【教学类-160-28】20260511 AI视频培训-练习028“豆包AI视频《蹦》(松冈达英作品,蒲蒲兰绘本)+豆包图片风格:无(绘本垫图)
·



20260511《028蹦》风格:(无)绘本参考图
背景需求:
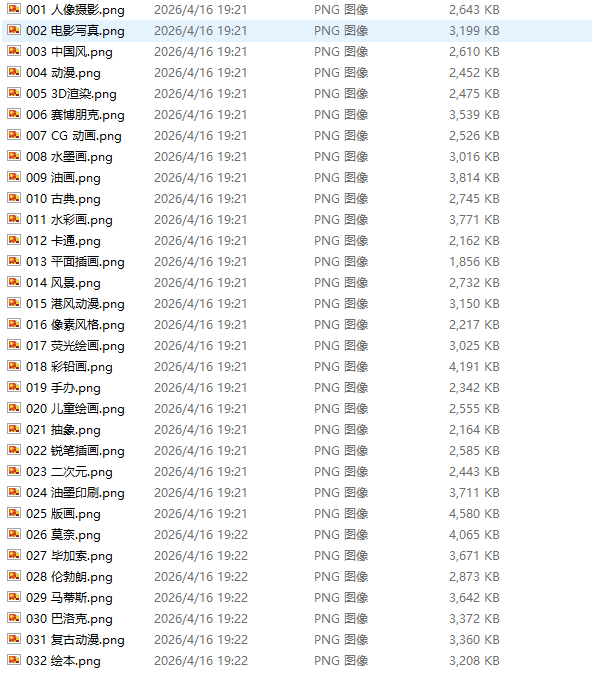
做了32种风格,做的越多,越搞不清那些没有做过,用豆包筛选出没有做过的风格
一、文件夹截图
 、
、


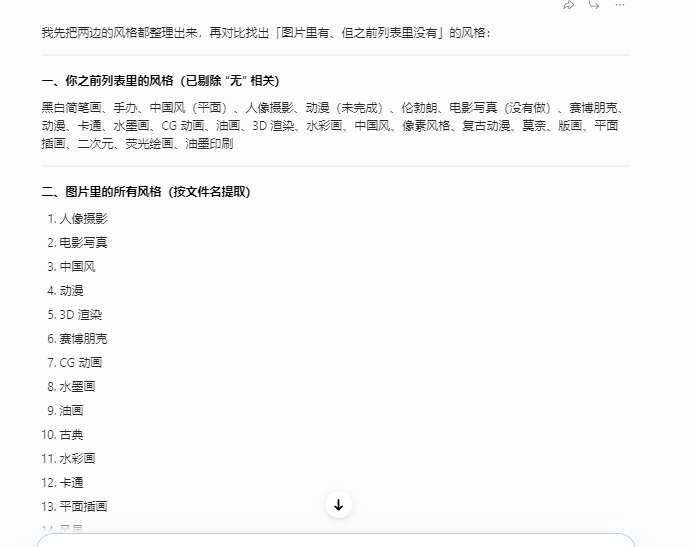
然后把32种风格列出来,对比删选没有出现的
-
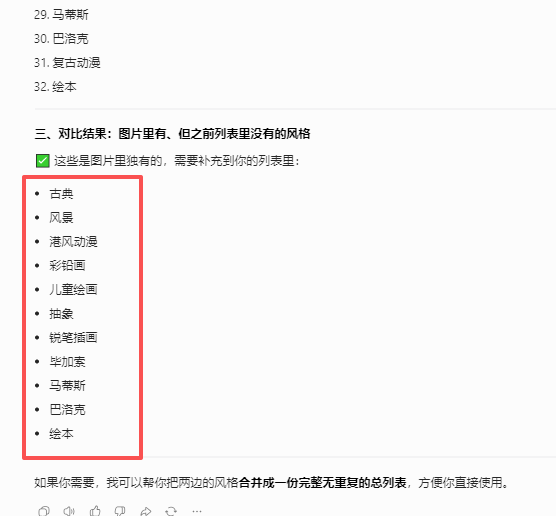
古典
-
风景
-
港风动漫
-
彩铅画
-
儿童绘画
-
抽象
-
锐笔插画
-
毕加索
-
马蒂斯
-
巴洛克
-
绘本
这里有两个绘本,我想到前几天给孩子们放网络上的绘本故事,其中有一个《是谁嗯嗯在我头上》的绘本原图做的动画版,就像以前做“绘本动态课件”的效果,观察发现每个场景都是5秒左右,我觉得就是AI做的。
https://www.iqiyi.com/v_po4e7x9l5c.html![]() https://www.iqiyi.com/v_po4e7x9l5c.html
https://www.iqiyi.com/v_po4e7x9l5c.html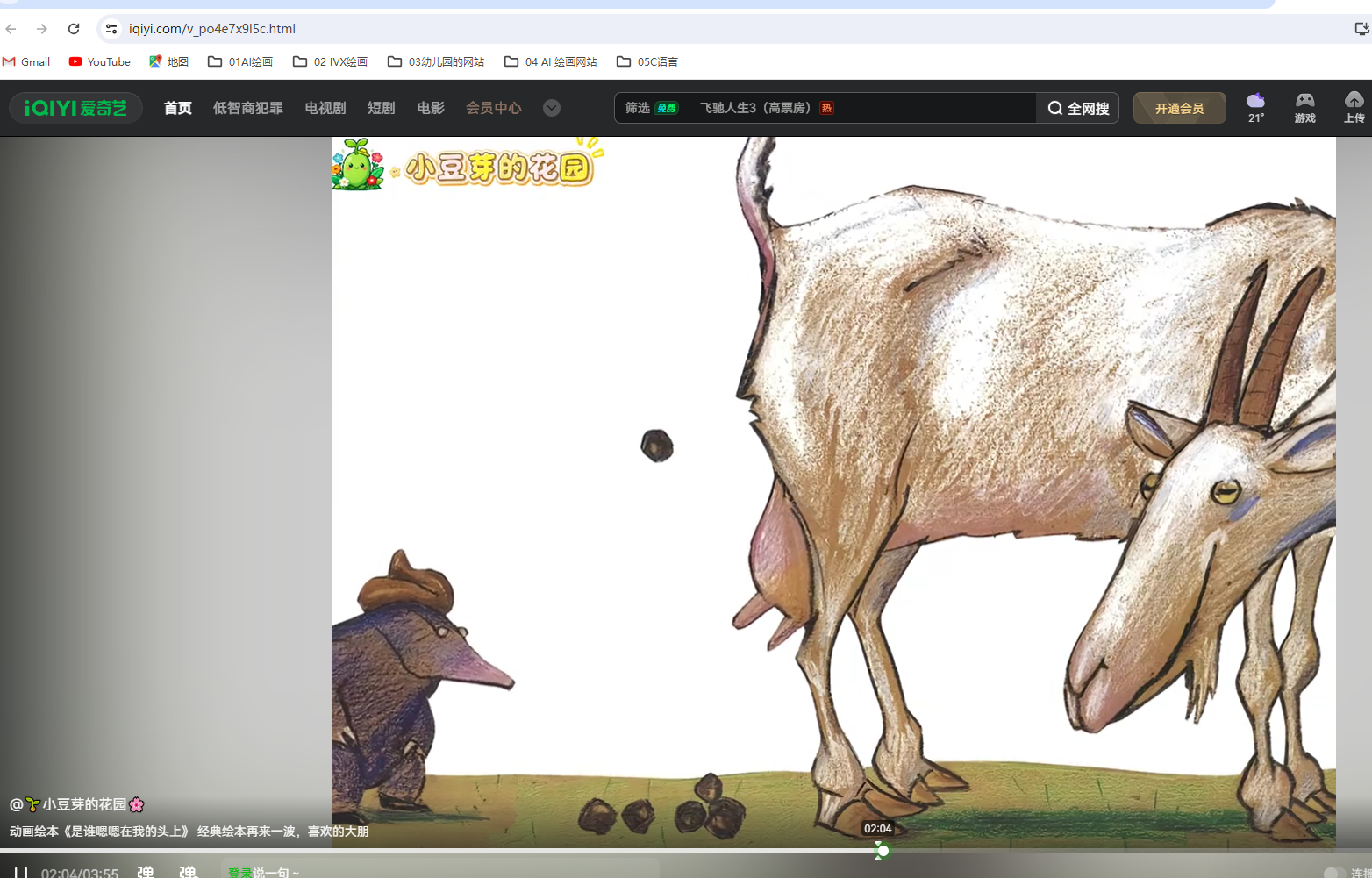
还有一个根据《嗯嗯》故事文字,做的手办风格的配图(不是绘本的样式,属于再创)
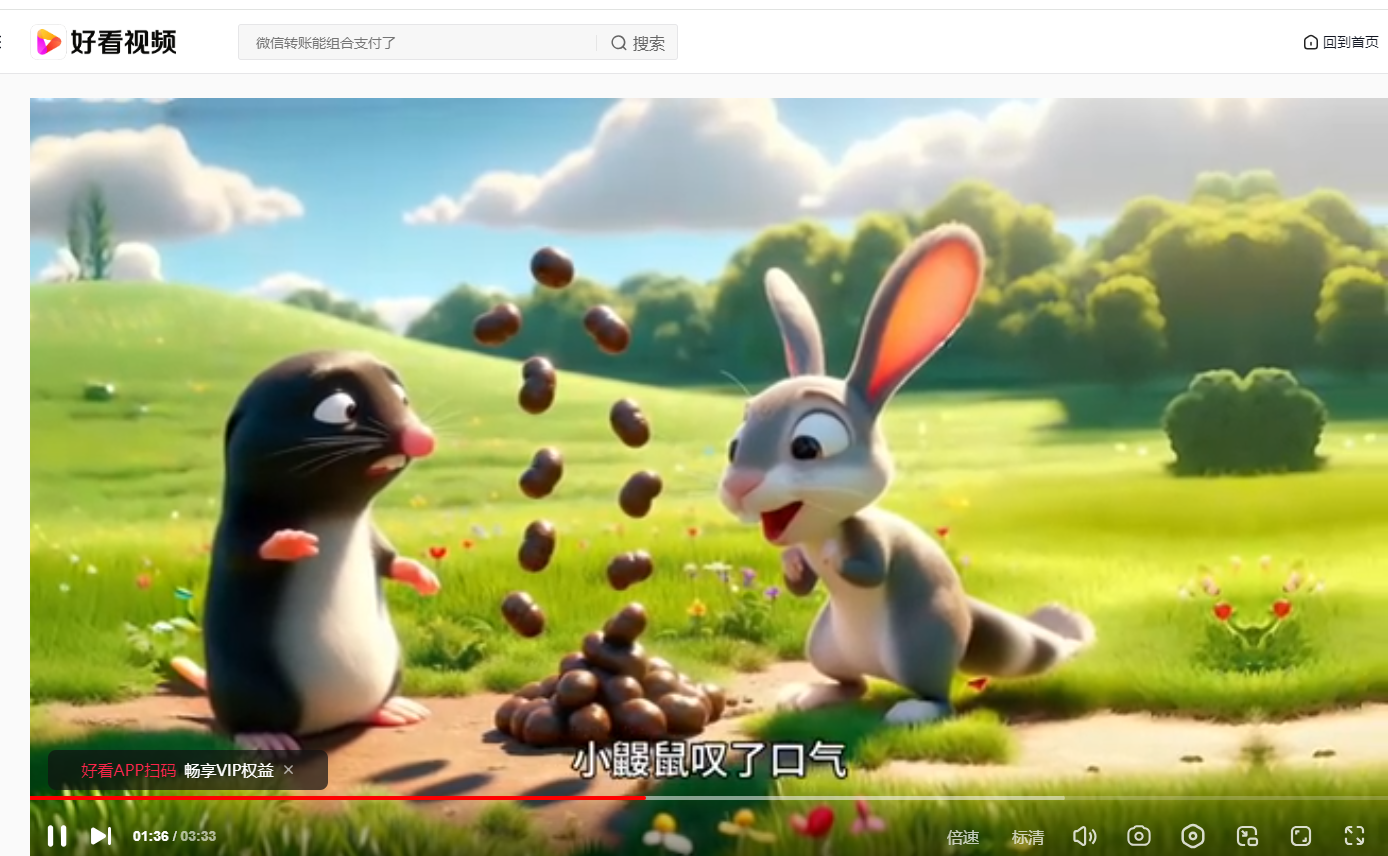
就是说,完全可以利用豆包视频,对平面绘本的每一页内容进行动画效果制作。
豆包选“绘本”


这里面的《蹦》是托班阅读的,感觉页数会很少

百度图片,找找有没有全部内容
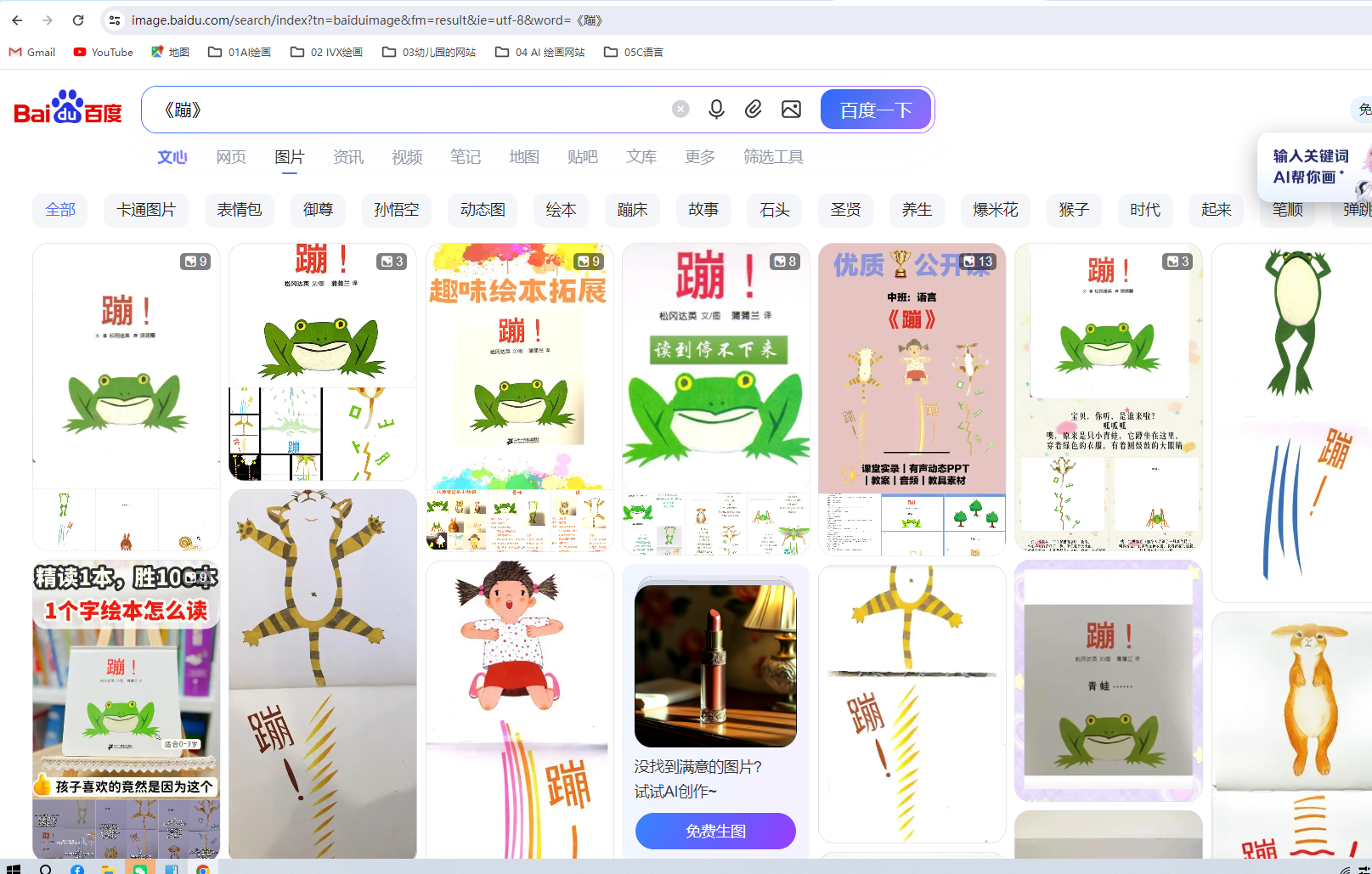
随机点开一个链接,看看所属网页是否有全部的绘本内容。
好不容易找到一个网站,里面是蹦的全部内容
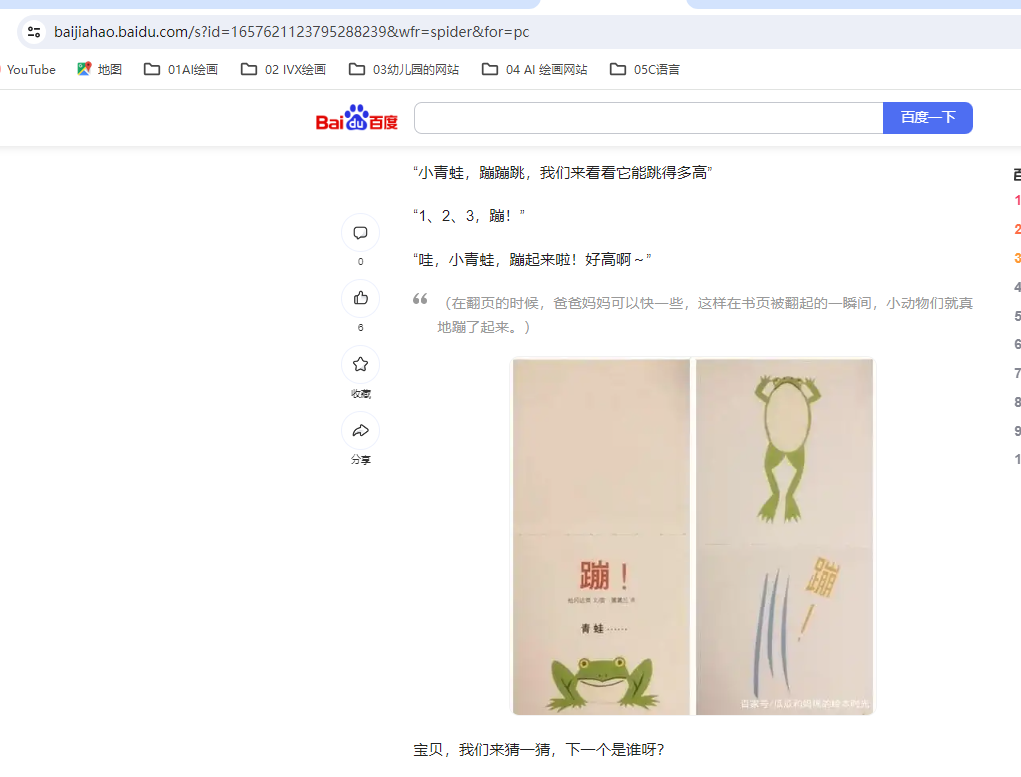
把每页图片下载
每张图片都是2页拼一页,一页只有5.3K,图案质量堪忧
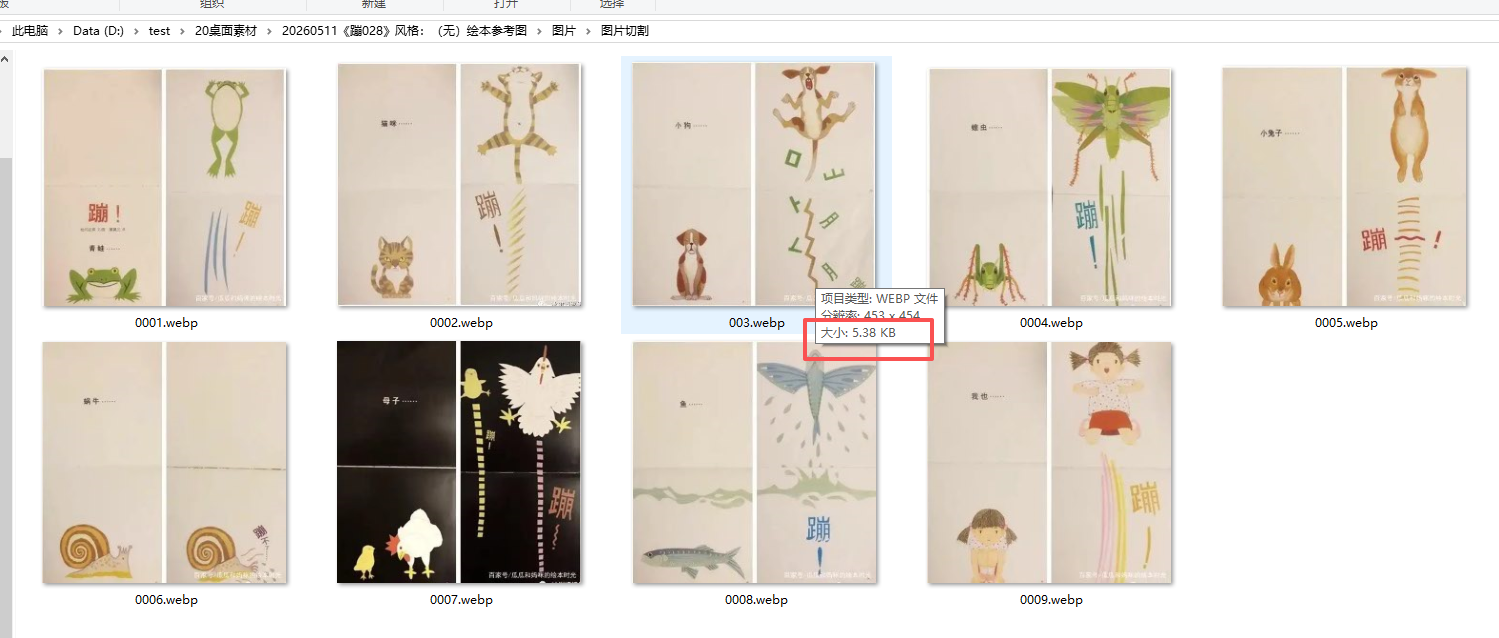
先把每张图片拆分成左右2张

import os
from PIL import Image
def split_images_left_right(input_folder='123', output_folder='234'):
"""
将文件夹中的每张图片左右平均分割成两张图片
参数:
input_folder: 输入文件夹路径(默认为'123')
output_folder: 输出文件夹路径(默认为'234')
"""
# 检查输入文件夹是否存在
if not os.path.exists(input_folder):
print(f"错误:输入文件夹 '{input_folder}' 不存在!")
return
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
print(f"已创建输出文件夹: '{output_folder}'")
# 支持的图片格式
supported_formats = ('.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.gif', '.webp')
# 获取文件夹中所有图片文件
image_files = []
for file in os.listdir(input_folder):
if file.lower().endswith(supported_formats):
image_files.append(file)
if not image_files:
print(f"在文件夹 '{input_folder}' 中没有找到图片文件!")
return
print(f"找到 {len(image_files)} 张图片")
print(f"输入文件夹: '{input_folder}'")
print(f"输出文件夹: '{output_folder}'")
print("-" * 50)
# 处理每张图片
success_count = 0
for idx, filename in enumerate(image_files, 1):
try:
# 获取文件完整路径
file_path = os.path.join(input_folder, filename)
# 打开图片
img = Image.open(file_path)
# 获取图片宽度和高度
width, height = img.size
# 计算中间分割点(确保是整数)
mid_point = width // 2
# 左右分割
left_img = img.crop((0, 0, mid_point, height))
right_img = img.crop((mid_point, 0, width, height))
# 生成输出文件名
name_without_ext, ext = os.path.splitext(filename)
left_filename = f"{name_without_ext}_left{ext}"
right_filename = f"{name_without_ext}_right{ext}"
# 获取保存路径
left_save_path = os.path.join(output_folder, left_filename)
right_save_path = os.path.join(output_folder, right_filename)
# 保存分割后的图片
left_img.save(left_save_path)
right_img.save(right_save_path)
print(f"[{idx}/{len(image_files)}] ✓ {filename}")
print(f" └─ 生成: {left_filename} ({width}x{height} -> {mid_point}x{height})")
print(f" └─ 生成: {right_filename} ({width}x{height} -> {width-mid_point}x{height})")
success_count += 1
except Exception as e:
print(f"[{idx}/{len(image_files)}] ✗ 处理失败: {filename}")
print(f" └─ 错误: {str(e)}")
print("-" * 50)
print(f"处理完成!成功: {success_count}/{len(image_files)} 张图片")
print(f"输出位置: '{output_folder}' 文件夹")
def main():
"""
主函数 - 执行图片分割
"""
# 你可以在这里自定义输入和输出文件夹路径
# 支持相对路径和绝对路径
# 方式1:使用原始字符串(推荐,避免转义字符问题)
input_folder = r'D:\test\20桌面素材\20260511《蹦》风格:绘本\图片\图片切割'
output_folder = r'D:\test\20桌面素材\20260511《蹦》风格:绘本\图片\图片切割2'
os.makedirs(output_folder,exist_ok=True)
# 方式2:使用普通字符串(Windows路径需要双反斜杠)
# input_folder = '123'
# output_folder = '234'
# 方式3:使用绝对路径示例
# input_folder = r'D:\MyImages\input'
# output_folder = r'D:\MyImages\output'
# 执行分割
split_images_left_right(input_folder, output_folder)
if __name__ == "__main__":
main()切割成两张后,图片更小了只有2K

用豆包把图片“变清晰”,并且去掉右下角的白色水印文字


手动下载到“图片1”,每张2-3MB,非常高清
但是这是拍照的,所以背景颜色有色差变化(右侧深,左侧浅),还有中线折痕、右下角有豆包生成字样

复制图片1到图片2,把每张图片的背景色做统一










虽然只有20张图片,但是修图统一背景颜色费了不少时间。
修改后的图片2文件夹的图片
制作视频的动态关键词
我不知道如何描述这些画面的动态效果

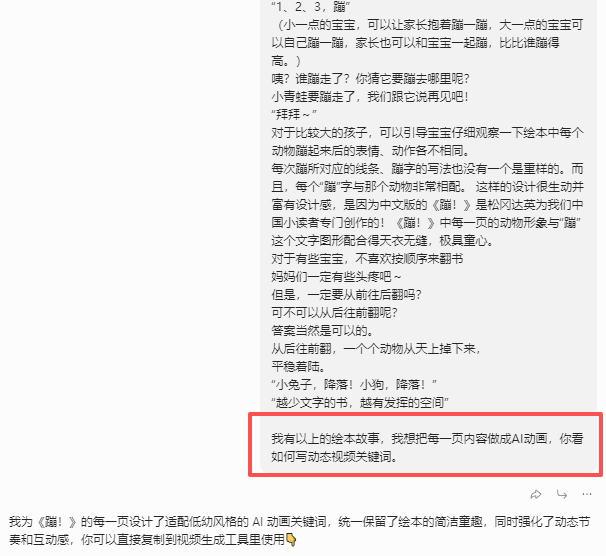
每一页都有一个适合的动态关键词



视频制作
一共20页,每天是5个10秒视频,考虑4张图片做一个视频,每个图片2.5秒的动画效果。
《蹦》的板式是正方形,打开是竖版的。所以比例就是9:16
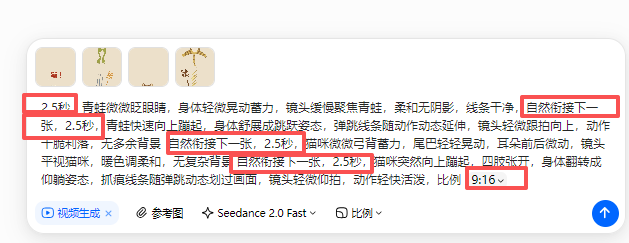

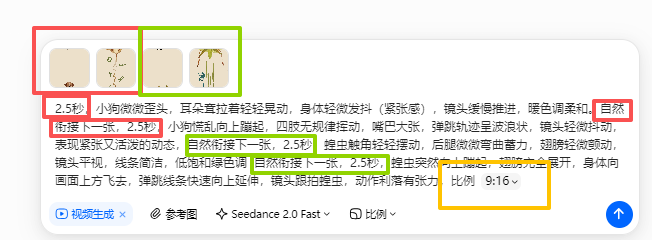
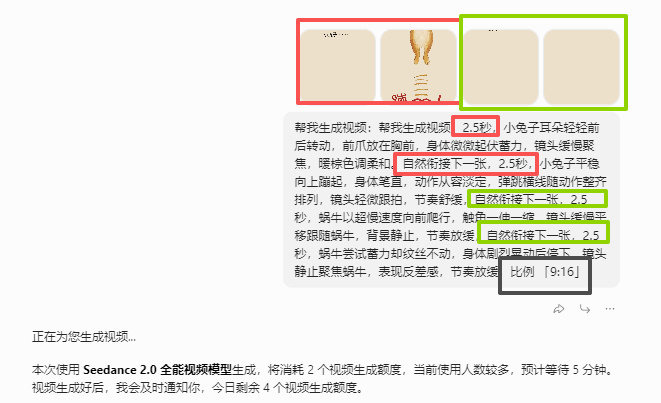

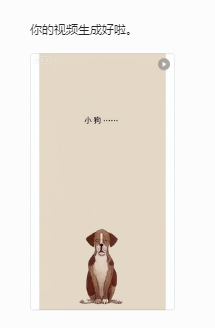



视频下载
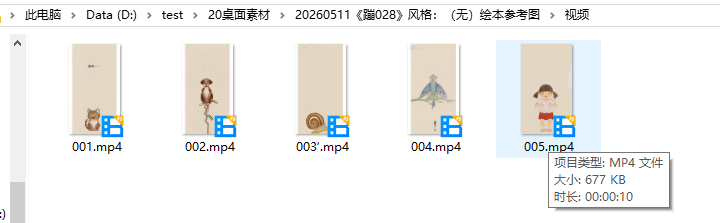





可以看到视频自动将动物静态与动态的图片内容连续起来,类似以前的flash补帧动画。
视频合成:
1、这个视频并没有对话和旁白,只有一个“蹦”字,所以我主要添加了各种动物的叫声的音效、跳跃的音效。
2、每段视频自带的音轨内容保留——我不想配乐了,就用它自带的声音,但是减轻音量,凸显动物的叫声。
3、每个视频左右有白边,把其中一个视频左右拉宽,上下不变。复制属性,黏贴属性到其他4个视频上。
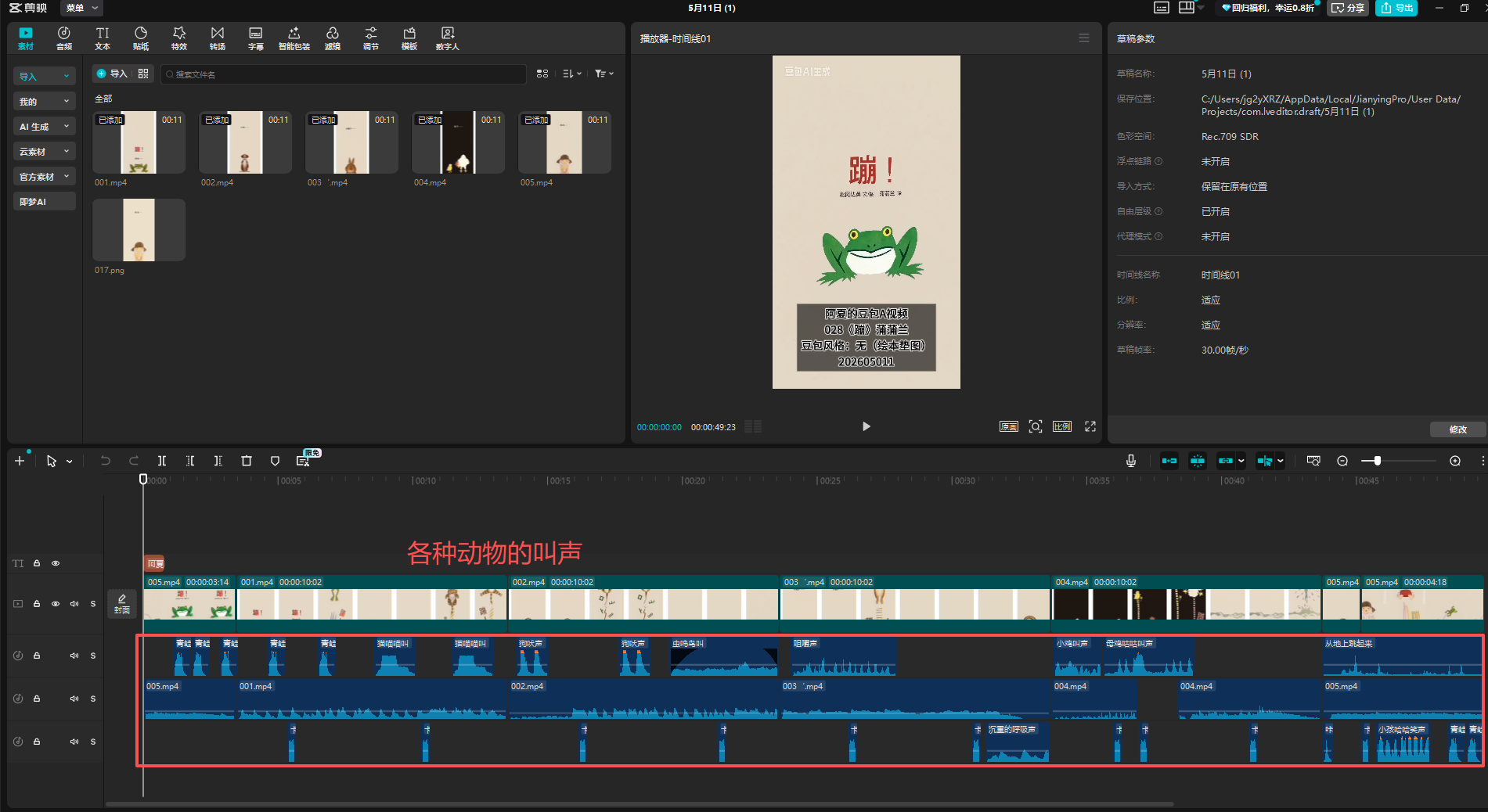
20260511《028蹦》风格:(无)绘本参考图
感悟:
修图费了不少力气,然后我发现实际上《蹦》的底色不是肉色,而是白色,后续找绘本要找扫描版的
2、人工智能(豆包视频)通过动态关键词设计,降低课件制作的难度——动态效果可以依靠AI视频来实现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)