阶段项目:音你太美--音乐推荐平台
一、项目背景
1.行业现状分析
-
市场规模:数字音乐市场用户规模突破6亿,市场规模超500亿元,年增长率保持在15%以上
-
竞争格局:QQ音乐、网易云音乐等头部平台占据主要市场,但用户增长放缓
-
技术趋势:AI推荐、个性化定制、社交化成为行业发展的三大方向
-
使用场景:用户日均听歌时长超过1.5小时,移动端占比超过70%
2.存在的问题痛点
| 序号 | 痛点 | 影响 | 解决方案 |
|---|---|---|---|
| 1 | 海量音乐资源难以筛选 | 用户选择困难,体验不佳 | 智能搜索 + AI推荐 |
| 2 | 传统推荐算法单一化 | 缺乏个性化,用户流失 | 多维度用户画像 |
| 3 | 歌单管理功能有限 | 组织音乐效率低下 | 智能歌单生成 |
| 4 | 社交互动不足 | 用户粘性低 | 歌单分享、社交推荐 |
3.项目目标与意义
-
目标:构建集听歌、管理、智能推荐于一体的现代化音乐平台
-
意义:提升用户音乐发现效率,提供个性化音乐体验,增强用户粘性
二、项目业务需求
功能模块架构
| 用户系统 | 歌曲管理 | 歌单管理 | 收藏管理 | AI推荐 |
|---|---|---|---|---|
| 注册登录 | 浏览搜索 | 创建编辑 | 收藏歌曲 | 自然语言推荐 |
| 密码重置 | 在线播放 | 歌曲管理 | 收藏列表 | 歌词情感分析 |
| 权限管理 | 上传管理 | 收藏关联 | 批量管理 | 智能发现 |
三、业务流程(图形)
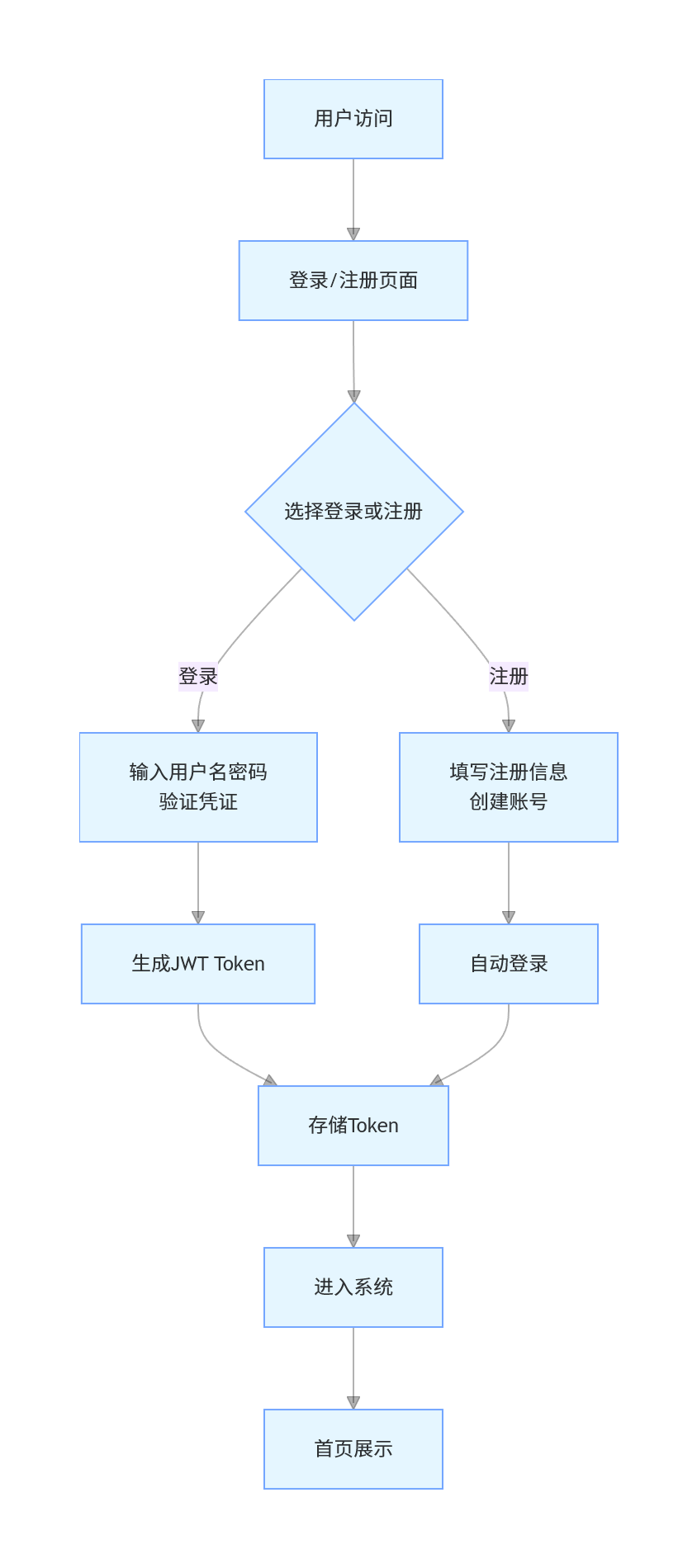
1.用户登录流程
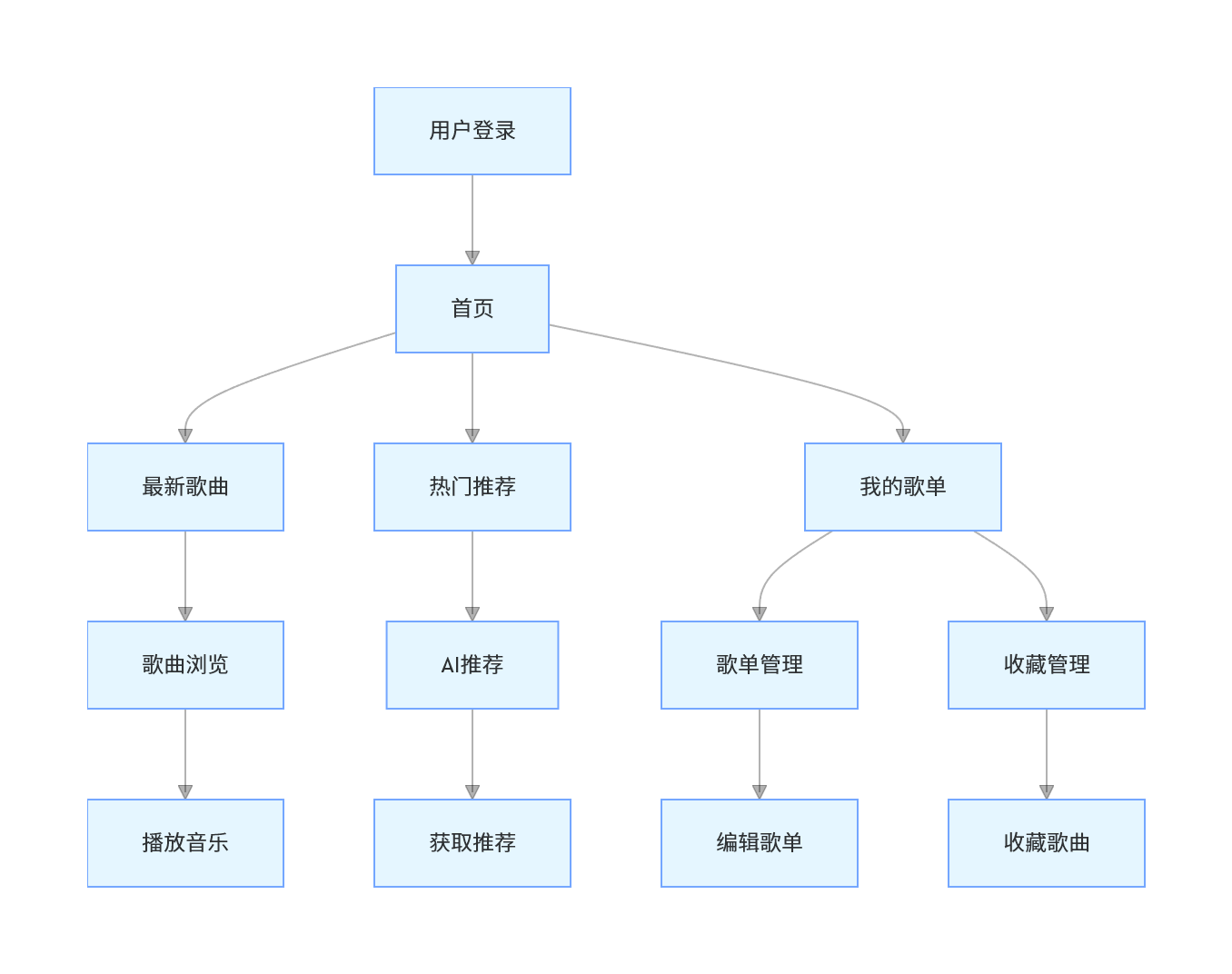
2.核心业务流程
3.总结
四、项目加购
1.系统架构图
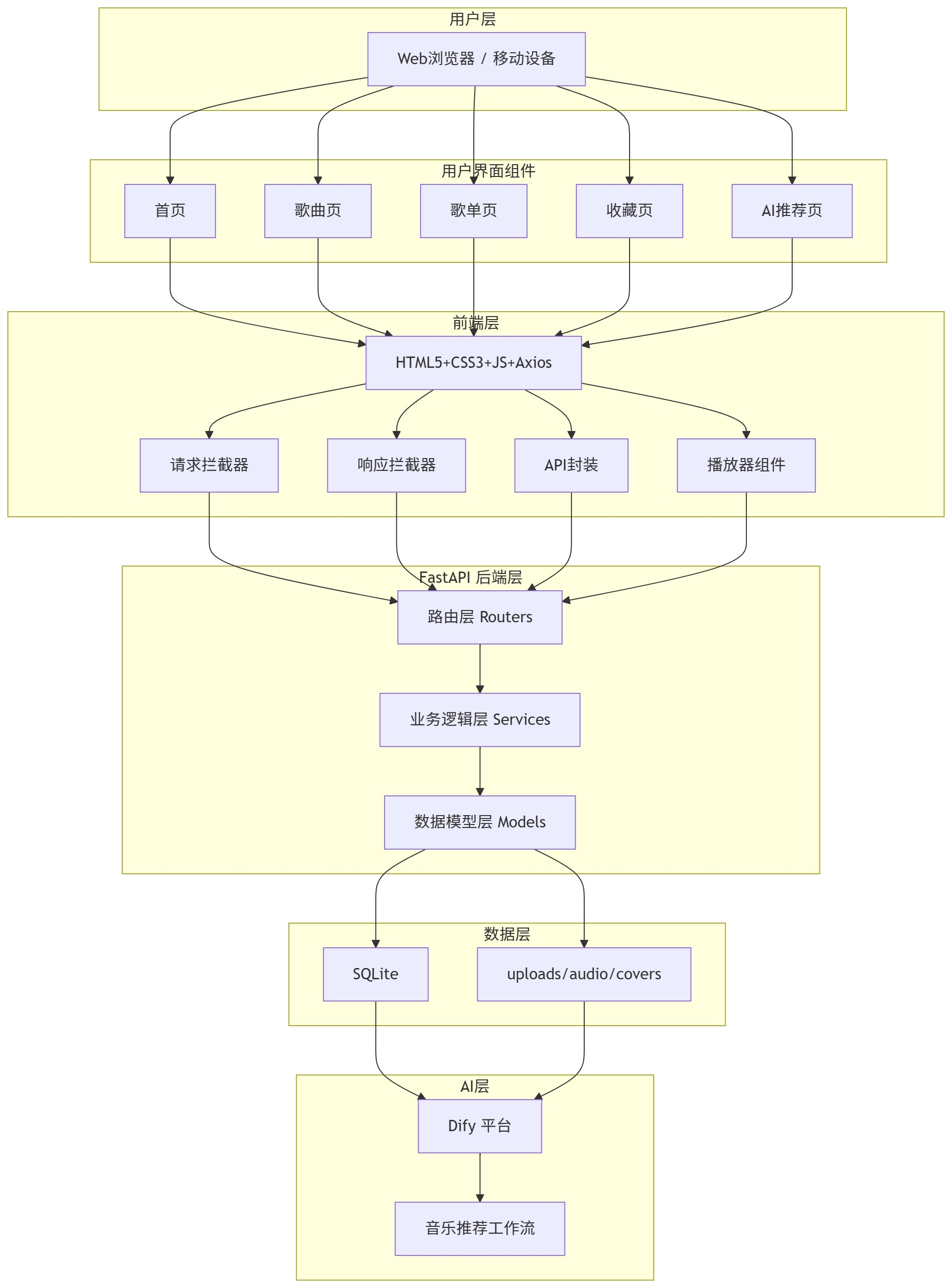
2.项目目录结构
project1/
├── backend/ # 后端服务
│ ├── app/ # 核心应用
│ │ ├── main.py # FastAPI 入口
│ │ ├── models/ # 数据模型
│ │ ├── routers/ # API 路由
│ │ ├── services/ # 业务逻辑
│ │ ├── schemas/ # 数据校验
│ │ └── utils/ # 工具类
│ ├── uploads/ # 文件存储
│ ├── .env # 环境变量
│ ├── requirements.txt # 依赖包
│ └── init_db.py # 数据库初始化
└── frontend/ # 前端页面
├── 各html页面 # 页面文件
├── css/ # 样式文件
└── js/ # 脚本文件
五、项目技术栈
1.后端技术栈
| 技术 | 版本 | 用途 | 优势 |
|---|---|---|---|
| FastAPI | 0.104.1 | Web框架 | 异步高性能、自动API文档、类型提示 |
| SQLAlchemy | 2.0.23 | ORM框架 | Python SQL工具包,支持多种数据库 |
| python-jose | 3.3.0 | JWT认证 | 生成和验证JWT Token |
| Passlib | 1.7.4 | 密码加密 | 支持多种哈希算法 |
| bcrypt | 4.0.1 | 哈希算法 | 自适应哈希函数,抗攻击 |
| Uvicorn | 0.24.0 | ASGI服务器 | 快速的ASGI服务器 |
| python-multipart | 0.0.6 | 文件上传 | 支持multipart/form-data |
| requests | 2.31.0 | HTTP客户端 | 调用外部API |
2.前端技术栈
| 技术 | 用途 | 特点 |
|---|---|---|
| HTML5 | 页面结构 | 语义化标签,SEO友好 |
| CSS3 | 样式设计 | 响应式布局,动画效果 |
| JavaScript (ES6+) | 交互逻辑 | 现代JS特性,异步编程 |
| Axios | HTTP请求库 | Promise-based,拦截器支持 |
3.AI集成方案
-
Dify平台:低代码AI应用开发平台,可视化编排工作流
-
工作流模式:自然语言理解 → 音乐检索 → 推荐生成
-
功能支持:音乐推荐、歌词分析、智能发现
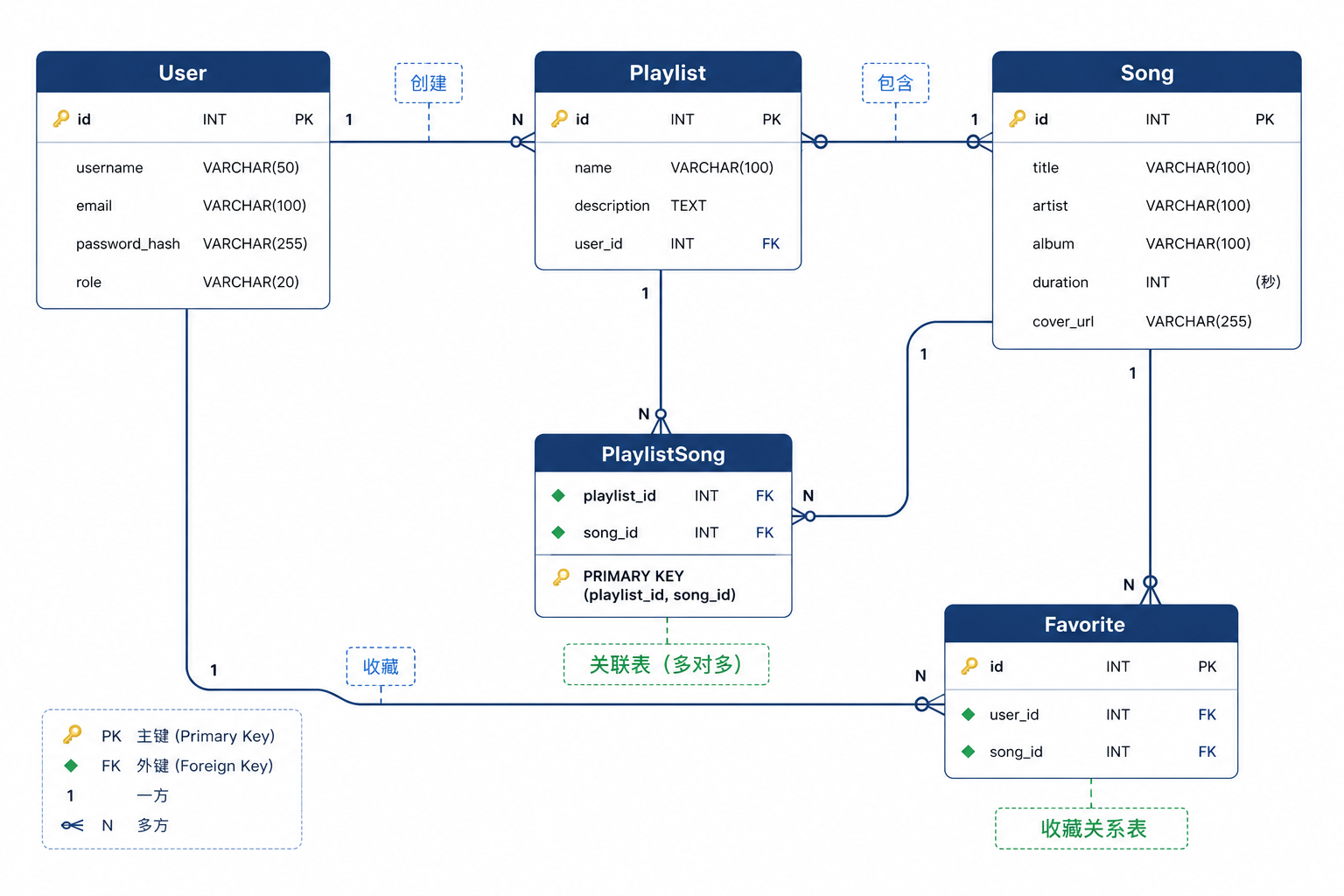
六、数据库设计
实体关系图
七、项目演示
1. 登录与注册页面
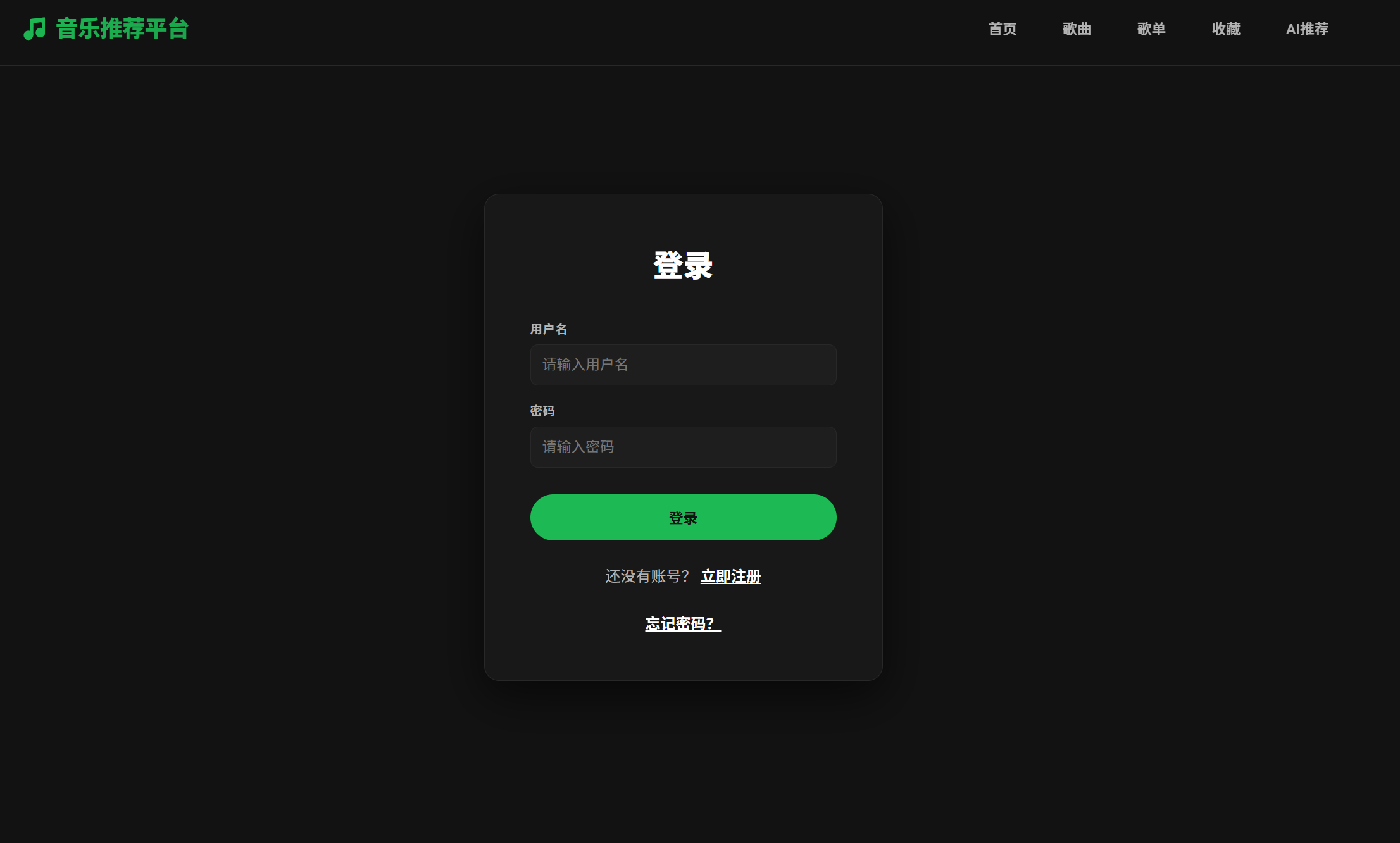
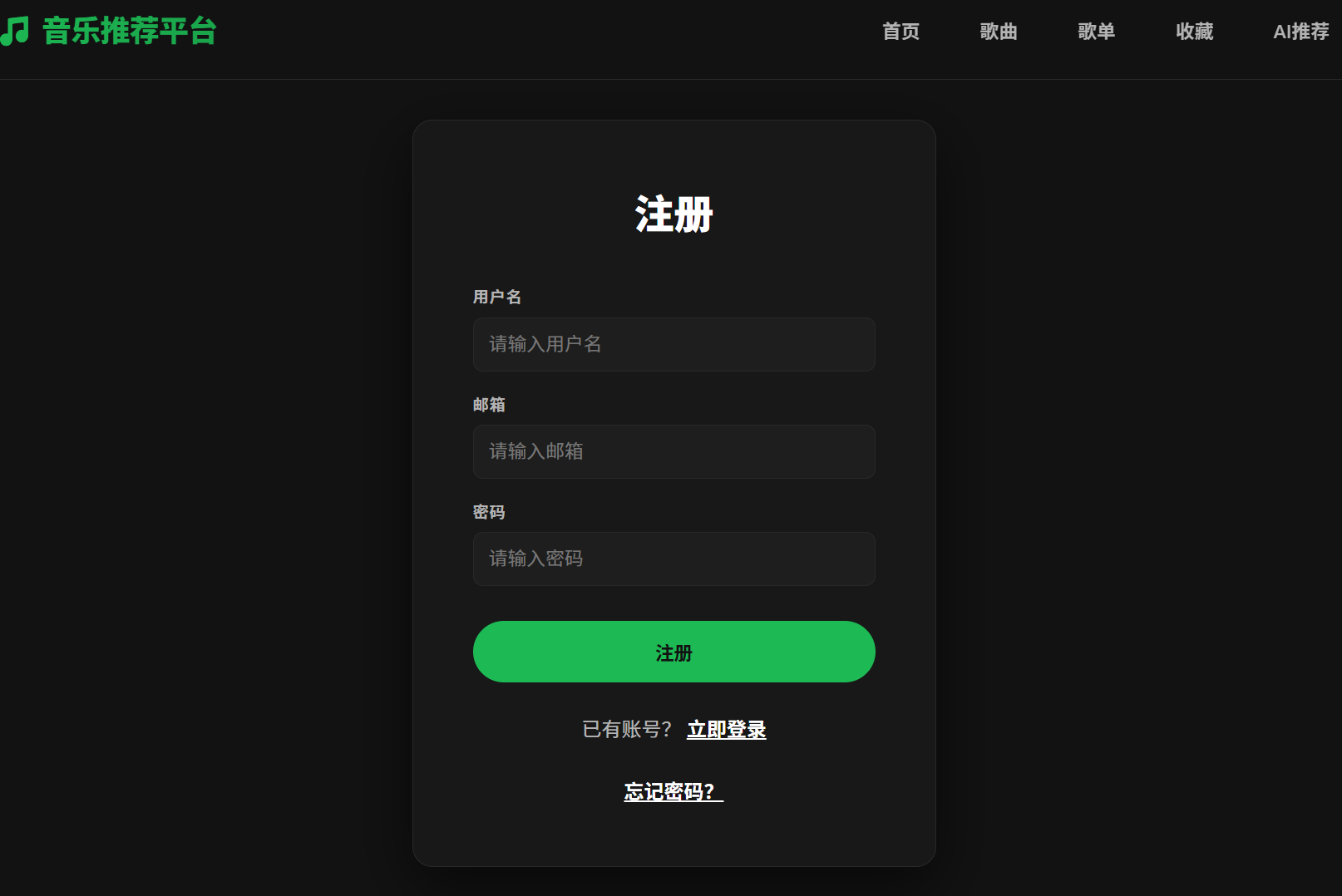
注: 用户如果忘记密码,可以点击下方的忘记密码选择通过邮箱进行重置密码
2.首页
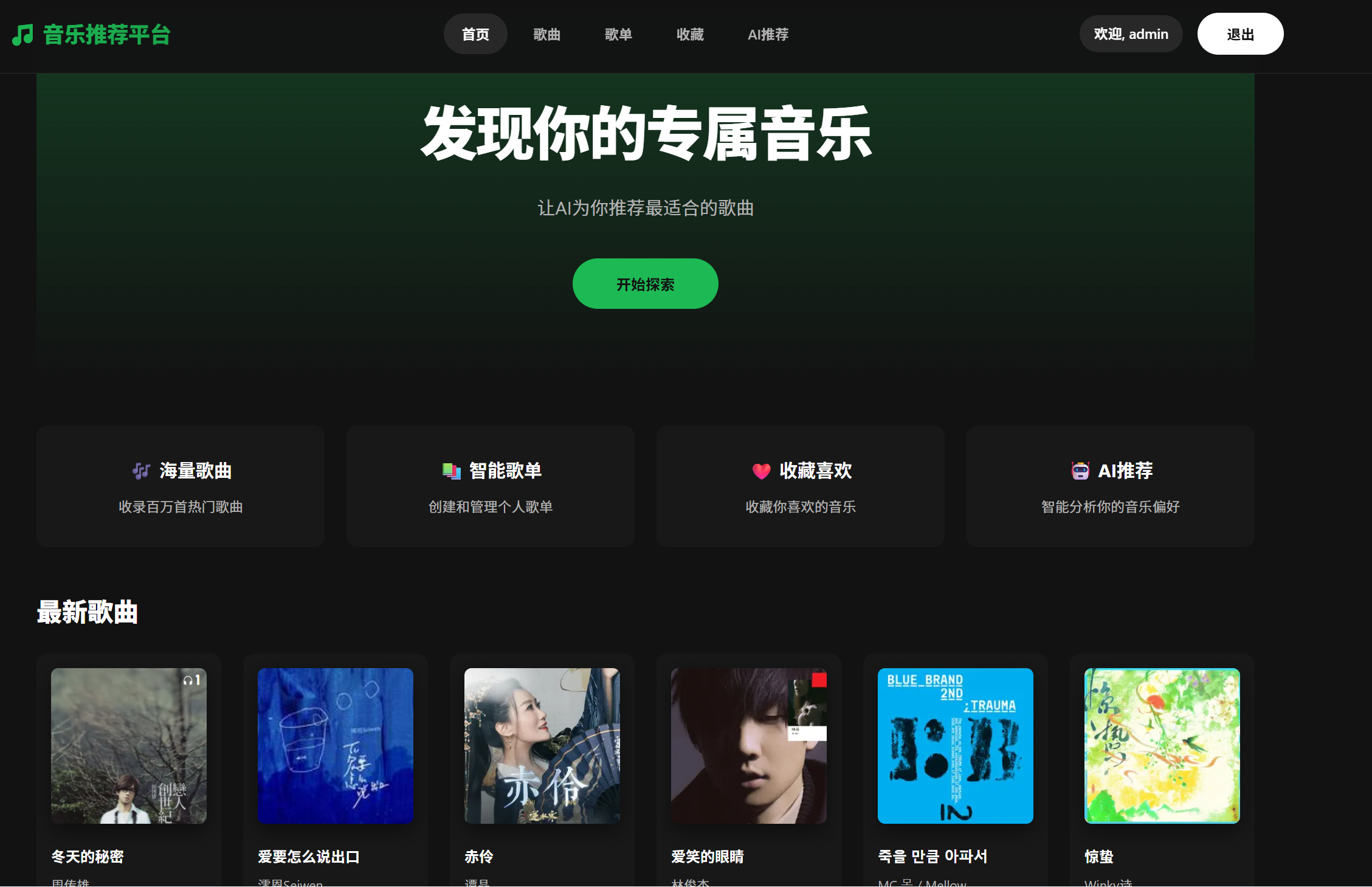
1.用户登录成功后第一个映入眼帘的就是我们的首页
2.最上方的是我们的探索功能,点击后可以直接跳转到我们的AI推荐页面
3.中间的是本网站的四大特点,以及最下方的歌曲在本网站都是可以播放的,通过漂亮的封面来吸引用户
3.歌曲页面
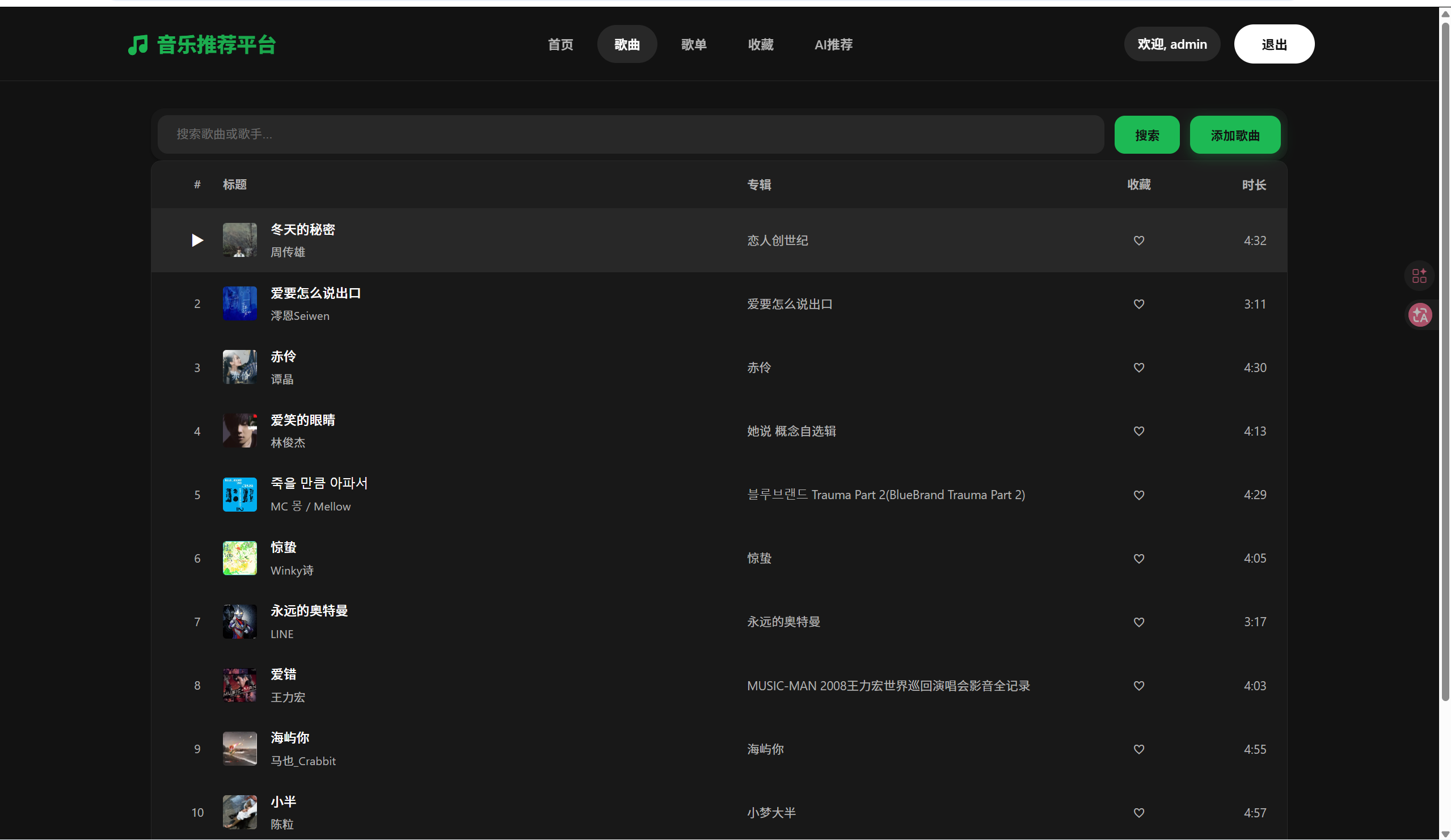

本网站蕴含了海量歌曲,为提升用户体验,我还在网页的上方添加了搜索框,输入关键字即可找到用户想听的歌曲
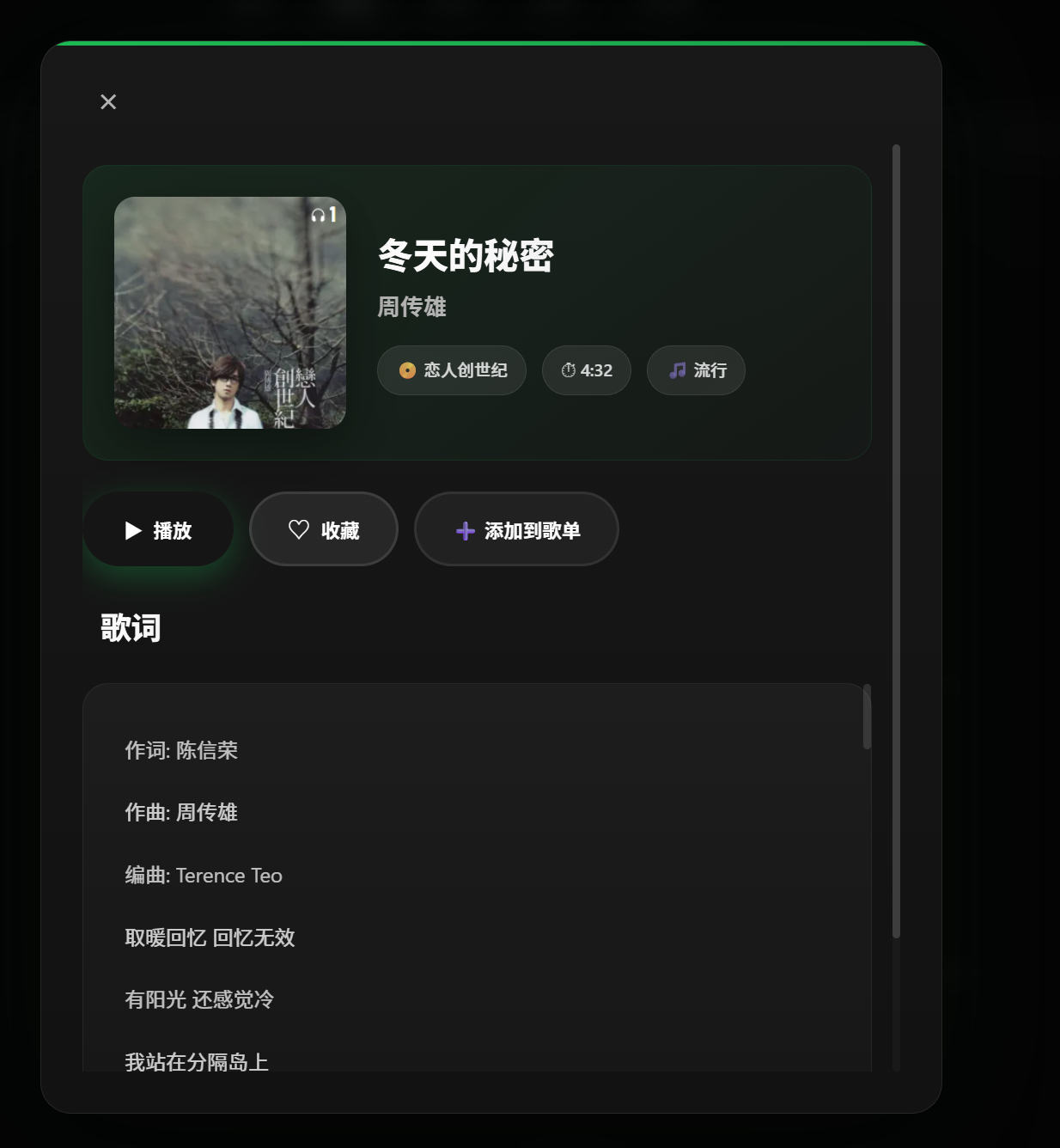
如果用户想要了解歌曲的具体信息,比如:歌手、专辑、歌词等,还可以点击歌曲,那么页面就会给我们弹出一个详情框,这些内容在这里面都可以找的到
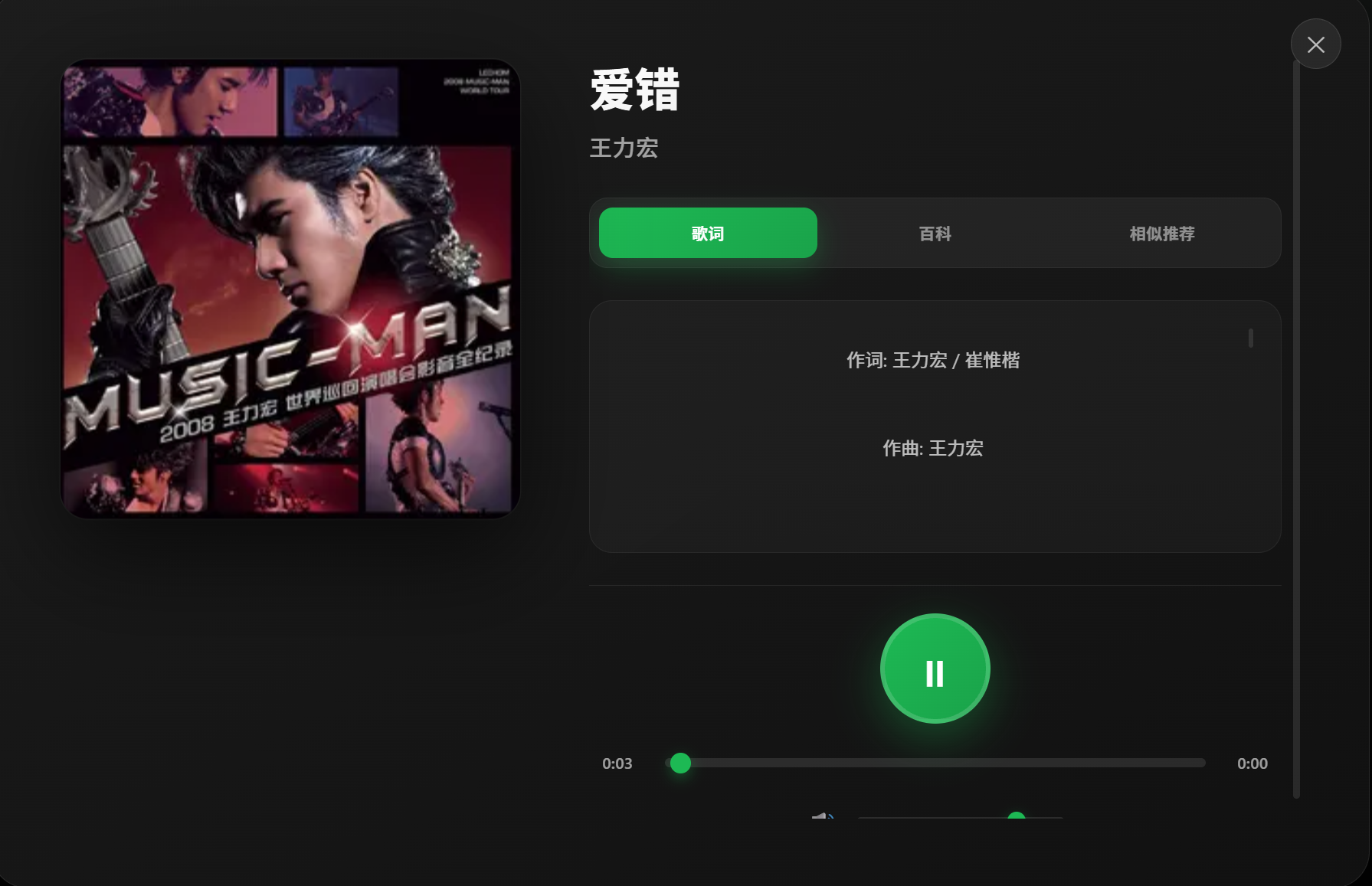
同时,如果你点击了播放歌曲,那么在页面的最下方还会出现一个播放栏,在这个播放栏上我们可以进行调整歌曲进度和音量大小的操作,如果用户点击最左方的歌曲封面,还会弹出一个全屏播放器,同时,在这个地方也可以查询到歌曲本身的信息。
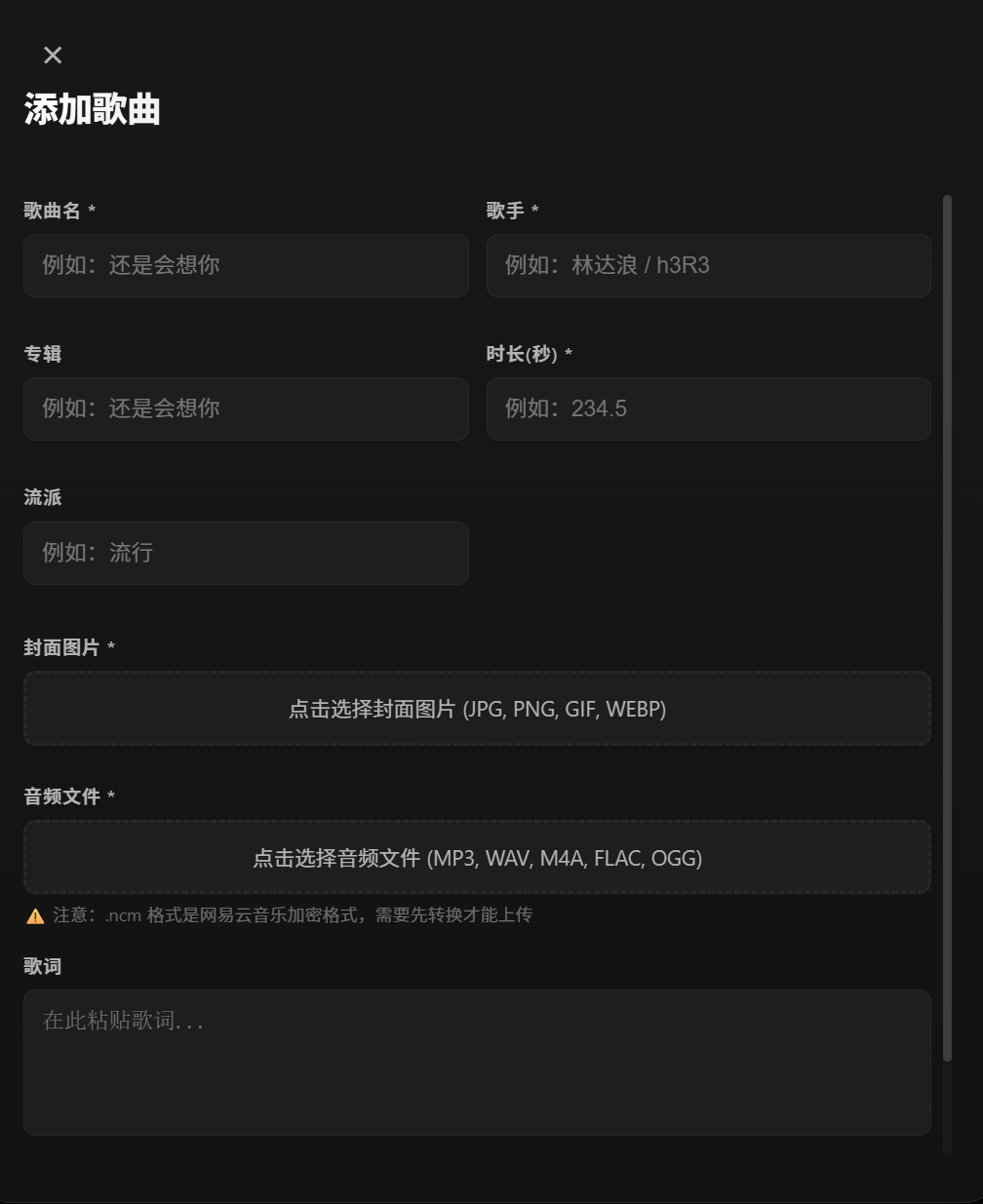
基于对网站的管理,在开发之初,我对网站设立了两种用户状态,一种是管理员,还有一种是普通用户,目前所展示的则是管理员的添加歌曲功能,管理员可以对曲库进行添加和删除歌曲
4.歌单页面
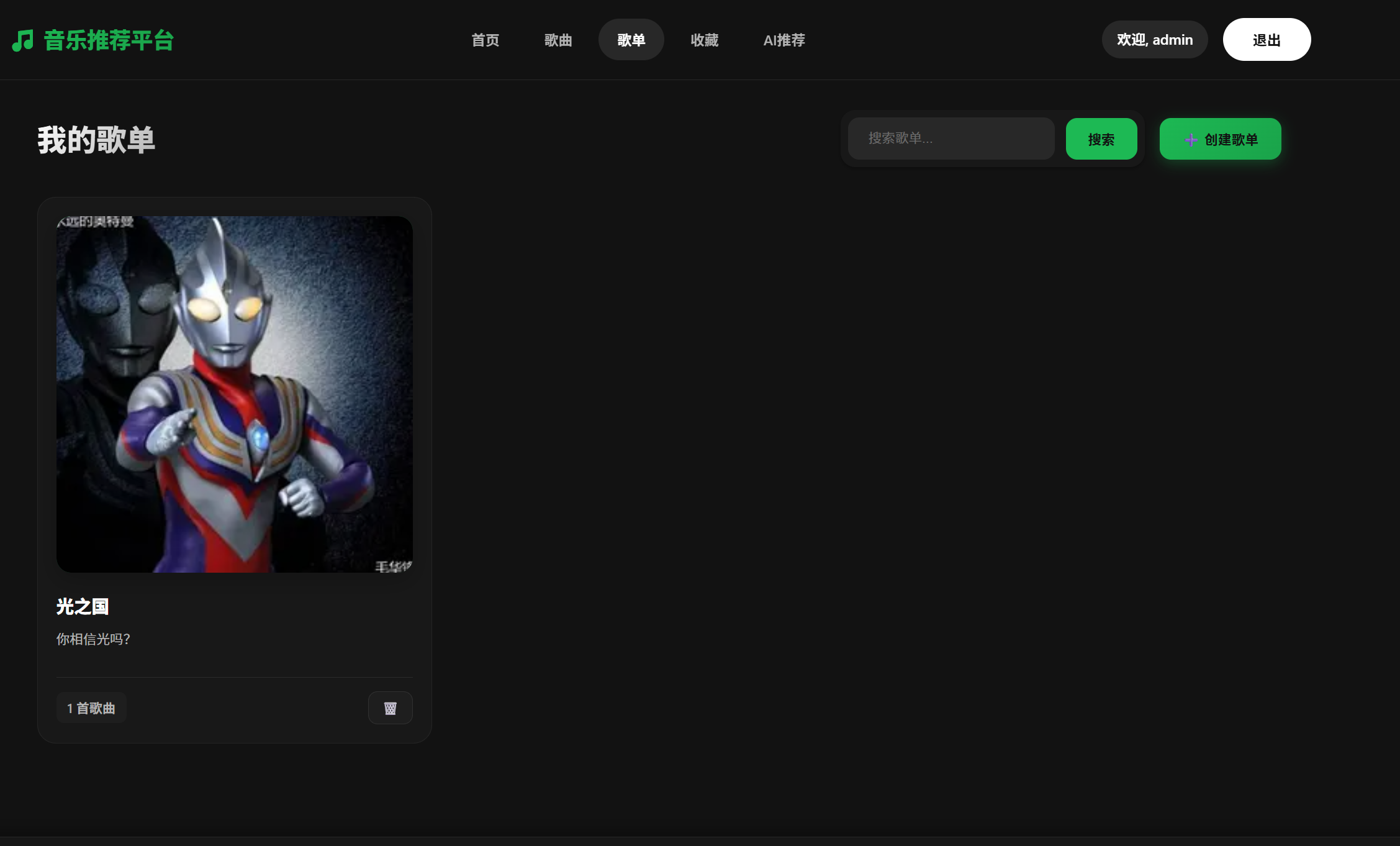
当然,歌单功能也是具备搜索,创建和删除的功能的,这个并不需要管理员权限,是向所有用户都开放的。
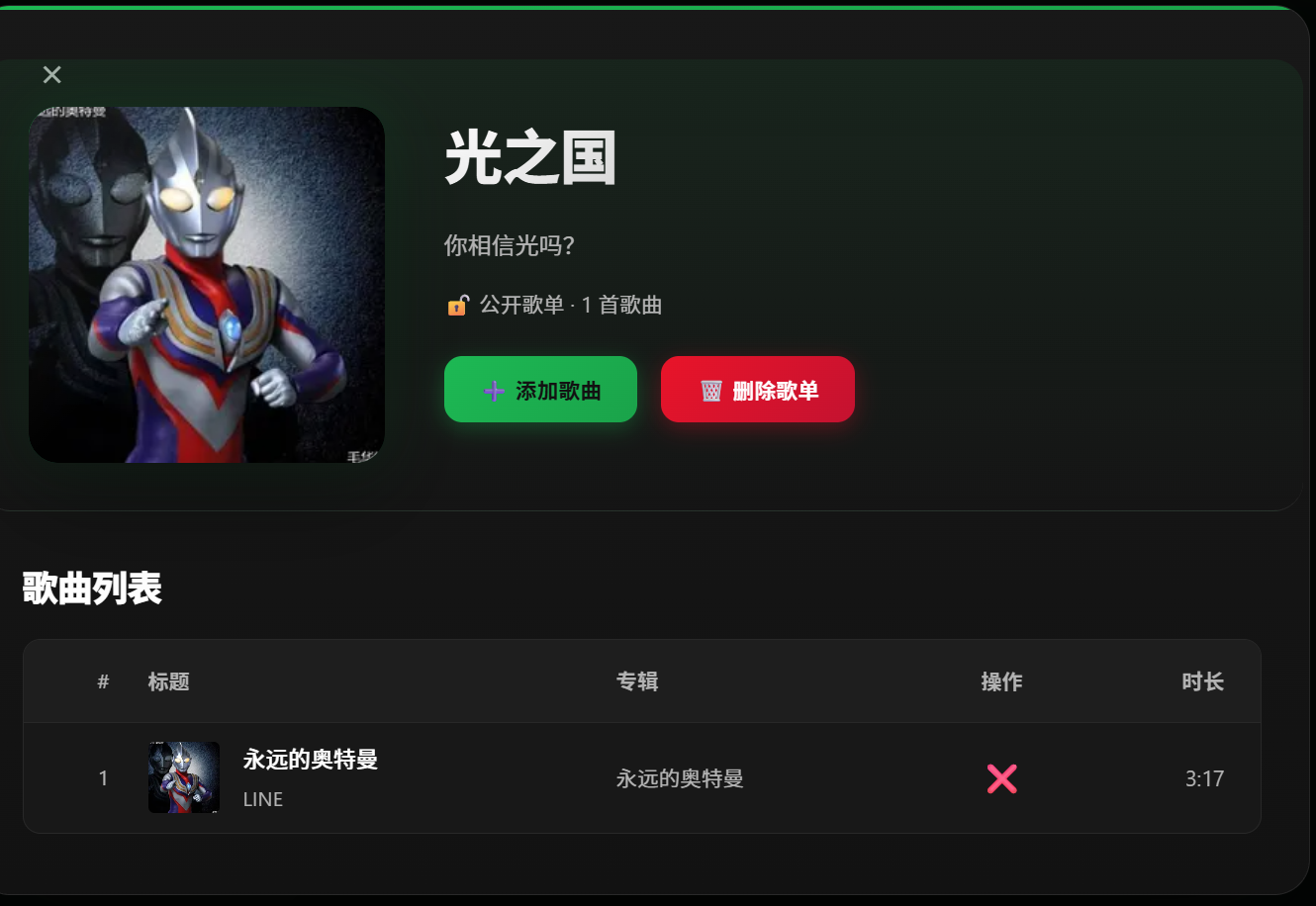
用户点击歌单之后,会弹出歌单的详细数据,里面可以进行歌曲的添加和删除本歌单的功能(删除歌单不会删除歌单本身),添加歌曲的功能也是可以进行搜索的(一切都是为了提升用户体验)
注: 歌曲详情页里面也是可以将歌曲添加到歌单的。
5.收藏页面
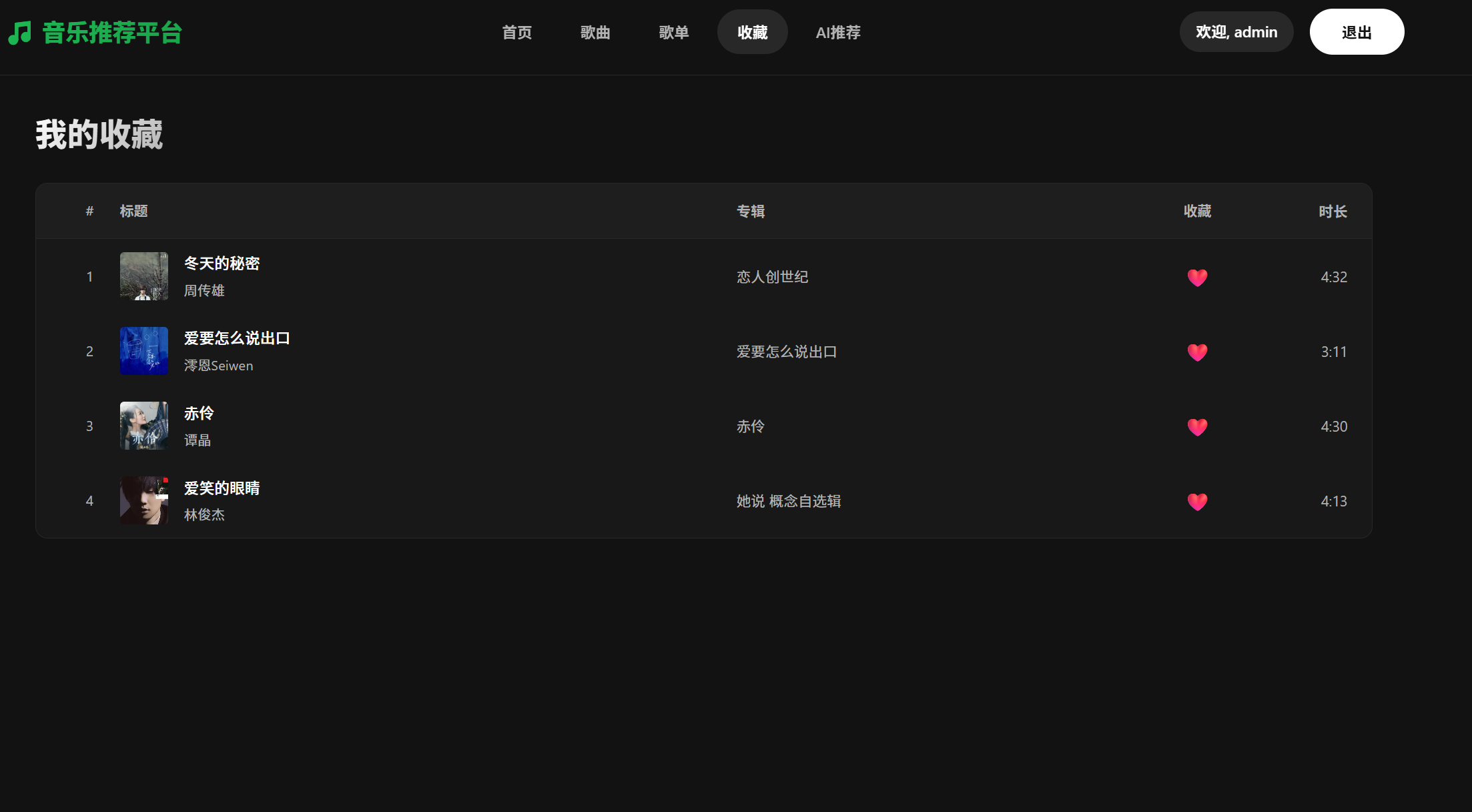
用户在歌曲页面点击歌曲右面的爱心即可把歌曲收藏到本页面,再次点击就是取消收藏,同时收藏页面将不会显示本歌曲
6.AI推荐页面
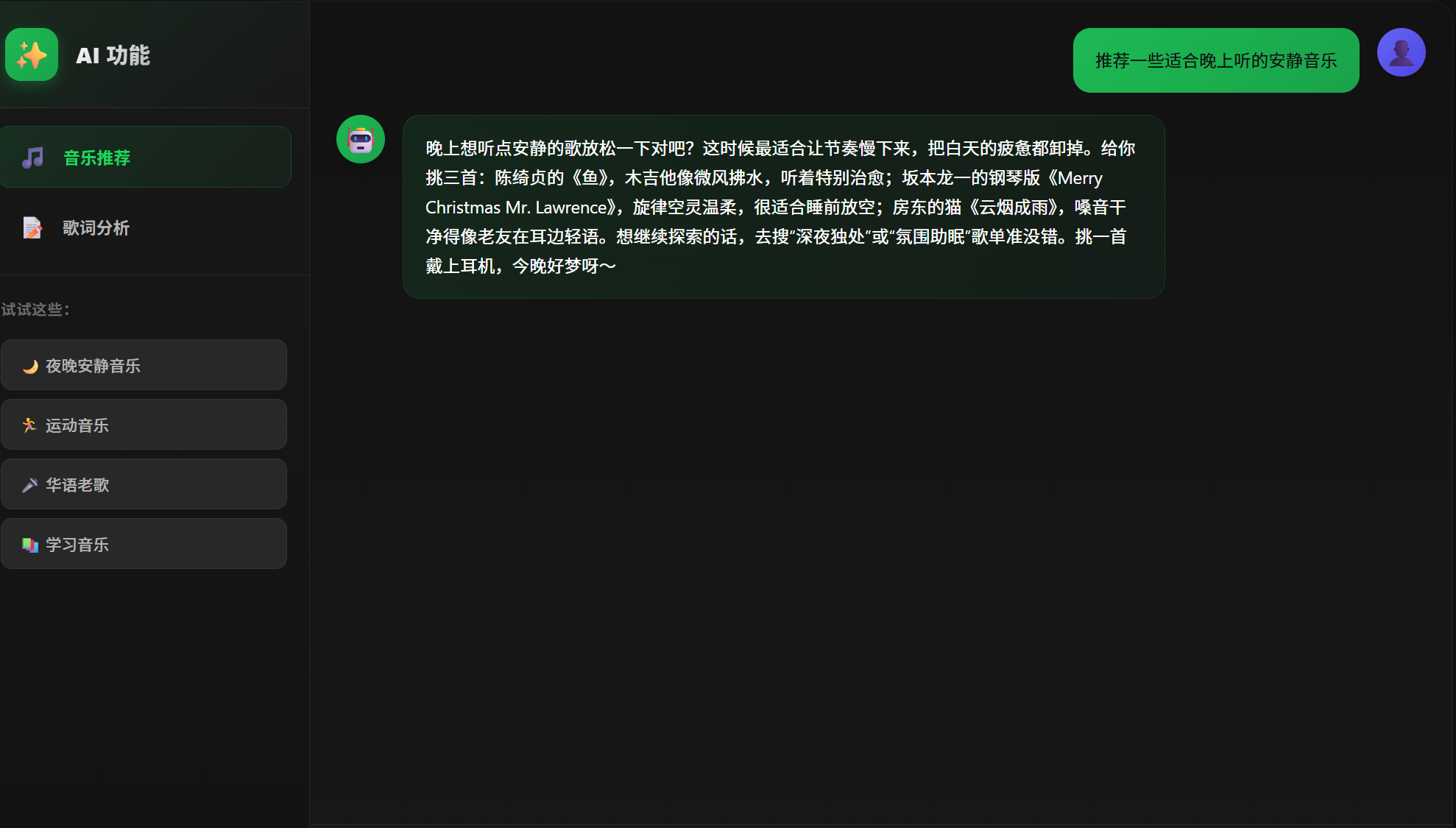
最后则是我们的AI页面,如果用户不知道听什么歌,那么就可以来到本页面,向AI询问,以便找到适合自己的歌曲。当然,如果你不知道怎么问,在页面的左下方还会有提示词给你使用,进一步的优化了用户体验。
八、核心模块的技术讲解
1. 用户认证模块 - JWT无状态认证
认证流程
用户登录请求
↓
验证用户名和密码
↓
生成JWT Token(Header + Payload + Signature)
↓
返回Token给前端
↓
前端存储Token(localStorage)
↓
后续请求携带Token(Authorization: Bearer <token>)
↓
后端验证Token有效性
↓
提取用户信息执行业务逻辑
核心代码
def create_access_token(data: dict):
expire = datetime.utcnow() + timedelta(minutes=30)
to_encode = {"exp": expire, **data}
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
技术要点
-
✅ 使用HS256算法签名Token
-
✅ Token有效期30分钟
-
✅ 密码使用bcrypt自适应哈希
-
✅ 无状态认证,易于水平扩展
2. 歌单管理模块 - 多对多关系设计
数据库模型
playlist_song = Table(
"playlist_song",
Base.metadata,
Column("playlist_id", Integer, ForeignKey("playlists.id"), primary_key=True),
Column("song_id", Integer, ForeignKey("songs.id"), primary_key=True)
)
class Playlist(Base):
__tablename__ = "playlists"
id = Column(Integer, primary_key=True)
name = Column(String(100), nullable=False)
user_id = Column(Integer, ForeignKey("users.id"))
songs = relationship("Song", secondary=playlist_song, back_populates="playlists")
核心业务逻辑
def add_song_to_playlist(db, playlist_id, song_id, user_id):
playlist = get_playlist(db, playlist_id)
if playlist.user_id != user_id:
raise PermissionError("无权操作此歌单")
song = get_song(db, song_id)
if song not in playlist.songs:
playlist.songs.append(song)
db.commit()
return playlist
技术要点
-
✅ SQLAlchemy声明式多对多关系
-
✅ 歌单所有权验证
-
✅ 重复添加检测
-
✅ 事务管理确保数据一致性
3. AI推荐模块 - Dify工作流集成
AI调用流程
用户输入自然语言请求
↓
前端发送POST请求到 /api/ai/recommend
↓
后端封装请求参数
↓
调用Dify API (HTTP POST)
↓
Dify执行工作流:
1. 理解用户意图
2. 查询音乐数据库
3. 调用大语言模型生成推荐
4. 格式化返回结果
↓
后端接收响应并解析
↓
返回格式化结果给前端
↓
前端展示推荐歌曲列表
核心代码
def call_dify_workflow(input_data):
headers = {"Authorization": f"Bearer {DIFY_API_KEY}"}
data = {
"inputs": {"query": input_data},
"response_mode": "blocking",
"user": "music_user"
}
response = requests.post(url, headers=headers, json=data, timeout=300)
return response.json()
技术要点
-
✅ 多输入格式兼容
-
✅ 多重重试机制
-
✅ 超时控制(300秒)
-
✅ 优雅降级处理
九、项目总结展望
1.项目成果
-
✅ 用户认证系统:注册、登录、密码重置、权限管理
-
✅ 歌曲管理系统:浏览、搜索、播放、上传
-
✅ 歌单管理系统:创建、编辑、歌曲管理
-
✅ 收藏功能:收藏/取消收藏、收藏列表
-
✅ AI推荐功能:自然语言推荐、歌词分析
2.技术亮点
-
现代异步框架:FastAPI高性能后端
-
JWT无状态认证:安全高效的身份验证
-
MVC分层架构:清晰的代码组织结构
-
ORM数据操作:SQLAlchemy数据库抽象
-
AI智能集成:Dify平台快速接入
-
自动API文档:Swagger UI自动生成
3.项目数据统计
-
后端代码:20+个Python模块,约1500行代码
-
前端页面:6个HTML页面,约800行JavaScript代码
-
API接口:20+个RESTful接口
-
数据库表:5张核心数据表
4.未来规划
-
性能优化:引入Redis缓存热门数据,优化数据库查询
-
功能扩展:添加社交分享、评论评分系统
-
AI增强:用户行为分析优化推荐算法
-
技术升级:Docker容器化部署、移动端APP开发

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)