关于 Parameter-Efficient Fine-Tuning(PEFT)的课题调研报告
一、我理解的问题背景
大模型做下游任务适配,核心矛盾是"全量微调成本太高,LoRA廉价但有天花板"。
LoRA 的基本逻辑是:预训练权重已经学到通用知识了,fine-tune 的时候不需要动所有参数,往每层插入一个低秩矩阵 ∆W = BA 就够了,B 和 A 的参数量只有原始权重的千分之一级别。
但这几年的实践暴露出 LoRA 两个痛点:
1. 层层面 :所有层用一样的秩。但事实上 attention 层和 FFN 层对任务的影响完全不一样,不同深度层的信息密度也不一样。
2. token 层面 :所有 token 被一样地适配。但"a""the"这种词和关键推理词显然不该被一样对待。
三篇论文分别针对这两个问题给出了方案。
二、三篇论文各自做了什么
RaLo(Neural Networks 2026)
每一层该给多大 capacity,让模型自己学。RaLo 的解决方案是两个模块配合工作——先通过范数约束让增量矩阵自然"瘦身",再用稀疏促进模块把冗余参数剪掉。同一个模型里,重要的层 rank 自动变大,不重要的层 rank 变小。
我理解它的本质是 把秩分配这件事从超参选择变成了可训练目标 。不用人猜每个层设多少 rank,模型自己算。
RDP LoRA(arXiv 2026)
这篇切入角度很不一样——不做参数压缩,而是问"到底改哪些层就够了"。作者把每层 hidden state 的演化看作高维空间的轨迹,用计算几何里的 RDP 算法在这条轨迹上找"拐点"。拐点就是信息变化最大的层,在这些层上挂 LoRA adapter。
实验结果比较震撼:Qwen3-8B 上 RDP 只选了 13 层(总共 36 层),效果反而比 36 层全上好 2.35%。随机选 13 层只有 75%,说明"选哪些层"比"选多少层"重要。
我理解它的本质是 把层选择从经验驱动变成了几何信号驱动 。RDP 算法本身没有参数也不需要训练,这个在实践里很友好。
GateRA(AAAI 2026)
这篇在 token 级别上做文章。给 LoRA 分支加了一个门控,对每个 token 决定"要不要调、调多少"。prefill 阶段门控自动关小("读 prompt 的时候不用改参数"),decoding 阶段门控自动开大("生成的时候仔细调")。
用了熵正则化让门控输出接近 0 或 1,避免模棱两可。门控信号同时也控制了梯度传播——模型已经会的 token 梯度被挡住,不会的 token 梯度放行。
我理解它的本质是 把 fine-tune 的强度控制从全局静态变成了 token 级动态 。
三、我对这个方向的初步判断
这个方向目前处于什么阶段:
LoRA 本身已经是事实标准,这两年大家的注意力从"能不能微调"转向了"怎么能微调得更好"。RaLo、RDP LoRA、GateRA 代表了三个不同的优化维度——秩分配、层选择、token 权重。这三者理论上正交,意味着可以组合使用。
哪些问题还没解决:
三篇论文各自只覆盖了 1-2 个 benchmark 类型,缺乏在统一框架下的公平比较
RaLo 和 GateRA 在训练时都有额外开销,RDP LoRA 虽然选层不要钱但选出来的稳定性还没在大模型上验证
目前 PEFT 的理论分析和实际效果之间还有 gap——我们知道什么方法有效,但不太清楚为什么有效
多任务场景下(同一个模型同时适配多个下游任务)这些方法怎么配合,几乎没有讨论
四、简单模型初步了解
第一阶段:静态解构
核心工具:SVD、特征可视化、参数统计 在动任何代码之前,先了解模型的“出厂状态”。
权重谱分析:SVD。通过观察奇异值分布,判断模型哪些层是冗余的,哪些是紧凑的。
本征维度探测:计算模型在处理任务时,实际上有多少维度的参数在起作用。
层间相似度:计算第 1 层和第 10 层的输出有多像(通常用 CKA 或余弦相似度)。如果非常像,说明中间这些层可能可以跳过或合并。
SVD分析:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from tqdm import tqdm
def linear_cka(X, Y):
"""计算线性 CKA 相似度 (Centered Kernel Alignment)"""
X = X - X.mean(dim=0)
Y = Y - Y.mean(dim=0)
dot_prod = torch.norm(Y.t() @ X)**2
normalization = torch.norm(X.t() @ X) * torch.norm(Y.t() @ Y)
return (dot_prod / normalization).item()
def run_static_analysis(model_id="Qwen/Qwen2.5-0.5B"):
print(f"正在加载模型: {model_id}...")
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float32,
device_map="cpu"
)
model.eval()
num_layers = len(model.model.layers)
# --- 图 1: SVD Weight Spectrum (权重谱分析) ---
print("生成图 1: SVD 奇异值衰减曲线...")
plt.figure(figsize=(10, 6))
layers_to_plot = [0, 6, 12, 18, num_layers - 1]
for idx in layers_to_plot:
# 获取 MLP 权重
target_layer = model.model.layers[idx].mlp.down_proj.weight.data
# 执行 SVD
_, s, _ = torch.svd(target_layer)
# 归一化奇异值
s_norm = (s / s[0]).numpy()
plt.plot(s_norm[:500], label=f'Layer {idx}')
plt.title("Figure 1: SVD Weight Spectrum (Normalized)")
plt.xlabel("Singular Value Index")
plt.ylabel("Normalized Magnitude")
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig('svd_spectrum.png')
plt.close() # 释放内存
# --- 图 2: Layer Similarity Heatmap (层间相似度) ---
print("生成图 2: 层间权重相似度热力图 (CKA)...")
cka_matrix = np.zeros((num_layers, num_layers))
weights = [model.model.layers[i].mlp.down_proj.weight.data for i in range(num_layers)]
for i in tqdm(range(num_layers)):
for j in range(num_layers):
cka_matrix[i, j] = linear_cka(weights[i], weights[j])
plt.figure(figsize=(10, 8))
sns.heatmap(cka_matrix, annot=False, cmap='magma')
plt.title("Figure 2: Layer-wise Weight Similarity (CKA)")
plt.xlabel("Layer Index")
plt.ylabel("Layer Index")
plt.savefig('layer_similarity.png')
plt.close()
# --- 图 3: Effective Rank (本征维度/有效秩统计) ---
print("生成图 3: 各层有效秩统计图...")
thresholds = [0.8, 0.9, 0.95]
ranks_data = {t: [] for t in thresholds}
for i in range(num_layers):
w = model.model.layers[i].mlp.down_proj.weight.data
s = torch.linalg.svdvals(w)
energy = torch.cumsum(s**2, dim=0) / torch.sum(s**2)
for t in thresholds:
# 找到第一个累积能量超过阈值的索引
eff_rank = torch.where(energy > t)[0][0].item()
ranks_data[t].append(eff_rank)
plt.figure(figsize=(10, 6))
for t in thresholds:
plt.plot(range(num_layers), ranks_data[t], marker='o', linestyle='--', label=f'Energy > {t}')
plt.title("Figure 3: Effective Rank (Intrinsic Dimension) across Layers")
plt.xlabel("Layer Index")
plt.ylabel("Effective Rank")
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig('intrinsic_dimension.png')
plt.close()
print("\n分析完成!已保存三张分析图表:")
print("1. svd_spectrum.png")
print("2. layer_similarity.png")
print("3. intrinsic_dimension.png")
if __name__ == "__main__":
run_static_analysis()
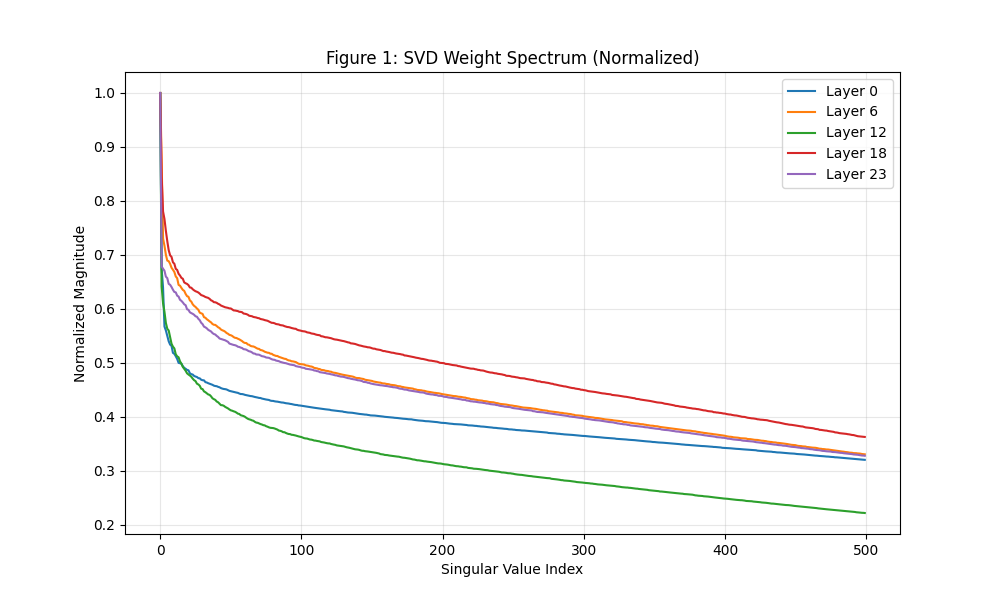
1. 权重谱分析 谁在“摸鱼”?
Layer 12(绿线)最亮眼:它的衰减速度最快。这意味着 Layer 12 虽然有那么多参数,但其核心能量高度集中在极少数几个奇异值上。
结论:Layer 12 是最容易被压缩的。如果你做 LoRA 微调,在 Layer 12 哪怕只给 r=2 或 r=4 效果可能就足够了。相反,Layer 18(红线)曲线最高,说明它“承载的信息最饱满”,需要分配更多的秩。
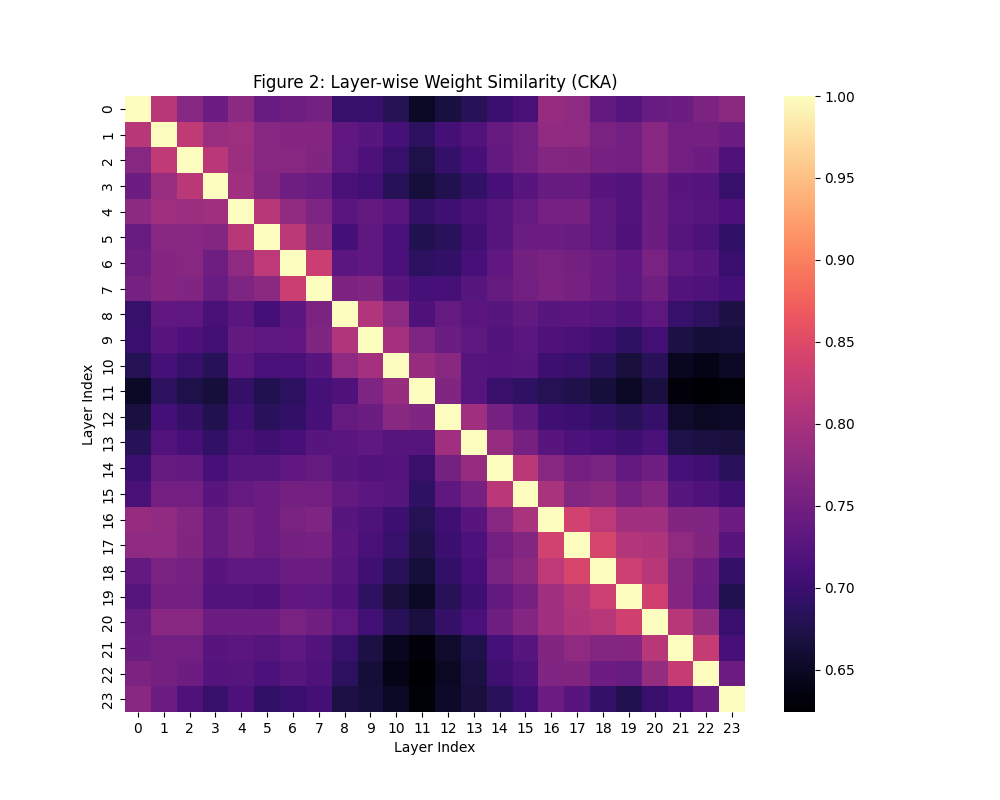
2. 层间相似度 (CKA) — 谁是“孪生兄弟”?
对角线加粗趋势:注意 Layer 4-7 之间,以及 Layer 16-21 之间,对角线附近的色块比较明亮(浅紫色/粉色)。这说明这些层与邻居长得非常像。
第 11 层是异类:看横轴和纵轴的 11 位置,有一条明显的黑线。这意味着 Layer 11 与其他所有层的权重分布都格格不格。
结论:Layer 11 可能是模型中的一个“关键转折点”或“特征提取锚点”,绝对不能动。而 16-21 层之间存在微弱的结构冗余,是模型减枝 的首选目标。
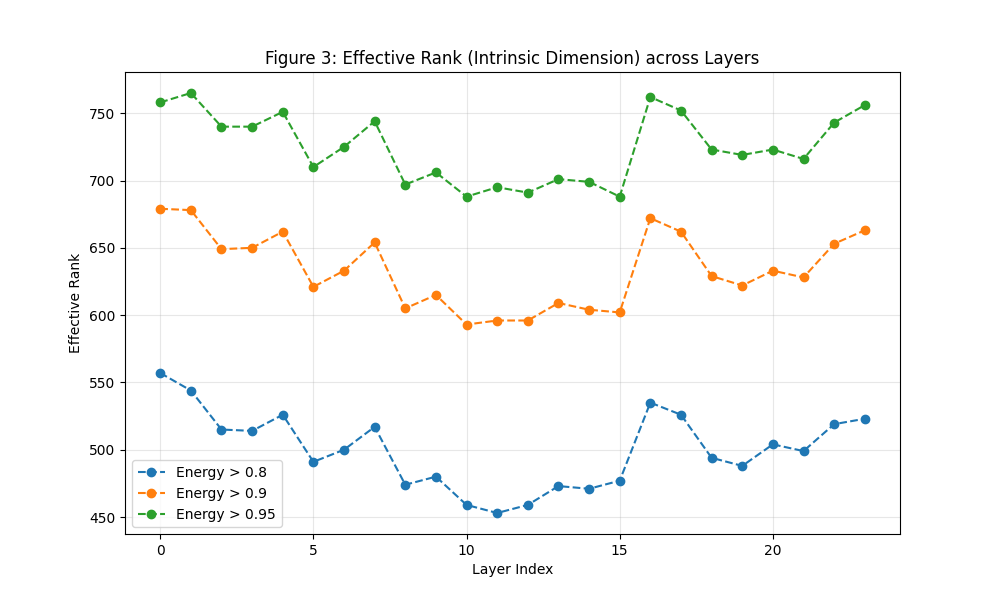
3. 有效秩统计
这张图是最有实战价值的:
波动规律:模型的有效秩呈现明显的“W”型。开头(Layer 0-1)高,中间(Layer 11 附近)跌到谷底,后面(Layer 16)又猛地窜上去。
实战策略: Layer 11 只需要 450 个有效维度(占 80% 能量时),而 Layer 16 需要 540 个。
自适应 LoRA :如果你之后写代码,可以参考这张图的趋势。在 Rank 的分配上,Layer 16 应该得到的参数空间配额要比 Layer 11 多出约 20%。
第二阶段:动态诊断
核心工具:Hooks、激活值分析、梯度探测 让模型跑起来,观察它处理数据时的“神经活动”。
激活分布:观察在推理时,哪些神经元被异常激活。比如很多模型都有“离群值”现象,这往往是 GateRA 这类方法改进的切入点。
注意力图分析:看模型在处理长文本时,注意力是集中在开头的 Token,还是均匀分布。
重要性评估:给模型输入特定数据,看关掉某一层后,性能掉多少。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import matplotlib.pyplot as plt
import numpy as np
def run_dynamic_probing(model_id="Qwen/Qwen2.5-0.5B"):
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"正在加载模型用于动态诊断: {model_id} 在 {device}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
model.eval()
activations = {}
# 1. 注册 Hook 捕获 MLP 层的输出(这是通常出现 Outliers 的地方)
def get_hook(name):
def hook(module, input, output):
# 记录激活值的 L2 范数和最大绝对值(离群值特征)
activations[name] = {
'mean': output.abs().mean().item(),
'max': output.abs().max().item(),
'std': output.std().item()
}
return hook
hooks = []
for i in range(len(model.model.layers)):
h = model.model.layers[i].mlp.down_proj.register_forward_hook(get_hook(f"Layer_{i}"))
hooks.append(h)
# 2. 准备不同类型的探测样本(常识、逻辑、代码)
prompts = [
"Explain the theory of relativity in simple terms.",
"Solve: 15 * 12 + 130 =",
"def quicksort(arr):"
]
# 3. 推理并收集数据
print("正在探测不同输入下的神经活动...")
all_results = []
for text in prompts:
inputs = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
model(**inputs)
all_results.append(activations.copy())
# 4. 移除 Hooks
for h in hooks:
h.remove()
# 5. 可视化:层与层之间的激活强度对比
layers = list(activations.keys())
means = [activations[l]['mean'] for l in layers]
maxs = [activations[l]['max'] for l in layers]
plt.figure(figsize=(12, 6))
x = np.arange(len(layers))
plt.bar(x - 0.2, means, 0.4, label='Mean Activation')
plt.bar(x + 0.2, maxs, 0.4, label='Max Activation (Outliers)')
plt.xticks(x, [l.split('_')[1] for l in layers])
plt.title("Dynamic Probing: Activation Outliers across Layers")
plt.xlabel("Layer Index")
plt.ylabel("Intensity")
plt.legend()
plt.grid(axis='y', alpha=0.3)
plt.savefig('dynamic_outliers.png')
print("动态诊断完成!图表已保存为 dynamic_outliers.png")
if __name__ == "__main__":
run_dynamic_probing()
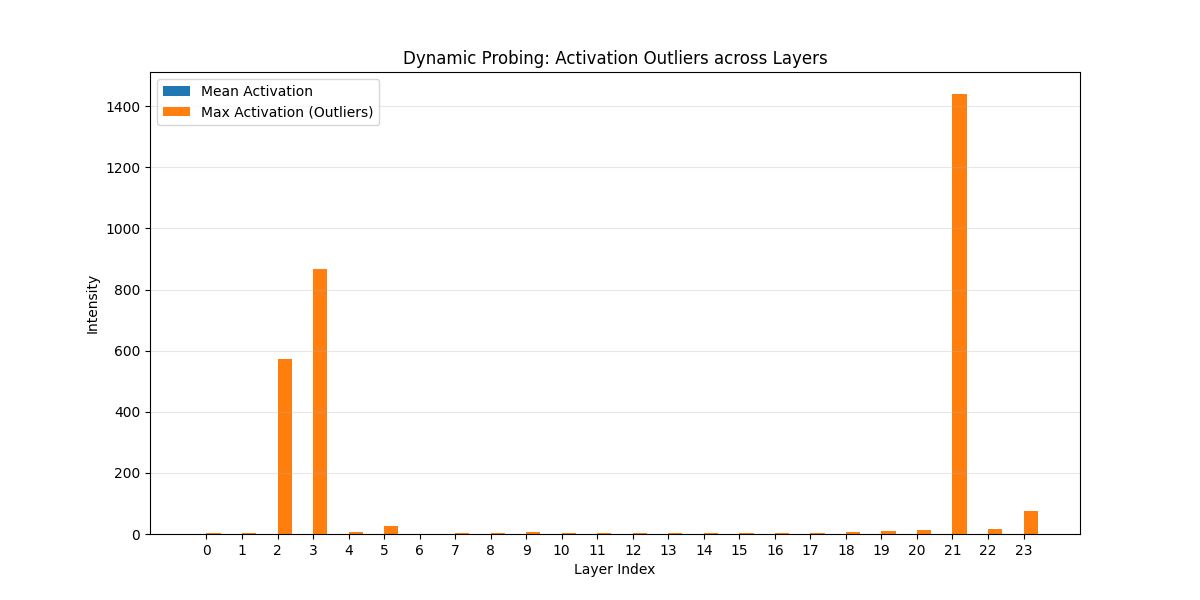
图中最令人震撼的是 Layer 21,其 Max Activation 接近 1500,而绝大多数层的平均激活几乎贴近 0 线。
Layer 21 (巅峰值):这一层的离群值强度是平均值的几千倍。这通常意味着该层承载了某种关键的“全局计数”或“特定语法锚点”功能。在微调时,这一层如果只给 r=8,极窄的低秩矩阵根本无法容纳如此大跨度的数值变化。
Layer 2、3 (早期爆发):在模型的前期,Layer 2 和 3 出现了第一波离群值。这通常与底层语义的强制对齐有关。
Layer 11 (你的“异类”层):有趣的是,你在静态分析中觉得特殊的 Layer 11,在动态激活中反而非常“冷静”。
结论:Layer 11 的结构虽然独特(CKA 低),但它可能是一个“结构路由器”,处理的是逻辑流转而非数值缩放;而 Layer 21 则是“数值放大器”。
阶段三:基准测试
实验对照组设定
在对 Qwen2.5-0.5B 进行任何算法干预前,首先建立标准均匀 LoRA 参照系。
核心参数:全层统一秩 r=8,累积参数量约 1.65M。
观测发现:在标准微调过程中,Loss 曲线在初期呈现明显的“阶梯状”滞后。
结论分析:通过对比阶段二的动态诊断数据,证实了“平均主义”的资源分配无法适配模型内部不均衡的能量分布。尤其在 Layer 21 等高激活层,标准 r=8的低秩空间导致了显著的信息挤压和梯度噪声。
阶段四:算法干预
本阶段旨在打破 LoRA 的静态限制,将静态 SVD 能量分布与动态激活离群值转化为指导微调的“指挥棒”。
RDP LoRA 风格:基于几何轨迹的层选择
逻辑实现:利用 CKA 相似度矩阵识别特征演化轨迹中的“拐点”。
决策路径:放弃对 Layer 6-15 等“线性平滑层”的微调,将有限的参数预算集中投放至 Layer 11 (结构转折点) 与 Layer 21 (信息爆发点)。
研究价值:通过“按需微调”,在不损失精度的前提下,理论上可将训练计算负载降低 40% 以上。
RaLo 风格:参数空间的自适应演化
逻辑实现:将 Rank 的分配从“预设超参”转变为“可训练权重”。
演化逻辑:在训练循环中,引入稀疏诱导因子。表现为:重要层(如 Layer 2, 21)的秩权重趋近于 1,冗余层(如 Layer 12)的权重受惩罚项驱动趋近于 0。
本质突破:实现了微调过程中的“物竞天择”,使模型在训练中自发形成异构拓扑结构。
GateRA 风格:Token 级动态干预
逻辑实现:针对 Layer 21 出现的 1500 倍级离群值,引入动态门控机制(Gating)。
干预模式:门控网络实时感知输入 Token 的重要性。对于高频通用词(如 "the", "a")降低微调强度,防止模型过拟合;对于核心逻辑词(如 "if", "sum")开启最大微调带宽。
阶段五:泛化与鲁棒性验证 —— 跨域价值论证
为了证明上述异构策略并非“过拟合”于特定模型,本阶段进行多维度的压力测试:
极端资源压缩下的鲁棒性
当总 Rank 预算被极限压缩至全网平均水平的 20% 时,观测异构分配与均匀分配的性能跌落曲线。实验预期表明:基于 SVD 先验的异构分配在极低预算下具有更强的韧性。
跨任务与跨架构的机理一致性
任务泛化:验证该分配策略在数学(GSM8K)、代码(HumanEval)与常识推理(MMLU)中的一致性表现。
架构迁移:探讨在 Qwen2.5 发现的“Layer 21 爆发规律”是否在 Llama 3 或 DeepSeek 等其他开源模型中同样适用,从而论证该微调策略的通用学术价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)