最新PPOCRv5模型训练教程。文字检测+文字识别(自用)
当前paddle
提前准备好的命令:
激活虚拟环境:conda activate ocr
检查ppocrlabel标注工具:pip show ppocrlabel
打开标注工具:python PPOCRLabel.py --lang ch
PPOCRLabel --lang ch
前情提要
我的paddleocr重新下载过,因为cpu跑的太慢了,换成主机gpu跑了。所以有的图片里是paddleocr-main。有的图片里是paddleocr。会意即可,其他的路径基本没有问题
图片数据集拆分(准备好文件夹,放在paddleocr下):
这里我准备了五百多张图片去训练。
在paddleocr-main文件夹下:放好导出的识别后的图片文件夹:
PPOCRLabel根目录下:cmd,激活虚拟环境。以下命令使用一个即可,放这么多是为了记录之前的探索过程。
python gen_ocr_train_val_test.py --trainValTestRatio 8:2 --datasetRootPath D:\mypaddle\PaddleOCR-main\picture
python gen_ocr_train_val_test.py --trainValTestRatio 8:2 --datasetRootPath D:\newpaddle\PaddleOCR-main\train_picture
python gen_ocr_train_val_test.py --trainValTestRatio 7:2:1 --datasetRootPath C:\zhjstudy\mypaddle\PaddleOCR\train_data
C:\zhjstudy\mypaddle\PaddleOCR\PPOCRLabel-main
- 训练集(Train)
用于:更新模型参数,学习字符特征,越大越好。 - 验证集(Val)
用于:监控过拟合,保存 best_accuracy,调参
太小会导致:acc忽高忽低,模型保存不稳定。 - 测试集(Test)
用于:最终评估真实性能,模拟真实场景,不能参与训练。
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。
detRootPath 是输出训练文字检测的数据集存放路径。默认路径是 …/train_data/det
recRootPath 是输出训练文字识别的数据集存放路径。默认路径是 …/train_data/rec
拆分后发现多出两个文件夹。这两个文件夹就是训练模型需要使用的。
文件配置
首先去下载det(检测)rec(识别)预训练模型
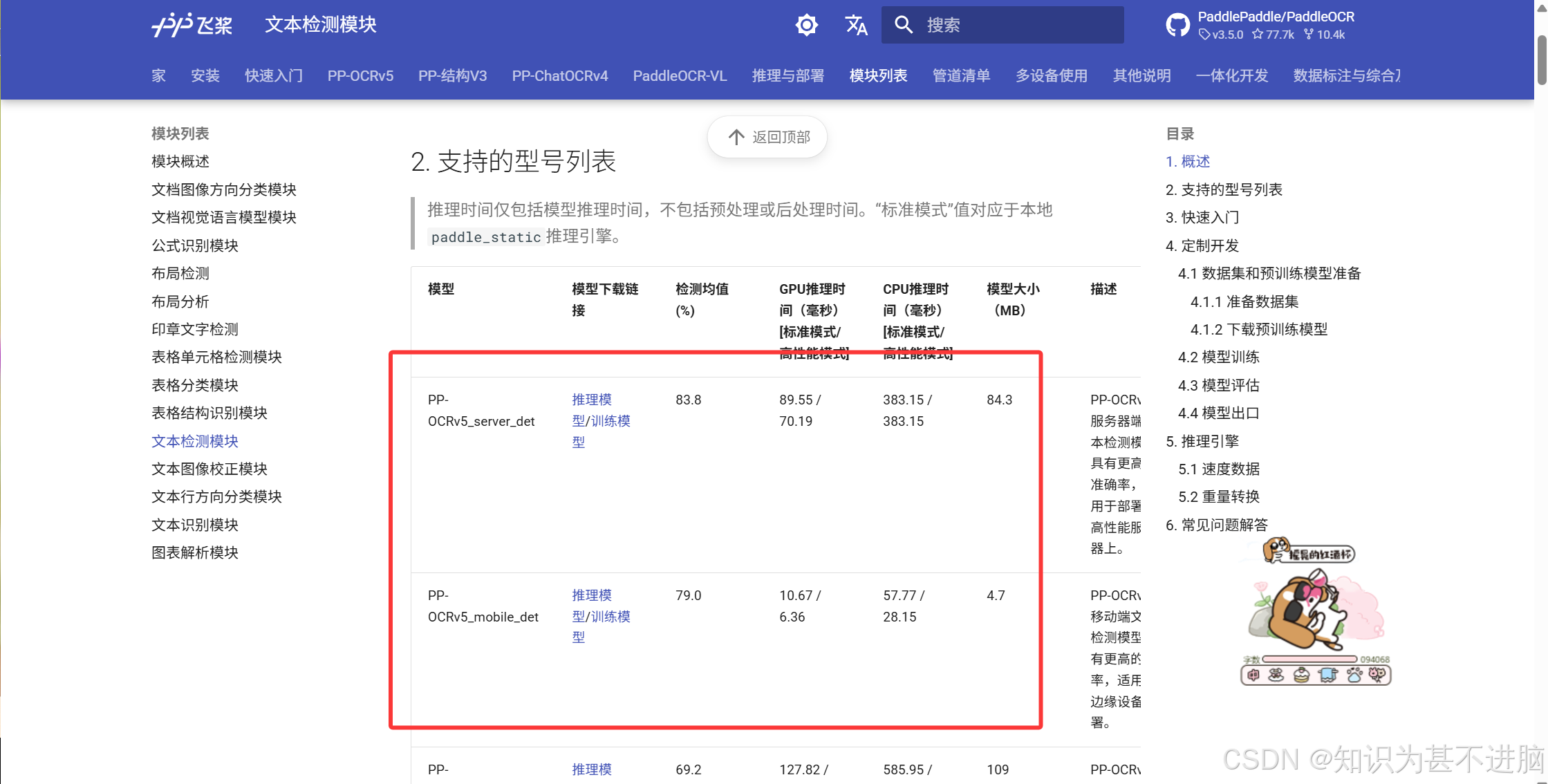
https://www.paddleocr.ai/main/en/version3.x/module_usage/text_detection.html#1-overview
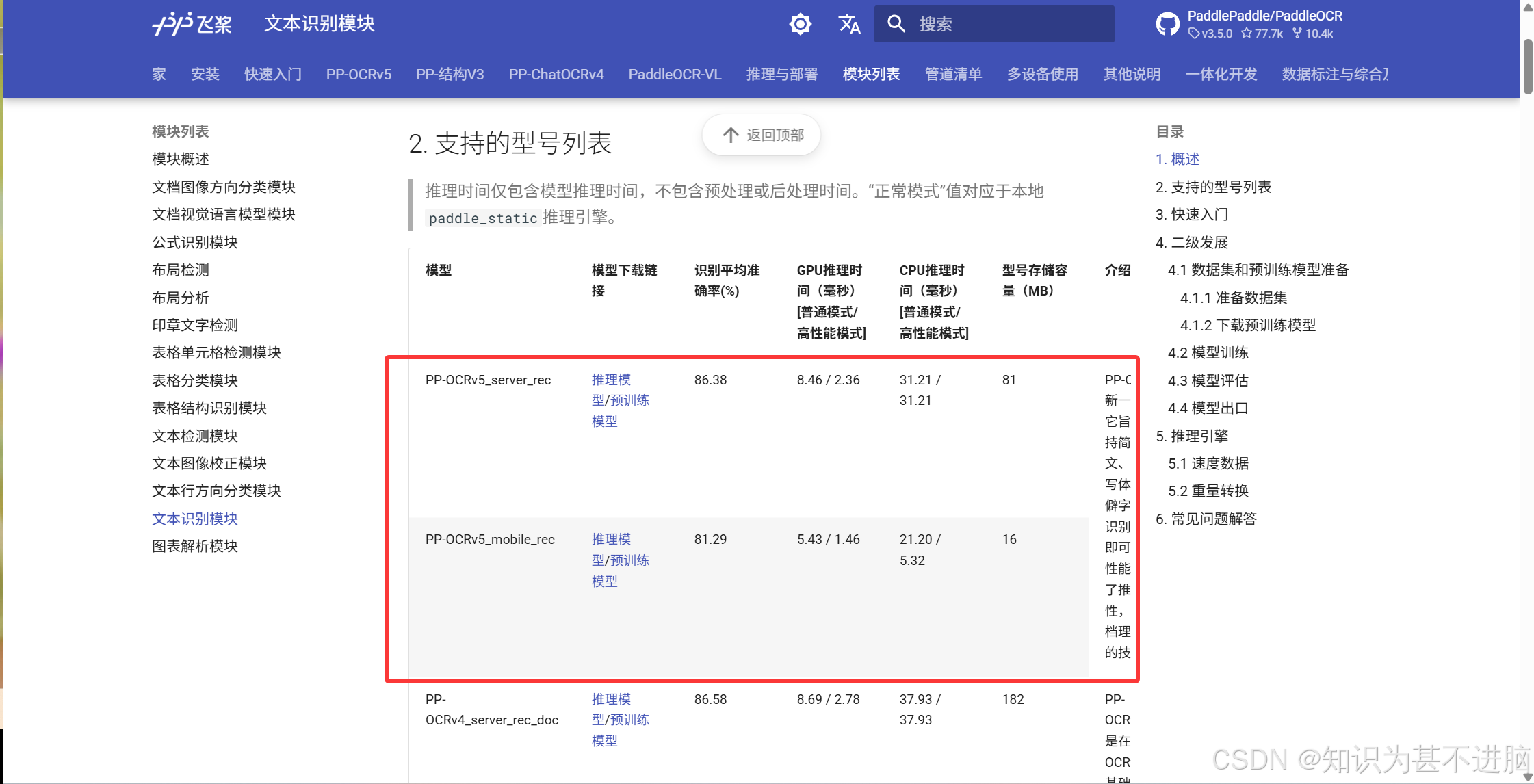
https://www.paddleocr.ai/main/en/version3.x/module_usage/text_recognition.html#1-overview
mobile和server的区别:
可以理解成mobile是轻量的,server是完整的。cpu推荐用mobile,gpu推荐server。
修改yml配置文件,路径在:
(det)“D:\newpaddle\PaddleOCR-main\configs\det\PP-OCRv5\PP-OCRv5_server_det.yml”
(rec)“D:\newpaddle\PaddleOCR-main\configs\rec\PP-OCRv5\PP-OCRv5_server_rec.yml”
由于这个是自带的,不建议在原路径直接改,建议复制到另外一个地方自行修改。
我这里把配置文件和预训练模型全都放在了同一个文件夹下,在paddleocr里面,命名为pretrain_modles.
我这里使用的server训练,所以展示的server,mobile同理。需要修改的是我后面有标注的内容。其他地方自己酌情修改。
det: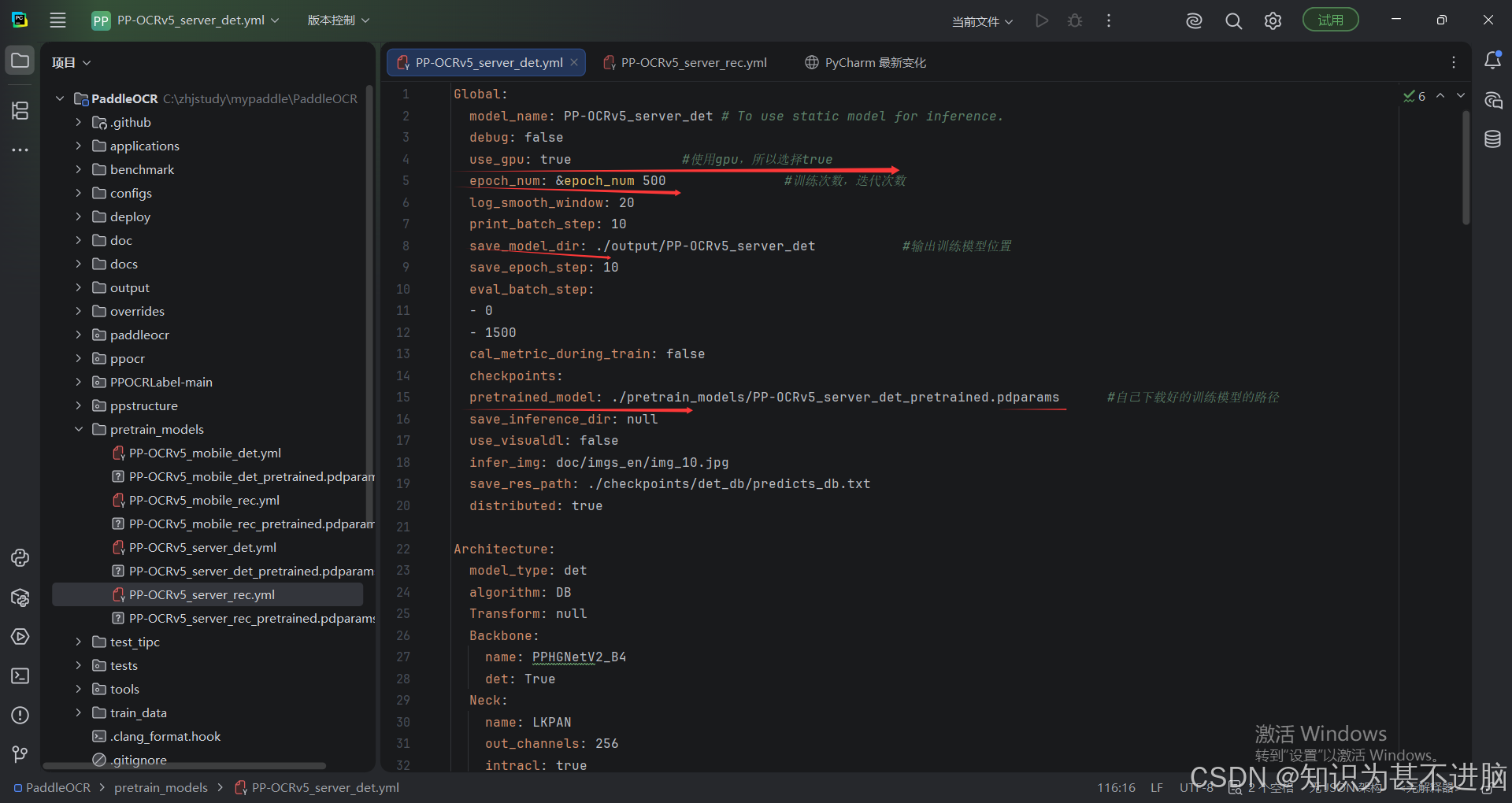
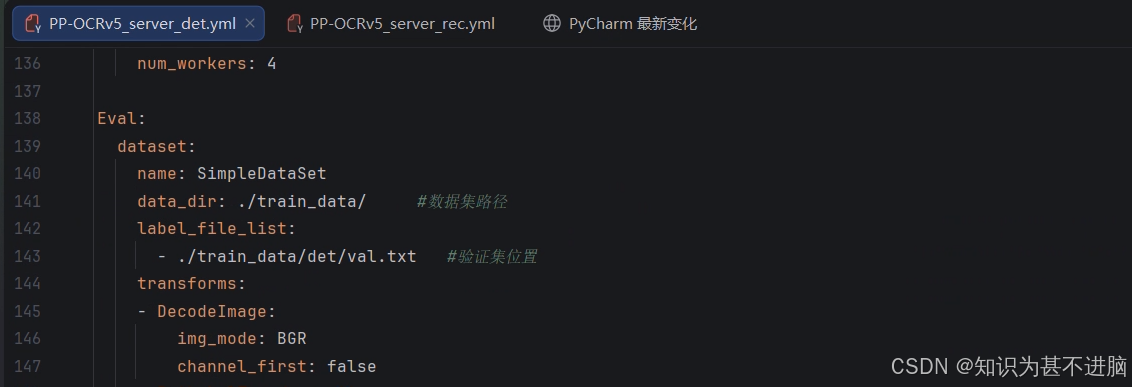
rec: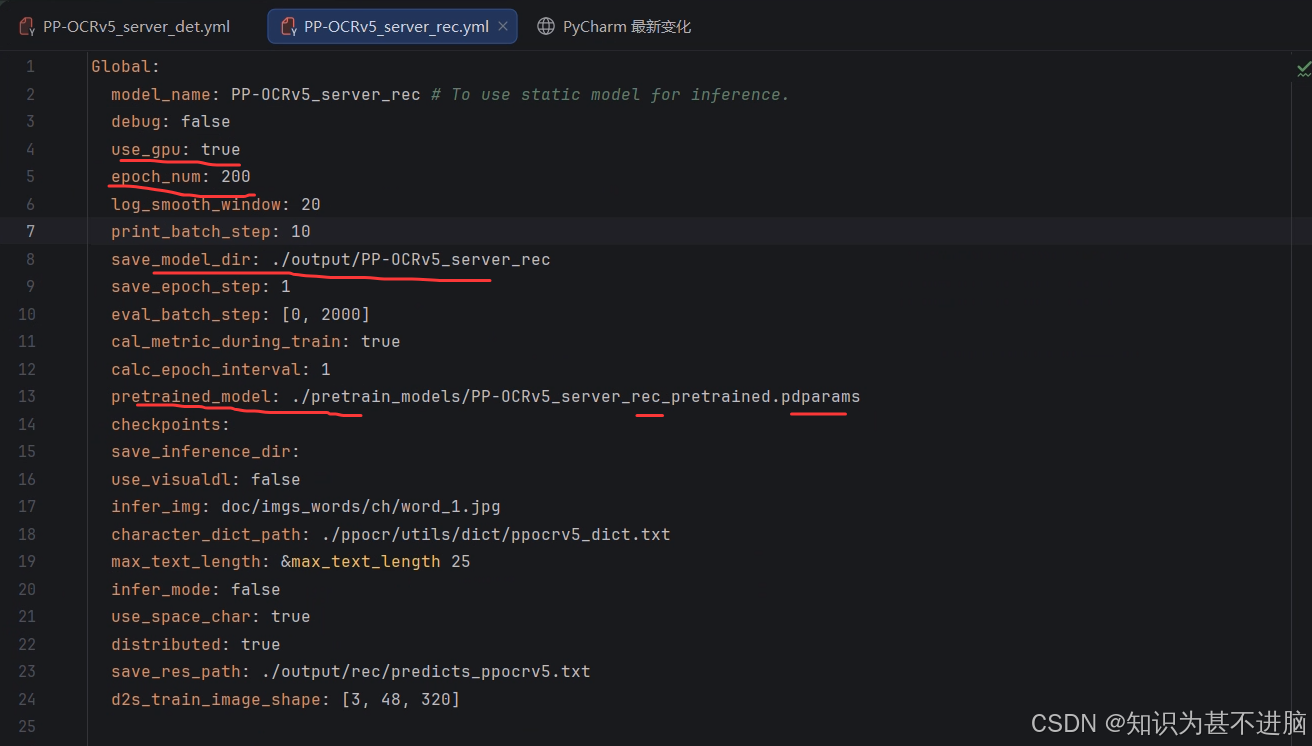
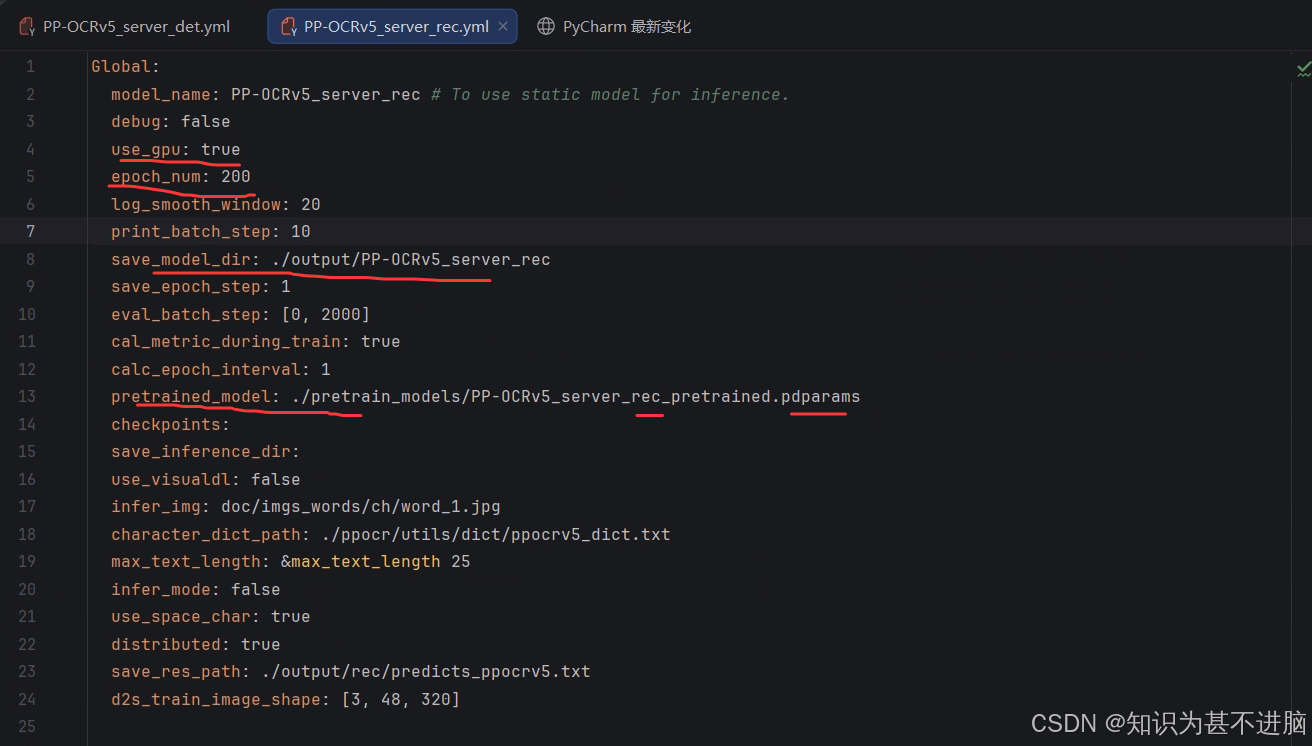
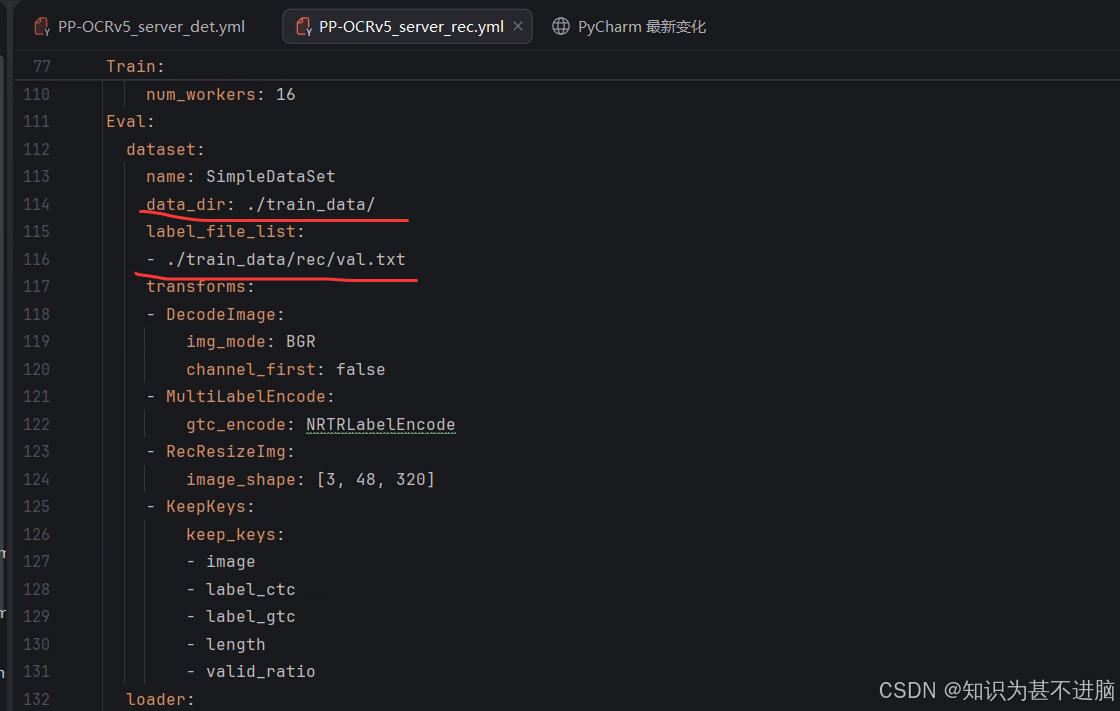
paddleocr 训练(server)
用第一张gpu卡:
set CUDA_VISIBLE_DEVICES=0
开始训练:
python tools/train.py -c pretrain_models/PP-OCRv5_server_det.yml
python tools/train.py -c pretrain_models/PP-OCRv5_server_rec.yml
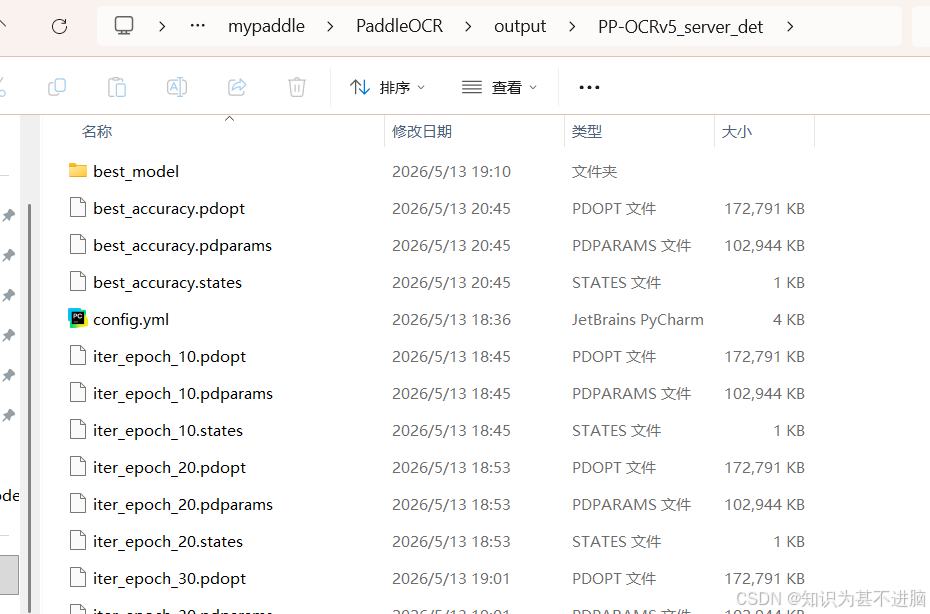
训练过程中产生的模型称为检查点(checkpoints)模型,包含完整参数,用于恢复训练及二次训练。一 个检查点模型包含三个文件:
.pdopt:训练优化器参数
.pdparams:训练网络参数
.states:训练状态
python tools/train.py -c pretrain_models/PP-OCRv5_server_det.yml -o Global.checkpoints=C:\zhjstudy\mypaddle\PaddleOCR\pretrain_models\PP-OCRv5_server_det_pretrained.pdparams
出现这样的效果就是开始训练了: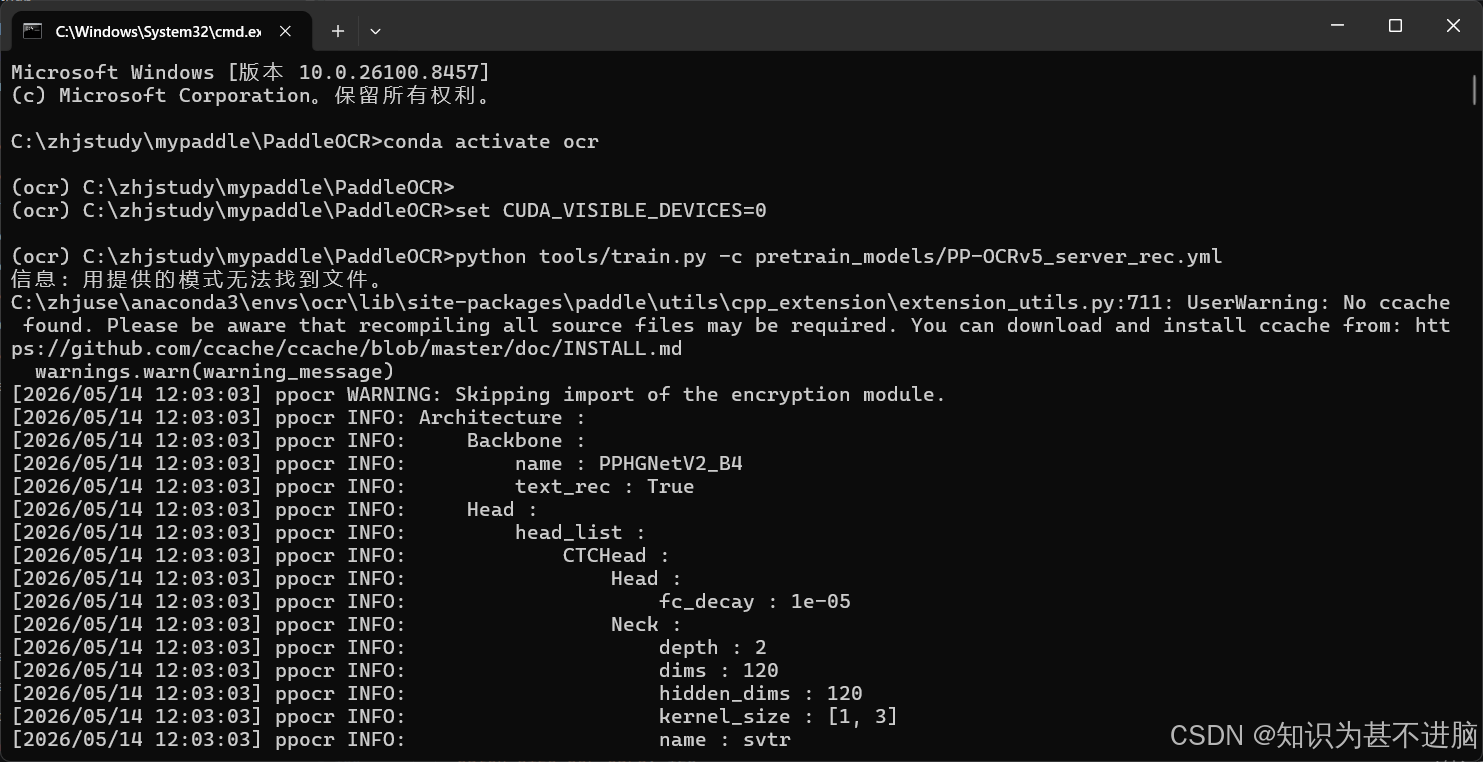
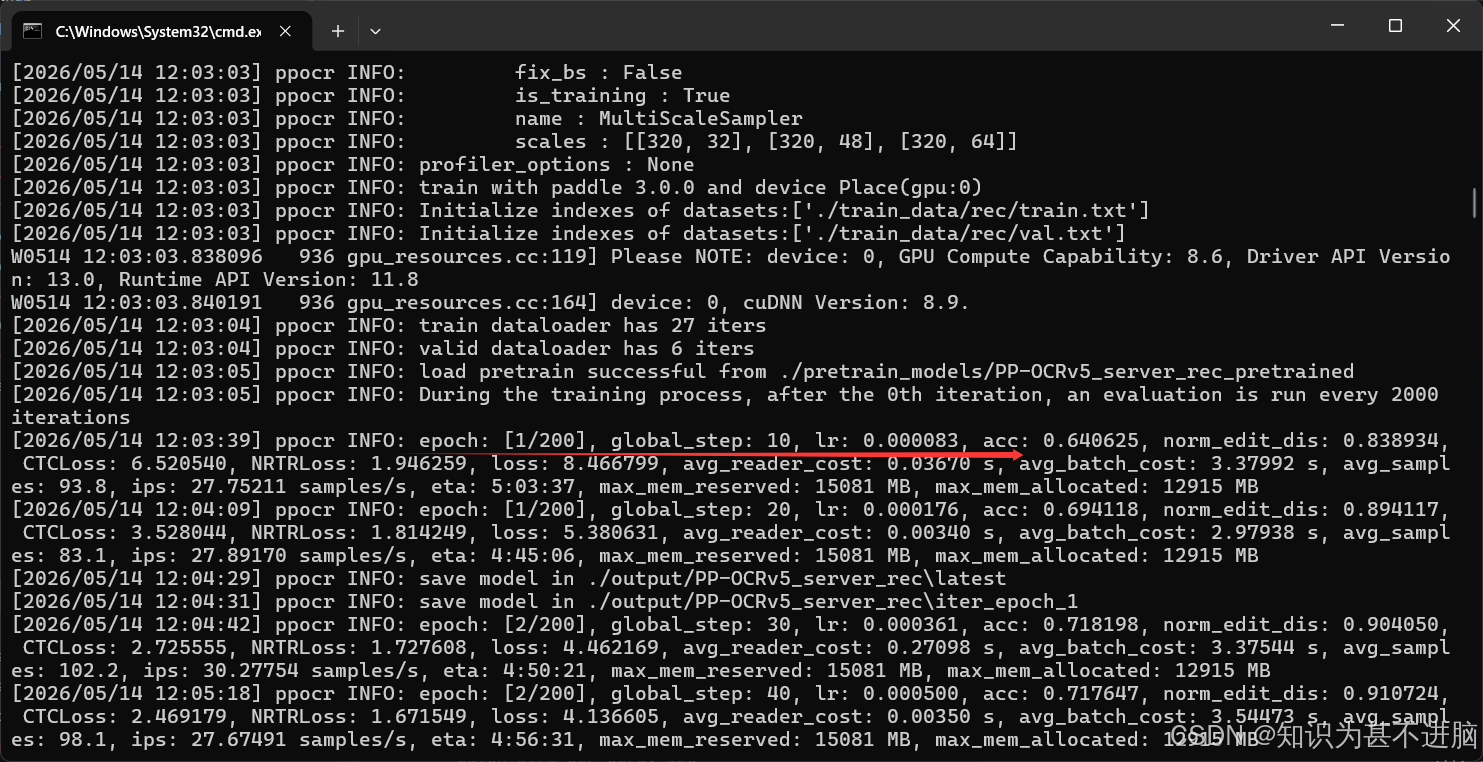
如果报错了也不要怕,可能是配置或者版本有问题。按照ai的说法酌情处理就好了。
练的感觉差不多了按ctrl+c即可退出。
保存的地址:在配置文件yml中自己写入的地址。
转换推理模型
导出模型的位置:
C:\zhjstudy\mypaddle\PaddleOCR\output\PP-OCRv5_server_det
C:\zhjstudy\mypaddle\PaddleOCR\output\PP-OCRv5_server_rec
转换推理模型命令:
# 最后一次训练过的模型
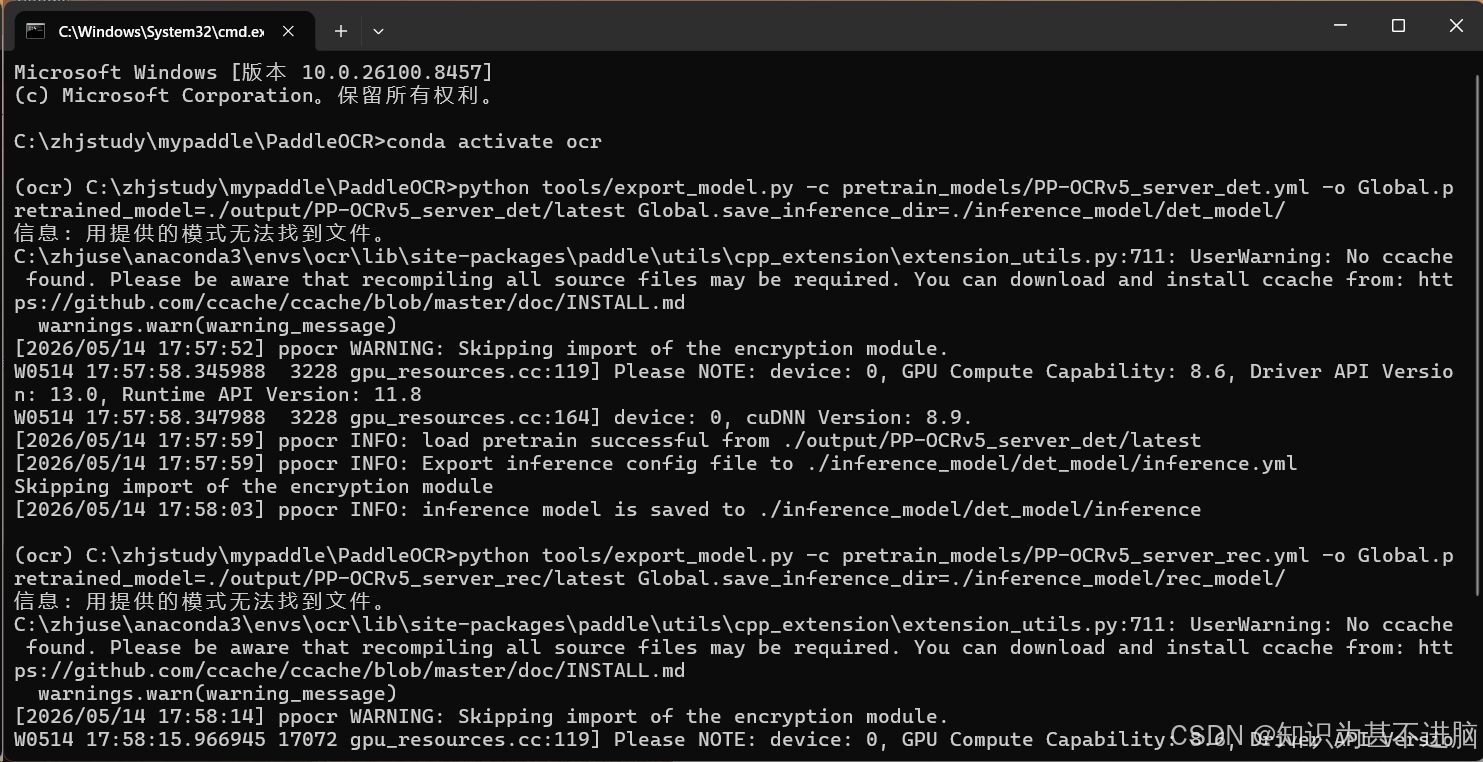
python tools/export_model.py -c pretrain_models/PP-OCRv5_server_det.yml -o Global.pretrained_model=./output/PP-OCRv5_server_det/latest Global.save_inference_dir=./inference_model/det_model/
python tools/export_model.py -c pretrain_models/PP-OCRv5_server_rec.yml -o Global.pretrained_model=./output/PP-OCRv5_server_rec/latest Global.save_inference_dir=./inference_model/rec_model/
# 训练结果最好的一次模型
python tools/export_model.py -c pretrain_models/PP-OCRv5_server_det.yml -o Global.pretrained_model=./output/PP-OCRv5_server_det/best_accuracy Global.save_inference_dir=./inference_model/det_model/
python tools/export_model.py -c pretrain_models/PP-OCRv5_server_rec.yml -o Global.pretrained_model=./output/PP-OCRv5_server_rec/best_accuracy Global.save_inference_dir=./inference_model/rec_model/
-c 指定导出模型使用的配置文件,需与训练时使用的配置文件相同
-o 指定配置文件中的某个参数,即在不修改配置文件的情况下修改参数
Global.pretrained_model 此处是指要导出模型的参数文件路径
Global.save_inference_dir 指导出模型的保存路径
验证模型,测试训练结果
打开python,我这里使用的pycharm
from paddleocr import PaddleOCR
paddleocr = PaddleOCR(
lang='ch',
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
enable_mkldnn=True,
text_detection_model_dir=r'C:/zhjstudy/mypaddle/PaddleOCR/inference_model/det_model',
text_recognition_model_dir=r'C:/zhjstudy/mypaddle/PaddleOCR/inference_model/rec_model',
device='gpu'
)
img_path = r'C:\Users\User\Desktop\train_d\9b10ff21-d6ea-4b8a-81d7-757002f57443.png'
result = paddleocr.predict(img_path)
print("输出所有结果")
print(result)
print("提取重要结果")
res = result[0]
texts = res['rec_texts']
scores = res['rec_scores']
for text, score in zip(texts, scores):
print(f"{text} 置信度: {score:.3f}")
输出结果如下: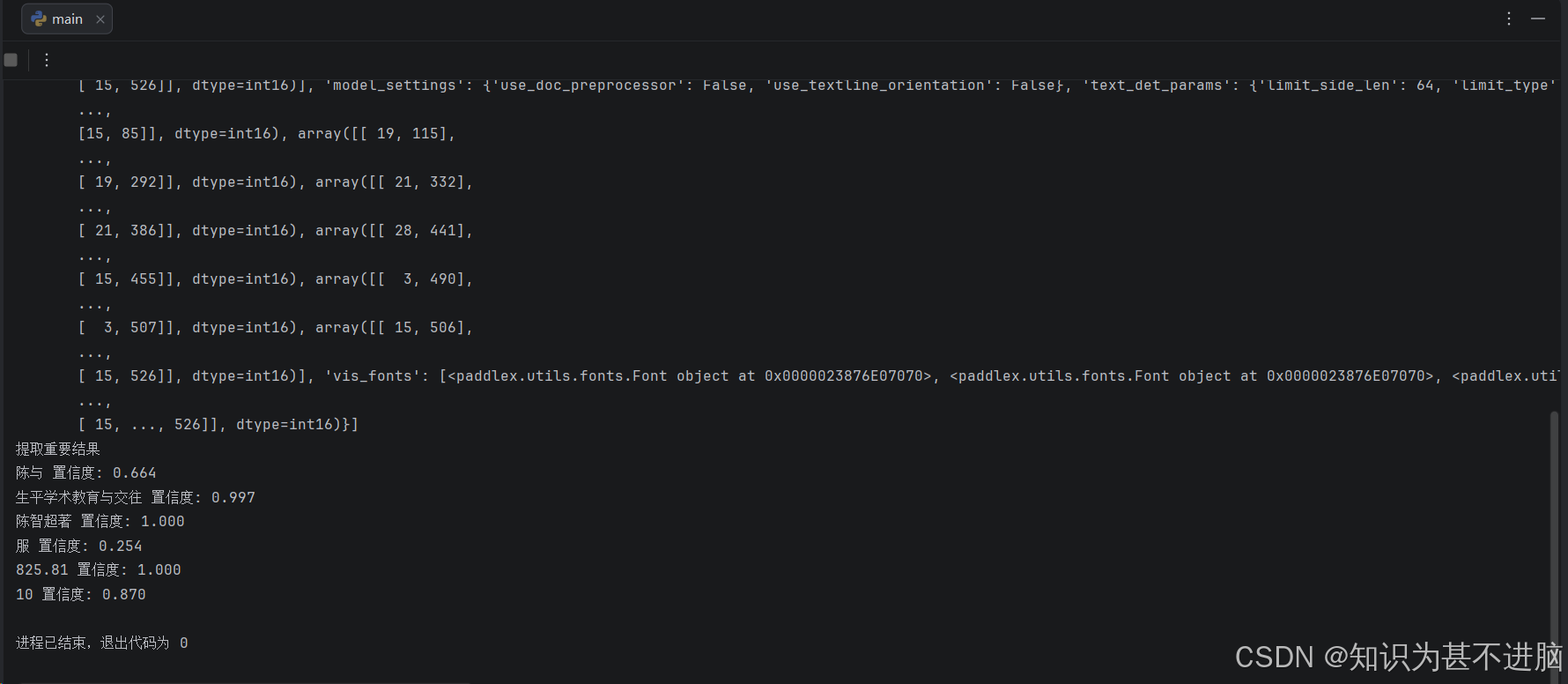
模型训练确实有效果,置信度增加。
感谢观看
接下来如果想进一步提升准确率需要增加训练图片量或者增加训练轮次。
有新改动随时会修改教程。
感谢收看,如果对您有用的话请点个赞或者收藏 😄

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)