VLM(Vision-Language Model)视觉语言模型学习笔记
VLM(Vision-Language Model)视觉语言模型学习笔记
主题:视觉语言模型的概念、架构、训练方法、代表模型、推理部署、评测体系与常见挑战。
1. 总览
VLM(Vision-Language Model)通常译为视觉语言模型。它的核心目标是让模型同时理解视觉信息和语言信息,并在两种模态之间建立可计算、可推理、可生成的对应关系。
最常见的 VLM 输入是“图像 + 文本”,输出可以是文本、类别、相似度分数、边界框、分割掩码或结构化结果。随着多模态大模型的发展,现代 VLM 往往会把视觉编码器接入大语言模型,让语言模型基于视觉 token 进行问答、推理与对话。
重点:VLM 的核心不是“给图片配一句话”,而是建立图像区域、视觉概念、文本描述、语言推理之间的跨模态对齐。
1.1 常用缩写速查
| 缩写 | 全拼 | 中文含义 |
|---|---|---|
| VLM | Vision-Language Model | 视觉语言模型 |
| MLLM | Multimodal Large Language Model | 多模态大语言模型 |
| LLM | Large Language Model | 大语言模型 |
| vLLM | 项目名,不是 Vision-Language Model 的缩写 | 高性能 LLM 推理服务框架 |
| GPT | Generative Pre-trained Transformer | 生成式预训练 Transformer |
| CV | Computer Vision | 计算机视觉 |
| OCR | Optical Character Recognition | 光学字符识别 |
| ViT | Vision Transformer | 视觉 Transformer |
| CLS | Classification Token | 分类汇聚 token |
| CLIP | Contrastive Language-Image Pre-training | 对比式图文预训练模型 |
| BLIP | Bootstrapping Language-Image Pre-training | 自举式图文预训练模型 |
| LLaVA | Large Language and Vision Assistant | 语言与视觉助手模型 |
| SigLIP | Sigmoid Loss for Language Image Pre-training | 使用 sigmoid 损失的图文预训练模型 |
| Q-Former | Querying Transformer | 查询式 Transformer |
| ITC | Image-Text Contrastive | 图文对比学习 |
| ITM | Image-Text Matching | 图文匹配 |
| ITG | Image-Text Generation | 图文生成 |
| LM | Language Modeling | 语言建模 |
| VQA | Visual Question Answering | 视觉问答 |
| MLP | Multi-Layer Perceptron | 多层感知机 |
| KV Cache | Key-Value Cache | 注意力键值缓存 |
| TTFT | Time to First Token | 首 token 延迟 |
| TPOT | Time Per Output Token | 每输出 token 时间 |
| Portable Document Format | 可移植文档格式 | |
| JSON | JavaScript Object Notation | 结构化数据交换格式 |
| CPU | Central Processing Unit | 中央处理器 |
| GPU | Graphics Processing Unit | 图形处理器 |
| IO | Input and Output | 输入输出 |
| FP16 | 16-bit Floating Point | 16 位浮点数 |
| INT8 | 8-bit Integer | 8 位整数 |
| INT4 | 4-bit Integer | 4 位整数 |
| VQAv2 | Visual Question Answering v2 | 视觉问答数据集第二版 |
| GQA | Graph Question Answering | 基于场景图的视觉问答评测 |
| TextVQA | Text Visual Question Answering | 图中文字问答评测 |
| DocVQA | Document Visual Question Answering | 文档视觉问答评测 |
| MMBench | Multi-modal Benchmark | 多模态综合评测基准 |
| MME | Multimodal Evaluation | 多模态评测基准 |
| MMMU | Massive Multi-discipline Multimodal Understanding | 大规模多学科多模态理解评测 |
| POPE | Polling-based Object Probing Evaluation | 对象幻觉评测方法 |
| SEED-Bench | Spatial and Embodied Decision Benchmark | 多模态综合评测基准 |
| F1 | F1 Score | 精确率和召回率的调和平均指标 |
| CIDEr | Consensus-based Image Description Evaluation | 图像描述生成评价指标 |
| BLEU | Bilingual Evaluation Understudy | 机器翻译与文本生成评价指标 |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation | 摘要与文本生成评价指标 |
全文按五条主线组织。
- 先区分 VLM、MLLM(Multimodal Large Language Model)、vLLM、视觉 token、图文对齐等基础概念。
- 再解释视觉编码器、连接器、语言模型如何组成完整数据流。
- 然后沿 CLIP、BLIP、BLIP-2、Flamingo、LLaVA 等模型梳理训练范式演进。
- 接着说明生成式 VLM 的推理过程、Prefill、Decode、KV Cache 与部署优化。
- 最后整理评测体系和常见挑战,用于判断模型是否真正理解图像。
1.2 VLM、MLLM 与 vLLM 的区别
| 名称 | 含义 | 关注重点 | 典型例子 |
|---|---|---|---|
| VLM | Vision-Language Model,视觉语言模型 | 图像或视频与文本之间的理解、对齐、生成 | CLIP、BLIP-2、LLaVA、Qwen-VL |
| MLLM | Multimodal Large Language Model,多模态大语言模型 | 以大语言模型为核心,接入图像、视频、音频、语音等多模态 | GPT-4o、Gemini、Qwen2.5-VL、InternVL |
| vLLM | 高性能推理服务框架,项目名本身不是 Vision-Language Model 的缩写 | PagedAttention、连续批处理、模型服务部署 | 用于部署 LLM 或部分多模态模型 |
VLM 与 MLLM 在当前语境中高度重叠。早期 VLM 不一定以大语言模型为核心,例如 CLIP 更偏图文表示学习,不怎么涉及推理生成;现代 VLM 通常使用 LLM 作为推理与生成核心,因此也常被归入 MLLM。
vLLM 不是视觉语言模型,而是推理引擎。它可以部署部分支持图像输入的多模态模型,但概念上不要把 VLM 和 vLLM 混为一类。
1.3 VLM 能解决什么问题
| 任务 | 输入 | 输出 | 说明 |
|---|---|---|---|
| 图文检索 | 文本查图像或图像查文本 | 相似度排序 | CLIP 类模型最典型应用 |
| 图像分类 | 图像 + 类别文本 | 类别 | 可通过文本提示实现零样本分类 |
| 图像描述 | 图像 | 描述文本 | 要求模型概括图像主体、属性、关系与场景 |
| 视觉问答 | 图像 + 问题 | 答案 | 要求模型根据问题读取视觉信息 |
| 文档理解 | 文档截图或 PDF(Portable Document Format)页面 + 问题 | 答案或结构化字段 | 需要 OCR(Optical Character Recognition)、版面理解、表格理解 |
| 视觉定位 | 图像 + 指代表达 | 边界框或区域 | 要求把语言实体对应到图像位置 |
| 多图理解 | 多张图 + 问题 | 比较或推理结果 | 常见于截图对比、流程分析、图表推理 |
| 视频理解 | 视频帧序列 + 问题 | 描述或答案 | 需要时间建模、事件识别与因果理解 |
1.4 为什么 VLM 很重要
现实世界的信息并不只以文本存在。医学影像、商品图片、监控画面、工业检测图、网页截图、论文图表、手写题目、票据表格都需要视觉理解。只会处理文本的 LLM(Large Language Model)无法直接读取这些信息,因此需要视觉编码器把像素、区域、文字版面和空间关系转成语言模型可用的表示。
VLM 的价值可以概括为三点。
- 把视觉信息接入语言推理系统。
- 让图像、文字、知识与推理能力统一到同一交互入口。
- 把传统 CV(Computer Vision)任务从固定类别、固定任务扩展到开放词表、自然语言指令和多轮对话。
2. 核心概念
2.1 模态
模态是信息的表现形式。图像、文本、视频、语音、音频、三维点云、传感器信号都可以视为模态。
VLM 主要处理视觉模态和语言模态。视觉模态负责提供“看到什么”,语言模态负责提供“如何提问、如何解释、如何推理、如何表达”。
2.2 视觉 token
视觉 token 是图像经过视觉编码器后得到的向量序列。以 ViT(Vision Transformer)为例,图像会被切成 patch,每个 patch 被映射成一个向量。
设图像大小为 H×W,patch 大小为 P×P,则视觉 token 数量近似为:
Nvision=HP×WP N_{\text{vision}}=\frac{H}{P}\times\frac{W}{P} Nvision=PH×PW
例如 336×336 图像使用 14×14 patch,则视觉 token 数量为 24×24=576。分辨率越高,视觉 token 越多,细节更丰富,但 Prefill 计算量、KV Cache 与显存占用也会明显增加。
2.3 图文对齐
图文对齐是让图像表示和文本表示在语义空间中建立对应关系。
例如一张猫的图片和文本“a photo of a cat”表面形式完全不同,但语义一致。好的 VLM 会让二者的向量更接近,让猫图片和“a photo of a car”这类错误文本距离更远。
CLIP(Contrastive Language-Image Pre-training)的核心训练目标就是图文对比学习:匹配的图像文本对相互靠近,不匹配的图像文本对相互远离。
2.4 多模态融合与连接器的关系
多模态融合是一个更抽象的问题:视觉信息和语言信息应该在什么位置、用什么方式发生交互。连接器是实现多模态融合的一类具体模块,尤其常见于“视觉编码器 + LLM”的现代 VLM 架构中。
二者可以按层次理解:
| 层次 | 关注问题 | 典型实现 | 代表模型 |
|---|---|---|---|
| 表征对齐 | 图像向量和文本向量怎样进入同一语义空间 | 双编码器相似度学习、对比学习 | CLIP、SigLIP |
| 信息筛选 | 视觉特征很多时,哪些视觉信息应该交给语言模型 | Q-Former、Perceiver Resampler、token pooling | BLIP-2、Flamingo |
| 特征接入 | 视觉特征怎样变成 LLM 可以读取的输入 token | Linear Projector、MLP(Multi-Layer Perceptron)Projector、Adapter | LLaVA、MiniGPT-4 |
| 深层交互 | 文本 token 怎样在生成过程中反复读取视觉特征 | Cross-Attention、Gated Cross-Attention | Flamingo、BLIP |
重点:多模态融合是目标,连接器是手段。
CLIP 主要在表征空间做融合,不需要把视觉 token 输入 LLM;LLaVA 通过 projector 把视觉 token 接入 LLM;BLIP-2 用 Q-Former 先筛选和压缩视觉信息,再交给 LLM。因此连接器不等于全部多模态融合,但它是现代生成式 VLM 中最关键的融合实现之一。
2.5 视觉幻觉
视觉幻觉是指模型生成与图像不一致的内容,例如把不存在的物体说成存在,把颜色、数量、位置或关系描述错误。
视觉幻觉常见原因包括图文训练数据偏差、语言模型先验过强、视觉 token 信息不足、细粒度定位能力弱、指令诱导模型过度推断。
3. VLM 的基本架构
现代 VLM 通常由三部分组成:视觉编码器、连接器、语言模型。
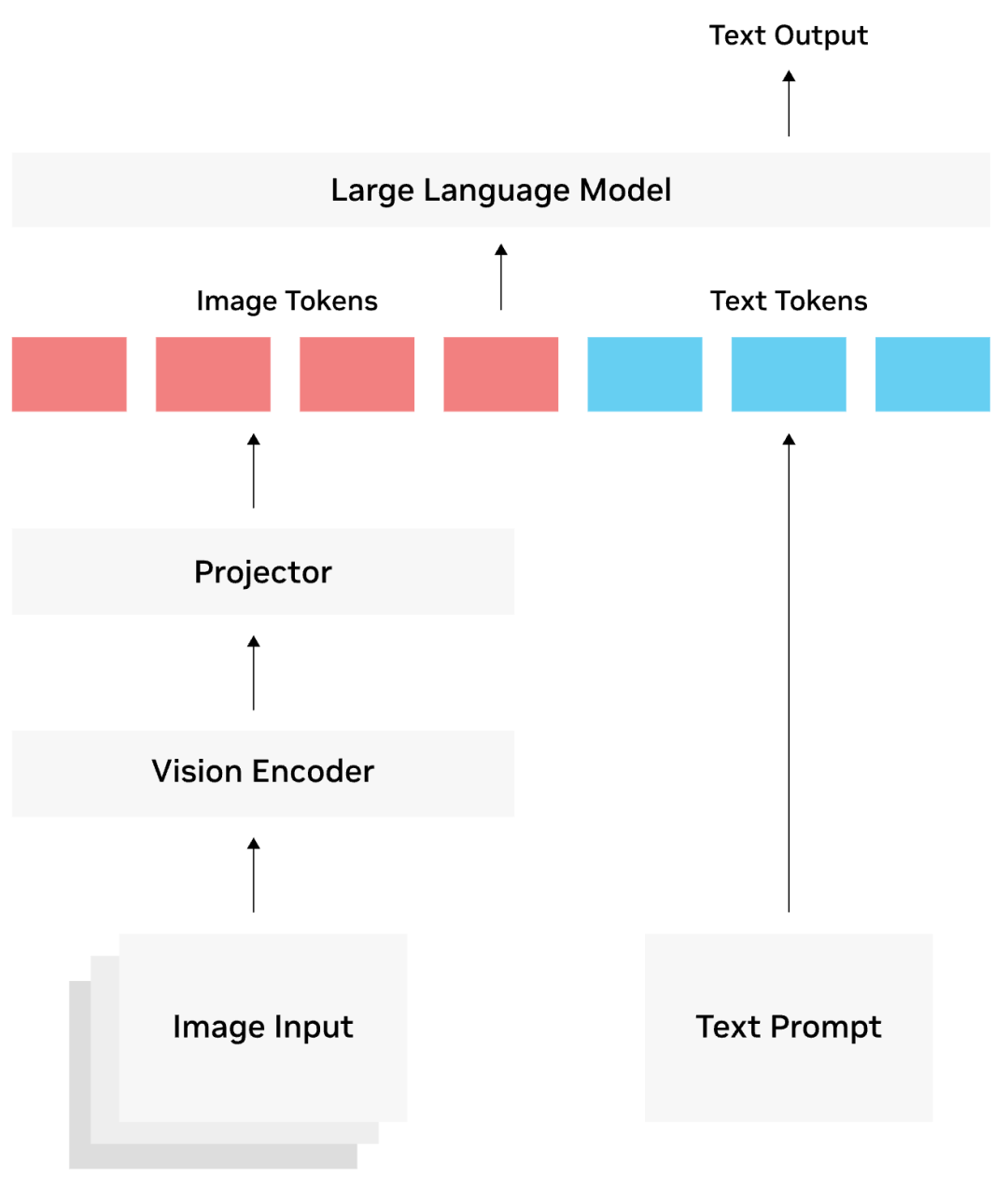
从数据流角度看,VLM 不是把图片“直接塞进”语言模型,而是先把图片转换成一串向量,再把这些向量改造成 LLM 可以处理的 token。完整过程如下。
原始图片
-> 图像预处理
-> 视觉编码器生成视觉特征
-> 连接器做维度映射、语义对齐或 token 压缩
-> 得到 LLM 可读的视觉 token
-> 与文本 token 拼接或通过 cross-attention 交互
-> LLM 基于图文上下文生成答案
重点:VLM 架构的本质是把像素空间的信息逐步变成语言模型可读、可注意力计算、可生成答案的 token 序列。
可以用一个具体例子理解。输入是一张猫坐在沙发上的图片,问题是“这只猫在哪里”。图像先被 resize 和 normalize,再被 ViT 切成 patch;每个 patch 变成一个视觉 token。连接器把这些视觉 token 投影到 LLM hidden size。最终 LLM 看到的是“若干视觉 token + 问题文本 token”,再通过注意力把“猫”“沙发”“在哪里”这些语言信息和图像局部区域对应起来,生成“猫在沙发上”。
3.1 视觉编码器
视觉编码器负责把图像从像素空间转换成向量空间。常见选择包括 ViT、CLIP ViT、EVA-CLIP、SigLIP、ConvNeXt 等。
以 ViT 类视觉编码器为例,具体实现通常分为四步。
- 切 patch:把图像切成固定大小的小块,例如 14×14 或 16×16。
- 线性投影:把每个 patch 的像素展开后映射成一个向量。
- 加入位置编码:告诉模型每个 patch 在图像中的空间位置。
- Transformer 编码:通过 self-attention 让不同 patch 之间交换信息,得到包含局部和全局语义的视觉 token。
视觉编码器输出一般有两种形式。
| 输出形式 | 含义 | 适合任务 |
|---|---|---|
| 全局向量 | 整张图的整体表示 | 图文检索、零样本分类 |
| token 序列 | 每个 patch 或区域的表示 | 视觉问答、定位、细粒度理解、文档理解 |
CLIP 类双编码器常使用全局向量(CLS,Classification Token)做相似度计算。LLaVA(Large Language and Vision Assistant)、Qwen-VL 这类生成式 VLM 通常需要视觉 token 序列,因为语言模型需要读取更细的视觉细节。
全局向量像“整张图的摘要”,适合判断图片整体和一句话是否匹配;token 序列像“图像局部证据清单”,适合回答具体问题,例如数量、位置、文字和局部属性。
3.2 连接器
连接器是 VLM 架构中的中间桥梁,负责把视觉编码器输出改造成语言模型可以使用的输入。它不是单独的任务模块,而是服务于“视觉信息接入语言模型”的结构模块。
连接器通常完成三件事。
- 维度映射:视觉编码器输出维度通常不同于 LLM hidden size,需要线性层或 MLP 投影到同一维度。
- 语义对齐:视觉特征来自图像编码器,LLM 习惯处理文本 token,连接器要让视觉 token 的分布更接近文本嵌入空间。
- 信息压缩:高分辨率图像会产生大量视觉 token,连接器可以筛选或压缩视觉信息,降低 LLM 输入长度。
| 连接器 | 代表模型 | 主要作用 | 适合场景 |
|---|---|---|---|
| Linear Projector | MiniGPT-4、早期 LLaVA | 做最简单的维度映射 | 结构验证、低成本训练 |
| MLP Projector | LLaVA 系列 | 增强非线性映射能力 | 通用图像问答、视觉对话 |
| Q-Former(Querying Transformer) | BLIP-2、InstructBLIP | 用少量 query 读取并压缩视觉信息 | 冻结视觉编码器与冻结 LLM 的桥接 |
| Perceiver Resampler | Flamingo | 把变长视觉特征压缩为固定数量 token | 图文交错、少样本提示 |
| Cross-Attention Adapter | Flamingo 类模型 | 让语言模型层间读取视觉特征 | 深层图文交互 |
连接器越简单,工程实现越直接;连接器越复杂,通常越能控制信息筛选和图文交互方式,但训练、调参和部署成本也更高。
连接器的原理可以按三类理解。
- Projector 型连接器:例如 Linear Projector 或 MLP Projector。它直接把每个视觉 token 从视觉编码器维度映射到 LLM hidden size。优点是简单,缺点是视觉 token 数不会减少。
- Query 型连接器:例如 Q-Former。它不是把所有视觉 token 都交给 LLM,而是用少量可学习 query 去“询问”视觉特征,从大量视觉 token 中抽取少量摘要 token。
- Cross-Attention 型连接器:例如 Flamingo 的 Gated Cross-Attention。视觉特征不一定直接拼入文本序列,而是在 LLM 生成过程中被 cross-attention 层读取。
重点:连接器决定了视觉信息以什么形态进入语言模型:逐 token 投影、query 摘要,或层间 cross-attention 读取。
3.3 语言模型
语言模型负责理解指令、组织推理过程并生成答案。常见基座包括 Llama、Mistral、Gemma、Qwen、InternLM 等。
在生成式 VLM 中,LLM 并不是只负责“润色文字”。它承担了问题理解、上下文整合、常识调用、逻辑推理和答案生成。视觉编码器提供视觉证据,LLM 决定如何使用这些证据回答问题。
3.4 输入序列组织
典型生成式 VLM 会把图像 token 和文本 token 拼成一个统一序列:
[系统提示] [用户文本前缀] [图像 token 序列] [用户问题] [回答起始标记]
语言模型看到的不是原始图片,而是一串被投影到 hidden size 的视觉 token。视觉 token 在注意力机制中与文本 token 一起参与上下文建模。
在常见“拼接式”VLM 中,LLM 的每一层 self-attention 都可以同时关注视觉 token 和文本 token。对于问题“猫在哪里”,问题中的“猫”可以关注图像中猫所在区域的视觉 token,“在哪里”可以关注位置关系相关的视觉 token,输出答案时再把这些视觉证据转成自然语言。
重点:现代 VLM 的关键工程问题之一是视觉 token 太多。
视觉 token 越多,细节越充分;但序列越长,Prefill 越慢,KV Cache 越大,显存越高。因此高分辨率、文档截图、多图输入和长视频理解都需要视觉 token 压缩或动态分辨率策略。
4. 训练范式与代表模型演进
VLM 的发展不是单一路线,而是从“图文表示对齐”逐步走向“视觉信息接入 LLM,再通过指令微调形成通用视觉对话能力”。训练范式和代表模型应放在同一条演进链路中理解。
4.1 训练范式总览
| 训练范式 | 目标 | 常见数据 | 代表模型 | 主要收益 | 主要局限 |
|---|---|---|---|---|---|
| 图文对比学习 | 让匹配图文对更接近,不匹配图文对更远 | 大规模图片和文本描述 | CLIP、SigLIP | 图文检索、零样本分类、开放词表识别强 | 不擅长长文本生成和复杂问答 |
| 图文匹配与图文生成 | 同时学习图文是否匹配,以及怎样根据图像生成文本 | caption 数据、图文对、合成描述 | BLIP | 兼顾理解和生成,提升 caption 质量 | 仍不是完整对话式 VLM |
| Query 桥接预训练 | 用少量 query 从视觉特征中抽取信息,再交给 LLM | 图文对、图像描述数据 | BLIP-2、InstructBLIP | 冻结大模型时也能低成本桥接视觉与语言 | query 数量会限制细节容量 |
| Cross-Attention 融合 | 让语言模型在生成过程中通过注意力读取视觉特征 | 图文交错序列、多图示例 | Flamingo | 支持少样本图文交错学习 | 结构复杂,训练成本高 |
| 多模态指令微调 | 让模型按照自然语言指令回答视觉问题 | 图像问答、多轮对话、GPT 合成数据 | LLaVA、Qwen-VL | 从图文模型变成视觉对话助手 | 依赖指令数据质量,可能产生视觉幻觉 |
| 偏好优化与安全对齐 | 让回答更符合人类偏好且忠实于图像证据 | 偏好对、拒答样本、安全样本 | 新一代 MLLM | 降低幻觉、格式错误和安全风险 | 多模态偏好标注成本高 |
4.2 CLIP:图文对齐的起点
4.2.1 核心思想
CLIP 的核心创新是使用自然语言作为视觉监督信号。传统图像分类依赖固定类别标签,CLIP 直接用大规模图文对训练图像编码器和文本编码器,让图像与文本进入同一个语义空间。

4.2.2 双编码器结构
CLIP 的结构是双编码器。图像编码器把图像映射为图像向量,文本编码器把文本映射为文本向量,然后通过相似度判断图文是否匹配。一个 batch 中有 N 个真实图文对时,可以得到 N×N 的相似度矩阵,对角线是正样本,其余位置是负样本由此可以构造自监督标签。
4.2.3 对比学习损失
图像到文本方向的对比损失可写为:
Li2t=−1N∑i=1Nlogexp(sim(Ii,Ti)/τ)∑j=1Nexp(sim(Ii,Tj)/τ) L_{\text{i2t}}= -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(\operatorname{sim}(I_i,T_i)/\tau)} {\sum_{j=1}^{N}\exp(\operatorname{sim}(I_i,T_j)/\tau)} Li2t=−N1i=1∑Nlog∑j=1Nexp(sim(Ii,Tj)/τ)exp(sim(Ii,Ti)/τ)
其中 Ii 表示第 i 张图的向量,Ti 表示匹配文本的向量,τ 是温度系数。文本到图像方向同理,最终通常取两个方向损失的平均。
4.2.4 零样本分类
CLIP 能做零样本分类,是因为类别可以被写成文本提示。例如把“猫”“狗”“汽车”写成 “a photo of a cat”“a photo of a dog”“a photo of a car”,再计算图像向量与各类别文本向量的相似度,相似度最高的类别就是预测结果。这类 zero-shot 流程不需要为每个下游类别重新训练分类头,而是把分类问题改写成图文匹配问题。

温度系数 τ 用来控制相似度 logits 的分布形状。τ 较大时,softmax 后的分布更平滑;τ 较小时,分布更尖锐,模型会更关注难负样本。温度系数过大容易削弱正负样本区分度,过小则可能让训练过度集中在少数难样本上。
4.2.5 特点总结
| 维度 | CLIP 的特点 |
|---|---|
| 训练目标 | 图文对比学习 |
| 架构形式 | 图像编码器 + 文本编码器 |
| 核心能力 | 图文检索、零样本分类、开放词表识别 |
| 创新意义 | 用自然语言监督替代固定类别监督 |
| 局限 | 输出主要是相似度,不适合直接做长推理和多轮对话 |
重点:CLIP 解决的是“图像和文本怎样对齐”,不是“怎样让模型围绕图片聊天”。
4.3 BLIP:理解与生成统一
4.3.1 核心思想
BLIP 的目标是同时提升图文理解和图文生成能力。它不是只判断图文相似,也不是只生成 caption,而是把图文对比、图文匹配和语言生成放入统一训练框架。
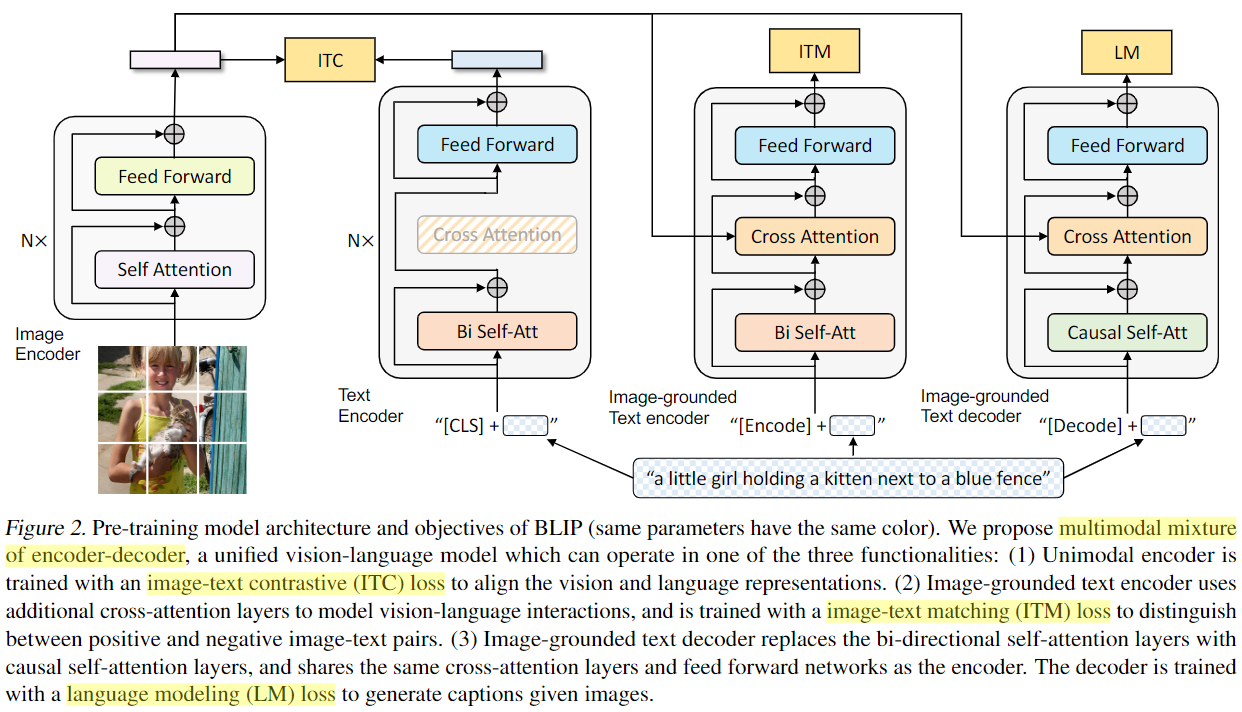
4.3.2 三种工作模式
BLIP 使用 Multimodal Mixture of Encoder-Decoder 思路,可以按任务切换为三种工作模式。
| 模式 | 使用模块 | 适合任务 | 核心作用 |
|---|---|---|---|
| 单模态编码 | Image Encoder、Text Encoder | 图文检索 | 分别提取图像和文本全局表示 |
| 图像引导文本编码 | Image Encoder、Image-grounded Text Encoder | 图文匹配、VQA 理解 | 通过 cross-attention 将图像特征注入文本表示 |
| 图像引导文本解码 | Image Encoder、Image-grounded Text Decoder | 图像描述生成 | 以图像为条件自回归生成文本 |
三种工作模式的具体原理如下。
**第一种:单模态编码模式。**图像和文本分别走各自的编码器。Image Encoder 输出图像全局向量,Text Encoder 输出文本全局向量,然后计算二者相似度。这种模式主要用于图文检索和图文对比学习。它的关键是“先各自理解,再在向量空间比较”。由于图像和文本没有在编码过程中深度交互,所以计算效率高,但细粒度关系判断能力有限。
图像 -> Image Encoder -> 图像全局向量
文本 -> Text Encoder -> 文本全局向量
图像全局向量 · 文本全局向量 -> 相似度
**第二种:图像引导文本编码模式。**图像先经过 Image Encoder 得到视觉 token,文本进入 Image-grounded Text Encoder。这个文本编码器不只是做文本 self-attention,还会通过 cross-attention 读取视觉 token。这样文本中的词可以对齐到图像区域,例如“红色杯子”会关注图像中杯子和颜色相关区域。这种模式主要用于 ITM 和 VQA 理解类任务。
图像 -> Image Encoder -> 视觉 token
文本 -> Text Encoder self-attention
文本 token -> cross-attention 读取视觉 token
输出图文融合后的文本表示 -> 匹配判断或问答理解
**第三种:图像引导文本解码模式。**图像仍先被编码为视觉 token,文本端改成 decoder。Decoder 使用 causal self-attention,只能看见已经生成的前文,同时通过 cross-attention 读取图像 token。它的任务不是判断图文是否匹配,而是一步一步生成描述文本。
图像 -> Image Encoder -> 视觉 token
已生成文本 token -> causal self-attention
文本 token -> cross-attention 读取视觉 token
预测下一个 token -> 继续生成 caption
**重点:BLIP 的三种模式共用视觉编码器,但文本侧会根据任务切换为“独立编码、图像引导编码、图像引导解码”。这就是 BLIP 同时适合理解任务和生成任务的原因。
4.3.3 三类损失函数
三种工作模式分别对应三类训练损失。
**第一类:Image-Text Contrastive Loss。**它对应单模态编码模式。图像和文本先分别编码成全局向量,再计算一个 batch 内所有图文组合的相似度矩阵。正确配对的图像和文本是正样本,batch 内其他图文组合是负样本。训练目标是让正样本相似度变高,让负样本相似度变低。
图像 I1、I2、I3 -> Image Encoder -> 图像向量 v1、v2、v3
文本 T1、T2、T3 -> Text Encoder -> 文本向量 t1、t2、t3
计算所有 v 和 t 的相似度矩阵
让 v1-t1、v2-t2、v3-t3 得分最高
这个损失训练的是“独立图像编码器”和“独立文本编码器”的对齐能力。它适合检索,因为推理时可以先离线存储图片向量,再用文本向量去做相似度搜索。
**第二类:Image-Text Matching Loss。**它对应图像引导文本编码模式。模型先用 Image Encoder 得到视觉 token,再让文本 token 通过 cross-attention 读取视觉 token,得到图文融合表示。然后在融合后的 [CLS] 表示上接一个二分类头,判断这对图文是否匹配。
图像 token + 文本 token
-> Image-grounded Text Encoder
-> 图文融合 [CLS] 表示
-> 二分类头
-> 匹配 / 不匹配
ITM 通常会配合 hard negative mining。原因是随机负样本太容易区分,例如猫图配汽车文本;难负样本更有训练价值,例如猫图配“狗趴在沙发上”。这类样本要求模型看清对象、属性和关系,而不是只判断大概语义。
**第三类:Language Modeling Loss。**它对应图像引导文本解码模式。模型根据图像 token 和已经生成的前文预测下一个 token。训练时给定真实 caption,decoder 每一步都预测下一个词,并用交叉熵损失衡量预测分布和真实 token 的差距。
图像 token + 已有文本:“一只 猫”
-> Decoder
-> 预测下一个 token:“坐”
-> 与真实下一个 token 对比
-> 计算交叉熵损失
因此,ITC 训练“图文全局对齐”,ITM 训练“图文细粒度匹配判断”,LM 训练“根据图像生成文本”。三者合在一起,才让 BLIP 同时具备检索、匹配和生成能力。
4.3.4 Caption Bootstrapping
BLIP 的一个关键思想是 caption bootstrapping,也就是“先用已有数据训练出初步模型,再反过来清洗和改写训练数据”。它针对的问题是:互联网图文对虽然规模很大,但噪声也很重。图片旁边的文字可能只是网页标题、广告语、文件名或上下文片段,并不一定准确描述图片内容。如果直接用这类图文对训练,模型会学到错误对齐关系。
BLIP 把这个问题拆成两个子模块。
- Captioner:负责根据图片重新生成 caption。它的作用不是判断原始文本是否正确,而是为图片生成一条更像“图像描述”的候选文本。
- Filter:负责判断“图片 + 文本”是否匹配。它既可以检查原始 caption,也可以检查 Captioner 生成的 synthetic caption。匹配度低的样本会被过滤掉。
完整流程可以理解为两条数据路径。
原始图片 + 原始 caption
-> Filter 判断是否匹配
-> 保留匹配样本,删除明显噪声样本
原始图片
-> Captioner 生成 synthetic caption
-> Filter 判断 synthetic caption 是否匹配图片
-> 保留高质量 synthetic caption
这样做的结果是,训练集不再只依赖互联网原始文本,而是同时包含两类更干净的数据:一类是通过过滤后保留下来的原始 caption,另一类是由 Captioner 生成并通过 Filter 检查的 synthetic caption。
重点:caption bootstrapping 的核心不是简单“生成新 caption”,而是用 Captioner 扩充描述,再用 Filter 控制质量,形成更可靠的图文监督信号。
从训练逻辑上看,BLIP 先在噪声图文数据和人工标注数据上训练基础模型;再把模型拆成 Captioner 和 Filter;随后用 Captioner 生成候选描述,用 Filter 筛选原始描述和生成描述;最后用清洗后的图文对继续训练。这个过程相当于让模型参与数据清洗,使大规模弱监督数据更接近高质量图文对。因此,BLIP 的 bootstrapping 仍需要一定规模的高质量人工标注数据作为启动监督,尤其用于基础模型训练和 Filter 的匹配判断能力学习。
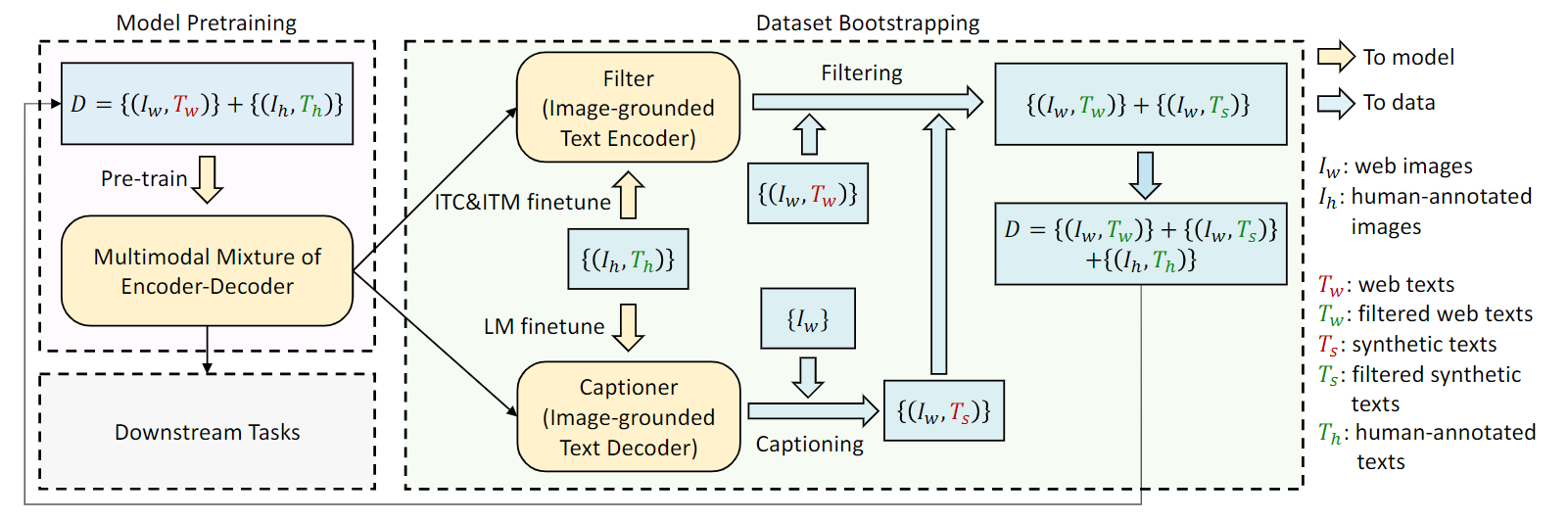
4.3.5 训练目标总结
BLIP 常见训练目标如下。
| 训练目标 | 作用 | 学到的能力 |
|---|---|---|
| Image-Text Contrastive | 拉近匹配图文,拉远不匹配图文 | 全局图文对齐和检索。训练两种编码器应该怎么输出特征向量 |
| Image-Text Matching | 判断图文是否真实匹配 | 细粒度关系判断,并可配合 hard negative mining 提升区分能力 |
| Language Modeling | 根据图像生成文本 | 图像描述和视觉到语言表达 |
BLIP 的创新在于把“理解”和“生成”合在一起训练。理解任务让模型知道图文是否对应,生成任务让模型学会把视觉内容组织成自然语言。
4.4 BLIP-2:冻结大模型下的低成本桥接
4.4.1 核心思想
BLIP-2 进一步解决训练成本问题。强视觉编码器和强语言模型已经分别具备能力,核心难点变成二者之间的桥接。BLIP-2 因此冻结视觉编码器和 LLM,只训练中间的 Q-Former。

4.4.2 Q-Former 结构
Q-Former 可以理解为“视觉信息提取器”。它包含一组可学习 query,这些 query 通过 cross-attention 从视觉编码器输出中读取信息,再把压缩后的视觉表示交给语言模型。
图像
-> 冻结视觉编码器
-> 图像 token
-> Q-Former 用少量 query 抽取视觉信息
-> 投影到 LLM 输入空间
-> 冻结 LLM 生成文本
Q-Former 内部可以分成 Image Transformer 和 Text Transformer 两个视角。Image Transformer 用可学习 query 与冻结图像特征做 cross-attention,提取与语言最相关的视觉信息;Text Transformer 既可作为文本编码器,也可作为文本解码器。二者共享 self-attention 层,因此 query token 和 text token 可以通过不同 attention mask 控制交互方式。
4.4.3 两阶段训练
BLIP-2 的两阶段训练逻辑如下。
| 阶段 | 训练目标 | 训练重点 |
|---|---|---|
| 第一阶段 | 从冻结视觉编码器中学习视觉语言表征 | 让 Q-Former 学会从图像 token 中提取与文本相关的信息 |
| 第二阶段 | 从冻结语言模型中学习视觉到语言生成 | 让 Q-Former 输出能被 LLM 理解的视觉提示 |
两个阶段的特征流不同。
**第一阶段:视觉语言表征学习。**图像先进入冻结 Image Encoder,得到图像 token;可学习 query 进入 Q-Former,并通过 cross-attention 读取图像 token;文本 caption 也进入 Q-Former 的文本侧。这个阶段不接 LLM,目标是让 Q-Former 学会“哪些视觉 token 与文本语义相关”。
图像 -> 冻结 Image Encoder -> 图像 token
可学习 query -> Q-Former Image Transformer -> 读取图像 token -> query 表示
文本 caption -> Q-Former Text Transformer -> 文本表示
query 表示 + 文本表示 -> ITC、ITM、ITG 训练目标
**第二阶段:视觉到语言生成学习。**图像仍先进入冻结 Image Encoder;query 仍由 Q-Former 读取图像 token,得到视觉摘要表示;然后这些 query embedding 会经过线性投影,变成与 LLM token embedding 维度一致的 soft visual prompts;最后把 soft visual prompts 放到文本 prompt 前面交给冻结 LLM 生成文本。
图像 -> 冻结 Image Encoder -> 图像 token
可学习 query -> Q-Former Image Transformer -> 读取图像 token -> query embedding
query embedding -> Linear Projection -> LLM 维度的 soft visual prompts
soft visual prompts + 文本 prompt -> 冻结 LLM -> 生成文本
**重点:第二阶段交给 LLM 的 query embedding 主要来自 Q-Former 的 Image Transformer 路径,也就是可学习 query 读取图像 token 后输出的视觉摘要。Text Transformer 主要负责训练阶段的文本编码或生成目标,不是最终交给 LLM 的视觉提示主体。
4.4.4 Attention Mask 机制
第一阶段常联合使用 ITC、ITM 和 ITG。这里“避免 query 与 text 提前互看”的意思是:在 ITC 这种全局对比任务中,query 表示应该只从图像侧得到信息,text 表示应该只从文本侧得到信息。如果二者在编码阶段已经通过 self-attention 互相看见,对比学习就会变成“已经交换答案后的匹配”,图像向量和文本向量不再是独立编码结果,检索式对齐目标会被破坏。
| 训练目标 | attention mask | query 与 text 是否互看 | 原因 |
|---|---|---|---|
| ITC | 单模态 mask | 不互看 | 保持图像表示和文本表示独立,才能做对比学习 |
| ITM | 双向 mask | 可以互看 | 需要细粒度判断图文是否匹配,允许充分交互 |
| ITG | causal mask | text 可以看 query 和前文,query 不看 text | 让 query 作为图像条件,引导文本自回归生成 |
因此,不是所有任务都禁止 query 与 text 互看,而是 ITC 禁止提前互看,ITM 需要互看,ITG 只允许按生成方向受控地看。
4.4.5 BLIP 与 BLIP-2 的 ITM 差异
原始 BLIP 和 BLIP-2 都有 ITM 任务,目标都是判断图文是否匹配,但结构并不相同。
原始 BLIP 的 ITM 使用 Image-grounded Text Encoder。图像先经过 Image Encoder 得到 image tokens,文本 token 进入文本编码器后,通过 cross-attention 读取 image tokens,得到图文融合后的文本表示。最后通常使用融合后的 [CLS] 表示接二分类头,判断 match 或 mismatch。
原始 BLIP 的 ITM:
图像 -> Image Encoder -> image tokens
文本 -> Text Encoder self-attention
文本 token -> cross-attention 读取 image tokens
图文融合 [CLS] 表示 -> 二分类头 -> match / mismatch
BLIP-2 的 ITM 发生在 Q-Former 内部。图像先经过冻结 Image Encoder 得到 image tokens;可学习 query 和 text token 拼在同一个 Q-Former 输入序列中;query 通过 cross-attention 读取 image tokens;query 和 text token 再通过双向 self-attention 交互。最后使用 query 输出接二分类头,得到图文匹配分数。
BLIP-2 Q-Former 的 ITM:
图像 -> 冻结 Image Encoder -> image tokens
[query tokens + text tokens] -> Q-Former
query tokens -> cross-attention 读取 image tokens
query tokens <-> text tokens 通过双向 self-attention 互看
query 输出 -> 二分类头 -> match / mismatch
这样做的意义是:query 先从冻结视觉特征里抽取候选视觉证据,text token 提供语义条件,两者在 self-attention 中互相校准。例如文本包含“红色杯子在桌子上”,query 读取图像中的颜色、杯子和桌面区域,text token 再与 query 交换信息,最终 query 表示中会包含“图像是否支持这句话”的证据。
| 对比项 | 原始 BLIP 的 ITM | BLIP-2 Q-Former 的 ITM |
|---|---|---|
| 图像输入 | Image Encoder 输出的 image tokens | 冻结 Image Encoder 输出的 image tokens |
| 图文交互主体 | text token 读取 image token | query token 读取 image token,并与 text token 交互 |
| 主要交互方式 | 文本侧 cross-attention 读取图像 | query-image cross-attention + query-text 双向 self-attention |
| 分类依据 | 图文融合后的文本 [CLS] 表示 |
query 输出后的匹配分数 |
| 训练目的 | 学细粒度图文匹配 | 训练 query 抽取与文本相关的视觉信息 |
**重点:BLIP 的 ITM 是“文本读图像后判断匹配”,BLIP-2 的 ITM 是“query 读图像并和文本交互后判断匹配”。二者目标相同,但 BLIP-2 多了 query 这个信息瓶颈,用来把冻结视觉编码器的输出压缩成少量可交给 LLM 的视觉提示。
4.4.6 推理与指令微调
第二阶段会把 Q-Former 输出的 query embedding 通过线性层投影到 LLM 的文本嵌入维度,再作为 soft visual prompts 放到文本输入前面。这样冻结 LLM 不需要直接理解原始视觉特征,而是读取已经被 Q-Former 压缩和对齐过的视觉提示。

在 VQA 或指令微调场景中,问题文本也可以输入 Q-Former,使 query 提取与问题更相关的视觉特征。这一点也影响了 InstructBLIP 的设计:指令不仅交给 LLM,也参与视觉特征抽取。
BLIP-2 的意义在于证明:不必端到端更新所有大模型参数,也可以通过中间桥接模块获得较强 VLM 能力。这一路线对资源有限的研究和应用非常重要。
4.5 Flamingo:图文交错与少样本学习
Flamingo 关注的是 few-shot 视觉语言学习。它允许输入中出现多组图文示例,再让模型按示例模式完成新任务。
Flamingo 的架构有三个关键点。
| 模块 | 作用 |
|---|---|
| Vision Encoder | 提取图像或视频特征 |
| Perceiver Resampler | 把可变长度视觉特征压缩为固定数量视觉 token |
| Gated Cross-Attention | 插入语言模型层间,让文本生成过程读取视觉信息 |
Flamingo 的重要创新是把视觉信息作为外部记忆供语言模型读取,而不是简单把所有视觉 token 拼到文本前面。这样可以支持图文交错输入,例如“示例图片 + 示例答案 + 新图片 + 新问题”。
4.6 LLaVA:视觉指令微调
LLaVA 把 VLM 推向视觉对话助手。它使用 CLIP 视觉编码器提取图像特征,通过 projector 映射到 LLM hidden size,再用多模态指令数据训练模型。
图像 -> CLIP Vision Encoder -> Projector -> 视觉 token
文本 -> Tokenizer -> 文本 token
视觉 token + 文本 token -> LLM -> 答案
LLaVA 的关键不是提出全新的视觉编码器,而是证明“视觉编码器 + 投影层 + LLM + 指令微调”可以形成有效的多模态对话能力。大量后续开源 VLM 都采用了类似结构。
多模态指令微调的价值体现在三个方面。
- 让模型理解自然语言任务要求,而不只是计算图文相似度。
- 让模型输出符合对话格式的答案。
- 让模型能够围绕图像进行描述、问答、比较和推理。
4.7 SigLIP、PaliGemma、Qwen2.5-VL 与 InternVL
SigLIP 是 CLIP 路线上的损失函数改进。它使用 pairwise sigmoid loss,而不是依赖 softmax 的全局归一化对比损失。这样可以降低对超大 batch 归一化的依赖,在不同 batch 设置下更容易扩展。
PaliGemma 使用 SigLIP 视觉编码器和 Gemma 语言模型,定位为开放、轻量、可迁移的 VLM 基座。它适合通过微调适配图像描述、视觉问答、检测、分割等任务。
Qwen2.5-VL 代表了更通用的视觉语言助手路线。它强调文档理解、视觉定位、视频理解、长上下文、多语言视觉任务和视觉 Agent 能力。与早期单图问答模型相比,这类模型更接近完整 MLLM。
InternVL3 强调原生多模态预训练。它不是简单在纯文本 LLM 后面外接视觉模块,而是在训练阶段同时利用多模态数据和纯文本语料,目标是减少后接式训练带来的对齐困难。
4.8 模型路线对比
| 模型 | 年份 | 主要路线 | 关键组件 | 核心贡献 |
|---|---|---|---|---|
| CLIP | 2021 | 双编码器对比学习 | 图像编码器、文本编码器 | 开放词表零样本视觉识别 |
| BLIP | 2022 | 理解与生成统一 | ITC、ITM、LM、caption bootstrapping | 同时提升图文理解和描述生成 |
| Flamingo | 2022 | 冻结 LM + 跨注意力 | Resampler、Gated Cross-Attention | 图文交错 few-shot 学习 |
| BLIP-2 | 2023 | 冻结视觉编码器和 LLM | Q-Former | 低成本桥接视觉与语言模型 |
| LLaVA | 2023 | Projector + 指令微调 | CLIP、MLP、LLM | 多模态对话与视觉指令微调 |
| SigLIP | 2023 | 对比学习损失改进 | Sigmoid loss | 提升图文预训练扩展性 |
| PaliGemma | 2024 | 开放 VLM 基座 | SigLIP、Gemma | 适合迁移的轻量 VLM |
| Qwen2.5-VL | 2025 | 通用视觉语言助手 | 动态视觉输入、LLM | 文档、定位、视频、Agent 能力 |
| InternVL3 | 2025 | 原生多模态预训练 | 统一训练、多模态数据 | 同时学习语言与多模态能力 |
5. VLM 与传统 CV 模型的区别
传统 CV 模型通常面向固定任务,例如分类、检测、分割。VLM 则更强调开放词表、语言指令和跨模态推理。
| 对比项 | 传统 CV 模型 | VLM |
|---|---|---|
| 输入 | 主要是图像 | 图像 + 文本指令 |
| 输出 | 类别、框、掩码等固定格式 | 文本、框、结构化结果、推理过程 |
| 类别空间 | 通常固定 | 可用自然语言扩展 |
| 任务形式 | 一个模型对应一个任务或少数任务 | 同一个模型可处理多种视觉语言任务 |
| 数据需求 | 依赖人工标注类别、框、掩码 | 可利用大规模图文对和指令数据 |
| 推理方式 | 主要是感知 | 感知 + 语言理解 + 常识推理 |
VLM 并不是替代所有传统 CV 模型。在高精度、低延迟、强约束场景中,检测模型和分割模型仍然重要。VLM 更适合作为开放式理解、交互式分析和通用视觉接口。
6. VLM 的推理逻辑
生成式 VLM 的推理过程可以看作“视觉编码 + 语言模型自回归生成”的组合。视觉侧负责把图像变成可计算的视觉 token,语言侧负责把视觉 token 和文本 token 放入同一个上下文中,再逐步生成答案。
重点:VLM 推理不是 LLM 直接读取图片,而是视觉编码器先把图片压缩成向量序列,再由 LLM 在注意力机制中读取这些视觉 token。
6.1 推理的基本原理
VLM 推理包含两条信息流。
- 视觉信息流:原始图像经过预处理、视觉编码器和连接器,变成 LLM 可以接收的视觉 token。
- 语言信息流:用户问题经过 tokenizer,变成文本 token。
两类 token 会被组织成统一上下文。对 LLM 来说,视觉 token 与文本 token 都是 hidden size 相同的向量,只是来源不同。后续推理依赖 Transformer 的注意力机制:文本 token 可以关注视觉 token,输出 token 也可以回看视觉证据。
6.2 图像预处理
图像首先会被 resize、crop、normalize,然后送入视觉编码器。不同模型对图像尺寸和切图方式要求不同。
图像预处理的意义不是简单改变尺寸,而是把真实图片变成视觉编码器训练时熟悉的输入分布。如果 resize 策略、归一化参数或切图方式与训练阶段不一致,模型可能出现识别退化、OCR 变差、定位偏移等问题。
常见策略包括固定分辨率、动态分辨率、多尺度切图和 high-resolution tiling。文档截图、长图、网页截图常需要切块处理,否则小字和细节容易丢失。多图输入和视频输入还需要控制帧数、图片数量和总 token 预算。
6.3 视觉编码
视觉编码器把图像转换成视觉 token。以 ViT 为例,图像经过 patch embedding 后形成 token 序列,再经过 Transformer Encoder 得到语义特征。
视觉编码器输出可以是全局向量,也可以是 patch token 序列。生成式 VLM 通常更依赖 token 序列,因为问答、OCR、定位和计数都需要局部细节。
视觉编码只在输入图像时执行一次。对于多轮对话,如果图像不变,工程系统可以缓存视觉特征或对应的 KV Cache,减少重复计算。
6.4 特征投影与序列融合
视觉 token 的维度通常和 LLM 的 hidden size 不一致,因此需要 projector 或 Q-Former 做映射。
映射后的视觉 token 会和文本 token 共同组成 LLM 输入序列。常见形式是:
<image_start> vision_token_1 ... vision_token_n <image_end>
用户问题 token
序列融合有两层含义:维度融合与上下文融合。第一层是维度融合,即视觉 token 被投影到 LLM 的 hidden size。第二层是上下文融合,即视觉 token 与文本 token 在同一个上下文窗口中参与注意力计算。
LLM 通过注意力机制同时读取视觉 token 和文本 token,再生成答案。若模型需要输出边界框、坐标或结构化字段,输出通常仍由文本 token 表达,例如 JSON、坐标字符串或特殊格式。
6.5 Prefill 阶段
Prefill 阶段负责一次性处理完整输入上下文,包括系统提示、用户问题和视觉 token。模型会为输入序列中的每个 token 计算 Key 和 Value,并写入 KV Cache。
Prefill 的本质是建立“模型已经看过的上下文”。对于 VLM,这个上下文不仅包含文字,还包含视觉 token。视觉 token 数越多,Prefill 需要处理的序列越长,首 token 延迟越高,KV Cache 占用越大。
TTFT 是 Time to First Token,表示从请求进入系统到生成第一个输出 token 的时间。VLM 的 TTFT 常由图像预处理、视觉编码、视觉 token 数量和 LLM Prefill 共同决定。
6.6 Decode 阶段
Decode 阶段逐 token 生成答案。每生成一个新 token,模型都会把该 token 的 K 和 V 追加到 KV Cache 中,然后继续预测下一个 token。
Decode 阶段不再重复编码整张图片,而是基于 Prefill 生成的 KV Cache 继续自回归生成。因此,Decode 的主要瓶颈通常是输出长度、模型规模、batch 策略和 KV Cache 管理。
TPOT 是 Time Per Output Token,表示平均生成每个输出 token 的时间。交互式 VLM 系统通常同时关注 TTFT 和 TPOT:TTFT 决定“多久开始回答”,TPOT 决定“回答速度是否流畅”。
6.7 推理方式的意义
这种推理方式的意义在于复用 LLM 已有的语言理解、推理和生成能力。视觉编码器提供图像证据,连接器完成跨模态接入,LLM 负责把视觉证据转化为自然语言答案或结构化结果。
同时,这种方式也带来代价。图像越清晰、切图越多、视频帧越密,视觉 token 越多,Prefill 和显存压力越大。因此 VLM 工程优化往往围绕视觉 token 数量、分辨率策略、KV Cache 和 batch 调度展开。
6.8 推理流程小结
| 阶段 | 输入 | 输出 | 主要瓶颈 |
|---|---|---|---|
| 图像预处理 | 原始图片 | 标准化图片张量 | CPU 预处理、切图、IO |
| 视觉编码 | 图片张量 | 视觉 token | 视觉编码器计算 |
| 特征投影 | 视觉 token | LLM 可读视觉 token | projector 或 Q-Former |
| Prefill | 视觉 token + 文本 token | 初始 KV Cache | 输入序列长度、显存 |
| Decode | 上一步 token + KV Cache | 新 token | 输出长度、并发调度 |
7. VLM 的推理优化
VLM 的推理优化目标通常是降低延迟、提高吞吐量、减少显存占用,并在质量下降可控的前提下降低成本。
7.1 KV Cache 优化
KV Cache 是自回归生成中的关键缓存。没有 KV Cache 时,每生成一个新 token 都要重复计算全部历史 token 的注意力表示;有了 KV Cache 后,只需要追加新 token 的 K 和 V。VLM 的特殊问题是视觉 token 会占用大量 KV Cache。高分辨率图像、多图输入和长文档会让输入序列迅速变长。
PagedAttention 把 KV Cache 按块管理,类似操作系统的分页思想,可以减少显存碎片,提高批处理容量。vLLM 的核心贡献之一就是 PagedAttention 与连续批处理。
7.2 视觉 token 压缩
视觉 token 压缩直接影响 VLM 的效率。
| 方法 | 思路 | 优点 | 风险 |
|---|---|---|---|
| Token pruning | 删除低重要性视觉 token | 降低输入长度 | 可能丢失关键小目标 |
| Token merging | 合并相似视觉 token | 保留整体语义 | 细粒度定位可能变差 |
| Query 压缩 | 用少量 query 读取视觉特征 | 长度固定,成本可控 | query 容量有限 |
| 动态分辨率 | 按图片内容和任务分配分辨率 | 保留重要细节 | 实现复杂 |
| 切图与局部放大 | 对高分辨率图像分块编码 | 适合文档和小字 | token 数可能增加 |
7.3 Continuous Batching
连续批处理允许请求动态进入和退出 batch。相比静态 batch,它可以减少 GPU 等待,提高吞吐。
VLM 服务中,不同请求的图像数量、视觉 token 数和输出长度差异很大,连续批处理更重要。否则一个长输出或多图请求可能拖慢整个 batch。
7.4 量化
量化是把模型权重或激活从高精度变成低精度,例如 FP16 降到 INT8 或 INT4。它可以降低显存占用,提高部署可行性。量化对 VLM 的影响需要分模块看。
| 模块 | 量化影响 |
|---|---|
| LLM | 通常收益最大,显存下降明显 |
| 视觉编码器 | 对细粒度视觉理解可能更敏感 |
| Projector | 参数量较小,收益有限 |
| KV Cache | KV Cache 量化可降低长上下文显存,但要关注输出质量 |
7.5 并行策略
当单张 GPU 无法承载模型时,可以使用张量并行、流水线并行或数据并行。张量并行把同一层的矩阵计算拆到多张 GPU。流水线并行把不同层放在不同 GPU。数据并行适合多个副本处理不同请求。
VLM 还要额外考虑视觉编码器与 LLM 的分配。小模型可以把视觉编码器和 LLM 放在同一张 GPU;大模型或高并发服务可以把视觉侧和语言侧拆开。
7.6 vLLM 与 VLM 部署
vLLM 作为高性能推理服务框架,它的价值在于高效管理 KV Cache、批处理和服务接口。
部署 VLM 时需要确认模型是否被推理框架完整支持,包括图像输入格式、chat template、processor、视觉编码器、projector、动态分辨率、最大图片数和多图输入。部署检查重点如下。
- 模型 processor 是否能正确处理图片和文本。
- chat template 是否与训练格式一致。
- 最大上下文长度是否能容纳视觉 token。
- 多图输入是否真正被模型和框架支持。
- 流式输出、并发请求和错误处理是否稳定。
- 量化后是否保留 OCR、计数、定位等关键能力。
8. VLM 的评测体系
VLM 评测不能只看回答是否流畅。关键是回答是否忠实于图像,是否能处理细节、空间关系、文字、图表、数学推理和多轮指令。
8.1 常见能力维度
| 能力 | 评测关注点 | 示例 |
|---|---|---|
| 物体识别 | 能否识别主体和类别 | 图中有哪些物体 |
| 属性识别 | 颜色、材质、大小、状态 | 车是什么颜色 |
| 计数 | 数量是否准确 | 图中有几个人 |
| 空间关系 | 上下左右、遮挡、远近 | 杯子在书的哪边 |
| OCR | 能否读出图中文字 | 标牌上写了什么 |
| 文档理解 | 版面、表格、字段、阅读顺序 | 发票金额是多少 |
| 图表理解 | 坐标轴、趋势、数值比较 | 哪一年增长最快 |
| 视觉推理 | 结合图像和常识推理 | 为什么这个人需要雨伞 |
| 幻觉控制 | 是否编造不存在内容 | 图片里有没有狗 |
| 指令遵循 | 是否按格式和约束回答 | 用 JSON 输出字段 |
8.2 常见评测基准
| 基准 | 关注能力 | 说明 |
|---|---|---|
| VQAv2 | 视觉问答 | 经典 VQA 数据集,关注常见图像问答 |
| GQA | 场景图与组合推理 | 强调对象、属性、关系和组合问题 |
| TextVQA | 图片文字问答 | 强调 OCR 和文字场景理解 |
| DocVQA | 文档问答 | 强调文档图片、表格和版面理解 |
| MMBench | 多维度多模态能力 | 使用选择题评估感知和推理能力 |
| MME | 感知与认知评估 | 覆盖物体、属性、关系、OCR、常识等 |
| MMMU | 专家级多学科理解 | 覆盖科学、工程、艺术、商业等学科 |
| MathVista | 视觉数学推理 | 强调图表、几何、数学与视觉结合 |
| POPE | 幻觉检测 | 通过对象存在性问题衡量幻觉 |
| SEED-Bench | 多模态综合评测 | 覆盖图像和视频理解能力 |
8.3 自动指标与人工评估
自动指标适合答案固定的任务,例如选择题、OCR 字段抽取、计数和 yes/no 问题。常见指标包括 Accuracy、Exact Match、F1、CIDEr、BLEU、ROUGE 等。
开放式回答更难评估。常见做法是 LLM-as-Judge,让更强模型作为裁判比较答案质量。但该方法也可能受裁判模型偏见、提示词格式和标准答案质量影响,因此重要评测仍需要人工抽样复核。
9. VLM 的主要挑战
9.1 视觉幻觉
视觉幻觉是 VLM 当前最重要的问题之一。模型可能描述不存在的物体,错误判断数量,错误读取文字,或者根据语言先验补全图像中没有的信息。
减少幻觉的常见方法包括更高质量图文数据、更强视觉编码器、细粒度监督、负样本训练、对象存在性评测、检索增强和偏好优化。
9.2 细粒度理解不足
VLM 对大物体和常见场景通常表现较好,但对小字、小物体、密集目标、复杂纹理、局部遮挡和细微差异常不稳定。
细粒度理解需要更高输入分辨率、更好的图像切块策略、更强局部注意力机制和更高质量细粒度标注。
9.3 空间关系与计数困难
空间关系和计数是 VLM 的常见短板。例如“左边第二个杯子”“三个人中谁戴帽子”“图中有几辆白色车”这类问题容易出错。
原因在于视觉 token 通常是压缩表示,语言模型又容易依赖语义先验。准确计数和定位需要模型保留局部区域信息,并在推理时进行更严格的视觉证据绑定。
9.4 OCR 与文档版面困难
文档截图包含大量小字、表格线、标题层级和阅读顺序。普通图像编码器未必擅长 OCR,压缩视觉 token 后也容易丢失文字。
优秀文档 VLM 通常需要高分辨率输入、专门的 OCR 数据、版面数据、表格数据和文档指令微调。
9.5 视频理解成本高
视频可以看作大量图像帧加时间关系。帧越多,视觉 token 越多,计算和显存成本越高。
视频 VLM 还要理解动作、事件顺序、因果关系和长时间依赖。只抽少量帧可能漏掉关键信息,抽太多帧又会超出上下文和显存预算。
9.6 数据质量与版权问题
VLM 依赖大规模图文数据。互联网图文对可能包含错误描述、偏见、隐私信息、版权内容和低质量 OCR。
数据质量会直接影响模型是否学会错误关联。例如某些职业、性别、地域或场景偏见可能被模型继承甚至放大。
9.7 评测不稳定
VLM 的开放式输出让评测更难。不同 prompt、不同图像分辨率、不同 answer parser 都会影响分数。某些评测集还可能被训练语料污染。
比较 VLM 时不能只看单一排行榜分数,应同时看任务类型、输入设置、模型规模、推理成本和实际业务样本表现。
10. 参考资料
- 给定本地笔记:【万字长文】一文搞懂 VLM 视觉语言模型:从原理到实践的完整指南(2025)_vlm模型-CSDN博客.html
- 本地下载材料:/Users/mac/Downloads/主流VLM原理深入刨析(CLIP,BLIP,BLIP2,Flamingo,LLaVA,MiniCPT,InstructBLIP,mPLUG-owl)-CSDN博客.html
- 本地下载材料:/Users/mac/Downloads/AIGC系列-CLIP论文阅读笔记 - 知乎.html
- CLIP:Learning Transferable Visual Models From Natural Language Supervision,https://arxiv.org/abs/2103.00020
- CLIP 中文参考材料:https://zhuanlan.zhihu.com/p/632785126
- BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation,https://arxiv.org/abs/2201.12086
- BLIP 中文参考材料:https://blog.csdn.net/weixin_54338498/article/details/135258723
- Flamingo:A Visual Language Model for Few-Shot Learning,https://arxiv.org/abs/2204.14198
- BLIP-2:Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,https://arxiv.org/abs/2301.12597
- LLaVA:Visual Instruction Tuning,https://arxiv.org/abs/2304.08485
- SigLIP:Sigmoid Loss for Language Image Pre-Training,https://arxiv.org/abs/2303.15343
- PaliGemma:A versatile 3B VLM for transfer,https://arxiv.org/abs/2407.07726
- Qwen2.5-VL Technical Report,https://arxiv.org/abs/2502.13923
- InternVL3:Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models,https://arxiv.org/abs/2504.10479
- MMBench:Is Your Multi-modal Model an All-around Player,https://arxiv.org/abs/2307.06281
- MME:A Comprehensive Evaluation Benchmark for Multimodal Large Language Models,https://arxiv.org/abs/2306.13394
- MMMU:A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark,https://arxiv.org/abs/2311.16502
- POPE:Evaluating Object Hallucination in Large Vision-Language Models,https://arxiv.org/abs/2305.10355
- vLLM 官方文档:多模态输入与模型服务相关说明,https://docs.vllm.ai/en/latest/features/multimodal_inputs/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)