基于 Isolation Forest + PyOD + Streamlit 的工业设备异常检测与故障预警系统:Python 机器学习项目实战
摘要:
本文围绕一个可以直接运行的工业设备异常检测项目展开,项目使用温度、压力、振动、电流、转速、负载和环境温度等传感器数据,完成数据读取、数据清洗、特征工程、Isolation Forest 无监督异常检测、报警分级、异常原因解释、设备健康评分和 Streamlit 可视化看板开发。项目不依赖 GPU,不需要下载大模型权重;本文运行效果使用 IBM 官方 IoT 传感器故障数据集,通过 python scripts/run_ibm_iot_real_data.py 生成外部数据检测结果、报警记录、趋势图、风险曲线和健康评分图,并使用 Streamlit 页面实际截图作为看板预览。它适合作为 Python 机器学习项目实战、工业 AI 课程设计、数学建模项目、预测性维护系统原型和企业设备监测看板的二次开发基础。
关键词:
Python 机器学习项目实战、工业设备异常检测、Isolation Forest、PyOD、Streamlit、传感器数据分析、故障预警系统、设备健康评分、预测性维护、无监督异常检测
项目资源说明:
本项目完整代码位于 industrial_anomaly_warning_system/。内置样例脚本为 run_demo.py,外部正式数据运行脚本为 scripts/run_ibm_iot_real_data.py,可视化 Web 页面入口为 app.py,CSDN 博客正文为 blog.md。默认不需要任何深度学习模型权重,weights/README_WEIGHTS.md 已说明后续如何扩展 LSTM-AE、Transformer-AE 等模型。
项目背景:从传感器数据到设备故障预警
工业设备一旦进入连续运行状态,现场通常会持续采集温度、压力、振动、电流、转速、流量、负载、环境温度等数据。对于电机、风机、水泵、压缩机、数控机床、生产线传送装置这类设备来说,很多故障并不是突然出现的,而是先在传感器数据中表现为细微偏移,例如振动逐渐升高、电流波动变大、压力持续下降、温度异常上升,或者多个指标同时偏离历史正常状态。
传统报警系统往往依赖人工阈值。例如温度超过 85℃ 报警,振动超过某个固定值报警,电流超过额定值报警。这种方法实现简单,但问题也很明显。第一,不同设备、不同负载、不同环境温度下的正常范围并不完全一样;第二,单个指标可能没有越界,但多个指标组合起来已经暗示设备状态异常;第三,阈值设置过严会产生大量误报,设置过松又会漏掉早期故障。
机器学习异常检测适合解决这类问题。项目不要求提前收集大量故障标签,而是通过历史运行数据学习设备的正常模式。当新数据偏离正常模式时,系统会给出异常风险分数,并进一步转换为报警等级。本文实现的项目不是简单地跑一个算法,而是把异常检测做成一个完整系统:数据输入、特征工程、模型检测、报警解释、健康评分、结果导出和可视化看板全部包含在项目里。
本项目对应的典型使用场景包括:工厂设备状态监测、泵站运行数据分析、电机振动预警、生产线质量巡检数据分析、数学建模课程设计、工业 AI 项目实战、预测性维护系统原型开发。相比图像检测、大模型问答和推荐系统,这个选题的数据形态、应用场景和交付方式都不同,更适合做差异化内容。
在真实工业场景中,异常检测通常服务于泵站、产线、机电设备和传感器采集系统。下面这张设备现场图可以帮助读者把后文的温度、压力、振动、电流等字段和实际设备运行状态对应起来:

系统功能设计与技术路线
本项目的目标是实现一个“能跑、能看、能改、能扩展”的工业传感器异常检测系统。用户既可以运行内置样例流程快速验证代码,也可以运行外部数据脚本下载并适配 IBM IoT 传感器 CSV,随后完成检测并保存结果。如果用户有自己的 CSV 数据,也可以通过 Streamlit 页面上传文件,快速查看异常趋势和报警记录。
项目主要功能包括:内置传感器样例数据生成、外部 CSV 数据适配、CSV 数据读取、缺失值插补、滚动统计特征构造、Isolation Forest 异常检测、PyOD 可选算法扩展、异常风险分数输出、报警等级划分、异常原因解释、设备健康评分、结果 CSV 导出、趋势图保存、Streamlit 页面展示。
整体技术路线如下:
工业设备传感器数据
↓
时间排序与缺失值处理
↓
温度、压力、振动、电流、转速等多维特征提取
↓
滚动均值、滚动标准差、差分和偏离量特征构造
↓
标准化为机器学习特征矩阵
↓
Isolation Forest / PyOD 无监督异常检测
↓
异常风险分数归一化
↓
报警等级、异常原因和健康评分计算
↓
趋势图、报警表、CSV 报告和 Streamlit 看板展示
从工程角度看,这条路线有两个优点。第一个优点是低门槛。项目没有要求用户下载大型模型,也不依赖 GPU,普通 Windows 或 Linux 环境只要安装 Python 依赖就可以运行。第二个优点是容易扩展。当前版本使用 Isolation Forest 作为基础算法,如果后续希望切换成 ECOD、KNN、LOF、AutoEncoder、LSTM-AE 或 Transformer-AE,只需要保留数据清洗、报警分级、健康评分和前端看板模块,把检测器替换掉即可。
数据字段设计与外部数据说明
为了让项目可以直接运行,代码包内置了 src/data_generator.py,用于生成一份模拟工业设备运行数据。除此之外,本文的运行效果使用 IBM iot-predictive-analytics 仓库中的外部 IoT 传感器 CSV,通过 scripts/run_ibm_iot_real_data.py 适配到项目字段。内置样例数据保存到:
data/sample_sensor_data.csv
外部数据运行脚本会把 IBM CSV 中的 temp、outpressure、footfall、PID、ClinLR、DoleLR、atemp 等字段映射为项目中的温度、压力、振动、控制电流、转速、负载和环境温度字段,并保留 fail 作为参考故障标签。这个标签只用于结果核对和页面展示,不参与 Isolation Forest 训练。
核心字段如下:
| 字段 | 含义 | 作用 |
|---|---|---|
| timestamp | 采集时间 | 用于排序、趋势图和时间分析 |
| device_id | 设备编号 | 支持后续扩展多设备管理 |
| temperature | 温度 | 发现过热、散热异常、负载异常 |
| pressure | 压力 | 发现泄漏、堵塞、压力波动 |
| vibration | 振动 | 发现轴承、转子、安装松动等问题 |
| current | 电流 | 发现过载、机械阻力变化 |
| rpm | 转速 | 发现转速不稳、传动异常 |
| load | 负载 | 辅助判断设备运行工况 |
| ambient_temp | 环境温度 | 辅助解释温度变化 |
| known_failure_label | 外部数据参考故障标签 | 仅用于结果核对,不参与训练 |
真实工业数据通常存在缺失值、重复时间、采样频率不一致、传感器漂移等问题。所以项目在 src/preprocessing.py 中单独写了清洗逻辑,先按时间排序,再对数值字段进行线性插值和前后填充。这样即使样例数据里故意加入少量缺失值,主程序也能正常运行。
这里要强调一点:known_failure_label 只是外部数据中的参考字段,模型训练并不会使用它。原因是本项目定位为无监督异常检测,大多数真实设备现场并没有完整故障标签。我们更希望系统从运行数据中自动学习“什么是正常”,再用风险分数提示“哪里不太正常”。
Isolation Forest 原理与项目建模方案
Isolation Forest 是本项目的默认检测算法。它适合无监督异常检测,核心思想可以简单理解为:异常点往往和大多数样本差异较大,在随机切分特征空间时,更容易被较少的切分次数单独隔离出来;正常点通常分布在数据密集区域,需要更多切分才能被隔离。因此,Isolation Forest 会通过多棵随机树统计样本被隔离的难易程度,并据此给出异常分数。
在 scikit-learn 中,IsolationForest 可以直接对特征矩阵进行训练和预测。项目中使用的关键参数包括:
detector:
algorithm: isolation_forest
contamination: 0.065
n_estimators: 220
random_state: 42
contamination 表示预计异常比例。它不是越大越好,也不是越小越好。如果设置过大,系统会把很多正常波动误判为异常;如果设置过小,系统可能漏掉轻微故障。当前项目默认设置为 0.065,也就是大约 6.5% 的样本会被模型重点关注。用户可以根据现场设备情况在 configs/config.yaml 中调整。
项目中没有直接把原始传感器值送进模型,而是构造了更适合异常检测的特征。以温度为例,除了原始 temperature,还会构造 temperature_roll_mean、temperature_roll_std、temperature_deviation 和 temperature_diff。这些特征能帮助模型捕捉局部趋势、突然变化和相对偏离,而不是只看某一个时刻的绝对值。
特征工程的思路如下:
原始传感器值:当前时刻设备状态
滚动均值:最近一段时间的局部基线
滚动标准差:最近一段时间的波动程度
偏离量:当前值相对局部基线的偏移
差分特征:当前值相对上一时刻的变化速度
这种设计比单纯使用原始字段更稳。因为设备正常运行时也会随着负载变化产生波动,滚动统计特征能提供局部上下文,使模型更容易发现真正异常的偏移模式。
项目同时预留了 PyOD 算法扩展。PyOD 是异常检测方向常用的 Python 工具库,包含 ECOD、KNN、LOF 等多种检测器。当前代码中已经写好可选入口,如果安装 requirements_pyod.txt,可以在 Streamlit 页面选择 pyod_ecod、pyod_knn 或 pyod_lof。如果没有安装 PyOD,系统会自动回退到 Isolation Forest,保证基础功能可运行。
项目目录结构与环境配置
项目目录结构如下:
核心文件说明如下:
app.py
Streamlit 可视化看板入口,支持参数配置、文件上传、趋势图展示和结果下载。
run_demo.py
一键运行演示脚本。它会生成样例数据,执行检测流程,保存 CSV、JSON 和图片结果。
scripts/run_ibm_iot_real_data.py
外部数据运行脚本。它会读取 IBM IoT 传感器 CSV,转换字段,执行检测流程,并生成本文使用的真实运行结果图。
configs/config.yaml
项目配置文件,用于控制样例数据规模、传感器字段、滚动窗口、算法参数和报警阈值。
src/data_generator.py
生成工业设备传感器样例数据,并注入几类可解释异常。
src/preprocessing.py
数据清洗与特征工程,包括缺失值处理、滚动统计、差分和标准化。
src/anomaly_detector.py
封装 Isolation Forest 和可选 PyOD 检测器,统一输出异常风险分数和模型标签。
src/alert_engine.py
把模型结果转换为“正常、轻微异常、中度异常、严重异常”,并生成异常原因。
src/health_score.py
根据异常风险和报警情况计算设备健康评分。
src/visualization.py
生成系统架构图、流程图、趋势图、风险曲线、健康评分图和报警表截图。
outputs/
保存异常检测结果、报警记录和报告摘要。
images/results/
保存运行效果图,可直接插入博客。
安装依赖:
pip install -r requirements.txt
基础依赖包括 numpy、pandas、scikit-learn、matplotlib、Pillow、PyYAML 和 streamlit。如果只想运行 run_demo.py,核心依赖主要是数据处理、机器学习和绘图库。如果要启动 Web 看板,需要安装 Streamlit。
可选安装 PyOD:
pip install -r requirements_pyod.txt
一键运行演示:
python run_demo.py
使用外部 IBM IoT 传感器数据生成本文运行效果:
python scripts/run_ibm_iot_real_data.py
启动 Web 看板:
streamlit run app.py
Windows 用户也可以双击 run.bat,Linux 或 macOS 用户可以执行:
bash run.sh
数据清洗、特征工程与异常检测代码讲解
项目的端到端流程封装在 src/pipeline.py 中。这个文件不是简单调用模型,而是把多个模块串成完整流水线。
核心流程如下:
clean_df = clean_sensor_data(df, sensor_columns=sensor_columns)
x_scaled, feature_df, _, feature_columns = prepare_features(
clean_df,
sensor_columns=sensor_columns,
rolling_window=int(config["features"].get("rolling_window", 12)),
diff_features=bool(config["features"].get("diff_features", True)),
)
detector = AnomalyDetector(
algorithm=detector_cfg.get("algorithm", "isolation_forest"),
contamination=float(detector_cfg.get("contamination", 0.065)),
n_estimators=int(detector_cfg.get("n_estimators", 220)),
random_state=int(detector_cfg.get("random_state", 42)),
)
detection = detector.fit_predict(x_scaled)
清洗阶段主要做三件事。第一,解析 timestamp 并按时间排序;第二,把传感器字段统一转换为数值类型;第三,对缺失值进行插值和前后填充。这种处理方式适合连续采样的传感器数据。如果某些设备的采样间隔非常不稳定,后续可以先重采样到固定时间间隔,再进入特征工程。
特征工程阶段由 build_feature_frame 完成。项目会遍历每个传感器字段,添加滚动均值、滚动标准差、偏离量和差分特征。例如对于 vibration 字段,会生成:
vibration
vibration_roll_mean
vibration_roll_std
vibration_deviation
vibration_diff
当前项目共有 7 个传感器字段,每个字段生成 5 类特征,因此最终特征数量为 35。运行结果摘要中也会记录这个数量,方便用户检查配置是否生效。
检测阶段由 src/anomaly_detector.py 负责。为了统一不同算法的输出,项目把检测结果转换成以下字段:
anomaly_score
模型原始异常分数,数值越大通常越异常。
anomaly_risk
归一化后的风险分数,范围约为 0 到 1,便于和报警阈值结合。
model_label
模型标签,-1 表示异常,1 表示正常。
model_result
中文结果,异常或正常。
algorithm_used
实际使用的算法名称。
这里需要注意的是,不同异常检测算法的原始分数方向不完全相同。项目在封装层里统一了分数方向,把“越异常,风险越高”作为最终输出标准。这样后面的报警模块、健康评分模块和前端页面不需要关心底层算法差异。
报警分级、异常原因解释与健康评分
机器学习模型输出异常分数并不等于业务系统完成了。工业现场更关心的是:这条数据是否需要报警、报警有多严重、可能是什么原因、设备整体健康状态如何。因此项目在 src/alert_engine.py 和 src/health_score.py 中加入了业务解释层。
报警等级默认分为四类:
正常
轻微异常
中度异常
严重异常
阈值配置如下:
alerts:
minor_threshold: 0.52
medium_threshold: 0.68
severe_threshold: 0.84
当模型判定为异常,或者风险分数超过轻微异常阈值时,系统会进入报警逻辑。风险分数越高,报警等级越高。这样做的好处是既保留模型标签,又允许用户通过业务阈值进行二次调整。
异常原因解释不是用复杂的黑盒解释算法,而是用一套简单、可理解、可改造的方法:系统先用正常样本计算每个传感器的均值和标准差,然后判断报警样本中哪些传感器偏离正常基线最明显。例如某条记录的温度和电流都明显高于正常区间,报警原因就可能输出为:
温度偏高、电流偏高
如果压力明显低于正常区间,同时电流偏高,则可能输出为:
压力偏低、电流偏高
这种解释方式虽然不复杂,但非常适合项目展示和工程原型。它能让用户看到异常不是凭空出现的,而是由具体传感器指标支撑的。后续如果要增强解释能力,可以加入 SHAP、规则库、专家知识或故障树分析。
设备健康评分的逻辑也尽量保持直观。项目根据归一化异常风险分数计算单点健康评分,再计算滚动健康评分。风险越高,健康评分越低;模型判定为异常时,会额外扣分。最终输出两个核心指标:
average_health_score
整段数据的平均健康评分。
latest_rolling_health_score
最近窗口内的滚动健康评分,更接近当前设备状态。
运行外部 IBM IoT 传感器数据后,得到的摘要如下:
Records analyzed: 944
Alerts detected: 69
Average health score: 76.28
Latest rolling health score: 72.78
Max anomaly risk: 1.0
Algorithm used: isolation_forest
内置演示流程会把摘要写入 outputs/report_summary.json;本文使用的外部数据流程会写入:
outputs/ibm_iot_report_summary.json
报警记录会写入:
outputs/ibm_iot_alert_records.csv
完整检测结果会写入:
outputs/ibm_iot_anomaly_detection_result.csv
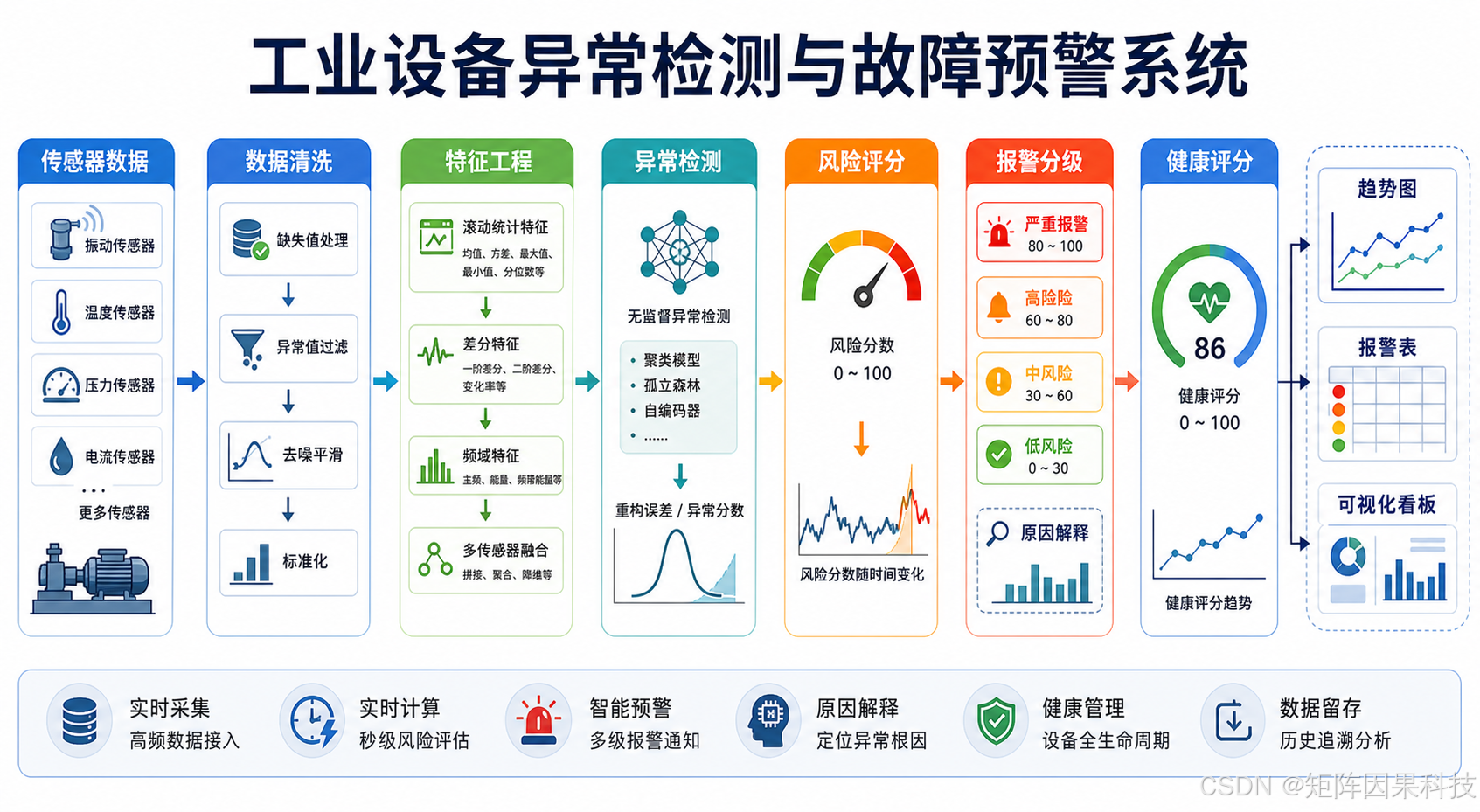
Streamlit 可视化看板与运行效果
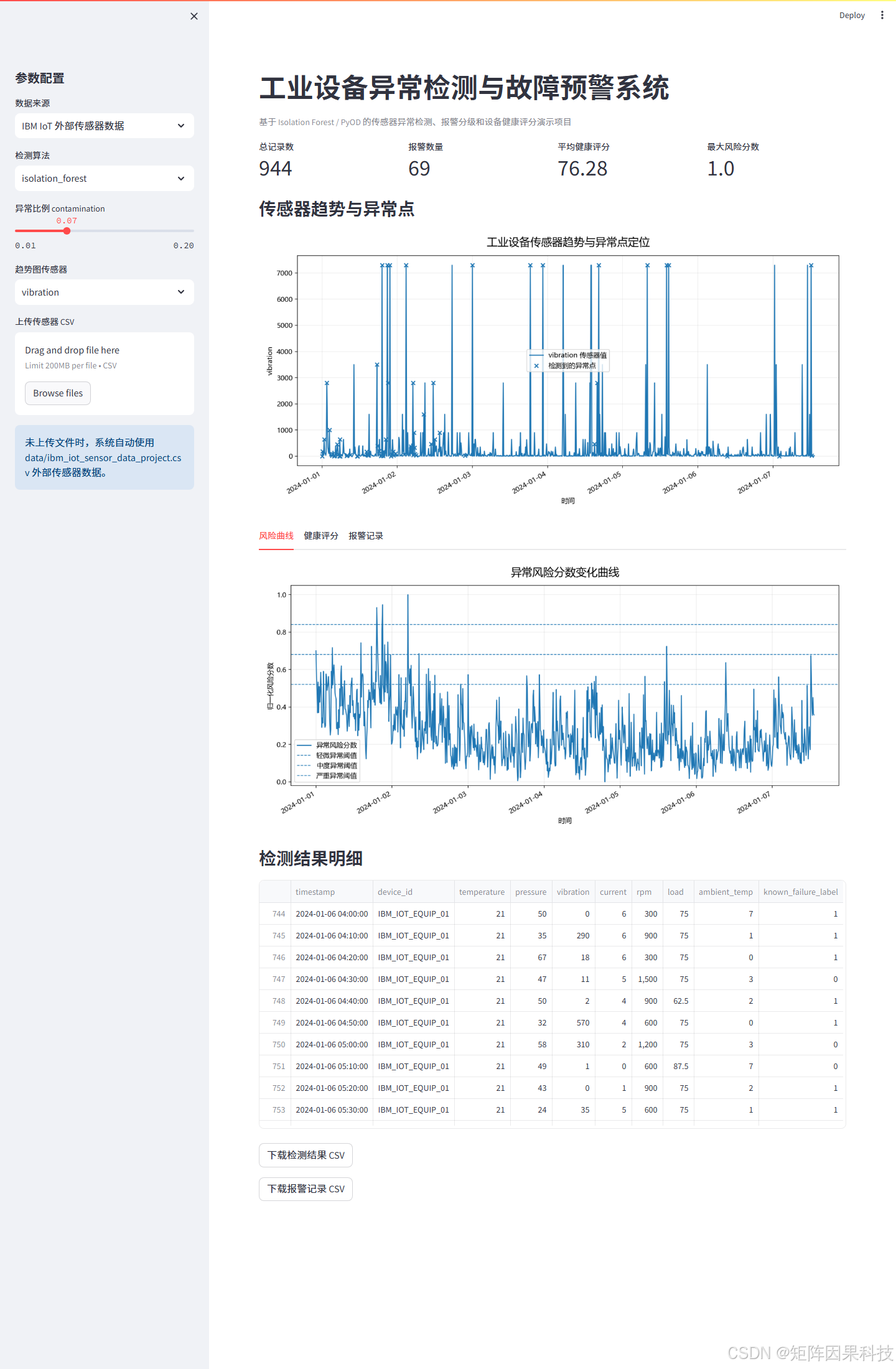
为了让项目不只是命令行脚本,本文使用 Streamlit 开发了一个简单的 Web 看板。用户启动后可以在浏览器中查看设备状态,调整检测算法和异常比例参数,也可以上传自己的 CSV 数据。本文截图中的页面数据来源选择为 IBM IoT 外部传感器数据,不是代码生成的演示数据。
启动命令:
streamlit run app.py
页面主要包含四类信息。第一类是指标卡,包括总记录数、报警数量、平均健康评分和最大风险分数。第二类是传感器趋势图,系统会把异常点标注出来。第三类是异常风险曲线和健康评分曲线,用于观察设备状态随时间变化。第四类是报警记录表,展示报警时间、报警等级、风险分数和异常原因。
看板预览图如下:
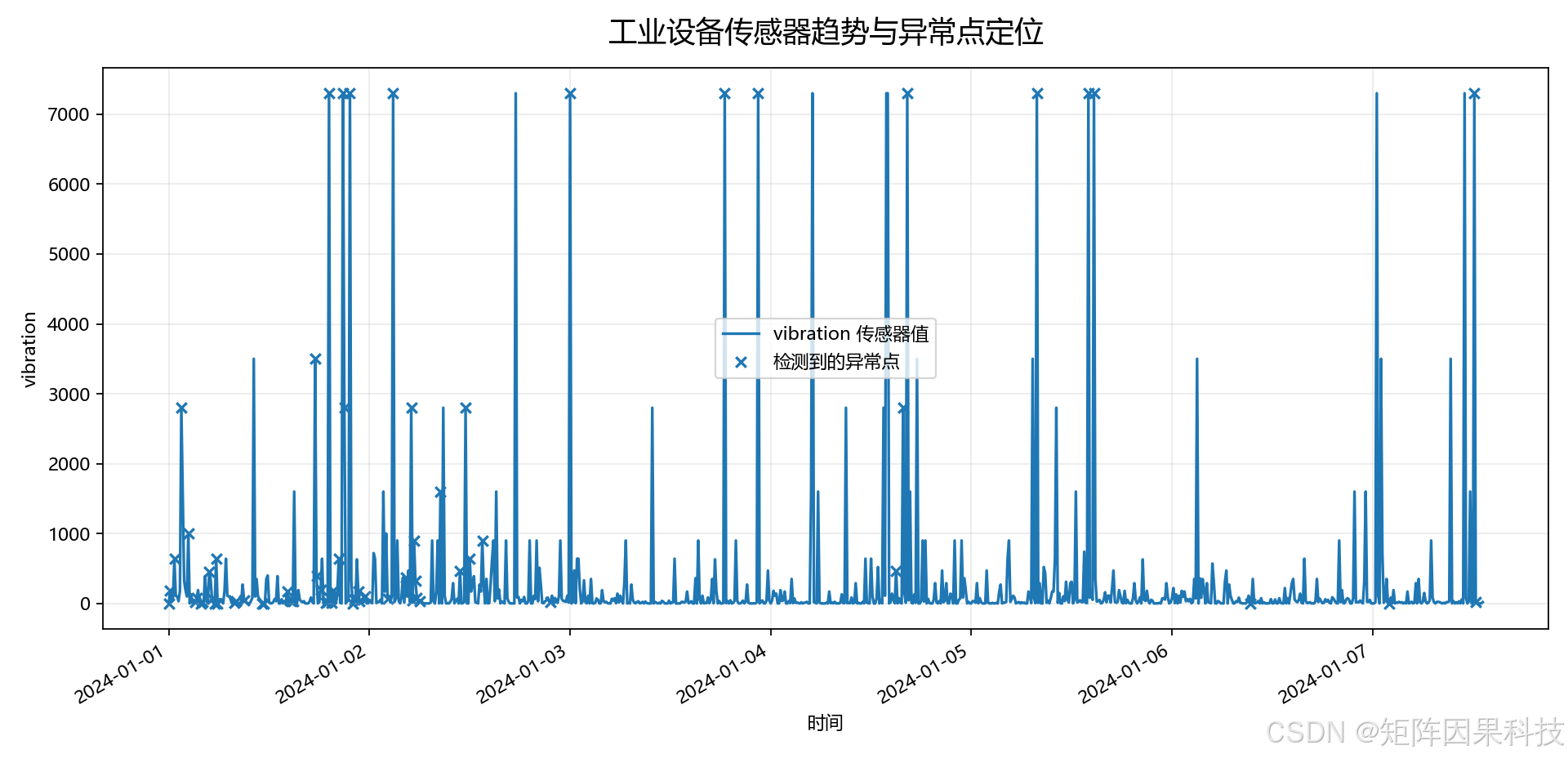
传感器趋势与异常点图如下:
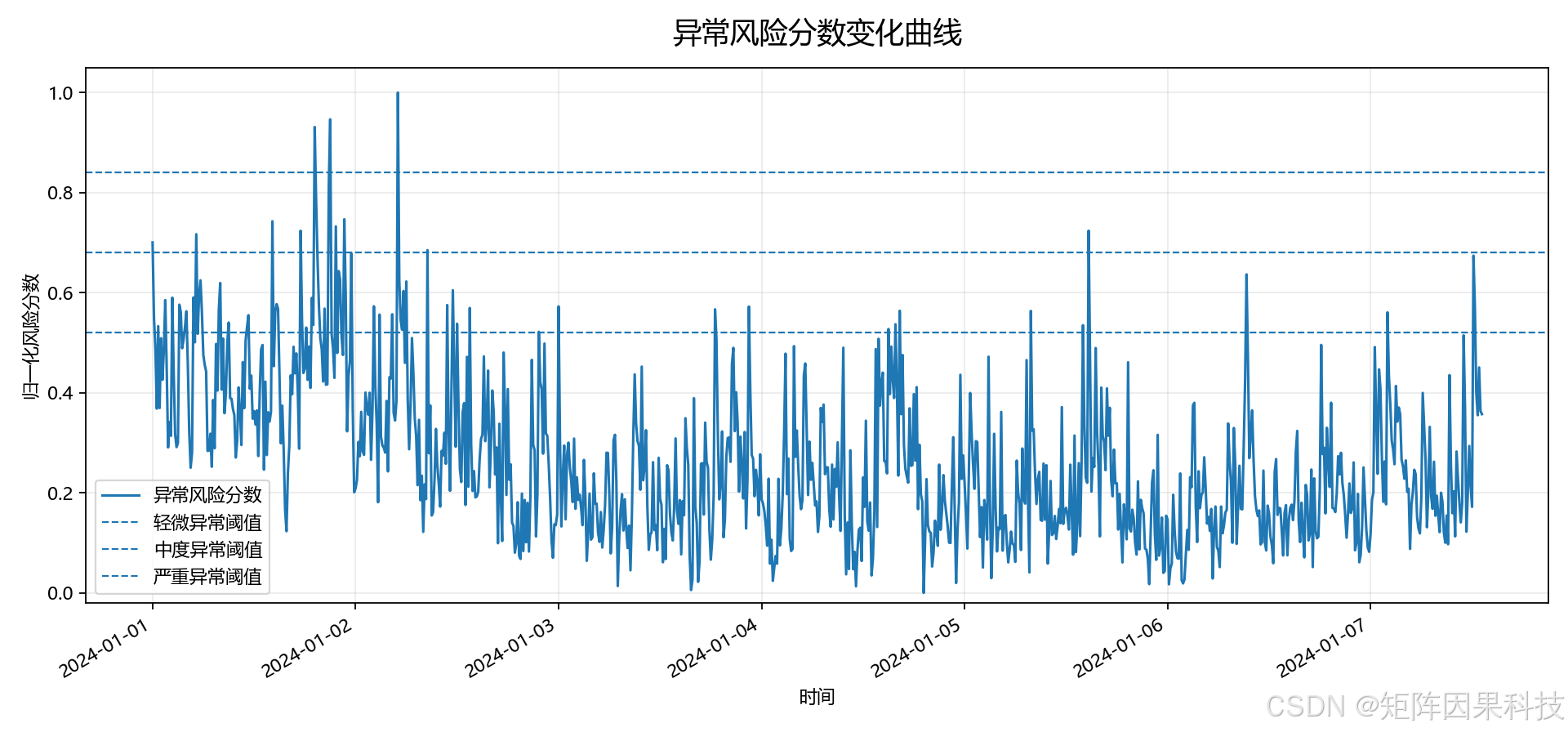
异常风险曲线如下:
设备健康评分趋势如下:
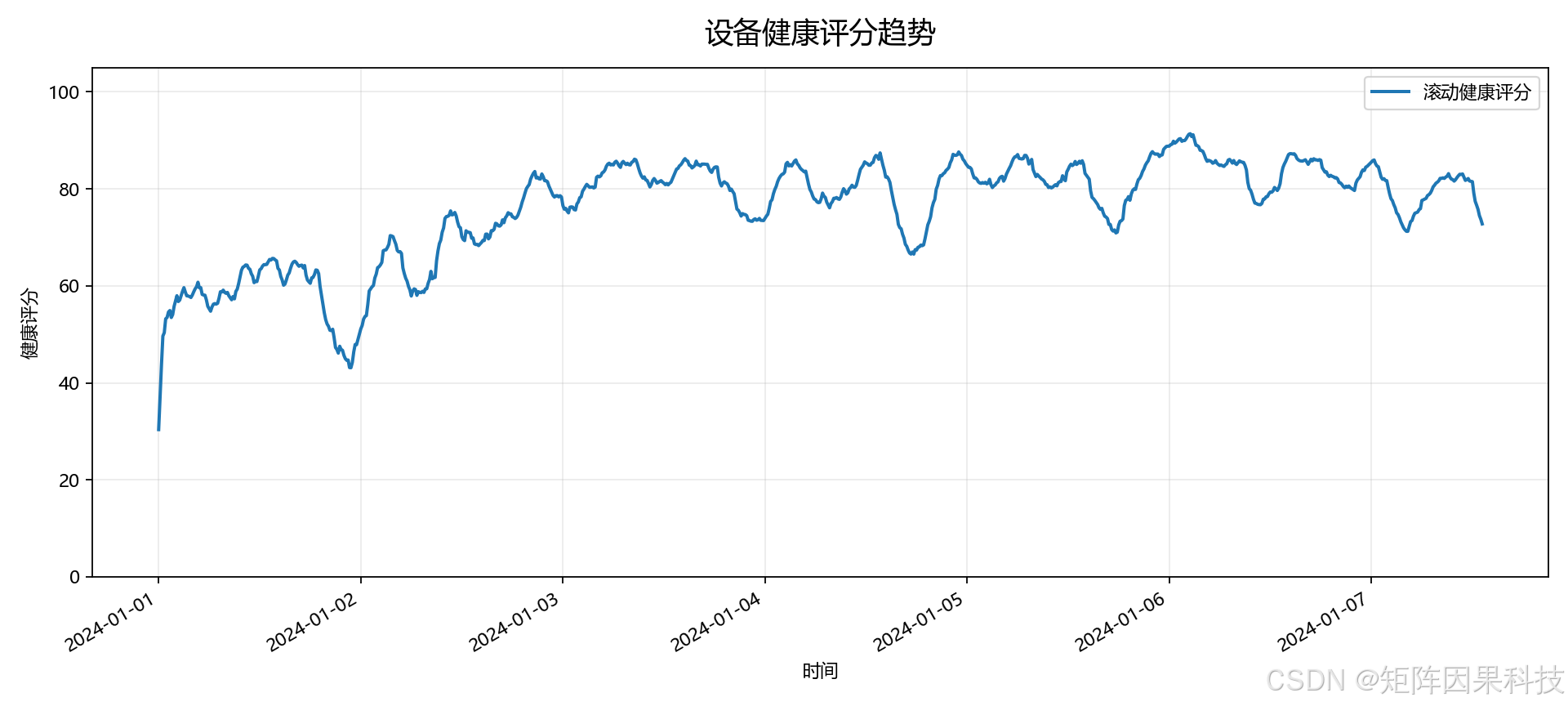
报警记录表如下:
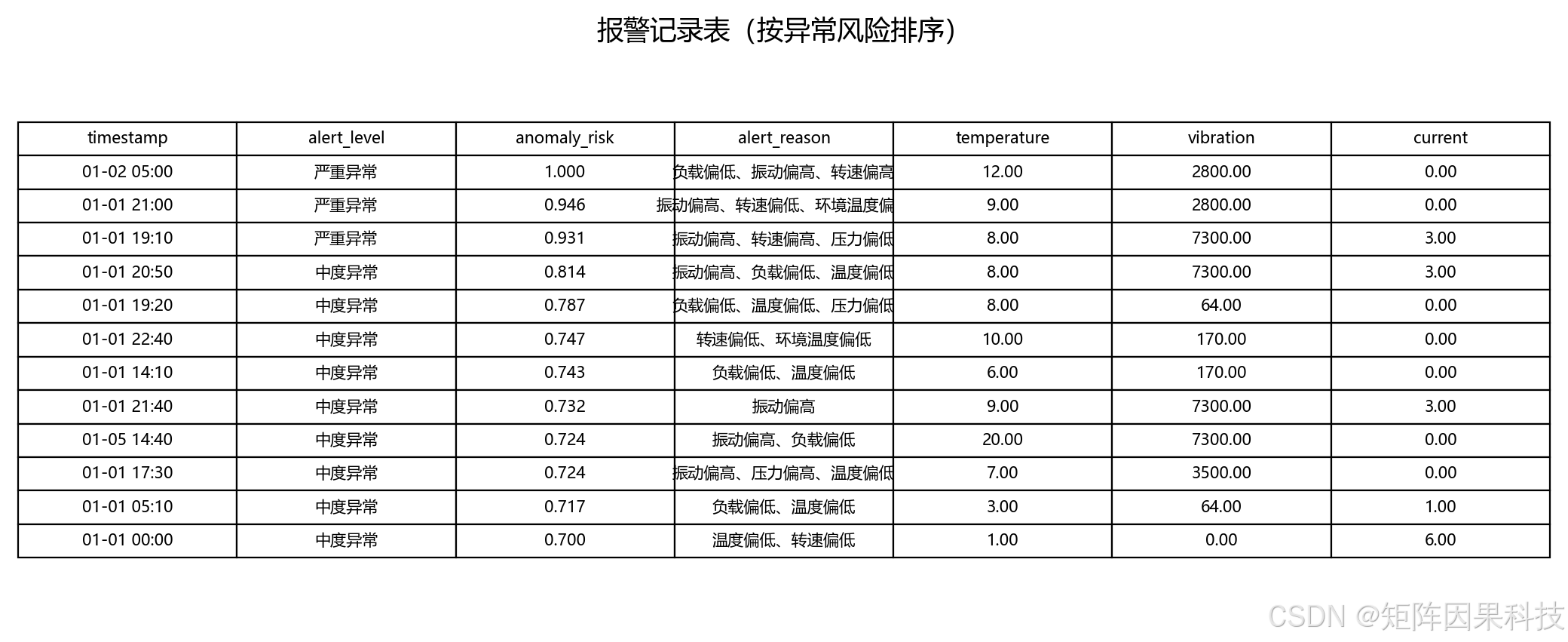
上面的看板图来自实际启动后的 Streamlit 页面截图;趋势图、风险曲线、健康评分和报警表来自 scripts/run_ibm_iot_real_data.py 对外部 CSV 的真实运行输出,并保存到 images/results/。对于 CSDN 项目实战文章来说,这一点很重要,因为读者通常会先看运行效果,再决定是否继续阅读代码说明。
如果你希望换成自己的数据,只需要保证 CSV 至少包含以下字段:
timestamp, temperature, pressure, vibration, current, rpm, load, ambient_temp
然后在 Streamlit 页面上传即可。字段名不同的情况,可以在 configs/config.yaml 里修改 sensor_columns,或者在 src/data_loader.py 中增加字段映射逻辑。
结果分析、常见问题与扩展优化
从本次外部数据运行结果看,系统分析了 944 条传感器记录,检测到 69 条报警记录,报警比例约为 7.31%。其中严重异常数量为 3,中度异常数量为 10,说明系统能够把少量高风险点和较多中等风险点区分开。
观察趋势图可以看到,外部数据中负载扰动、压力、温度和控制信号出现明显偏离时,风险曲线会明显抬升。健康评分图则会在异常密集出现的时间段下降,能够从另一个角度反映设备状态变化。报警表中给出的“振动偏高、压力偏高、环境温度偏低”等原因,来自模型对当前记录相对正常基线偏移程度的解释。
常见问题可以从以下几个方面排查。
运行时报缺少依赖。
先确认是否安装了基础依赖:
pip install -r requirements.txt
如果只想运行基础版,不需要安装 requirements_pyod.txt。PyOD 是增强项,不影响 Isolation Forest 版本运行。
检测出的异常太多。
可以降低 configs/config.yaml 中的 contamination,例如从 0.065 调整为 0.04。也可以提高 minor_threshold、medium_threshold 和 severe_threshold,减少报警数量。
检测出的异常太少。
可以适当提高 contamination,或者降低报警阈值。也可以增加更多变化特征,例如滚动最大值、滚动最小值、斜率特征、频域振动特征等。
中文图表显示为方块。
项目的 src/visualization.py 已经优先查找 NotoSansCJK、微软雅黑、黑体、苹方等中文字体。如果本机没有中文字体,可以安装 Noto Sans CJK 或微软雅黑字体,再重新运行 python scripts/run_ibm_iot_real_data.py 或 python run_demo.py。
真实数据字段和样例字段不一样。
可以修改 configs/config.yaml 中的 sensor_columns。例如你的数据只有 temperature、vibration 和 current,就把列表改成这三个字段。代码会根据配置自动构造特征。
项目能否用于真实工业现场。
当前项目适合做原型、课程设计、算法验证和内部数据分析。真实现场部署还需要接入数据库、消息队列、实时采集服务、报警推送、权限管理和专家规则,并且要结合设备类型和历史故障记录重新校准阈值。
后续扩展方向包括:支持多设备同时监控、接入 SQLite/MySQL/PostgreSQL、增加实时数据流、接入 MQTT、增加短信或企业微信报警、加入 SHAP 解释、加入 LSTM-AE 深度学习模型、接入 NASA C-MAPSS 数据集做剩余寿命预测、把 Streamlit 改造成 FastAPI + Vue 前后端系统。
总结与发布建议
本文完成了一个完整的工业设备传感器异常检测与故障预警系统。项目不是只讲 Isolation Forest 算法概念,而是围绕真实项目交付所需的内容展开:有样例数据、有配置文件、有清洗代码、有特征工程、有异常检测、有报警分级、有健康评分、有可视化图表、有 Streamlit 页面、有 README、有运行脚本,也有可以直接发布到 CSDN 的博客正文。
项目默认不依赖 GPU,不需要下载大模型权重,适合普通电脑直接运行。它和常见的 YOLO 目标检测、RAG 知识库、CLIP 图片检索项目有明显差异,数据类型是结构化传感器时序数据,应用场景是工业设备监测和预测性维护,展示形式是趋势图、报警表和健康评分看板。对于想做差异化 AI 项目实战内容的账号来说,这个选题很适合发布。
建议发布标题:
基于 Isolation Forest + PyOD + Streamlit 的工业设备异常检测与故障预警系统:Python 机器学习项目实战
建议标签:
Python
机器学习
异常检测
Isolation Forest
PyOD
Streamlit
工业设备
故障预警
传感器数据分析
预测性维护
数学建模
课程设计
参考资料:
scikit-learn IsolationForest 官方文档
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
PyOD 官方文档
https://pyod.readthedocs.io/
Streamlit 官方文档
https://docs.streamlit.io/
IBM iot-predictive-analytics IoT sensor dataset
https://github.com/IBM/iot-predictive-analytics
NASA C-MAPSS Jet Engine Simulated Data
https://data.nasa.gov/dataset/cmapss-jet-engine-simulated-data
如果需要继续强化项目,可以优先做三件事。第一,把样例数据替换为真实设备数据,并调整字段配置;第二,增加多算法对比,例如 Isolation Forest、LOF、ECOD、KNN 的报警结果对比;第三,把 Streamlit 看板扩展成支持多设备、多日期筛选和报警记录管理的完整系统。这样项目就可以从课程设计原型继续升级为更接近工程交付的工业 AI 数据应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)