ProDrive:基于自车与环境协同演化的自动驾驶主动规划
26年4月来自南方科技大学和港科大的论文“ProDrive: Proactive Planning for Autonomous Driving via Ego-Environment Co-Evolution”。
端到端的自动驾驶规划器通常仅依据当前观测数据来生成轨迹。然而,现实世界的驾驶环境高度动态,这种被动式的规划方式无法预判未来场景的演变,往往导致决策短视,甚至引发危及安全的故障。为此提出 ProDrive,一个基于世界模型的主动规划框架,旨在实现自动驾驶中的“自车-环境”协同演化。ProDrive 采用端到端的方式,联合训练一个以查询为中心的轨迹规划器和一个鸟瞰图(BEV)世界模型:规划器负责生成多样化的候选轨迹及具有规划-觉察能力的“自车” tokens,而世界模型则以此为条件,预测未来场景的演变。通过将规划器的特征注入世界模型,并对所有候选轨迹进行并行评估,ProDrive 保持端到端的梯度流,从而使对未来结果的预估能够直接反哺并指导规划决策。这种双向耦合机制使得主动规划成为可能,从而超越仅由当前观测数据驱动的传统决策模式。在 NAVSIM v1 数据集上的实验结果表明,ProDrive 在安全性与规划效率两方面均显著优于强基线模型;同时,消融实验也充分验证所提出的“自车-环境”耦合设计方案的有效性。
世界模型通过预测未来的环境状态,为前瞻性推理提供一种机制。在自动驾驶领域,现有的研究工作主要分为两大类:生成式世界模型和结构化世界模型。生成式世界模型方法(例如 GAIA-1 [11]、DriveDreamer [31] 和 ADriver-I [14])侧重于根据多模态输入,合成逼真的未来驾驶视频或图像帧。尽管这些方法在视觉效果上引人注目,但它们是在高维像素空间中进行操作,这不仅计算成本高昂,而且难以与下游的规划模块紧密集成。
另一条研究路线探索的是结构化世界模型,这类模型旨在预测紧凑且与任务高度相关的表征。以 LAW [17] 为例,该模型学习一种潜世界模型,能够在给定自车动作的条件下预测未来的场景特征,并利用自监督机制来提升特征学习和动作预测的性能。近期的一些研究工作进一步将未来状态建模与端到端的规划流程紧密结合。具体而言,SeerDrive [36] 通过预测未来的鸟瞰图(BEV)表征来辅助规划;PWM [40] 在一种“策略世界模型”框架下统一预测与规划任务;FutureSightDrive [34] 利用视觉时空推理能力来实现具备未来感知能力的规划;而 ImagiDrive [15] 则在一个“想象-规划”的闭环中,将自动驾驶智体与场景想象模块进行耦合。
本文提出的方法与结构化世界模型这一研究方向最为接近,但在一个关键方面有所不同。其并未像现有方法那样,将世界模型的预测过程建立在通用的潜特征或相互解耦的动作tokens之上;取而代之,本文将规划器动态优化生成的轨迹tokens直接注入到基于 BEV 视图的世界模型之中。这种规划器与世界模型之间更为紧密的耦合机制,为未来状态的预测提供更为丰富且具备“规划-觉察”能力的语义信息;这使得模型能够针对特定的候选轨迹进行有针对性的未来状态推演,并基于更具信息量的奖励信号对候选轨迹进行重新排序与筛选。
如图 1 所示从被动式到主动式自动驾驶:(a) 传统的端到端规划器属于被动式,主要依据当前观测生成轨迹,而未显式地对未来场景演变进行建模;(b) 近期的一些方法利用“世界模型”对轨迹进行重排序,但规划器与世界模型之间仍处于松耦合状态,从而限制规划器端从未来推理中直接获益的能力;© 相比之下,ProDrive 通过“自车-环境协同演化”实现主动式驾驶:规划器提供“自车tokens“以支持感知规划器的未来预测;与此同时,世界模型对候选轨迹进行评估,并通过端到端的梯度反馈来引导规划器。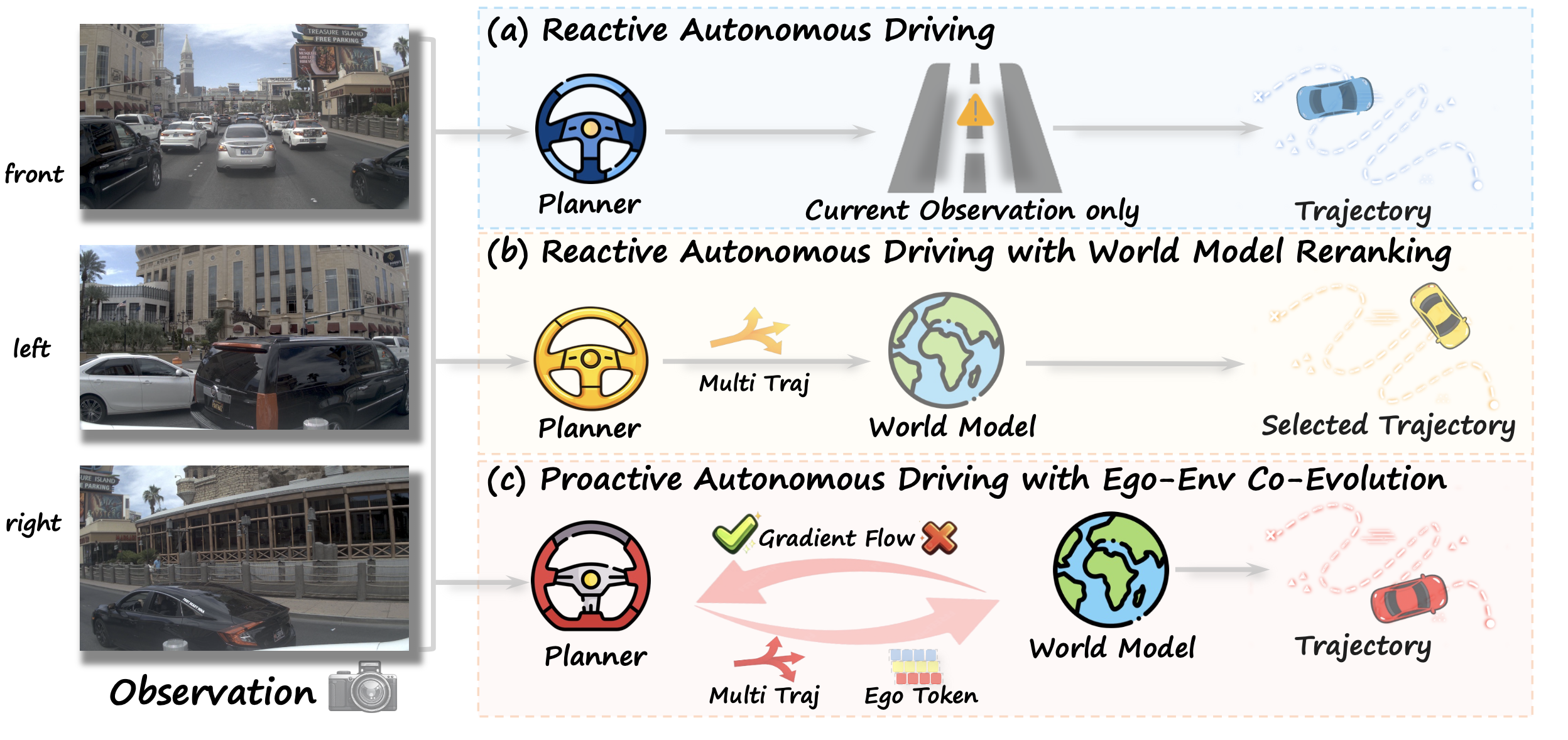
ProDrive 由两个紧密耦合的组件构成:一是“自车模块”(Ego Module),这是一个以查询为中心的规划器,通过优化可学习的“自车Tokens“来生成多样化的候选轨迹;二是“环境模块”(Environment Module),这是一个基于鸟瞰图(BEV)的世界模型,用于预测未来的场景状态并对上述候选轨迹进行评估。此外,还引入一种“自车-环境耦合机制”,将这两个模块相互连接,从而实现自车规划与环境动态之间的双向交互与协同演化。
如图 2 所示ProDrive 概览。给定多视角图像、激光雷达数据以及自车状态,自车模块(Ego Module)通过 L 层自车细化器(Ego Refiner)对可学习的自车查询(ego queries)进行精炼,从而获得自车tokens;随后,系统基于这些表征解码出候选轨迹,并将其转化为轨迹表征。在这些表征及当前鸟瞰图(BEV)状态的条件下,环境模块(Environment Module)执行循环式的 BEV 未来状态预测,并基于奖励机制对轨迹进行评估。通过自车tokens的注入以及端到端的梯度反馈,这种双向耦合机制实现自车与环境的协同演化,使 ProDrive 能够基于对未来场景动态的预判,学习并执行主动式的规划策略。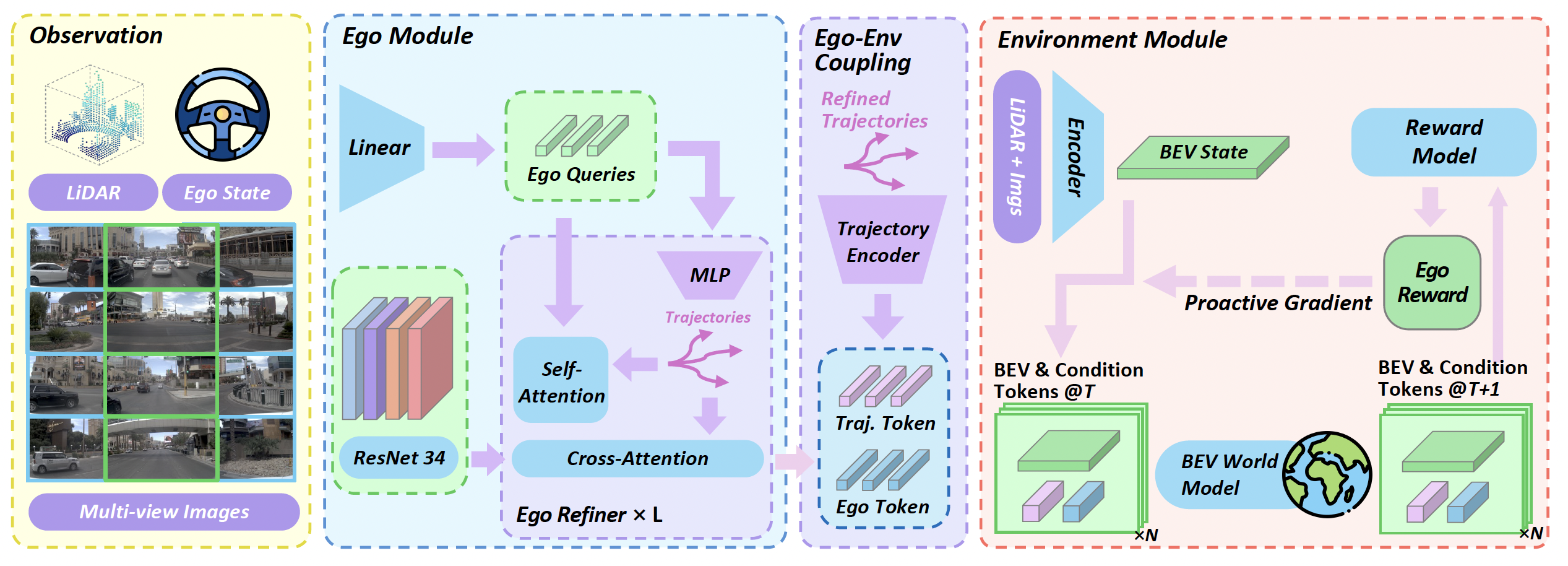
1. 问题定义
给定来自 C 个相机的多视角图像集 I = {I_1, …, I_C}、激光雷达点云 P 以及自车状态 s_ego(包括速度、加速度和横摆角速度),目标是预测一条未来轨迹 τˆ_t = {(xˆ_t, yˆ_t, θˆ_t)} 。该轨迹包含 T 个航点,位于以自车为中心的坐标系下,其中每个航点指定了位置 (x, y) 和航向角 θ。
2. 自车模块:以查询为中心的规划器
自车模块(Ego Module)是一个以查询为中心的规划器,其架构基于 BEVFormer [19]。该模块利用 ResNet-34 主干网络 [10] 对多视角图像进行编码,并将自车状态投影为自车条件特征,随后将这些特征添加至一组可学习的自车 Token Q(0) 中。所得的规划 Token 随后经过迭代细化,以生成针对各类候选轨迹的、具有轨迹感知能力的表征。
迭代交叉注意力细化。自车 Token 经过 L 个级联的细化阶段进行迭代优化,这些阶段共享参数。在每个阶段 l 中,细化过程包含两个步骤:
步骤 1:轨迹解码。一个 MLP 头将每个自车 Token 解码为一个轨迹航点 τ(l) = MLP,从而在细化阶段 l 生成 K 条候选轨迹。
步骤 2:基于交叉注意的特征细化。解码所得的轨迹位置 τ(l) 作为参考点,用于执行可变形交叉注意(Deformable Cross-Attention),从而重新关注多视角图像特征。自车 Token 通过关注图像特征中与各轨迹航点相对应的空间位置信息而得到更新,生成新的自车 Token Q(l+1) = EgoRefiner。
这种迭代细化机制确保 Ego tokens 能够循序渐进地从场景中编码出更为丰富的空间上下文信息,且这些信息均对应于各候选轨迹所处的相关位置。经过 L 个阶段后,最终的候选轨迹集 {τk} = τ(L) 以及经过细化的 Ego tokens Q(L) 便生成完毕。
Ego 模块训练。Ego 模块的训练过程综合运用轨迹损失、评分损失以及辅助感知损失。针对轨迹生成任务,在所有细化阶段上统一应用一种“赢者通吃”(winner-take-all)式的回归损失 L_traj,并辅以一项多样性正则化项。
进一步利用在线的逐提案 PDM 目标及辅助标签(包括关键智体状态、有效性指标和自车区域占用情况),对规划器侧的评分器 L_score 进行监督。
此外,保留来自自查询的辅助 BEV 感知损失 L_aux,这有助于稳定自车 token 的表征,并提升候选框的生成质量。综合而言,这些优化目标共同促进准确且多样化的候选框生成、面向规划的评分机制,以及鲁棒的自车 token 学习。
3. 环境模块:BEV 世界模型
为了在未来交互情境下对每个候选方案进行评估,沿用 TransFuser [24] 的做法,采用独立的相机-激光雷达主干网络来生成初始 BEV 状态 B_0。对于每一个候选方案 τ k,相应的动作token ak 编码其轨迹几何特征及自车运动学状态。
循环未来预测。该世界模型将通过 N 次迭代,对未来的 BEV 状态进行预测。该序列经由学得的位置嵌入进行增强,随后由 Transformer 编码器进行处理;这一过程可表述为如下方程:
[ak_i+1 ; ˆsk_i ; Bk_i+1 ] = WorldModel(F_i + P_scene)
其输出结果包含预测的未来动作 token ak_i+1、增强后的状态 token ˆsk_i,以及预测的未来 BEV 状态 Bk_i+1。
轨迹选择。对于每一个候选轨迹,将多步 BEV 特征与动作 Token 聚合成一种紧凑的奖励表征。两个预测头分别负责预测:一是受专家轨迹距离监督的模仿奖励;二是针对避撞、可行驶区域合规性、行驶进度、碰撞剩余时间及舒适度等指标的仿真导向型奖励。
在计算最终得分时,与安全性相关项作为强约束条件,而效率与舒适度项则进行柔性权衡。无论是在训练阶段还是推理阶段,最终均通过 argmax 操作选取得分最高的轨迹。
环境模块训练。环境模块采用奖励监督和语义BEV预测进行训练。对于轨迹级奖励学习,它预测模仿型奖励和模拟型奖励。模仿型奖励由一个软目标进行监督即L_im,该软目标源自轨迹与专家轨迹的接近程度。其中模仿式奖励由一个“软目标”进行监督即L_sim,该软目标基于预测轨迹与专家轨迹的接近程度计算得出;而仿真式奖励则利用预计算的、源自最近锚点轨迹的仿真器指标进行监督。为了进一步耦合自车模块(Ego Module)与环境模块,将规划器的得分与归一化的世界模型得分进行对齐,即L_align。
这样定义:
L_reward = λ_im L_im + λ_sim L_sim + λ_align L_align
此外,为了学习与规划相关的场景动态,对世界模型所预测的当前及未来语义 BEV 地图均施加监督,即L_wm,未来的目标图是以“提案条件化”的方式构建的——具体做法是在未来的语义 BEV 画布上,于采样的提案位置处渲染出自车的边框。综合来看,上述各项目标共同促使环境模块生成信息丰富的奖励信号,并输出具有规划-觉察能力的未来场景预测。
4. 自车-环境耦合
ProDrive 以双向方式耦合“自车模块”(Ego Module)与“环境模块”(Environment Module)。自车模块通过注入“自车Token“ 来提升对未来的预测能力;而环境模块则通过端到端优化来引导自车模块,从而使其能够基于预测到的未来场景演变进行主动规划。
自车token注入。将规划器与世界模型耦合时面临的一个关键挑战在于:未来的预测结果可能会丢失规划器内部的决策语义。现有方法 [17] 通常仅依赖通用的潜特征或原始轨迹坐标来对世界模型进行条件化处理,但这往往会舍弃掉规划过程中所积累的更为丰富的上下文信息。为了解决这一问题,将经过精炼的规划器特征直接注入到世界模型之中。具体而言,规划器的输出 Q(L) 会被重塑为 Q_plan。在世界模型的第 i 次迭代中,对应于时间步 t_i 的对齐特征 sk_i 会被投影为一个自车token。这一机制使得未来的预测结果不仅取决于自车将要移动至何处,更取决于规划器提出该项移动决策背后的深层原因。
联合训练目标。采用多任务目标函数对 ProDrive 进行端到端训练,该目标函数对以下三个环节进行联合监督:自车模块中的方案生成、环境模块中的方案评估,以及这两个模块之间的耦合关系:
L = L_traj + L_score + L_reward + L_wm + L_aux
除非另有说明,所有实验均遵循已发布代码实现中的默认训练方案。ProDrive 基于 PyTorch 和 PyTorch Lightning 实现。两个模块均采用 ResNet-34 作为图像主干网络,其中环境模块(Environment Module)额外采用 ResNet-34 作为 LiDAR 主干网络。智体(Agent)从 NAVSIM 历史窗口中读取索引为 [3] 的同步传感器切片作为输入,该切片包含四路环视相机图像(前视、左视、右视和下视)以及一次 LiDAR 扫描数据。设定 4 秒的规划视域(planning horizon)和 0.5 秒的采样间隔,从而生成 T = 8 个轨迹航点。以查询为中心的规划器(query-centric planner)生成 K = 64 条候选轨迹;除非另有说明,完整模型在训练时默认启用“世界模型分支”(world-model branch)和“自车token注入”(ego token injection)机制。
在训练阶段,从头开始训练模型,且所有参数均保持可训练状态。优化过程采用 Adam 优化器,并针对两组参数分别设置学习率:自车模块(Ego Module)的学习率为 10⁻⁴,环境模块(Environment Module)的学习率为 10⁻⁵;这种设置有助于在耦合轨迹生成与未来预测任务时,稳定模型的联合优化过程。训练共进行 15 个 Epoch,利用 8 块 GPU 采用混合精度(mixed precision)进行分布式数据并行训练。为每块 GPU 设置 16 的批次大小(batch size),并配置 8 个数据加载工作进程。训练数据取自 NAVSIM 数据集的“trainval”拆分集,并应用“navtrain”场景过滤器进行筛选。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)