从 y = ax + b 到神经网络:为什么 AI 可以被看作函数逼近
把神经网络理解成“复杂函数逼近”,不是说图像识别、翻译、文本生成背后都藏着一个像 y = 2x + 1 这样漂亮的公式。它更像是在给初学者搭一个入口:只要一个任务能被描述成“给定输入,产生输出”,我们就可以先把它看成某种映射,再讨论这个映射如何由数据学出来。
这个入口很朴素,却足够有力。因为神经网络的第一层直觉正是:不要试图手写所有规则,而是构造一个带大量可学习参数的函数,让数据一点点塑造它。
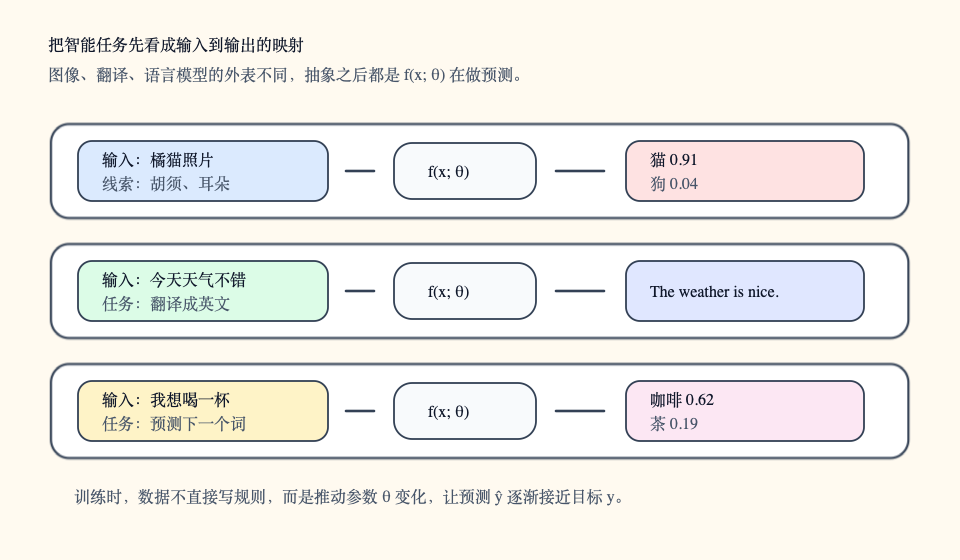
先把任务写成 x 到 y 的映射
函数在这里不是高中数学里那种必须写成显式公式的对象,而是一个更宽泛的说法:输入和输出之间存在某种对应关系。这个关系可能清楚,也可能模糊;可能输出一个确定值,也可能输出一组概率;可能输入是一张图片,也可能输入是一串 token。
图像分类就是一个典型例子。一张彩色图片在计算机里不是“猫”或者“狗”,而是一个由像素值组成的数组。假设图片大小是 224 x 224,每个像素有 RGB 三个通道,那么输入 x 可以看成一个形状为 224 x 224 x 3 的数字张量。模型 f 接收这个张量,输出的不是一句“我觉得是猫”,而通常是一个概率向量,例如“猫 0.91,狗 0.04,狐狸 0.02,其他类别合计 0.03”。从函数视角看,这就是 f(图像像素) = 类别概率分布。
机器翻译也是映射,只是输入输出不再是固定长度的数字表格。输入可能是“我喜欢机器学习”,输出可能是“I enjoy machine learning”。这个函数的难点不在于查词典,而在于它要处理语序、上下文、省略和表达习惯。“我请你吃饭”和“我请你帮忙”里的“请”不是同一种翻译方式,模型必须根据上下文决定输出。
语言模型更适合用概率映射来理解。给定前文 token 序列,例如“今天天气很”,模型不会直接从空气里抽出唯一答案。它会输出下一个 token 的概率分布:好 的概率可能很高,冷、热、糟糕 也有机会出现。模型每次生成一个 token,再把新 token 放回上下文里继续预测下一个 token。看起来像是在写句子,本质上是一连串 前文 -> 下一个 token 概率分布 的函数调用。
这个视角能把很多任务放在同一个框架里。输入 x 进入一个带参数的函数 f(x; θ),输出预测值 ŷ。这里的 θ 表示模型里所有可学习参数,ŷ 表示模型当前给出的答案。训练时,数据集会提供目标答案 y,模型则不断调整 θ,让 ŷ 更接近 y。
手写规则为什么会撞上墙
早期人工智能有一条自然路线:人先总结规则,再让机器照着执行。这个方法在边界明确、规则稳定的任务里很好用。比如发票金额校验、表单字段验证、棋类游戏中的合法走法判断,都可以写出比较可靠的规则。
图像和自然语言的问题在于,变化空间太大。你可以写一条规则说“猫有尖耳朵”,但猫可以趴着、跳着、蜷成一团,也可能被沙发挡住半张脸。你可以继续补规则,“猫通常有胡须”“猫的眼睛比较圆”“猫的尾巴细长”,很快又会遇到反例:有些图片只露出猫背,有些猫在暗光里,有些毛绒玩具看起来也像猫。规则越写越多,系统却越来越脆弱。
自然语言更麻烦,因为词语含义会被上下文改写。“苹果很甜”里的苹果是水果,“苹果发布了新芯片”里的苹果是公司;“这电影不差”可能是温和肯定,也可能是在委婉批评;“你可真行”在不同语气里甚至能表达相反意思。规则系统如果想覆盖所有同义、歧义、省略和语境,就会像给一张漏水的网不断打补丁。
神经网络的做法不是把这些规则一条条写出来。它先给出一个足够灵活的函数结构,再用大量样本调整参数。人不告诉模型“猫的耳朵角度必须在多少度之间”,而是给它看许多猫和非猫的图片,让训练过程自己找到哪些模式对区分类别有用。
这并不意味着模型“自动理解了世界”。更准确的说法是,它从训练数据里学习了输入和输出之间的统计关系。当训练数据覆盖得足够好,模型就可能在新样本上表现不错;当新样本离训练分布很远,模型也会露出短板。
从 y = ax + b 看懂可学习参数
神经网络的参数听起来抽象,可以先从最简单的线性函数看起:
y = ax + b
这里的 x 是输入,y 是输出,a 和 b 是参数。a 控制输入对输出的影响方向和幅度,也就是直线的倾斜程度;b 控制整条线的上下平移。如果 a 是正数,x 越大,y 通常越大;如果 a 是负数,x 越大,y 反而越小;如果 b 变大,同样的 x 会得到更高的 y。在神经网络里,类似 a 这样的参数通常会被叫作权重。
拿“气温预测冰淇淋销量”举例。x 可以是当天最高气温,y 可以是门店卖出的冰淇淋数量。天气越热,销量通常越高,所以 a 大概率是正数。即使气温是 0 度,门店也可能卖出少量冰淇淋,因此 b 可以理解成某种基础销量。真实世界当然不会这么整齐,周末、门店位置、促销活动都会影响结果,但这个例子足够说明参数的意义:函数形状由参数决定。
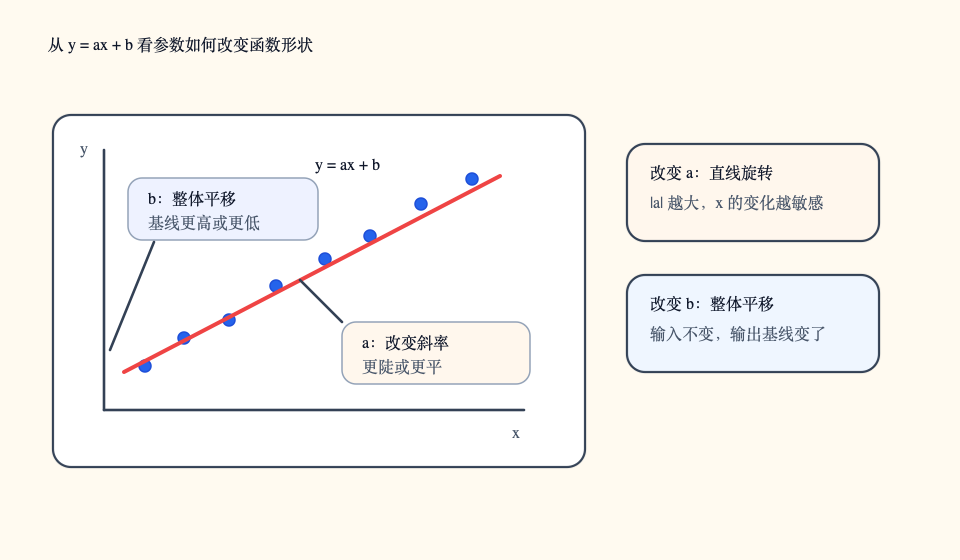
a 改变直线倾斜程度, b 改变直线位置。
训练的第一层直觉也在这里出现。传统程序由人写死 a 和 b,而机器学习让数据推动它们变化。模型一开始随便猜一组参数,用这组参数做预测,发现预测和真实答案之间有误差,就沿着能让误差变小的方向微调参数。反复多次以后,那条线会逐渐贴近数据的趋势。
当输入不止一个数时,可以先把它理解成“多个输入各自乘上一个系数,再加起来”:
y = a1x1 + a2x2 + ... + anxn + b
这里的 x1、x2 到 xn 是不同输入特征,a1、a2 到 an 是对应的可学习系数,b 仍然负责整体平移。图像、文本、语音进入模型以后,都会先被表示成数字向量或张量。线性层的工作就是把这些数字重新加权、组合、平移,生成下一层要处理的新表示。
神经元是一小段可调的计算流程
一个神经元可以看成一小段可调计算。它先把多个输入按不同系数加起来,再把这个中间结果交给下一步处理:
z = a1x1 + a2x2 + ... + anxn + b
这个神经元本身并不神秘,它只是一个带参数的小函数。许多神经元并排放在一起,就得到一层;多层堆叠起来,就得到一个神经网络。先记住这一点:神经网络不是一条公式突然变聪明,而是很多个小函数接力,把输入一步步改写成更容易判断的表示。
这时模型不再只有一个 a 和一个 b,而是有很多可学习系数和偏置。第一层可能把原始输入变成一些低级特征,后面的层继续组合这些特征,形成更抽象的表示。在图像任务中,早期层可能对边缘、方向、颜色块比较敏感,中间层可能组合出纹理或局部形状,后面层才把这些线索汇总成“像猫”或“不像猫”的判断。这个描述是直觉层面的,不是说每一层都能被人清楚命名,但它有助于理解“多层”为什么有意义。
在文本任务里,类似过程发生在 token 表示上。模型先把 token 变成向量,再通过多层计算让向量不断吸收上下文信息。比如“苹果”这个 token,刚进入模型时只是一个初始向量;经过上下文处理后,它在“苹果很甜”和“苹果发布芯片”里的表示会朝不同方向变化。
先让直线弯起来,再理解隐藏层和激活函数
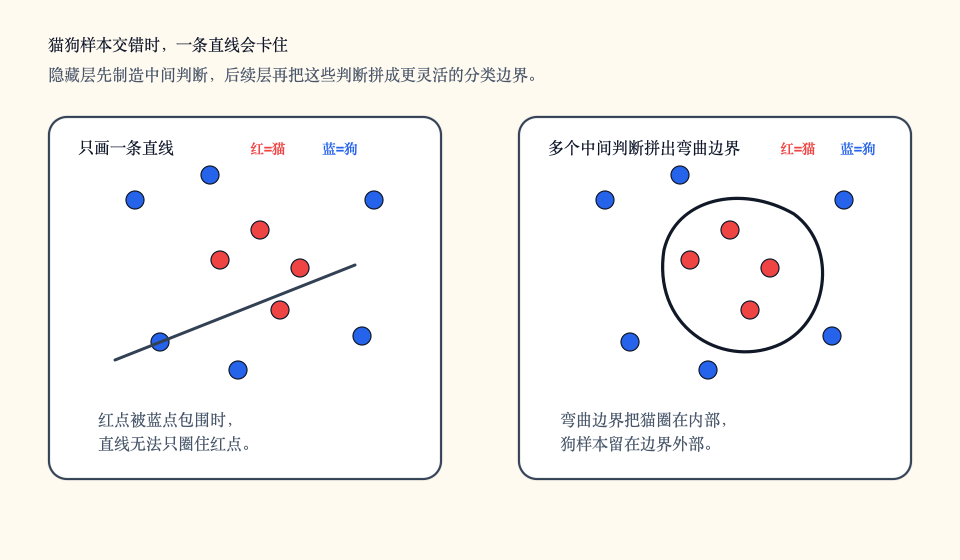
猫狗分类里经常会遇到这种情况:只看两个特征时,一条直线分不开两类样本。模型需要先制造一些中间判断,再把这些判断组合起来,最后形成弯曲的分类边界。
假设我们给图片提了两个很粗糙的特征:x1 表示耳朵尖不尖,x2 表示脸部轮廓圆不圆。有些猫耳朵尖、脸也圆,很容易判断;有些狗也有尖耳朵,某些猫的脸又不明显圆。一条直线只能做一次“一边是猫,一边是狗”的切分,遇到这种交错分布就会别扭。
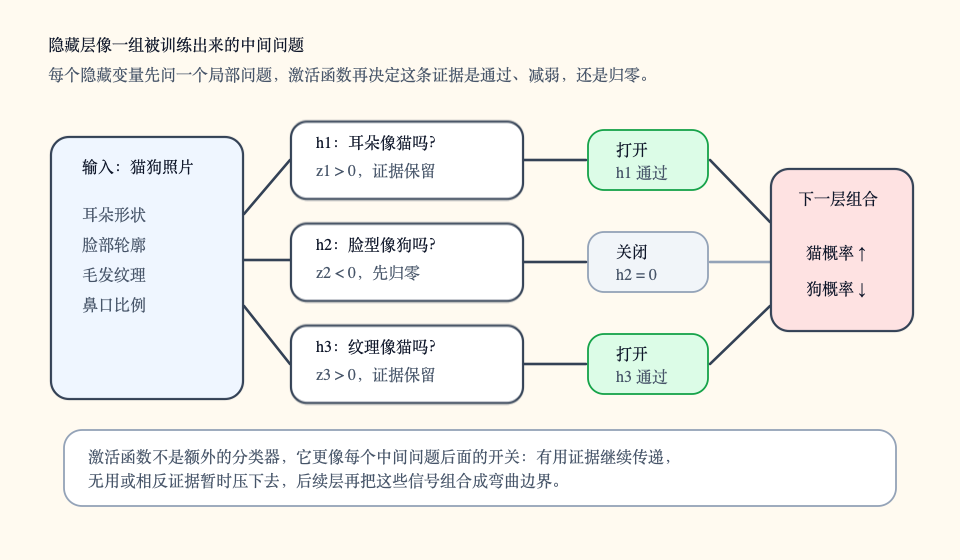
一个自然想法是:别急着直接输出“猫”或“狗”,先引入几个新的中间变量。比如 h1 专门检测“耳朵尖到一定程度了吗”,h2 专门检测“脸部轮廓像不像猫”,h3 专门检测“是否出现胡须和鼻口区域的组合纹理”。这些 h 不在原始数据里,也不是人工标注的答案,而是模型自己在中间层里学出来的信号。
这些中间变量所在的层,就叫隐藏层。它“隐藏”的意思不是神秘,而是它不直接对应输入和标签:训练数据里只有图片和“猫/狗”答案,没有告诉模型 h1、h2、h3 应该长什么样。模型只能通过最终分类误差,倒推这些中间变量怎么设置更有用。
不过,只引入中间变量还不够。如果 h1 = a1x + b1,h2 = a2h1 + b2,最后 y = a3h2 + b3,把式子展开后仍然会变成:
y = ax + b
也就是说,很多层“纯线性计算”叠在一起,最后仍然等价于一条直线。模型看起来变深了,边界却没有真正弯起来。
真正让边界发生弯折的是中间那一步“点亮或压住”的处理。比如某个中间变量算出 z 后,不把 z 原样传下去,而是做一次截断:
h = max(0, z)
如果 z 小于 0,h 就变成 0;如果 z 大于 0,h 才保留下来。它像一个小开关:证据不够时先不发声,证据足够时再把信号传给下一层。这个把中间结果重新处理的函数,就叫激活函数。ReLU 是最常见的激活函数之一,sigmoid 会把数值压到 0 到 1 之间,tanh 会把数值压到 -1 到 1 之间。名字可以晚点记,先抓住作用:它让隐藏层不只是搬运数字,而是能把输入空间折出拐点。
可以把分类边界想成模型在输入空间里画的一条线或一个面。单个线性模型只能画直线或平面。现实数据经常不是这样分布的:一类点可能围成圆环,另一类点可能藏在中间;一类句子可能由多个远距离词共同决定情感,不能只看某个关键词。线性层负责搬运和组合信息,隐藏层负责制造中间信号,激活函数负责给这些信号加上“开关”和“拐点”。三者合在一起,神经网络才有能力逼近复杂函数。
把 PyTorch 示例拆成一次可观察的实验
这个例子仍然使用二维点分类。点落在圆内记为 1,圆外记为 0。选择圆形边界不是为了炫技,而是为了制造一个清楚的对照:一层线性模型只能画直线,多层模型加上 ReLU 才能把边界折成近似圆形。
第一步先造数据。每个样本只有两个输入特征,所以它可以画在平面上;标签由半径决定,所以真正的分界线是一圈圆。
import torch
torch.manual_seed(7)
n = 512
x = torch.rand(n, 2) * 2 - 1
radius_squared = x[:, 0] ** 2 + x[:, 1] ** 2
y = (radius_squared < 0.42).float().unsqueeze(1)
这里的 x 是输入,形状是 [512, 2]。y 是目标答案,形状是 [512, 1]。如果点接近原点,它更可能在圆内;如果点远离原点,它就在圆外。这个规则人知道,但模型不知道,模型只能通过训练样本去逼近这个映射。
第二步定义模型。nn.Linear(2, 16) 把二维坐标变成 16 个隐藏变量,nn.ReLU() 决定哪些隐藏信号继续往后传。
from torch import nn
model = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 16),
nn.ReLU(),
nn.Linear(16, 1),
)
这段结构可以读成一个函数链条:二维输入先被投影成 16 个中间信号,ReLU 把一部分信号压成 0,后面的线性层继续组合这些信号。最后一层输出一个 logit。logit 不是概率,它可以是任意实数;经过 torch.sigmoid 之后,才会变成 0 到 1 之间的概率。
第三步再训练。损失函数负责衡量“预测和答案差多远”,优化器负责根据梯度改参数。
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
for step in range(1000):
logits = model(x)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 200 == 0:
print(f"step={step:4d}, loss={loss.item():.4f}")
训练循环展示了参数如何被数据推动。model(x) 是前向传播,loss_fn(logits, y) 把预测误差变成一个数,loss.backward() 做反向传播,计算每个参数对误差的影响,optimizer.step() 根据这些影响更新参数。读这段代码时,不必先记住所有 PyTorch 细节,先看清楚一件事:模型不是被人手写出圆形边界,而是在误差压力下把参数调到能近似圆形边界的位置。
最后可以拿几个点试一下模型当前学到的函数。
with torch.no_grad():
test_points = torch.tensor([
[0.0, 0.0],
[0.4, 0.2],
[0.9, 0.9],
[-0.8, 0.1],
])
probabilities = torch.sigmoid(model(test_points))
print(probabilities)
如果把模型改成只有一层 nn.Linear(2, 1),它只能学到一条直线边界。面对“圆内 vs 圆外”这种数据,它无论怎么调参数都会别扭。加入隐藏层和 ReLU 后,模型可以先生成一批中间变量,再用这些变量拼出近似圆形的区域。这就是“函数逼近”的具体样子:模型不是拿到一个完美圆公式,而是在参数空间里找到了一个能把训练数据分开的近似映射。
如果希望把这次实验真正跑起来,可以把下面的完整脚本保存为 circle_boundary_experiment.py。仓库里也保留了一份同名示例脚本:examples/circle_boundary_experiment.py。它不依赖数据集下载,运行后会打印训练过程中的 loss、accuracy,以及几个测试点被判为“圆内”的概率。
import torch
from torch import nn
# 1. 固定随机种子,保证每次运行时随机生成的数据和初始参数尽量一致。
# 这不是训练必须条件,但写教程和调试时很有用,因为读者能复现相近的输出。
torch.manual_seed(7)
def make_circle_data(sample_count=512, radius_squared_threshold=0.42):
"""生成一个二维圆形分类数据集。
每个样本是平面上的一个点 (x1, x2)。如果点到原点的距离足够近,
它就属于圆内类别 1;否则属于圆外类别 0。这里用“半径平方”判断,
是为了避免额外开平方,让规则更直接。
"""
# torch.rand(sample_count, 2) 会生成 [0, 1) 区间的随机数。
# 乘以 2 再减 1 后,坐标范围变成 [-1, 1),点会散布在一个正方形里。
x = torch.rand(sample_count, 2) * 2 - 1
# 半径平方 r^2 = x1^2 + x2^2。圆形边界的本质就藏在这个非线性关系里。
radius_squared = x[:, 0] ** 2 + x[:, 1] ** 2
# 小于阈值的点标为 1,大于等于阈值的点标为 0。
# unsqueeze(1) 把形状从 [sample_count] 变成 [sample_count, 1],
# 这样它能和模型输出的 logits 对齐。
y = (radius_squared < radius_squared_threshold).float().unsqueeze(1)
return x, y
class CircleNet(nn.Module):
"""一个很小的多层感知机,用来学习圆形分类边界。"""
def __init__(self):
super().__init__()
# 第一层把二维坐标变成 16 个隐藏变量。
# 可以把这 16 个变量理解成 16 个“中间问题”,例如:
# 点是否在左上方、是否靠近某个方向、是否触发某条局部边界。
self.net = nn.Sequential(
nn.Linear(2, 16),
# ReLU 是激活函数。它会把负数压成 0,正数保留下来。
# 没有这一步,多层线性层叠起来仍然等价于一层线性层,边界很难弯起来。
nn.ReLU(),
# 第二层继续组合上一层产生的中间变量,让局部边界可以拼成更复杂的形状。
nn.Linear(16, 16),
nn.ReLU(),
# 最后一层输出一个 logit。logit 不是概率,可以是任意实数;
# 后面用 sigmoid 才会把它转换成“属于圆内”的概率。
nn.Linear(16, 1),
)
def forward(self, x):
# PyTorch 会在调用 model(x) 时自动进入 forward。
return self.net(x)
def accuracy_from_logits(logits, y):
"""把 logit 转成 0/1 预测,并计算分类准确率。"""
# sigmoid(logit) 得到 0 到 1 之间的概率。
probabilities = torch.sigmoid(logits)
# 二分类里常用 0.5 作为阈值:概率 >= 0.5 判为 1,否则判为 0。
predictions = (probabilities >= 0.5).float()
# predictions 和 y 形状相同,逐个比较后取平均,就是准确率。
return (predictions == y).float().mean().item()
def main():
# 2. 生成训练数据。这里没有 train/test 划分,是为了让示例集中在函数逼近本身。
# 如果要写成正式实验,应该再生成一份独立测试集。
x, y = make_circle_data()
# 3. 创建模型。此时参数是随机初始化的,所以刚开始的预测通常接近乱猜。
model = CircleNet()
# 4. BCEWithLogitsLoss 会把 sigmoid 和二分类交叉熵合在一起算。
# 这样比先 sigmoid 再算 BCELoss 更稳定,也更符合 PyTorch 的常见写法。
loss_fn = nn.BCEWithLogitsLoss()
# 5. Adam 优化器根据梯度更新所有可学习参数。
# lr 控制每次更新走多远;这个小实验里 0.03 收敛较快。
optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
# 6. 训练循环。每一轮都包含前向传播、计算损失、反向传播、更新参数四步。
for step in range(1001):
# 前向传播:把所有二维点交给模型,得到每个点对应的 logit。
logits = model(x)
# 损失函数:把模型输出和真实标签比较,得到一个需要尽量变小的数。
loss = loss_fn(logits, y)
# 清空上一轮留下的梯度。PyTorch 默认会累加梯度,所以每轮训练前要归零。
optimizer.zero_grad()
# 反向传播:计算每个参数对当前 loss 的影响方向和大小。
loss.backward()
# 参数更新:优化器根据梯度调整权重和偏置。
optimizer.step()
if step % 200 == 0:
# 打印中间结果,方便观察模型是不是在真正学习。
accuracy = accuracy_from_logits(logits, y)
print(f"step={step:4d} loss={loss.item():.4f} accuracy={accuracy:.3f}")
# 7. 用几个手工指定的点检查模型学到的函数。
# 前两个点靠近圆心,应该更像圆内;后两个点远离圆心,应该更像圆外。
test_points = torch.tensor([
[0.0, 0.0],
[0.4, 0.2],
[0.9, 0.9],
[-0.8, 0.1],
])
# 推理阶段不需要梯度,torch.no_grad() 可以减少额外开销。
with torch.no_grad():
probabilities = torch.sigmoid(model(test_points))
print("\n测试点被判为“圆内”的概率:")
for point, probability in zip(test_points, probabilities):
x1, x2 = point.tolist()
print(f"point=({x1:+.1f}, {x2:+.1f}) probability={probability.item():.3f}")
if __name__ == "__main__":
main()
可视化扩展:用 MNIST 看模型如何学会识别数字
二维点分类适合讲清楚“边界为什么会弯”,MNIST 更适合把同一套函数视角落到手写数字识别上。MNIST 的输入是一张 28 x 28 灰度图,展开后就是 784 个像素值;输出是 0 到 9 十个类别的概率分布。
这个扩展现在不是静态曲线页,而是一个在线交互演示。读者在页面画一个数字,浏览器会把笔画裁剪、缩放、居中成 28 x 28 的灰度输入,然后用内嵌参数做一次本地前向传播,最后输出预测数字和 0 到 9 的概率条。
可视化页面:在线体验手写数字识别演示
演示页面已经内嵌模型参数、样式和交互逻辑,打开链接即可直接使用。
演示里使用的是一个小型 784 -> 96 -> 10 ReLU 神经网络,在 MNIST 测试集上的准确率约为 98.54%。它足够小,可以完整嵌入单个页面,同时比线性 softmax 分类器更能容忍笔画粗细、轻微偏移和不太标准的手写形态。读者打开页面后,识别过程会在浏览器本地完成,手写内容只参与本地计算,不会发送到服务器。
从函数逼近的角度看,MNIST 仍然是同一件事:模型接收 784 个像素值,通过一组可学习参数输出十个数字类别的概率。页面里那张小的 28 x 28 预览图很重要,它提醒读者模型看到的不是“人脑里的数字”,而是一个像素向量。手写得太靠边、太小、太潦草时,预处理后的向量会偏离 MNIST 训练分布,预测也会跟着变差。
函数视角有用,但别把它用过头
函数逼近是入门深度学习的好入口,因为它把任务、模型、参数和训练统一到了一个清楚框架里。可是这个视角也有边界。
首先,神经网络不是在寻找一个永恒正确的显式公式。很多任务没有单一确定答案,尤其是语言生成。同一句开头可以接出不同风格、不同事实密度、不同情绪的文本。模型输出概率分布,比输出唯一答案更贴近实际机制。温度、采样策略、top-k、top-p 这些推理参数会继续影响最终生成的文字。
其次,模型学到的函数依赖训练数据分布。一个猫狗分类器如果只见过白天、高清、正面拍摄的宠物照片,到了夜间监控、医学影像或者卡通图片上就可能失效。不是函数突然坏了,而是输入离它熟悉的区域太远。很多模型错误,本质上都是“训练时支持的映射”被拿到陌生分布上使用。
再次,函数视角还不能解释深度学习的全部问题。表示学习关心模型内部如何组织信息,概率建模关心不确定性如何表达,优化理论关心为什么巨大的参数空间还能被训练到可用状态。理解 Transformer、大语言模型和多模态模型时,这些视角都会继续出现。
所以,“神经网络是函数近似器”应该被当成第一张地图,而不是整本地图册。它帮助我们知道模型在做什么:接收输入,经过参数化计算,输出预测。后面还要继续追问:参数怎样被学出来,数据怎样影响模型,模型为什么会泛化,又为什么会犯错。
下一步:参数从哪里来
这篇文章把神经网络的第一直觉落在了“用可学习函数替代手写规则”上。线性层提供可调参数,隐藏层制造中间变量,激活函数让这些变量产生拐点,多层结构再把简单计算组合成复杂映射。图像分类、机器翻译和语言模型虽然形态不同,都可以先被写成 x -> f(x; θ) -> y。
接下来真正的问题是训练。既然参数决定了函数形状,模型就必须知道当前形状哪里不好、应该朝哪个方向改。这个问题会把我们带到损失函数、梯度下降和反向传播:神经网络不是凭感觉变聪明,而是在误差的指引下一步步改参数。
名词说明
| 名词 | 解释 | 在本文中的作用 |
|---|---|---|
| 神经网络 | 由可学习参数、层和非线性计算组成的函数族。 | 本文讨论的主要模型形式。 |
| 复杂函数逼近 | 用参数化模型学习输入到输出的近似映射,而不是手写完整规则。 | 解释 AI 任务为什么能被统一成函数视角。 |
| Token | 文本被模型处理前切成的离散片段,可以是字、词、子词或符号。 | 说明语言模型的输入输出单位。 |
| 概率分布 | 对多个可能结果分别给出概率的一组数值。 | 解释分类和语言生成为什么不是只吐出唯一答案。 |
| 参数 | 模型中通过训练更新的数值,常记为 θ。 |
决定函数形状,是训练要调整的对象。 |
| 权重 | 控制某个输入信号影响方向和幅度的参数。 | 用 y = ax + b 类比神经网络里的可调系数。 |
| 偏置 | 在线性计算中控制整体平移的参数。 | 解释为什么同样输入可以被整体抬高或压低。 |
| 线性层 | 对输入做加权求和和平移的网络层。 | 神经网络最基本的信息组合单元。 |
| 神经元 | 接收多个输入、做线性组合并传递结果的小计算单元。 | 帮助读者把网络拆成可理解的局部计算。 |
| 位于输入和输出之间、不直接对应标签的中间层。 | 负责制造模型自己学出的中间信号。 | |
| 激活函数 | 对线性结果做非线性处理的函数。 | 让多层网络能形成弯曲边界。 |
| ReLU | 常见激活函数,定义为 max(0, z)。 |
作为“证据不足归零,证据足够保留”的例子。 |
| Logit | 转成概率之前的原始模型输出,可以是任意实数。 | 解释 PyTorch 二分类示例里最后一层的输出。 |
| 损失函数 | 衡量预测和真实答案差距的函数。 | 为参数更新提供可优化目标。 |
| 优化器 | 根据梯度和更新策略修改参数的算法。 | 让模型沿着误差变小的方向移动。 |
| 前向传播 | 输入按模型结构一路计算到输出和损失的过程。 | 对应训练循环里的 model(x)。 |
| 反向传播 | 从损失出发反向计算参数梯度的方法。 | 对应训练循环里的 loss.backward()。 |
| 训练分布 | 训练样本覆盖的数据范围和统计规律。 | 说明模型为什么在陌生输入上可能失效。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)