RAG 答错了,先别急着喊模型幻觉,回头看看证据链断在哪一层
做过智能体的人多半都有过这种瞬间:运营截一张离谱的回答给你,问"是不是模型不行"。
很多团队的第一反应也确实是这套:模型太弱?幻觉太重?要不要换更大的?
能理解,但十有八九会把问题带偏。
RAG 答不准,很少是一个单点故障。检索、排序、注入、生成这四层里,至少有一层走偏了。用户最后看到的只是一句错答,可这句错答前面,系统已经默默走完了好几道工序:先去检索,把候选材料找回来;再做排序,决定哪些靠前;再决定哪些片段进入模型真正看到的上下文;最后才轮到模型生成。
任意一环偏一点,结果就跑了。
更麻烦的是,智能体场景里这条链子还会被放大。RAG 通常以"工具"的形式被 Agent 反复调用,多轮之间上下文不断累加,错误证据一旦进了对话历史,后面几轮都会被它带跑。检索层的问题,可能要等到第三、第四轮才暴露出来。
遇到错答,老一点的做法不是先喊"模型幻觉",而是回头问三件事:证据进没进来?进来之后排得对不对?排对之后模型有没有真的照着证据回答?
这三件事没拆清楚,调优全凭感觉。
先说结论
RAG 出问题这件事,按"层"看比按"现象"看顺手得多。
四层从前往后:
- 检索层——该找的证据有没有被找回来
- 排序层——找回来的一堆候选里,对的那条有没有冒到前面
- 注入层——排到前面的那条,有没有真正进入模型看到的那段上下文
- 生成层——证据都在了,模型还按不按它回答
前面三层属于证据链的事,最后一层才稍微贴近大家平时说的"模型问题"。
记住一句就够了:RAG 先查证据链,再怪模型。
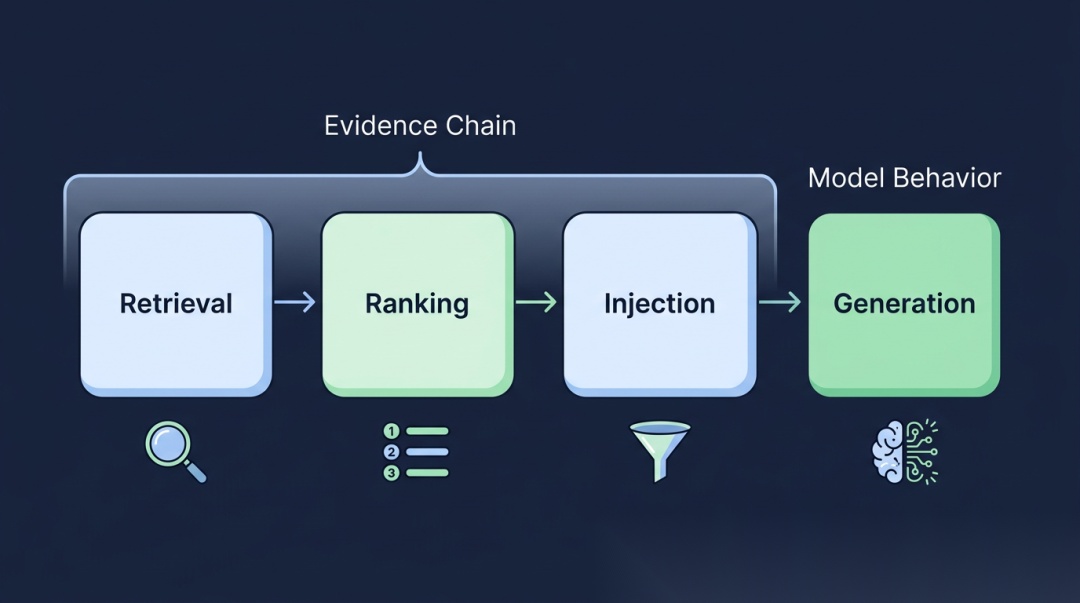
一、四层各自在管什么
检索层:证据进没进来
最前面这关,做的是"去哪找、怎么找、找哪些"。这关偏了,后面就别谈了。
容易翻车的几个点:用户的问法和文档里的术语对不上;查询改写改着改着把关键限定词改没了;Embedding 向量空间不匹配,语义召回偏;关键词那一路没覆盖缩写、别名、行业黑话;分块切得太碎,相关证据被切散,根本召不到。
这层出问题的样子很好认:你把候选结果翻出来,正确文档压根没出现。碰到这种情况,再去调 Prompt、换模型,等于在错的地方使劲。
智能体场景里还要多注意一个坑:很多 Agent 会自己改写查询,比如把"上海公司今年 Q3 加班费政策"改写成"加班费"。听起来是简化,实际上把限定条件全丢了,召回出来的全是别的城市、别的年份的内容。这种问题不看候选,光看最终答案是看不出来的。
排序层:进来了,但没排上来
更多时候不是"没找到",而是"找到了,但顺序不对"。
最常见的几种:正确答案在 Top20 里,卡在第 18 名进不了 Top3;新版制度召回到了,旧版制度排得反而更前;一段口语化的 FAQ 把正式制度压了下去;概述性材料挤掉了真正的操作规则。
这时候你看召回率,数据可能挺好看,但用户拿到的答案就是不准。原因也简单:候选池里有什么不重要,最后送进去的是谁才重要。
如果你的系统只用纯向量相似度排序,没有引入权威性、时效性、文档类型这些维度,这层基本一定会出问题。生产里很少能靠"语义最相近"一招通吃。
注入层:排对了,但没真进上下文
这层最容易被忽略。
很多人默认排序对了模型就一定看到了,其实中间还隔着一道工序:TopK 取多大、上下文预算怎么分、多个 chunk 怎么拼、有冲突的怎么处理、重复的去不去。
这道工序没做好会出现两种情况。一种是证据根本没进去:TopK 设小了把正确 chunk 截掉;长文档前半段塞满窗口,关键片段被挤出去;多路召回合并的时候,某一路的正确结果丢在了拼接环节。另一种是进去了但被污染了:弱相关片段塞了一大堆,新旧版本一起进,表格和它的标题被切散,OCR 噪声、页脚、免责声明也跟着进来凑热闹。
智能体里这层尤其危险。Agent 多轮调用的时候,上一轮的检索结果会留在历史里,下一轮再叠新的进来,几轮之后,上下文窗口可能 70% 都是 RAG 拼出来的"噪声块"。模型在这堆东西里挑信息,挑错的概率自然就高。
这层关心的不是"候选池里有没有",而是"模型最后看到的那段上下文,到底干净不干净、完整不完整"。
生成层:证据都在,模型还偏
只有把前面三层都确认下来了,生成层的问题才真有讨论价值。
也就是:证据召回了、排序没大问题、最终上下文里也确实有正确材料,模型还是答偏。这时候才比较像生成层的事。
常见的偏法是这样的:忽略证据里的限定条件;把好几段材料糊在一起编出一个新结论;面对冲突材料自己拍板选一个;证据不够也要硬补,把答案凑齐;引用了材料,但结论已经飞出材料能支持的范围。
到这一步再谈"模型幻觉",才比较站得住脚。不然很多被叫做幻觉的东西,本质上只是模型在错的证据上写得很流畅而已。
二、智能体场景里,这四层会被放大
普通 RAG 的链路是单次的:一个 query 进来,跑一遍四层,给个答案。
Agent 不一样。一个任务下来,它可能调用 RAG 工具五次、十次,每次的检索、排序、注入都在叠加,错误也在叠加。所以同样一条不稳的检索链,在普通问答里也许只是偶尔出错,到了 Agent 里就会被多轮一起放大成系统性问题。
几个典型的"放大"场景,做过 Agent 的人应该都不陌生。
多轮污染。 第一轮把一份过期的旧政策召回了,模型基于它写了一段答案,留进了对话历史。第二轮用户追问细节,Agent 又调了一次 RAG,新检索结果还没来得及覆盖旧证据,模型已经把第一轮的旧政策当成了"已确认事实"。后面几轮全错。最坑的地方是:你单看任意一轮的检索结果,都没问题;问题是几轮证据被串起来之后产生的。
子查询丢限定。 Agent 自己拆任务的时候,常会把"上海分公司 2024 年 Q3 销售数据"拆成"销售数据"这种宽泛子查询。检索层瞬间退化成模糊搜索,召回的全是别的地区、别的季度的内容。这种错你从主任务的输入看不出来——主输入完全合规,错出在 Agent 内部那一层"任务分解"上。
工具滥用与跳过。 模型有时候会跳过 RAG 工具,直接用预训练里的知识回答企业内部问题,看起来像是"答上了",其实根本没查证据。这种错最隐蔽,因为答得越流畅越像对的。
证据来源混淆。 Agent 同时挂了多个知识库工具——产品文档、运维手册、客户合同。多轮下来,模型会分不清哪段证据来自哪个库,回答时把客户合同里的条款套到了产品文档的语境上。这本质上是注入层没做好"来源标注"的衍生问题。
应对这些放大效应,关键不在某个具体技术,而在 Agent 框架层面前置几条约束:每条注入证据带上来源、版本、时间戳;多轮历史超过一定长度就主动清理早期 RAG 片段;强制 Agent 在企业内部知识问题上必须走工具,不能直答;子查询的最小限定信息(时间、主体、地域)必须从父任务里继承下来。
这些约束单看都不复杂,难的是把它们当成框架里的硬规则,而不是事后想起来再补。
三、错答到手以后,怎么一层层往下查
讲到这儿,我把日常排查 RAG 错答的顺序写得更具体一点,给智能体开发者一份可以照着走的流程。
第一步,先复现,并且把过程数据全留下来。 拿到一个错答,第一件事不是分析它,是把它跑回来,并且把每一层的中间产物都打印出来:用户原始问题、Agent 改写过的子查询、每一路检索的 TopN 候选(带分数)、Rerank 之后的顺序、最终拼到 Prompt 里的上下文片段及其来源。没有这些数据,后面所有讨论都是猜。Agent 系统尤其要把每次工具调用的输入输出都落盘——线上排错的时候,你会无数次感谢自己当初记了日志。
第二步,看检索候选里有没有正确证据。 凭经验或者人工标注,先确定这条问题"理论上应该命中哪份文档的哪一段",然后到候选列表里翻。如果根本没翻到,问题钉死在检索层,往这几个方向看:用户问法和文档术语的差距大不大(要不要做术语对齐或同义词扩展),分块策略是不是把答案切碎了(chunk 边界对吗,重叠够吗),Embedding 模型是不是不适配你的领域(医疗、法律、内部黑话这些场景,通用模型常常拉胯),关键词检索是不是被忽略了(很多团队只用向量,碰到型号、编号、专有名词时召回就崩)。
第三步,看排序结果。 候选里有,但排到第 15 名,最终 TopK 没带上它,那是排序层的事。这层最值得做的两件事:一是上一个 Rerank 模型,cross-encoder 类的对短句和精确语义判断比纯向量好得多;二是把"权威性、时效性、文档类型"这些非语义信号加进排序权重——内部规章应该压过 FAQ,新版应该压过旧版,正式制度应该压过会议纪要。这些规则一旦补上,排序层的稳定性会立刻上一个台阶。
第四步,看模型实际看到的那段 Prompt。 这一步很多人跳过,但它是最容易揪出问题的一步。把发给大模型的最终消息原样打印出来,逐行看:正确证据真的在里面吗?是不是被截断了?前后有没有混着不相关的东西?历史轮次的旧证据是不是还赖在上下文里?如果到这一步发现 Prompt 里压根没那条证据,说明排序之后的注入环节出了问题——可能 TopK 太小,可能预算分配不合理,可能多路结果合并的时候丢了东西。
第五步,确认证据都在以后,再讨论模型行为。 只有当上面四步都确认 OK,错答才真正属于生成层。这时候去看 Prompt 的约束够不够(有没有要求"只能用材料回答"“材料里没有就承认没有”“每条事实标注来源”),temperature 是不是太高,模型是不是在冲突材料前缺乏处理指令,要不要加一道拒答策略或人工兜底。这些动作放对了位置才有效,放错位置就只是徒劳。
走完这五步,绝大多数错答都能定位到具体的那一层。剩下的少数疑难杂症,再单独深挖。
四、定位顺序决定调优效率
RAG 系统最怕的不是出错,是错了不知道该修哪儿。
很多团队一看见结果不准,就同时下手:调 Prompt、换模型、加 Rerank、改分块、加查询改写——一通操作下来,问题可能解决了,可能没解决,但你说不清是哪一刀起的作用。下次再遇到类似的错,还得从头猜一遍。Agent 系统里更麻烦,Prompt 改得复杂之后模型推理变长,Rerank 加上之后延迟翻倍,分块策略一动整个索引要重建——叠在一起就成了打地鼠。
分层定位就是为了避免这种乱调。
拿评测来说。不分层的时候,团队拿到一个错答,能说出口的也就一句"这个 RAG 不太准",对优化基本没用。真正有用的评测得拆成:召回有没有命中正确证据、正确证据有没有排到有效位置、最终上下文有没有包含关键材料、回答有没有忠于上下文。RAGAS 这类框架做的也是这件事,只不过指标名叫 context recall、context precision、faithfulness、answer relevancy,本质就是分层。
再说模型背锅这事。模型最显眼,最容易当背锅侠。可检索和注入本来就不稳的话,你换再大的模型,也只是把错答写得更像对的——一颗 GPU 解决不了一段切错的 chunk。
调优顺序也一样。先把证据链打通、再让证据链稳定、最后才讨论模型要不要升级。倒过来就会变成召回还没稳就堆复杂 Prompt、排序还没稳就上多轮 Agent、注入还没稳就换更大模型,复杂度和成本一起涨,问题该有还是有。
做智能体的团队还多一个好处:分层之后,监控能直接挂到每一层上。线上哪层指标掉了,立刻知道是哪条流水线出了问题,不用盯着"用户满意度"干瞪眼。
归结起来一句话:文档没召回到,先查检索;召回了但没进最终上下文,是排序或注入;证据都在、模型还偏,才轮到生成层。先看证据链,再看模型行为。 顺序反了,调优就是扔骰子。
五、治理类问题,最后也都落在这四层上
前面把问题都收进了"检索、排序、注入、生成"。但真实项目里,还有一堆看起来像治理问题的东西,拆到底还是这四层的事。
知识过期,最先打到检索层和排序层;权威源不清,排序就乱;新旧版本并存,直接污染注入;权限前置没做好,注入进来的上下文本身就不可信。治理不是跟四层并列的另一套东西,它是这些层长期出错的上游原因。
做久了 RAG 的团队,不会只盯检索分数,也不会只盯模型回答——文档源头靠不靠谱、版本清不清楚、排序规则有没有体现权威、注入的上下文能不能追溯来源,这几件事得一起看。做 Agent 的还要再加一条:上下文里每一段能不能追溯到具体哪次工具调用、来自哪个知识库、拿的哪个版本。多轮场景里,可追溯性几乎是刚需。
结语
一句话带走就行:RAG 先查证据链,再怪模型。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)