2026 大模型 API 选型:价格、性能与性价比全面对比
一、前言:为什么需要对比大模型 API?
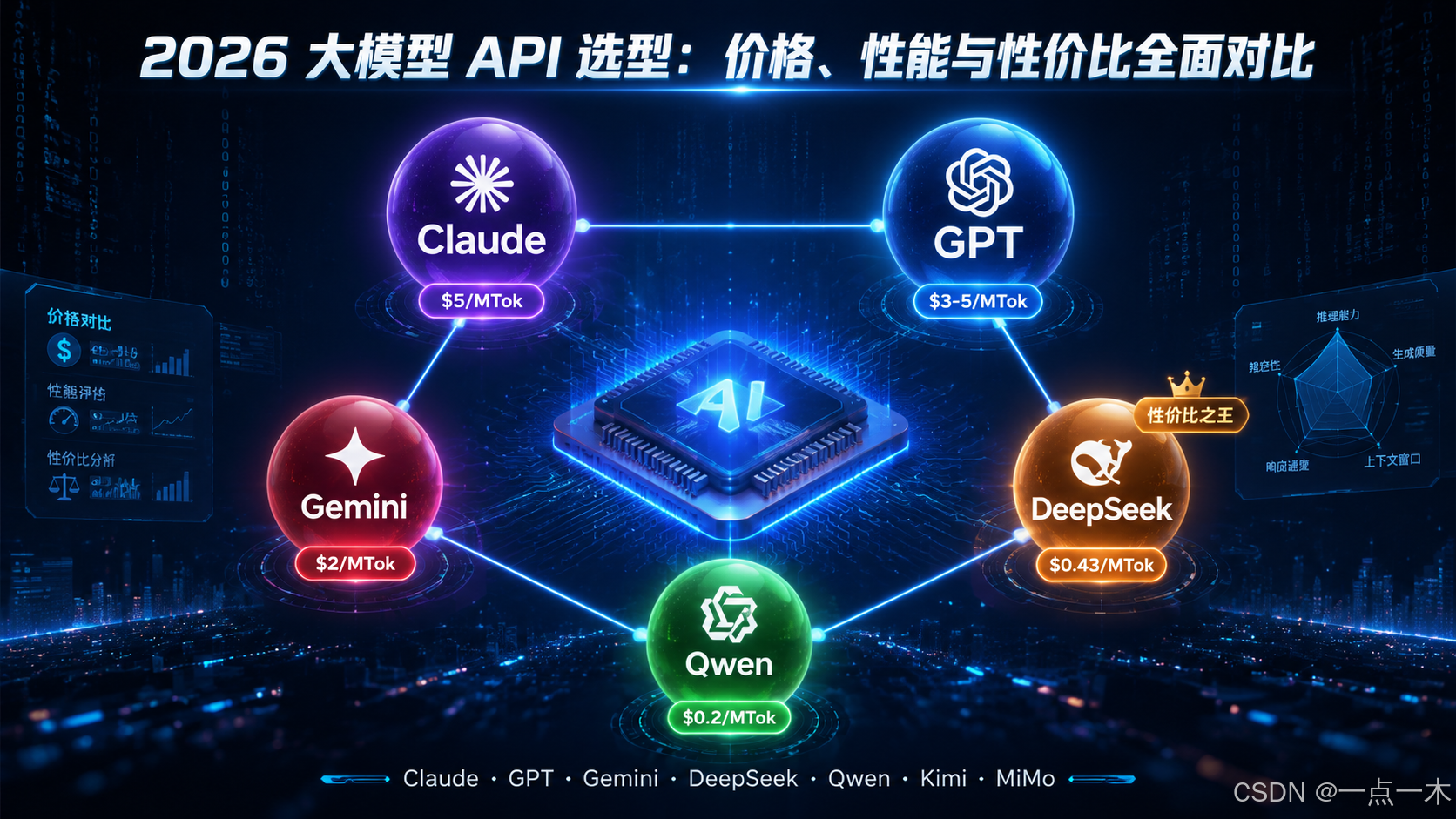
当前,大模型 API 市场已经高度分化:
- 海外模型(Claude、GPT、Gemini)在顶级推理和 Agent 能力上仍有优势
- 国内模型(DeepSeek、Qwen、Kimi、MiMo)在性价比、中文能力和访问稳定性上全面领先
- 价格持续下降,缓存命中(Prompt Cache)成为降低成本的关键
- 没有绝对王者,组合使用(高质量模型 + 性价比模型)仍是主流
本文将对 当前 最主流和有趋势的大模型 API 进行全面对比,重点考虑:
- 编码能力(SWE-bench Verified、Terminal-Bench)
- Token 价格(输入/输出、缓存命中)
- 国内访问难度
- 上下文窗口
- 推理/多模态能力
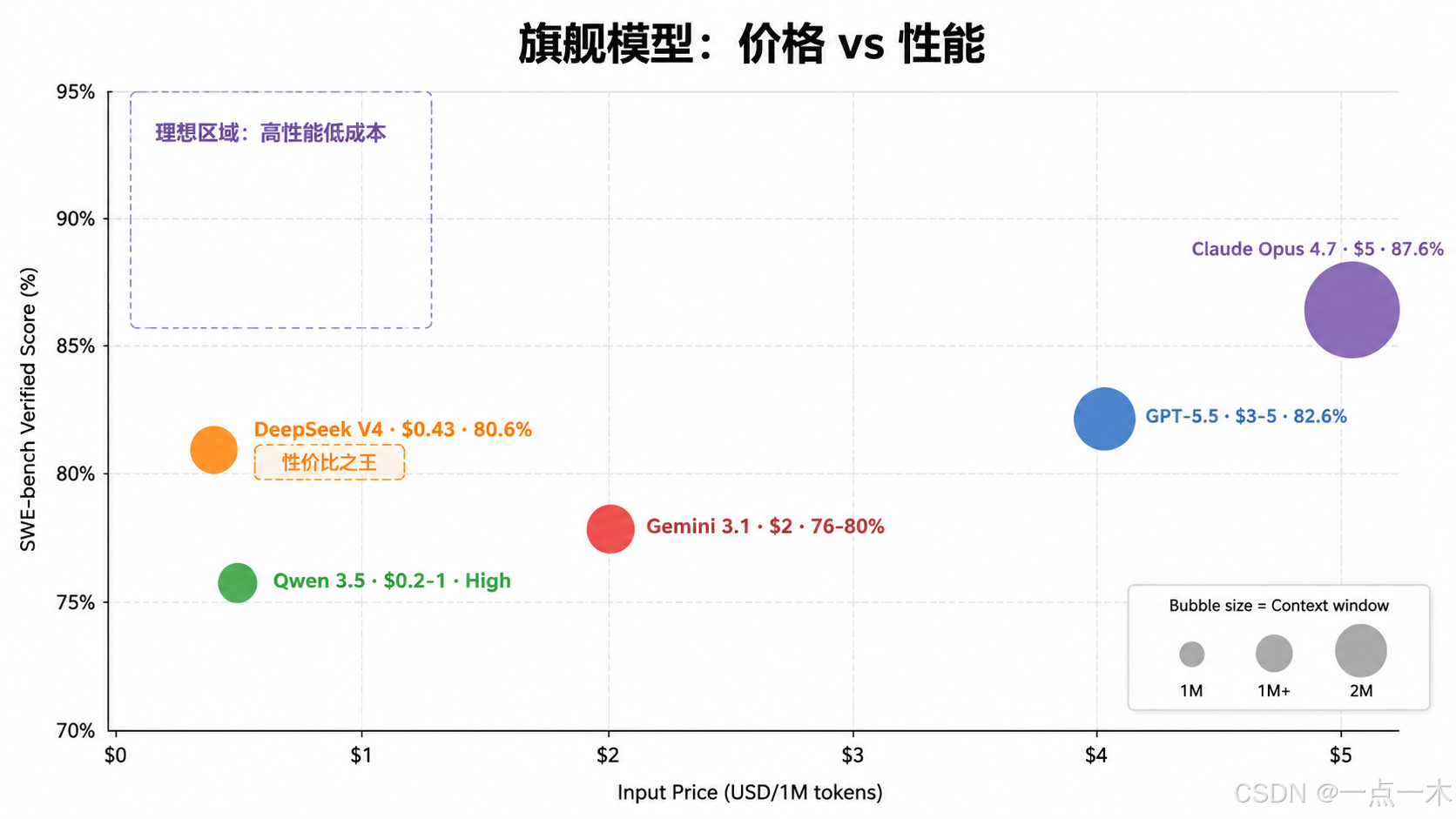
二、顶级梯队对比(旗舰模型)
2.1 旗舰模型核心参数
| 模型系列 | 开发者 | 输入价格 (USD/1M tokens) | 输出价格 (USD/1M tokens) | 上下文窗口 | SWE-bench Verified | 核心优势 | 国内访问难度 |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.7 | Anthropic | $5 | $25 | 1M | ~87.6%-93.9% | 复杂推理、代码质量、自然写作、Agent 规划 | 高(需国际访问) |
| GPT-5.5 / o-series | OpenAI | $3-$5 | $15-$30 | 1M+ | ~82.6%-88.7% | Agent 能力、工具调用、速度均衡 | 高(需国际访问) |
| Gemini 3.1 Pro | $2-$2.5 | $10-$15 | 2M | ~76-80.6% | 多模态(图/视频)、长上下文、科学推理 | 中等 | |
| DeepSeek V4-Pro | DeepSeek | $0.435 (75%折扣后) | $0.87 (75%折扣后) | 1M | ~80.6% | 极致性价比、编码强、MoE 高效 | 最低 |
| Qwen 3.5/3.6 Max | 阿里 | ~$0.2-$1.0 | ~$0.7-$4.0 | 1M+ | 高 | 中文最强、指令遵循、开源生态 | 最低 |
注:DeepSeek V4-Pro 当前享有 75% 折扣,有效期至 5 月 31 日 15:59 UTC。
2.2 详细价格对比(已验证数据)
Anthropic Claude 系列(来源:anthropic.com/pricing)
| 模型 | 输入价格 | 输出价格 | 缓存写入 | 缓存读取 |
|---|---|---|---|---|
| Opus 4.7 | $5/MTok | $25/MTok | $6.25/MTok | $0.50/MTok |
| Sonnet 4.6 | $3/MTok | $15/MTok | $3.75/MTok | $0.30/MTok |
| Haiku 4.5 | $1/MTok | $5/MTok | $1.25/MTok | $0.10/MTok |
DeepSeek 系列(来源:api-docs.deepseek.com)
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 | 备注 |
|---|---|---|---|---|
| V4-Flash | $0.0028/MTok | $0.14/MTok | $0.28/MTok | 基础价格 |
| V4-Pro | $0.003625/MTok | $0.435/MTok | $0.87/MTok | 75% 折扣后(截至 5/31) |
| V4-Pro(原价) | $0.0145/MTok | $1.74/MTok | $3.48/MTok | 折扣结束后价格 |
OpenAI 系列(参考价格)
| 模型 | 输入价格 | 输出价格 | 备注 |
|---|---|---|---|
| GPT-5.5 | $3-$5/MTok | $15-$30/MTok | 旗舰模型 |
| o-series | $3-$5/MTok | $15-$30/MTok | 推理优化 |
Google Gemini 系列(参考价格)
| 模型 | 输入价格 | 输出价格 | 上下文 |
|---|---|---|---|
| Gemini 3.1 Pro | $2-$2.5/MTok | $10-$15/MTok | 2M |
| Gemini 3 Flash | $0.5-$1/MTok | $3-$5/MTok | 1M |
三、编码能力基准对比
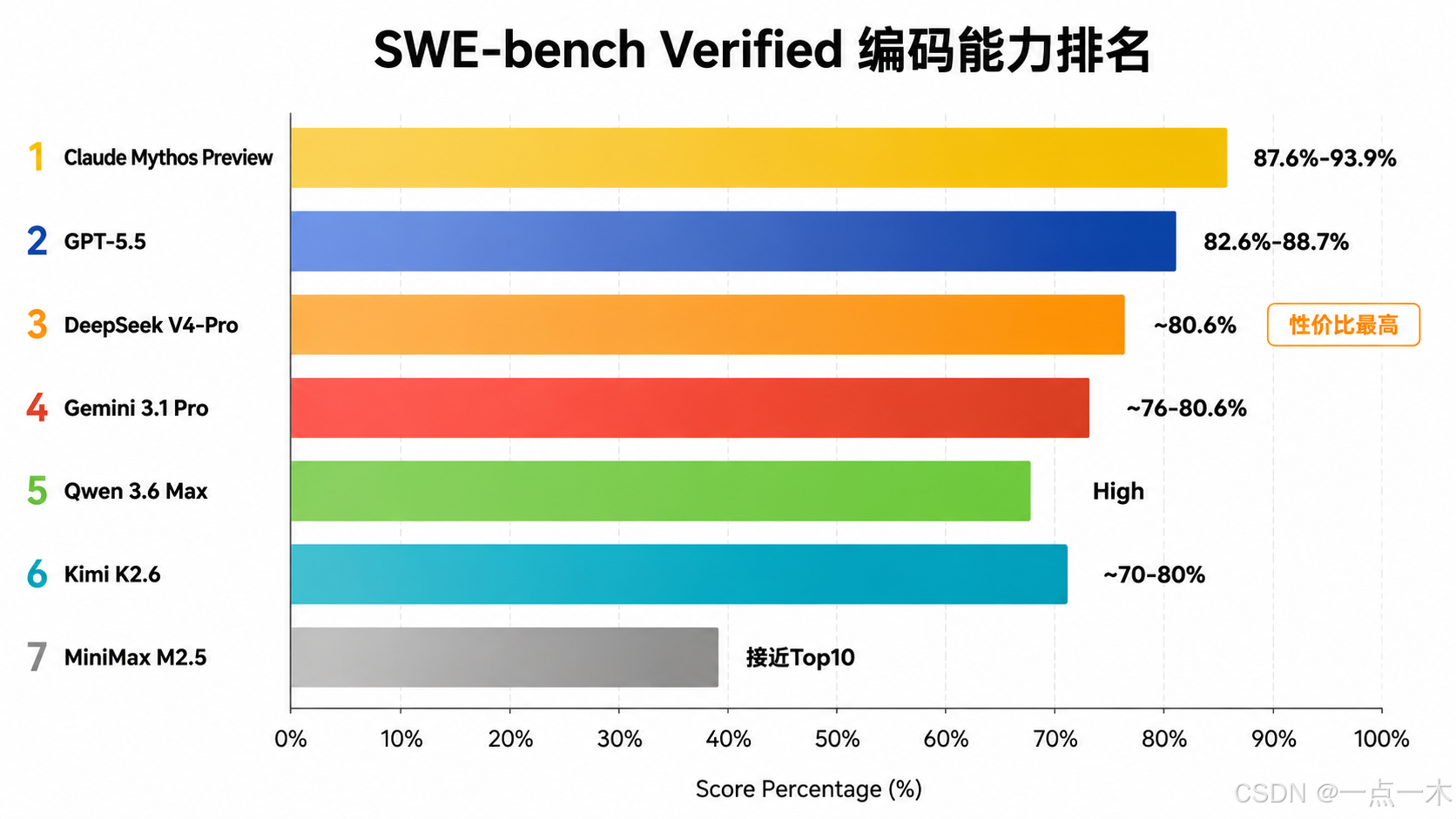
3.1 SWE-bench Verified 最新排名
SWE-bench Verified 是目前评估真实编码/Agent 能力的最重要基准(500 个经过人工验证的真实 GitHub Issue)。
| 排名 | 模型 | SWE-bench Verified 分数 | 说明 |
|---|---|---|---|
| 1 | Claude Mythos Preview / Opus 4.7 | 87.6%-93.9% | 复杂多文件推理、架构设计最强 |
| 2 | GPT-5.5 / 5.3 Codex | 82.6%-88.7% | Agent 工具调用和 Terminal 任务强 |
| 3 | DeepSeek V4-Pro | ~80.6% | 性价比最高,常接近或在特定子任务超越 |
| 4 | Gemini 3.1 Pro | ~76-80.6% | 长上下文优势明显 |
| 5 | Qwen 3.5/3.6 Max | 高分 | 尤其中文任务和某些 Agent 基准领先 |
| 6 | Kimi K2.5/K2.6 | ~70-80%+ | 中文和视觉编码强 |
| 7 | MiniMax M2.5 / GLM-5 | 接近 Top 10 | 常在开源/性价比榜单领先 |
重要提示:SWE-bench Verified 存在"刷榜"争议(数据污染),实际新项目表现(SWE-bench Pro)通常低 20-40 个百分点。
3.2 Terminal-Bench(终端 Agent 任务)
| 排名 | 模型/工具 | 表现 |
|---|---|---|
| 1 | Codex CLI + GPT-5.5 | 常居首位(77.3%+) |
| 2 | Claude Code + Claude Opus 4.7 | 紧随其后 |
| 3 | DeepSeek-TUI + V4 | 表现优秀 |
3.3 编码能力详细分析
- Claude Opus 4.7:长期领先 SWE-bench,代码优雅、规划周密,复杂重构和架构设计最强
- GPT-5.5:在 Terminal-Bench(终端 Agent)常排第一,工具调用和多步执行强
- DeepSeek V4:已非常接近甚至在某些子任务超越海外旗舰,性价比碾压
- Gemini 3.1:在长代码库理解上优势明显,多模态最强
- Qwen 3.5/3.6:中文任务和指令遵循领先
四、其他关键维度对比
4.1 中文能力
| 等级 | 模型 | 说明 |
|---|---|---|
| 母语级领先 | Qwen、Kimi、DeepSeek、GLM | 中文理解、生成、文化适配最佳 |
| 优秀 | Claude、Gemini | 也很好,但文化适配稍逊 |
| 良好 | GPT 系列 | 均衡但中文特色不突出 |
4.2 速度
| 等级 | 模型 | 说明 |
|---|---|---|
| 最快 | Gemini Flash / DeepSeek Flash / Groq 托管系列 | 适合高频调用、实时响应 |
| 快 | GPT-5.5 / Claude Sonnet | 均衡速度 |
| 中等 | Claude Opus / DeepSeek Pro | 旗舰模型,推理深度优先 |
4.3 多模态能力
| 等级 | 模型 | 说明 |
|---|---|---|
| 最强 | Gemini 3.1 | 图片/视频/设计图转代码,多模态输入领先 |
| 优秀 | Kimi / GPT | 视觉编码、图片理解强 |
| 良好 | Claude / DeepSeek | 基础多模态支持 |
4.4 Agent / 工具调用
| 等级 | 模型 | 说明 |
|---|---|---|
| 领先 | GPT-5 / Claude | 工具调用、多步执行、Agent 框架支持最强 |
| 快速追近 | DeepSeek / Qwen | 国内模型在 Agent 能力上进步迅速 |
| 良好 | Gemini | 基础 Agent 能力 |
4.5 开源与本地部署
| 等级 | 模型 | 说明 |
|---|---|---|
| 生态最好 | DeepSeek、Qwen、Llama 系列 | 开源权重、社区支持、本地部署方案成熟 |
| 部分开源 | GLM、MiniMax | 部分开源 |
| 闭源 | Claude、GPT、Gemini | 仅通过 API 访问 |
五、国内使用深度分析
5.1 国内访问难度
| 等级 | 模型 | 说明 |
|---|---|---|
| 最低(直连顺畅) | DeepSeek、Qwen、Kimi、MiMo、GLM | 国内公司,API 在国内访问顺畅、无限制 |
| 中等 | Gemini | Google 访问方式不同,但可通过国际访问 |
| 高(需国际访问) | Claude、OpenAI | 官方对国内访问方式不同,需通过国际网络访问 |
5.2 国际访问方案
国内开发者常用的国际访问方案:
国际访问的成本:海外模型可打 7-9 折;国内模型直连最便宜(有时相差 10-30 倍)。
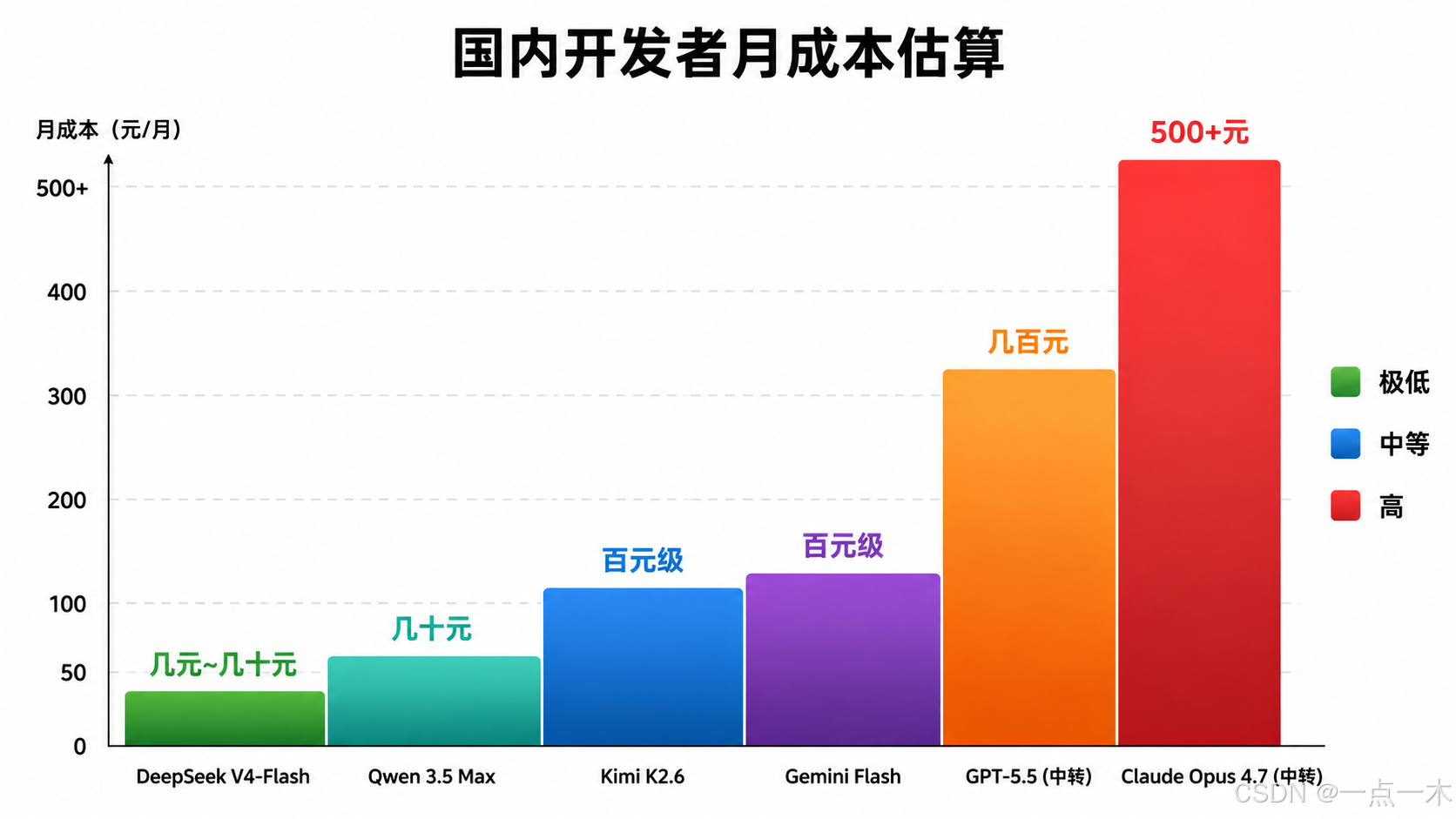
5.3 国内实际成本排序
| 排名 | 模型 | 月成本估算(中等使用量) | 说明 |
|---|---|---|---|
| 1 | DeepSeek V4-Flash | 极低(几元到几十元) | 缓存命中价格极低($0.0028/MTok) |
| 2 | Qwen 3.5 Max | 很低 | 国内直连,价格便宜 |
| 3 | Kimi K2.6 | 低 | 性价比高 |
| 4 | Gemini Flash | 低-中等 | 免费额度 + 低价 |
| 5 | GPT-5.5(国际访问) | 中等-较高 | 国际访问仍有溢价 |
| 6 | Claude Opus 4.7(国际访问) | 较高 | 质量最高但价格也最高 |
六、各模型详细分析
6.1 Claude Opus 4.7 / Mythos Preview
定位:质量天花板,复杂推理和编码最强
核心数据:
- 输入:$5/MTok,输出:$25/MTok
- 缓存写入:$6.25/MTok,缓存读取:$0.50/MTok
- 上下文:1M tokens
- SWE-bench Verified:87.6%-93.9%
优势:
- 复杂多文件推理、架构设计最强
- 代码最优雅、bug 最少
- 自然写作能力最佳
- Agent 规划最周密
劣势:
- 价格最贵
- Token 消耗较多(输出冗长)
- 国内访问困难,需国际访问
适合场景:复杂重构、架构设计、高质量代码生成、不差钱的场景
6.2 GPT-5.5 / o-series
定位:Agent 均衡王,工具调用最强
核心数据:
- 输入:$3-$5/MTok,输出:$15-$30/MTok
- 上下文:1M+ tokens
- SWE-bench Verified:82.6%-88.7%
优势:
- Agent 工具调用和多步执行最强
- Terminal-Bench 常居首位
- 速度均衡
- 生态最完善
劣势:
- 价格较高
- 国内访问需国际访问
适合场景:多步 Agent 任务、通用编码、工具调用密集场景
6.3 Gemini 3.1 Pro
定位:长上下文 + 多模态之王
核心数据:
- 输入:$2-$2.5/MTok,输出:$10-$15/MTok
- 上下文:2M tokens(最大)
- SWE-bench Verified:76-80.6%
优势:
- 上下文窗口最大(2M tokens)
- 多模态能力最强(图片/视频/设计图转代码)
- 价格相对合理
- 免费额度慷慨
劣势:
- 代码质量和复杂推理略逊 Claude/GPT
- 国内访问稳定性较低
适合场景:大文档、多模态、大项目探索、预算有限
6.4 DeepSeek V4-Pro/Flash
定位:极致性价比王
核心数据(V4-Pro,75% 折扣后):
- 输入(缓存命中):$0.003625/MTok
- 输入(缓存未命中):$0.435/MTok
- 输出:$0.87/MTok
- 上下文:1M tokens
- SWE-bench Verified:~80.6%
V4-Flash 价格:
- 输入(缓存命中):$0.0028/MTok
- 输入(缓存未命中):$0.14/MTok
- 输出:$0.28/MTok
优势:
- 价格极低(缓存命中时仅 $0.003625/MTok)
- 编码能力强,接近旗舰水平
- MoE 架构高效
- 国内直连顺畅,无限制
- 1M 上下文
劣势:
- 75% 折扣有截止时间(5/31)
- 极复杂推理可能略逊 Claude
适合场景:高性价比编码、生产环境、高频调用、国内开发者首选
6.5 Qwen 3.5/3.6 Max
定位:中文最强,国内生态最好
核心数据:
- 输入:$0.2-$1.0/MTok,输出:$0.7-$4.0/MTok
- 上下文:1M+ tokens
- 中文任务和某些 Agent 基准领先
优势:
- 中文理解、生成、文化适配最佳
- 指令遵循能力强
- 开源生态好
- 国内直连,无限制
劣势:
- 英文编码能力略逊 DeepSeek
- 国际知名度较低
适合场景:中文任务、国内生产环境、指令遵循
6.6 Kimi K2.6
定位:视觉编码 + 性价比
核心数据:
- 输入:$0.6-$1.0/MTok,输出:$2-$4/MTok
- 上下文:256K+ tokens
- 视觉编码强
优势:
- 视觉编码能力强
- 中文优秀
- 性价比高
- 国内直连
劣势:
- 上下文窗口相对较小
- 整体能力略逊旗舰
适合场景:视觉相关编码、中文任务、性价比优先
6.7 其他值得关注的模型
| 模型 | 开发者 | 核心优势 | 价格区间 | 国内访问 |
|---|---|---|---|---|
| Grok 4 | xAI | 编码领先,风格幽默,实时信息 | 中等 | 中高 |
| MiMo-V2.5 | 小米 | Agent 优化好,长上下文 | 低 | 最低 |
| GLM-5 | 智谱 | 中文强,开源生态 | 低 | 最低 |
| MiniMax M2.5 | MiniMax | 接近 Top 10,开源/性价比榜单领先 | 低 | 最低 |
七、Token 消耗与成本优化
7.1 不同模型的 Token 消耗特点
| 模型 | Token 消耗特点 | 优化建议 |
|---|---|---|
| Claude Opus | 输出冗长,思考步骤多,消耗最高 | 使用 Sonnet 替代、开启缓存 |
| GPT-5.5 | 中等,Agent 循环时消耗快 | 控制 Agent 循环次数 |
| DeepSeek V4 | 高效,MoE 架构省 Token | 充分利用缓存命中 |
| Gemini Flash | 最快最省 | 简单任务用 Flash |
| Qwen | 中等 | 中文任务效率高 |
7.2 缓存命中优化
缓存命中(Prompt Cache)是降低成本的关键:
| 模型 | 缓存命中价格 | 缓存未命中价格 | 节省比例 |
|---|---|---|---|
| DeepSeek V4-Pro | $0.003625/MTok | $0.435/MTok | 99.2% |
| DeepSeek V4-Flash | $0.0028/MTok | $0.14/MTok | 98% |
| Claude Opus 4.7 | $0.50/MTok | $5/MTok | 90% |
| Claude Sonnet 4.6 | $0.30/MTok | $3/MTok | 90% |

优化建议:
- 保持系统提示稳定,提高缓存命中率
- 使用支持缓存的工具(如 OpenCode 的 compact 模式)
- 高频任务使用 Flash/Lite 版本
- 复杂任务才用旗舰模型
八、选型建议
8.1 按需求场景选型
| 需求场景 | 最推荐模型 | 理由 |
|---|---|---|
| 追求最高代码质量 | Claude Opus 4.7 | SWE-bench 领先,代码最优雅 |
| 追求Agent 均衡能力 | GPT-5.5 | 工具调用和多步执行最强 |
| 追求长上下文/多模态 | Gemini 3.1 Pro | 2M 上下文 + 多模态最强 |
| 追求极致性价比(国内) | DeepSeek V4 | 价格最低,性能接近旗舰 |
| 追求中文能力 | Qwen 3.5/3.6 Max | 中文最强,指令遵循好 |
| 追求视觉编码 | Kimi K2.6 | 视觉编码强,性价比高 |
| 追求Agent 优化 | MiMo-V2.5 | Agent 能力优化好 |
| 追求高频/实时 | Gemini Flash / DeepSeek Flash | 速度最快,价格最低 |
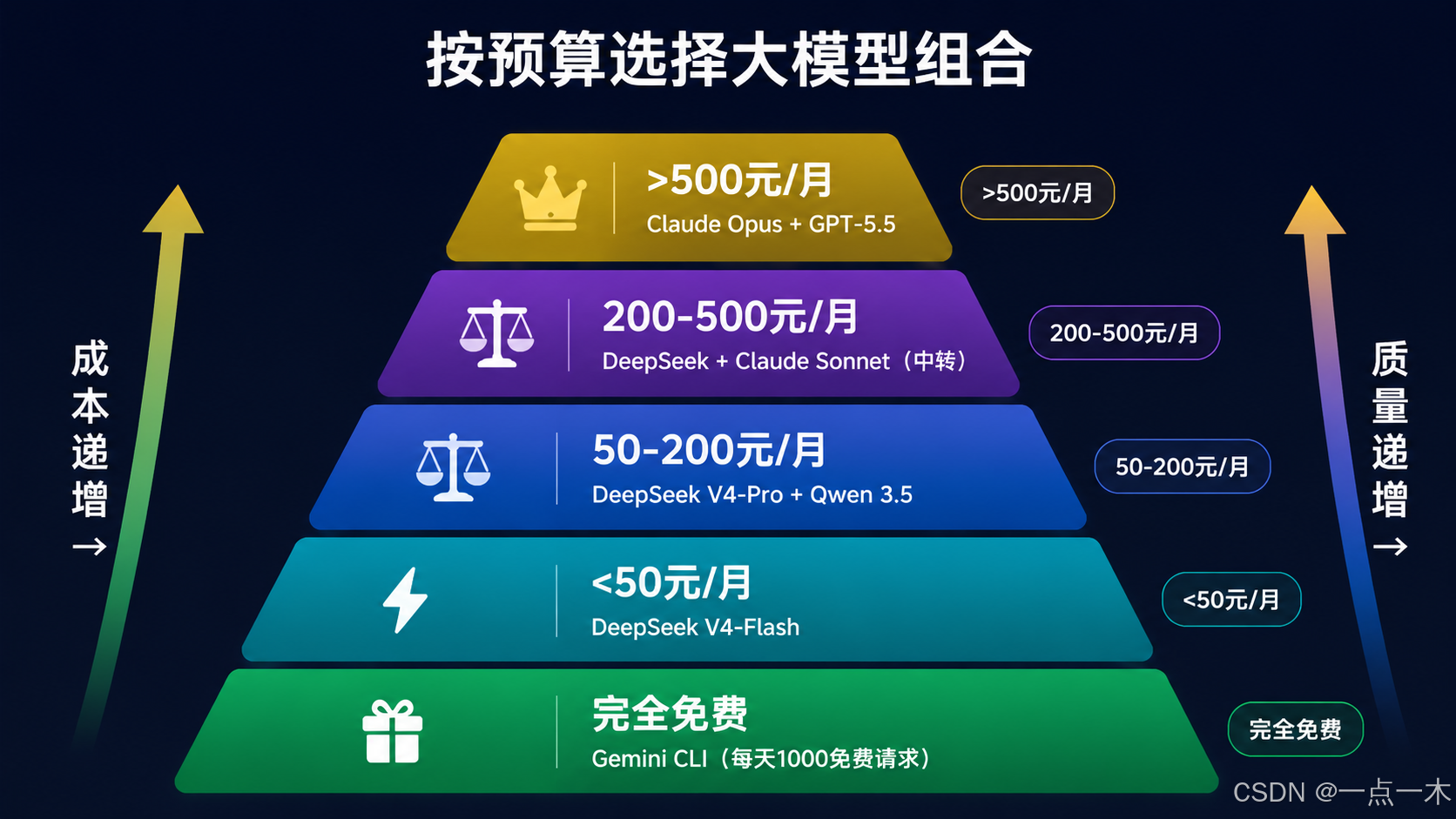
8.2 按预算选型
| 预算 | 推荐组合 |
|---|---|
| 完全免费 | Gemini CLI(每天 1000 免费请求) |
| 极低预算(<50元/月) | DeepSeek V4-Flash |
| 低预算(50-200元/月) | DeepSeek V4-Pro + Qwen 3.5 |
| 中等预算(200-500元/月) | DeepSeek + Claude Sonnet(国际访问) |
| 高预算(>500元/月) | Claude Opus + GPT-5.5(高质量任务) |
8.3 国内开发者推荐组合
主力方案(推荐):
- 日常编码:DeepSeek V4(性价比最高)
- 高质量任务:Claude Sonnet/Opus(国际访问)
- 中文任务:Qwen 3.5 Max
- 大上下文/多模态:Gemini 3.1(国际访问)
省钱方案:
- 主力:DeepSeek V4-Flash
- 补充:Qwen 3.5 / Kimi K2.6
质量优先方案:
- 主力:Claude Opus 4.7(国际访问)
- 补充:GPT-5.5(国际访问)
九、大模型市场格局总结
9.1 质量天花板
- 编码/复杂推理:Claude Opus 4.7 + GPT-5.5
- Agent 均衡:GPT-5.5
9.2 性价比之王(尤其是国内)
- DeepSeek V4:性能接近旗舰,价格 1/10~1/30
- Qwen 3.5/3.6:中文最强,价格便宜
- Kimi K2.6:视觉+中文优秀,性价比高
9.3 长上下文/多模态
- Gemini 3.1:2M 上下文 + 多模态最强
9.4 趋势
- 价格持续下降:各大厂商不断降价,缓存命中成为关键
- 国内模型全面崛起:在性价比、中文、生产部署上全面领先
- 海外模型仍有优势:在顶级基准和生态上保持领先
- 组合使用成为主流:高质量模型 + 性价比模型搭配使用
- Agent 能力成为核心竞争力:工具调用、多步执行、子代理能力越来越重要
十、总结
目前没有单一模型"全面碾压",格局高度分化:
- 海外模型在顶级推理/Agent 上仍有优势
- 国内模型在性价比、中文、访问稳定性上全面领先
最佳策略:根据具体场景选择或组合使用多个模型,而非试图找到"一个最好的模型"。
国内开发者核心建议:
- 主力使用国内模型(DeepSeek、Qwen、Kimi),成本低、访问稳
- 高质量任务通过国际访问使用海外模型(Claude、GPT)
- 充分利用缓存命中降低成本
- 搭配合适的编码 Agent 工具(OpenCode、Aider、DeepSeek-TUI 等)
附录:常用模型快速参考
| 模型 | 输入价格 | 输出价格 | 上下文 | SWE-bench | 国内访问 |
|---|---|---|---|---|---|
| Claude Opus 4.7 | $5/MTok | $25/MTok | 1M | 87.6%+ | 需国际访问 |
| Claude Sonnet 4.6 | $3/MTok | $15/MTok | 1M | 高 | 需国际访问 |
| GPT-5.5 | $3-5/MTok | $15-30/MTok | 1M+ | 82.6%+ | 需国际访问 |
| Gemini 3.1 Pro | $2-2.5/MTok | $10-15/MTok | 2M | 76-80.6% | 中等 |
| DeepSeek V4-Pro | $0.435/MTok | $0.87/MTok | 1M | ~80.6% | 直连 |
| DeepSeek V4-Flash | $0.14/MTok | $0.28/MTok | 1M | - | 直连 |
| Qwen 3.5 Max | $0.2-1.0/MTok | $0.7-4.0/MTok | 1M+ | 高 | 直连 |
| Kimi K2.6 | $0.6-1.0/MTok | $2-4/MTok | 256K+ | ~70-80% | 直连 |
本文数据基于 5 月 12 日的最新信息。DeepSeek V4-Pro 的 75% 折扣有效期至 5 月 31 日 15:59 UTC。价格和基准分数可能随时间变化,建议实际测试后选择最适合自己的模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)