Google 发布 Gemma 4:开放模型正在进入多模态与端侧部署新阶段
Google DeepMind 近日发布 Gemma 4 系列开放模型。和上一代相比,Gemma 4 的重点不只是参数规模变大,而是把多模态、长上下文、推理模式、MoE 架构和端侧部署能力放在了一起。Google 官方介绍显示,Gemma 4 支持文本和图像输入,小模型还支持音频输入,并提供预训练和指令微调版本,最高上下文窗口可达 256K tokens,同时继续支持 140 多种语言。
一、密集模型:三兄弟各有所长
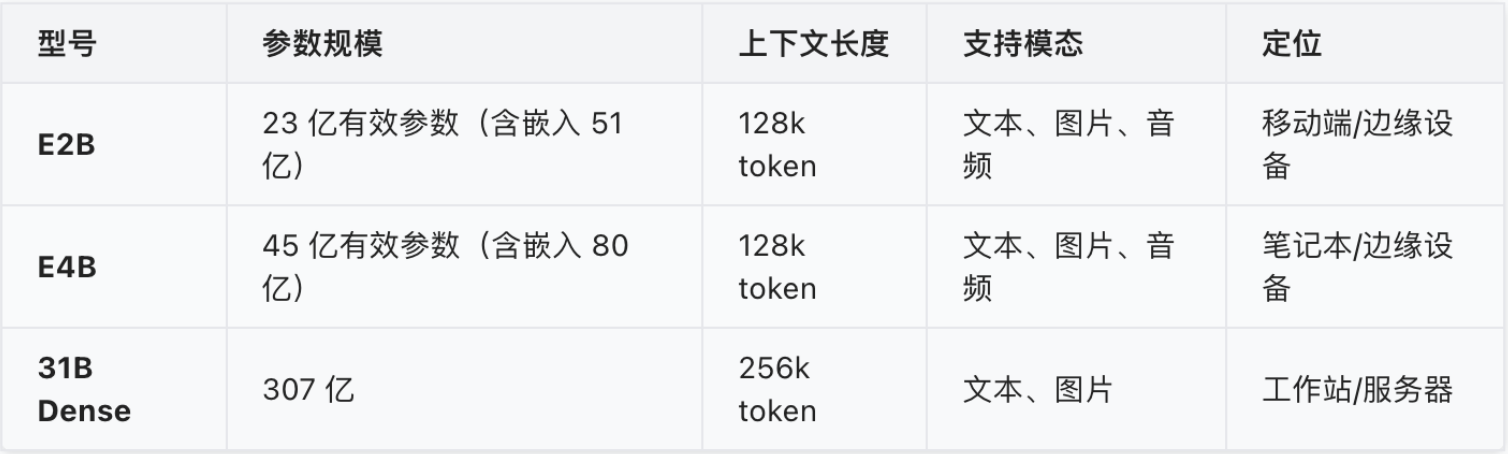
这次 Gemma 4 一共提供四种规模:E2B、E4B、26B A4B 和 31B。E2B 与 E4B 面向移动设备、笔记本和边缘场景;26B A4B 和 31B 则更适合消费级 GPU、工作站和服务器环境。换句话说,Google 这次并不是只推出一个“更强的大模型”,而是在尝试覆盖从端侧设备到企业服务器的不同部署需求。
二、MoE 模型:速度与能力的完美平衡
从架构上看,Gemma 4 同时采用了 Dense 和 Mixture-of-Experts(MoE)两类路线。E2B、E4B 和 31B 属于密集模型,其中 E2B 为 23 亿有效参数,E4B 为 45 亿有效参数,31B Dense 为 307 亿参数;26B A4B 则是 MoE 模型,总参数约 252 亿,但推理时只激活约 38 亿参数。这样的设计让 26B A4B 在保持较强能力的同时,也能获得接近小模型的推理速度。
Gemma 4 的另一个重要变化,是更强调多模态和长上下文能力。E2B 和 E4B 支持文本、图像和音频输入,31B 与 26B A4B 支持文本和图像输入。小模型支持 128K tokens 上下文,较大的 26B A4B 和 31B 支持 256K tokens。对于企业场景来说,这意味着模型可以处理更长的文档、更复杂的项目资料,或更大规模的知识库片段,而不只是完成简单问答。
三、核心能力对比
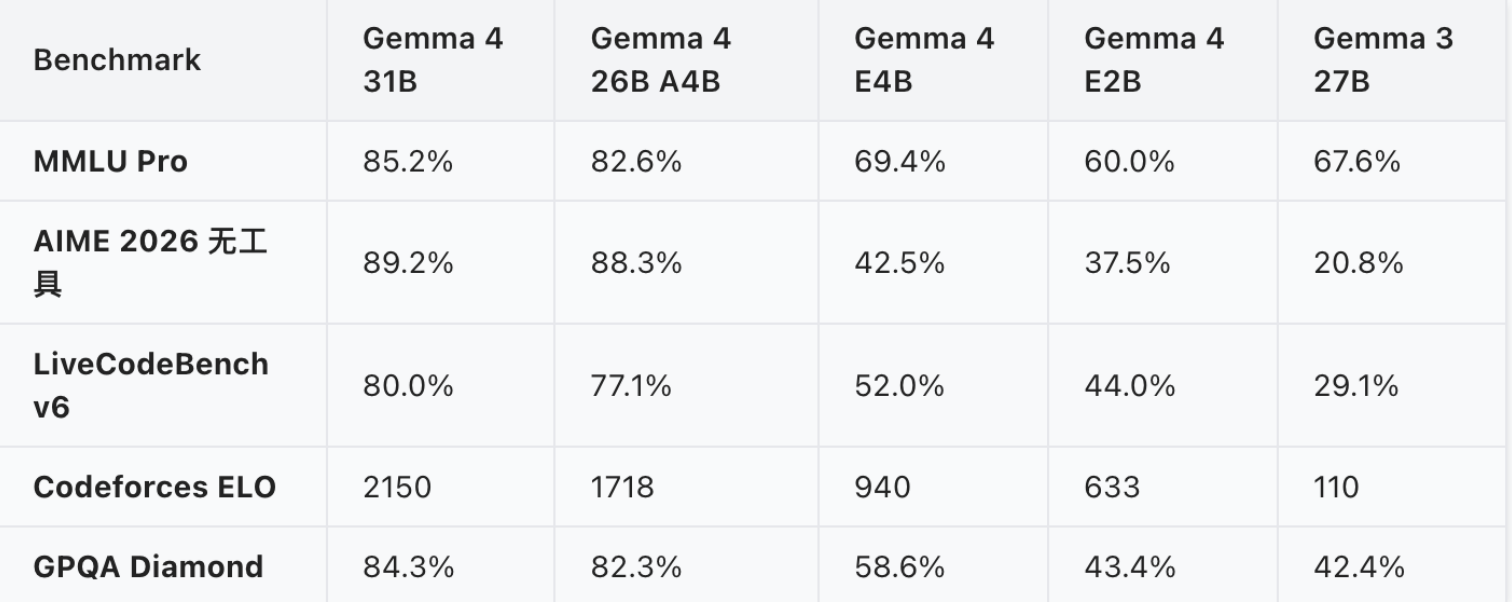
在能力表现上,Gemma 4 的提升也比较明显。官方模型卡显示,Gemma 4 31B 在 MMLU Pro 上达到 85.2%,在 AIME 2026 无工具测试中达到 89.2%,LiveCodeBench v6 达到 80.0%;26B A4B 在这些项目中也分别达到 82.6%、88.3% 和 77.1%。视觉任务方面,31B 在 MMMU Pro 上达到 76.9%,在 MATH-Vision 上达到 85.6%。这些结果说明,Gemma 4 不只是文本模型,而是在数学、代码、视觉理解和文档解析方面都有进一步增强。
对开发者来说,Gemma 4 比较值得关注的还有两点。第一,它支持内置 Thinking 模式,可以让模型在回答前进行分步推理;第二,它支持原生函数调用,更适合构建 agentic workflows,也就是能连接工具、执行任务的智能体流程。Google 官方也提到,Gemma 4 引入了 system 角色支持,使对话控制和结构化交互更加方便。
这对企业有什么意义?过去,开放模型常常被认为适合实验、研究或成本敏感场景,但在真正企业落地时,往往会遇到能力不足、上下文不够、多模态支持弱、部署不灵活等问题。Gemma 4 的方向正好回应了这些需求:小模型可以用于端侧和本地部署,大模型可以用于更复杂的知识工作,MoE 模型则在性能和成本之间提供折中。
不过,开放模型并不等于可以随意上线。企业在使用 Gemma 4 这类模型时,仍然需要考虑数据边界、模型部署环境、权限控制、输出审核和合规要求。Google 官方也强调,Gemma 4 经过了安全评估,并在内容安全方面相比前代模型有所改进,但企业自身的治理机制仍然不可缺少。
Gemma 4 的发布说明,开放模型正在从“能用”走向“更适合部署”。未来企业选择 AI 模型时,不一定只看最强闭源模型,也可以根据场景选择更灵活的开放模型方案。真正关键的是,企业是否能把模型能力、数据安全、部署成本和业务流程结合起来,让 AI 在可控环境中产生实际价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)