在线批量抠图的技术实现路径:图像分割模型对比与工程化部署方案
在电商运营、新媒体内容生产和证件照处理等场景中,批量抠图已成为一项高频需求。传统手动抠图不仅耗时耗力,面对成百上千张图片时更是难以规模化。本文将从技术视角出发,系统梳理当前主流的图像分割模型,对比其在批量处理场景下的性能表现,并探讨从算法到产品的工程化落地路径。

目录
一、批量抠图的技术演进与核心挑战
早期的抠图工作流依赖 Photoshop 的钢笔工具或魔棒工具,操作者需要逐张处理边缘细节。随着深度学习的发展,基于神经网络的自动抠图方案逐渐成熟,但单张推理与批量工程化之间存在显著差距。
批量抠图面临的核心挑战可归纳为三点:
第一,精度与效率的权衡。高精度模型往往参数量大、推理速度慢,而轻量模型在复杂边缘(如发丝、透明材质)上容易丢失细节。如何在保证商用级精度的前提下实现高吞吐,是工程化的首要难题。
第二,场景泛化能力。不同业务场景对"主体"的定义差异巨大:电商需要精准提取商品轮廓,证件照要求人像完整保留,而设计素材可能涉及不规则图形。单一模型难以覆盖全品类需求。
第三,边缘case的稳定性。实际业务中的图片质量参差不齐,低分辨率、压缩伪影、复杂背景交织等情况会显著影响模型表现,需要完善的前处理和后处理流水线兜底。
二、主流图像分割模型技术对比
当前开源社区中,U²Net、MODNet 和 BiRefNet 是抠图领域的三个代表模型,各自适用于不同的技术路线。
2.1 U²Net:通用场景的均衡之选
U²Net 最初设计用于显著性检测,其架构采用多层嵌套的 U 型结构,能够在不同尺度上捕捉图像特征。这种"金字塔"式的设计使其对各种主体类型都有不错的适应性,无论是人像、物品还是动物,都能获得可用的分割结果。
在工程实践中,U²Net 的优势在于推理速度快(单张 1024×1024 图片约 0.1~0.2 秒)和模型体积适中(约 170MB),非常适合作为批量处理的基线模型。但其局限性在于边缘精度:对于特别细淡的发丝或半透明区域,容易出现细节丢失或边缘模糊。
2.2 MODNet:人像领域的特长生
MODNet 采用多分支结构,同时处理语义估计、边缘预测和透明度蒙版生成三个子任务。这种"分工协作"的设计使其在人像抠图,特别是发丝边缘处理上表现出色,精度可与更复杂的模型媲美。
该模型最大的特点是极度轻量(约 25MB)和推理高效(单张约 0.2~0.3 秒),非常适合移动端集成或实时视频流处理。然而,其设计目标明确指向人像,对于商品、印章、Logo 等非人像主体的识别能力相对有限,场景泛化性是其主要短板。
2.3 BiRefNet:边缘精度的天花板
BiRefNet 通过"双向注意力"机制,在全局特征提取与局部边缘优化之间反复迭代,形成了"由粗到细、由细反馈回粗"的闭环优化。这种架构使其在处理毛发、婚纱、玻璃杯等复杂边缘时表现突出,在多个公开数据集上达到了当前最优水平。
代价是更高的计算复杂度:模型体积约 500MB,单张推理时间约 0.5~0.8 秒。对于追求极致精度的电商产品图、广告素材等场景,这种"以时间换精度"的取舍通常是值得的。
|
模型 |
核心优势 |
推理速度 |
模型体积 |
适用场景 |
|
U²Net |
通用性强、速度快 |
0.1~0.2s |
~170MB |
批量处理、多品类混合 |
|
MODNet |
人像精度高、极轻量 |
0.2~0.3s |
~25MB |
移动端、实时人像 |
|
BiRefNet |
边缘精度顶级 |
0.5~0.8s |
~500MB |
高精度商用素材 |
三、工程化部署的关键技术路径
将上述模型从研究代码转化为可落地的批量处理系统,需要解决架构设计、性能优化和稳定性保障三个层面的问题。
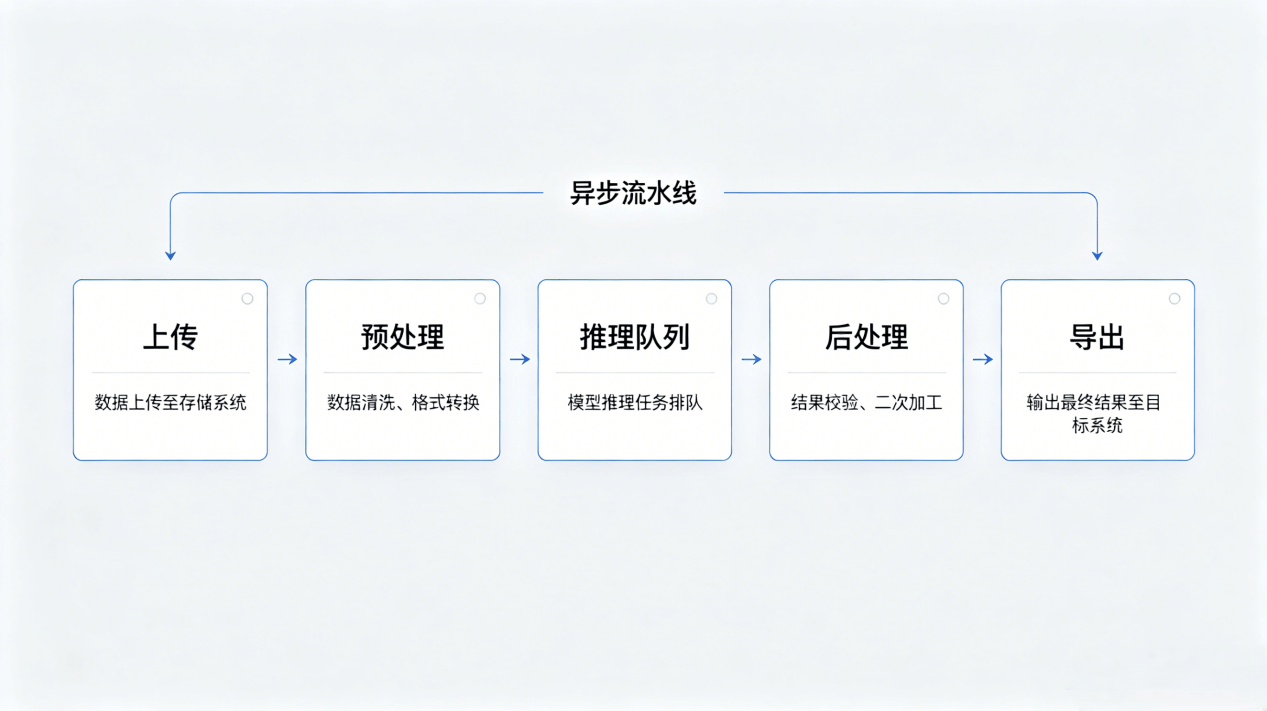
3.1 异步流水线架构
批量抠图不适合同步阻塞式处理。典型的生产级架构采用"上传→预处理→推理队列→后处理→导出"的异步流水线:
上传层:接受多格式图片(JPG/PNG/BMP/TIFF),进行格式统一和元数据提取
预处理层:执行尺寸归一化、色彩空间转换、质量增强(如去压缩伪影)
推理层:根据业务类型动态路由至不同模型(人像→MODNet,通用→U²Net,高精度→BiRefNet)
后处理层:边缘羽化、锯齿消除、阴影合成、背景替换
导出层:支持透明 PNG、纯色 JPG、自定义背景图等多格式输出
3.2 动态批处理与硬件加速
为提升 GPU 利用率,推理层通常采用动态批处理(Dynamic Batching)。系统根据显存容量将多张图片组批(常见 batch=8~16),配合 ONNX Runtime 或 TensorRT 进行图优化,可显著降低单张均摊耗时。对于 U²Net 这类轻量模型,在 RTX 4090 上结合批处理可实现每秒 15~20 张的吞吐。
模型量化(INT8)和半精度推理(FP16)也是常用的加速手段,但需注意精度敏感场景(如发丝边缘)可能因量化损失而降级,需要针对性校准。
3.3 边缘 Case 的兜底策略
纯依赖模型推理难以覆盖所有业务场景。工程实践中通常引入多级兜底:
置信度阈值过滤:对模型输出的蒙版置信度进行统计,低置信度图片自动进入人工复核队列
边缘羽化算法:对硬边缘进行高斯羽化,消除锯齿感,提升合成自然度
用户修正接口:提供画笔擦除/恢复工具,允许对 AI 结果进行像素级微调
模板匹配兜底:对于证件照等标准化场景,结合人脸检测框进行几何约束,确保头部比例合规
四、从开源方案到产品化工具的实践观察
在将上述技术路径落地为可交付工具的过程中,有几个工程细节对最终体验影响显著。
本地 vs 云端推理的取舍。 对于涉及隐私数据的场景(如企业内部证件照、未上市产品图),本地化处理是刚需。这要求工具能够在消费级硬件上流畅运行,同时保持合理的处理速度。U²Net 和轻量版 MODNet 在此类场景下更具优势。
批量交互设计的复杂度。 真正的批量处理不仅是"一次选多张图",还包括:处理进度可视化、失败重试机制、输出命名规则自定义、批量尺寸调整、统一背景色应用等。这些功能看似琐碎,却直接决定了工具在真实工作流中的可用性。
多场景模型的无缝切换。 用户通常不会关心底层是 U²Net 还是 BiRefNet,他们需要的是"人像模式""物品模式""证件照模式"等直觉化选项。产品层需要将技术模型映射为场景化预设,并自动完成参数调优。
以当前市面上的工具实践为例,嗨格式抠图大师在这一路径上提供了可参考的落地样本。其技术架构底层融合了多模型策略:针对不同主体类型(人像、物品、印章、Logo 等)自动匹配最优分割方案,而非单一模型通吃。 在工程层面,该工具支持本地离线处理(数据不出域),同时提供了批量上传、自动队列处理、多格式导出(透明 PNG/纯色 JPG)、证件照尺寸模板等完整流水线功能。

从开发者视角看,这类工具的价值不在于算法本身的独创性,而在于将模型能力封装为低摩擦的工作流:用户无需理解 BiRefNet 的双向注意力机制,也无需手动调整 batch size,只需选择"批量添加"即可获得可用的结果。对于缺乏 GPU 运维资源但又有高频批量需求的中小团队,这种"开箱即用"的中间层产品,实际上填补了开源代码与商业需求之间的工程鸿沟。
五、选型建议与未来趋势
对于不同技术储备的团队,批量抠图方案的选型可参考以下维度:
|
维度 |
自研方案 |
开源工具链 |
成熟产品工具 |
|
技术门槛 |
高(需算法+工程团队) |
中(需工程化封装) |
低(开箱即用) |
|
定制化程度 |
完全可控 |
中等 |
受产品功能边界限制 |
|
数据隐私 |
完全本地 |
取决于部署方式 |
需确认是否支持本地处理 |
|
维护成本 |
高(模型迭代、硬件运维) |
中 |
低 |
|
适用场景 |
大型平台、深度定制需求 |
中型团队、技术储备充足 |
中小企业、高频标准化需求 |
展望未来,批量抠图技术将呈现两个演进方向:
一是端侧推理的普及。 随着 WebGPU 和移动端 NPU 的成熟,越来越多的推理负载将从云端下沉到浏览器或本地设备。这要求模型进一步轻量化(如基于 Transformer 的高效变体),同时保持可接受的精度。
二是多模态交互的融合。 文本指令驱动的抠图(如"保留人物但去除右侧的椅子")正在成为可能,SAM(Segment Anything)及其后续变体为此提供了技术基础。未来的批量处理工具可能不再是"一键全抠",而是"批量语义编辑"。
结语
从技术实现到产品落地,批量抠图的本质是在精度、效率、易用性之间寻找最优平衡点。开源模型提供了算法基础,但真正的工程挑战在于流水线设计、边缘 case 兜底和用户体验封装。无论是选择自研还是借助成熟工具,理解底层模型的能力边界与适用场景,都是做出合理技术决策的前提。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)