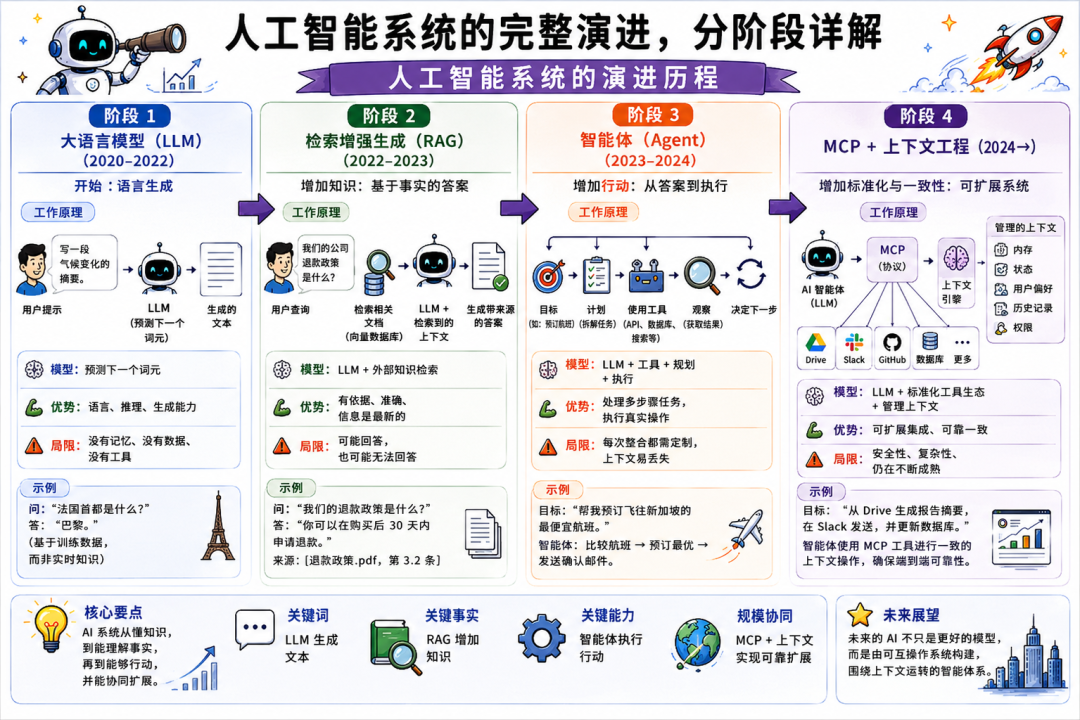
LLM、RAG、智能体、MCP:你必须了解的人工智能演进
本文深入剖析了AI技术从LLM到MCP的演进历程,揭示了现代AI系统并非简单的聊天机器人,而是具备浏览网页、执行代码、调用API等复杂能力的综合架构。文章详细阐述了LLM的局限性,以及RAG、Agent和MCP如何逐步解决这些问题,构建起完整的AI应用生态。核心观点在于,AI产品的成功并非取决于模型本身,而是取决于围绕模型构建的系统设计能力,包括记忆、检索、工具协同和上下文管理等。未来AI的发展将更加注重系统层面的创新,而非单纯追求模型智能的提升。
很多人以为 AI 只是一个聊天机器人。
这个想法已经过时了。
现代 AI 系统可以浏览网页、记住你的偏好、执行代码、查询数据库、调用 API、编排工作流,甚至像“软件员工”一样运转。
从“一个提示框连着 ChatGPT”跃迁到这一整套能力,并不是因为模型突然变得更聪明了,而是因为架构变了。
现代 AI 技术栈里的每一层,都是因为上一层在关键场景里“失败过”才出现的。理解每次演进背后的原因,是最快掌握当今严肃 AI 产品工作方式的路径。
这就是这段演进史。
我会用更直观、深入的方式,讲清 AI 的每个阶段:从 LLM 到 MCP。
LLM 时代
从零理解 LLM 是什么
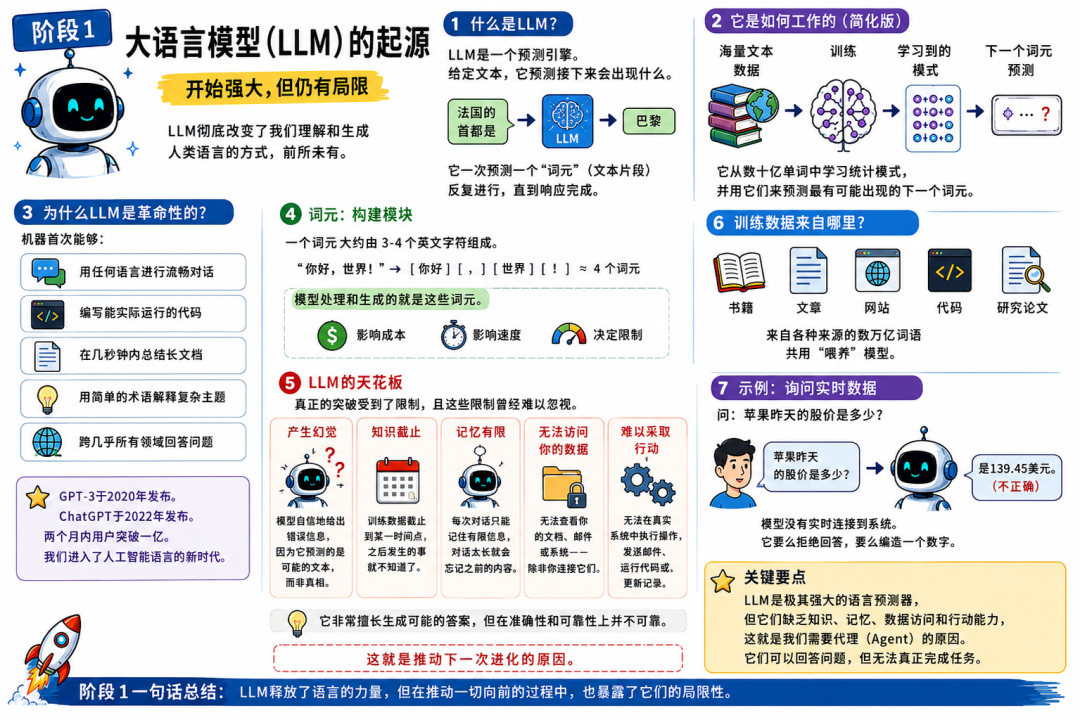
LLM(大语言模型)本质上是一个预测引擎。
不是推理引擎,不是数据库,也不是搜索系统。
给它一段文本,它做的事情是:预测下一段最可能出现的内容。这个预测会一遍又一遍地发生——按 token(词元)逐个生成——直到完成整段回答。
模型通过海量人类文本学习统计规律:书籍、文章、代码、论文、网页内容等。
示例:
输入: “法国的首都是”模型: [预测下一个 token]输出: “巴黎”
概念很简单,真正惊人的是规模。
token 大约相当于 3–4 个英文字符(中文的 token 切分方式不同,但同样存在“按 token 计费/限长”的约束)。比如 “Hello, world!” 大概是 4 个 token。模型处理和生成的一切都以 token 为单位计量,这直接影响成本、速度以及后面要讲的各种限制。
为什么 LLM 让人觉得革命性
人们第一次看到机器能做到:
- • 用几乎任何语言流畅对话
- • 写出真的能运行的代码
- • 几秒钟总结 50 页文档
- • 用通俗方式解释复杂概念
- • 在几乎任何领域回答问题
纯 LLM 很快撞到的天花板
当人们开始做“真正的产品”,这些限制立刻变得无法忽视。
纯 LLM 的核心问题:
- • 幻觉(Hallucination):模型会自信地输出错误信息,因为它预测“看起来合理”的内容,而不是“真实”的内容
- • 知识截止(Knowledge Cutoff):训练数据有日期;问最近发生的事,它只能猜
- • 没有记忆:每次对话都像从零开始;昨天聊过的事,今天就像没发生
- • 无法访问你的数据:公司文档、数据库、内部系统——模型天然不知道
- • 无法行动:它只产出文本,不能发邮件、跑查询、更新记录
比如你问一个纯 LLM:“苹果公司昨天的股价是多少?”它要么拒绝,要么编一个数字。
它并不连接实时系统。它是一个极其聪明的自动补全引擎,但自动补全并不能经营一家企业。
于是下一次演进出现了。
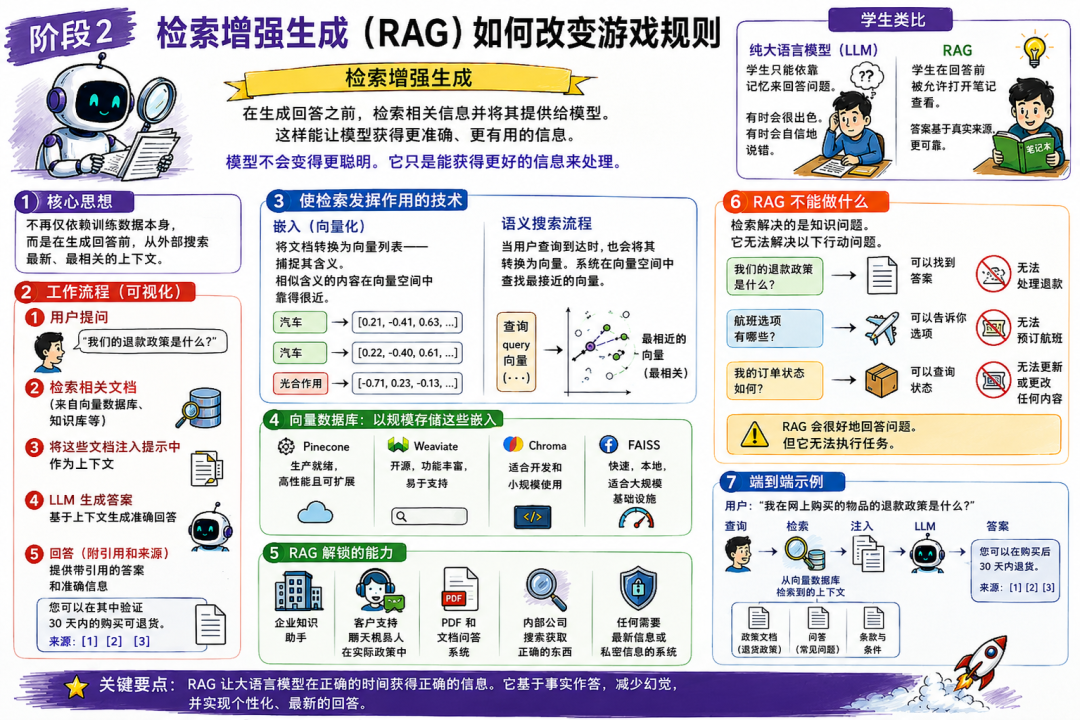
RAG 改变游戏规则
核心思想
RAG 是 Retrieval-Augmented Generation(检索增强生成)。一句话概括:
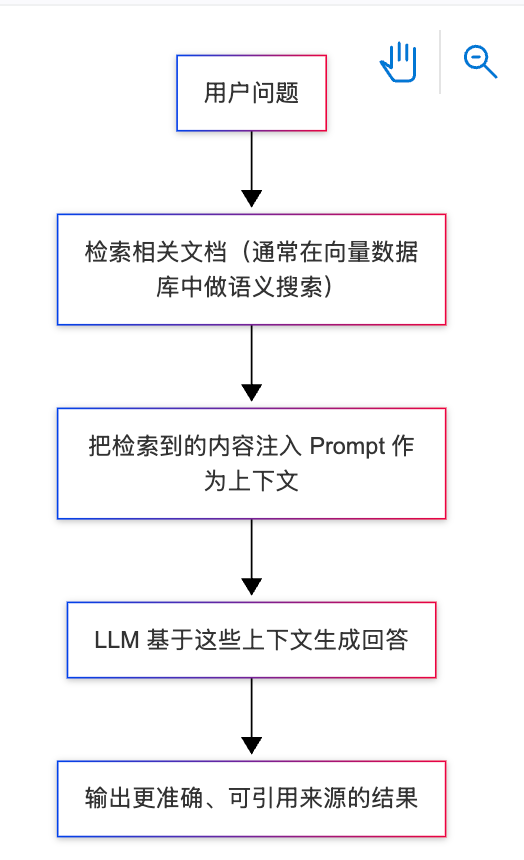
在生成回答之前,先把相关信息检索出来,再交给模型。
系统不再只依赖训练数据,而是在每次提问时动态获取最新、最相关的上下文。
学生类比
可以这样理解:
纯 LLM:像学生只靠记忆答题。有时很惊艳,有时自信地写错。RAG:像学生答题前可以先翻笔记。答案被真实资料“锚定”。
模型不一定更聪明,但它拿到了更好的信息。
RAG 的工作流程
检索能成立的技术基础:Embedding
Embedding 让“语义搜索”成为可能。
文档会被转换成向量(数字列表),在向量空间里表达“含义”。语义相近的内容在空间中更接近:比如 “car” 和 “automobile” 会靠近;“car” 和 “photosynthesis” 会很远。
用户问题同样会被向量化,然后去找最接近的文档向量,把最相关内容检索出来并注入上下文。
常见向量数据库:
- • Pinecone —— 托管型,生产可用
- • Weaviate —— 开源,查询能力强
- • Chroma —— 适合开发与小规模场景
- • FAISS —— 本地高速,偏基础设施组件
RAG 解锁了什么
RAG 成为严肃 AI 产品的底座:
- • 企业知识库助手
- • 基于真实政策的客服机器人
- • PDF / 文档问答系统
- • 更“像人”的内部搜索
- • 一切需要“最新”或“私有”信息的应用
RAG 仍然做不到的事
检索解决的是“知识”问题,但解决不了“行动”问题。
RAG 能回答“退款政策是什么”,但不能真正帮你处理退款;能告诉你航班选择,但不能替你订票。
要完成“执行任务”,需要完全不同的能力:Agent(智能体)。
AI Agent 的崛起
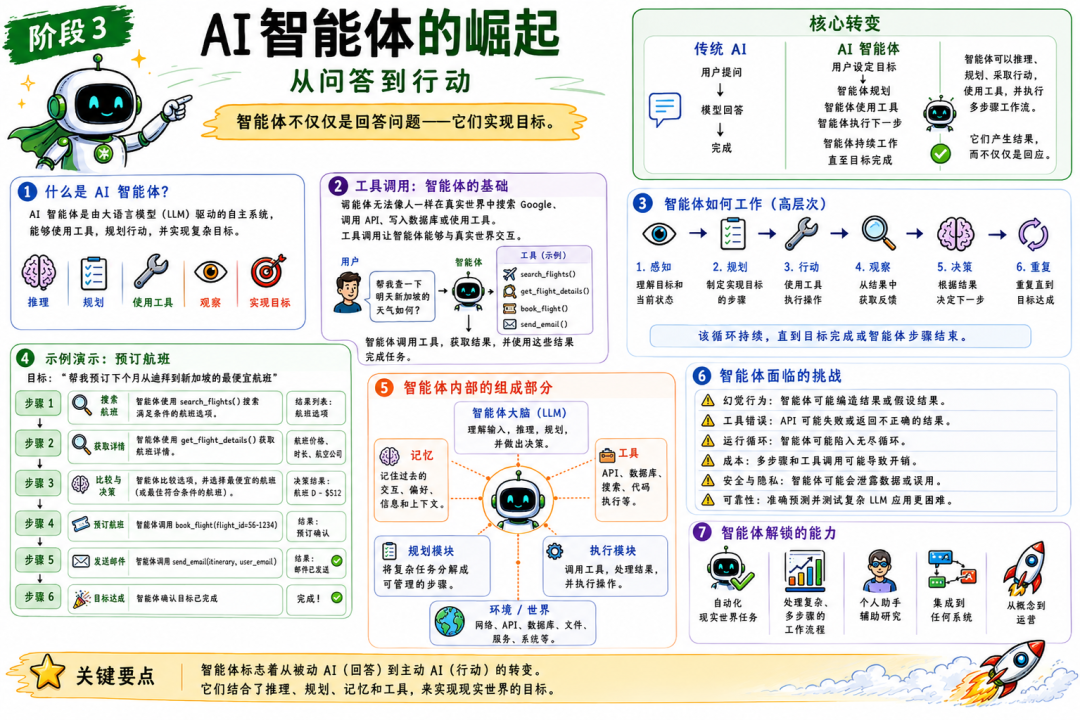
从“回答”到“执行”的转变
Agent 引入的变化简单但深刻:
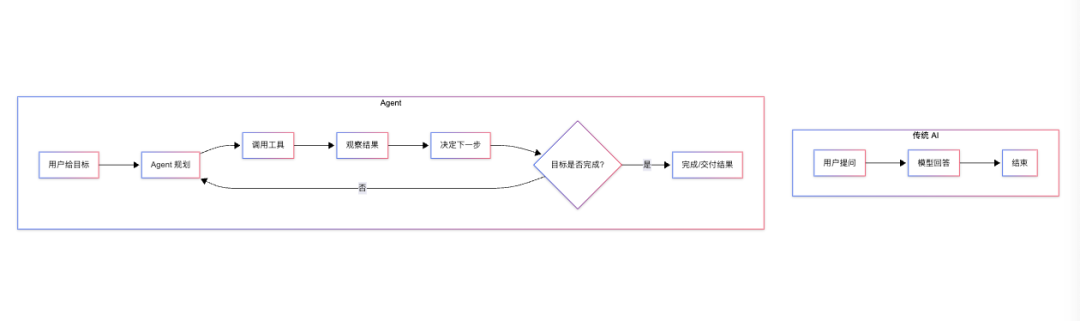
Agent 可以规划、使用工具、执行多步流程,不只是“说”,而是“做”。
Tool Calling:智能体的地基
LLM 本身不会搜索网页、调用 API、写数据库、运行代码。工具调用把模型“接入现实世界”。
用户:“帮我找下个月从北京到三亚最便宜的机票”步骤 1:调用航班搜索 API(携带参数)步骤 2:接收返回结果步骤 3:排序与对比步骤 4:总结最便宜的三种方案
关键在于:模型要能决定调用哪个工具、传什么参数、拿到结果后怎么继续推进。
Agent 能做什么
一个强的 Agent 可以:
- • 浏览网站并抽取信息
- • 编写、执行、调试代码
- • 发送邮件和消息
- • 查询与更新数据库
- • 解析文件与文档
- • 在有权限/凭证的前提下调用任意 API
- • 和其他 Agent 协作
- • 安排并管理工作流
让 Agent 走向实用的框架
从零搭 Agent 很难,框架解决了大量样板工程:
- • LangChain / LangGraph —— 最常用,图式编排
- • AutoGen —— 多 Agent 对话协作
- • CrewAI —— 角色分工的“团队式”工作流
- • OpenAI Agents SDK —— 原生工具调用与编排支持
Agent 仍然会在哪些地方有问题
能力更强,失败模式也更多:
- • 上下文溢出:运行太久,context window 被塞满,早期指令被“遗忘”,准确性下降
- • 记忆碎片化:没有统一的记忆系统,就会丢失任务主线
- • 工具混乱:工具太多时,模型选错或用错
- • 幻觉式行动:编造“已调用工具的结果”,但实际没调用
- • 失控循环:没有停止条件时一直跑,应该澄清却不问
更深层的问题是:每个工具的接入都是定制化的。接 Slack 要做一套,接 Google Drive 又一套,接 Salesforce 再来一套。没有标准就难以规模化。
这就是 MCP 出现的原因。
MCP —— 标准化连接的一次跃迁
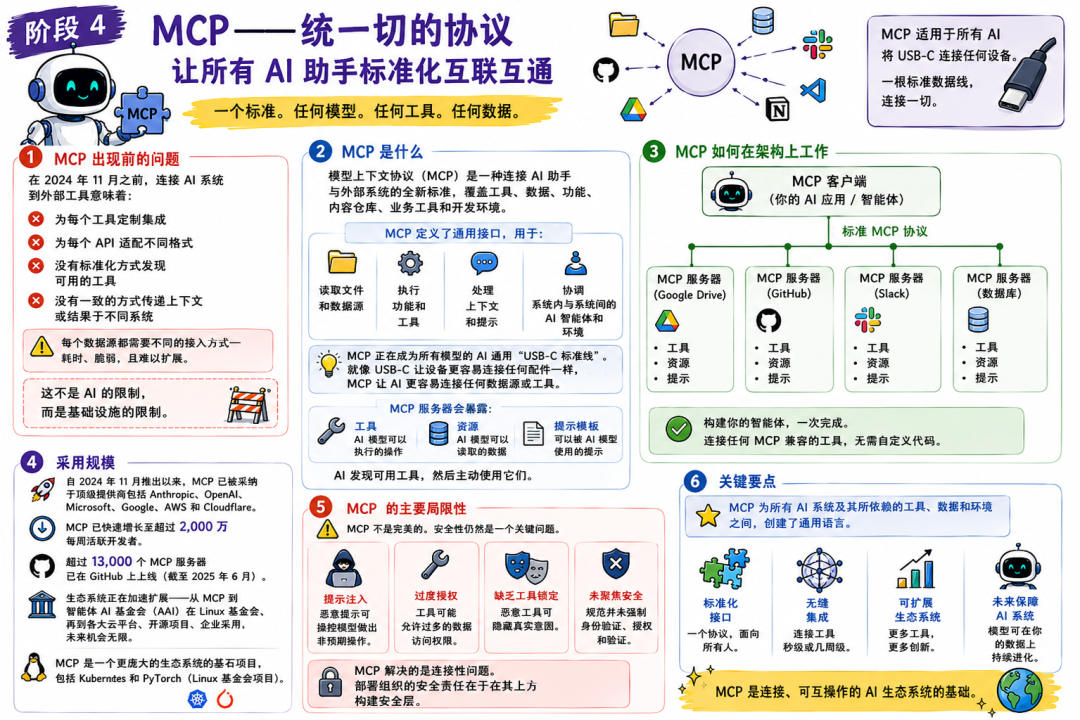
MCP 之前的问题
在 2024 年 11 月之前,把 AI 接到外部系统通常意味着:
- • 每个工具都要单独写集成
- • 每个 API 的格式和约定都不同
- • 模型无法标准化“发现有哪些工具可用”
- • 不同系统之间缺少一致的上下文/结果传递方式
这不是 AI 的问题,而是基础设施的问题。
MCP 是什么
MCP(Model Context Protocol,模型上下文协议)是一种新标准,用来把 AI 助手连接到数据和工具所在的系统:内容库、业务系统、开发环境等。
Anthropic 于 2024 年 11 月发布并立即开源。MCP 定义了通用接口,用于:
- • 读取文件与数据源
- • 执行函数与工具
- • 处理上下文与提示词(prompts)
- • 在模型与外部环境间协调交互
一个直观比喻:MCP 对 AI 模型的意义,类似 USB-C 对设备连接的意义——统一接口,让“接什么都更容易”。
MCP 的架构是怎么工作的
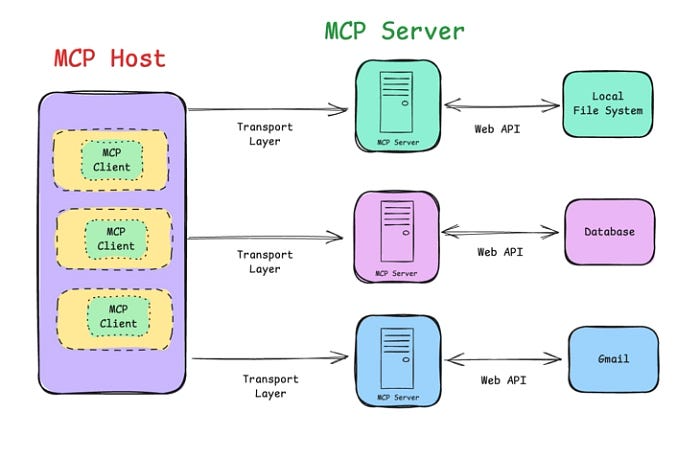
MCP Server 会暴露三类能力:
- • tools:模型可调用的动作
- • resources:模型可读取的数据
- • prompts:可复用的交互模板
模型先向 server 查询“有哪些能力”,再用结构化、可校验的格式发起调用。
采用速度与规模
MCP 的传播不是缓慢的学术标准推进,而是快速工程化扩散:
- • 主要模型提供商(OpenAI、Microsoft、Google、Cloudflare 等)都已采用
- • Python 与 JavaScript SDK 的每周下载量超过 2000 万
- • 仅 2025 年,就有超过 13,000 个 MCP server 在 GitHub 上发布
- • 2025 年 12 月,Anthropic 将 MCP 捐赠给 Linux Foundation 旗下的 Agentic AI Foundation(AAIF),由 Anthropic、Block、OpenAI 等共同发起,并获得 Google、Microsoft、AWS、Cloudflare 等支持
MCP 已不再是 Anthropic 的单一项目,而是进入类似 Kubernetes、PyTorch 那样的基金会生态。
MCP 的诚实限制
MCP 并不完美,尤其是安全问题。
安全研究者指出过多类风险:提示注入、工具权限导致的数据外泄、以及“长得很像的工具”可能悄悄替换可信工具等。
MCP 的优先目标是简单、易集成,而不是强制的认证、加密、审计、沙箱与验证。
MCP 解决的是“连接问题”。企业要大规模落地,必须自己把安全层补上。
Context Engineering:把一切真正连起来的关键层
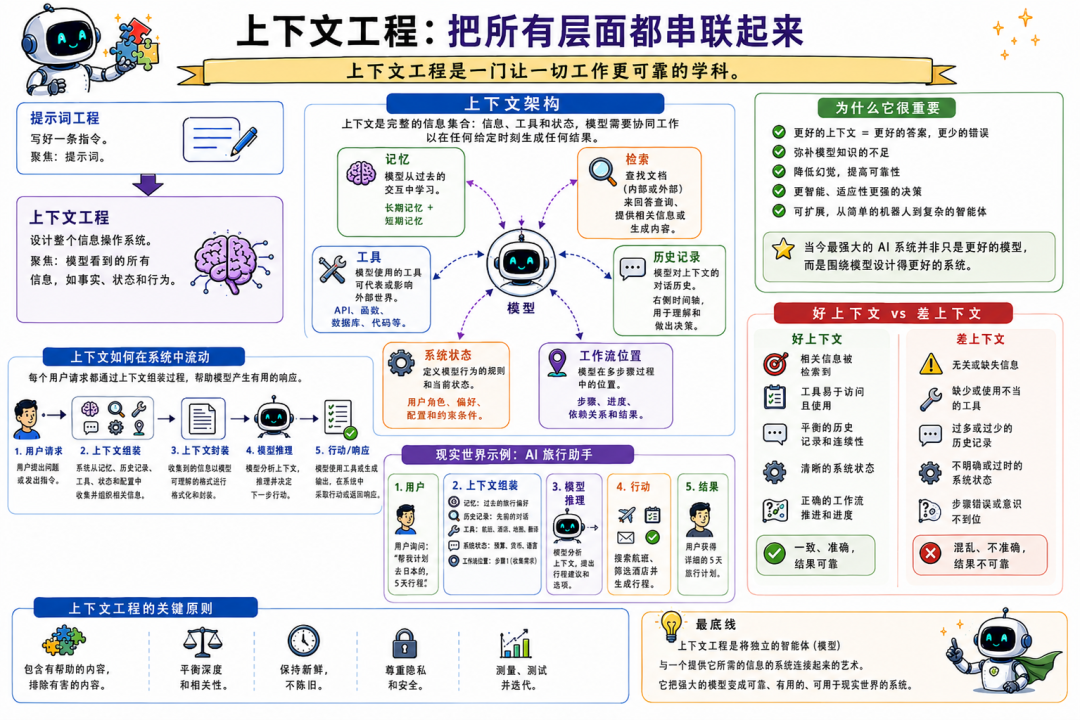
Context engineering(上下文工程)是让上述系统在生产环境稳定工作的学科。
- • Prompt engineering:写好一段指令
- • Context engineering:设计模型运行的“信息环境”,包括:
- • 记忆:跨轮次/跨会话记住什么
- • 检索:每次查询取哪些文档/数据
- • 工具:有哪些动作可用,如何描述与约束
- • 历史:保留多少对话上下文
- • 系统状态:当前任务在什么状态、有哪些已知事实
- • 工作流位置:多步骤流程走到哪一步
今天最强的 AI 产品,往往不是因为模型更强,而是因为围绕模型构建的系统更强。
“上下文做对”,是区分“生产可用”与“演示可用”的分水岭。
2026 年的现代 AI 产品架构长什么样
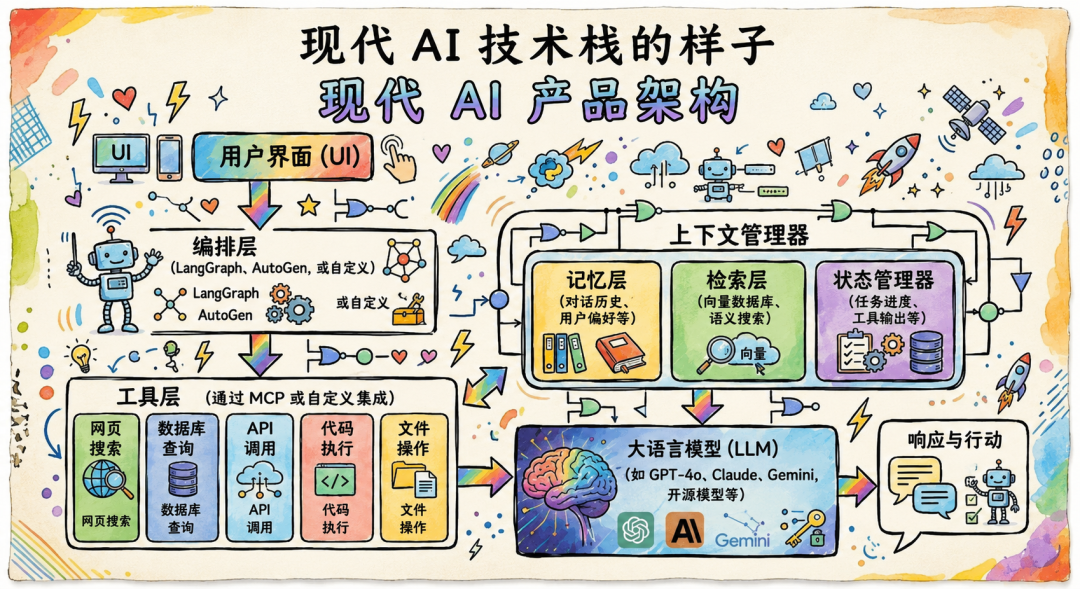
严肃的 AI 产品早已不是一次 API 调用,而是一整套系统:
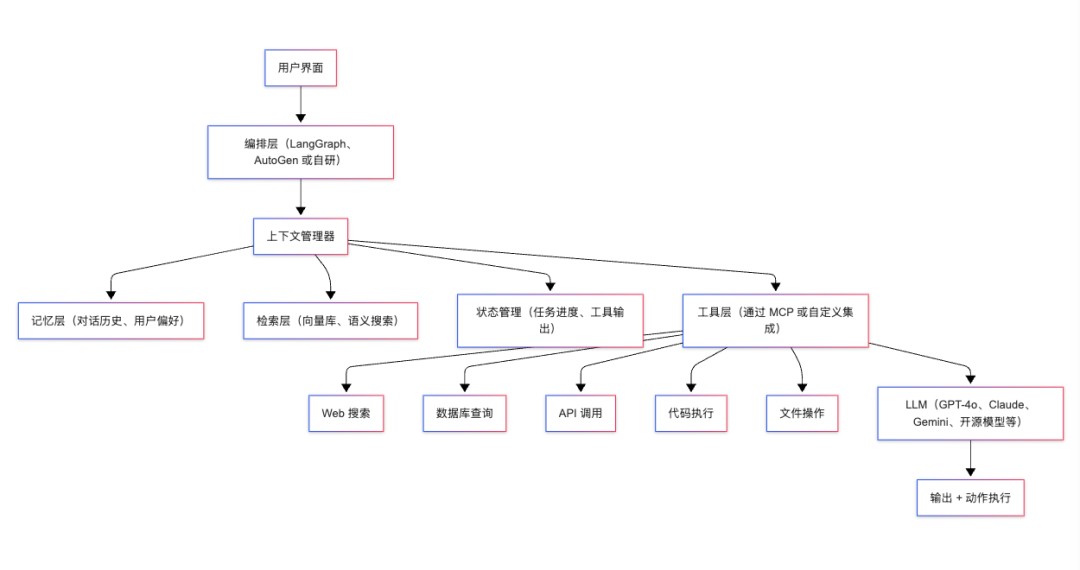
每一层都是为了解决上一层的某个关键缺陷。去掉任意一层,相应的问题就会重新出现。
决策框架:你到底需要哪一层?
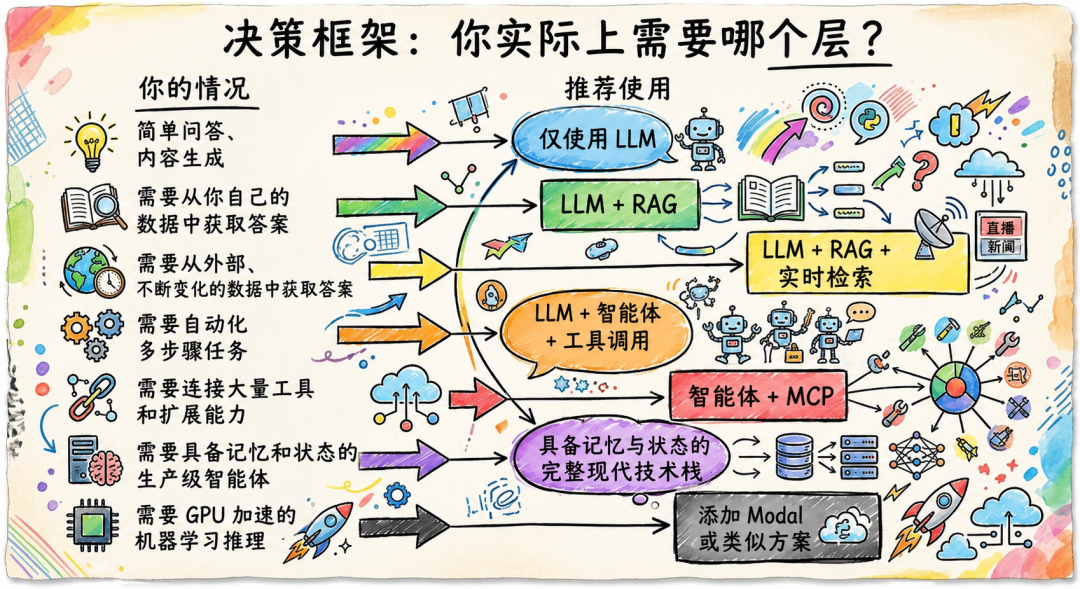
不要过度工程化。
对大多数“文档问答”场景,一个简单的 RAG 管线通常比复杂 Agent 更可靠、成本更低。
只有当更简单的系统无法满足需求时,才逐层引入更复杂的能力。
下一步会发生什么
下一代 AI 系统将更多聚焦于:
- • 长期持久记忆:跨月记住偏好,而不是只记得一段会话
- • 多智能体协作:由专长不同的 Agent 组成网络,共同完成目标
- • 现实世界执行:更深度接入操作系统与软件工具链
- • 个性化 AI:适配你的领域、风格、上下文并持续进化
- • 自治工作流:不再一步步等人指令,而是自己管理任务队列
瓶颈已经迁移:2020 年主要瓶颈是模型智能;到 2026 年,瓶颈是系统设计——你如何管理记忆、检索、工具协同,以及复杂流程中的上下文。
打造最佳 AI 产品的公司,拼的不只是模型,而是围绕模型搭建的系统能力。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献188条内容
已为社区贡献188条内容

所有评论(0)