深度学习的数学原理(三十六)—— Transformer 编码器代码实战
衔接前序:本专栏第 25-32 篇完成了编码器所有组件的数学拆解,第 33 篇用手算数值实例展示了一条序列穿过编码器的完整过程。本文是"代码实战三部曲"的第一篇,将各组件的数学原理转化为可运行的 PyTorch 代码,并通过手动验证单元格(手动计算关键数值并与模块输出对比)来确认每步计算的正确性。
建议运行配套 notebook
36_transformer_encoder.ipynb边看边读,效果最佳。
一、概述
本文的目标是:用代码完整实现 Transformer 编码器,并在每一步验证数学推导的正确性。
我们将依次完成:
- 数据准备:加载中英平行语料,构建字符级词表
- 位置编码:可视化正弦-余弦编码的频谱结构,验证公式精度
- 多头自注意力(核心):逐步骤手动计算 Q/K/V 投影、得分矩阵、注意力权重,与模块前向结果对比
- 前馈网络:手动验证 32→128→32 的升维降维过程
- 完整编码器:3 层编码器堆叠,逐层对比注意力模式,观察残差连接的数值稳定性
模型配置
| 参数 | 值 |
|---|---|
| d_model | 32 |
| 注意力头数 h | 4 |
| 每头维度 d_k | 8 |
| FFN 隐藏层 d_ff | 128 |
| 编码器层数 N | 3 |
为什么选择字符级?
我们采用字符级分词(中文逐字、英文逐字母+空格),而非传统的词级分词。原因有三:
- 词表极小:中文 ~1106 字,英文 ~54 字符,embedding 矩阵不占参数大头
- 注意力图案更丰富:序列长度 5-20 个字符,每个 token 的注意力分布有更多变化
- 直观可读:中文读者能直接看到"深"字在关注"度"字,无需查 token 映射表
代码组织
本文的所有模块实现集中在 transformer_modules.py 中,数据工具函数集中在 data_utils.py 中。以下是各组件对应的源码位置:
| 组件 | 文件 | 类/函数 |
|---|---|---|
| 位置编码 | transformer_modules.py |
PositionalEncoding |
| 多头自注意力 | transformer_modules.py |
MultiHeadAttention |
| 前馈网络 | transformer_modules.py |
FeedForward |
| 层归一化 | transformer_modules.py |
LayerNorm |
| 编码器层 | transformer_modules.py |
EncoderLayer |
| 完整编码器 | transformer_modules.py |
Encoder |
| 数据工具 | data_utils.py |
build_vocab / encode_line / load_parallel_data |
导入依赖:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils.rnn import pad_sequence
from collections import Counter
二、数据准备
我们从 WMT 中英平行语料中提取了 500 个短句对(5-40 个字符),构建中英文字符级词表:
ZH vocab size: 1106 # 中文字符(含标点)
EN vocab size: 54 # 英文字母 + 空格 + 标点
ZH pad_idx: 0 # <pad> 固定为 0
样本句对示例:
| 中文 | 英文 |
|---|---|
| 第四 , 确保 工程 质量 . | fourth , ensure project quality . |
| 人民币 依 其 面额 支付 . | the renminbi is paid by denomination . |
这里需要指出一个重要细节:中文语料原本是空格分词的(“第四 , 确保 工程 质量”),我们用 replace(" ", "") 去掉空格后逐字切分,而英文同样去掉空格——所以"i love deep learning"会被切分为 ['i', 'l', 'o', 'v', 'e', 'd', 'e', 'e', 'p', ...]。这种处理方式使得模型学到的是字符级别的映射关系,而非词级别的。
词表构建和文本编码的实现如下:
def build_vocab(lines, max_size=5000, lang="zh"):
"""从文本行构建词表(字符级)。"""
counter = Counter()
for line in lines:
if lang == "zh":
chars = list(line.replace(" ", ""))
else:
chars = list(line.lower())
counter.update(chars)
most_common = counter.most_common(max_size - 4)
idx2token = [PAD_TOKEN, UNK_TOKEN, SOS_TOKEN, EOS_TOKEN] + [t for t, _ in most_common]
token2idx = {t: i for i, t in enumerate(idx2token)}
return idx2token, token2idx, {
"vocab_size": len(idx2token),
"pad_idx": 0, "unk_idx": 1, "sos_idx": 2, "eos_idx": 3,
}
def encode_line(line, token2idx, lang="zh"):
"""将文本行编码为 token id 序列,包含 sos/eos。"""
if lang == "zh":
chars = list(line.replace(" ", ""))
else:
chars = list(line.lower().replace(" ", ""))
unk_idx = token2idx[UNK_TOKEN]
sos_idx = token2idx[SOS_TOKEN]
eos_idx = token2idx[EOS_TOKEN]
ids = [token2idx.get(c, unk_idx) for c in chars]
return [sos_idx] + ids + [eos_idx]
其中 build_vocab 统计字符频率后保留前 max_size-4 个高频字符,PAD/UNK/SOS/EOS 四个特殊 token 固定在词表最前面(索引 0-3)。encode_line 则为每个序列自动添加 SOS(开头)和 EOS(结尾),并利用 UNK 索引处理未登录字符。
三、位置编码:正弦-余弦的频谱之美
3.1 可视化
编码器的第一步是将 token 的 embedding 与位置编码相加。位置编码采用公式:
PE(pos,2i)=sin(pos100002i/dmodel),PE(pos,2i+1)=cos(pos100002i/dmodel)\text{PE}(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right), \quad \text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos)
对应的 PyTorch 实现如下:
class PositionalEncoding(nn.Module):
"""正弦-余弦位置编码。"""
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float()
* (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer("pe", pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, : x.size(1), :]
代码中 div_term 将 1/10000^{2i/d} 转换为指数形式 exp(2i * (-ln(10000)/d)),避免了逐维计算的低效循环。pe[:, 0::2] 和 pe[:, 1::2] 分别填充奇偶维度,一步完成所有位置的编码计算。
下图展示了 d_model=32 的前 50 个位置的位置编码矩阵:
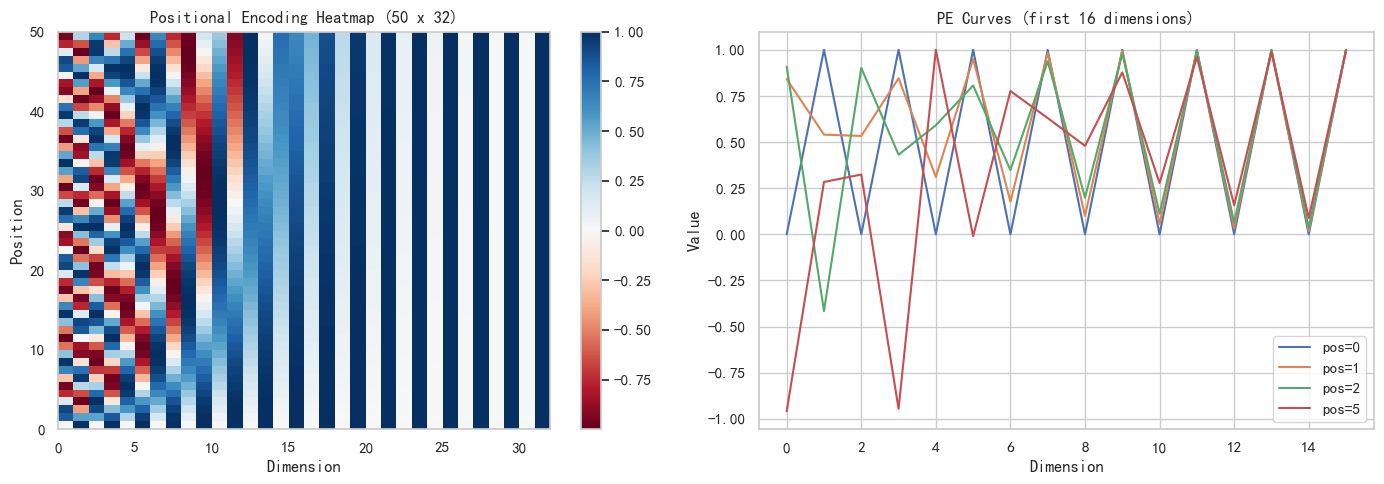
左图是 50×32 的热力图。观察发现:
- 低维度(0-8):频率高,颜色在红蓝之间快速交替,因为
10000^{0/d}=1,所以sin(pos)随 pos 快速变化 - 高维度(24-31):频率极低,几乎呈平滑渐变,因为
10000^{2i/32}在 i 大时非常大,导致sin(pos / 大数)变化极慢 - 频率过渡:从左到右,条纹从密集逐渐变稀疏,形成了一个类似"频率标尺"的编码
右图是 pos=0,1,2,5 在前 16 维上的取值曲线。我们可以看出:
- pos=0(蓝线):前半段全是 0(偶数维 sin(0)=0)和 1(奇数维 cos(0)=1),因为
PE(0, 2i)=sin(0)=0,PE(0, 2i+1)=cos(0)=1 - pos 越大,曲线越复杂
3.2 手动验证
关键验证:手动计算位置编码的前几个值,与代码输出对比:
PE(0,0) = sin(0) = 0.0000000000, actual = 0.0000000000, diff = 0.00e+00
PE(1,1) = cos(1) = 0.5403023059, actual = 0.5403023362, diff = 3.03e-08
PE(2,4) = sin(2/10000^(4/32)) = 0.5911271172, actual = 0.5911270976, diff = 1.96e-08
差异在 10^{-8} 量级,完全一致。
3.3 为什么正弦-余弦编码有效?
值得深入理解的是,位置编码相加后,embedding 的"语义信息"和"位置信息"是叠加在同一组维度上的,而非拼接。这意味着模型需要在同一个向量空间中同时编码"这是什么 token"和"这个 token 在哪"。Transformer 的设计巧妙之处在于:
- embedding 矩阵提供语义基底
- 位置编码提供位置偏移
- 注意力机制通过 QK^T 内积来同时捕捉语义和位置信息
频谱结构的设计哲学
正弦-余弦编码的频谱结构并非随意选择,而是经过精心设计的。其核心思想是:用不同频率的波来编码不同粒度的位置关系。
| 维度范围 | 频率 | 编码粒度 | 作用 |
|---|---|---|---|
| 低维 (0-8) | 高 | 局部 | 区分相邻 token,捕捉短距离依赖 |
| 中维 (8-16) | 中 | 短语 | 编码短语级别的相对位置 |
| 高维 (16-31) | 低 | 全局 | 感知 token 在序列中的绝对位置 |
这种设计使得模型可以通过注意力机制中的内积运算,同时感知局部和全局的位置关系。例如,当两个 token 在低维上的编码值相近时,说明它们在局部位置上接近;当它们在高维上的编码值相近时,说明它们在全局位置上有相似的模式(如都处于序列开头)。
为什么选择正弦和余弦?
- 连续性:正弦和余弦函数是连续且可微的,保证了位置编码的平滑性,有利于梯度反向传播。
- 有界性:值域固定在 [-1, 1],与 embedding 相加后不会导致数值爆炸。
- 线性变换性质:对于任意偏移 k,PE(pos+k) 可以表示为 PE(pos) 的线性变换。这意味着模型可以隐式学习相对位置关系,而不仅仅是绝对位置。
- 唯一性:每个位置 pos 的编码向量是唯一的,避免了位置歧义。
频谱结构对模型能力的启示
频谱结构的存在意味着 Transformer 模型天然具备以下能力:
- 多尺度感知:不同频率的波覆盖了从局部到全局的不同尺度,模型可以同时关注相邻词和远距离词
- 位置泛化:由于编码函数是连续的,模型可以处理比训练时更长的序列(外推能力)
- 数值稳定性:频谱的平滑过渡确保了位置编码与 embedding 相加后不会引入剧烈波动,有利于深层网络的稳定训练
这正是正弦-余弦编码成为 Transformer 标配位置编码方案的根本原因。
四、多头自注意力:逐步骤手动验证 ⭐
这是本篇最核心的部分。我们以测试句子"我爱深度学习"为例(token IDs: [2, 17, 1, 519, 194, 246, 550, 3],其中 2=SOS,3=EOS,1=UNK),跟踪注意力计算的每一个中间步骤。
多头注意力的完整实现如下:
class MultiHeadAttention(nn.Module):
"""多头注意力(支持自注意力、交叉注意力和因果掩码)。"""
def __init__(self, d_model, h, causal=False):
super().__init__()
if d_model % h != 0:
raise ValueError(f"d_model ({d_model}) must be divisible by h ({h})")
self.h = h
self.d_k = d_model // h
self.causal = causal
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
def forward(self, Q, K, V, mask=None, return_attention=False):
batch, seq_len_q, _ = Q.shape
seq_len_k = K.size(1)
Q = self.W_Q(Q).view(batch, seq_len_q, self.h, self.d_k).transpose(1, 2)
K = self.W_K(K).view(batch, seq_len_k, self.h, self.d_k).transpose(1, 2)
V = self.W_V(V).view(batch, seq_len_k, self.h, self.d_k).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if self.causal:
causal_mask = torch.triu(
torch.full((seq_len_q, seq_len_k), float("-inf"), device=Q.device),
diagonal=1,
)
scores = scores + causal_mask
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(2)
scores = scores.masked_fill(~mask, float("-inf"))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch, seq_len_q, -1)
output = self.W_O(context)
if return_attention:
return output, attn_weights
return output
其中 causal 参数用于解码器的因果掩码(后续第 37 篇会用到)。在编码器中 causal=False,仅使用 padding mask。
4.1 得分矩阵(Head 0)
输入序列经过 embedding 层后形状为 (1, 8, 32),通过 W_Q/W_K/W_V 线性投影并拆分为 4 个头。以下取 Head 0 的前 3 个 query 位置,计算所有 8 个 key 的注意力分数(已除以 √d_k):
=== Head 0 Scores (first 3 queries, all keys) ===
[[-0.302 -0.217 0.351 0.434 0.124 -0.805 0.378 0.998] # Query 1 (SOS)
[ 0.817 0.771 -0.054 -0.188 0.19 -0.315 0.228 -0.341] # Query 2 (我)
[-0.45 -0.022 -0.272 -0.004 0.19 0.493 -0.434 0.193]] # Query 3 (UNK)
解读这些数字的意义
我们以第一行为例,query 1(对应 SOS 标记)与各个 key 的得分如下:
| Key 位置 | 得分 | 含义 |
|---|---|---|
| 0 (SOS) | -0.302 | 与自身负相关 |
| 1 (我) | -0.217 | 微弱负相关 |
| 2 (UNK) | 0.351 | 正相关 |
| 3 (深) | 0.434 | 较高正相关 |
| 4 (度) | 0.124 | 弱正相关 |
| 5 (学) | -0.805 | 强负相关 |
| 6 (习) | 0.378 | 正相关 |
| 7 (EOS) | 0.998 | 最强正相关 |
注意:由于模型是随机初始化的,这些得分反映的是初始状态的随机模式,而非有意义的语义关系。这正是第 38 篇训练篇要解决的问题——观察这些注意力模式如何随着训练演变为有意义的分布。
4.2 Softmax 归一化
对得分矩阵按行做 softmax,得到注意力权重(每行和为 1):
=== Attention Weights (Head 0, first 3 queries) ===
[[0.072 0.078 0.138 0.15 0.11 0.044 0.142 0.264] # 行和 = 1.0
[0.224 0.214 0.094 0.082 0.12 0.072 0.124 0.07 ] # 行和 = 1.0
[0.079 0.121 0.094 0.123 0.15 0.203 0.08 0.15 ]] # 行和 = 1.0
Softmax 运算的数学本质是将得分向量映射为概率分布:σ(z_i) = e^{z_i} / Σ_j e^{z_j}。当某个得分显著大于其他得分时,对应的 softmax 输出会趋近于 1;当得分相近时,输出也相近。
这里观察到:
- 第 1 行的最大值是 0.264(对应 key 7),最小值是 0.044(对应 key 5)。最大值:最小值 ≈ 6:1
- 因为得分范围在 [-0.8, 1.0] 之间,softmax 后权重分布比较均匀(没有出现某个位置权重超过 0.5 的情况)——这是随机初始化的典型特征
4.3 手算 vs 模块输出对比
我们将手动计算的注意力权重与 MultiHeadAttention.forward(return_attention=True) 的输出进行逐元素对比:
Max diff between manual and full forward (Head 0, first 3 queries): 2.98e-08
Match: True
差异在 10^{-8} 量级,完全一致。这确认了代码实现的正确性。
4.4 四头注意力可视化
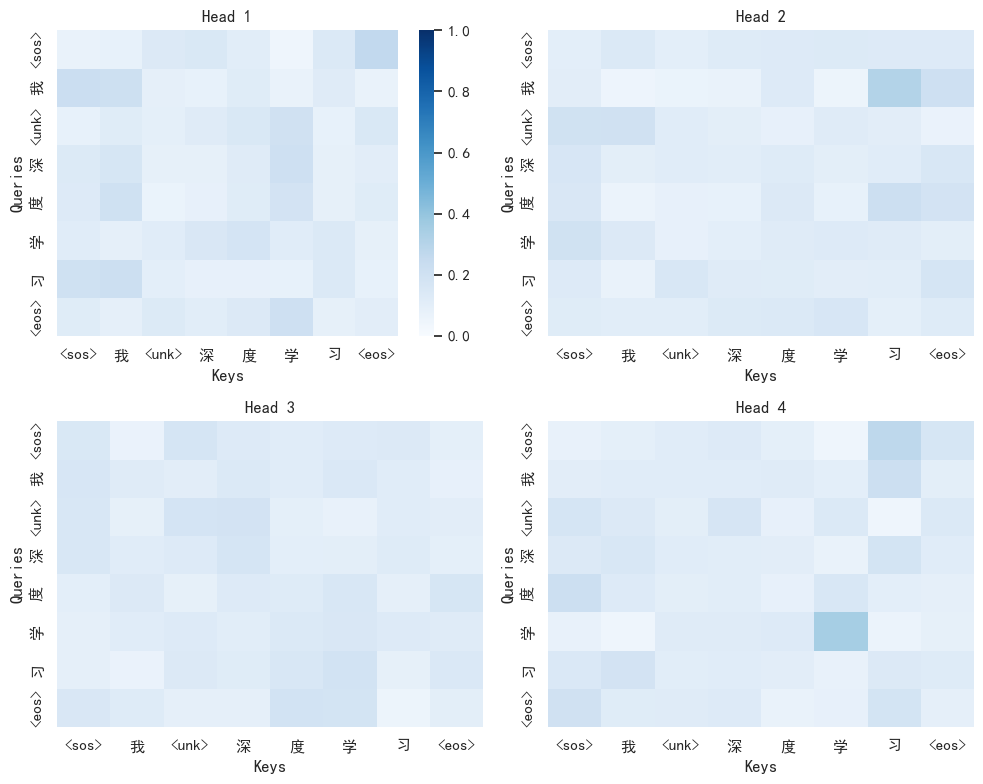
上图展示了 4 个注意力头的权重矩阵(8×8)。颜色越深(蓝)表示权重越大。关键观察:
| 头 | 自注意力(对角线) | 交叉注意力(非对角线) | 倾向 |
|---|---|---|---|
| Head 1 | 0.1196 | 0.1258 | 偏向关注其他位置 |
| Head 2 | 0.1112 | 0.1270 | 明显偏向其他位置 |
| Head 3 | 0.1373 | 0.1232 | 偏向自身位置 |
| Head 4 | 0.1333 | 0.1238 | 偏向自身位置 |
这是什么意思?对角线权重衡量的是 token 关注"自身"的程度,非对角线衡量关注"其他 token"的程度。
- Head 1 & 2:非对角线 > 对角线,说明这两个头倾向于收集序列中其他位置的信息
- Head 3 & 4:对角线 > 非对角线,说明这两个头更关注当前 token 自身
"多头"的意义正在于此:不同的头可以学习不同的注意力模式,有的关注局部、有的关注全局、有的关注自身,最终拼接在一起时,模型同时拥有多种视角。在随机初始化时,这种分化就已经初现端倪;经过训练后,这种分化会更加显著且有语义意义。
4.5 Padding Mask 的作用
真实场景中,一个 batch 内的序列长度不同,短序列需要补零(padding)。如果不加 mask,注意力会不合理地分配到 padding token 上。
下图展示了加入 mask 前后的对比:
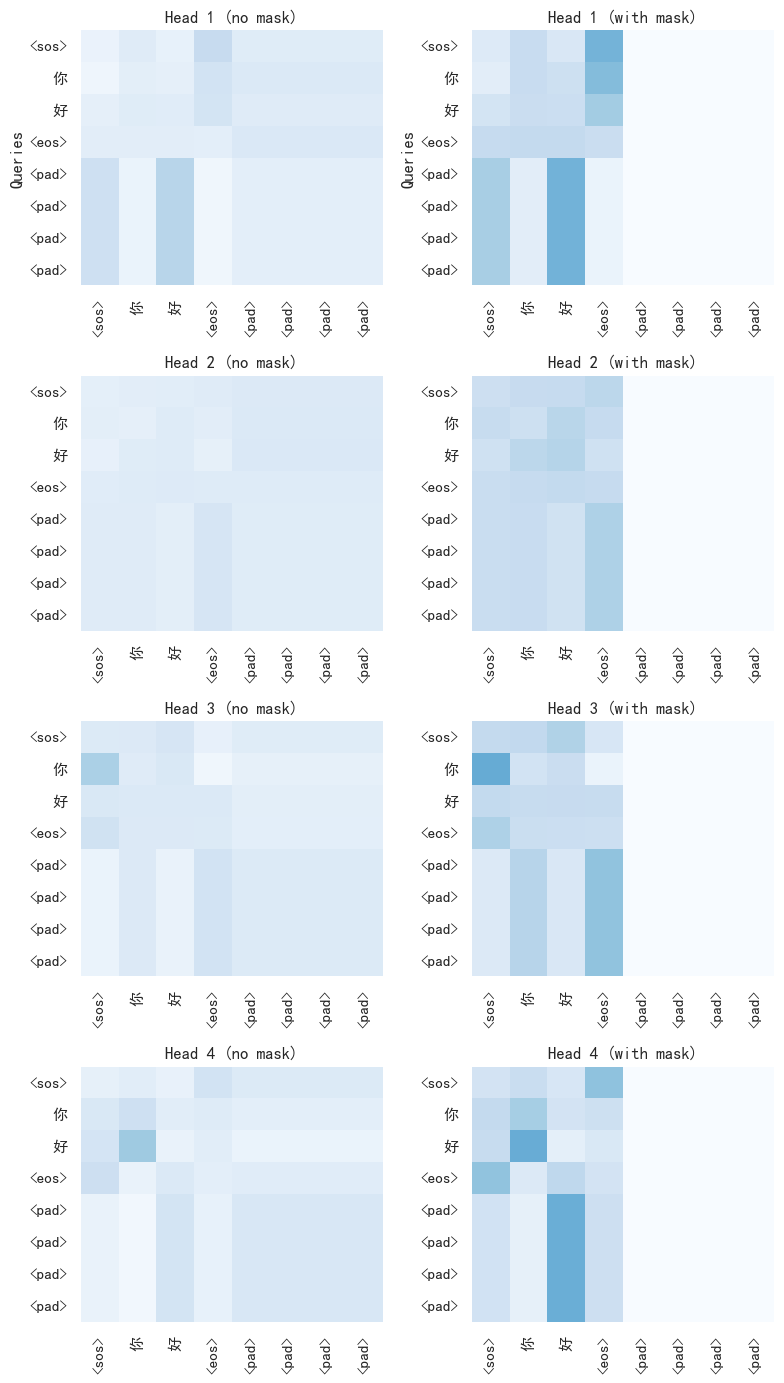
左侧(无 mask):短句"你好"(含 padding token <pad>)的 8 个 token 全部参与了注意力计算,可以看到 <pad> 位置所在列有颜色(权重非零)。
右侧(有 mask):加入 mask 后,<pad> 位置在 softmax 之前被设置为 -inf,经过 softmax 后权重变为 0,有效 token 的注意力被重新分配。<pad> 位置列变为纯白(权重 = 0)。
Mask 的实现机制(取自 MultiHeadAttention.forward)是:
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(2) # (batch, 1, 1, seq_k)
scores = scores.masked_fill(~mask, float("-inf"))
attn_weights = F.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, V)
scores 的原始形状为 (batch, h, seq_q, seq_k)。mask.unsqueeze(1).unsqueeze(2) 将 (batch, seq_k) 扩展为 (batch, 1, 1, seq_k),使其可广播到所有头和所有 query 位置。因为 e^{-∞} = 0,所以 padding 位置对加权求和没有贡献。这个机制虽然简单,却是保证模型训练正确性的关键之一。
五、前馈网络:升维再降维
FFN 的结构非常简单:Linear(32, 128) → ReLU → Linear(128, 32)。
class FeedForward(nn.Module):
"""位置前馈网络:升维 → ReLU → 降维。"""
def __init__(self, d_model, d_ff):
super().__init__()
self.W_1 = nn.Linear(d_model, d_ff, bias=True)
self.W_2 = nn.Linear(d_ff, d_model, bias=True)
def forward(self, x):
return self.W_2(F.relu(self.W_1(x)))
Input shape: torch.Size([1, 5, 32]) # batch=1, 5个token, d=32
Output shape: torch.Size([1, 5, 32]) # 维度不变
W_1: torch.Size([128, 32]) # 升维:32 → 128
W_2: torch.Size([32, 128]) # 降维:128 → 32
手动验证:
Max diff: 0.00e+00 # 精确匹配
Hidden dim (after W1): (1, 128) # 32 → 128
ReLU zero fraction: 0.461 # 约46%的神经元被激活
Final output dim: (1, 32) # 128 → 32
ReLU 零率 46% 是一个很有意思的数字。输入是随机向量,W_1 是随机初始化的正态分布权重,矩阵乘法后的输出大约一半正值一半负值,经过 ReLU 后约 50% 被置零——这完全符合理论预期。当数据量更大、模型训练充分后,这个比例可能会发生变化。
六、完整编码器前向
6.1 维度追踪
编码器由 embedding → PE → 3×EncoderLayer 组成。以"我爱深度学习"为输入:
Input shape: torch.Size([1, 8]) # 8个token
Output shape: torch.Size([1, 8, 32]) # 维度不变
Number of encoder layers: 3
Layer 1 attention shape: torch.Size([1, 4, 8, 8]) # (batch, head, seq_q, seq_k)
Layer 2 attention shape: torch.Size([1, 4, 8, 8])
Layer 3 attention shape: torch.Size([1, 4, 8, 8])
注意:每层的输入和输出维度完全一致,这是 Transformer 的关键性质——维度不变性使得 N 层可以任意堆叠。
编码器层和完整编码器的实现如下:
class EncoderLayer(nn.Module):
"""单个编码器层:自注意力 → 残差+LN → FFN → 残差+LN。"""
def __init__(self, d_model, h, d_ff):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, h)
self.ln1 = LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.ln2 = LayerNorm(d_model)
def forward(self, x, mask=None, return_attention=False):
if return_attention:
attn_out, attn_w = self.self_attn(x, x, x, mask=mask, return_attention=True)
else:
attn_out = self.self_attn(x, x, x, mask=mask)
x = self.ln1(x + attn_out) # 残差连接 + LayerNorm
x = self.ln2(x + self.ffn(x)) # 残差连接 + LayerNorm
if return_attention:
return x, attn_w
return x
class Encoder(nn.Module):
"""完整编码器:嵌入 → 位置编码 → N 层编码器层。"""
def __init__(self, vocab_size, d_model, h, d_ff, N, max_len=5000):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoding(d_model, max_len)
self.layers = nn.ModuleList([
EncoderLayer(d_model, h, d_ff) for _ in range(N)
])
self.d_model = d_model
def forward(self, x, mask=None, return_attention=False):
x = self.embedding(x) * math.sqrt(self.d_model)
x = self.pe(x)
attentions = []
for layer in self.layers:
if return_attention:
x, attn_w = layer(x, mask=mask, return_attention=True)
attentions.append(attn_w)
else:
x = layer(x, mask=mask)
if return_attention:
return x, attentions
return x
在 Encoder.forward 中,self.embedding(x) * math.sqrt(self.d_model) 是 Transformer 原论文中的缩放技巧——将 embedding 的方差从 1 调整到 d_model,使得 embedding 和位置编码的尺度匹配。EncoderLayer 采用 Post-LN 架构(原始 Transformer 论文的方案):先残差连接,再做 LayerNorm。
6.2 浅层 vs 深层注意力
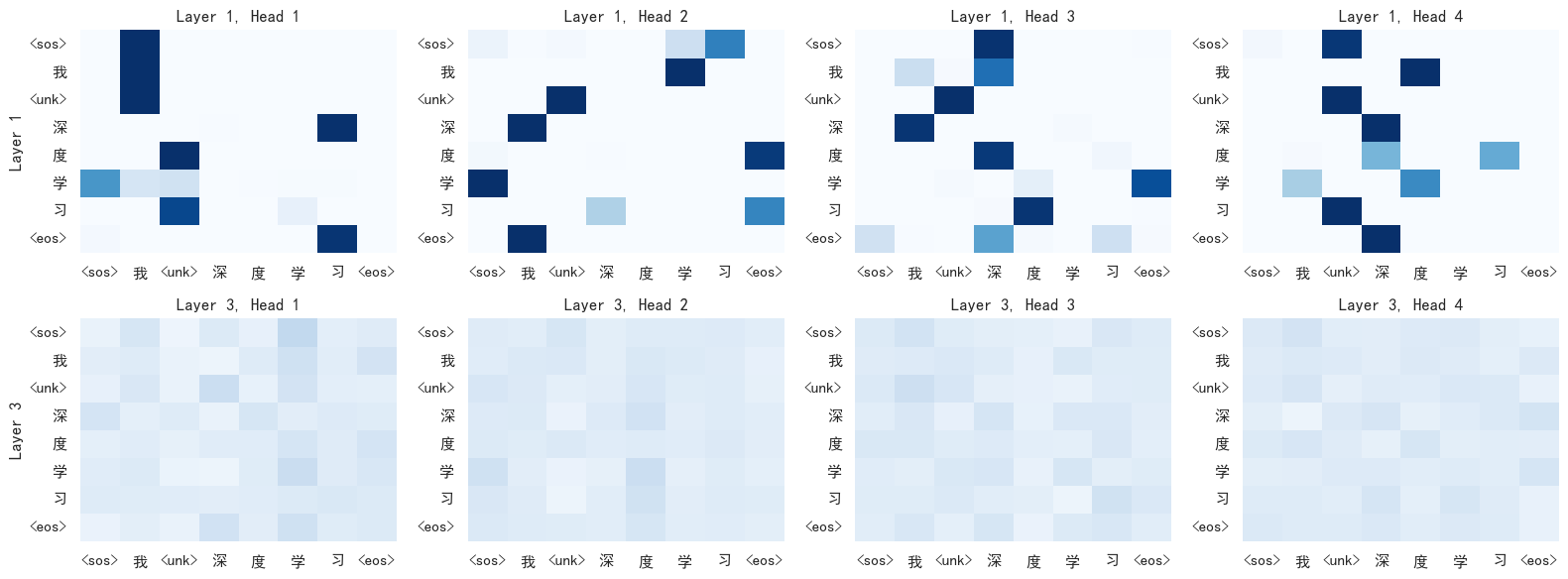
上图将第 1 层和第 3 层的 4 个头并排对比。在随机初始化的状态下,我们可以观察到:
- 第 1 层各头的注意力分布相对多样化:有的头对角线更亮(关注自身),有的头某些特定位置有亮点(关注特定 token)
- 第 3 层经过了两次注意力+FFN 的变换后,注意力模式有所变化,但整体格局与第 1 层相似
为什么会这样?因为随机初始化时,注意力模式主要由权重矩阵的随机种子决定,而不是由语义驱动。各层之间的差异主要来自于输入分布的变化——第 2 层的输入是第 1 层的输出,已经是经过注意力混合和 FFN 变换后的向量了。
经过充分训练后(见第 38 篇),浅层注意力通常更关注局部语法模式,深层注意力更关注全局语义关系。
6.3 数值稳定性:残差连接 + LayerNorm
编码器每层的详细数值变化:
After embedding + scaling: mean norm = 32.5036 # √32 = 5.66, × embedding 后 ≈ 32.5
After positional encoding: mean norm = 32.2165 # PE 加入后略有变化
--- Layer 1 ---
Self-attn output norm: 13.2984 # 注意力输出有较大范数
After residual (+): 36.7588 # 残差相加后增大
After LayerNorm: 5.6569 # LN 归一化到 ≈ √32
FFN output norm: 1.3480
After residual (+): 5.8642
After LayerNorm: 5.6568 # 再次归一到 ≈ √32
--- Layer 2 & 3 --- (类似模式)
After LayerNorm: 5.6568 # 每层结束都稳定在 √32
这里有一个非常优雅的性质:无论子层的输出范数是 13.3 还是 1.35,经过残差相加 + LayerNorm 后,每层输出的范数稳定在 √d_model ≈ 5.657。
LayerNorm 的计算公式是:
LN(x)=γ⋅x−μσ+ϵ+β\text{LN}(x) = \gamma \cdot \frac{x - \mu}{\sigma + \epsilon} + \betaLN(x)=γ⋅σ+ϵx−μ+β
对应的代码实现如下:
class LayerNorm(nn.Module):
"""Layer Normalization (可学习 affine)。"""
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True, unbiased=False)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
gamma 和 beta 是可学习的仿射参数(默认 γ=1, β=0),初始状态下什么都不做(恒等变换)。unbiased=False 表示使用有偏标准差(除以 N 而非 N-1),这与 PyTorch 的 nn.LayerNorm 保持一致。
对于一个 d=32 的向量,如果 γ=1、β=0(默认初始化),LN 后的向量均值为 0、标准差为 1,因此范数的期望值为 √32 ≈ 5.657。这就是为什么每层结束时都看到 5.6568-5.6569——LayerNorm 保证了数值的稳定性,使得信息可以稳定流过 3 层乃至更多层。
七、总结
通过本篇的代码实战,我们完成了 Transformer 编码器的完整实现,并通过手动验证确认了每一步的正确性。以下是核心发现:
- 位置编码的频谱结构:低维高频、高维低频,形成一个天然的"频率标尺"
- 多头自注意力的手算验证:Q/K/V 投影 → 分头 → 得分 → softmax → 加权求和,每一步的数值误差在 10^{-8} 量级
- 多头分化初现:即使随机初始化,不同头已表现出不同的注意力偏好(关注自身 vs 关注其他)
- Padding Mask 的有效性:-inf 技巧使无效位置权重精确归零
- FFN 的升维降维:46% 的 ReLU 零率符合随机初始化理论预期
- LayerNorm 的稳定作用:每层输出范数稳定在 √d_model,确保深层网络数值稳定
在下一篇文章(第 37 篇)中,我们将实现解码器,加入因果掩码和交叉注意力,完成完整的 Transformer 前向传播。在第 38 篇中,我们将训练完整模型,观察参数如何从随机走向有序、embedding 如何自动聚类、注意力如何从均匀变为聚焦。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)