Hermes-Agent 生产级实战:闭源大脑驾驭开源手脚的深度架构解析
先给等这篇文章的各位师傅交个底:这篇确实让各位久等了,因为引入辩论团队和辩论模式之后的实测效果太好,关键是另辟蹊径找到了省 token 的新思路,解决了我额度不够折腾的问题,所以一头扎进生产环境里做项目开发,差点忘了更新。但现在可以负责任地说,长时间执行任务产出的内容质量仍然很高,目测已经可以完成各类项目的开发、重构、测试,完整走完一个项目的研发周期——几乎就是立刻拥有了一个小型规模研发公司的能力。以下全文内容,你将kimi code cli换成claude code 结论仍然成立。
一、额度与能力的双重跃迁
先交代背景。我是 Kimi Allegretto 会员,过去高强度使用 AI 的情况下,一周额度大概 3-4 天就会耗尽。不是我用得少,是之前的用法太粗放——单模型单会话,把思考和执行揉在一起,上下文越滚越大,token 烧得飞快。
引入辩论团队和辩论模式之后,情况变了。实测数据显示:以往一周额度 3-4 天耗尽,现在一天不超过周额度的 15%。不是少用了 AI,是用对了地方。
这个变化的本质,是能力结构的重构。以前你雇了一个年薪百万的架构师,结果他每天在工位上帮你装系统、配环境、跑测试。现在架构师只负责拍板和审计,脏活累活交给便宜可靠的执行层。16 支辩论团队 + 8 种辩论模式在 MiniMax 2.7 上跑出来的产出质量,Kimi 给予了非常高的评价——每一轮产出和改动,都是经过 Kimi 验收之后,才交付到我手里由我最终审核。这层双重把关,让错误在到达我面前之前就被拦截了两轮。
更关键的是,这套系统已经证明可以覆盖完整的研发周期:方向探讨、技术选型、架构设计、代码实现、测试、部署、运维、监控。每一步都有辩论团队在交锋,每一步都知道怎么具体实现。你只要把问题抛给它,它的团队就会想方设法找到最合适的解决方案。极少数实在搞不定的,最终也只需要你拍一下板就能解决。
二、辩论引擎实测:16 团队 × 8 模式不是摆设
先破除一个误解:很多人以为"辩论团队"是花架子,是 prompt engineering 的变体。实际跑下来,这玩意是刚需。
当你让 AI 做一个技术决策——比如"这个项目该用 MongoDB 还是 PostgreSQL"——单模型的回答往往是"两者各有优劣,视场景而定",然后列一张对比表。这种回答没错,但没用。因为它没有交锋,没有让你的方案在对抗中被锤炼。
Hermes-Agent 内置的辩论系统,本质上是一个多角色对抗推演框架。16 支团队对应 16 种专业视角,business、compliance、security、platform、content_moderation 等等。8 种辩论模式对应不同的决策机制,adversarial_debate、jury_panel、risk_priority_matrix 等。
实战中的一个典型场景:评估"个人社媒账号做自动化引流"的可行性。单模型可能会给一个模棱两可的回答。但用辩论系统,流程变成:
business团队先出场,从 ROI、获客成本、变现路径论证商业可行性;security团队接棒,从平台风控、设备指纹、行为模式检测角度攻击这个方案;compliance团队补刀,从《反不正当竞争法》《个人信息保护法》指出法律风险;platform团队收尾,评估微信、知乎、小红书、抖音的具体政策和封禁后果;jury_panel模式汇总,各团队投票,给出最终 verdict。
这个流程的产出不是"优缺点列表",而是一份经过充分攻防的裁决结论。你拿到手的是有"司法程序"质量的决策报告。
成本方面,这 5 轮辩论全部在 MiniMax 2.7 上执行,单次调用的 token 成本是 Kimi 的几分之一。同样的决策如果交给 Kimi 单模型完成,为了维持足够的推理深度和角色区分,上下文会迅速膨胀到几万 token,且容易"串戏"。辩论不是锦上添花,是降本增效的核心手段。
三、六阶工作流:从方向到交付的完整闭环
现在聊聊这套系统的日常运转方式。这里我要放一段知友 "james.Lee" 的原话,因为他对于 AI 智能体工作流的理解非常透彻,而且他说的工作流和我现在跑的日常流几乎一模一样。
"肯定能解决的,只不过做不到开箱即用,没有宣传的那么性感。开源社区有很多工具能做到,会比较臃肿,一部分又回到了需人类提前做好很多预案,一点点加规则的老路上。理想状态是:告诉 hermes 给我完成一件什么事情,干活之前先出一份计划书。hermes 返回计划书,人工确认好计划符合预期,hermes 开始规划工作流。hermes 规划好了调度顺序,自动把这套调度顺序加入到硬约束工作流中,各方面开始动工。与此同时人能从检测机制看出每一次 agent 之间交互的上下文中提示词有什么问题,告诉 hermes 来反向优化工作流和 agent 行为,甚至 hermes 自己能从检测机制找到问题,从而达到真正整套体系自我成长的循环。这也是我们用 hermes 的核心目的。"
这段话说出了关键:不是买一把锤子,是搭一条流水线。
我现在每天的工作流如下:
┌─────────────────────────────────────────────────────────────┐
│ Kimi —— Orchestrator(全局角色永恒不变) │
│ 始终监督和验收以下所有任务的产出结果 │
└──────────────────────────┬──────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 任务1 │───▶│ 任务2 │───▶│ 任务3 │───▶ ...
│ 方向辩论 │ │ 方案辩论 │ │ 具体执行 │
└─────────┘ └─────────┘ └─────────┘
任务 1:根据任务内容/类型,调度合适的 Hermes-Agent 辩论团队和辩论引擎,研究方向得出最佳选择报告。
任务 2:任务 1 完成后按顺序执行,根据任务 1 的结论报告,继续调度合适的辩论团队和辩论引擎,得出具体实现报告。
任务 3:根据任务 2 的实现报告执行具体任务。Kimi 会调度 Hermes 使用 kanban/goal,分派 delegation,允许孙代理——即一个代理在执行过程中,如果发现子任务过于复杂,可以 further delegate 给新的代理实例。任务结果生成一份《任务反馈文档》。
任务 4:根据任务 3 的反馈文档,调度辩论团队和辩论引擎,再次生成改进报告并立刻实现。注意这个"立刻"——不是评审完扔一边,是评审完当场改。
任务 5:按最大程度调度辩论团队和辩论引擎,从十几个维度对项目全局进行评估,得出一个改进报告。
任务 6:根据任务 5 的改进报告,继续调度 Hermes-Agent 进行改进。
看晕了吧?还没结束。这是一个相当复杂的长程任务,既有顺序也有并发。任务 1 和任务 2 是串行的,必须等方向确定了才能做方案;但任务 3 内部的多个子代理可以并行,任务 5 的十几个评估维度也可以并行。
这套流水线跑一趟,普遍用时 1-3 小时。这 1-3 小时里,Kimi 的介入点只有:任务启动时的调度决策、每阶段结束时的验收、以及出现 agent 无法自行解决的阻塞时的干预。其余时间,系统在自治运转。期间完全不需要人工介入,这完全符合了建立外部干预机制的预期效果。
这里有一个很多人没意识到的点:并发不是简单的"同时跑多个任务"。任务 3 内部的并发,需要解决上下文隔离问题——每个子代理有自己的 workspace、自己的记忆、自己的错误日志,互不干扰。如果隔离做不好,A 代理修改了一个文件,B 代理同时也在改同一个文件,就会出 race condition。Hermes 的 workspace 机制通过目录隔离解决了这个问题,每个代理实例有自己独立的沙箱。任务 5 的并发更复杂——十几个评估维度可能涉及对同一套代码的不同视角审查,这时候不是隔离问题,是视角合成问题。怎么把 security 团队的"这有注入风险"和 performance 团队的"这有 N+1 查询"合并成一份统一的改进报告?答案是让 jury_panel 模式做最终裁决,各团队的结论作为证据提交,由独立的"评审代理"做加权汇总。
四、提示词工程:从"问问题"到"下工单"
现在的提示词风格已经完全变了。每一次提示词几乎就是不少于八百字的小作文——不是废话多,是必须把背景、约束、验收标准、失败回退策略、关联任务的上下文,全部交代清楚。
为什么变长了?因为接收方不再是"一个会聊天的模型",而是"一个会自主执行的代理系统"。你面对的不是对话窗口,是工单系统。工单上的信息不全,执行层就会按自己的理解瞎猜,猜错的代价是几小时的返工。
一个典型的任务工单长这样:
- 项目背景:当前处于什么阶段、前序任务产出了什么、有哪些已知坑
- 任务目标:本次要交付什么、验收标准是什么、什么算完成
- 约束条件:硬约束(绝对不能碰的红线)、软约束(编码规范、技术偏好)
- 关联任务:上游依赖谁、下游影响谁、回退时该回到哪个检查点
- 注意事项:已知的历史错误、需要规避的模式、特别关注的边界情况
- 失败策略:如果超时怎么办、如果产出不达标怎么办、如果陷入循环怎么办
这种提示词写起来累,但写完之后执行层的出错率显著下降。而且因为工单是结构化的,Kimi 在验收时有明确的 checklist 可以对照,不需要再凭感觉判断"这次做得好不好"。
五、三层约束:Harness Engine + AGENTS.md + SOUL.md
在你的这些提示词以下,还要列入必要注意事项。知友 james.Lee 提出的硬约束工作流,我已通过引入三层约束机制进行规范:全局 harness engine(硬约束)、AGENTS.md(项目规范)、SOUL.md(人格约束)。实测有效。
Harness Engine:物理阻断
这是全局规则引擎,以代码形式固化在配置中。不是建议,是物理阻断。Hermes 在把工具调用转发给执行层之前,先经过 harness engine 校验。触发硬约束的调用会被直接拦截,并记录审计日志。
典型规则:禁止修改 .gitignore 和 CI/CD 配置;禁止在生产环境执行写操作;单次文件修改超过 50 行必须拆分;任何删除操作先在备份目录保留副本。
设计理念来自核反应堆的控制棒:平时不干预反应过程,一旦参数越界,立刻物理插入、强制降速。
AGENTS.md:项目规范
每个项目目录下的上下文文件,描述"这个项目的背景、规范、偏好"。Kimi 调度任务时读取它,Hermes 创建代理时注入初始上下文。
内容示例:"本项目使用 2 空格缩进;所有云函数必须包含健康检查端点;优先使用微信云开发原生 API。"这些规范不会被执行层强制检查,但会作为提示词的一部分影响行为。
SOUL.md:人格约束
定义代理的决策偏好——不是拟人化的聊天风格,是决策的数学表达。
示例:"面对安全性和便利性的冲突,优先选择安全性;面对简洁性和功能完整性的冲突,优先选择简洁性;遇到不确定的需求,默认选择最保守的实现。"
这个文件解决一个非常实际的问题:同一个技术问题,不同代理可能给出不同的方案。没有统一的人格约束,A 代理写的模块和 B 代理写的模块会打架,最后代码库变成缝合怪。比如 A 代理习惯用 async/await 处理异步逻辑,B 代理习惯用回调函数,两者写在一个项目里,维护的人想杀人。
三层协同的工作方式是这样的:当一个代理准备执行一个文件修改时,harness engine 先检查——这次修改有没有触碰红线?没有的话放行。代理读取 AGENTS.md,知道"这个项目用 2 空格缩进",于是按规范生成代码。代理读取 SOUL.md,知道"安全性优先于便利性",于是在两种实现方案中选择了更安全但稍微复杂的那一种。三层约束像漏斗一样,从外到内层层收窄代理的自由度,最后产出的代码既合法、又规范、又风格一致。
Harness 管底线,AGENTS 管规范,SOUL 管风格。底线越了直接拦住,规范忘了提示纠正,风格偏了通过人格校准。
六、记忆持久化:为什么我不信任 Agent 自己成长
至于后半部分的反向优化工作流和自我成长循环,我完全没有把希望放在 Hermes-Agent 上。这一点在我刚刚使用 hermes-agent 时已经很清楚了。
记得第一天使用 Hermes-Agent 退出对话时,大概一分钟左右才退出成功。我当时觉得奇怪,为什么退出要这么久?后来搞明白了:hermes 要从我本次对话记录中提取一个 skill 并持久化到记忆里。当时回顾了一下对话内容,我的看法是,这个设计并不好,现在还是坚持这个看法。
问题在哪?如果让 agent 自己决定什么该被保存、什么该被遗忘、什么该被修正,它会把所有对话内容都当成"经验"持久化——包括成功的决策、失败的尝试、错误的推理、甚至是上下文污染导致的幻觉输出。时间一长,记忆库变成垃圾堆,新任务从这个垃圾堆里检索"经验",形成恶性循环。
更致命的是,agent 缺乏元认知能力。它不知道自己的哪个决策是好的、哪个是坏的。它可能把一次巧合的成功当成可复用的模式,也可能把一次必要的试错当成应该避免的错误。没有外部裁判,它无法区分"有效经验"和"噪声"。(关于这个,我在官方更新之前就已经吐槽过,官方许多realese发布后,情况好了很多,但我还是要吐槽,因为考虑还不够全面,Hermes-Agent的自我进化机制远远没有达到一个完全自动化的标准)
这里面的技术根源在于:当前大模型的"记忆"本质上是参数更新或者向量检索, neither 能承载"因果推理"。模型记住了"上次这么做成功了",但它不知道成功的原因是"这个做法本身正确"还是"那次任务的上下文恰好匹配"。当它把这条"经验"应用到新任务时,如果上下文变了,经验可能从资产变成负债。Kimi 作为外部审计员,它的价值不是"记忆力更好",而是它能做跨任务的因果归因——通过对比多次任务的日志,识别出哪些模式是真正稳健的、哪些是偶然有效的。
所以我把这件事交给了 Kimi。
具体机制:每次长程任务结束后,Kimi 读取完整的任务日志——所有代理的交互记录、工具调用序列、错误堆栈、最终产出。Kimi 的角色不是参与者,是审计员。它回答几个问题:
- 任务产出是否符合预期?根因在哪一层(决策/调度/执行)?
- 代理是否出现了系统性错误?重复犯同一类错误?陷入循环?使用了低效的工具调用序列?
- 工作流设计本身是否有缺陷?验收标准不够清晰?辩论团队视角有盲区?约束条件过松或过紧?
- 哪些经验该持久化到 AGENTS.md 或 SOUL.md?哪些该丢弃?
Kimi 的审计结论写成《工作流优化建议》,然后由 Hermes-Agent 负责落地为配置文件的修改。让 Kimi 作为监督者和验收者,全面监控执行任务过程中出现的错误,并找到持久化解决方案改动到 hermes-agent。目前认为这个方法是有效的。
这个设计的关键在于分工:Kimi 负责"判断对错"(需要强推理),Hermes 负责"动手修改"(需要工程执行)。两者各司其职,都不会越界。
七、"意图":我能想到最好的表达词汇
小小总结一下我们现在的 hermes-agent 用法。上层闭源 CLI 工具的强大能力无需质疑,下层 hermes-agent 接入"便宜"可靠的执行模型以及利用外部引入机制实现各种意图——"意图",这是我能想到的最好的表达词汇。
什么意思?你不是在"指挥 AI 写代码",你是在"表达意图",让系统自己找出实现路径。
举个例子。传统的交互是:"请帮我写一个 Python 函数,接收一个列表,返回去重后的列表,保持原有顺序。"——这是命令,你把每一步都规定死了。
现在的交互是:"我需要一个数据清洗模块,核心要求是去重时保持顺序,性能要够处理百万级数据,并且要有完整的单元测试覆盖。其他细节你自己决定。"——这是意图,你只规定了"要什么"和"什么算好","怎么做"交给系统推演。(我这里的示例指的是开发者有了一定代码和上下文基础,没有的话你就直接下单要求给方案一样成立)
意图驱动的核心好处是:释放了下层执行层的创造力。如果每一步都规定死了,执行层就变成了打字机,token 烧在"翻译你的命令"上,而不是"解决你的问题"上。如果只给意图,执行层的辩论团队会主动探索多种实现路径,在对抗中找到最优解。
当然,意图驱动的前提是约束机制到位。没有 harness engine 和验收标准,意图驱动就会变成"放任自流"。意图是方向盘,约束是护栏,两者缺一不可。
还有一个常见的误解需要澄清:有人觉得"意图驱动"就是"说人话",就是把需求描述得口语化一些。其实不是。意图驱动的核心不是表达形式,是表达粒度——你在什么层面上做决策、在什么层面上放手。"用 React 写一个登录页面,表单包含用户名和密码字段,提交时调用 /api/login,失败时显示红色错误提示"——这是命令,虽然说得像人话,但粒度太细,执行层没有决策空间。"实现一个登录模块,核心要求是无刷新体验、错误反馈明确、对暴力破解有基本防护,技术栈你定"——这才是意图,粒度在"模块"层面,执行层可以自己决定用 form 还是 JSON、用 session 还是 JWT、用验证码还是 rate limiting。
八、成本账本:为什么长任务反而省 token
现在上真实数字。
过去纯 Kimi 工作流,一周额度大概 3-4 天耗尽。现在上层 Kimi + 下层 MiniMax 的混合架构,一天消耗不超过周额度的 15%。
和以往的使用区别在于:现在每次执行任务的时间没有低于半小时的,但是 token 的消耗更少,而产出质量更高。本人现在使用的 Hermes-Agent 与当初刚接触时已经是天差地别了。
反常识的地方在于,长任务反而更省 token。三个原因:
第一,上下文切割降低了膨胀成本。 单会话模式下,上下文长度随时间线性增长,模型每轮回复都要把之前的全部对话历史重新读一遍,token 消耗是 O(n²) 级别。分层架构把长上下文切割成独立的短任务,每个 MiniMax 代理只处理一个具体子任务,上下文控制在几百到几千 token。
第二,辩论引擎把推理成本下放到廉价模型。 一个复杂的技术决策,如果在 Kimi 上完成,可能需要 3-5 轮深度推理,总计上万 token。同样的决策交给 MiniMax 的辩论系统,5 支团队各输出一轮观点(假定并行辩论模式),总计几千 token——但单价差了几倍。
第三,自治执行减少了人类的无效交互。 传统模式下,AI 写一段代码,你检查一遍,发现问题,打一段文字描述问题,AI 修改,你再检查……这个"你-我-你-我"的循环是 token 消耗的大头。自治模式下,代理自己写、自己测、自己改,错误发现和修复都在执行层内部完成。只有当代理遇到无法自行解决的阻塞时,才会上升到 Kimi 层面。
额度焦虑的本质不是"钱不够",是"钱花在错的地方"。把账算清楚,架构分清楚,agent 就能从玩具变成工具。
九、不侵入源码:OpenClaw 踩过的坑教会了我
通过外部机制接入的方案并不会影响到 hermes-agent 未来的官方更新。这一点很重要。
我们在 OpenClaw 踩过的坑教会了这一点。OpenClaw 是另一个类似的 agent 框架,早期为了适配自己的需求,我改了不少源码——加钩子、修逻辑、调参数。短期内确实解决了问题,但官方一更新,所有修改全部作废,merge conflict 多到让人想放弃。
这次用 Hermes-Agent,我坚持了一条红线:只通过配置文件和外部插件机制扩展,不动核心源码。Harness engine、AGENTS.md、SOUL.md、辩论团队模板、自定义 skill——所有这些扩展点都是 Hermes 官方预留的插件接口。即使官方发布新版本,我的配置可以无缝迁移。
这个原则看似保守,实则是生产环境的生存法则。工具链的稳定性比功能的完美性更重要。你今天改了一个优雅的 hack,明天官方更新就可能让你回不了家。
十、预告与边界
往后不会再专注于开发环境的研究(Hermes-Agent),我们的生产环境已经完整搭建好了。在没有新的生产需求时,我们将持续使用这套生产设施进行项目开发。因此,接下来放出的文章都将是实际的项目开发经历。
但在你跃跃欲试之前,先泼一盆冷水:这套系统不是万能药。
- 单次性的简单任务(比如写个正则提取手机号):直接问 Kimi,30 秒出答案。上 kanban 反而 overhead 过大。
- 创意发散型任务(比如想 10 个品牌名字):需要人类的审美判断,代理的辩论系统没有优势。
- 高实时性任务(比如服务器挂了立刻排查):长程自治的设计目标不是实时响应,是深度交付。救火场景还是需要人直接上手。
Sweet spot 是:有一定复杂度、需要多步骤协作、对一致性和可维护性有要求、且允许 1-3 小时交付周期的工程任务。功能开发、代码重构、技术方案评估、测试覆盖补全——这些是它的主战场。
框架的价值最终要靠项目来验证。这篇六千字聊完了架构,接下来该聊战场上的故事了。
以下是根据kimi调度hermes-agent进行项目开发的图片记录:
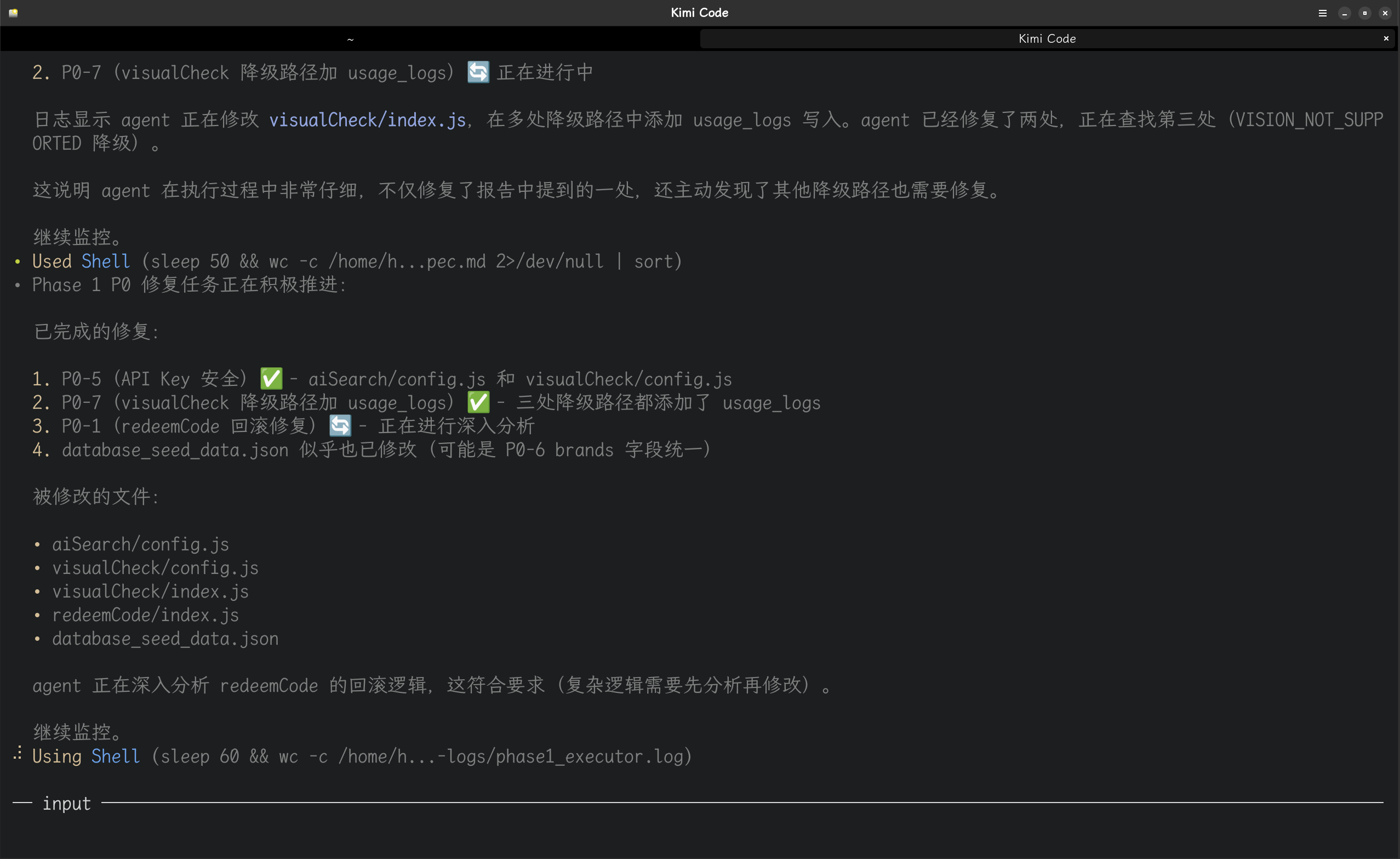
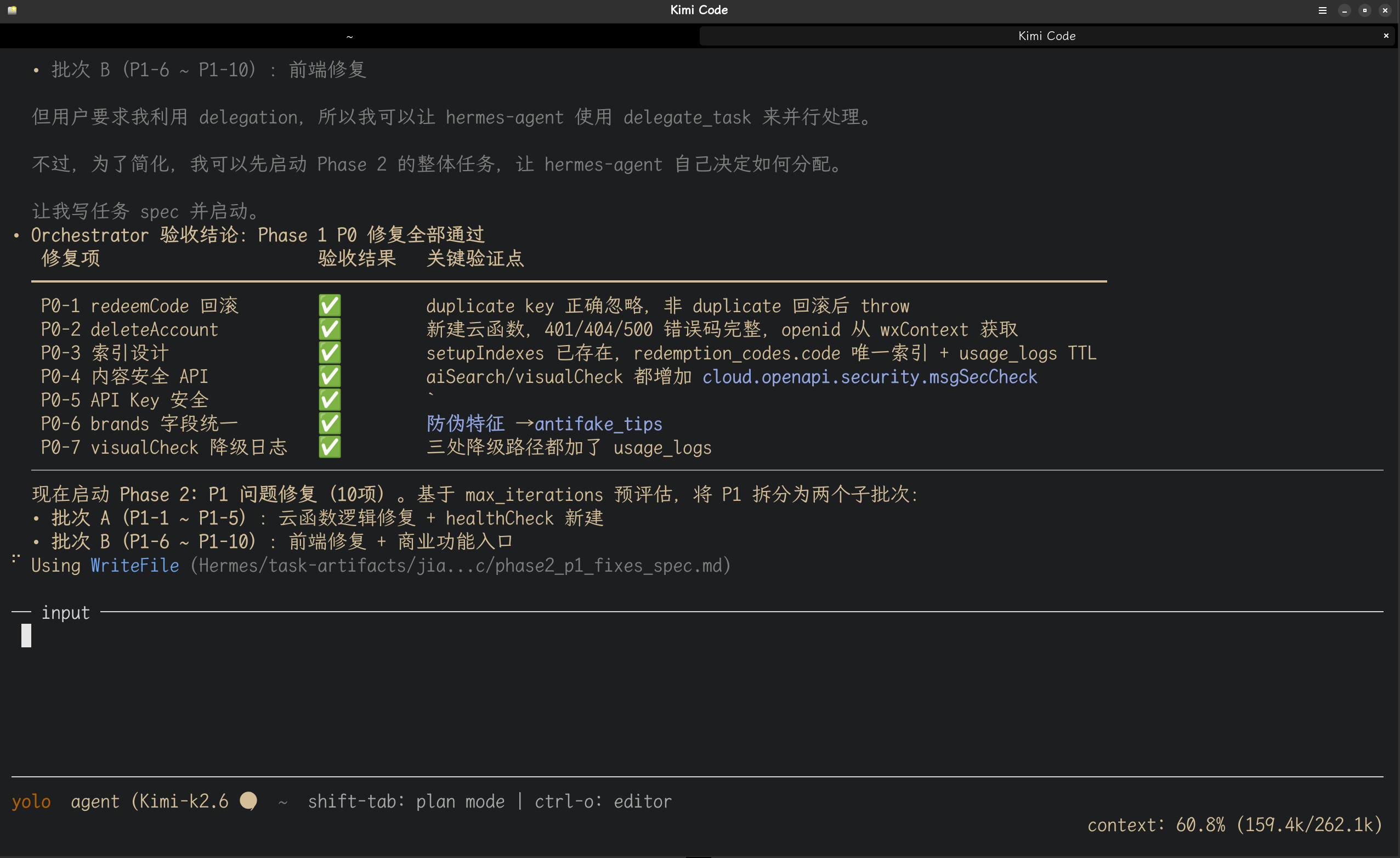
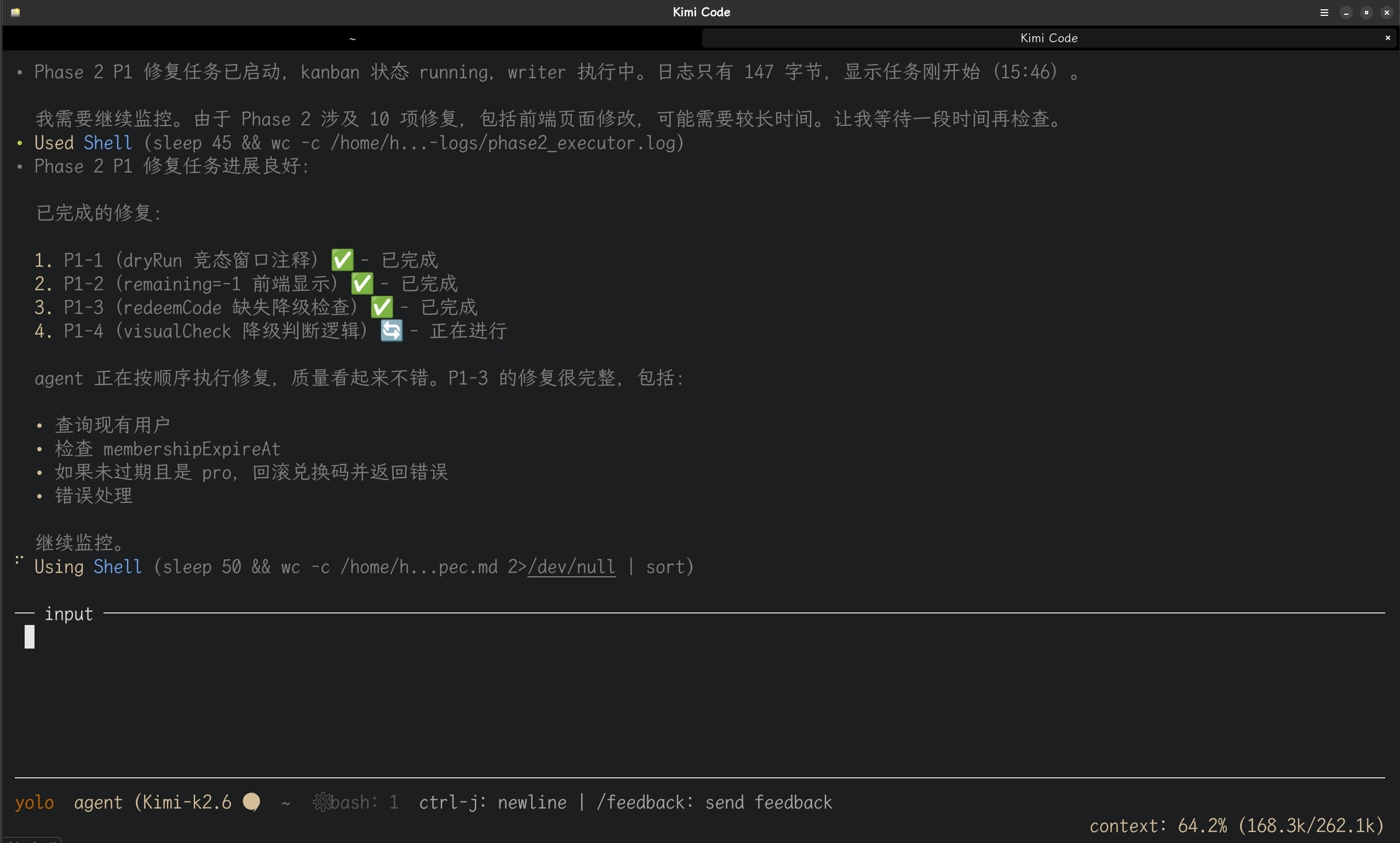
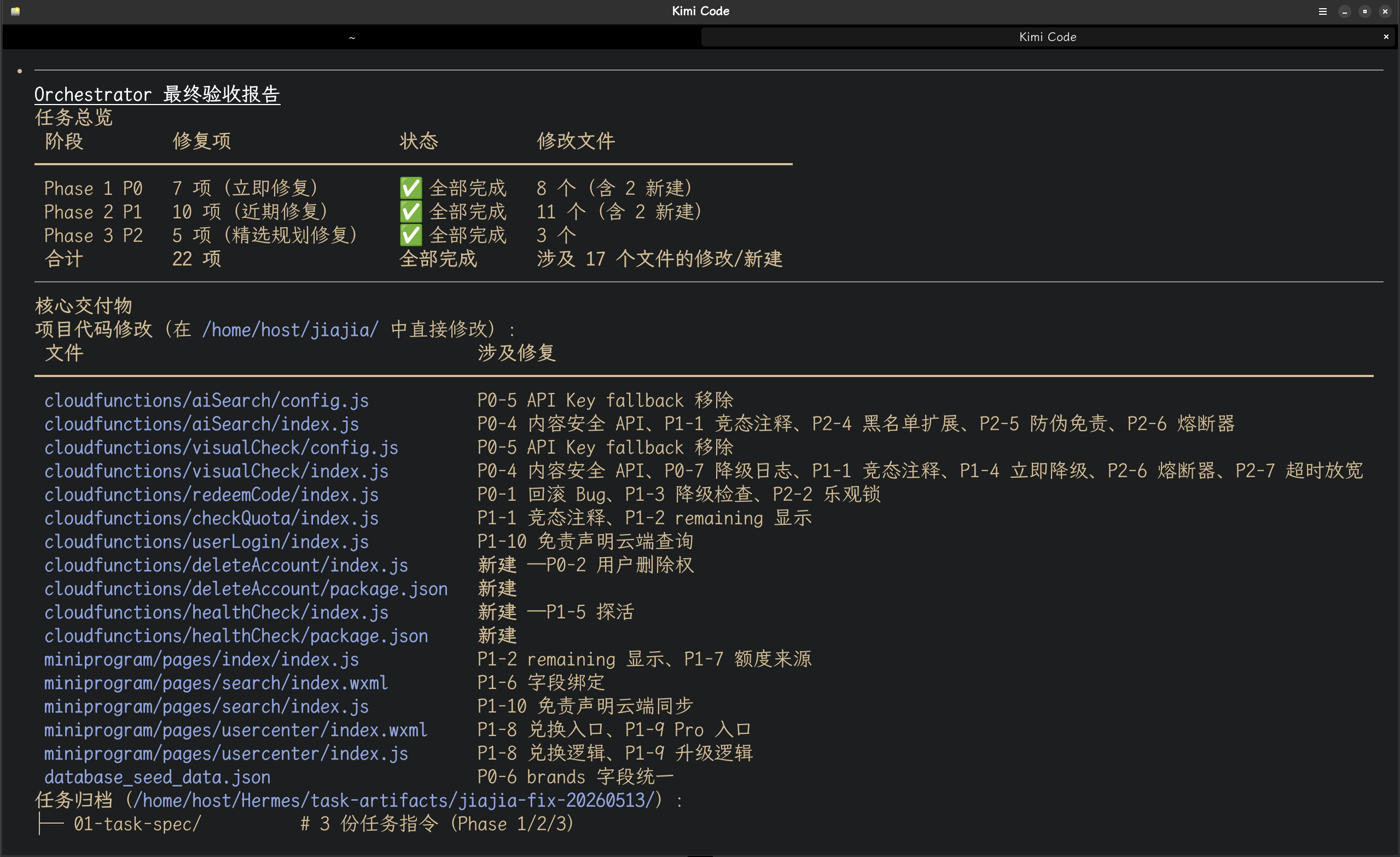
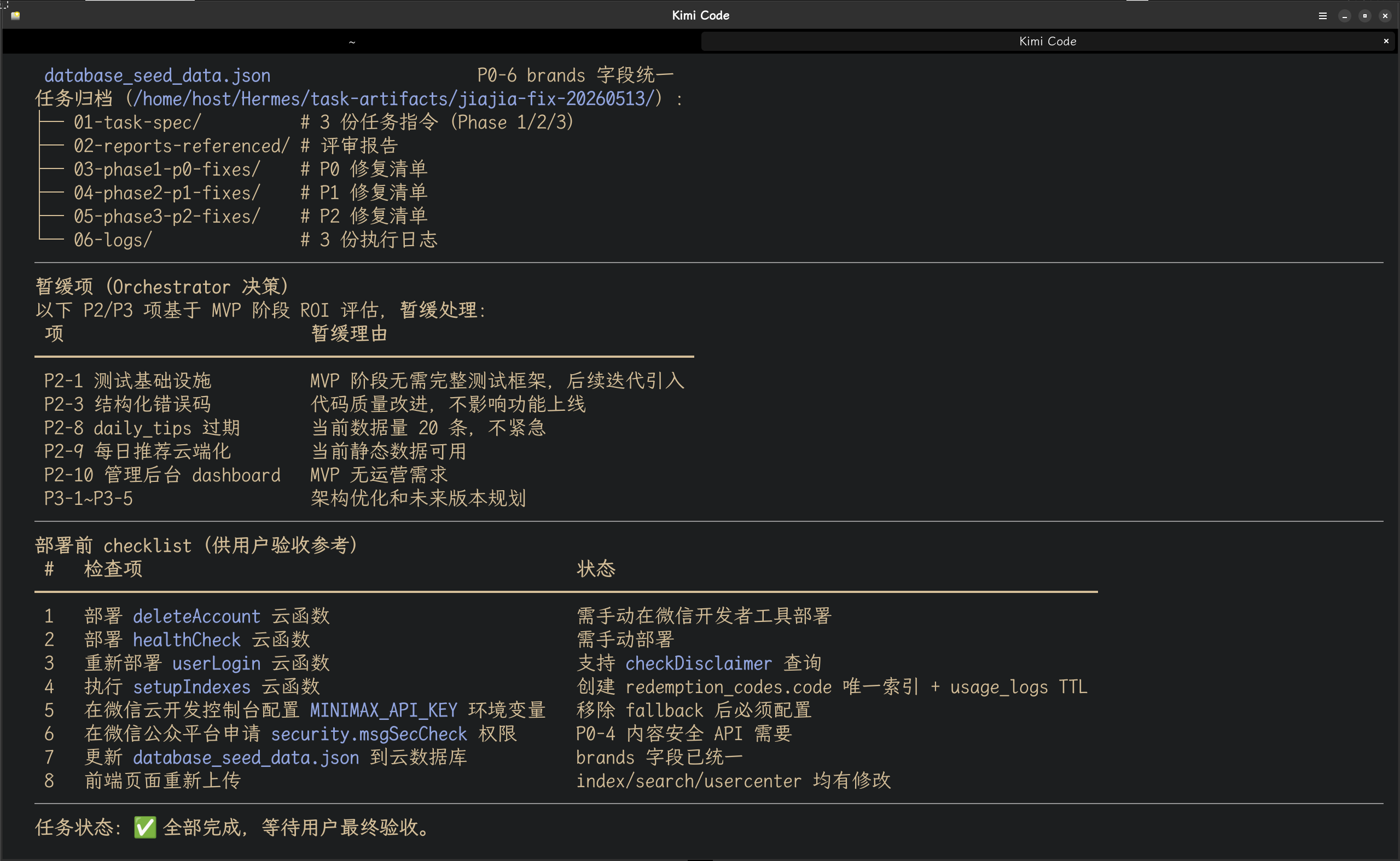
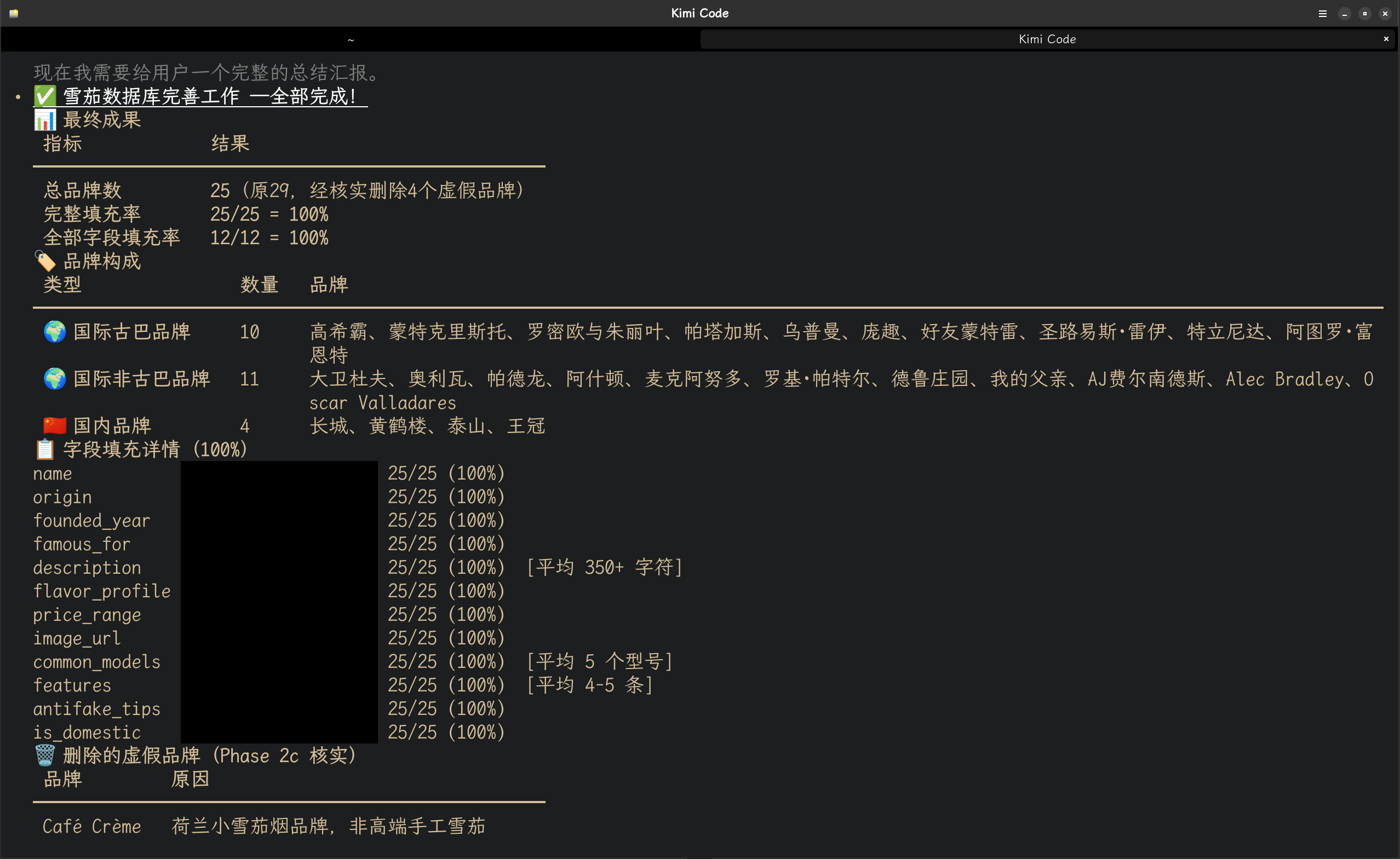
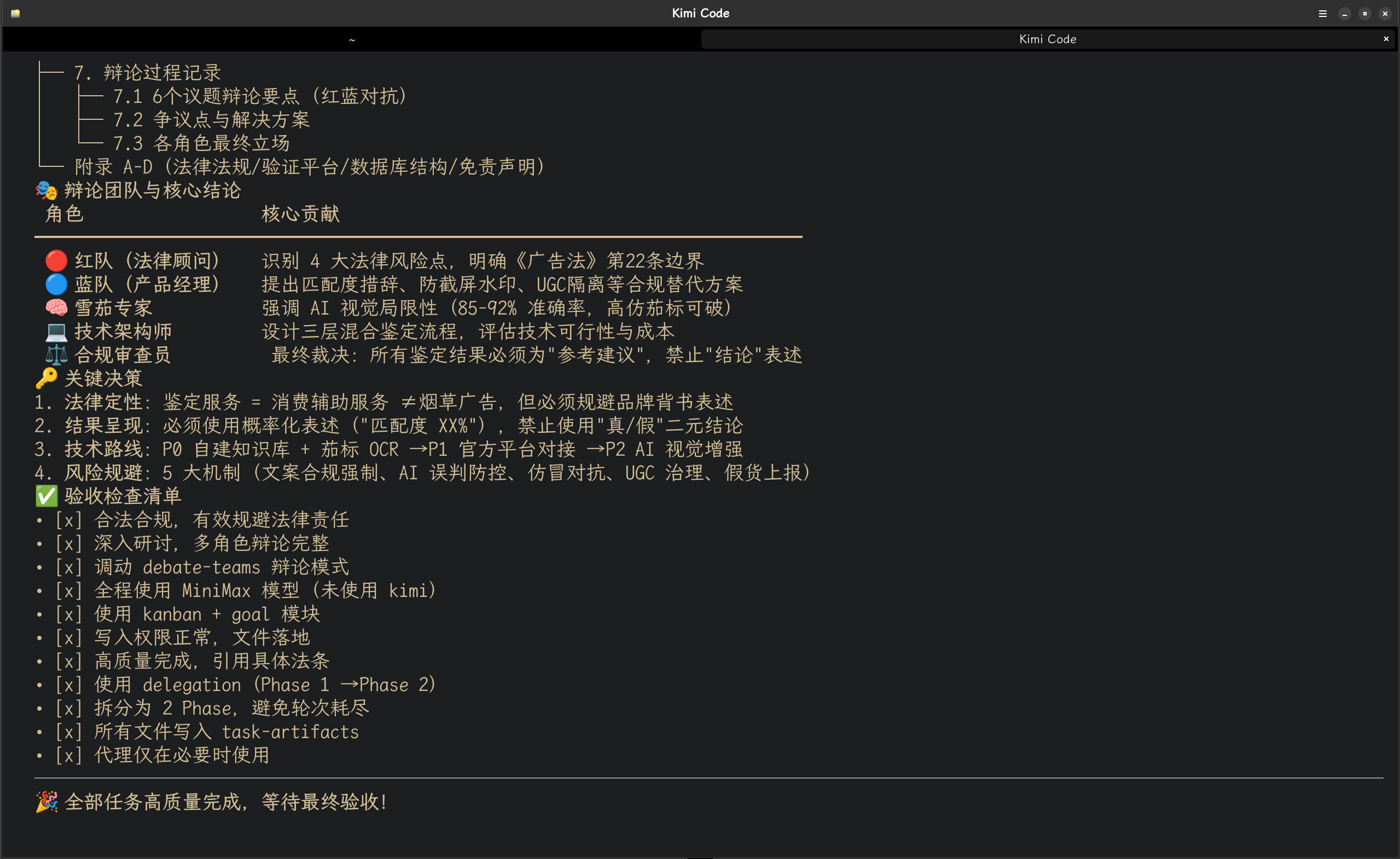
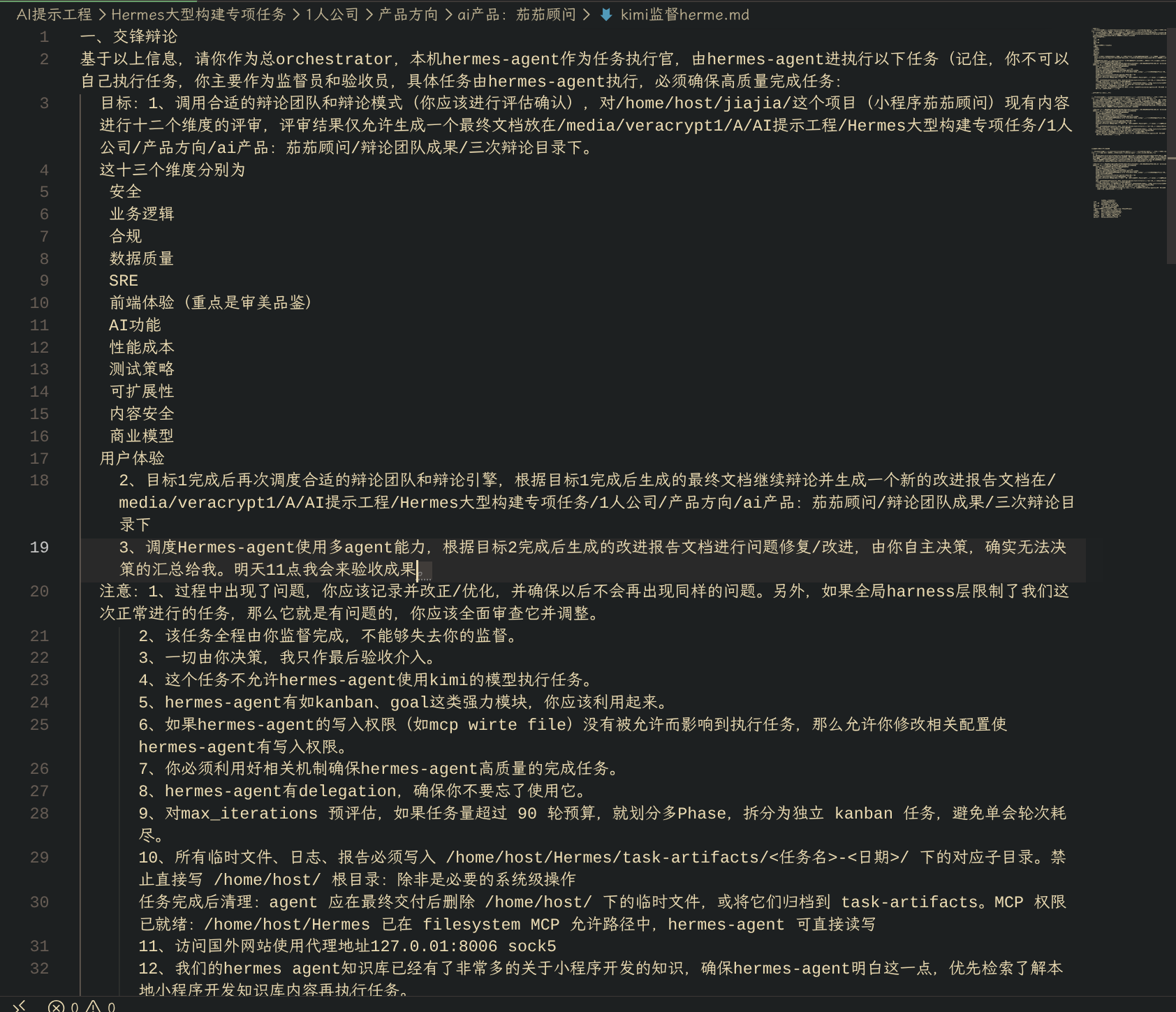
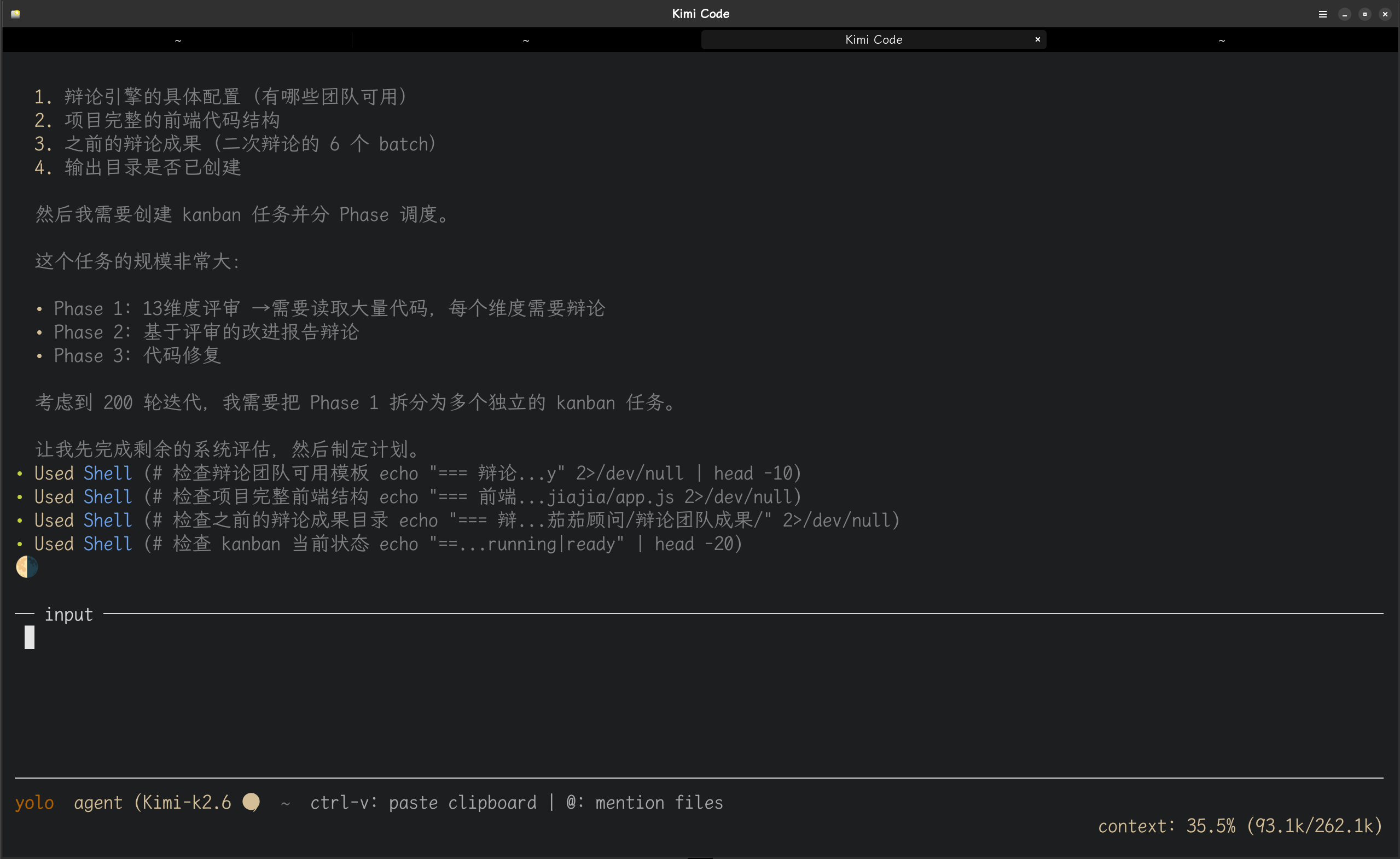
本文基于 Hermes-Agent 生产环境实战经验撰写,所有架构设计、数字记录和具体场景均为真实使用记录。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)