的核心:不是“更多”,而是“空间信息”
很多人以为多麦克风的作用是:多个麦一起收音 → 声音更大。但这其实只是最初级的理解。在消费电子和语音设备领域,"多麦克风"已成为高端产品的代名词。各类产品宣传中常见:"4麦阵列""6麦远场拾音""8麦克风全向收音".这导致用户普遍形成"麦克风数量决定拾音质量"的认知。然而事实并非如此简单。
真正影响拾音效果的关键因素包括:
- 麦克风布局
- 阵列结构
- 空间声学设计
- 算法能力
- AI语音处理能力
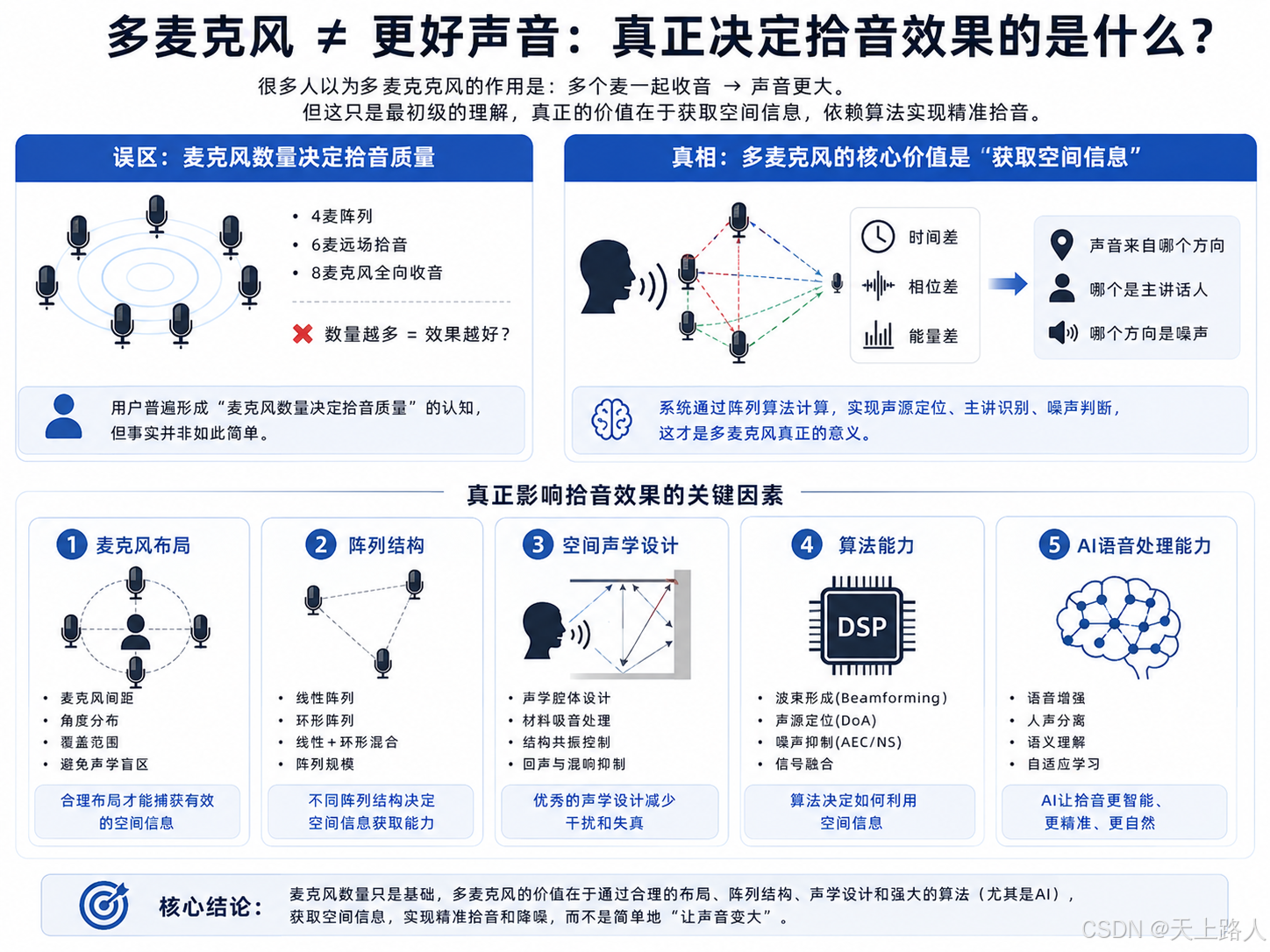
随着AI ENC技术的成熟,算法能力的重要性已逐渐超越硬件配置。多麦克风系统的核心价值在于获取空间信息而非单纯增加拾音点。通过分析不同麦克风接收到的:
- 时间差
- 相位差
- 能量差
系统能够实现: ✓ 声源定位 ✓ 主讲话人识别 ✓ 噪声方向判断这才是多麦克风阵列的真正意义所在。值得注意的是,盲目增加麦克风数量可能导致音质下降。由于声波干涉效应,多麦克风系统容易出现:
- 梳状滤波
- 人声空洞
- 高频缺失
- 语音识别率降低
实验数据显示,即便3-5cm的间距,1kHz声音仍可能产生65°相位差。这就是为什么某些8麦设备实际表现可能不及双麦系统的原因。
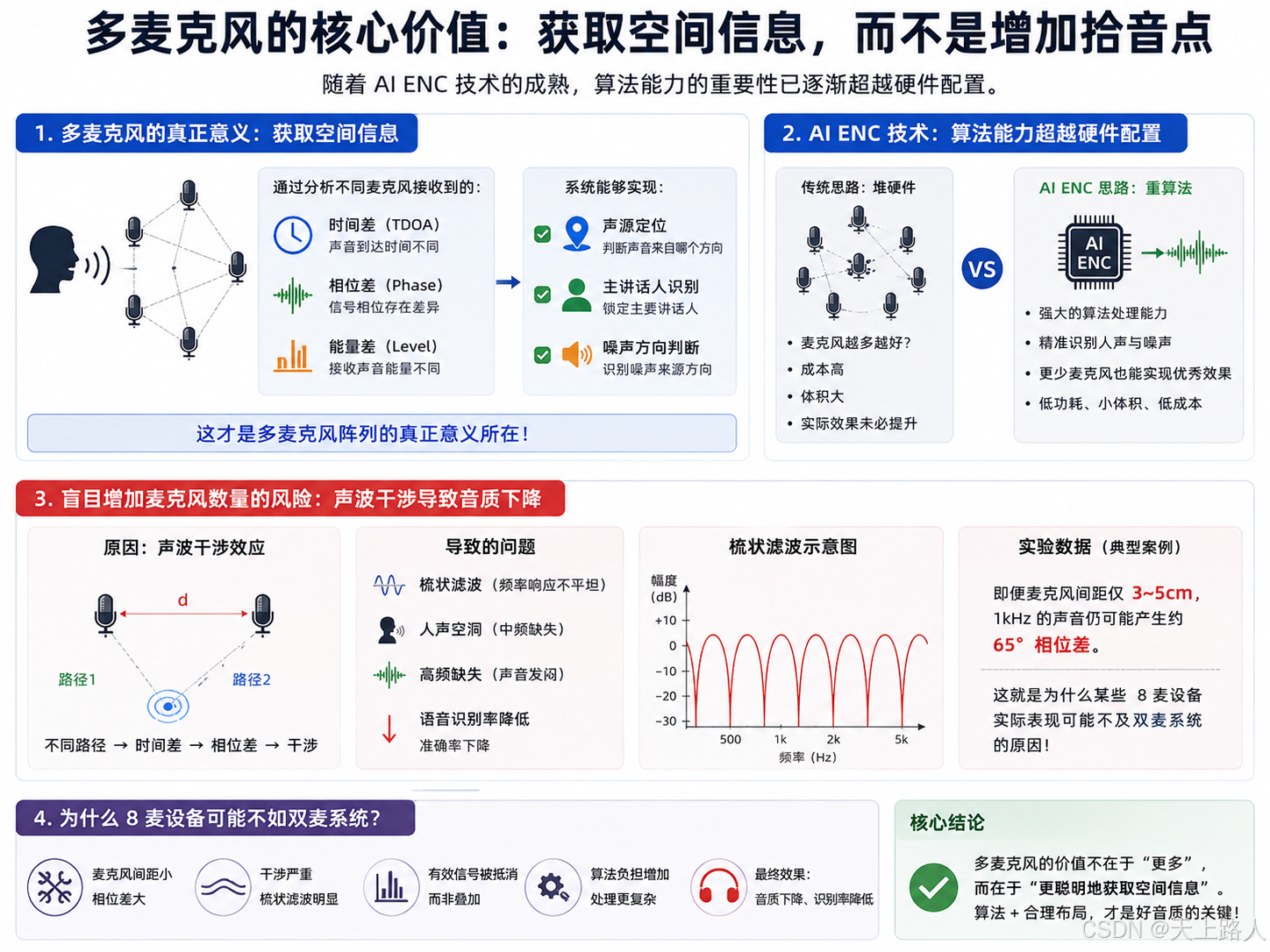
适用多麦克风的典型场景:
- 智能音箱:需要5-10米远场唤醒和360°全向识别
- 会议系统:要求发言人自动追踪和多人语音识别
- 车载系统:需应对复杂车内声学环境

而不适合多麦克风的设备包括:
- 耳机:空间限制导致阵列效果有限
- 小型对讲机:固定方向拾音需求
- 桌面会议麦:物理尺寸制约阵列性能

AI ENC技术正在改变行业格局,其核心优势在于:
- 不依赖空间定位
- 通过频谱分析实现智能降噪
- 可识别并保留人声特征
- 有效抑制各类环境噪声
未来发展趋势将呈现: → 算法优先于硬件堆叠 → 更少的麦克风数量 → 更强的AI处理能力 → 更低的功耗需求,这种转变使得AI ENC方案特别适合:
- 耳机设备
- 会议系统
- 工业语音终端
- AI交互设备
最终解决的是复杂环境中的实际通话问题,而非单纯追求麦克风数量的增加。真正的多麦克风系统,其核心价值并不是“放大声音”,而是:获取空间信息。
因为多个麦克风分布在不同位置,同一个声音到达不同麦克风时,会产生:
时间差
相位差
能量差
系统再通过阵列算法计算:
声音来自哪个方向
哪个是主讲话人
哪个方向是噪声
这才是多麦克风真正的意义。因此:多麦克风真正依赖的是“阵列算法”。而不是“简单增加麦克风数量”。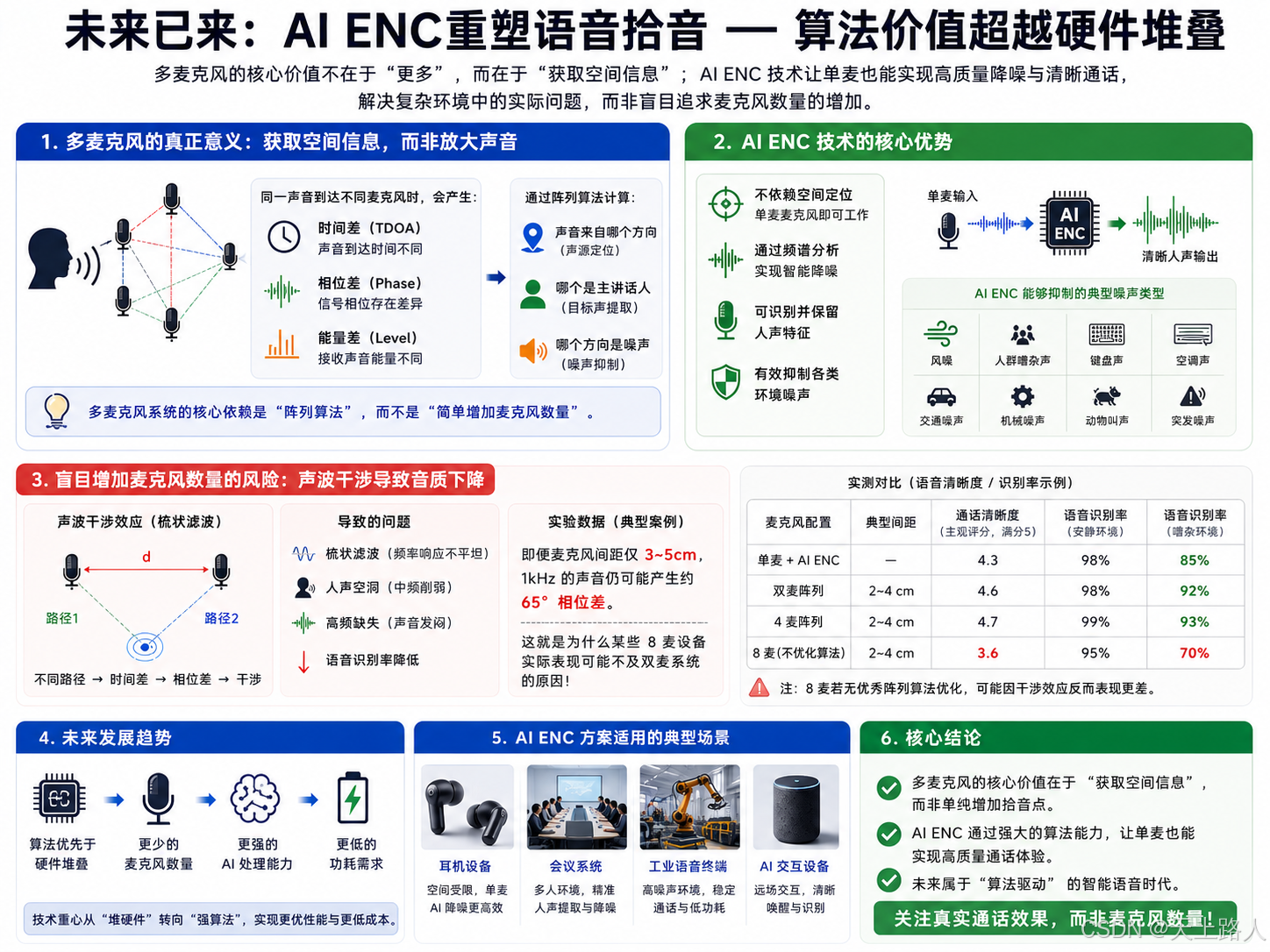
为什么“多麦克风并联”反而可能让声音更差
很多人会认为:多个麦克风一起工作,声音应该更强、更清晰。理论上确实如此。
2个麦克风并联,理论灵敏度提升约3dB
3个并联可提升约4.8dB。
但现实问题在于:声音不是静态电流。声音是“波”。只要是波,就会存在:相位干涉。
多麦克风最大的物理问题:梳状滤波
当两个麦克风距离不同,同一个声音到达它们的时间也不同。于是会产生:相位差。
某些频率会增强。某些频率会抵消。最后形成:梳状滤波。这会导致:人声发空,声音发闷,高频缺失,语音识别下降,远场拾音变差,即便只有3~5cm间距,1kHz声音仍可能产生约65°相位差。这意味着:并不是麦克风越多越好。如果布局不好,反而会让声音质量下降。
为什么有些8麦设备,效果并不比2麦更强
这是很多行业内人士都知道,但消费者很少知道的事实。Google Home 仅使用双麦阵列,但在6米测试中依然表现优秀,甚至成本远低于部分6麦、8麦产品。
原因很简单:决定拾音效果的,已经不再是“麦克风数量”。而是:算法。

AI ENC 为什么开始改变行业方向
传统多麦降噪,本质上还是:“空间过滤”。它依赖:方向差异。但 AI ENC 完全不同。AI ENC 的核心逻辑是:声音识别。它不是判断:“声音从哪里来”。而是判断:这是不是人声”。
AI单麦降噪为什么能做到强降噪
A-59F 的 AI ENC 核心本质是:神经网络声音分类。
系统会先将声音转换成:频谱数据。随后 AI 神经网络实时分析:频率变化时间,连续性语音节奏,能量分布,声纹结构.AI 会判断:哪些符合人类语音结构哪些属于噪声例如:风噪通常是低频随机扩散;动物叫声具有瞬态高频特征;键盘声具有短脉冲冲击结构;人群声缺乏主语音焦点。AI 会把这些全部分类。然后:保留人声。压制噪声。
AI ENC 最大的优势:不依赖空间
传统双麦:依赖麦克风间距。依赖方向。依赖空间关系。而 AI 单麦:只依赖声音特征。
因此:即使只有一个麦克风,依然能实现:风噪抑制,突发噪声过滤,人群噪声,压制动物叫声,抑制键盘敲击过滤.这也是为什么:现在越来越多设备,开始从:“硬件堆叠”转向:“AI算法增强”。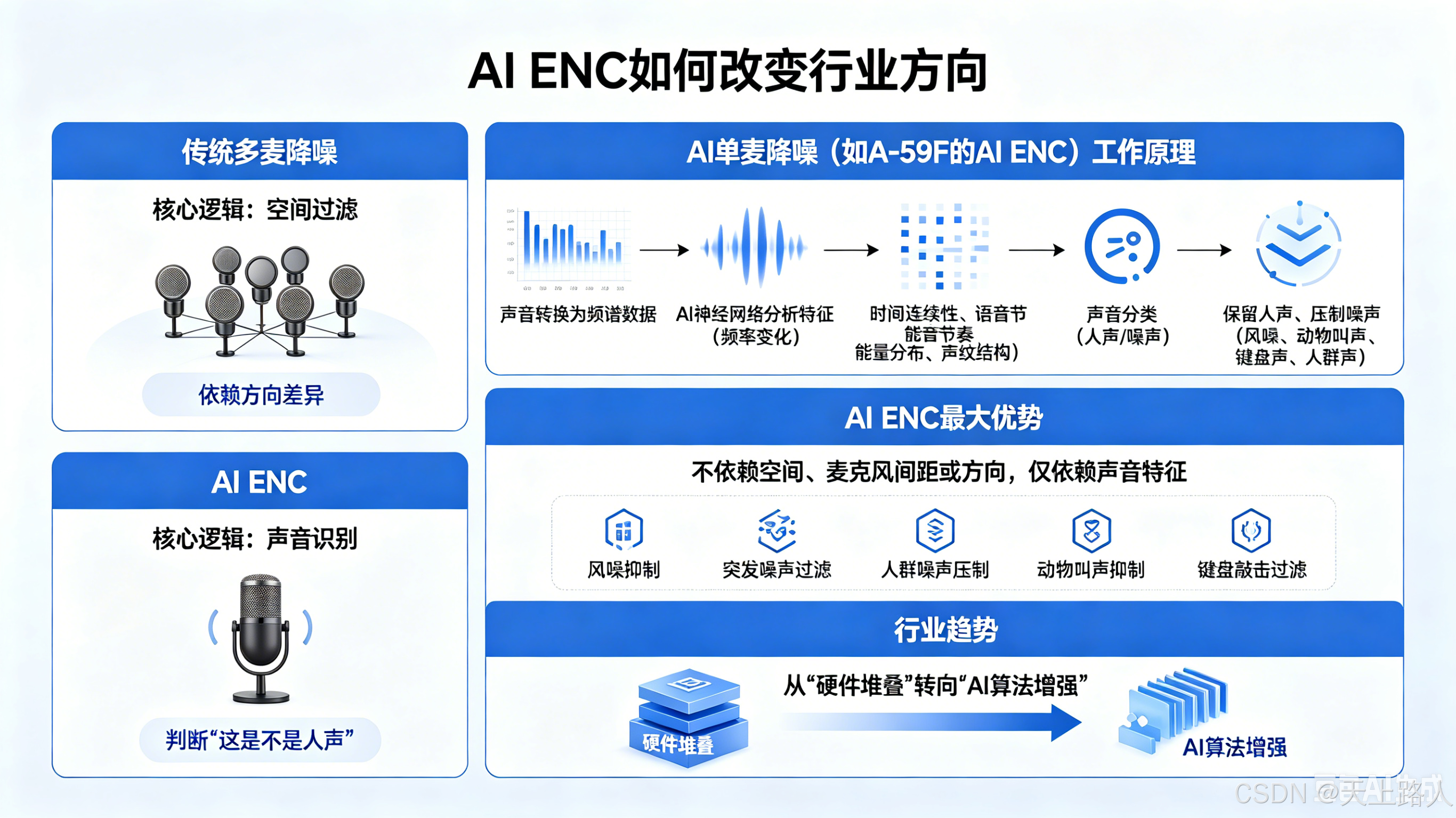
AI 单麦与传统多麦的真实对比
| 对比项 | 传统双麦/阵列 | AI 单麦 ENC |
|---|---|---|
| 核心原理 | 空间定位 | 声音识别 |
| 是否依赖麦克风布局 | 高度依赖 | 几乎不依赖 |
| 是否需要阵列结构 | 必须 | 不需要 |
| 风噪处理 | 较弱 | 强 |
| 突发噪声处理 | 较弱 | 强 |
| 小型设备适配 | 一般 | 非常适合 |
| 成本 | 高 | 低 |
| 集成复杂度 | 高 | 低 |
| 远场定位能力 | 强 | 一般 |
| 通话降噪能力 | 中等 | 很强 |
为什么未来趋势一定是“算法优先”
过去十年,行业一直在靠:增加麦克风数量提升语音性能。但 AI 的出现,正在改变整个逻辑。因为:空间阵列存在物理极限。而 AI 模型不存在。麦克风数量不可能无限增加,但 AI 模型却可以持续训练。
因此未来真正的方向会变成:更少的麦克风,更强的AI算法,更低的功耗,更高的降噪能力,这也是为什么:A-59F 这类 AI ENC 方案,开始越来越适合:耳机会议设备对讲系统工业语音终端AI语音交互设备因为它真正解决的是:复杂真实环境中的通话问题。而不仅仅只是:“增加几个麦克风”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)