0.4B模型,为什么能听懂更多方言
这两天我看到一个新的 ASR 模型发布,第一反应不是「又来一个语音识别模型」。
而是,终于有人认真处理这件事了。
它叫 Dolphin-CN-Dialect,海天瑞声和清华大学电子工程系语音与音频技术实验室 SATLab 一起做的,一个面向汉语多方言、多口音、真实场景的语音识别模型。
你如果只看一句话介绍,可能会觉得这不就是又一个中文 ASR 吗。
但我觉得这次有意思的地方恰恰在于,它没有走那条最常见的路。
不是上来就喊,我参数更大了,我数据更多了,我榜单更高了。
它处理的是一个更土,但是更真实的问题。
很多语音识别模型,在普通话上已经非常能打了。你拿一段播音腔,拿一段比较标准的会议录音,识别结果通常不会太差。
但只要你把场景稍微往真实世界里挪一点,问题就开始冒出来。
四川话、吴语、闽南语、上海话、带口音的普通话、客服录音里的行业词、会议里突然出现的人名和项目名。
这时候你会发现,所谓「中文语音识别」,很多时候其实是在识别「比较标准的普通话」。
这俩不是一回事。

坦率的讲,这个问题我自己做视频字幕的时候也经常遇到。
不是那种模型完全听不懂的灾难,而是特别烦人的小错。
一个地名错了。
一个产品名错了。
一个人名听成了另一个同音词。
如果你只是刷短视频,可能笑一下就过去了。但如果这是会议纪要、客服质检、医疗随访、政务热线、教育录播,错误就没那么可爱了。
语音识别真正落地的时候,最麻烦的往往不是「大意听懂」。
而是那些必须一个字都不能错的地方。
回到 Dolphin-CN-Dialect。
官方 README 里列了五个模型,不是只发布了一个。
base.cn,0.1B 参数,不带热词。
base.cn.streaming,0.1B 参数,流式版本。
small.cn,0.4B 参数,支持 encoder-level 的热词增强。
small.cn.streaming,0.4B 参数,支持流式和 encoder-level 热词。
small.cn.prompt,0.4B 参数,走 prompt-based 热词方案。
这个矩阵其实挺实用。
你要轻量部署,可以选 base。
你要实时字幕,可以选 streaming。
你要处理人名、药名、地名、品牌名这种长尾词,就看 small 这一组热词模型。
它不是一个「我最强你都来用我」的单点模型,而是把不同场景拆开了。
这点我觉得挺重要。
因为 ASR 不像聊天机器人,很多场景不是你等它慢慢想就行。
实时字幕要低延迟。
客服系统要稳定吞吐。
本地部署要看显存和 CPU。
长尾词识别又要看热词。
一个模型再厉害,如果每个场景都得硬凑,最后就是工程上很难受。
Dolphin-CN-Dialect 的设计里,最核心的一个词叫 temperature-based sampling。
这词听起来有点学术,我用大白话讲。
如果你把普通话数据和方言数据直接混在一起训练,普通话数据量天然更大,模型当然会更偏向普通话。
不是模型坏。
是它每天听到的绝大多数声音,本来就是普通话。
那低资源方言怎么办?
你不能只是把它们丢进训练集里,然后祈祷模型自己重视它们。
temperature-based sampling 做的事,就是重新调训练里的数据配方,让低资源方言在训练过程中被更多看见,同时又不把普通话能力搞崩。
这一下就很像做菜。
不是食材越多越好,而是配方要对。
参考稿里有一个数字挺直观,多方言测试集平均 WER 从 8.04 降到 5.62,相对下降 30.1%。README 里也写到,相比上一代 Dolphin,整体 CER 有 16.3% 的相对下降,方言识别准确率提升 38%。
这不是那种「模型大一点所以自然好一点」的进步。
这是你承认方言是一个需要被单独照顾的问题,然后真的为它改训练策略。
说真的,这个思路比单纯堆参数更打动我。
另一个我觉得值得单独拎出来讲的是 tokenizer。
Dolphin-CN-Dialect 把中文改成字符级建模,英文和字母语言继续用 BPE subword,同时加入任务 token、时间戳 token、方言和地区 token,还预留了 80 个方言 token slot。
你可能会问,这些 token 有啥可聊的。
其实吧,tokenizer 就像模型的耳朵和嘴之间那套切分规则。
如果切分方式不适合中文,尤其不适合方言和口音,后面模型再努力,也是在一个别扭的表示空间里干活。
词表从 40000 降到 18173,中文字符级,方言 token 可扩展。
这几个动作合起来,我理解就是一句话。
别拿一套通用规则,硬套所有中国话。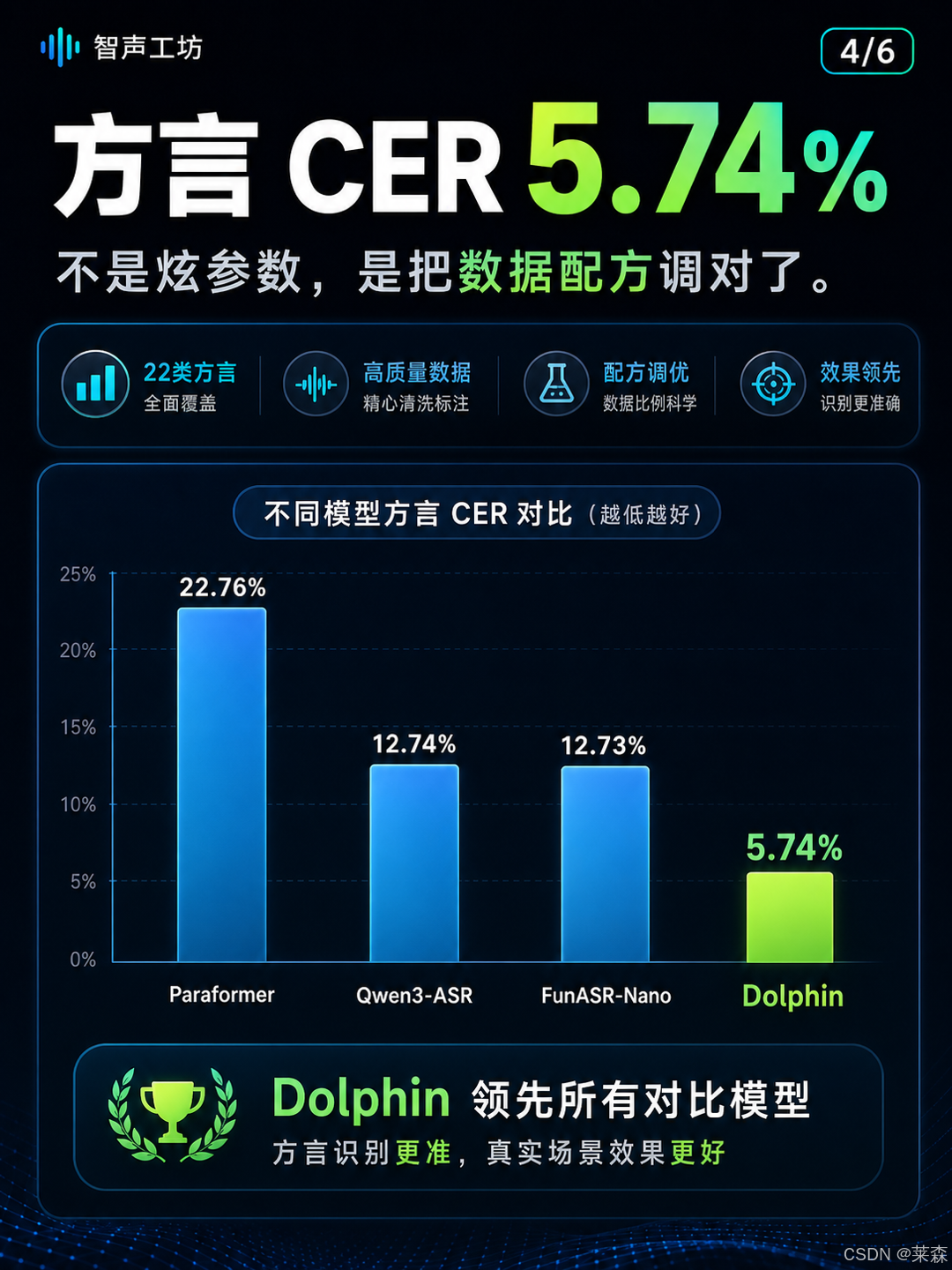
效果上,参考稿里给了几个比较狠的数字。
在 21 类方言和口音测试集上,Dolphin-CN-Dialect 0.4B 平均 CER 是 5.74%。
对比 Paraformer_zh 的 22.76%,相对降低约 74.8%。
对比 Qwen3-ASR-0.6B 的 12.74%,相对降低约 54.9%。
对比 FunASR-Nano-2512 的 12.73%,也是约 54.9% 的相对降低。
高难度方言里,吴语 CER 9.49%,闽南语 CER 20.74%。闽南语这个数字看起来仍然不低,但你把它放到其他模型旁边看,差距就出来了,Qwen3-ASR-0.6B 是 38.64%,FunASR-Nano-2512 是 55.36%。
这就是方言 ASR 很现实的一面。
它不是每个地方都已经完美了。
但只要你承认它难,然后专门为它优化,它就会明显往前走。
还有一个很工程的点,热词。
热词这个东西,很多普通用户不太会主动关心,但真正做系统的人都知道,它非常要命。
因为真实场景里最容易错的,往往不是「今天开会讨论了预算」这种普通句子。
而是公司名、药品名、项目代号、人名、地名、品牌名。
这些词如果没进模型的常识范围,它就只能靠声音去猜。
猜对了是惊喜。
猜错了才是常态。
Dolphin-CN-Dialect 给了两种热词增强方案。
一种是 encoder-level contextual biasing,流式和非流式都能用,把上下文信息注入 encoder 表示。
另一种是 prompt-based hotword biasing,主要给非流式模型用,把热词直接塞进 decoder prompt,尤其适合长尾词和罕见词。
参考稿里提到,在 Common Voice 的 prompt-based 热词实验中,WER 从 7.11 降到 6.08,BWER 从 15.22 降到 6.79,BWER 相对降低 55.4%。
这个数字对做业务的人来说,比很多榜单都更有感觉。
因为它解决的是「我明明告诉你这个词很重要,你能不能别再听错」。
当然,这个模型也不是没有边界。
README 里说它支持普通话和 22 类中文方言,同时也保留了 Dolphin 系列继承下来的多语言 ASR 能力。
但它最核心的价值,显然还是中文真实场景。
你如果拿它去问一个宏大的问题,什么「ASR 终局是什么」,我觉得反而没必要。
它更像是一个很具体的补课。
过去很多语音识别系统默认,中文就是普通话。
最多再加一点口音鲁棒性。
但真实中国不是这样的。
真实中国有方言,有夹杂,有地区口音,有行业黑话,有人名地名,有噪声,有电话压缩,有会议室回声。
所以我看到 Dolphin-CN-Dialect 的时候,真正让我有感觉的不是某一个榜单数字。
而是它背后的态度。
它没有把这些非标准声音当成异常值。
它把它们当成了中文的一部分。
这件事其实挺重要的。
技术很多时候会悄悄塑造什么叫「标准」。
如果一个系统只听得懂标准普通话,那久而久之,系统里的「中文」就会被收窄成一种最规整、最容易被机器处理的中文。
这当然有效率。
但也会丢东西。
方言不是普通话的错误版本。
口音也不是语音识别里的噪声。
它们就是人说话本来的样子。
我觉得 Dolphin-CN-Dialect 这类模型的意义就在这儿。
它不一定是一个普通用户明天就会立刻感知到的爆款产品。
但它会慢慢出现在实时字幕、会议转写、客服质检、录音整理、行业语音系统里。
你可能不会知道背后是哪一个模型。
但你会发现,字幕里那个地名终于没错。
会议纪要里那个同事的名字终于对了。
客服录音里那句带口音的话,终于不是一串离谱的乱码。
这就够了。
普通话听得准,当然很好。
但下一步,ASR 得学会听懂更多真实的中国话。
不然它听到的,就永远只是一个被压平过的世界。
参考资料
- Dolphin-CN-Dialect 官方 README
- Dolphin GitHub,https://github.com/DataoceanAI/Dolphin
- 技术报告,https://arxiv.org/abs/2605.08961
- ModelScope 组织页,https://modelscope.cn/organization/DataoceanAI
- HuggingFace 组织页,https://huggingface.co/DataoceanAI

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)