【OWLv2】开放词汇目标检测
论文:Scaling Open-Vocabulary Object Detection
OWLv2(Open-World Localization version 2,开放词汇目标检测)
一、技术跃迁:从OWL-ViT到OWLv2
OWLv2是Google DeepMind于2023年提出的开放词汇目标检测模型,收录于NeurIPS 2023。其核心贡献在于通过自训练(OWL-ST,Open-World Localization Self-Training) 将检测训练数据扩展至十亿级,大幅提升了零样本检测性能——在未见过任何人工标注的LVIS稀有类别上,AP从31.2%提升至44.6%(相对提升43%)。最大模型(ViT-G/14)达到47.2%,刷新了当时的业界纪录。
- 论文:Scaling Open-Vocabulary Object Detection(arXiv:2306.09683)
- 官方代码:GitHub - google-research/scenic/projects/owl_vit
- 预训练模型:Hugging Face模型库
- 论文主页:NeurIPS 2023
| 术语 | 全称 | 定义说明 |
|---|---|---|
| OWL | Open-World Localization | 模型命名的核心缩写,代表“开放世界定位”的设计理念 |
| OWL-ViT | Vision Transformer for Open-World Localization | 第一代模型,采用Vision Transformer架构实现开放世界定位 |
| OWLv2 | Open-World Localization version 2 | 第二代模型,架构优化并引入自训练机制,命名中不再包含架构标识 |
| OWL-ST | OWL Self-Training | OWL系列的自训练方法,利用已有检测器生成伪标注进行自我迭代优化 |
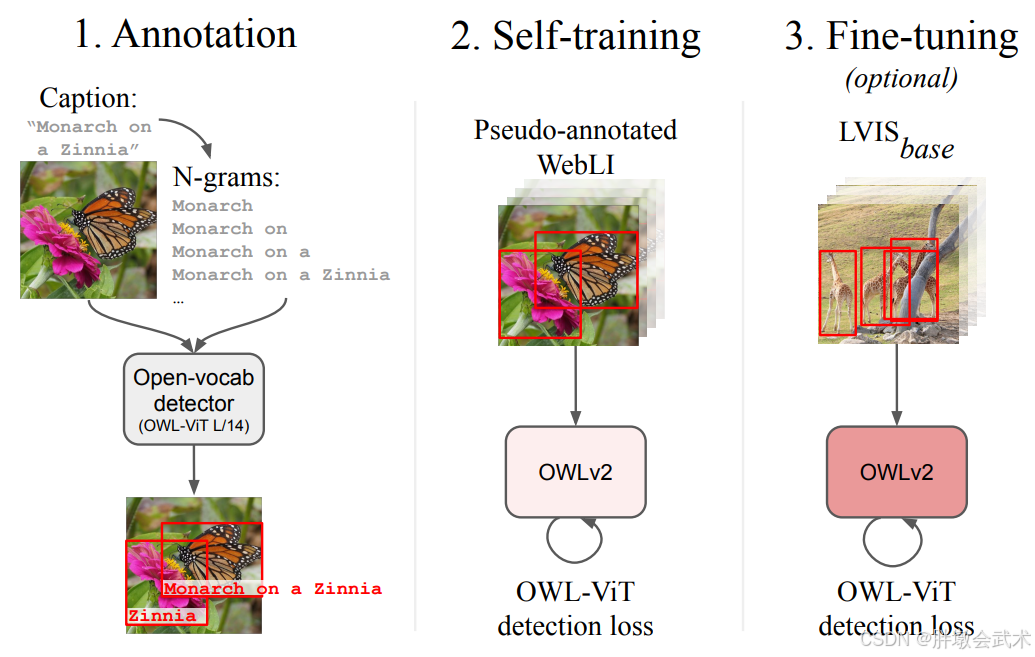
二、三大核心技术支柱
- 双分支跨模态架构:ViT图像编码器 + CLIP风格文本编码器,通过跨模态注意力对齐图文表示,支持任意文本查询。
- OWL-ST自训练:用已有检测器在100亿图文对(WebLI)上生成伪标签,通过N-gram标签空间、宽松置信度过滤(>0.1)、训练效率优化(token dropping、instance selection、mosaics),使训练吞吐量提升2倍。
- 十亿级数据预训练:训练规模超10亿示例,首次实现检测训练的Web级扩展。
三、Image-Guided Detection:one-shot视觉提示的本质
3.1 功能简述
OWLv2支持图像引导检测:给定一张查询图,在目标图中寻找视觉相似的目标。功能实现简单:同时编码查询图与目标图,计算特征相似度匹配。工程优化包括特征层面IoU匹配(提升3~5% mAP)和K-shot平均原型(最优K≈3~5)。
3.2 本质剖析:只换输入,不换核心
这项功能并非为模型增加了一个专用的“以图搜图”算法,而是换了一种方式复用模型固有的能力。可以将OWLv2理解为一个“翻译官”,它擅长将“文本描述”翻译成“视觉特征”来理解目标。Image-Guided Detection所做的,只是在模型内部,将您输入的“图片”也翻译成了相同类型的“视觉查询向量”,然后完全投入到与文本查询相同的检测流程中。
因此,其工作流程本质是特征匹配,关键在于模型对视觉特征的提取和比较能力。它的强大,根植于OWLv2在海量数据上训练出的、对世界广泛而通用的视觉表征能力;它的脆弱,则暴露了这种能力在面对完全陌生领域时的知识边界。
3.3 与文本引导的对比
| 对比维度 | 文本引导检测 (Text-Guided) | 图像引导检测 (Image-Guided) |
|---|---|---|
| 查询输入 | 自然语言文本(如:“一只戴红帽子的狗”) | 一张或多张参考图像 |
| 核心转换 | 模型内部的文本编码器将文字转换为语义向量 | 模型内部的图像编码器将图片转换为视觉特征向量 |
| 技术本质 | 零样本 (Zero-Shot) 学习:理解未曾见过的类别概念 | 单次/少次 (One/K-Shot) 学习:从有限的视觉示例中学习 |
| 对模型的依赖 | 极大依赖于视觉-语言的跨模态对齐能力 | 极大依赖于视觉-视觉的特征匹配能力和骨干网络的表征能力 |
3.4 跨域脆弱性:在专业图像中会失效
由于完全依赖模型从海量网络图片中学到的表征,Image-Guided Detection在面对分布外 (Out-of-Distribution) 的图像时,性能会急剧下降:
- 在熟悉的自然领域:模型表征空间里储备了丰富的特征模式,表现稳定。
- 在陌生的专业领域(如电镜):模型从未见过“晶格”、“位错”这类视觉模式,无法提取有效的匹配特征。
一个有力的证据来自航空图像的零样本检测研究:当检测类别从80类缩减到约3类时,模型性能实现了15倍的大幅提升。这清晰地表明,OWLv2图像引导的瓶颈根本不在于相似度匹配算法本身,而在于其语义表征能力在跨域时的匮乏。
四、模型对比:OWLv2 vs Grounding DINO vs SAM
| 维度 | OWLv2 | Grounding DINO | SAM |
|---|---|---|---|
| 核心定位 | 开放词汇检测 | 开放集检测+短语定位 | 通用提示式分割 |
| 输出 | 边界框+标签 | 边界框+短语 | 像素掩码 |
| 交互方式 | 文本/图像引导 | 文本(复杂短语) | 点、框、掩码 |
| 对专业图像适应性 | 弱(依赖自然图像预训练) | 弱 | 强(不依赖语义) |
| 典型协同 | 作为SAM的提示生成器 | 作为SAM的提示生成器 | 细化检测框为掩码 |
| 推理速度 | 快 | 较慢 | 中等 |
协同工作流:OWLv2(或Grounding DINO)→ 边界框 → SAM → 精细掩码。已验证案例:密集牛群分割,准确率提升27.13%。
五、在专业科学图像中的局限
- 数据分布偏移:OWLv2预训练于自然图像,对电镜等灰度、低信噪比图像泛化能力有限。
- 专业术语理解:对“位错”“孪晶”等材料学术语响应不佳。
- 类别长尾问题:专业结构在互联网图像中几乎不存在,自训练数据无法覆盖。
- 本质原因:其图像引导检测的性能完全依赖预训练获得的视觉表征,而专业图像的表征不在其知识范围内,因此无法作为可靠的解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)