Codex Automated Paper Reader:一个用 Codex 自动读、筛论文,并生成每日文献推荐的开源工具
一个用 Codex 自动读论文、筛选论文、生成每日文献推荐的开源工具:CAPR
项目名称:Codex Automated Paper Reader (CAPR)
GitHub 地址:https://github.com/Jurio0304/Codex_Automated_Paper_Reader
目标:让 Codex 每天自动帮你从 arXiv / OpenReview 中抓取候选论文,结合你的研究方向做语义筛选,并生成一份可读的每日文献推荐报告。
和普通的关键词订阅不同,CAPR 并不希望只靠关键词匹配来“机械推荐”。它把流程拆成两层:
- 脚本负责稳定抓取候选论文
- Codex 负责真正阅读、评分、筛选和总结
这样既保留了自动化效率,也避免了纯关键词系统经常出现的“看起来相关但实际没用”的问题。
一、为什么要做这个项目?
现在 AI 相关论文增长非常快,尤其是 arXiv、OpenReview 上每天都有大量新文章。如果每天手动浏览:
- 时间成本很高;
- 容易漏掉跨领域但有启发的论文;
- 关键词订阅经常过窄或过宽;
- RSS / 邮件提醒通常只解决“看到标题”,没有解决“判断价值”。
真正想要的是一个“科研助理式”的流程:
- 自动抓取近期论文;
- 根据研究方向粗筛;
- 再由大模型进行语义理解;
- 选出真正值得看的论文;
- 给出为什么值得看、怎么借鉴、有哪些局限。
这就是 CAPR 的出发点。
二、CAPR 是什么?
CAPR,全称 Codex Automated Paper Reader,是一个面向科研场景的每日论文阅读自动化工作流。
项目主要由两部分组成:
Codex_Automated_Paper_Reader/
├── Paper_Reader.template.txt # 中文 Codex 自动化 Prompt 模板
├── Paper_Reader.template.en.txt # 英文 Codex 自动化 Prompt 模板
├── paper-daily/ # 候选论文抓取脚本
│ ├── config.yaml
│ ├── scripts/
│ └── tests/
├── README.md
├── README.en.md
└── LICENSE
其中:
paper-daily是 Python 脚本工具;Paper_Reader.template.txt是给 Codex 自动化任务使用的中文 Prompt 模板;Paper_Reader.template.en.txt是英文 Prompt 模板;- 最终推荐报告由 Codex 阅读候选池后生成,而不是由脚本直接模板化生成。
三、整体工作流
CAPR 的每日运行流程大致如下:
arXiv / OpenReview
↓
paper-daily 抓取候选论文
↓
统一元数据、去重、粗排序
↓
生成 candidates.json
↓
Codex 读取候选池
↓
语义评分、深度阅读、Top 10 选择
↓
生成 Markdown 每日文献报告
这个设计的核心原则是:
脚本只负责候选检索,最终判断交给 Codex。
也就是说,CAPR 不希望把论文推荐做成一个固定关键词模板,而是让 Codex 结合研究背景、论文摘要、方法贡献、可迁移性等因素做更接近“科研助理”的判断。
四、主要功能
目前 CAPR 支持以下功能:
1. 从 arXiv 和 OpenReview 抓取论文
paper-daily 可以从多个来源抓取近期论文候选:
- arXiv
- OpenReview
可以在 config.yaml 中配置:
- arXiv 分类;
- OpenReview venue;
- lookback 天数;
- 最大候选数量;
- 正向关键词;
- 负向关键词。
2. 统一论文元数据格式
不同来源的论文数据结构不一样。CAPR 会将它们统一成类似下面的 JSON schema:
{
"id": "2605.12345",
"source": "arxiv",
"title": "Paper title",
"authors": ["Author One", "Author Two"],
"abstract": "Paper abstract...",
"url": "https://arxiv.org/abs/2605.12345",
"pdf_url": "https://arxiv.org/pdf/2605.12345",
"published_at": "2026-05-15T00:00:00+00:00",
"venue": "cs.LG",
"categories": ["cs.LG", "cs.AI"],
"matched_keywords": ["uncertainty estimation"],
"coarse_retrieval_score": 8.0
}
这样后续 Codex 可以稳定读取候选池,而不用关心论文来自哪个平台。
3. 去重和粗排序
CAPR 会基于:
- source ID;
- 标准化后的论文标题;
进行去重。
同时,它还会根据配置文件中的关键词、分类、发布时间等信息生成一个粗略检索分数。
需要注意的是,这个分数不是最终推荐分数。它只是告诉 Codex:
哪些论文可能更值得优先阅读。
最终排序仍然由 Codex 做语义评分。
4. 网络预检,避免空跑
这是实际使用中非常需要的功能。
自动化任务最怕一种情况: 网络断了,或者代理配置错误,结果脚本没抓到任何论文,但自动化流程仍然继续往下跑,最后生成一份“看似正常”的空报告。
CAPR 在抓取前会先检查核心网址是否可访问,例如:
export.arxiv.orgarxiv.orgopenreview.netapi2.openreview.net
如果网络预检失败,流程会直接退出,并报告网络错误。
这样可以避免“空跑”和“假日报”。
5. arXiv API 限流时自动 fallback
arXiv export API 有时会触发限流。CAPR 对这种情况做了 fallback 处理:
- 优先使用 arXiv export API;
- 如果 API 被限流或失败;
- 自动尝试从 arXiv HTML recent-list 页面抓取近期论文。
这可以提高每日自动化任务的稳定性。
6. 中英文 Codex 自动化 Prompt 模板
项目中提供了两个 Prompt 模板:
Paper_Reader.template.txt # 中文版
Paper_Reader.template.en.txt # 英文版
用户可以复制模板为本地私有 Prompt:
cp ../Paper_Reader.template.txt ../Paper_Reader.txt
或者使用英文版:
cp ../Paper_Reader.template.en.txt ../Paper_Reader.txt
然后在本地的 Paper_Reader.txt 中填写自己的研究背景、关注方向、评分偏好和本地路径。
五、如何使用?
1. 克隆项目
git clone https://github.com/Jurio0304/Codex_Automated_Paper_Reader.git
cd Codex_Automated_Paper_Reader/paper-daily
2. 安装依赖
推荐 Python 3.10+。
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Windows PowerShell 示例:
python -m venv .venv-win
.\.venv-win\Scripts\python.exe -m pip install -r requirements.txt
3. 抓取候选论文
python scripts/daily_papers.py --config config.yaml --date today --stage fetch --force
运行后会生成:
data/raw/YYYY-MM-DD.json
data/processed/YYYY-MM-DD_candidates.json
logs/YYYY-MM-DD.log
其中最重要的是:
data/processed/YYYY-MM-DD_candidates.json
这是 Codex 后续阅读和筛选的候选池。
六、Codex 自动化推荐流程
非常建议把 CAPR 和 Codex APP 的 standalone automation 功能结合使用。
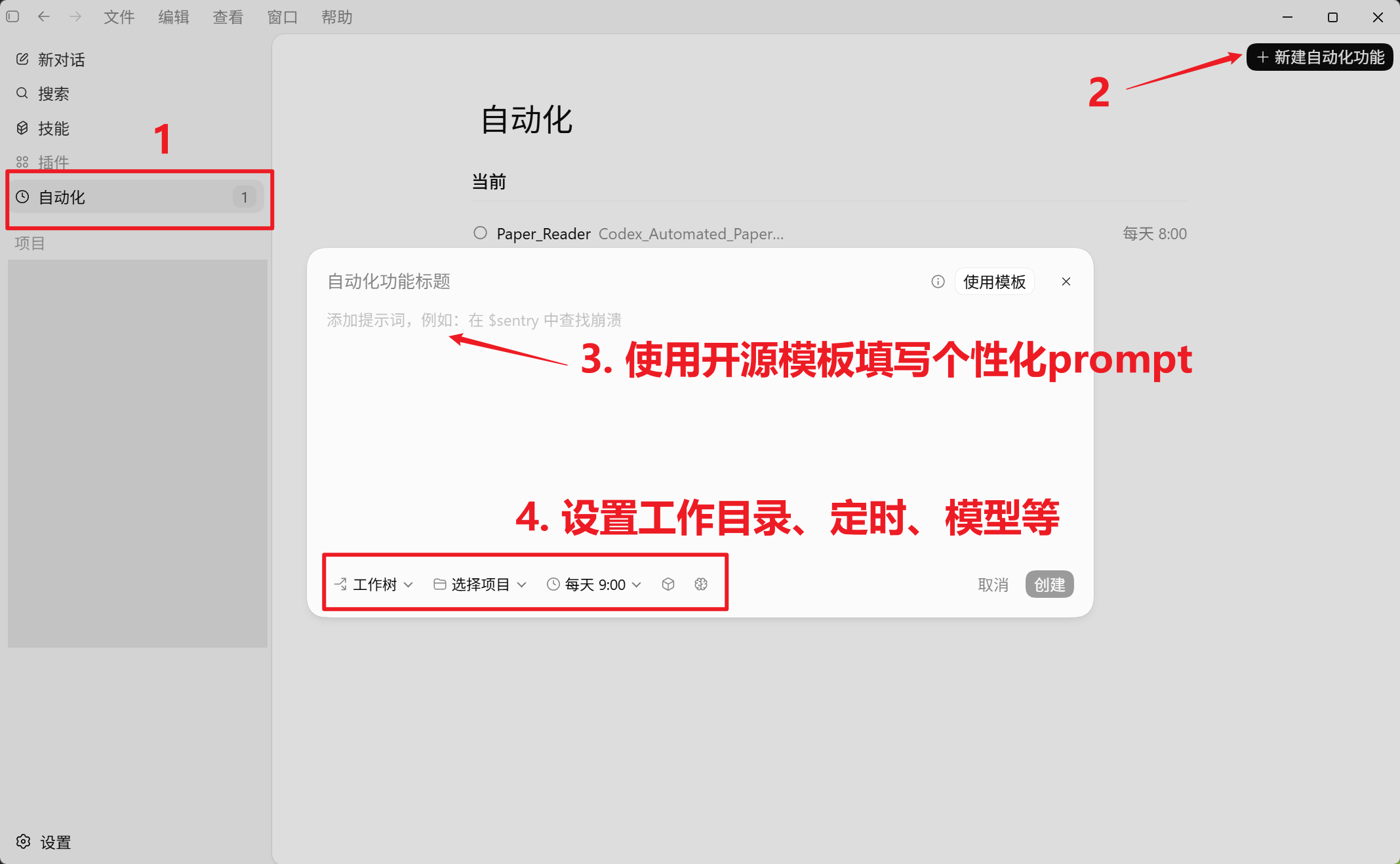
一个完整的自动化任务可以这样设计:
- 进入
paper-daily工作目录; - 运行候选抓取脚本;
- 读取当天的
candidates.json; - 对每篇论文进行语义评分;
- 选出约 15 篇做进一步阅读;
- 最终选出 Top 10;
- 写入 Markdown 日报。
Prompt 模板中已经约束 Codex:
- 不要只运行脚本就结束;
- 不要直接用关键词模板生成报告;
- 不要没有阅读候选内容就总结;
- 不要编造 PDF 或正文中没有的信息;
- 需要标明每篇总结是基于 abstract、paper page 还是 PDF。
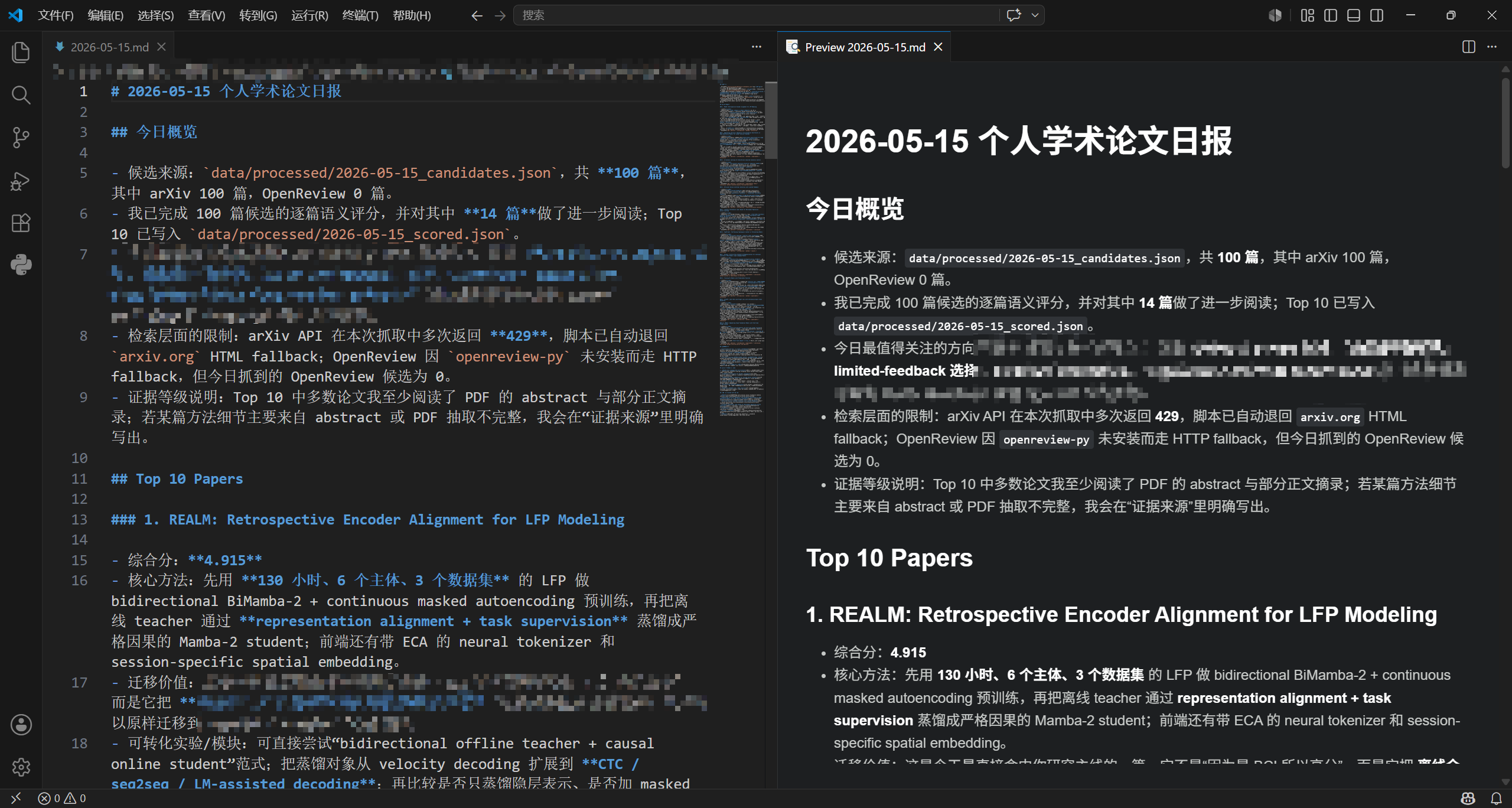
七、生成的日报长什么样?
理想情况下,每日文献报告会包含:
- 今日概览;
- Top 10 Papers;
- 每篇论文的核心方法;
- 对当前研究的迁移价值;
- 可转化成实验或模块的想法;
- 局限性;
- 阅读建议;
- 证据来源;
- 今日研究趋势;
- 值得加入 related work 的论文。
示例结构如下:
# Daily Paper Report - YYYY-MM-DD
## Overview
今天共检索到 XX 篇候选论文,最终选择 Top 10。
## Top 10 Papers
### 1. Paper Title
- Source: arXiv
- Evidence: paper page / PDF / abstract-only
- Method:
- Transfer Value:
- Actionable Idea:
- Limitation:
- Reading Advice:
## Trends of the Day
...
## Potential Research Ideas
...
## Papers Worth Adding to Related Work
...
八、项目适合谁?
CAPR 适合以下用户:
- 每天需要跟踪大量 AI / ML 论文的研究者;
- 希望用 Codex 做科研助理;
- 想搭建个性化论文推荐系统;
- 不满足于 RSS / 邮件关键词订阅;
- 希望自动生成每日文献简报;
- 想把论文筛选流程工程化、自动化。
如果你有自己的研究方向,只需要调整:
config.yamlPaper_Reader.txt
就可以让 CAPR 更贴合你的需求。
项目地址
GitHub 地址:https://github.com/Jurio0304/Codex_Automated_Paper_Reader
如果你也在尝试用 Codex / AI Agent 改造科研工作流,欢迎试用、star 或提出 issue。
后续计划
后续可能会继续改进以下功能:
- 更完善的 PDF 阅读流程;
- 更细粒度的论文评分 schema;
- 支持更多论文源;
- 支持按研究方向生成多个日报;
- 更好的失败恢复机制;
- 更友好的配置模板;
- 更完整的自动化部署说明。
总结
CAPR 是一个面向科研场景的 Codex 自动化论文阅读工具。
它并不是一个简单的 arXiv 爬虫,也不是一个关键词订阅器,而是一个把“候选检索”和“语义阅读”分离的自动化工作流:
- Python 脚本负责稳定抓取候选论文;
- Codex 负责理解、筛选和总结;
- 最终生成每日 Markdown 文献报告。
如果你每天也被海量论文淹没,希望让 AI 真正参与到论文筛选和研究灵感发现中,CAPR 也许可以作为一个不错的起点。
项目地址: https://github.com/Jurio0304/Codex_Automated_Paper_Reader

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)